En mi charla, compartí mi experiencia con el uso de Alembic, una herramienta probada para administrar migraciones. Por qué elegir Alembic, cómo usarlo para preparar migraciones, cómo ejecutarlas (automática o manualmente), cómo resolver los problemas de cambios irreversibles, por qué probar las migraciones, qué problemas pueden revelar las pruebas y cómo implementarlas, intenté responder a todas estas preguntas. Al mismo tiempo, compartí varios trucos de vida que harán que trabajar con migraciones en Alembic sea fácil y agradable.
Desde el día del informe, el código en GitHub se ha actualizado ligeramente, hay más ejemplos. Si desea ver el código exactamente como aparece en las diapositivas, aquí hay un enlace a una confirmación de ese momento.
- ¡Hola! Mi nombre es Alejandro, trabajo en Edadil. Hoy quiero contarte cómo vivimos las migraciones y cómo podrías vivir con ellas. Quizás esto te ayude a vivir más fácilmente.
¿Qué son las migraciones?
Antes de comenzar, vale la pena hablar sobre qué son las migraciones en general. Por ejemplo, tienes una aplicación y creas un par de tablets para que funcione, va a ellas. Luego, lanza una nueva versión, en la que algo ha cambiado: la primera placa ha cambiado, la segunda no y la tercera no estaba allí antes, pero apareció.

Luego aparece una nueva versión de la aplicación, en la que se borra alguna placa, al resto no le pasa nada. ¿Lo que es? Podemos decir que este es el estado que se puede describir por migración. Cuando nos movemos de un estado a otro, esto es una actualización, cuando queremos retroceder - degradar.
¿Qué son las migraciones?

Por un lado, este es un código que cambia el estado de la base de datos. Por otro lado, este es el proceso que iniciamos.

¿Qué propiedades deben tener las migraciones? Es importante que los estados entre los que cambiamos en las versiones de la aplicación sean atómicos. Si, por ejemplo, queremos que tengamos dos tablas, pero solo aparece una, esto puede tener consecuencias no muy buenas en la producción.
Es importante que podamos revertir nuestros cambios, porque si lanzas una nueva versión, esta no despega y no puedes revertir, todo suele terminar mal.
También es importante que las versiones estén ordenadas para que pueda encadenar la forma en que se enrollaron.
Herramientas
¿Cómo podemos implementar estas migraciones?
La primera idea que me viene a la mente: está bien, la migración es SQL, ¿por qué no tomar y hacer archivos SQL con consultas? Hay varios módulos más que pueden hacernos la vida más fácil.

Si miramos lo que está sucediendo adentro, entonces hay un par de solicitudes. Podría ser CREAR TABLA, ALTERAR, cualquier otra cosa. En el archivo downgrade_v1.sql, lo cancelamos todo.

¿Por qué no deberías hacer esto? Principalmente porque necesitas hacerlo con tus manos. No olvide escribir begin, luego confirme sus cambios. Cuando escriba código, deberá recordar todas las dependencias y qué hacer en qué orden. Este es un trabajo bastante rutinario, difícil y que requiere mucho tiempo.
No tiene protección contra el lanzamiento accidental de un archivo incorrecto. Necesita ejecutar todos los archivos a mano. Si tienes 15 migraciones no es fácil. Necesitará llamar a psql 15 veces, no será muy bueno.
Lo más importante es que nunca se sabe en qué estado se encuentra su base de datos. Debe anotar en algún lugar, en una hoja de papel, en otro lugar, qué archivos descargó y cuáles no. Tampoco suena muy bien.

Hay un módulo de migraciones yoyo . Es compatible con las bases de datos más comunes y utiliza consultas sin formato.

Si miramos lo que nos ofrece, se ve así. Vemos el mismo SQL. Ya hay un código Python a la derecha que importa la biblioteca yoyo.

Por lo tanto, ya podemos iniciar migraciones, exactamente de forma automática. En otras palabras, hay un comando que crea y agrega una nueva migración a la cadena, donde podemos escribir nuestro código SQL. Usando comandos, puede aplicar una o más migraciones, puede revertir, esto ya es un paso adelante.

La ventaja es que ya no necesita escribir en una hoja de papel qué solicitudes ha realizado en la base de datos, qué archivos ha lanzado y dónde necesita revertir si algo sucede. Tiene algún tipo de protección infalible: ya no podrá ejecutar una migración diseñada para otra cosa, para la transición entre otros dos estados de la base de datos. Una gran ventaja: esto hace que cada migración se realice en una transacción separada. Esto también da tales garantías.

Las desventajas son obvias. Todavía tiene SQL sin formato. Si, por ejemplo, tiene una gran producción de datos con lógica en expansión en Python, no puede usarla, porque solo tiene SQL.
Además, encontrará una gran cantidad de trabajo de rutina que no se puede automatizar. Es necesario realizar un seguimiento de todas las relaciones entre las tablas: lo que se puede escribir en algún lugar y lo que aún no es posible. En general, existen desventajas bastante obvias.
Otro módulo al que merece la pena prestar atención, y del que se habla toda la jornada de hoy, es Alambique .

