
Así que ha llegado el momento de la publicación de la segunda parte, hoy continuaremos desarrollando nuestro editor de código y añadiéndole autocompletado y resaltado de errores, y también hablaremos sobre por qué ningún editor de código
EditTextno se retrasará.
Antes de seguir leyendo, le recomiendo que lea la primera parte .
Introducción
 Primero, recordemos dónde lo dejamos en la última parte . Escribimos un resaltado de sintaxis optimizado que analiza el texto en el fondo y colorea solo su parte visible, así como la numeración de línea agregada (aunque sin guión de Android, pero aún así).
Primero, recordemos dónde lo dejamos en la última parte . Escribimos un resaltado de sintaxis optimizado que analiza el texto en el fondo y colorea solo su parte visible, así como la numeración de línea agregada (aunque sin guión de Android, pero aún así).
En esta parte agregaremos la finalización del código y el resaltado de errores.
Completar código
Primero, imaginemos cómo debería funcionar:
- El usuario escribe una palabra
- Después de ingresar los primeros N caracteres, aparece una ventana con consejos
- Cuando hace clic en la pista, la palabra se "imprime" automáticamente
- La ventana con sugerencias se cierra y el cursor se mueve al final de la palabra.
- Si el usuario ingresó la palabra que se muestra en la información sobre herramientas, la ventana con sugerencias debería cerrarse automáticamente
¿No se parece a nada? Android ya tiene un componente con exactamente la misma lógica,
MultiAutoCompleteTextViewpor PopupWindowlo que no tenemos que escribir muletas con nosotros (ya se han escrito para nosotros).
El primer paso es cambiar el padre de nuestra clase:
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
Ahora necesitamos escribir
ArrayAdapterlo que mostrará los resultados encontrados. El código completo del adaptador no estará disponible, se pueden encontrar ejemplos de implementación en Internet. Pero me detendré en este momento con el filtrado.
Para
ArrayAdapterpoder entender qué sugerencias deben mostrarse, debemos anular el método getFilter:
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf<String>()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() //
addAll(suggestions)
notifyDataSetChanged()
}
}
}
Y en el método,
performFilteringcomplete la lista suggestionsde palabras según la palabra que el usuario comenzó a ingresar (contenida en una variable constraint).
¿Dónde obtener los datos antes de filtrar?
Todo depende de usted: puede usar algún tipo de intérprete para seleccionar solo opciones válidas o escanear todo el texto cuando abre el archivo. Para simplificar el ejemplo, usaré una lista de opciones de autocompletado:
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() //
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
La lógica de filtrado aquí es bastante primitiva, revisamos toda la lista y, ignorando el caso, comparamos el comienzo de la cadena.
Instalado el adaptador, escriba el texto, no funciona. Que pasa En el primer enlace en Google, encontramos una respuesta que dice que olvidamos instalar
Tokenizer.
¿Para qué sirve Tokenizer?
En términos simples,
Tokenizerayuda a MultiAutoCompleteTextViewentender después de qué carácter ingresado la palabra ingresada puede considerarse completa. También tiene una implementación preparada en forma de CommaTokenizerseparación de palabras en comas, que en este caso no nos conviene.
Bueno, como
CommaTokenizerno estamos satisfechos, escribiremos el nuestro:
Tokenizer personalizado
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
Vamos a resolverlo:
TOKEN una cadena con caracteres que separan una palabra de otra. En los métodos findTokenStarty findTokenEndrevisamos el texto en busca de estos símbolos muy separados. El método le terminateTokenpermite devolver un resultado modificado, pero no lo necesitamos, por lo que simplemente devolvemos el texto sin cambios.
