Puedes hacerlo de forma manual, pero también existen frameworks y bibliotecas para ello que hacen que este proceso sea más rápido y sencillo. Hoy hablaremos
de uno de ellos, featuretools , así como de la experiencia práctica de usarlo.

La tubería más de moda
¡Hola! Soy Alexander Loskutov, trabajo en Leroy Merlin como analista de datos o, como está de moda llamarlo ahora, científico de datos. Mis responsabilidades incluyen trabajar con datos, comenzar con consultas analíticas y descargar, terminar con entrenar el modelo, empaquetarlo, por ejemplo, en un servicio, configurar la entrega e implementación del código y monitorear su trabajo.
Deshacer predicción es uno de los productos en los que estoy trabajando.
Objetivo del producto: predecir la probabilidad de que un cliente cancele un pedido en línea. Con la ayuda de tal predicción, podemos determinar a cuál de los clientes que hicieron un pedido se debe llamar primero para pedir que confirme el pedido, y quién no puede ser llamado en absoluto. En primer lugar, el hecho mismo de una llamada y la confirmación de un pedido de un cliente por teléfono reduce la probabilidad de cancelación y, en segundo lugar, si llamamos y la persona se niega, podemos ahorrar recursos. Se liberará más tiempo para los empleados, que habrían dedicado a recoger el pedido. Además, de esta forma el producto quedará en la estantería, y si en ese momento el cliente de la tienda lo necesita, podrá comprarlo. Y esto reducirá la cantidad de productos que se recogieron en pedidos cancelados posteriormente y que no estaban presentes en los estantes.
Precursores
Para el piloto del producto, solo aceptamos pedidos de pospago para recoger en varias tiendas.
Una solución lista para usar funciona así: nos llega un pedido, con la ayuda de Apache NiFi enriquecemos la información, por ejemplo, extrayendo datos sobre mercancías. Luego, todo esto se transfiere a través del corredor de mensajes Apache Kafka al servicio escrito en Python. El servicio calcula las características del pedido y luego se toma un modelo de aprendizaje automático para ellas, lo que da la probabilidad de cancelación. Después de eso, de acuerdo con la lógica comercial, preparamos una respuesta si necesitamos llamar al cliente ahora o no (por ejemplo, si el pedido se realizó con la ayuda de un empleado dentro de la tienda o el pedido se realizó por la noche, entonces no debe llamar).
Al parecer, ¿qué impide llamar a todos seguidos? El hecho es que tenemos una cantidad limitada de recursos para llamadas, por lo que es importante comprender quién debe llamar definitivamente y quién definitivamente recogerá su pedido sin llamar.
Modelo de desarrollo
Estuve involucrado en el servicio, el modelo y, en consecuencia, el cálculo de características para el modelo, que se discutirá más adelante.
Al calcular las características durante el entrenamiento, usamos tres fuentes de datos.
- Placa con metainformación del pedido: número de pedido, marca de tiempo, dispositivo del cliente, método de entrega, método de pago.
- Placa con posiciones en recibos: número de pedido, artículo, precio, cantidad, cantidad de mercancía en stock. Cada posición va en una línea separada.
- Tabla: un libro de referencia de productos: artículo, varios campos con una categoría de productos, unidades de medida, descripción.
Usando métodos estándar de Python y la biblioteca de pandas, puede combinar fácilmente todas las tablas en una grande, después de lo cual, usando groupby, puede calcular todo tipo de atributos como agregados por orden, historial por producto, por categoría de producto, etc. Pero aquí hay varios problemas.
- Paralelismo de cálculos. El groupby estándar funciona en un hilo, y en big data (hasta 10 millones de filas), cien características se consideran inaceptablemente largas, mientras que la capacidad de los núcleos restantes está inactiva.
- La cantidad de código: cada solicitud de este tipo debe escribirse por separado, verificar su exactitud y luego todos los resultados aún deben recopilarse. Esto lleva tiempo, especialmente dada la complejidad de algunos de los cálculos, por ejemplo, calcular el historial más reciente de un artículo en un recibo y agregar estas características para un pedido.
