
Un camino espinoso y difícil de una persona que se ha encontrado con el FSIS USRN Rosreestr. Está esperando interminables esperas a que se cargue el navegador, claves, captchas, intervalos entre solicitudes de 5 minutos. ¿Por qué iba a sufrir tanto? Ya había contribuido con el dinero que tanto le costó ganar cuando decidió trabajar con este sistema y encargar sus extractos. Pero no, obtener un extracto de la USRN es como desvestir cebollas. El último paso que le espera al paciente: el codiciado extracto descargado está representado por un archivo zip, en el que, um, otro archivo y un archivo sig. Y el archivo de declaración en sí ya está dentro. Pero tampoco es fácil de leer, está en xml. Y para que todo crezca junto, resulta que es necesario descargar este xml junto con sig a una página especial de Rosreestr. Y ahí, todavía hay un captcha esperando. ¡Y así con cada declaración! Hoy superaremos este último dolor usando Python.
Tarea:
- descomprime todo el zip en la carpeta,
- descargar por especificación. enlace a Rosreestr,
- finalmente descarga !, una vista legible por humanos de la declaración.
Entonces, inicialmente en la carpeta hay archivos zip descargados de extractos:
Después de importar los módulos de Python:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Desempaquetemos todos los archivos zip y eliminémoslos para que no se confundan con el contenido:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Tenemos archivos zip y archivos sig para ellos, que luego se subirán al sitio web de Rosreestr:
Vaya al ciclo principal del programa para todos los archivos en el directorio (en mi caso, "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
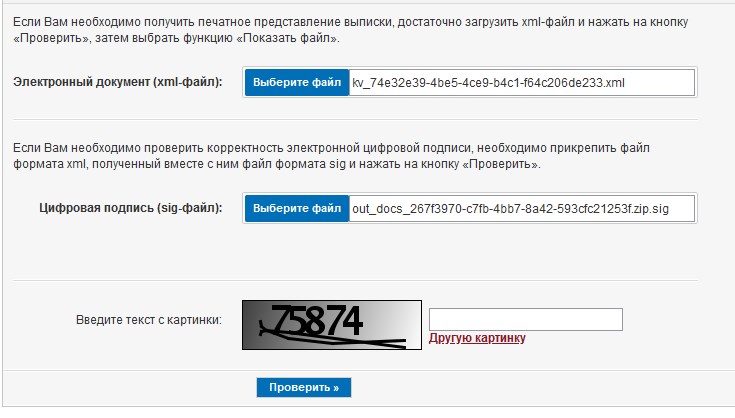
Después de cargar con éxito la página del portal Rosreestr rosreestr.gov.ru/wps/portal/cc_vizualisation , el programa encontrará el archivo zip en el directorio, obtendrá el archivo de declaración xml desde allí y lo insertará en el campo requerido en el sitio web. El programa hará lo mismo con el archivo sig adjunto al xml:
A continuación, el programa esperará a que se
ingrese el captcha : Después de que el usuario ingrese el captcha, lo enviará al sitio y hará clic en el enlace de descarga para el extracto ya "normal" de la USRN:
Se abrirá una ventana en la que se terminó extracto, que se puede guardar en html o presionando CTRL + P en Chrome - en pdf.
Queda por agregar captcha de resolución automática y descarga automática de extractos legibles por humanos. Pero esto es lo más simple aquí, ¿no?
El código del programa está aquí .