* Este artículo está escrito en base al taller abierto REBRAIN & Yandex.Cloud, si te gusta ver el video, puedes encontrarlo en este enlace: https://youtu.be/cZLezUm0ekE
Recientemente tuvimos la oportunidad de sentir Yandex.Cloud en vivo. Como queríamos sentirlo durante mucho tiempo y con firmeza, abandonamos inmediatamente la idea de lanzar un blog de wordpress simple con una base en la nube: es demasiado aburrido. Después de algunas deliberaciones, decidimos implementar algo similar a la arquitectura de producción de un servicio para recibir y analizar eventos en modo casi en tiempo real.
Estoy absolutamente seguro de que la gran mayoría de las empresas en línea (y no solo) de una forma u otra recopilan una montaña de información sobre sus usuarios y sus acciones. Como mínimo, esto es necesario para tomar ciertas decisiones, por ejemplo, si está administrando un juego en línea, puede ver las estadísticas en qué nivel los usuarios están atascados con mayor frecuencia y eliminar su juguete. O por qué los usuarios abandonan su sitio sin comprar nada (hola, Yandex.Metrica).
Entonces, nuestra historia: cómo escribimos una aplicación en golang, probamos kafka vs rabbitmq vs yqs, escribimos transmisión de datos a un clúster de Clickhouse y visualizamos datos usando yandex datalens. Naturalmente, todo esto se condimentó con delicias de infraestructura en forma de docker, terraform, gitlab ci y, por supuesto, prometheus. ¡Vamonos!
Me gustaría hacer una reserva de inmediato de que no podemos configurar todo de una sola vez; para ello, necesitamos varios artículos de la serie. Un poco sobre la estructura:
Parte 1 (la estás leyendo). Definiremos la especificación técnica y la arquitectura de la solución, y también escribiremos una aplicación en golang.
Parte 2. Lanzamos nuestra aplicación a producción, la hacemos escalable y probamos la carga.
Parte 3. Tratemos de averiguar por qué necesitamos almacenar mensajes en un búfer y no en archivos, y también comparemos los servicios de cola kafka, rabbitmq y yandex entre ellos.
Parte 4. Implementaremos el clúster de Clickhouse, escribiremos la transmisión para transferir datos desde el búfer allí, configuraremos la visualización en datalens.
Parte 5. Pongamos toda la infraestructura en forma adecuada: configure ci / cd usando gitlab ci, conecte el monitoreo y el descubrimiento de servicios usando prometheus y consul.
TK
Primero, formularemos los términos de referencia: qué es exactamente lo que queremos obtener en el resultado.
- Queremos tener un punto final de la forma events.kis.im (kis.im es el dominio de prueba que usaremos en todos los artículos), que debería recibir eventos usando HTTPS.
- Los eventos son un json simple de la forma: {"event": "view", "os": "linux", "browser": "chrome"}. En la etapa final, agregaremos un poco más de campos, pero esto no jugará un papel importante. Si lo desea, puede cambiar a protobuf.
- El servicio debería poder procesar 10.000 eventos por segundo.
- Debería poder escalar horizontalmente simplemente agregando nuevas instancias a nuestra solución. Y sería bueno si pudiéramos mover la parte frontal a diferentes geolocalizaciones para reducir la latencia de las solicitudes de los clientes.
- Tolerancia a fallos. La solución debe ser lo suficientemente estable y poder sobrevivir cuando se caiga alguna pieza (hasta una cierta cantidad, por supuesto).
Arquitectura
En general, para este tipo de tareas, se han inventado durante mucho tiempo arquitecturas clásicas que permiten escalar de forma eficaz. La figura muestra un ejemplo de nuestra solución.

Entonces, lo que tenemos:
1. A la izquierda están nuestros dispositivos que generan varios eventos, ya sea pasando el nivel de jugadores en un juguete en un teléfono inteligente o creando un pedido en una tienda en línea a través de un navegador normal. El evento, como se indica en los TOR, es un json simple que se envía a nuestro punto final: events.kis.im.
2. Los dos primeros servidores son equilibradores simples, sus principales tareas son:
- . , , keepalived, IP .
- TLS. , TLS . -, , -, , backend .
