
Resolver problemas de ciencia de datos en Python no es fácil
¿Por qué? Las herramientas existentes no son adecuadas para resolver problemas relacionados con series de tiempo y estas herramientas son difíciles de integrar entre sí. Los métodos de Scikit-learn asumen que los datos están estructurados en un formato tabular y que cada columna consta de variables aleatorias independientes e igualmente distribuidas, suposiciones que no tienen nada que ver con los datos de series de tiempo. Los paquetes que tienen módulos para aprendizaje automático y funcionan con series de tiempo, como statsmodels , no son muy buenos amigos entre sí. Además, muchas operaciones importantes con series de tiempo, como la división de datos en conjuntos de entrenamiento y prueba en intervalos de tiempo, no están disponibles en los paquetes existentes.
Para resolver problemas similares, se creó sktime .

Logotipo de la biblioteca Sktime en GitHub
Sktime es un kit de herramientas de aprendizaje automático de código abierto en Python diseñado específicamente para trabajar con series de tiempo. Este proyecto es desarrollado y financiado por la comunidad por el British Council for Economic and Social Research , Consumer Data Research y el Alan Turing Institute .
Sktime amplía la API de scikit-learn para resolver problemas de series de tiempo. Contiene todos los algoritmos y herramientas de transformación necesarios para resolver de manera eficiente problemas de regresión, previsión y clasificación de series de tiempo. La biblioteca incluye algoritmos especiales de aprendizaje automático y métodos de transformación para series de tiempo que no se encuentran en otras bibliotecas populares.
Sktime fue diseñado para trabajar con scikit-learn, adaptar fácilmente algoritmos para problemas de series de tiempo interrelacionados y construir modelos complejos. ¿Cómo funciona? Muchos problemas de series de tiempo están relacionados entre sí de una forma u otra. Un algoritmo que se puede utilizar para resolver un problema a menudo se puede aplicar para resolver otro relacionado con él. Esta idea se llama reducción. Por ejemplo, un modelo para la regresión de series de tiempo (que usa una serie para predecir un valor de salida) se puede reutilizar para un problema de predicción de series de tiempo (que predice un valor de salida, un valor que se recibirá en el futuro).
La idea principal del proyecto:“Sktime ofrece aprendizaje automático integrable y fácil de entender mediante series de tiempo. Tiene algoritmos que son compatibles con scikit-learn y herramientas para compartir modelos, respaldados por una taxonomía clara de tareas de aprendizaje, documentación clara y una comunidad amigable ".
En este artículo, destacaré algunas de las características únicas de sktime .
Modelo de datos correcto para series de tiempo
Sktime utiliza una estructura de datos anidada para series de tiempo en forma de marcos de datos de pandas .
Cada línea en un marco de datos típico contiene variables aleatorias independientes e igualmente distribuidas (casos y columnas) variables diferentes. Para los métodos sktime, cada celda en un marco de datos de Pandas ahora puede contener una serie de tiempo completa. Este formato es flexible para datos multidimensionales, de panel y heterogéneos y permite la reutilización de métodos tanto en Pandas como en scikit-learn .
En la siguiente tabla, cada fila es una observación que contiene una matriz de series de tiempo en la columna X y un valor de clase en la columna Y. Los evaluadores y transformadores de sktime son expertos en trabajar con tales series de tiempo.
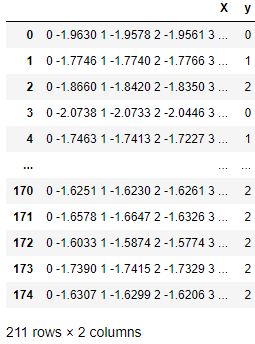
Una estructura de datos de series temporales nativa compatible con sktime.
En la siguiente tabla, cada elemento de la serie X se ha movido a una columna separada según lo requieren los métodos de scikit-learn. La dimensión es bastante alta: ¡251 columnas! Además, los algoritmos de aprendizaje que trabajan con valores tabulares ignoran la ordenación temporal de las columnas (pero que se utilizan en los algoritmos de regresión y clasificación de series temporales).
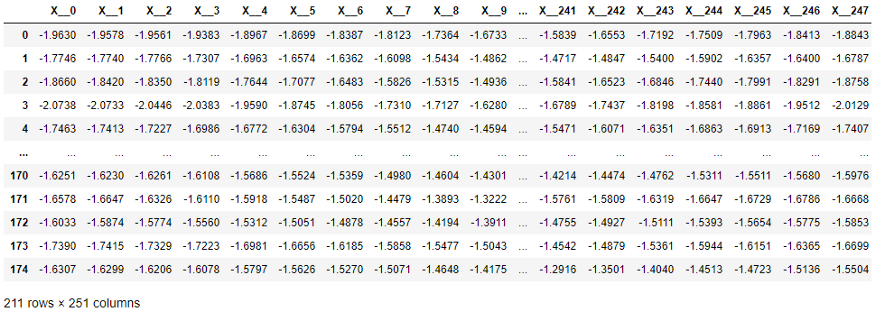
Estructura de datos de series de tiempo requerida por scikit-learn.
Para tareas de modelado de varias series conjuntas, lo ideal es una estructura de datos de series de tiempo nativa que sea compatible con sktime . Los modelos entrenados en los datos tabulares esperados por scikit-learn se empantanarán en muchas características.
¿Qué puede hacer sktime ?
Según la página de GitHub , sktime actualmente proporciona las siguientes capacidades:
- Algoritmos modernos para la clasificación de series de tiempo, el análisis de regresión y la previsión (trasladados del kit
tsmlde herramientas a Java); - Transformadores de series de tiempo: transformaciones de series únicas (por ejemplo, destrending o deseasonización), transformaciones de series como características (por ejemplo, extracción de características) y herramientas para compartir múltiples transformadores.
- Tuberías para transformadores y modelos;
- Configuración del modelo;
- Conjunto de modelos, por ejemplo, bosque aleatorio totalmente personalizable para clasificación y regresión de series de tiempo, conjunto para problemas multidimensionales.
API sktime
Como se mencionó anteriormente, sktime compatible con la API básica scikit-learn métodos de clases
fit, predicty transform.
Para las clases (o modelos) del evaluador , sktime proporciona un método
fitpara entrenar el modelo y un método predictpara generar nuevas predicciones.
Los evaluadores sktime amplían los regresores y clasificadores de scikit-learn al proporcionar series de tiempo análogas a estos métodos.
Para las clases, sktime transformer proporciona métodos
fity transformpara convertir los datos en serie. Hay varios tipos de transformaciones disponibles:
- , , ;
- , (, );
- (, );
- , , , (, ).
El siguiente ejemplo es una adaptación de la guía de pronóstico de GitHub . La serie de este ejemplo (el conjunto de datos de la aerolínea Box-Jenkins) muestra el número de pasajeros de aviones internacionales por mes desde 1949 hasta 1960.
Primero, cargue los datos y divídalos en conjuntos de pruebas y entrenamiento, y haga un gráfico. En sktime tiene dos funciones convenientes para una fácil ejecución de estas tareas,
temporal_train_test_splitforque están separadas por un conjunto de datos y tiempo plot_ys, trazados sobre la base de la prueba y la muestra de entrenamiento.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])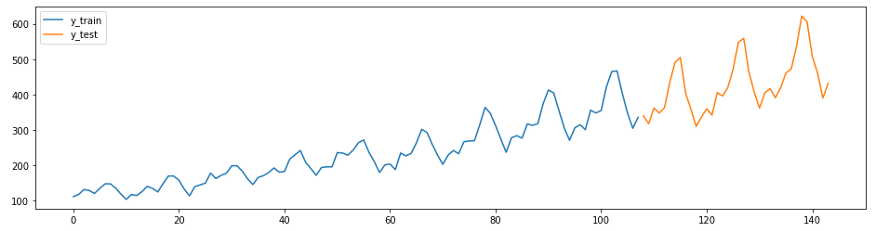
Antes de realizar pronósticos complejos, es útil comparar su pronóstico con los valores obtenidos utilizando algoritmos bayesianos ingenuos. Un buen modelo debería superar estos valores. En sktime tenemos un método
NaiveForecastercon diferentes estrategias para crear proyecciones de línea base.