- Puede cometer errores si codifica todo a mano.
La ventaja del enfoque de "escribimos todo a mano" es, por supuesto, una total libertad de acción, puede dar rienda suelta a su imaginación.
Surge la pregunta: ¿cómo se puede optimizar esta parte del trabajo? Una solución es utilizar la biblioteca featuretools .
Aquí ya estamos pasando a la esencia de este artículo, a saber, la biblioteca en sí y la práctica de su uso.
¿Por qué featuretools?
Consideremos varios marcos para el aprendizaje automático en forma de placa (la imagen en sí fue robada honestamente de aquí y lo más probable es que no todos estén indicados allí, pero aún así):
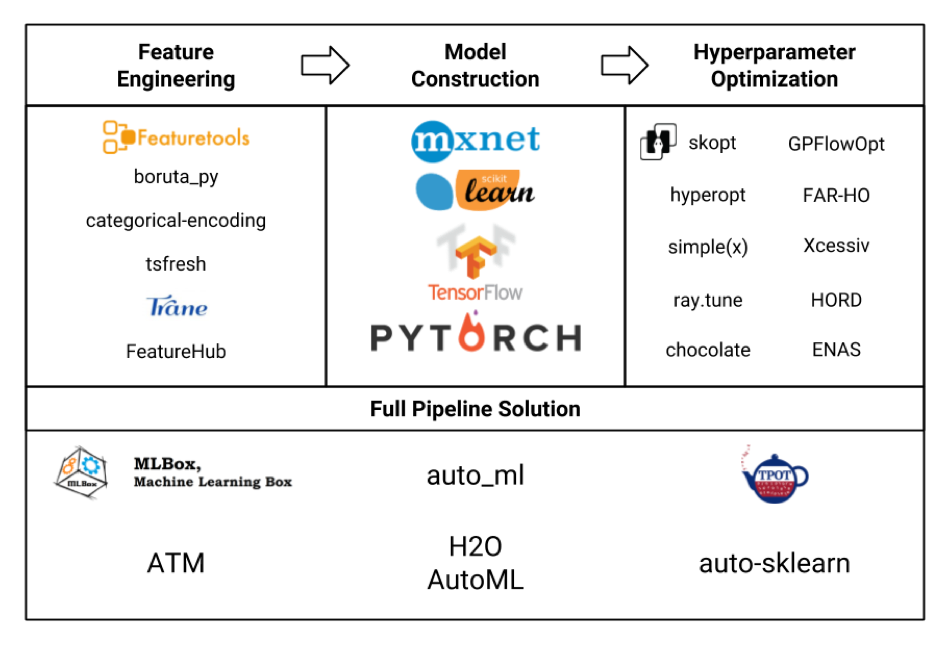
Estamos interesados principalmente en el bloque de ingeniería de características. Si miramos todos estos marcos y paquetes, resulta que featuretools es el más sofisticado de ellos, e incluso incluye la funcionalidad de algunas otras bibliotecas como tsfresh .
Además, las ventajas de las herramientas de funciones (¡sin publicidad!) Incluyen:
- computación paralela lista para usar
- disponibilidad de muchas funciones listas para usar
- flexibilidad en la personalización: se pueden considerar cosas bastante complejas
- contabilidad de las relaciones entre diferentes tablas (relacional)
- menos código
- menos probabilidades de cometer un error
- por sí solo, todo es gratis, sin registro y SMS (pero con pypi)
Pero no es tan simple.
- El marco requiere algo de aprendizaje, y el dominio completo llevará una cantidad de tiempo decente.
- No tiene una comunidad tan grande, aunque las preguntas más populares todavía están bien en Google.
- El uso en sí también requiere cuidado para no inflar el espacio de funciones innecesariamente y no aumentar el tiempo de cálculo.
Formación
Daré un ejemplo de la configuración de featuretools.