- backend . — . , , load balancer’ .
3. Detrás de los equilibradores, tenemos servidores de aplicaciones que ejecutan una aplicación bastante simple. Debería poder aceptar solicitudes HTTP entrantes, validar el json enviado y almacenar los datos en un búfer.
4. El diagrama muestra kafka como un búfer, aunque, por supuesto, se pueden utilizar otros servicios similares en este nivel. Compararemos Kafka, rabbitmq y yqs en el tercer artículo.
5. El penúltimo punto de nuestra arquitectura es Clickhouse, una base de datos en columnas que le permite almacenar y procesar una gran cantidad de datos. En este nivel, necesitamos transferir datos del búfer al sistema de almacenamiento (más sobre esto en el artículo 4).
Esta disposición nos permite escalar de forma independiente cada capa horizontalmente. Los servidores backend no se adaptan, agreguemos más, porque son aplicaciones sin estado y, por lo tanto, esto se puede hacer incluso en modo automático. No extrae un búfer en forma de kafka; agregaremos más servidores y les transferiremos algunas de las particiones de nuestro tema. El clickhouse falla, es imposible :) De hecho, también soltaremos los servidores y compartiremos los datos.
Por cierto, si desea implementar la parte opcional de nuestra especificación técnica y realizar escalado en diferentes geolocalizaciones, entonces no hay nada más fácil:
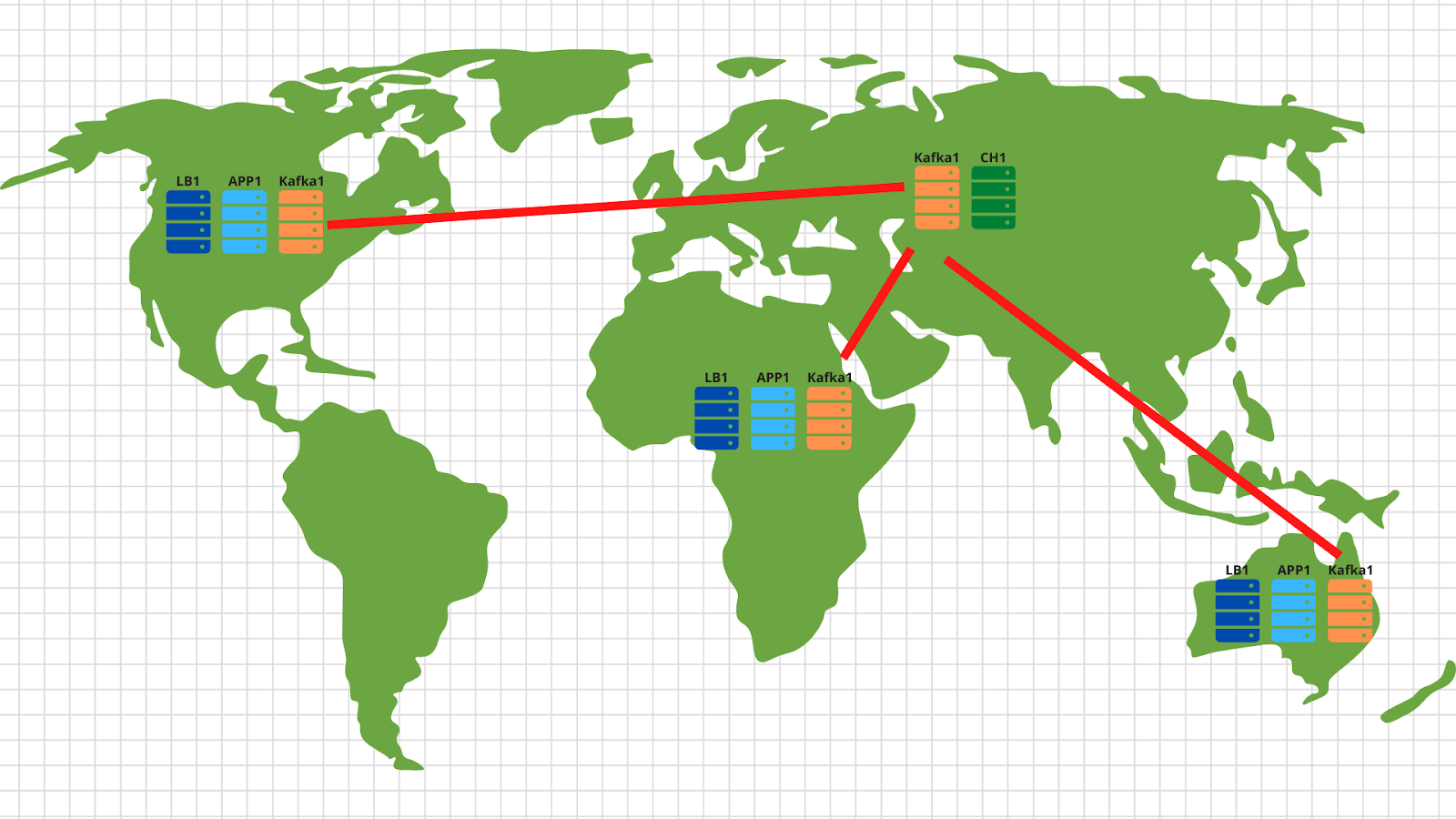
En cada geolocalización, desplegamos un balanceador de carga con aplicación y kafka. En general, son suficientes 2 servidores de aplicaciones, 3 nodos kafka y un equilibrador de nube, por ejemplo, cloudflare, que comprobarán la disponibilidad de los nodos de la aplicación y equilibrarán las solicitudes por geolocalización en función de la dirección IP original del cliente. Así, los datos enviados por el cliente americano aterrizarán en los servidores americanos. Y los datos de África, sobre los africanos.
Entonces todo es bastante simple: usamos la herramienta de espejo del conjunto de kafka y copiamos todos los datos de todas las ubicaciones a nuestro centro de datos central ubicado en Rusia. En el interior, analizamos los datos y los escribimos en Clickhouse para su posterior visualización.
Entonces, descubrimos la arquitectura: ¡comencemos a sacudir Yandex.Cloud!
Escribir una solicitud
Antes de la nube, todavía tiene que aguantar un poco y escribir un servicio bastante simple para procesar los eventos entrantes. Usaremos golang, porque se ha probado muy bien como lenguaje para escribir aplicaciones de red.
Después de pasar una hora (tal vez un par de horas), obtenemos algo como esto: https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/main.go .
¿Cuáles son los puntos principales aquí que me gustaría señalar:
1. Al iniciar la aplicación, puede especificar dos banderas. Uno es responsable del puerto en el que escucharemos las solicitudes http entrantes (-addr). El segundo es para la dirección del servidor kafka donde registraremos nuestros eventos (-kafka):
addr = flag.String("addr", ":8080", "TCP address to listen to")
kafka = flag.String("kafka", "127.0.0.1:9092", "Kafka endpoints”)2. La aplicación utiliza la biblioteca sarama ( [] github.com/Shopify/sarama ) para enviar mensajes al clúster kafka. Inmediatamente configuramos la configuración enfocada en la velocidad máxima de procesamiento:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Además, nuestra aplicación tiene un cliente prometheus integrado que recopila varias métricas, como:
- el número de solicitudes a nuestra aplicación;
- la cantidad de errores al ejecutar la solicitud (es imposible leer la solicitud de publicación, json roto, es imposible escribir al kafka);
- tiempo de procesamiento de una solicitud de un cliente, incluido el tiempo de escritura de un mensaje a kafka.
4. Tres puntos finales que procesa nuestra aplicación:
- / status - simplemente regresa ok para mostrar que estamos vivos. Aunque puede agregar algunas comprobaciones, como la disponibilidad del clúster de kafka.
- / metrics: de acuerdo con esta URL, el cliente de prometheus devolverá las métricas que ha recopilado.
- /post — endpoint, POST json . json — -.
Haré una reserva de que el código no es perfecto: puede (¡y debe!) Estar terminado. Por ejemplo, puede dejar de usar el net / http incorporado y cambiar a fastttp más rápido. O puede ganar tiempo de procesamiento y recursos de la CPU llevando la verificación de validación de json a una etapa posterior, cuando los datos se transferirán desde el búfer al clúster de clickhouse.
