 Dialogue 2020 , una conferencia científica internacional sobre lingüística computacional y tecnología inteligente, ha finalizado recientemente . Por primera vez, la Escuela Phystech de Matemática Aplicada e Informática (FPMI) de MIPT se convirtió en socio de la conferencia . Tradicionalmente, uno de los eventos clave del Diálogo es la Evaluación del Diálogo , una competencia entre los desarrolladores de sistemas automáticos para el análisis de texto lingüístico. Ya hemos hablado en Habré sobre las tareas que los participantes de la competencia resolvieron el año pasado, por ejemplo, sobre generar encabezados y encontrar palabras faltantes en el texto. Hoy hablamos con los ganadores de dos pistas de la Evaluación del Diálogo de este año, Vladislav Korzun y Daniil Anastasyev, sobre por qué decidieron participar en competencias tecnológicas, qué problemas y de qué manera resolvieron, qué les interesa a los chicos, dónde estudiaron y qué planean hacer en el futuro. ¡Bienvenido al gato!
Dialogue 2020 , una conferencia científica internacional sobre lingüística computacional y tecnología inteligente, ha finalizado recientemente . Por primera vez, la Escuela Phystech de Matemática Aplicada e Informática (FPMI) de MIPT se convirtió en socio de la conferencia . Tradicionalmente, uno de los eventos clave del Diálogo es la Evaluación del Diálogo , una competencia entre los desarrolladores de sistemas automáticos para el análisis de texto lingüístico. Ya hemos hablado en Habré sobre las tareas que los participantes de la competencia resolvieron el año pasado, por ejemplo, sobre generar encabezados y encontrar palabras faltantes en el texto. Hoy hablamos con los ganadores de dos pistas de la Evaluación del Diálogo de este año, Vladislav Korzun y Daniil Anastasyev, sobre por qué decidieron participar en competencias tecnológicas, qué problemas y de qué manera resolvieron, qué les interesa a los chicos, dónde estudiaron y qué planean hacer en el futuro. ¡Bienvenido al gato!
Vladislav Korzun, ganador de la ruta de evaluación de diálogo RuREBus-2020

¿Qué haces?
Soy desarrollador en NLP Advanced Research Group en ABBYY. Actualmente estamos resolviendo una tarea de aprendizaje de una sola vez para extraer entidades. Es decir, al tener una pequeña muestra de capacitación (5-10 documentos), debe aprender cómo extraer entidades específicas de documentos similares. Para esto, vamos a utilizar los resultados del modelo NER capacitados en tipos de entidad estándar (Persona, Ubicación, Organización) como características para resolver este problema. También planeamos usar un modelo de lenguaje especial, que fue entrenado en documentos similares en el tema de nuestra tarea.
¿Qué tareas resolvió en la evaluación de diálogo?
En el Diálogo, participé en el concurso RuREBus dedicado a extraer entidades y relaciones de documentos específicos del corpus del Ministerio de Desarrollo Económico. Este caso era muy diferente de los casos utilizados, por ejemplo, en la competencia de Conll . Primero, los tipos de entidades en sí no eran estándar (Personas, Ubicaciones, Organizaciones), entre ellos incluso hubo acciones sustantivas y sin nombre. En segundo lugar, los textos en sí mismos no eran conjuntos de oraciones verificadas, sino documentos reales, lo que condujo a varias listas, encabezados e incluso tablas. Como resultado, las principales dificultades surgieron precisamente con el procesamiento de datos y no con la resolución del problema. de hecho, estas son las tareas clásicas de reconocimiento de entidades nombradas y extracción de relaciones.
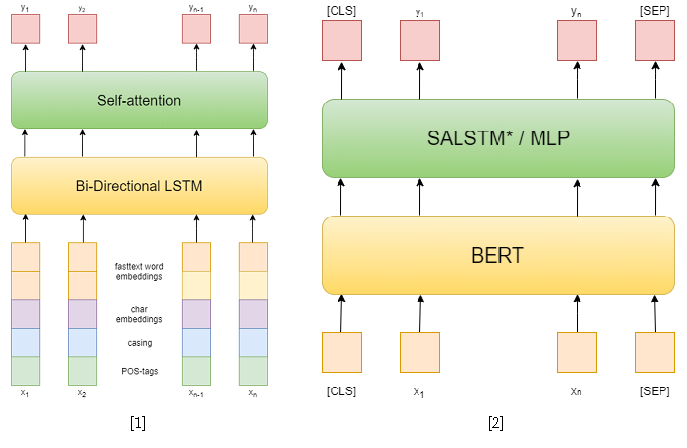
En la competencia en sí, había 3 pistas: NER, RE con entidades dadas y RE de extremo a extremo. Traté de resolver los dos primeros. En la primera tarea, utilicé enfoques clásicos. Primero, traté de usar una red recurrente como modelo, y las incorporaciones de palabras de texto rápido, los patrones de mayúsculas, las incorporaciones simbólicas y las etiquetas POS [1] como características. Entonces ya he usado varios BERT pre-entrenados [2], que son bastante superiores a mi enfoque anterior. Sin embargo, esto no fue suficiente para tomar el primer lugar en esta pista.
Pero en la segunda pista tuve éxito. Para resolver el problema de extraer relaciones, lo reduje al problema de clasificar relaciones, similar a SemEval 2010 Tarea 8 . En este problema, para cada oración, se da un par de entidades, para las cuales la relación necesita ser clasificada. Y en una pista, cada oración puede contener tantas entidades como desee, sin embargo, simplemente se reduce a la anterior al muestrear la oración para cada par de entidades. Además, durante el entrenamiento, tomé ejemplos negativos al azar para cada oración en un tamaño que no excede el doble del número de los positivos para reducir la muestra de entrenamiento.
Como enfoques para resolver el problema de clasificar las relaciones, utilicé dos modelos basados en BERT-e. En el primero, simplemente concatenaba las salidas BERT con incrustaciones NER y luego promediaba las características de cada token usando la auto atención [3]. Una de las mejores soluciones para SemEval 2010 Tarea 8 - R-BERT [4] fue tomada como el segundo modelo. La esencia de este enfoque es la siguiente: inserte tokens especiales antes y después de cada entidad, promedie las salidas BERT para los tokens de cada entidad, combine los vectores resultantes con la salida correspondiente al token CLS y clasifique el vector de característica resultante. Como resultado, este modelo ocupó el primer lugar en la pista. Los resultados de la competencia están disponibles aquí .
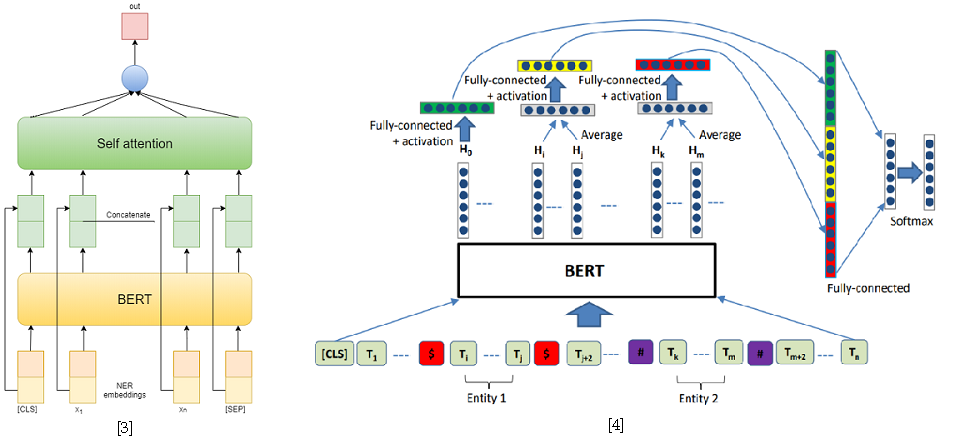
[4] Wu, S., He, Y. (noviembre de 2019). Enriquecimiento del modelo de lenguaje pre-entrenado con información de entidad para la clasificación de relaciones. En Actas de la 28ª Conferencia Internacional ACM sobre Gestión de la Información y el Conocimiento ( pp. 2361-2364 ).
¿Qué te pareció más difícil en estas tareas?
Lo más problemático fue el procesamiento del caso. Las tareas en sí mismas son lo más clásicas posible, para su solución ya hay marcos ya preparados, por ejemplo, AllenNLP. Pero la respuesta debe darse al guardar tramos de tokens, por lo que no podría simplemente usar la tubería preparada sin escribir mucho código adicional. Por lo tanto, decidí escribir toda la tubería en PyTorch puro para no perderme nada. Aunque todavía utilicé algunos módulos de AllenNLP.
También hubo muchas oraciones bastante largas en el corpus, lo que causó inconvenientes al enseñar transformadores grandes, por ejemplo, BERT, porque se vuelven exigentes con la memoria de video al aumentar la longitud de las oraciones. Sin embargo, la mayoría de estas oraciones son enumeraciones delimitadas por punto y coma y podrían estar separadas por ese carácter. Simplemente dividí las ofertas restantes por el número máximo de tokens.
¿Has participado en Diálogo y canciones antes?
El año pasado hablé con mi maestría en la sesión de estudiantes.