Tiene las mismas cosas que el yoyo y mucho más. No solo monitorea sus migraciones y sabe cómo crearlas, sino que también le permite escribir una lógica comercial muy compleja, conectar toda su producción de datos, cualquier función en Python. Extraiga los datos y trátelos internamente si lo desea. Si no quieres, no tienes que hacerlo.
Él puede escribir código automáticamente en la mayoría de los casos. No siempre, por supuesto, pero suena como una buena ventaja después de haber tenido que escribir mucho con las manos.
Tiene muchas cosas interesantes. Por ejemplo, SQLite no es totalmente compatible con ALTER TABLE. Y Alembic tiene una funcionalidad que te permite evitar esto fácilmente en un par de líneas, y ni siquiera pensarás en ello.
En las diapositivas anteriores, había un módulo de migraciones de Django. Este también es un módulo muy bueno para migraciones. Su principio es comparable al Alembic en funcionalidad. La única diferencia es que es específico del marco y Alembic no lo es.
SQLAlchemy
Dado que Alembic se basa en SQLAlchemy, sugiero ejecutar un poco a través de SQLAlchemy para recordar o descubrir qué es.

Hasta ahora, hemos analizado las consultas sin procesar. Las consultas sin procesar no están mal. Esto puede ser muy bueno. Cuando tiene una aplicación muy cargada, tal vez esto sea exactamente lo que necesita. No es necesario perder el tiempo convirtiendo algunos objetos en algún tipo de consulta.
No se requieren bibliotecas adicionales. Solo toma el controlador y listo, funciona. Pero, por ejemplo, si escribe consultas complejas, no será tan fácil: bueno, puede tomar una constante, moverla hacia arriba, escribir un código grande de varias líneas. Pero si tiene entre 10 y 20 solicitudes de este tipo, ya será muy difícil de leer. Entonces no puede reutilizarlos de ninguna manera. Tienes mucho texto y, por supuesto, funciones para trabajar con strings, f-strings y todo eso, pero esto ya no suena muy bien. Son difíciles de leer.
Si, por ejemplo, tiene una clase dentro de la cual también desea tener consultas y estructuras complejas, la sangría es una molestia. Si desea realizar una migración sin procesar, la única forma de encontrar dónde está usando algo es con grep. Y tampoco tiene una herramienta dinámica para consultas dinámicas.
Por ejemplo, una tarea súper fácil. Tienes una entidad, tiene 15 campos en una placa. Quieres hacer una solicitud de PATCH. Parecería super simple. Intente escribir esto en consultas sin formato. No se verá muy bonito y es poco probable que se apruebe la solicitud de extracción.

Existe una alternativa a esto: el generador de consultas. Ciertamente tiene inconvenientes porque le permite representar sus consultas como objetos en Python.
Para mayor comodidad, tendrá que pagar tanto el tiempo de generación de solicitudes como la memoria. Pero hay ventajas. Cuando escribe aplicaciones grandes y complejas, necesita abstracciones. El generador de consultas puede proporcionarle estas abstracciones. Estas consultas se pueden descomponer; veremos cómo se hace esto un poco más adelante. Se pueden reutilizar, ampliar o incluir en funciones que ya se denominarán nombres descriptivos asociados con la lógica empresarial.
Es muy fácil crear consultas dinámicas. Si necesita cambiar algo, escriba una migración, el análisis estadístico del código es suficiente. Es muy conveniente.
¿Por qué SQLAlchemy de todos modos? ¿Por qué vale la pena detenerse?