Además del lado del desarrollo del problema, inmediatamente pensamos en nuestra infraestructura futura y decidimos implementar nuestra aplicación a través de Docker. El Dockerfile final para compilar la aplicación es https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/Dockerfile . En general es bastante sencillo, el único punto sobre el que quiero llamar la atención es el montaje multietapa, que nos permite reducir la imagen final de nuestro contenedor.
Primeros pasos en la nube
En primer lugar, nos registramos en cloud.yandex.ru . Después de completar todos los campos obligatorios, crearemos una cuenta y recibiremos una subvención por una cierta cantidad de dinero que se puede utilizar para probar los servicios en la nube. Si desea repetir todos los pasos de nuestro artículo, esta subvención debería ser suficiente para usted.
Después del registro, se le creará una nube separada y un directorio predeterminado, en el que podrá comenzar a crear recursos en la nube. En general, en Yandex.Cloud, la relación de recursos es la siguiente:

Puede crear varias nubes para una cuenta. Y dentro de la nube, cree diferentes directorios para diferentes proyectos de la empresa. Puede leer más sobre esto en la documentación: https://cloud.yandex.ru/docs/resource-manager/concepts/resources-hierarchy... Por cierto, a continuación en el texto a menudo me referiré a él. Cuando configuré toda la infraestructura desde cero, la documentación me ayudó más de una vez, así que te aconsejo que estudies.
Para administrar la nube, puede usar tanto la interfaz web como la utilidad de la consola - yc. La instalación se realiza con un comando (para Linux y Mac OS):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashSi un guardia de seguridad interno se enfureció por ejecutar scripts desde Internet, entonces, en primer lugar, puede abrir el script y leerlo, y en segundo lugar, lo ejecutamos bajo nuestro usuario, sin derechos de root.
Si desea instalar el cliente para Windows, puede usar las instrucciones aquí y luego seguir
yc initpara configurarlo por completo:
vozerov@mba:~ $ yc init
Welcome! This command will take you through the configuration process.
Please go to https://oauth.yandex.ru/authorize?response_type=token&client_id= in order to obtain OAuth token.
Please enter OAuth token:
Please select cloud to use:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Please enter your numeric choice: 2
Your current cloud has been set to 'fevlake-cloud' (id = b1g6bvup3toribomnh30).
Please choose folder to use:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Create a new folder
Please enter your numeric choice: 1
Your current folder has been set to 'default' (id = b1g5r6h11knotfr8vjp7).
Do you want to configure a default Compute zone? [Y/n]
Which zone do you want to use as a profile default?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Don't set default zone
Please enter your numeric choice: 1
Your profile default Compute zone has been set to 'ru-central1-a'.
vozerov@mba:~ $En principio, el proceso es simple: primero debe obtener el token oauth para la administración de la nube, seleccionar la nube y la carpeta que utilizará.
Si tiene varias cuentas o carpetas dentro de la misma nube, puede crear perfiles adicionales con configuraciones separadas a través de yc config profile create y cambiar entre ellos.
Además de los métodos anteriores, el equipo de Yandex.Cloud ha escrito un complemento terraform muy bueno para administrar los recursos de la nube. Por mi parte, preparé un repositorio de git, donde describí todos los recursos que se crearán en el marco del artículo - https://github.com/rebrainme/yandex-cloud-events/ . Estamos interesados en la rama maestra, clonémosla localmente:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Cloning into 'events'...
remote: Enumerating objects: 100, done.
remote: Counting objects: 100% (100/100), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 100 (delta 37), reused 89 (delta 26), pack-reused 0
Receiving objects: 100% (100/100), 25.65 KiB | 168.00 KiB/s, done.
Resolving deltas: 100% (37/37), done.
vozerov@mba:~ $ cd events/terraform/Todas las variables principales utilizadas en terraform están escritas en el archivo main.tf. Para comenzar, cree un archivo private.auto.tfvars en la carpeta terraform con el siguiente contenido:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Todas las variables se pueden tomar de la lista de configuración de yc, ya que ya hemos configurado la utilidad de la consola. Le aconsejo que agregue de inmediato private.auto.tfvars a .gitignore para no publicar inadvertidamente datos privados.
