
En el mundo moderno de Big Data, Apache Spark es el estándar de facto para desarrollar tareas de procesamiento de datos por lotes. Además, también se utiliza para crear aplicaciones de transmisión que operan en el concepto de micro lotes, procesando y enviando datos en pequeñas porciones (Spark Structured Streaming). Y tradicionalmente ha sido parte de la pila general de Hadoop, utilizando YARN (o, en algunos casos, Apache Mesos) como administrador de recursos. Para 2020, su uso tradicional para la mayoría de las empresas está en duda debido a la falta de distribuciones decentes de Hadoop: el desarrollo de HDP y CDH se detuvo, CDH está subdesarrollado y tiene un alto costo, y el resto de los proveedores de Hadoop dejaron de existir o tienen un futuro vago.Por lo tanto, el creciente interés entre la comunidad y las grandes empresas es el lanzamiento de Apache Spark usando Kubernetes, convirtiéndose en el estándar en la orquestación de contenedores y la gestión de recursos en nubes públicas y privadas, resuelve el problema de la programación de recursos inconvenientes de las tareas de Spark en YARN y proporciona una plataforma en constante desarrollo con muchos y distribuciones de código abierto para empresas de todos los tamaños y tipos. Además, en la ola de popularidad, la mayoría ya ha logrado adquirir un par de sus instalaciones y aumentar su experiencia en su uso, lo que simplifica el movimiento.resuelve la incómoda programación de las tareas de Spark en YARN y proporciona una plataforma en constante evolución con muchas distribuciones comerciales y de código abierto para empresas de todos los tamaños y tipos. Además, en la ola de popularidad, la mayoría ya ha logrado adquirir un par de sus instalaciones y aumentar su experiencia en su uso, lo que simplifica el movimiento.resuelve la incómoda programación de recursos de las tareas de Spark en YARN y proporciona una plataforma sólida con muchas distribuciones comerciales y de código abierto para empresas de todos los tamaños y tipos. Además, en la ola de popularidad, la mayoría ya ha logrado adquirir un par de sus instalaciones y aumentar su experiencia en su uso, lo que simplifica el movimiento.
A partir de la versión 2.3.0, Apache Spark adquirió soporte oficial para ejecutar tareas en el clúster de Kubernetes y hoy hablaremos sobre la madurez actual de este enfoque, varios casos de uso y dificultades que se encontrarán durante la implementación.
En primer lugar, consideraremos el proceso de desarrollo de tareas y aplicaciones basadas en Apache Spark y destacaremos los casos típicos en los que necesita ejecutar una tarea en un clúster de Kubernetes. Al preparar esta publicación, OpenShift se utiliza como un kit de distribución y se darán los comandos que son relevantes para su utilidad de línea de comandos (oc). Para otras distribuciones de Kubernetes, se pueden usar los comandos correspondientes de la utilidad de línea de comandos estándar de Kubernetes (kubectl) o sus análogos (por ejemplo, para la política oc adm).