¿Por qué decidiste participar en la competencia este año?
En este momento, solo estaba resolviendo el problema de extraer relaciones, pero para un cuerpo diferente. Traté de usar un enfoque diferente basado en árboles de análisis. La ruta en el árbol de una entidad a otra se usó como entrada. Pero este enfoque, desafortunadamente, no mostró resultados sólidos, aunque estaba en un nivel con el enfoque basado en redes recurrentes, utilizando incrustaciones de token y otras características como signos, como la longitud del camino desde un token a una raíz o una de las entidades en el árbol sintáctico. análisis, así como la posición relativa de las entidades.
En esta competencia, decidí participar, porque ya tenía algunas bases para resolver problemas similares. ¿Y por qué no aplicarlos en una competencia y publicarlos? Resultó no tan fácil como pensaba, pero se debe más bien a problemas con la interacción con los cascos. Como resultado, para mí fue más una tarea de ingeniería que de investigación.
¿Has participado en otras competiciones?
Al mismo tiempo, nuestro equipo participó en SemEval . Ilya Dimov estuvo involucrado principalmente en la tarea, solo sugerí un par de ideas. Estaba la tarea de clasificar la propaganda: se seleccionó la extensión del texto y fue necesario clasificarlo. Sugerí usar el enfoque R-BERT, es decir, seleccionar esta entidad en tokens, insertar un token especial delante y después de ella, y promediar las salidas. Como resultado, esto dio un pequeño aumento. Este es el valor científico: para resolver el problema, utilizamos un modelo diseñado para algo completamente diferente.
También participé en ABBYY hackathon, en ACM icpc - competencia en programación deportiva en los primeros años. No llegamos muy lejos en ese entonces, pero fue divertido. Tales competencias son muy diferentes de las presentadas en el Diálogo, donde hay suficiente tiempo para implementar y probar con calma varios enfoques. En los hackatones, debes hacer todo rápidamente, no hay tiempo para relajarte, no hay té. Pero esta es la belleza de tales eventos: tienen una atmósfera específica.
¿Cuáles son los problemas más interesantes que resolvió en concursos o en el trabajo?
Hay una competencia de generación de gestos GENEA próximamente y voy a ir allí. Creo que será interesante Este es un taller en ACM - Conferencia Internacional sobre Agentes Virtuales Inteligentes . En esta competencia, se propone generar gestos para un modelo humano 3D basado en la voz. Hablé este año en el Diálogo con un tema similar, hice una pequeña descripción de los enfoques al problema de la generación automática de expresiones faciales y gestos a partir de la voz. Necesito ganar experiencia, porque todavía tengo que defender mi tesis sobre un tema similar. Quiero intentar crear un agente virtual de lectura, con expresiones faciales, gestos y, por supuesto, voz. Los enfoques actuales de síntesis de voz permiten generar un discurso bastante realista a partir del texto, mientras que los enfoques de generación de gestos permiten generar gestos a partir de la voz. Entonces, ¿por qué no combinar estos enfoques?
Por cierto, ¿dónde estás estudiando ahora?
Soy un estudiante de posgrado en el Departamento de Lingüística Computacional en ABBYY en la Escuela de Matemáticas Aplicadas e Informática de Phystech en MIPT . Defenderé mi tesis en dos años.
¿Qué conocimientos y habilidades adquiridos en la universidad te ayudan ahora?
Curiosamente, las matemáticas. Aunque no me integro todos los días y no multiplico matrices en mi cabeza, las matemáticas enseñan el pensamiento analítico y la capacidad de resolver cualquier cosa. Después de todo, cualquier examen incluye probar teoremas, y tratar de aprenderlos es inútil, pero es posible comprender y probarse a sí mismo, recordando solo una idea. También tuvimos buenos cursos de programación, donde aprendimos de un nivel bajo para comprender cómo funciona todo, analizamos varios algoritmos y estructuras de datos. Y ahora no será un problema lidiar con un nuevo marco o incluso un lenguaje de programación. Sí, por supuesto, tuvimos cursos de aprendizaje automático y de PNL en particular, pero aún así, me parece que las habilidades básicas son más importantes.
Daniil Anastasyev, ganador del Dialogue Evaluation GramEval-2020 track

¿Qué haces?
Estoy desarrollando el asistente de voz "Alice", trabajo en la búsqueda del grupo de significado. Analizamos las solicitudes que llegan a Alice. Un ejemplo estándar de una consulta es "¿Qué tiempo hará en Moscú mañana?" Debe comprender que esta es una solicitud sobre el clima, que la solicitud pregunta sobre la ubicación (Moscú) y hay una indicación de la hora (mañana).