En private.auto.tfvars, también especificamos datos de Cloudflare, para crear registros dns y transferir el dominio principal events.kis.im a nuestros servidores. Si no desea utilizar cloudflare, elimine la inicialización del proveedor cloudflare en main.tf y el archivo dns.tf, que es responsable de crear los registros dns necesarios.
En nuestro trabajo, combinaremos los tres métodos: la interfaz web, la utilidad de consola y terraform.
Redes virtuales
Honestamente, este paso podría omitirse, porque cuando crea una nueva nube, automáticamente tendrá una red separada y 3 subredes, una para cada zona de disponibilidad. Aún así, me gustaría crear una red separada para nuestro proyecto con su propio direccionamiento. El esquema general de operación de la red en Yandex.Cloud se muestra en la siguiente figura (honestamente tomado de https://cloud.yandex.ru/docs/vpc/concepts/ )
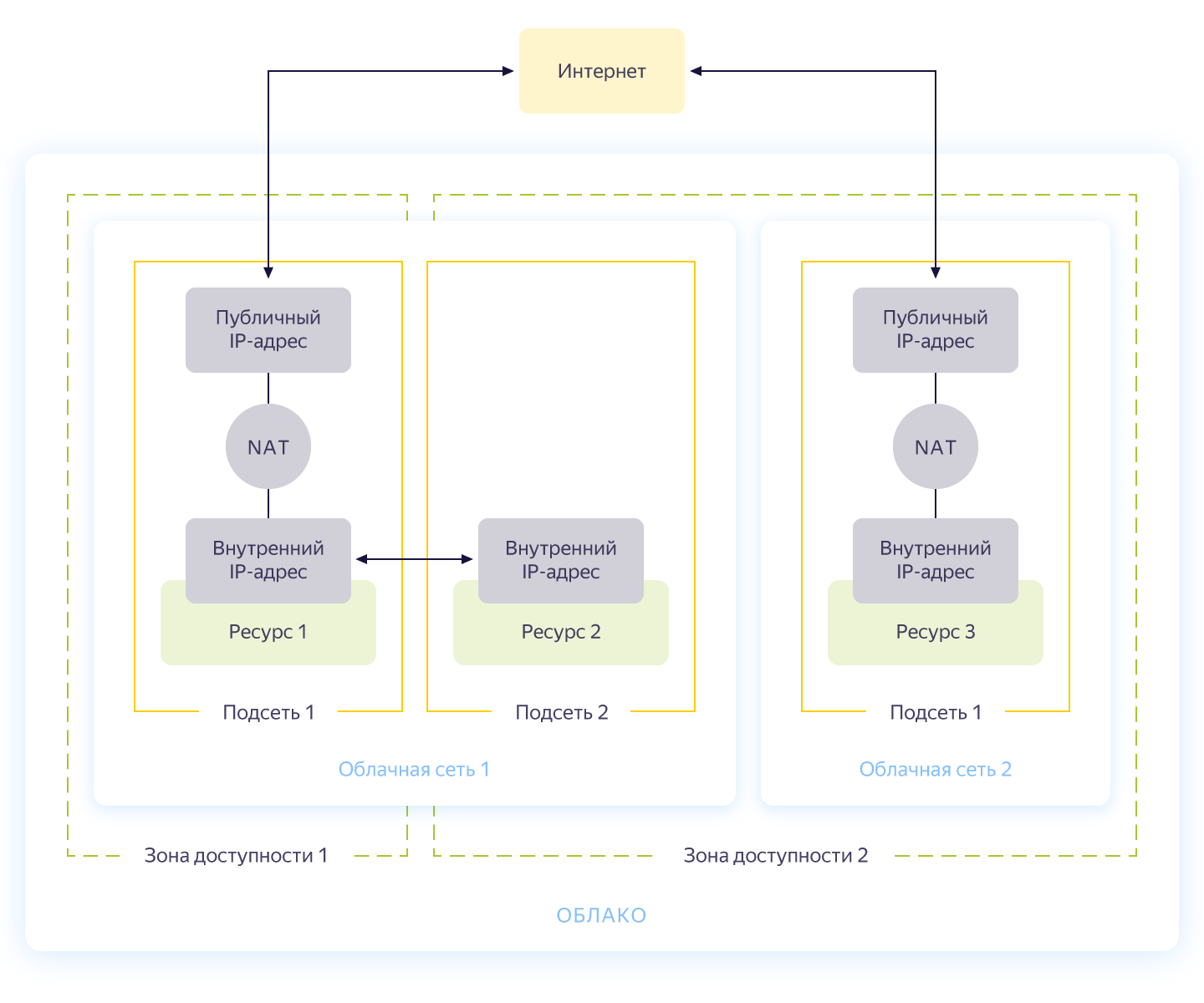
Entonces, crea una red común dentro de la cual los recursos pueden comunicarse entre sí. Para cada zona de disponibilidad, se crea una subred con su propio direccionamiento y se conecta a la red pública. Como resultado, todos los recursos en la nube que contiene pueden comunicarse, incluso estando en diferentes zonas de disponibilidad. Los recursos conectados a diferentes redes en la nube solo pueden verse entre sí a través de direcciones externas. Por cierto, cómo funciona esta magia en el interior se describió bien en Habré .
La creación de la red se describe en el archivo network.tf del repositorio. Allí creamos una red privada común interna y conectamos tres subredes a ella en diferentes zonas de disponibilidad: interna-a (172.16.1.0/24), interna-b (172.16.2.0/24), interna-c (172.16.3.0/24). ).
Inicializamos terraform y creamos redes:
vozerov@mba:~/events/terraform (master) $ terraform init
... skipped ..
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... skipped ...
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
yandex_vpc_network.internal: Creating...
yandex_vpc_network.internal: Creation complete after 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Creating...
yandex_vpc_subnet.internal-b: Creating...
yandex_vpc_subnet.internal-c: Creating...
yandex_vpc_subnet.internal-a: Creation complete after 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Creation complete after 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Still creating... [10s elapsed]
yandex_vpc_subnet.internal-c: Creation complete after 10s [id=b0c2qhsj2vranoc9vhcq]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.¡Excelente! Hemos creado nuestra red y ahora estamos listos para crear nuestros servicios internos.
Creando maquinas virtuales
Para probar la aplicación, nos bastará con crear dos máquinas virtuales - necesitaremos la primera para construir y ejecutar la aplicación, la segunda - para ejecutar kafka, que usaremos para almacenar los mensajes entrantes. Y crearemos otra máquina, donde configuraremos prometheus para monitorear la aplicación.
Las máquinas virtuales se configurarán usando ansible, así que antes de iniciar terraform, asegúrese de tener una de las últimas versiones de ansible. E instale los roles requeridos con ansible galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) is already installed, skipping.
- cloudalchemy-grafana (master) is already installed, skipping.
- sansible.kafka (master) is already installed, skipping.
- sansible.zookeeper (master) is already installed, skipping.
- geerlingguy.docker (master) is already installed, skipping.
vozerov@mba:~/events/ansible (master) $Dentro de la carpeta ansible, hay un archivo de configuración .ansible.cfg de muestra que estoy usando. Quizás útil.
Antes de crear máquinas virtuales, asegúrese de tener ssh-agent ejecutándose y una clave ssh agregada; de lo contrario, terraform no podrá conectarse a las máquinas creadas. Encontré un error en os x, por supuesto: https://github.com/ansible/ansible/issues/32499#issuecomment-341578864 . Para evitar que esta historia se repita, agregue una pequeña variable al env antes de iniciar Terraform:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESCree los recursos necesarios en la carpeta terraform:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Refreshing state... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Refreshing state...
yandex_vpc_subnet.internal-a: Refreshing state... [id=e9b1dad6mgoj2v4funog]
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
... skipped ...
Plan: 3 to add, 0 to change, 0 to destroy.
... skipped ...Si todo terminó bien (y debería serlo), entonces tendremos tres máquinas virtuales:
- build: una máquina para probar y crear una aplicación. Docker fue instalado automáticamente por ansible.
- monitoreo - máquina de monitoreo - prometheus & grafana está instalado en él. El inicio de sesión / contraseña es estándar: admin / admin
- kafka es un automóvil pequeño con kafka instalado, disponible en el puerto 9092.