El código y el diagrama a continuación muestran dos predicciones ingenuas. El pronosticador c
strategy = “last”siempre predecirá el último valor de la serie.
El
strategy = “seasonal_last”pronosticador s predice el último valor de la serie para la temporada dada. La estacionalidad en el ejemplo se establece como “sp=12”, es decir, 12 meses.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957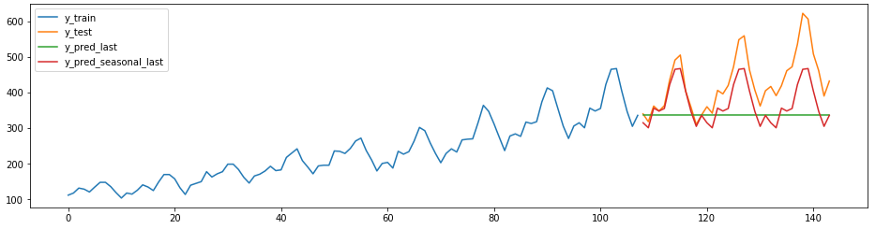
El siguiente fragmento de predicción muestra cómo los regresores sklearn existentes pueden adaptarse de manera fácil, correcta y con un esfuerzo mínimo para las tareas de predicción. A continuación se muestra un método
ReducedRegressionForecasterde sktime que predice una serie usando un modelo sklearnRandomForestRegressor. Bajo el capó, sktime divide los datos de entrenamiento en ventanas de 12 para que el regresor pueda continuar entrenando.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)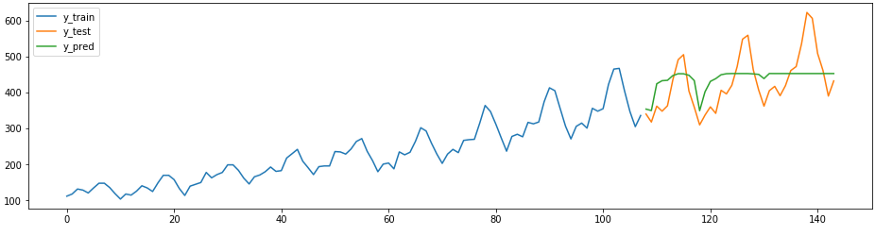
En sktime también tienen sus propios métodos de previsión, por ejemplo
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469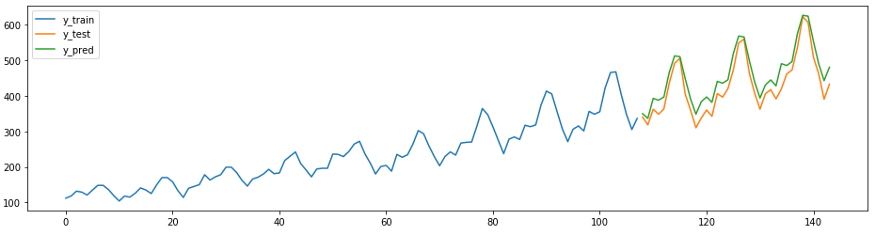
Para profundizar en la funcionalidad de pronóstico de sktime , consulte el tutorial aquí .
Clasificación de series de tiempo
También
sktimese puede utilizar para clasificar series de tiempo en diferentes grupos.
En el ejemplo de código a continuación, la clasificación de series temporales únicas es tan fácil como la clasificación en scikit-learn. La única diferencia es la estructura de datos de series de tiempo anidadas de la que hablamos anteriormente.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868El ejemplo se tomó de pypi.org/project/sktime. Los
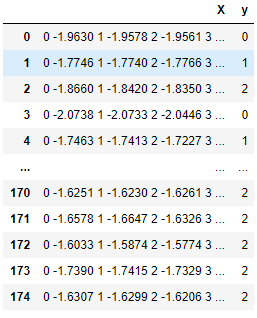
datos pasaron a TimeSeriesForestClassifier.
Para obtener más información sobre la clasificación de series, consulte los tutoriales de clasificación univariante y multidimensional de sktime .
Recursos adicionales de sktime
Para obtener más información sobre Sktime, consulte los siguientes enlaces para obtener documentación y ejemplos.
- Descripción detallada de la API: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .