Creo que casi todos los proyectos que usan Ruby on Rails y Postgres como arma principal en el backend están en una lucha constante entre la velocidad de desarrollo, la legibilidad / mantenibilidad del código y la velocidad del proyecto en producción. Le contaré sobre mi experiencia de equilibrio entre estas tres ballenas en un caso en el que la legibilidad y la velocidad del trabajo sufrieron en la entrada, y al final resultó hacer lo que varios ingenieros talentosos intentaron hacer antes que yo sin éxito.

Toda la historia tendrá varias partes. Esta es la primera vez que hablaré sobre qué es PMDSC para optimizar las consultas SQL, compartir herramientas útiles para medir el rendimiento de las consultas en postgres y recordarme una hoja de trucos antigua y útil que todavía es relevante hoy en día.
Ahora, después de un tiempo, "en retrospectiva", entiendo que a la entrada de este caso no esperaba en absoluto que tuviera éxito. Por lo tanto, esta publicación será útil más bien para los desarrolladores atrevidos y no para los más experimentados que para los súper mayores que han visto rieles con SQL desnudo.
Datos de entrada
En Appbooster estamos promoviendo aplicaciones móviles. Para presentar y probar hipótesis fácilmente, desarrollamos varias de nuestras aplicaciones. El backend para la mayoría de ellos es la API de Rails y Postgresql.
El héroe de esta publicación ha estado en desarrollo desde finales de 2013, luego acababan de lanzar los rieles 4.1.0.beta1. Desde entonces, el proyecto se ha convertido en una aplicación web completamente cargada que se ejecuta en varios servidores en Amazon EC2 con una instancia de base de datos separada en Amazon RDS (db.t3.xlarge con 4 vCPU y 16 GB de RAM). Las cargas máximas alcanzan las 25k RPM, la carga diaria promedio es de 8-10k RPM.
Esta historia comenzó con una instancia de base de datos, o más bien, con su saldo crediticio.
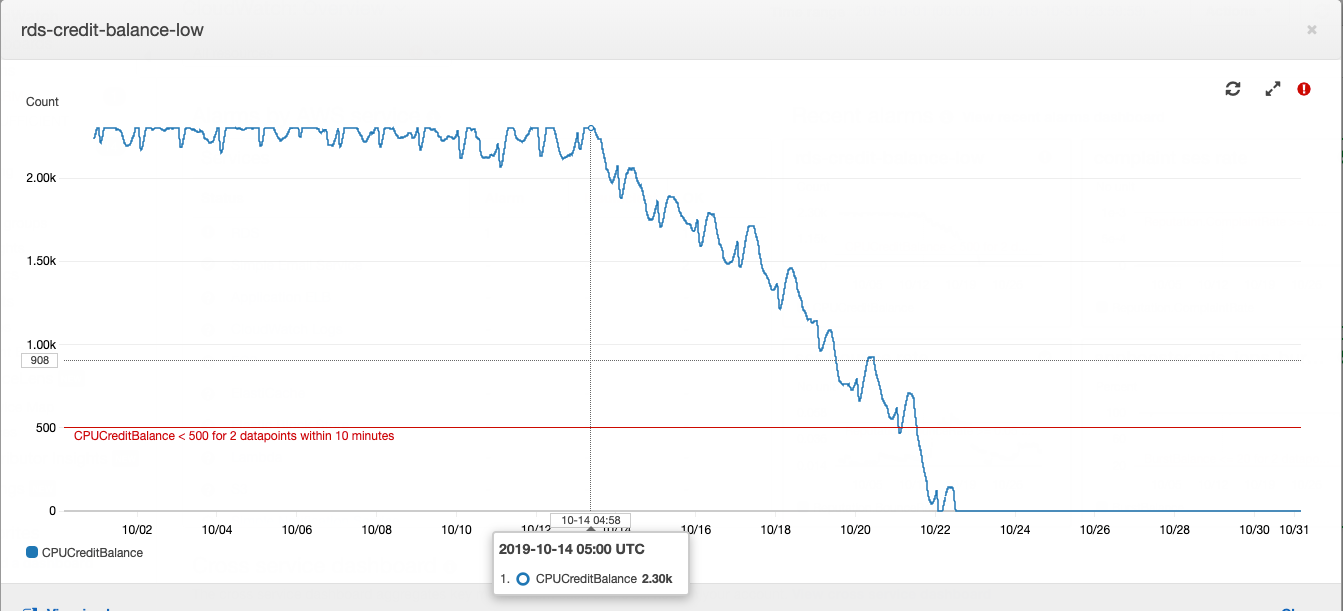
Cómo funciona una instancia de Postgres tipo "t" en Amazon RDS: si su base de datos se ejecuta con un consumo promedio de CPU por debajo de un cierto valor, entonces acumula créditos en su cuenta, que la instancia puede gastar en el consumo de CPU durante las horas de alta carga - esto le ahorra pagar de más para la capacidad del servidor y para hacer frente a la alta carga. Puede encontrar más detalles sobre qué y cuánto pagan con AWS en el artículo de nuestro CTO .
El saldo de los préstamos en cierto punto se agotó. Durante algún tiempo, esto no se le dio mucha importancia, porque el saldo de los préstamos puede reponerse con dinero: nos costó alrededor de $ 20 por mes, lo que no es muy notable por el costo total del alquiler de la potencia informática. En el desarrollo de productos, es costumbre prestar atención principalmente a las tareas formuladas a partir de los requisitos comerciales. El mayor consumo de CPU del servidor de bases de datos se ajusta a la deuda técnica y se compensa con el pequeño costo de comprar un saldo acreedor.
Un buen día, escribí en el resumen diario que estaba muy cansado de apagar los "incendios" que aparecían periódicamente en diferentes partes del proyecto. Si esto continúa, el desarrollador agotado dedicará tiempo a las tareas comerciales. El mismo día, fui al gerente principal del proyecto, le expliqué la alineación y solicité tiempo para investigar las causas de los incendios periódicos y la reparación. Después de recibir el visto bueno, comencé a recopilar datos de varios sistemas de monitoreo.
Usamos Newrelic para rastrear el tiempo de respuesta total por día. La imagen se veía así:
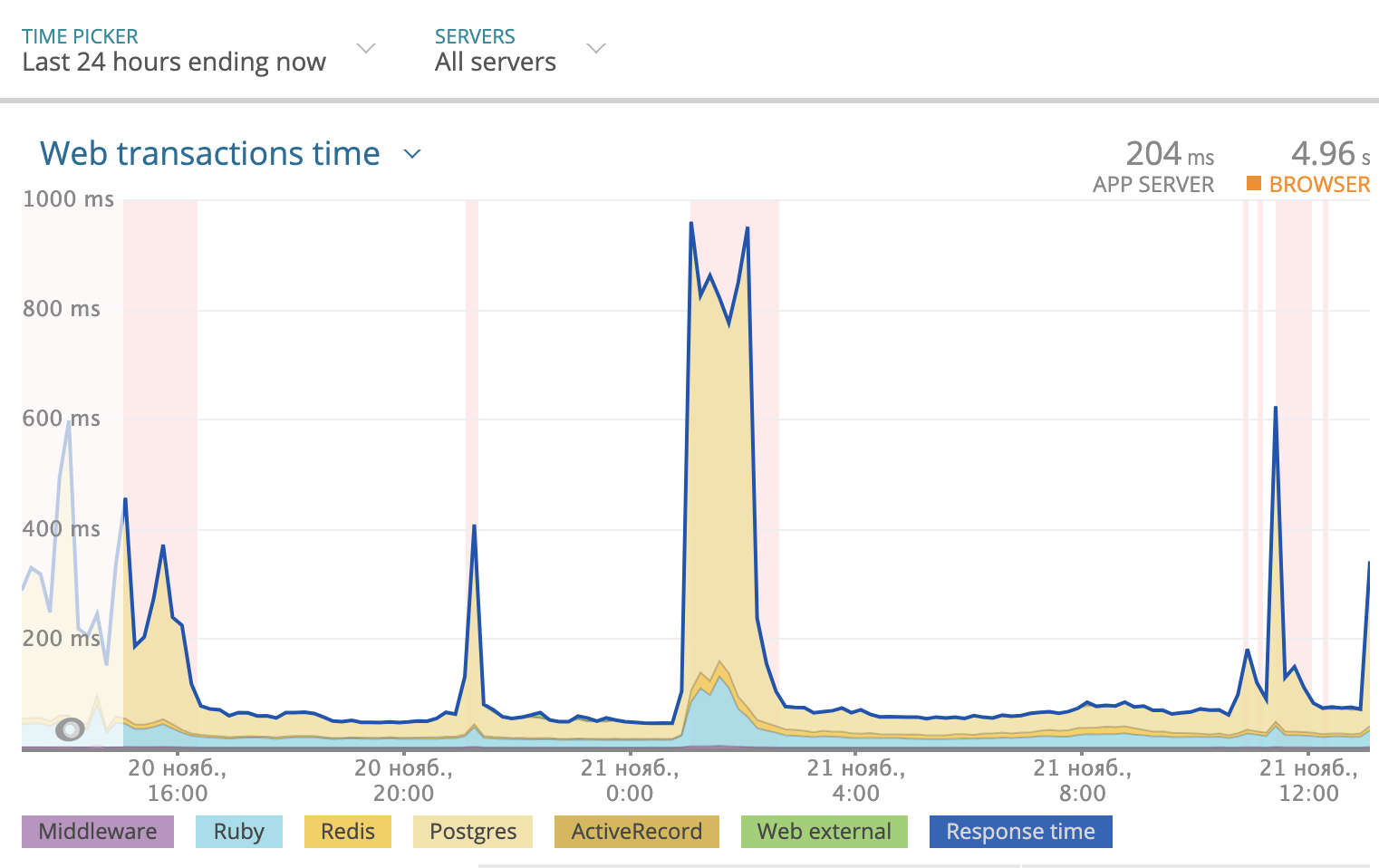
parte del tiempo de respuesta que toma Postgres se resalta en amarillo en el gráfico. Como puede ver, a veces el tiempo de respuesta alcanzó los 1000 ms, y la mayoría de las veces fue la base de datos la que consideró la respuesta. Por lo tanto, debe mirar lo que sucede con las consultas SQL.
PMDSC es una práctica simple y directa para cualquier trabajo aburrido de optimización de SQL
¡Juegalo!
¡Mídelo!
¡Dibujalo!
¡Supónlo!
¡Revisalo!
¡Juegalo!
Quizás la parte más importante de toda la práctica. Cuando alguien dice la frase "Optimizando consultas SQL", más bien provoca un ataque de bostezo y aburrimiento en la gran mayoría de las personas. Cuando dices "Investigación de detectives y búsqueda de villanos peligrosos", te atrae más y te pone de buen humor. Por lo tanto, es importante entrar en el juego. Disfruté jugando al detective. Imaginé que los problemas con la base de datos son delincuentes peligrosos o enfermedades raras. Y se imaginó a sí mismo en el papel de Sherlock Holmes, el teniente Columbo o Doctor House. ¡Elige un héroe a tu gusto y vete!
¡Mídelo!

Para analizar las estadísticas de solicitud, instalé PgHero . Esta es una forma muy conveniente de leer datos desde la extensión pg_stat_statements Postgres. Vaya a / consultas y mire las estadísticas de todas las consultas de las últimas 24 horas. Ordenar las consultas de forma predeterminada de acuerdo con la columna Tiempo total (la proporción del tiempo total que la base de datos procesa la consulta) es una fuente valiosa para encontrar sospechosos. Tiempo promedio: cuántos, en promedio, se ejecuta la solicitud. Llamadas: cuántas solicitudes se realizaron durante el tiempo seleccionado. PgHero considera que las solicitudes son lentas si se ejecutaron más de 100 veces al día y demoraron más de 20 milisegundos en promedio. Lista de consultas lentas en la primera página, inmediatamente después de la lista de índices duplicados.

Tomamos el primero de la lista y miramos los detalles de la consulta, inmediatamente puede verlo explicar analizar. Si el tiempo de planificación es mucho menor que el tiempo de ejecución, entonces algo está mal con esta solicitud y estamos centrando nuestra atención en este sospechoso.
PgHero tiene su propio método de visualización, pero me gustó usar más explicando.depesz.com, copiando datos de explicar analizar allí.