Asegurémonos de que estén todos en su lugar:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+Los recursos están en su lugar y desde aquí podemos extraer sus direcciones IP. En todas partes a continuación, usaré direcciones IP para conectarme a través de ssh y probar la aplicación. Si tiene una cuenta de cloudflare conectada a terraform, no dude en utilizar los nombres DNS recién creados.
Por cierto, al crear una máquina virtual, se emiten una ip interna y un nombre DNS interno, por lo que puede referirse a los servidores dentro de la red por nombres:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msEsto nos será útil para indicarle a la aplicación un punto final con kafk.
Armar la aplicación
Genial, hay servidores, hay una aplicación, todo lo que queda es recopilarla y publicarla. Para el ensamblaje, usaremos la compilación de docker habitual, pero como almacenamiento de imágenes, tomaremos el servicio de Yandex: el registro de contenedores. Pero lo primero es lo primero.
Copie la aplicación en la máquina de compilación, vaya a ssh y recopile la imagen:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... skipped ...
sent 3849 bytes received 70 bytes 7838.00 bytes/sec
total size is 3644 speedup is 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Sending build context to Docker daemon 6.144kB
Step 1/9 : FROM golang:latest AS build
... skipped ...
Successfully built 9760afd8ef65
Successfully tagged app:latestLa mitad de la batalla ha terminado; ahora puede verificar la funcionalidad de nuestra aplicación ejecutándola y apuntándola a kafka:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092</code>
event :
<code>vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 13:53:54 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":0}
vozerov@mba:~/events (master) $La aplicación respondió con el éxito de la grabación e indicando el id de la partición y el offset, en el que cayó el mensaje. Lo único que hay que hacer es crear un registro en Yandex.Cloud y subir nuestra imagen allí (cómo hacerlo usando tres líneas se describe en el archivo registry.tf). Creamos un repositorio:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... skipped ...
Plan: 1 to add, 0 to change, 0 to destroy.
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Hay varias formas de autenticarse en el registro del contenedor: mediante el token oauth, el token iam o la clave de la cuenta de servicio. Para obtener más información sobre estos métodos, consulte la documentación https://cloud.yandex.ru/docs/container-registry/operations/authentication . Usaremos la clave de la cuenta de servicio, así que creamos una cuenta:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... skipped ...
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.Ahora queda hacer una clave para él:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Obtenemos información sobre la identificación de nuestro almacenamiento, giramos la tecla e iniciamos sesión:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
WARNING! Your password will be stored unencrypted in /home/ubuntu/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
ubuntu@build:~$Para cargar la imagen en el registro, necesitamos el registro del contenedor de ID, lo tomamos de la utilidad yc:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: ACTIVE
created_at: "2020-04-13T13:56:41.914Z"Después de eso, etiquetamos nuestra imagen con un nuevo nombre y cargamos:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
The push refers to repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Pushed
477c318b05cb: Pushed
beee9f30bc1f: Pushed
v1: digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 size: 946Podemos asegurarnos de que la imagen se inicie correctamente:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Por cierto, si instala la utilidad yc en una máquina Linux, puede usar el comando
yc container registry configure-dockerpara la configuración de la ventana acoplable.
Conclusión
Hemos hecho un gran y difícil trabajo y como resultado:
- .
- golang, -.
- container registry.
En la siguiente parte, pasaremos a las cosas interesantes: pondremos nuestra aplicación en producción y finalmente lanzaremos la carga en ella. ¡No cambies!
Este material está en el video del taller abierto REBRAIN & Yandex.Cloud: Aceptamos 10,000 solicitudes por segundo en Yandex Cloud - https://youtu.be/cZLezUm0ekE
Si está interesado en asistir a tales eventos en línea y hacer preguntas en tiempo real, conéctese al canal DevOps por REBRAIN .
Nos gustaría agradecer especialmente a Yandex.Cloud por la oportunidad de realizar un evento de este tipo. Un enlace a ellos es https://cloud.yandex.ru/prices
Si necesita un cambio a la nube o tiene preguntas sobre su infraestructura, no dude en dejar una solicitud .
P.S. 2 , , .