Esta es una pregunta no solo sobre la migración, sino en general. Porque cuando tenemos Alembic, tiene sentido usar toda la pila a la vez, porque SQLAlchemy no solo funciona con controladores síncronos. Es decir, Django es una herramienta genial, pero Alchemy se puede usar, por ejemplo, con asyncpg y aiopg . Asyncpg le permite leer, como dijo Selivanov, un millón de líneas por segundo: leer de la base de datos y transferir a Python. Por supuesto, con SQLAlchemy habrá un poco menos, habrá algunos gastos generales. Pero de todos modos.
SQLAlchemy tiene una cantidad increíble de controladores con los que sabe cómo trabajar. Existen Oracle y PostgreSQL, y todo para todos los gustos y colores. Además, ya están listos para usar, y si necesita algo por separado, allí, recientemente miré, incluso está Elasticsearch. Es cierto, solo para leer, pero ¿entiendes? - Elasticsearch en SQLAlchemy.
Hay muy buena documentación, una gran comunidad. Hay muchas bibliotecas. Y lo que es más importante, no le impone marcos ni bibliotecas. Cuando está realizando una tarea limitada que debe hacerse bien, puede ser una herramienta.
Entonces, ¿en qué consiste?
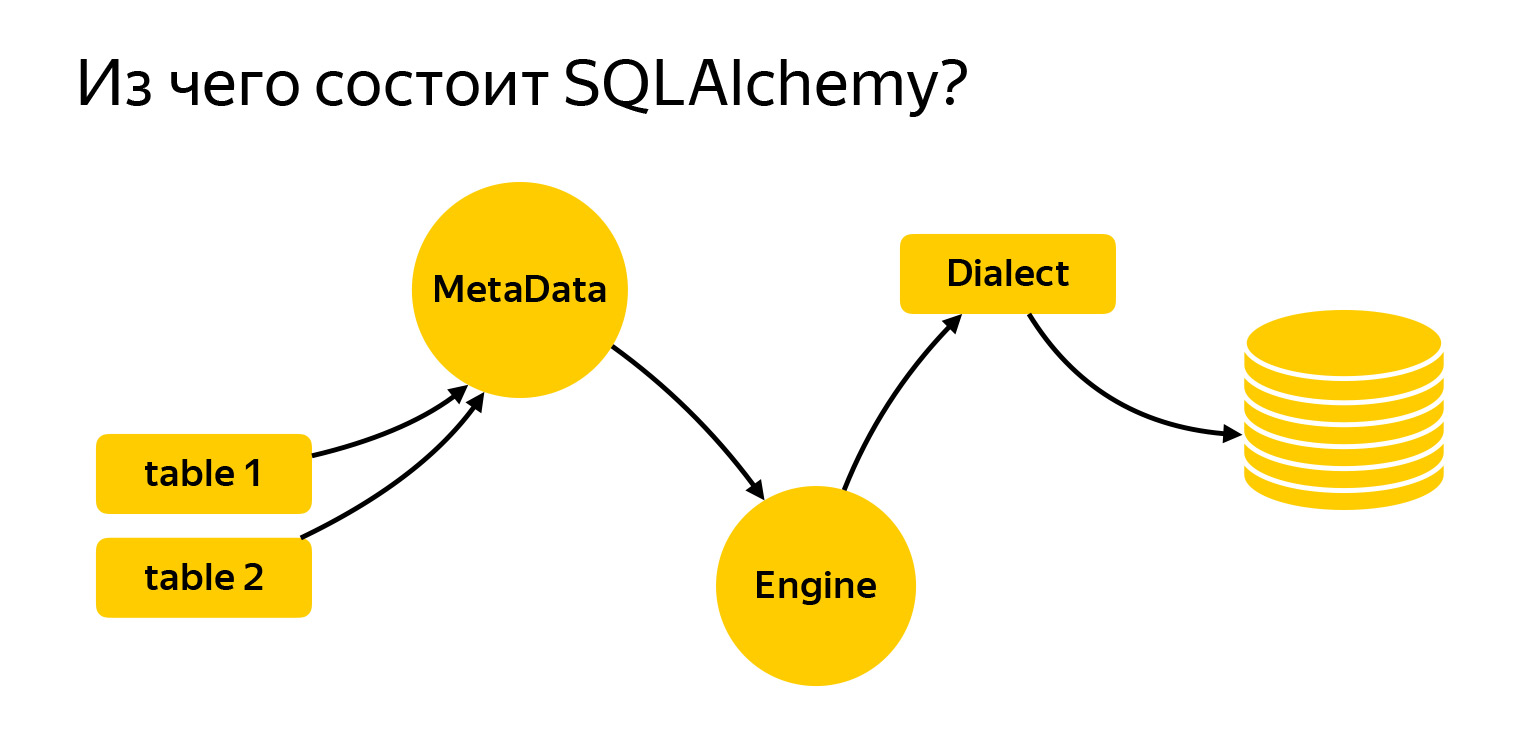
Traje aquí las principales entidades con las que trabajaremos hoy. Estas son tablas. Para escribir solicitudes, es necesario que le digan a Alchemy qué es y con qué estamos trabajando. El siguiente es el registro de metadatos. El motor es algo que se conecta a la base de datos y se comunica con ella a través de Dialect.
Echemos un vistazo más de cerca a lo que es.

MetaData es una especie de objeto, un contenedor, en el que agregarás tus tablas, índices y, en general, todas las entidades que tengas. Este es un objeto que refleja, por un lado, cómo desea ver la base de datos, en función de su código escrito. Por otro lado, los metadatos pueden ir a la base de datos, obtener una instantánea de lo que realmente está allí y construir este modelo de objetos.
Además, el objeto MetaData tiene una característica muy interesante. Le permite definir una plantilla de nomenclatura predeterminada para índices y restricciones. Esto es muy importante cuando escribe migraciones, porque cada base de datos, ya sea PostgreSQL, MySQL, MariaDB, tiene su propia visión de cómo deben llamarse los índices.
Algunos desarrolladores también tienen su propia visión. Y SQLAlchemy le permite establecer un estándar de una vez por todas sobre cómo funciona. Tuve que desarrollar un proyecto que necesitaba trabajar con SQLite y PostgreSQL. Fue muy conveniente.