Cuéntenos sobre el problema que resolvió este año en una de las pistas de Evaluación de Diálogo.
Estaba haciendo una tarea muy cercana a lo que ABBYY está haciendo. Era necesario construir un modelo que analizara la oración, hiciera un análisis morfológico y sintáctico, y definiera lemas. Esto es muy similar a lo que hacen en la escuela. Me llevó unos 5 días libres construir el modelo.

El modelo estudió en ruso normal, pero, como puede ver, también funciona en el idioma del problema.
¿Suena esto como lo que haces en el trabajo?
Probablemente no. Aquí debe comprender que esta tarea en sí misma no tiene mucho significado: se resuelve como una subtarea en el marco de la resolución de algún problema comercial importante. Entonces, por ejemplo, en ABBYY, donde una vez trabajé, el análisis morfosintáctico es la etapa inicial para resolver el problema de la extracción de información. Dentro del marco de mis tareas actuales, no necesito tales análisis. Sin embargo, la experiencia adicional de trabajar con modelos de lenguaje previamente entrenados como BERT parece ser ciertamente útil para mi trabajo. En general, esta fue la principal motivación para participar: no quería ganar, sino practicar y adquirir algunas habilidades útiles. Además, mi diploma estaba relacionado en parte con el tema del problema.
¿Has participado antes en la evaluación del diálogo?
Participó en la pista MorphoRuEval-2017 en el quinto año y también obtuvo el primer lugar. Entonces fue necesario definir solo la morfología y los lemas, sin relaciones sintácticas.
¿Es realista aplicar su modelo a otras tareas en este momento?
Sí, mi modelo se puede usar para otras tareas: publiqué todo el código fuente. Planeo publicar el código usando un modelo más ligero y rápido pero menos preciso. En teoría, si alguien quiere, se puede usar el modelo actual. El problema es que será demasiado grande y lento para la mayoría. En competencia, a nadie le importa la velocidad, es interesante lograr la mayor calidad posible, pero en la aplicación práctica, todo suele ser al revés. Por lo tanto, el principal beneficio de modelos tan grandes es saber qué calidad es la más alcanzable para comprender lo que está sacrificando.
¿Por qué participa en la evaluación del diálogo y otras competiciones similares?
Los hackatones y esas competiciones no están directamente relacionados con mi trabajo, pero sigue siendo una experiencia gratificante. Por ejemplo, cuando participé en el hackathon AI Journey el año pasado, aprendí algunas cosas que luego usé en mi trabajo. La tarea consistía en aprender a aprobar el examen en ruso, es decir, resolver exámenes y escribir un ensayo. Está claro que todo esto tiene poco que ver con el trabajo. Pero la capacidad de encontrar y entrenar rápidamente un modelo que resuelva algún problema es muy útil. Por cierto, mi equipo y yo ganamos el primer lugar.
¿Qué educación obtuviste y qué hiciste después de la universidad?
Se graduó de los títulos de licenciatura y maestría del Departamento de Lingüística Computacional ABBYY en el Instituto de Física y Tecnología de Moscú, se graduó en 2018. También estudió en la Escuela de Análisis de Datos (SHAD). Cuando llegó el momento de elegir un departamento básico en el segundo año, la mayoría de nuestro grupo fue a los departamentos de ABBYY: lingüística computacional o reconocimiento de imágenes y procesamiento de texto. En el programa de pregrado nos enseñaron a programar bien, había cursos muy útiles. Desde el cuarto año trabajé en ABBYY durante 2.5 años. Primero, en el grupo de morfología, luego participé en tareas relacionadas con modelos de lenguaje para mejorar el reconocimiento de texto en ABBYY FineReader. Escribí código, modelos entrenados, ahora estoy haciendo lo mismo, pero para un producto completamente diferente.
¿Como gastas tu tiempo libre?
Me encanta leer libros. Dependiendo de la temporada, intento correr o esquiar. Soy aficionado a la fotografía mientras viajo.
¿Tiene planes u objetivos para los próximos 5 años?
5 años está demasiado lejos planeando horizonte. Ni siquiera tengo 5 años de experiencia laboral. En los últimos 5 años, mucho ha cambiado, ahora hay claramente un sentimiento diferente de la vida. Apenas puedo imaginar qué más puede cambiar, pero hay pensamientos de obtener un doctorado en el extranjero.
¿Qué consejo puede dar a los desarrolladores jóvenes que se dedican a la lingüística computacional y están al comienzo de su viaje?
Es mejor practicar, probar y competir. Los principiantes completos pueden tomar uno de los muchos cursos: por ejemplo, de SHAD , DeepPavlov o incluso el mío , que una vez enseñé en ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .