Para recibir llamadas, usamos la plataforma Voximplant , y para reconocer las preguntas y respuestas - DeepPavlov . El asistente de voz se lanzó en dos semanas y media y ayudó a procesar 5.000 llamadas. Logramos lanzar un producto que ayudó a los residentes de Tartaristán a recibir información confiable de las autoridades y simplemente salir a la calle. A continuación te contamos cómo lo hicimos.
Cual fue la tarea
Originalmente planeamos hacer un asistente de voz que ayudaría a las personas a recibir servicios gubernamentales y responder a las preguntas frecuentes. Pero cuando comenzó todo el truco con el coronavirus, nos dimos cuenta de que Lilia ayudaría a descargar el centro de llamadas: por ejemplo, asesorar sobre la línea directa, ayudar a obtener pases digitales y beneficios de desempleo. Todo lo que una persona puede averiguar en el sitio web de los servicios estatales se puede encontrar en Lilia, y también puede simplemente charlar con ella.
. 1 -: , . : , , , . 12.
. , . , . , , , — « ».
Además de emitir pases digitales, Lilia tuvo que responder preguntas de los residentes de Tatarstán. Concebimos un asistente de voz que respondería preguntas comunes como "¿Qué debe hacer para obtener un pase" y "¿El jengibre lo ayuda con el coronavirus?"
Para solucionar este problema, podríamos hacer un IVR regular. Pero IVR lleva mucho tiempo, y si lo hace normalmente, entonces necesita construir una arquitectura compleja. En general, no hubo tiempo para esto. Pensamos que sería más fácil hacer un asistente de voz (que puede traducir el habla en texto, procesarla, clasificar intenciones y dar una respuesta de voz). Jeje.
Cómo se ve desde la perspectiva del usuario
Aquí todo es sencillo.
- El hombre llama a la línea directa, se le ofrece elegir entre una conversación con el operador y Lilia. En cualquier momento, puede cambiar a un operador en vivo.
- .
- , . , -.
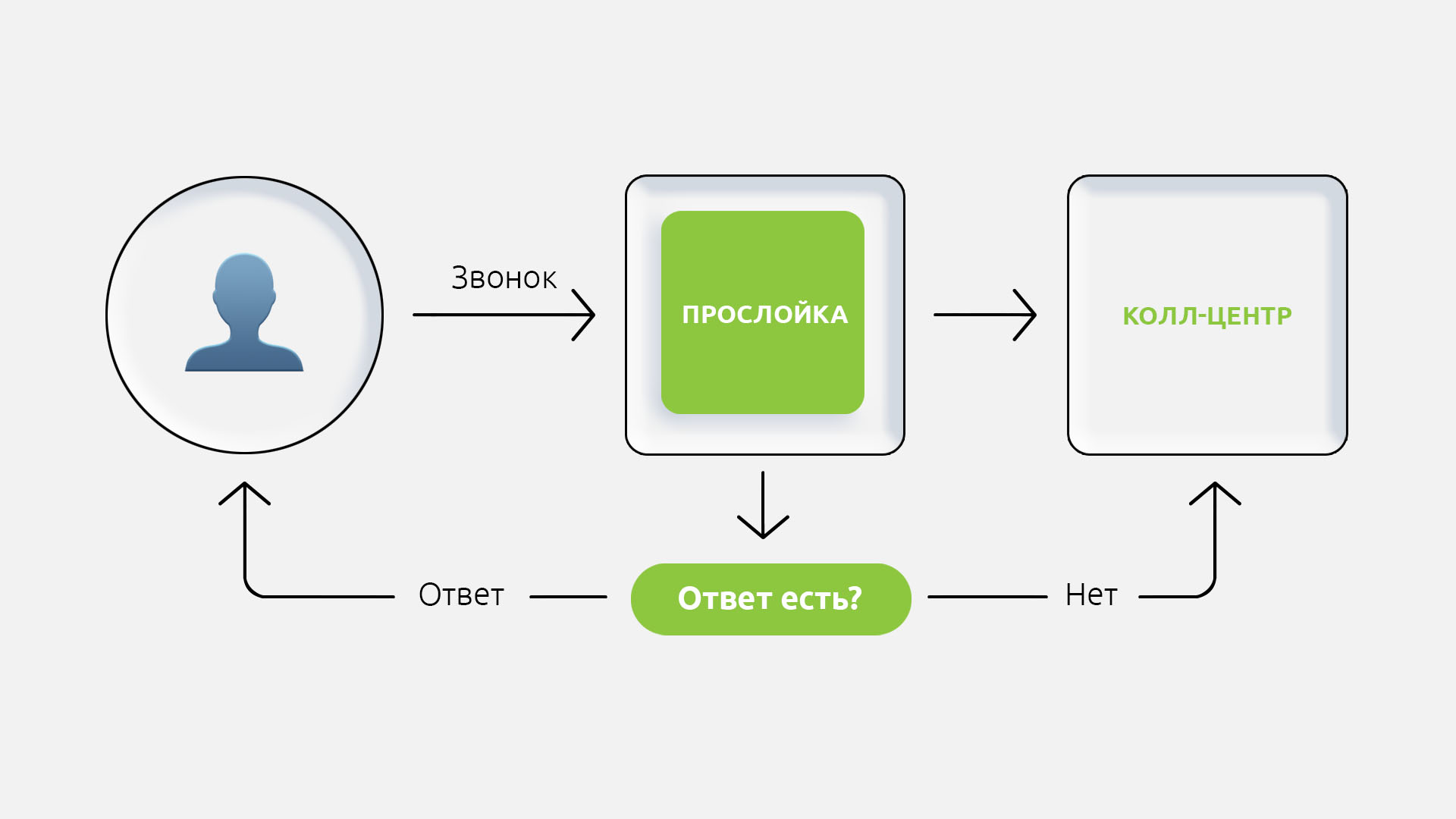
Para recibir llamadas e implementar scripts, usamos la plataforma Voximplant: escribimos un script y conectamos una señal de contestador automático. Lily saludó al hombre y le preguntó qué quería.
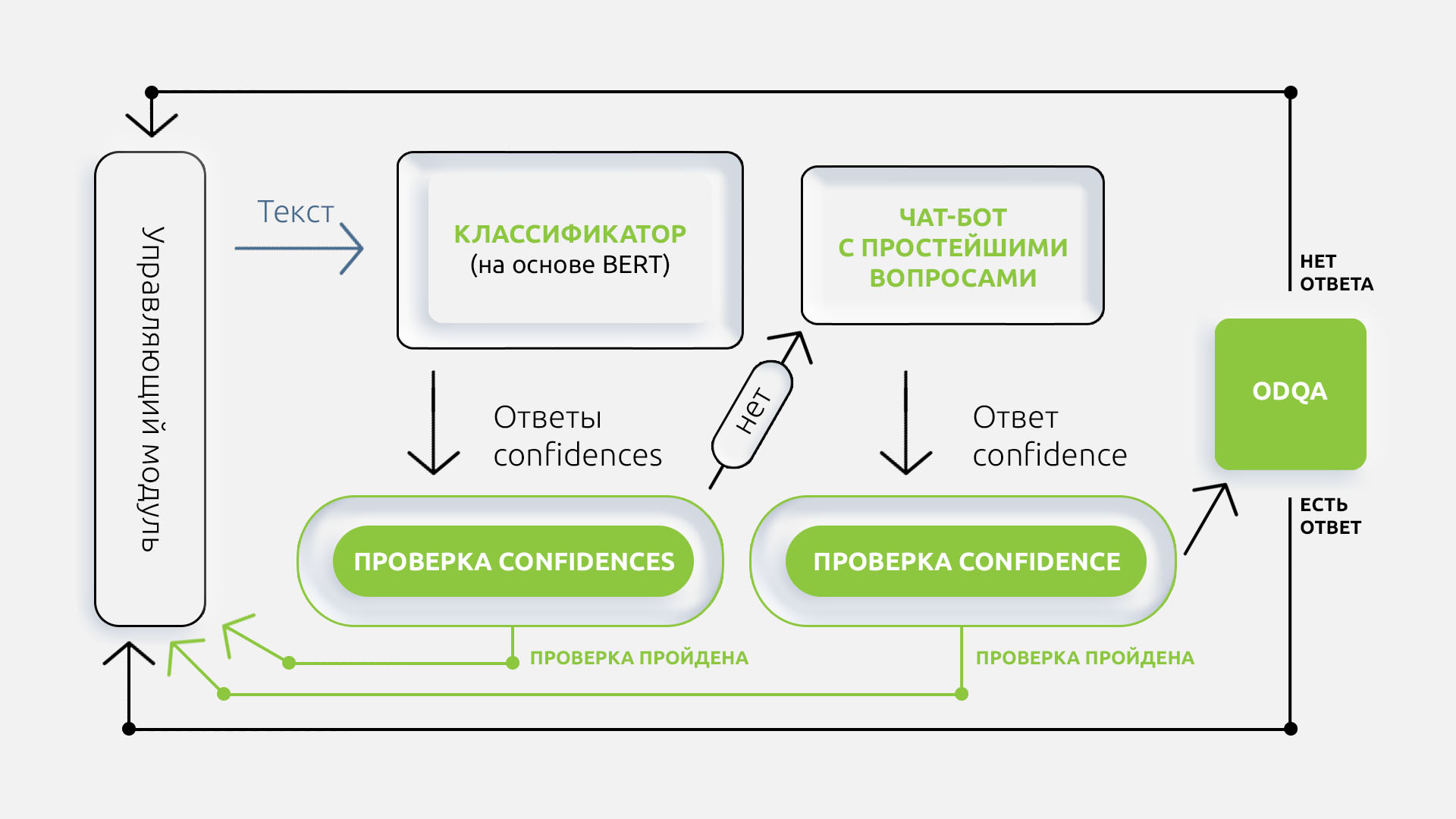
La persona que llama hace una pregunta por teléfono. Entonces Lilia empezó a escuchar. En VoxImplant, usamos el módulo ASR para traducir la voz en texto, lo que llama el modelo Yandex.SpeechKit bajo el capó. Por lo tanto, la transmisión de audio se traduce en texto, que luego se tokeniza y se deriva. También intentamos extraer características: NER, POS y Chunk para los métodos básicos de ML, pero todo esto llevó mucho tiempo.

Por ejemplo, inicialmente, de la pregunta "Por favor, dígame cómo protegerse del coronavirus", eliminamos "protección" y "coronavirus" y los convertimos en representación vectorial. La representación vectorial de entidades se incluye en el clasificador del coronavirus (y más tarde, para los servicios públicos). Ahora DeepPavlov está haciendo todo esto.
Luego hay varias opciones, dependiendo del nivel de confianza (confianza):
- Si la red clasificó la pregunta con suficiente confianza (según el estudio, los umbrales se seleccionaron individualmente, por clase), entonces Lilia responderá la pregunta.
- Si la red tiene una respuesta de baja confianza, asumimos que esta es una pregunta que no cubrimos dentro de nuestro conjunto de datos (pero la pregunta aún se refiere al dominio del coronavirus) o que la persona solo quería hablar sobre otro tema. Por ejemplo, preguntó "¿Quién es Elon Musk"?
Para tales preguntas, usamos el modelo BERT entrenado en el volcado de Wikipedia para el problema de respuesta a preguntas de la base de conocimientos.
Al final, Lilia necesariamente verifica la exactitud del reconocimiento de la intención y la calidad de la respuesta preguntando: "¿Respondí a tu pregunta?" Si el usuario responde que sí, entonces Lilia esperará a la siguiente pregunta. De lo contrario, le pediremos que reformule la pregunta y vuelva a pasar por todo el ciclo. Sucede que esto no funciona. Entonces, los operadores en vivo entran en la batalla.