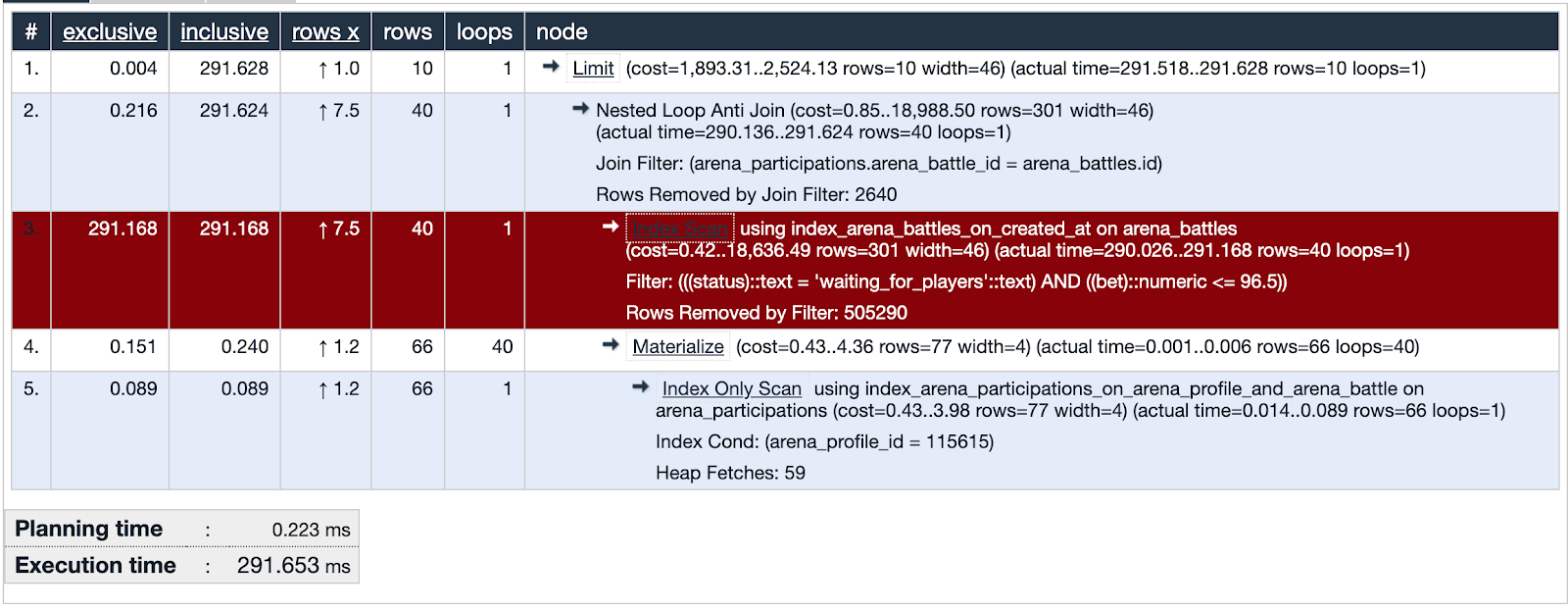
Una de las consultas sospechosas está utilizando Index Scan. La visualización muestra que este índice no es efectivo y es un punto débil, resaltado en rojo. ¡Multa! ¡Examinamos las huellas del sospechoso y encontramos evidencia importante! La justicia es inevitable!
¡Dibujalo!
Dibujemos muchos datos que se usan en la parte problemática de la consulta. Será útil comparar con qué datos cubre el índice.
Un poco de contexto. Probamos una de las formas de mantener al público en la aplicación, algo así como una lotería en la que puede ganar algo de moneda local. Realiza una apuesta, adivina un número del 0 al 100 y toma el bote completo si su número es el más cercano al que recibió el generador de números aleatorios. Lo llamamos "Arena" y llamamos a las manifestaciones "Batallas".

La base de datos en el momento de la investigación contiene alrededor de quinientos mil registros de batallas. En la parte problemática de la solicitud, estamos buscando batallas en las que la tasa no exceda el saldo del usuario y el estado de la batalla esté esperando a los jugadores. Vemos que la intersección de conjuntos (resaltada en naranja) es un número muy pequeño de registros.
El índice utilizado en la parte sospechosa de la solicitud cubre todas las batallas creadas en el campo created_at. La solicitud se ejecuta a través de 505330 registros de los cuales selecciona 40, y 505290 los elimina. Se ve muy derrochador.
¡Supónlo!