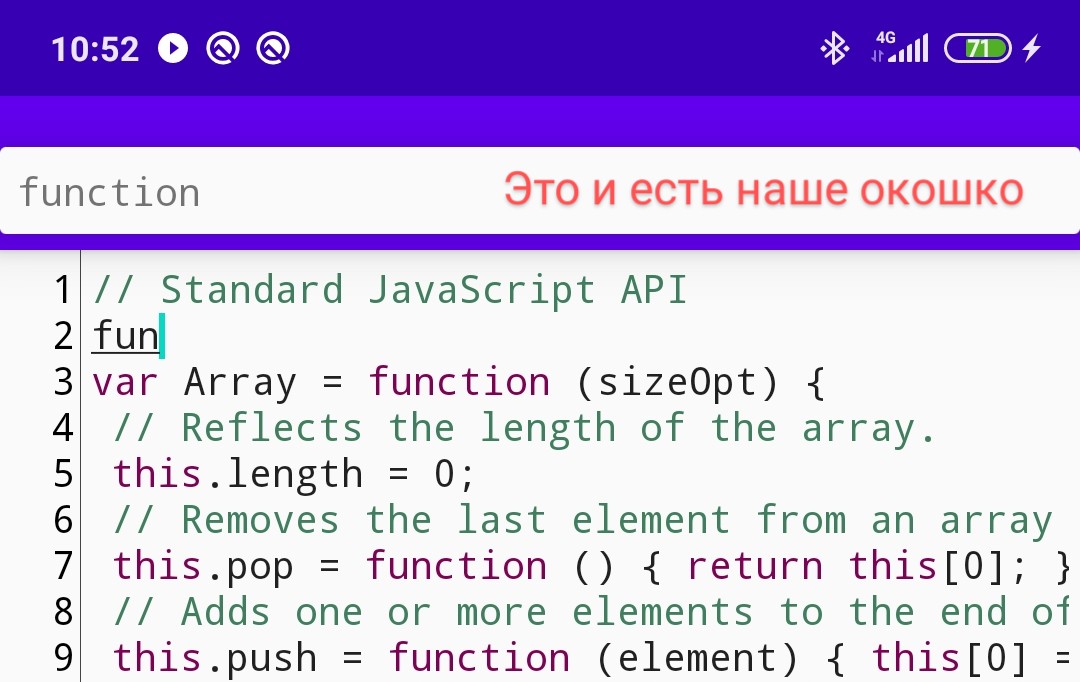
También prefiero agregar un retraso de entrada de 2 caracteres antes de mostrar la lista:
textProcessor.threshold = 2Instalar, ejecutar, escribir texto: ¡funciona! Pero por alguna razón, la ventana con indicaciones se comporta de manera extraña: se muestra en todo su ancho, su altura es pequeña y, en teoría, debería aparecer debajo del cursor, ¿cómo lo solucionaremos?
Corrección de defectos visuales
Aquí es donde comienza la diversión, porque la API nos permite cambiar no solo el tamaño de la ventana, sino también su posición.
Primero, decidamos el tamaño. En mi opinión, la opción más conveniente sería una ventana de la mitad de la altura y el ancho de la pantalla, pero dado que nuestro tamaño
Viewcambia según el estado del teclado, seleccionaremos los tamaños en el método onSizeChanged:
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
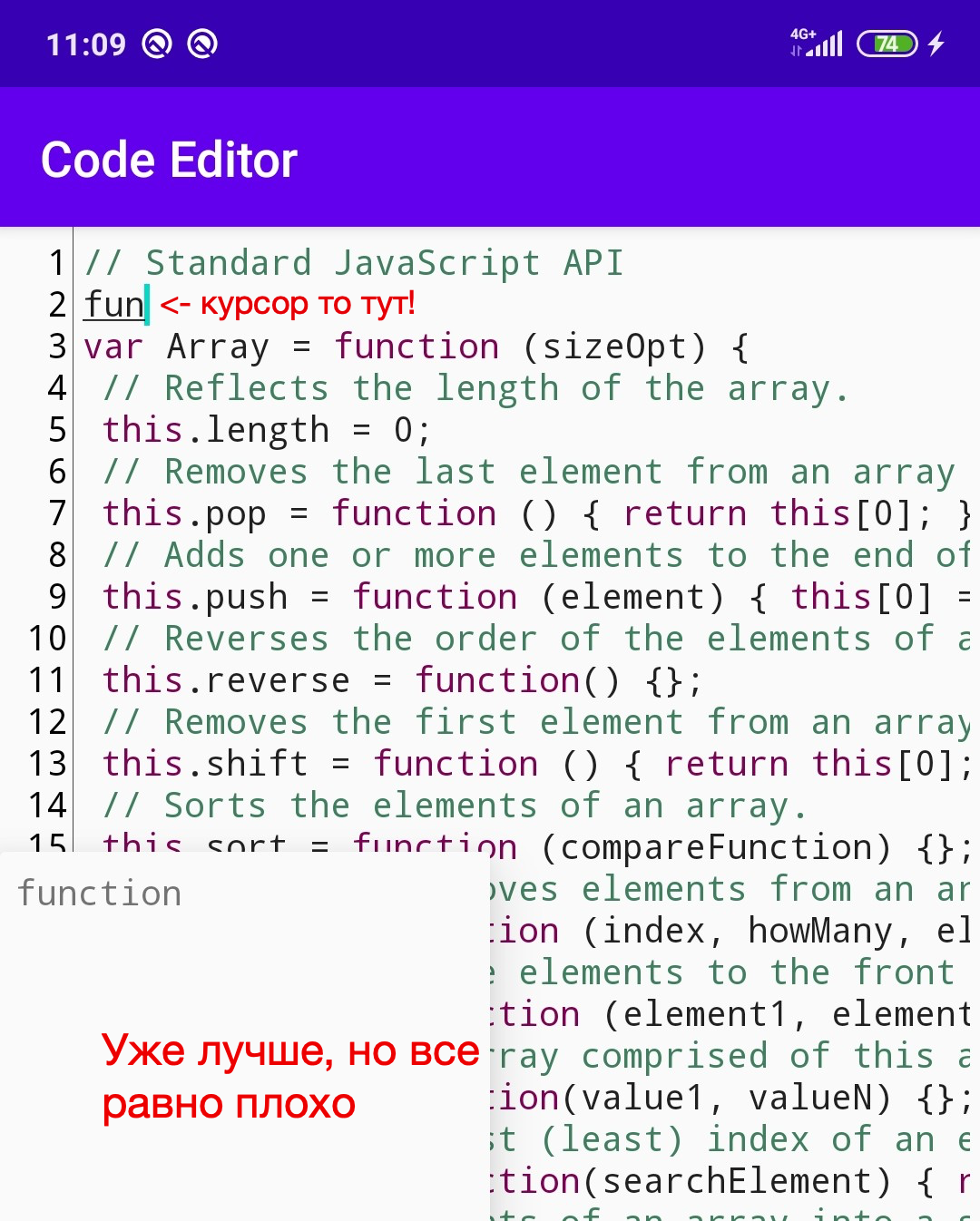 Se ve mejor, pero no mucho. Queremos lograr que la ventana aparezca debajo del cursor y se mueva con ella durante la edición.
Se ve mejor, pero no mucho. Queremos lograr que la ventana aparezca debajo del cursor y se mueva con ella durante la edición.
Si todo es bastante simple al moverse a lo largo de X : tomamos la coordenada del comienzo de la letra y establecemos este valor en
dropDownHorizontalOffset, entonces elegir la altura será más difícil.
Google sobre las propiedades de las fuentes, puede tropezar con esta publicación . La imagen que adjuntó el autor muestra claramente qué propiedades podemos usar para calcular la coordenada vertical.

Ahora escribamos un método que llamaremos cuando el texto cambie a
onTextChanged:
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) //
val x = layout.getPrimaryHorizontal(selectionStart) //
val y = layout.getLineBaseline(line) // baseline
val offsetHorizontal = x + gutterWidth //
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY ""
dropDownVerticalOffset = offsetVertical
}
Parece que no han olvidado nada: el desplazamiento X funciona, pero el desplazamiento Y se calcula incorrectamente. Esto se debe a que no especificamos
dropDownAnchoren el marcado:
android:dropDownAnchor="@id/toolbar"Al especificar
Toolbarla calidad, le dropDownAnchorinformamos al widget que la lista desplegable se mostrará debajo .
Ahora, si comenzamos a editar el texto, todo funcionará, pero con el tiempo notaremos que si la ventana no cabe debajo del cursor, se arrastra hacia arriba con una sangría enorme, que se ve fea. Es hora de escribir una muleta:

val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
No necesitamos cambiar la sangría si la suma es
offsetVertical + dropDownHeightmenor que la altura visible de la pantalla, porque en este caso la ventana se coloca debajo del cursor. Pero si aún es más, restamos la sangría dropDownHeight, por lo que se ajustará sobre el cursor sin una sangría enorme que el widget mismo agregue.
PD: Puedes ver el teclado parpadeando en el gif, y para ser sincero, no sé cómo solucionarlo, así que si tienes una solución, escribe.
Destacando errores
Con el resaltado de errores, todo es mucho más simple de lo que parece, porque nosotros mismos no podemos detectar directamente los errores de sintaxis en el código; utilizaremos una biblioteca de analizador de terceros. Como estoy escribiendo un editor para JavaScript, mi elección recayó en Rhino , un popular motor de JavaScript que ha sido probado y aún soportado.
¿Cómo vamos a analizar?
Lanzar Rhino es una operación bastante engorrosa, por lo que ejecutar el analizador después de cada carácter ingresado (como hicimos con el resaltado) no es una opción en absoluto. Para resolver este problema, usaré la biblioteca RxBinding , y para aquellos que no quieran arrastrar RxJava al proyecto, pueden probar opciones similares .
El operador
debouncenos ayudará a lograr lo que queremos, y si no está familiarizado con él, le aconsejo que lea este artículo .
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
//
}
.disposeOnFragmentDestroyView()
Ahora escribamos un modelo que el analizador nos devolverá:
data class ParseResult(val exception: RhinoException?)Sugiero usar la siguiente lógica: si no se encuentran errores, entonces los
exceptionhabrá null. De lo contrario, obtendremos un objeto RhinoExceptionque contiene toda la información necesaria: número de línea, mensaje de error, StackTrace, etc.