Se ve así: importa un objeto de metadatos de SQLAlchemy y cuando lo crea, especifica las plantillas usando el parámetro naming_convention, cuyas claves especifican los tipos de índices y restricciones: ix - índice regular, uq - índice único, fk - clave externa, pk - Clave primaria.
En los valores del parámetro naming_convention, puede especificar una plantilla que consta del tipo de índice / restricción (ix / uq / fk, etc.) y el nombre de la tabla, separados por guiones bajos. En algunas plantillas, también puede enumerar todas las columnas. Por ejemplo, no es necesario hacer esto para la clave principal, simplemente puede especificar el nombre de la tabla.
Cuando comienzas a hacer un nuevo proyecto, le agregas plantillas de nombres una vez y olvidas. Desde entonces, todas las migraciones se han generado con los mismos nombres de índice y restricción.
Esto es importante por otra razón: cuando decide que este índice ya no es necesario en su modelo de objetos y lo elimina, Alembic sabrá cómo se llama y generará correctamente la migración. Esto ya es una cierta garantía de fiabilidad, que todo funcionará como debería.
Otra entidad muy importante con la que seguramente se encontrará es una tabla, un objeto que describe lo que contiene la tabla.

La tabla tiene un nombre, columnas con tipos de datos, y necesariamente se refiere al registro de MetaData, ya que MetaData es un registro de todo lo que usted describe. Y hay columnas con tipos de datos.
Gracias a lo que hemos descrito, SQLAlchemy ahora puede y sabe mucho. Si hubiéramos especificado una clave externa aquí, ella aún sabría cómo nuestras tablas están conectadas entre sí. Y ella sabría el orden en el que se debe hacer algo.

SQLAlchemy también tiene Engine. Importante: lo que dijimos sobre las consultas se puede usar por separado y Engine se puede usar por separado. Y puedes usar todo junto, nadie lo prohíbe. Es decir, Engine sabe cómo conectarse directamente al servidor y le brinda exactamente la misma interfaz. No, por supuesto, diferentes controladores intentan cumplir con DBAPI, hay un PEP en Python que hace recomendaciones. Pero Engine le ofrece exactamente la misma interfaz para todas las bases de datos y es muy conveniente.

El último gran hito es el dialecto. Así es como el motor se comunica con diferentes bases de datos. Hay diferentes idiomas, diferentes personas y diferentes dialectos aquí.
Veamos para qué sirve todo esto.

Así es como se verá un inserto normal. Si queremos agregar una nueva línea, la placa que describimos anteriormente, en la que había un campo de ID y correo electrónico, aquí especificamos el correo electrónico, hacemos Insert, e inmediatamente recuperamos todo lo que hemos insertado.
¿Y si queremos agregar muchas líneas? No hay problema.

Simplemente puede transferir una lista de dictados aquí. Parece el código perfecto para un bolígrafo súper simple. Los datos llegaron, pasaron algún tipo de validación, algún esquema JSON y todo entró en la base de datos. Muy facil.
Algunas consultas son bastante complejas. A veces, una solicitud incluso se puede ver con una impresión, a veces es necesario compilarla. Esto no es dificil. La alquimia te permite hacer todo esto. En este caso, hemos compilado la solicitud y puede ver lo que realmente volará a la base de datos.

La solicitud de datos parece bastante simple. Literalmente dos líneas, incluso puedes escribir en una.

Volvamos a nuestra pregunta sobre cómo, por ejemplo, escribir una solicitud de PATCH para 15 campos. Aquí debe escribir solo el nombre del campo, su clave y valor. Esto es todo lo que se necesita. Sin archivos, sin construcción de cadenas, nada en absoluto. Suena conveniente.
Quizás la característica más importante de Alchemy que uso todos los días en mi trabajo es la descomposición y expansión de consultas.

Suponga que está escribiendo una interfaz en PostgreSQL, su aplicación debe de alguna manera autorizar a una persona y permitirle realizar CRUD. De acuerdo, no hay mucho que descomponer.
Cuando escribe una aplicación muy compleja que usa control de versiones de datos, un montón de abstracciones diferentes, las consultas que generará pueden consistir en una gran cantidad de subconsultas. Las subconsultas se unen a las subconsultas. Hay diferentes tareas. Y, a veces, la descomposición de consultas ayuda mucho, permite una gran separación entre la lógica y el diseño del código.
¿Por qué funciona así? Cuando llamas al método users_table.select (), por ejemplo, devuelve un objeto. Cuando llama a cualquier otro método en el objeto resultante, como where (), devuelve un objeto completamente nuevo. Todos los objetos de consulta son inmutables. Por lo tanto, puede construir encima lo que quiera.
Migraciones de alambique
Entonces, nos hemos ocupado de SQLAlchemy y ahora finalmente podemos escribir migraciones de Alembic.