Presentamos una hipótesis. ¿Qué ayudará a la base de datos a encontrar cuarenta de quinientos mil registros? Tratemos de hacer un índice que cubra el campo de tasa, solo para batallas con el estado "esperando jugadores", un índice parcial.
add_index :arena_battles, :bet,
where: "status = 'waiting_for_players'",
name: "index_arena_battles_on_bet_partial_status"
Índice parcial : existe solo para aquellos registros que coinciden con la condición: el campo de estado es igual a "esperar a jugadores" e indexa el campo de índice, exactamente lo que está en la condición de consulta. Es muy beneficioso usar este índice en particular: solo toma 40 kilobytes y no cubre las batallas que ya se han jugado y no necesitamos obtener una muestra. A modo de comparación, el índice index_arena_battles_on_created_at, que fue utilizado por el sospechoso, ocupa unos 40 MB, y la tabla con batallas es de unos 70 MB. Este índice se puede eliminar de forma segura si otras consultas no lo usan.
¡Revisalo!
Lanzamos la migración con el nuevo índice a producción y observamos cómo ha cambiado la respuesta del punto final con las batallas.
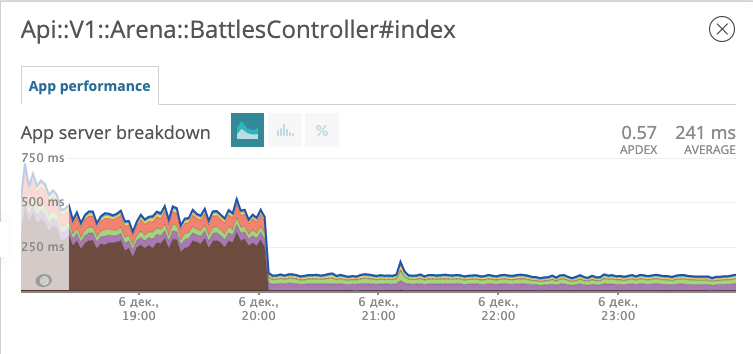
El gráfico muestra a qué hora implementamos la migración. En la tarde del 6 de diciembre, el tiempo de respuesta disminuyó aproximadamente 10 veces de ~ 500 ms a ~ 50ms. El sospechoso en la corte recibió el estatus de prisionero y ahora está en prisión. ¡Multa!
Fuga de la prisión
Unos días después, nos dimos cuenta de que éramos felices desde el principio. Parece que el prisionero encontró cómplices, desarrolló e implementó un plan de escape.
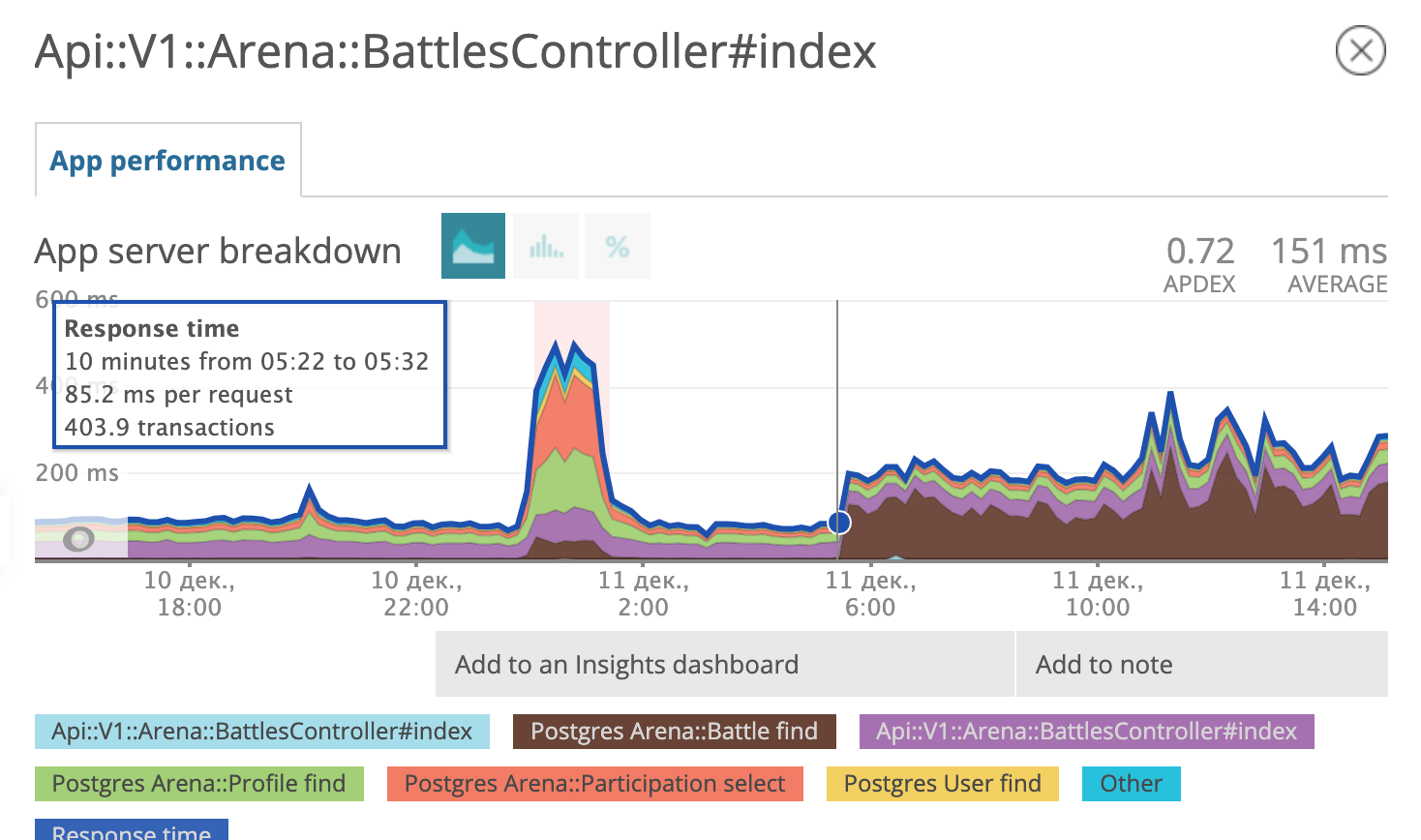
En la mañana del 11 de diciembre, el programador de consultas de postgres decidió que usar un nuevo índice analizado ya no era rentable y comenzó a usar el antiguo nuevamente.
¡Estamos de vuelta en la etapa Suponga que! Preparando un diagnóstico diferencial, en el espíritu del Dr. House:
- Puede ser necesario optimizar la configuración de postgres;
- tal vez actualice postgres a una versión más nueva en términos menores (9.6.11 -> 9.6.15);
- y tal vez, nuevamente, estudie cuidadosamente qué consulta SQL forma Rails?
Probamos las tres hipótesis. Este último nos llevó al rastro de un cómplice.
SELECT "arena_battles".*
FROM "arena_battles"
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
))
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0Veamos juntos este SQL. Seleccionamos todos los campos de batalla de la tabla de batalla cuyo estado es igual a "esperar jugadores" y la tasa es menor o igual a cierto número. Hasta ahora todo ESTÁ CLARO. El siguiente término en la condición se ve espeluznante.
NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
)Estamos buscando un resultado de subconsulta inexistente. Obtén el primer campo de la tabla de participación en la batalla, donde la identificación de la batalla coincide y el perfil del participante pertenece a nuestro jugador. Intentaré dibujar el conjunto descrito en la subconsulta.