Bueno, en realidad, el análisis en sí mismo:
// !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
Comprensión:
Lo más importante aquí es el método
evaluateString: le permite ejecutar el código que pasamos como una cadena sourceCode. El fileNamenombre del archivo se indica en: se mostrará con errores, la unidad es el número de línea para comenzar a contar, el último argumento es el dominio de seguridad, pero no lo necesitamos, así que lo configuramos null.
optimizationLevel y maximumInterpreterStackDepth
Un parámetro
optimizationLevelcon un valor de 1 a 9 le permite habilitar ciertas "optimizaciones" de código (análisis de flujo de datos, análisis de flujo de tipo, etc.), lo que convertirá una simple verificación de error de sintaxis en una operación que requiere mucho tiempo, y no la necesitamos.
Si lo usa con un valor de 0 , entonces todas estas "optimizaciones" no se aplicarán, sin embargo, si entiendo correctamente, Rhino seguirá usando algunos de los recursos que no son necesarios para la simple verificación de errores, lo que significa que no nos conviene.
Solo queda un valor negativo: al especificar -1 activamos el modo "intérprete", que es exactamente lo que necesitamos. La documentación dice que esta es la forma más rápida y económica de ejecutar Rhino.
El parámetro le
maximumInterpreterStackDepthpermite limitar el número de llamadas recursivas.
Imaginemos qué sucede si no especifica este parámetro:
- El usuario escribirá el siguiente código:
function recurse() { recurse(); } recurse(); - Rhino ejecutará el código, y en un segundo nuestra aplicación fallará
OutOfMemoryError. El fin.
Mostrar errores
Como dije antes, tan pronto como obtengamos el que
ParseResultcontiene RhinoException, tendremos todos los datos necesarios para mostrar, incluido el número de línea, solo tenemos que llamar al método lineNumber().
Ahora escribamos el tramo de línea roja y ondulada que copié en StackOverflow . Hay mucho código, pero la lógica es simple: dibuje dos líneas rojas cortas en ángulos diferentes.
ErrorSpan.kt
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
Ahora puede escribir un método para instalar span en la línea del problema:
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
Es importante recordar que debido a que el resultado llega con un retraso, el usuario puede tener tiempo para borrar un par de líneas de código, y luego
lineNumberpuede resultar inválido.
 Por lo tanto, para no obtenerlo,
Por lo tanto, para no obtenerlo, IndexOutOfBoundsExceptionagregamos un cheque desde el principio. Bueno, entonces, de acuerdo con el esquema familiar, calculamos el primer y último carácter de la cadena, después de lo cual establecemos el intervalo.
Lo principal es no olvidar borrar el texto de los tramos ya establecidos en
afterTextChanged:
fun clearErrorSpans() {
val spans = text.getSpans<ErrorSpan>(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
¿Por qué los editores de código se retrasan?
En dos artículos, escribimos un buen editor de código heredando de
EditTexty MultiAutoCompleteTextView, pero no podemos presumir de rendimiento cuando trabajamos con archivos grandes.
Si abre el mismo TextView.java para 9k + líneas de código, cualquier editor de texto escrito de acuerdo con el mismo principio que el nuestro se retrasará.
P: ¿Por qué QuickEdit no se retrasa entonces?
A: Porque debajo del capó, no usa ni
EditText, ni TextView.
Recientemente, los editores de código en CustomView están ganando popularidad ( aquí y allá , bueno, o aquí y allá), hay muchos de ellos). Históricamente, TextView tiene demasiada lógica redundante que los editores de código no necesitan. Las primeras cosas que vienen a la mente son Autocompletar , Emoji , Dibujables compuestos , enlaces en los que se puede hacer clic , etc.
Si entendí correctamente, los autores de las bibliotecas simplemente se deshicieron de todo esto, como resultado de lo cual obtuvieron un editor de texto capaz de trabajar con archivos de un millón de líneas sin mucha carga en el hilo de la interfaz de usuario. (Aunque puedo estar parcialmente equivocado, no entendí mucho la fuente)
Hay otra opción, pero en mi opinión menos atractiva: editores de código en WebView ( aquí y allá, hay muchos de ellos también). No me gustan porque la interfaz de usuario en WebView se ve peor que la nativa, y también pierden a los editores en CustomView en términos de rendimiento.
Conclusión
Si su tarea es escribir un editor de código y llegar a la cima de Google Play, no pierda el tiempo y tome una biblioteca preparada en CustomView. Si desea obtener una experiencia única, escriba todo usted mismo utilizando widgets nativos.
También dejaré un enlace al código fuente de mi editor de código en GitHub , allí encontrará no solo las características que le mencioné en estos dos artículos, sino también muchas otras que quedaron sin atención.
¡Gracias!