Comenzar a usar Alembic no es nada difícil, especialmente si ya ha descrito sus tablas, como dijimos anteriormente, y ha especificado un objeto MetaData. Simplemente pip install alambic, llame alambic init alambic. alambique: el nombre del módulo, esta es la línea de comandos, lo tendrá. init es un comando. El último argumento es la carpeta donde colocarlo.
Cuando llame a este comando, tendrá varios archivos, que veremos más de cerca ahora.

Habrá configuración general en alembic.ini. script_location es exactamente donde le gustaría que fuera. A continuación, habrá una plantilla para los nombres de sus migraciones que generará e información para conectarse a la base de datos.

También hay una plantilla para nuevas migraciones. Dices: "Quiero una nueva migración" y Alembic la creará de acuerdo con una plantilla determinada. Puedes personalizar todo esto, es muy sencillo. Entras en este archivo y editas lo que necesites. Todas las variables que se pueden especificar aquí están en la documentación. Ésta es la primera parte. Hay algún tipo de comentario en la parte superior para que sea conveniente ver qué está pasando allí. Luego, hay un conjunto de variables que deberían estar en cada migración: revisión, down_revision. Trabajaremos con ellos hoy. Además, metainformación adicional.

Los métodos más importantes son actualizar y degradar. Alembic sustituirá aquí cualquier diferencia que encuentre el objeto MetaData entre la descripción de su esquema y lo que hay en la base de datos.

env.py es el archivo más interesante de Alembic. Controla el progreso de los comandos y le permite personalizarlo usted mismo. Es en este archivo que conecta su objeto de metadatos. Como dije antes, el objeto MetaData es el registro de todas las entidades en su base de datos.
Estás conectando este objeto de metadatos aquí. Y a partir de ese momento, Alembic entiende que aquí están, mis modelos, aquí están, mis placas. Entiende con qué está trabajando. A continuación, Alembic tiene un código que llama a Alembic ya sea fuera de línea o en línea. Ahora también consideraremos todo esto.
Esta es exactamente la línea donde necesita conectar MetaData en su proyecto. No se preocupe si algo no está muy claro, puse todo en un proyecto y lo publiqué en GitHub . Puedes clonarlo y verlo, sentirlo todo.

¿Qué es el modo online? En modo en línea, Alembic se conecta a la base de datos especificada en el parámetro sqlalchemy.url en el archivo alembic.ini y comienza a ejecutar migraciones.
¿Por qué estamos mirando este código? Alambique se puede personalizar de forma muy flexible.
Imagine que tiene una aplicación que necesita vivir en diferentes esquemas de base de datos. Por ejemplo, desea tener muchas instancias de aplicaciones ejecutándose a la vez, y cada una vive en su propio esquema. Puede ser conveniente y necesario.
No le cuesta nada en absoluto. Después de llamar al método context.begin_transaction (), puede escribir el comando "SET search_path = SCHEMA", que le dice a PostgreSQL que use un esquema predeterminado diferente. Y eso es todo. A partir de ahora, su aplicación vive en un esquema completamente diferente, las migraciones pasan a un esquema diferente. Esta es una pregunta de una línea.

También hay un modo fuera de línea. Tenga en cuenta que Alembic no usa Engine aquí. Simplemente puede pasarle un enlace aquí. Por supuesto, también puede transferir el motor, pero no se conecta a ninguna parte. Simplemente genera consultas sin procesar que luego puede ejecutar en algún lugar.

Entonces, tienes Alembic y algunos MetaData con tablas. Y finalmente quieres generar migraciones por ti mismo. Ejecuta este comando, y básicamente eso es todo. Alembic irá a la base de datos y verá qué hay allí. ¿Existe su etiqueta especial "alembic_versions", que le dirá que las migraciones ya se han implementado en esta base de datos? Verá qué tablas existen allí. Verá qué datos necesita en la base de datos. Analizará todo esto, generará un nuevo archivo, solo basado en esta plantilla, y tendrás una migración. Por supuesto, definitivamente debe mirar lo que se generó en la migración, porque Alembic no siempre genera lo que desea. Pero la mayor parte del tiempo funciona.

¿Qué hemos generado? Había un cartel de usuarios. Cuando generamos la migración, indiqué el mensaje inicial. La migración se denominará initial.py con alguna otra plantilla que se especificó anteriormente en alembic.ini.
También aquí hay información sobre qué ID tiene esta migración. down_revision = None: esta es la primera migración.
La siguiente diapositiva será la parte más importante: actualizar y degradar.

En la actualización, vemos que se está creando una placa. En la degradación, este signo se elimina. Alembic, por defecto, agrega específicamente dichos comentarios para que vayas allí, lo edites, al menos borres estos comentarios. Y por si acaso, revisamos la migración, nos aseguramos de que todo le quede bien. Es cuestión de un solo equipo. Ya tienes una migración.