A continuación, habrá un código con breves explicaciones, con más detalle sobre featuretools, sus clases, métodos, capacidades, que puede leer, incluso en la documentación en el sitio web del framework. Si está interesado en ejemplos de aplicación práctica con una demostración de algunas posibilidades interesantes en tareas reales, escriba en los comentarios, tal vez escriba un artículo por separado.
Entonces.
Primero, necesita crear un objeto de la clase EntitySet, que contiene tablas con datos y conoce su relación entre sí.
Permíteme recordarte que tenemos tres tablas con datos:
- orders_meta (metainformación del pedido)
- orders_items_lists (información sobre artículos en pedidos)
- artículos (referencia de artículos y sus propiedades)
Escribimos (además, se utilizan los datos de solo 3 tiendas):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

¡Hurra! Ahora tenemos un objeto que nos permitirá contar todo tipo de signos.
Daré un código para calcular características bastante simples: para cada pedido, calcularemos varias estadísticas sobre precios y cantidad de bienes, así como un par de características por tiempo y los productos y categorías de bienes más frecuentes en el pedido (las funciones que realizan diversas transformaciones con datos se denominan primitivas en las herramientas de características) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)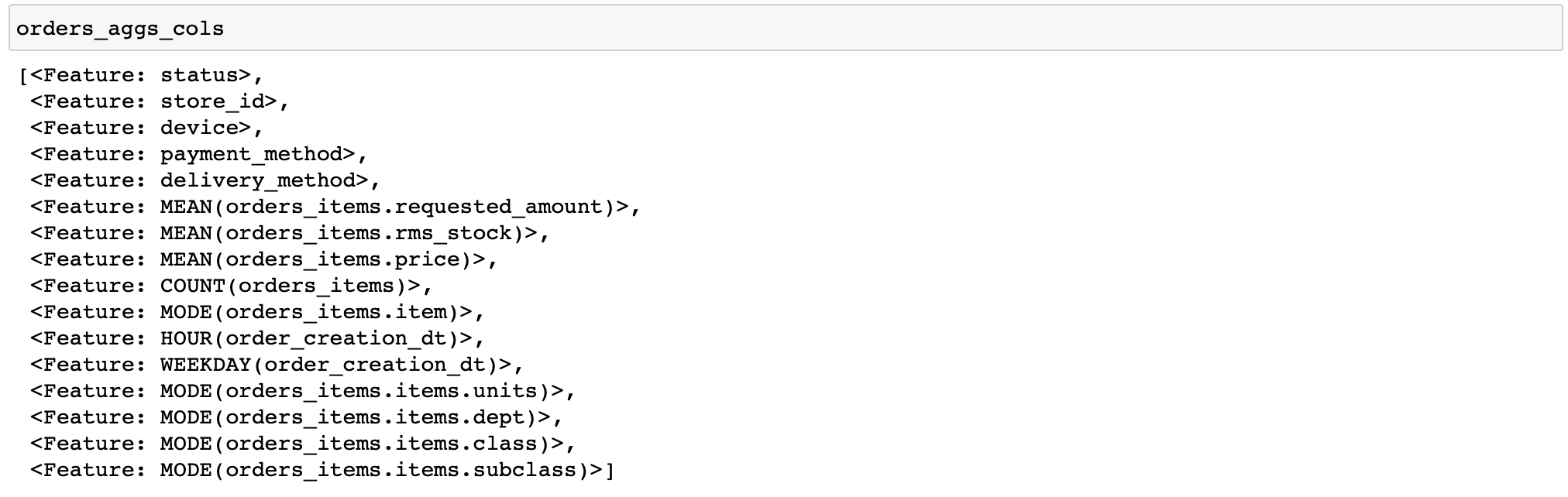

No hay columnas booleanas en las tablas aquí, por lo que no se aplicó la primitiva any. En general, es conveniente que featuretools analice el tipo de datos y aplique solo las funciones apropiadas.
Además, especifiqué manualmente solo algunos pedidos para el cálculo. Esto le permite depurar rápidamente sus cálculos (qué sucede si configuró algo mal).