Ahora Lilia habla con una voz agradable de un sintetizador de voz de Yandex: cambiamos ligeramente la clave y aumentamos la velocidad. A veces, Lily confunde el acento, pero esto se puede solucionar con un marcado. Por supuesto, me gustaría agregar a Tatar, pero hasta ahora es difícil.
En total, el proyecto tomó dos semanas y media, teniendo en cuenta conjuntos de datos: surgió una idea, discutimos el proyecto con el ministro y, como decimos, alga. Se dedicó una semana a la estimación y la investigación, el desarrollo tomó otros 10 días, luego finalizamos y ajustamos funciones adicionales. Los caballos principales fueron Nvidia RTX2070. Los BERT requieren alrededor de 12-16 GB de memoria de video.
De LSVM y catboost a DeepPavlov
Durante el proceso de desarrollo, utilizamos diferentes modelos de clasificadores. Primero, probamos modelos de aprendizaje automático como bosque aleatorio, LSVM, catboost, logreg. En general, la precisión de los modelos de aprendizaje automático no fue muy alta. ¿Porqué es eso? Porque muchas de las preguntas de los usuarios son muy parecidas entre sí: la pregunta “mi hijo está enfermo de coronavirus qué hacer” es bastante similar a la pregunta “es posible caminar con el niño durante el coronavirus”, aunque estas son categorías diferentes y se requieren respuestas diferentes.
Podríamos hacer extracción de entidades, muestreo, investigación. Pero teníamos prisa. Por lo tanto, decidimos utilizar la biblioteca DeepPavlov de MIPT en nuestro trabajo, que dio una precisión del 78% con regresión logística y BERT - 84%.
La precisión de las respuestas depende del marcado de los conjuntos de datos. Teníamos una lista de 200 preguntas que la gente hacía en la línea directa, pero no estaban debidamente segregadas. Por ejemplo, la gente preguntaba qué hacer si uno de sus familiares se enfermaba y la pregunta era cuáles son los síntomas del coronavirus. Los modelos ML se confundieron.
Resultados y planes para el futuro
Lilia trabajó durante 2 semanas y procesó 5000 llamadas. Durante este tiempo, Lilia facilitó enormemente el trabajo de los operadores de la línea directa: no tenían que responder preguntas triviales y repetitivas. Gracias a Lilia, los usuarios recibieron pases, respuestas a preguntas y simplemente hablaron. Por supuesto, hubo usuarios que la insultaron y pidieron transferirse al operador.
El régimen de autoaislamiento fue cancelado, los pases digitales ya no son válidos, pero Lilia sigue en las filas. Continúa respondiendo preguntas sobre el coronavirus, pero ahora se le ha agregado la capacidad de responder preguntas relacionadas con los servicios públicos.
Somos un ministerio y, de hecho, tenemos dos tareas: que otros departamentos usen normalmente las tecnologías y que los residentes de Tartaristán puedan comunicarse fácil y simplemente con el estado. La segunda tarea la maneja perfectamente el portal de servicios estatales, el nuestro, local, no federal. Pero este portal es un sitio y una aplicación, que todavía es difícil de alcanzar para algunos. Y si los residentes no van al portal, entonces el portal irá al residente, es decir, estamos avanzando hacia la simplificación de la interacción con el portal para las personas que no usan particularmente Internet.
Ahora, el Ministerio de Asuntos Digitales de Tartaristán está trabajando para garantizar que las personas puedan recibir servicios gubernamentales por voz y por chat. Queremos crear un asistente universal al que pueda llamar / escribir y obtener respuestas a todas las preguntas importantes.
Hasta ahora, Lilia puede decir cuánto tiempo está abierta la oficina de registro, y en el futuro planeamos que podrá tomar lecturas de los medidores (pero esto es solo cuando resolvemos el problema con la seguridad de la transferencia de estos datos). En general, estamos convirtiendo a Lilia en un producto independiente.
Si estaría interesado en enseñar a Lilia, bienvenido a nuestro equipo.