Después de eso, lo más probable es que desee aplicar esta migración. No podría ser más sencillo. Solo necesita decir: cabeza de mejora alambique. Aplicará absolutamente todo.
Si decimos head, intentará actualizarse a la migración más reciente. Si nombramos una migración específica, se actualizará.
También hay un comando de degradación, en caso de que cambie de opinión, por ejemplo. Todo esto se hace en transacciones y funciona de manera bastante simple.

Entonces, tienes migraciones, sabes cómo ejecutarlas. Tienes una aplicación y haces, por ejemplo, esta pregunta: tengo CI, se están ejecutando pruebas y ni siquiera sé si quiero, por ejemplo, ejecutar migraciones automáticamente. ¿Quizás es mejor hacerlo con las manos?
Aquí hay diferentes puntos de vista. Probablemente, vale la pena cumplir con la regla: si no tiene un acceso fácil, la capacidad de subirse a un automóvil con una base de datos, entonces es mejor, por supuesto, hacerlo automáticamente.
Si tienes acceso, haces un servicio que funciona en la nube, y puedes ir allí desde un portátil que siempre tienes contigo, entonces puedes hacerlo tú mismo y así tener más control.
En general, existen muchas herramientas para hacer esto automáticamente. Por ejemplo, en el mismo Kubernetes. Hay contenedores de inicio que pueden hacer esto y en los que puede ejecutar estos comandos. Puede agregar un comando de inicio directamente a Docker para hacer esto.
Solo debe considerar: si aplica las migraciones automáticamente, entonces debe pensar en lo que sucede si, por ejemplo, desea revertir, pero no puede. Por ejemplo, tenía una placa de datos de 500 gigabytes. Pensó: está bien, estos datos ya no son necesarios para la lógica empresarial, probablemente pueda eliminarlos. Lo tomaron y lo dejaron caer. O cambió el tipo de columna, que cambió con la pérdida de datos. Por ejemplo, hubo una fila larga, pero se hizo corta. O algo se ha ido. O ha eliminado una columna. No puede retroceder incluso si lo desea.
En un momento, hice productos para locales, que se instalan mediante un archivo exe para personas directamente en la máquina. Una vez que entienda: sí, escribió la migración, entró en producción, la gente ya la instaló. En los próximos cinco años, puede funcionar para ellos de acuerdo con el SLA, y si desea cambiar algo, algo podría ser mejor. En este momento, piensa en cómo lidiar con los cambios irreversibles.

Aquí tampoco hay ciencia espacial. La idea es que puede evitar el uso de estas columnas o tablas tanto como sea posible. Deja de contactarlos. Puede, por ejemplo, marcar campos en el ORM con un decorador especial. Dirá en los registros que parecía que no querías tocar este campo, pero aún te refieres a él. Simplemente cree una tarea en la lista de trabajos pendientes y elimínela algún día.
Usted, en todo caso, tendrá tiempo para retroceder. Y si todo va bien, con tranquilidad hará esta tarea más adelante en el backlog. Realice otra migración que borrará todo.
Ahora, la pregunta más importante: ¿por qué y cómo probar las migraciones?

Esto lo hacen algunos de los que les pregunté. Pero es mejor hacerlo. Esta es una regla escrita con dolor, sangre y sudor. Utilizar la migración en la producción siempre es riesgoso. Nunca se sabe cómo podría terminar. Incluso una muy buena migración en una producción de trabajo perfectamente normal, cuando tiene CI configurado, puede dar tirones.
El caso es que cuando estás probando migraciones, incluso puedes descargar, por ejemplo, etapa o alguna parte de producción. La producción puede ser grande, no se puede descargar por completo para pruebas u otras tareas. Las bases de desarrollo, por regla general, no son realmente bases de producción. No tienen mucho de lo que podrían haber acumulado a lo largo de los años.

Esto puede ser datos corruptos, cuando migramos algo, o software antiguo que trajo los datos a un estado inconsistente. También pueden ser dependencias implícitas, si alguien olvidó agregar una clave externa. Él cree que está conectado, pero sus compañeros, por ejemplo, no lo saben. Los campos también se llaman completamente por casualidad, no está del todo claro que estén conectados.
Entonces alguien decidió ingresar y agregar algún tipo de índice directamente a la producción, porque "ahora se ralentiza, ¿y si comienza a funcionar más rápido?" Quizás exagero, pero la gente realmente a veces cambia algo en las bases de datos.
Por supuesto, existen errores en las herramientas, en la migración de esquemas. Para ser honesto, no me he encontrado con esto. Por lo general, existían los tres primeros problemas. Y quizás más errores en las suposiciones sobre cómo se deben transferir los datos.
Cuando tiene un modelo de objetos muy grande, es difícil tenerlo todo en mente. Es difícil redactar documentación actualizada constantemente. La documentación más actualizada es su código, y no siempre tiene una lógica empresarial completamente escrita: qué debería funcionar y cómo, quién tenía qué en mente.

¿Qué podemos comprobar? Al menos el hecho de que comience la migración. Esto ya es genial. Y que no hay errores tipográficos estúpidos en el código. Podemos comprobar que existe un método downgrade () válido, que todos los tipos de datos creados por SQLAlchemy se eliminan en el método downgrade ().
SQLAlchemy hace muchas cosas buenas. Por ejemplo, cuando describe una tabla y especifica un tipo de columna Enum, SQLAlchemy creará automáticamente un tipo de datos para esa enumeración en PostgreSQL. Pero el código para eliminar este tipo de datos en el método downgrade () no se generará automáticamente.
Debe recordar y verificar esto: cuando desee revertir y volver a aplicar la migración, un intento de crear un tipo de datos existente en el método upgrade () generará una excepción. Y lo más importante, si la migración cambia algún dato, debe verificar que los datos cambien correctamente en la actualización. Y es muy importante comprobar que retroceden correctamente en la degradación sin efectos secundarios.

Antes de pasar a las pruebas en sí, veamos cuál es la mejor manera de prepararnos para escribirlas. He visto muchos enfoques para esto. Algunas personas crean una base, placas, luego escriben un accesorio que lo limpia todo, usan algún tipo de accesorios de aplicación automática . Pero la forma ideal que lo protegerá al 100% y ejecutará las pruebas en un espacio completamente aislado es crear una base de datos separada.
Hay un módulo sqlalchemy_utils increíble que puede crear y eliminar bases de datos. En PostgreSQL, también comprueba: si uno de los clientes se quedó dormido y no se desconectó, no se bloqueará con el error de que "alguien está usando la base de datos, no puedo hacer nada con ella, no puedo borrarla". En cambio, verá con calma quién se ha conectado con ellos, desconectará a estos clientes y eliminará con calma la base.
Crear una base de datos y aplicar una migración a cada prueba no siempre es un proceso rápido. Esto se puede resolver de la siguiente manera: PostgreSQL admite la creación de nuevas bases de datos a partir de una plantilla, por lo que puede dividir la preparación de la base de datos en dos accesorios.
El primer dispositivo se ejecuta una vez para ejecutar todas las pruebas (alcance = sesión), crea una base de datos y le aplica migraciones. El segundo accesorio (alcance = función) crea bases directamente para cada prueba basándose en la base del primer accesorio.
Crear una base de datos a partir de una plantilla es muy rápido y ahorra tiempo en la aplicación de migraciones para cada prueba.

Si solo estamos hablando de cómo podemos crear temporalmente una base de datos, entonces podemos escribir dicho accesorio. ¿Que está pasando aqui? Generaremos un nombre aleatorio. Agregamos, por si acaso, al final de pytest, para que cuando vayamos a localhost a nosotros mismos a través de algún Postico, podamos entender qué fue creado por las pruebas y qué no.
Luego generamos a partir del enlace con información sobre la conexión a la base de datos, que la persona mostró, una nueva, ya con una nueva base de datos. Lo creamos y simplemente lo enviamos a pruebas. Una vez que una persona ha trabajado con esta base de datos, la eliminamos.

También podemos preparar el motor para conectarse a esta base de datos. Es decir, en este dispositivo nos referimos al dispositivo anterior utilizado como dependencia. Creamos un motor y lo enviamos a pruebas.

Entonces, ¿qué pruebas podemos escribir? La primera prueba es simplemente una brillante invención de mi colega. Desde que apareció, creo que me he olvidado de los problemas de las migraciones.
Esta es una prueba muy simple. Lo agrega a su proyecto una vez. Está en el proyecto en GitHub.... Puede simplemente arrastrarlo hacia usted, agregar y olvidar, tal vez, alrededor del 80 por ciento de los problemas.
Hace algo muy simple: obtiene una lista de todas las migraciones y comienza a iterar sobre ellas. Actualización de llamadas, degradación, actualización.

Por ejemplo, tenemos cinco migraciones. Veamos cómo funciona esto. Aquí está la primera migración. Lo hemos cumplido. Revierte la primera migración, ejecútala de nuevo. ¿Que pasó aquí? De hecho, vimos aquí que una persona implementó correctamente el método downgrade (), porque dos veces, por ejemplo, no habría sido posible crear tablas.
Vemos que si una persona creó algunos tipos de datos, también los borró, porque no hay errores tipográficos y en general al menos de alguna manera funciona.
Luego, la prueba continúa. Toma la segunda migración, inmediatamente corre hacia ella, retrocede un paso, corre hacia adelante nuevamente. Y esto sucede tantas veces como migraciones.
El propósito de esta prueba es encontrar errores básicos, problemas al cambiar la estructura de datos.
La escalera comienza en una base vacía y suele ser muy rápida. Es decir, esta prueba trata más sobre la estructura de datos. No se trata de cambiar datos en las migraciones. Pero en general, puede salvarle la vida muy bien.
Si quieres una solución rápida, esta es. Esta regla es. Como regla general: insértelo en su proyecto y le resultará más fácil.