Ahora agreguemos algunos agregados más a nuestras características, a saber, percentiles. Pero las herramientas de características no tienen primitivas integradas para calcularlas. Por lo tanto, debe escribirlo usted mismo.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
Y agréguelos al cálculo:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Entonces todo es igual. Hasta ahora, todo es bastante simple y fácil (relativamente, por supuesto).
¿Qué pasa si queremos guardar nuestra calculadora de características y usarla en la etapa de ejecución del modelo, es decir, en el servicio?
Herramientas destacadas en combate
Aquí es donde comienzan las principales dificultades.
Para calcular las características de un pedido entrante, deberá realizar todas las operaciones con la creación del EntitySet nuevamente. Y si para tablas grandes arrojar objetos pandas.DataFrame en EntitySet parece bastante normal, entonces realizar operaciones similares para DataFrames desde una fila (hay más de ellos en la tabla con cheques, pero en promedio 3.3 posiciones por cheque, es decir, no es suficiente) - no mucho. Después de todo, la creación de tales objetos y cálculos con su ayuda inevitablemente contienen una sobrecarga, es decir, un número inamovible de operaciones necesarias, por ejemplo, para la asignación de memoria y la inicialización al crear un objeto de cualquier tamaño o el proceso de paralelización en sí mismo al calcular varias características simultáneamente.
Por lo tanto, en el modo de operación "un pedido a la vez" en las herramientas de características de nuestro producto no se muestra la mejor eficiencia, tomando en promedio el 75% del tiempo de respuesta del servicio (en promedio 150-200 ms dependiendo del hardware). A modo de comparación: calcular una predicción usando catboost en funciones listas para usar toma el 3% del tiempo de respuesta del servicio, es decir, no más de 10 ms.
Además, existe otro problema asociado con el uso de primitivas personalizadas. El hecho es que no podemos simplemente guardar en escabeche un objeto de la clase que contiene las primitivas que hemos creado, ya que estos últimos no están en escabeche.
Entonces, ¿por qué no usar la función save_features () incorporada, que puede guardar una lista de objetos FeatureBase, incluidas las primitivas que creamos?
Los guardará, pero no será posible leerlos luego usando la función load_features () si no los volvemos a crear con anticipación. Es decir, las primitivas que, en teoría, deberíamos leer del disco, las volvemos a crear primero, para no volver a utilizarlas nunca más.
Se parece a esto:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorEn la función load (), debe crear primitivas (declarando la variable custom_primitives) que no se utilizarán. Pero sin esto, la carga de funciones adicionales en el lugar donde se llama a la función load_features () fallará con el RuntimeError: Primitive "percentile05" en el módulo "featuretools.primitives.base.aggregation_primitive_base" no encontrado .
No resulta muy lógico, pero funciona, y puede guardar tanto la calculadora ya vinculada a un determinado formato de datos (ya que las características están vinculadas al EntitySet para el que fueron calculadas, aunque sin los valores en sí), y la calculadora solo con una lista dada de primitivas.
Quizás en el futuro esto se corrija y sea posible guardar convenientemente un conjunto arbitrario de objetos FeatureBase.
Entonces, ¿por qué lo usamos?
Porque desde el punto de vista del tiempo de desarrollo, es barato, mientras que el tiempo de respuesta bajo la carga existente se ajusta a nuestro SLA (5 segundos) con un margen.
Sin embargo, debe tener en cuenta que para un servicio que debe responder rápidamente a las solicitudes recibidas con frecuencia, el uso de herramientas de funciones sin "okupas" adicionales, como las llamadas asincrónicas, será problemático.
Esta es nuestra experiencia en el uso de herramientas de funciones en las etapas de aprendizaje e inferencia.
Este marco es muy bueno como herramienta para calcular rápidamente una gran cantidad de funciones para entrenamiento, reduce en gran medida el tiempo de desarrollo y reduce la probabilidad de errores.
Si usarlo en la etapa de retiro depende de sus tareas.