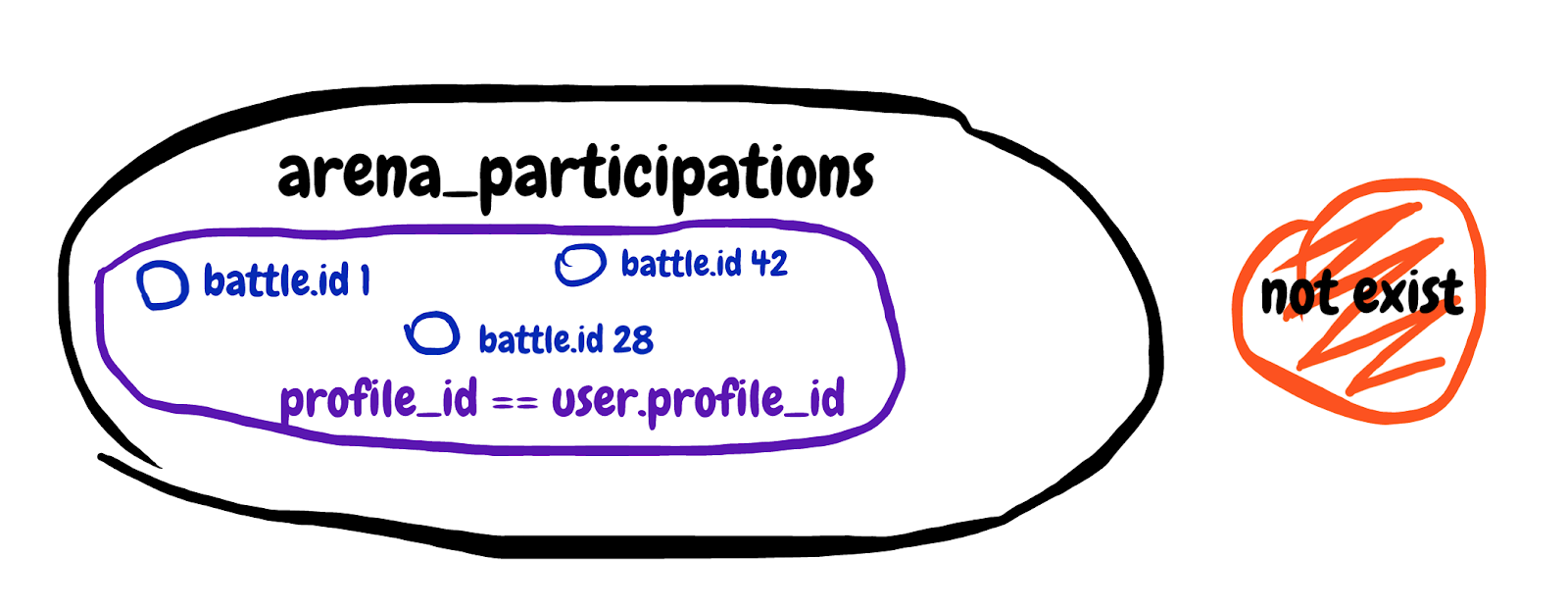
Es difícil de comprender, pero al final, con esta subconsulta, tratamos de excluir aquellas batallas en las que el jugador ya está participando. Observamos la explicación general de la consulta y vemos Tiempo de planificación: 0.180 ms, Tiempo de ejecución: 12.119 ms. ¡Encontramos un cómplice!
Es hora de mi hoja de trucos favorita, que ha estado en Internet desde 2008. Aquí está:

¡Sí! Tan pronto como una consulta encuentre algo que debería excluir un cierto número de registros basados en datos de otra tabla, este meme con barba y rizos debería aparecer en la memoria.
De hecho, esto es lo que necesitamos:

Guarde esta imagen para usted o, mejor aún, imprímala y cuélguela en varios lugares de la oficina.
Reescribimos la subconsulta para IZQUIERDA UNIRSE DONDE B.key ES NULO, obtenemos:
SELECT "arena_battles".*
FROM "arena_battles"
LEFT JOIN arena_participations
ON arena_participations.arena_battle_id = arena_battles.id
AND (arena_participations.arena_profile_id = 46809)
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (arena_participations.id IS NULL)
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0La consulta corregida se ejecuta en dos tablas a la vez. Agregamos una tabla con registros de la participación del usuario en las batallas a la "izquierda" y agregamos la condición de que el identificador de participación no existe. Veamos la explicación analizar la consulta recibida: Tiempo de planificación: 0.185 ms, Tiempo de ejecución: 0.337 ms. ¡Multa! Ahora el planificador de consultas no dudará en usar el índice parcial, sino que usará la opción más rápida. El prisionero fugitivo y su cómplice fueron condenados a cadena perpetua en una institución de régimen estricto. Será más difícil para ellos escapar.
El resumen es breve.
- Use Newrelic u otro servicio similar para encontrar clientes potenciales. Nos dimos cuenta de que el problema está precisamente en las consultas de la base de datos.
- Use la práctica de PMDSC: funciona y, en cualquier caso, es muy atractivo.
- Use PgHero para encontrar sospechosos e investigar pistas en las estadísticas de consultas SQL.
- Utilice explicar.depesz.com : es fácil de leer, explicar, analizar consultas allí.
- Intente extraer muchos datos cuando no sepa qué está haciendo exactamente la solicitud.
- Piensa en el tipo duro con rizos en la cabeza cuando ves a una subconsulta buscando algo que no está en otra mesa.
- Juega detective, incluso podrías obtener una insignia.