Esta prueba se parece a esto. Obtenemos todas las revisiones, generamos la configuración de Alembic. Esto es lo que vimos antes, el archivo alembic.ini, aquí está la función get_alembic_config, lee este archivo, le agrega nuestra base temporal, porque especificamos la ruta a la base allí. Y después de eso podemos usar los comandos de Alembic.
El comando ejecutado anteriormente - cabeza de actualización alambique - también se puede importar de forma segura. Desafortunadamente, esta diapositiva no se ajusta a todas las importaciones, pero confíe en mi palabra. Es solo de la actualización de importación de alembic.com. Traduce la configuración allí, dice dónde ir a través de la actualización. Luego di: rebaja.
Con la degradación, la migración se revierte a down_revision, es decir, a la revisión anterior, oa "-1".
"-1" es una forma alternativa de decirle a Alembic que revierta la migración actual. Es muy relevante cuando se inicia la primera migración, su down_revision es None, mientras que la API de Alembic no permite pasar None al comando downgrade.
Luego, el comando de actualización se ejecuta nuevamente.
Ahora hablemos sobre cómo probar las migraciones con datos.

Las migraciones de datos son el tipo de cosas que suelen parecer muy simples, pero que duelen más. Parecería que podría escribir seleccionar, insertar, tomar datos de una tabla, transferirlos a otra en un formato ligeramente diferente, ¿qué podría ser más simple?
Queda por decir de esta prueba que, a diferencia de la anterior, es muy cara de desarrollar. Cuando hice grandes migraciones, a veces me tomó seis horas mirar todas las invariantes, está bien describir todo. Pero cuando ya estaba rodando estas migraciones, estaba tranquilo.

¿Cómo funciona esta prueba? La idea es que apliquemos todas las migraciones hasta la que ahora queremos probar. Insertamos en la base de datos un conjunto de datos que cambiarán. Podemos pensar en insertar datos adicionales que podrían cambiar implícitamente. Luego actualizamos. Comprobamos que los datos se han modificado correctamente, ejecutamos una degradación y comprobamos que los datos se han modificado correctamente.

El código se parece a esto. Es decir, también hay una parametrización por revisión, hay un conjunto de parámetros. Aceptamos nuestro Engine aquí, aceptamos la migración con la que queremos empezar a probar.
Luego rev_head, que es lo que queremos probar. Y luego tres devoluciones de llamada. Estas son las devoluciones de llamada que definimos en algún lugar, y se llamarán después de que se haga algo. Podemos comprobar qué está pasando allí.
¿Dónde puedo ver un ejemplo?
Lo empaqueté todo en un ejemplo en GitHub . Realmente no hay mucho código allí, pero es bastante difícil agregarlo a la diapositiva. Traté de soportar lo más básico. Puedes ir a GitHub y ver cómo funciona en el propio proyecto, esta será la forma más sencilla.
¿A qué más vale la pena prestar atención? Durante el inicio, Alembic busca el archivo de configuración alembic.ini en la carpeta donde se inició. Por supuesto, puede especificar la ruta usando la variable de entorno ALEMBIC_CONFIG, pero esto no siempre es conveniente y obvio.
Otro problema: la información para conectarse a la base de datos se especifica en alembic.ini, pero a menudo es necesario poder trabajar con varias bases de datos sucesivamente. Por ejemplo, implemente migraciones a la etapa y luego a la producción. En general, puede especificar información de conexión en la variable de entorno SQLALCHEMY_URL, pero esto no es muy obvio para los usuarios finales de su software.
También será mucho más intuitivo para los usuarios finales utilizar la utilidad "$ project $ -db" que "alambic".
Mientras observa los ejemplos del proyecto, eche un vistazo a la utilidad staff-db. Este es un envoltorio delgado alrededor de Alembic y otra forma de personalizar Alembic para usted. De forma predeterminada, busca el archivo alembic.ini en el proyecto en relación con su ubicación. Desde cualquier carpeta que los usuarios la llamen, ella misma encontrará el archivo de configuración. Además, staff-db agrega un argumento --db-url, con el cual puede especificar información para conectarse a la base de datos. Y, lo que es más importante, véalo pasando la opción de ayuda generalmente aceptada. Después de todo, el nombre de la utilidad es intuitivo.
Todos los comandos de proyectos ejecutables comienzan con el nombre del módulo "staff": staff-api, que ejecuta la API REST, y staff-db, que administra el estado base. Al comprender este patrón, el cliente escribirá el nombre de su programa y podrá ver todas las utilidades disponibles presionando la tecla TAB, incluso si olvida el nombre completo. Lo tengo todo, gracias.