El primer caso de uso es Spark-Submit
En el proceso de desarrollo de tareas y aplicaciones, el desarrollador necesita ejecutar tareas para depurar la transformación de datos. En teoría, los stubs pueden usarse para estos propósitos, pero el desarrollo con la participación de instancias reales (aunque de prueba) de sistemas finitos se ha mostrado en esta clase de tareas más rápido y mejor. En el caso de que depuramos en instancias reales de sistemas finales, son posibles dos escenarios:
- el desarrollador ejecuta la tarea Spark localmente en modo autónomo;
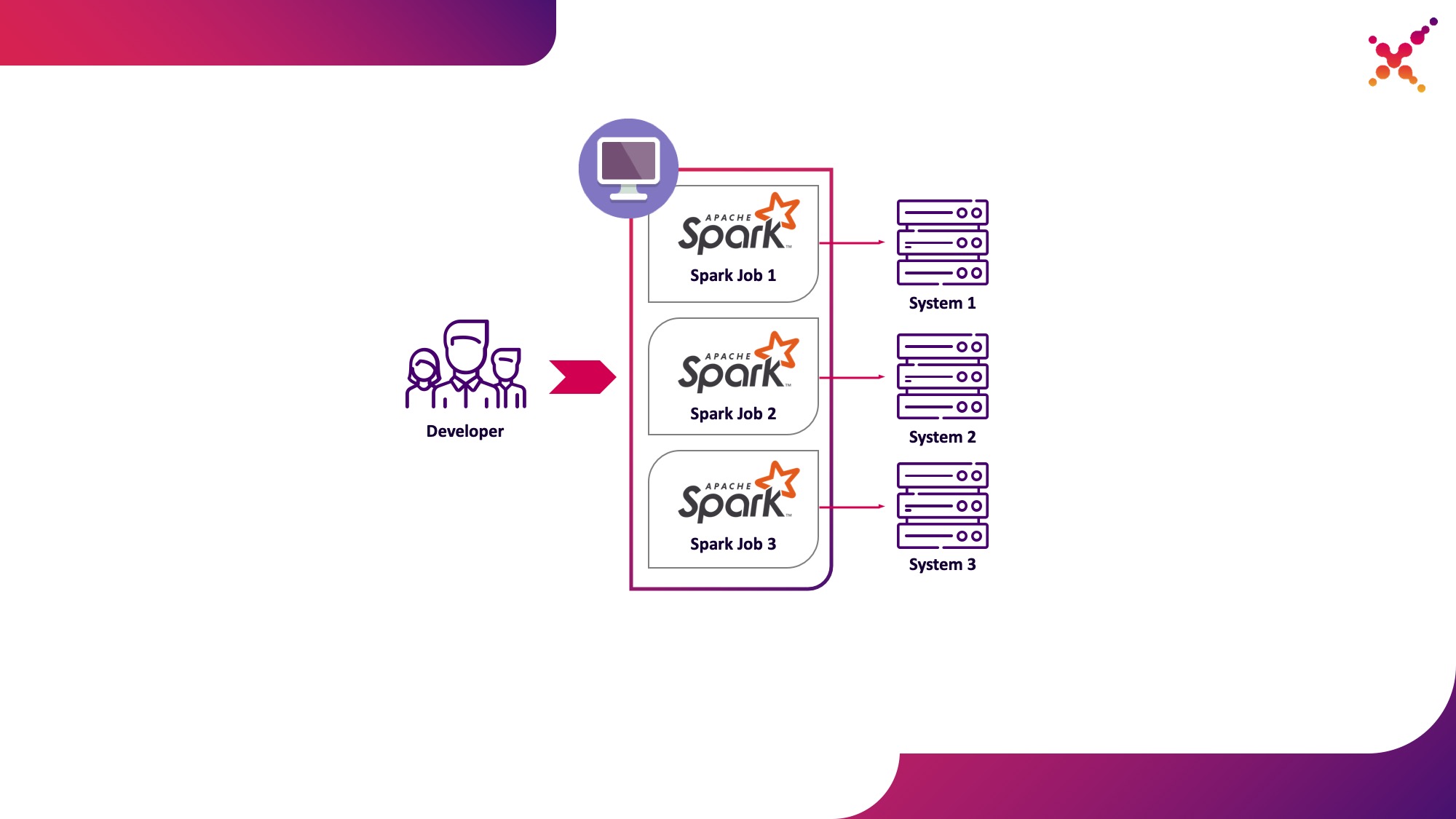
- un desarrollador ejecuta una tarea de Spark en un clúster de Kubernetes en un ciclo de prueba.

La primera opción tiene derecho a existir, pero conlleva una serie de desventajas:
- para cada desarrollador se requiere proporcionar acceso desde el lugar de trabajo a todas las copias de los sistemas finales que necesita;
- la máquina en funcionamiento requiere recursos suficientes para ejecutar la tarea desarrollada.
La segunda opción carece de estas desventajas, ya que el uso de un clúster de Kubernetes le permite asignar el grupo de recursos necesario para ejecutar tareas y proporcionarle el acceso necesario a las instancias de los sistemas finales, brindándole acceso de manera flexible utilizando el modelo de rol de Kubernetes para todos los miembros del equipo de desarrollo. Destaquémoslo como el primer caso de uso: ejecutar tareas de Spark desde una máquina de desarrollo local en un clúster de Kubernetes en un ciclo de prueba.
Echemos un vistazo más de cerca al proceso de configuración de Spark para que se ejecute localmente. Para comenzar a usar Spark, debe instalarlo:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Recopilamos los paquetes necesarios para trabajar con Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
La compilación completa lleva mucho tiempo, y para compilar imágenes de Docker y ejecutarlas en el clúster de Kubernetes, en realidad, solo necesita archivos jar del directorio "assembly /", por lo que solo puede compilar este subproyecto:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Para ejecutar tareas de Spark en Kubernetes, debe crear una imagen de Docker para usarla como imagen base. Aquí son posibles 2 enfoques:
- La imagen de Docker generada incluye el código ejecutable para la tarea Spark;
- La imagen creada incluye solo Spark y las dependencias necesarias, el código ejecutable está alojado de forma remota (por ejemplo, en HDFS).
Primero, creemos una imagen de Docker que contenga un ejemplo de prueba de una tarea de Spark. Para crear imágenes de Docker, Spark tiene una herramienta llamada "docker-image-tool". Estudiemos la ayuda al respecto:
./bin/docker-image-tool.sh --help
Se puede usar para crear imágenes de Docker y subirlas a registros remotos, pero por defecto tiene varias desventajas:
- sin falta crea 3 imágenes de Docker a la vez: para Spark, PySpark y R;
- no le permite especificar el nombre de la imagen.
Por lo tanto, usaremos una versión modificada de esta utilidad, que se muestra a continuación:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Usándolo, creamos una imagen base de Spark que contiene una tarea de prueba para calcular el número de Pi usando Spark (aquí {docker-registry-url} es la URL de su registro de imágenes de Docker, {repo} es el nombre del repositorio dentro del registro, que coincide con el proyecto en OpenShift , {image-name} es el nombre de la imagen (si se usa la separación de imágenes de tres niveles, por ejemplo, como en el registro de imágenes integrado de Red Hat OpenShift), {tag} es la etiqueta de esta versión de la imagen):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Inicie sesión en el clúster de OKD mediante la utilidad de la consola (aquí, {OKD-API-URL} es la URL de la API del clúster de OKD):
oc login {OKD-API-URL}
Consigamos el token del usuario actual para la autorización en el Registro de Docker:
oc whoami -t
Inicie sesión en el Docker Registry interno del clúster OKD (use el token obtenido con el comando anterior como contraseña):
docker login {docker-registry-url}
Sube la imagen de Docker construida al OKD de Docker Registry:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Comprobemos que la imagen ensamblada está disponible en OKD. Para hacer esto, abra una URL con una lista de imágenes del proyecto correspondiente en el navegador (aquí {proyecto} es el nombre del proyecto dentro del clúster de OpenShift, {OKD-WEBUI-URL} es la URL de la consola web de OpenShift) - https: // {OKD-WEBUI-URL} / console / proyecto / {proyecto} / navegar / imágenes / {nombre-imagen}.
Para ejecutar tareas, se debe crear una cuenta de servicio con los privilegios de ejecutar pods como root (discutiremos este punto más adelante):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Ejecute el comando spark-submit para publicar la tarea Spark en el clúster de OKD, especificando la cuenta de servicio creada y la imagen de Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Aquí:
--name es el nombre de la tarea que participará en la formación del nombre de los pods de Kubernetes;
--clase: la clase del archivo ejecutable llamado cuando se inicia la tarea;
--conf - Parámetros de configuración de Spark;
spark.executor.instances El número de ejecutores de Spark que se ejecutarán.
spark.kubernetes.authenticate.driver.serviceAccountName: el nombre de la cuenta de servicio de Kubernetes que se usa al lanzar pods (para definir el contexto de seguridad y las capacidades al interactuar con la API de Kubernetes);
spark.kubernetes.namespace: espacio de nombres de Kubernetes en el que se ejecutarán los pods de controlador y ejecutor;
spark.submit.deployMode: método de lanzamiento de Spark ("clúster" se usa para el envío de chispa estándar, "cliente" para Spark Operator y versiones posteriores de Spark);
spark.kubernetes.container.image La imagen de Docker utilizada para ejecutar los pods.
spark.master: URL de la API de Kubernetes (la externa se especifica para que la llamada se produzca desde la máquina local);
local: // es la ruta al ejecutable de Spark dentro de la imagen de Docker.
Vaya al proyecto OKD correspondiente y estudie los pods creados: https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
Para simplificar el proceso de desarrollo, se puede usar otra opción, en la que se crea una imagen de Spark base común que es utilizada por todas las tareas para ejecutar, y las instantáneas de los archivos ejecutables se publican en un almacenamiento externo (por ejemplo, Hadoop) y se especifican al llamar a Spark-submit como un enlace. En este caso, puede ejecutar diferentes versiones de las tareas de Spark sin reconstruir las imágenes de Docker, utilizando, por ejemplo, WebHDFS para publicar imágenes. Enviamos una solicitud para crear un archivo (aquí, {host} es el host del servicio WebHDFS, {port} es el puerto del servicio WebHDFS, {path-to-file-on-hdfs} es la ruta deseada al archivo en HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
Esto recibirá una respuesta del formulario (aquí {ubicación} es la URL que se debe utilizar para descargar el archivo):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Cargue el ejecutable Spark en HDFS (aquí, {path-to-local-file} es la ruta al ejecutable Spark en el host actual):
curl -i -X PUT -T {path-to-local-file} "{location}"
Después de eso, podemos hacer Spark-submit usando el archivo Spark cargado en HDFS (aquí, {class-name} es el nombre de la clase que debe iniciarse para completar la tarea):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Cabe señalar que para acceder a HDFS y garantizar el funcionamiento de la tarea, es posible que deba cambiar el archivo Dockerfile y el script entrypoint.sh; agregue una directiva al Dockerfile para copiar las bibliotecas dependientes al directorio / opt / spark / jars e incluya el archivo de configuración HDFS en SPARK_CLASSPATH en el punto de entrada. sh.
Segundo caso de uso: Apache Livy
Además, cuando se desarrolla la tarea y se requiere probar el resultado obtenido, surge la pregunta de lanzarla dentro del proceso CI / CD y rastrear el estado de su ejecución. Por supuesto, puede ejecutarlo con una llamada de envío de chispa local, pero esto complica la infraestructura de CI / CD, ya que requiere instalar y configurar Spark en los agentes / ejecutores del servidor de CI y configurar el acceso a la API de Kubernetes. Para este caso, la implementación de destino ha optado por utilizar Apache Livy como la API REST para ejecutar tareas de Spark alojadas dentro del clúster de Kubernetes. Con su ayuda, puede ejecutar tareas de Spark en un clúster de Kubernetes mediante solicitudes cURL regulares, que se implementan fácilmente en función de cualquier solución de CI, y su ubicación dentro de un clúster de Kubernetes resuelve el problema de autenticación al interactuar con la API de Kubernetes.
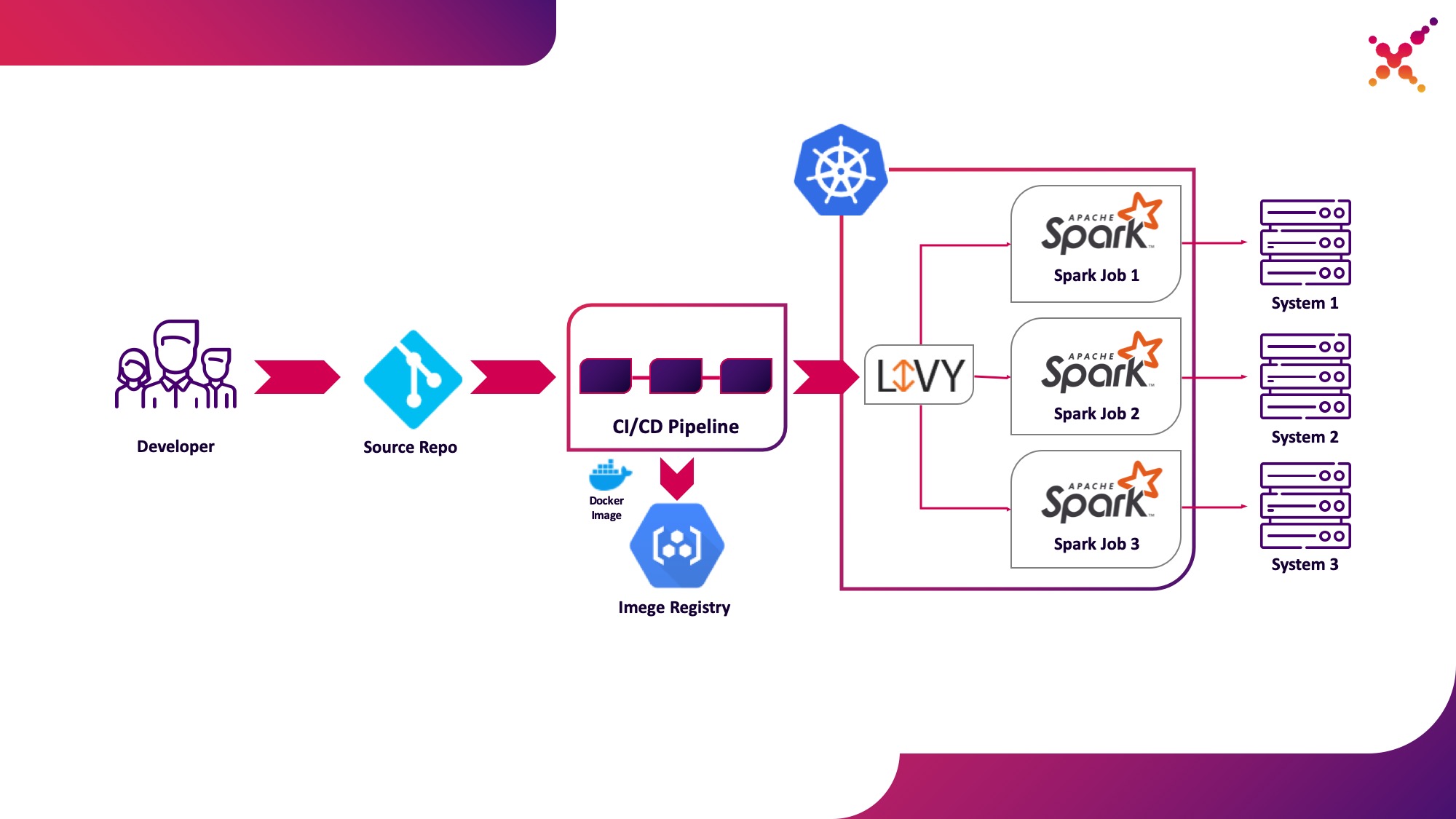
Destaquémoslo como el segundo caso de uso: ejecutar tareas de Spark como parte del proceso de CI / CD en un clúster de Kubernetes en un ciclo de prueba.
Un poco sobre Apache Livy: funciona como un servidor HTTP que proporciona una interfaz web y una API RESTful que le permite ejecutar spark-submit de forma remota pasando los parámetros necesarios. Tradicionalmente, se enviaba como parte de la distribución HDP, pero también se puede implementar en OKD o en cualquier otra instalación de Kubernetes utilizando el manifiesto apropiado y un conjunto de imágenes de Docker, como esta: github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . Para nuestro caso, se creó una imagen de Docker similar, incluida Spark versión 2.4.5 del siguiente Dockerfile:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
La imagen generada se puede crear y cargar en su repositorio de Docker existente, como el repositorio interno de OKD. Para implementarlo, se utiliza el siguiente manifiesto ({registration-url} es la URL del registro de imágenes de Docker, {image-name} es el nombre de la imagen de Docker, {tag} es la etiqueta de la imagen de Docker, {livy-url} es la URL deseada en la que estará disponible el servidor Livy; el manifiesto de "Ruta" se utiliza si se utiliza Red Hat OpenShift como distribución de Kubernetes; de lo contrario, se utiliza el manifiesto de servicio o Ingress correspondiente de tipo NodePort):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Después de su aplicación y el lanzamiento exitoso del pod, la interfaz gráfica de Livy está disponible en el enlace: http: // {livy-url} / ui. Con Livy, podemos publicar nuestra tarea Spark mediante una solicitud REST, por ejemplo, de Postman. A continuación se presenta un ejemplo de una colección con solicitudes (en la matriz "args", se pueden pasar argumentos de configuración con variables necesarias para que la tarea en ejecución funcione):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Ejecutemos la primera solicitud de la colección, vayamos a la interfaz de OKD y verifiquemos que la tarea se haya iniciado correctamente: https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. En este caso, aparecerá una sesión en la interfaz de Livy (http: // {livy-url} / ui), dentro de la cual, utilizando la API de Livy o la interfaz gráfica, puede seguir el progreso de la tarea y estudiar los registros de sesión.
Ahora mostremos cómo funciona Livy. Para hacer esto, examinemos los registros del contenedor Livy dentro del pod con el servidor Livy: https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}? Tab = logs. A partir de ellos, puede ver que cuando se llama a la API REST de Livy en un contenedor llamado "livy", se ejecuta un envío de chispa similar al que usamos anteriormente (aquí {livy-pod-name} es el nombre del pod creado con el servidor Livy). La colección también proporciona una segunda solicitud que le permite ejecutar tareas con alojamiento remoto del ejecutable Spark utilizando el servidor Livy.
Tercer caso de uso: operador Spark
Ahora que la tarea se ha probado, surge la cuestión de ejecutarla con regularidad. La forma nativa de ejecutar tareas regularmente en el clúster de Kubernetes es la entidad CronJob y puede usarla, pero por el momento, el uso de operadores para controlar aplicaciones en Kubernetes es muy popular, y para Spark hay un operador bastante maduro, que, entre otras cosas, se usa en soluciones de nivel empresarial. (por ejemplo, Lightbend FastData Platform). Recomendamos usarlo: la versión estable actual de Spark (2.4.5) tiene opciones bastante limitadas para configurar el lanzamiento de tareas de Spark en Kubernetes, mientras que en la próxima versión principal (3.0.0) se anuncia el soporte completo para Kubernetes, pero su fecha de lanzamiento sigue siendo desconocida. Spark Operator compensa esta deficiencia agregando importantes opciones de configuración (por ejemplo,montaje de ConfigMap con configuración de acceso a Hadoop en Spark pods) y la capacidad de ejecutar la tarea con regularidad en un horario.
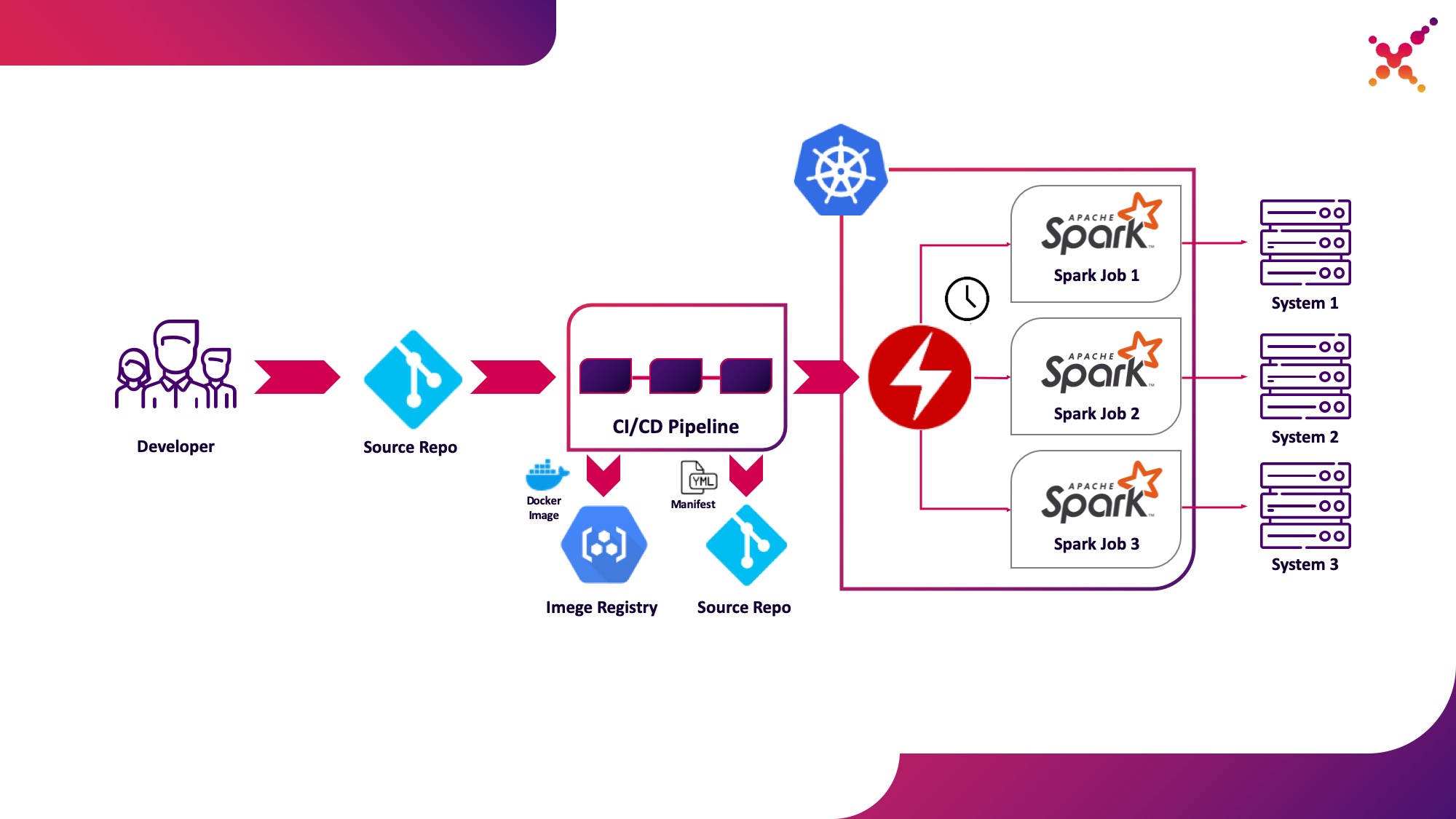
Destaquémoslo como el tercer caso de uso: ejecutar regularmente tareas de Spark en un clúster de Kubernetes en un ciclo de producción.
Spark Operator es de código abierto y se desarrolló bajo Google Cloud Platform: github.com/GoogleCloudPlatform/spark-on-k8s-operator . Su instalación se puede realizar de 3 formas:
- Como parte de la instalación de Lightbend FastData Platform / Cloudflow;
- Con Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Si el operador está configurado correctamente, aparecerá un pod activo con el operador Spark (por ejemplo, cloudflow-fdp-sparkoperator en el espacio de Cloudflow para instalar Cloudflow) en el proyecto correspondiente y aparecerá el tipo de recurso de Kubernetes correspondiente llamado "sparkapplications". Puede examinar las aplicaciones Spark disponibles con el siguiente comando:
oc get sparkapplications -n {project}
Para ejecutar tareas con Spark Operator, debe hacer 3 cosas:
- Cree una imagen de Docker que incluya todas las bibliotecas necesarias, así como los archivos ejecutables y de configuración. En la imagen de destino, esta es una imagen creada en la etapa CI / CD y probada en un grupo de prueba;
- publicar la imagen de Docker en el registro accesible desde el clúster de Kubernetes;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- el diccionario "spec.sparkVersion" debe indicar la versión de Spark utilizada;
- el diccionario "spec.driver.serviceAccount" debe contener una cuenta de servicio dentro del espacio de nombres de Kubernetes apropiado que se utilizará para iniciar la aplicación;
- el diccionario "spec.executor" debe indicar la cantidad de recursos asignados a la aplicación;
- el diccionario "spec.volumeMounts" debe especificar el directorio local en el que se crearán los archivos de tareas de Spark locales.
Un ejemplo de cómo generar un manifiesto (aquí, {spark-service-account} es una cuenta de servicio dentro del clúster de Kubernetes para ejecutar tareas de Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Este manifiesto especifica una cuenta de servicio para la cual, antes de publicar el manifiesto, debes crear los enlaces de roles necesarios que brinden los derechos de acceso necesarios para que la aplicación Spark interactúe con la API de Kubernetes (si es necesario). En nuestro caso, la aplicación necesita los derechos para crear Pods. Creemos el enlace de roles requerido:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
También vale la pena señalar que la especificación de este manifiesto puede especificar el parámetro "hadoopConfigMap", que le permite especificar un ConfigMap con una configuración de Hadoop sin tener que colocar primero el archivo correspondiente en la imagen de Docker. También es adecuado para iniciar tareas con regularidad; con el parámetro "programación", puede especificar la programación de inicio para esta tarea.
Después de eso, guardamos nuestro manifiesto en el archivo spark-pi.yaml y lo aplicamos a nuestro clúster de Kubernetes:
oc apply -f spark-pi.yaml
Esto creará un objeto de tipo "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Esto creará un pod con una aplicación, cuyo estado se mostrará en las "aplicaciones de sparka" creadas. Se puede visualizar con el siguiente comando:
oc get sparkapplications spark-pi -o yaml -n {project}
Una vez completada la tarea, el POD pasará al estado "Completado", que también se actualiza a "aplicaciones sparka". Los registros de la aplicación se pueden ver en un navegador o con el siguiente comando (aquí, {sparkapplications-pod-name} es el nombre del pod de la tarea en ejecución):
oc logs {sparkapplications-pod-name} -n {project}
Las tareas de Spark también se pueden administrar mediante la utilidad especializada Sparkctl. Para instalarlo, clonamos el repositorio con su código fuente, instalamos Go y construimos esta utilidad:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Examinemos la lista de tareas Spark en ejecución:
sparkctl list -n {project}
Creemos una descripción para la tarea Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Ejecutemos la tarea descrita usando sparkctl:
sparkctl create spark-app.yaml -n {project}
Examinemos la lista de tareas Spark en ejecución:
sparkctl list -n {project}
Examinemos la lista de eventos de la tarea Spark iniciada:
sparkctl event spark-pi -n {project} -f
Examinemos el estado de la tarea Spark en ejecución:
sparkctl status spark-pi -n {project}
En conclusión, me gustaría considerar las desventajas descubiertas de operar la versión estable actual de Spark (2.4.5) en Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- La ejecución de tareas de Spark con Kubernetes todavía está oficialmente en modo experimental, y puede haber cambios significativos en los artefactos utilizados (archivos de configuración, imágenes base de Docker y scripts de inicio) en el futuro. De hecho, al preparar el material, se probaron las versiones 2.3.0 y 2.4.5, el comportamiento fue significativamente diferente.
Esperaremos actualizaciones: recientemente se lanzó una nueva versión de Spark (3.0.0), que trajo cambios tangibles al trabajo de Spark en Kubernetes, pero mantuvo el estado experimental de soporte para este administrador de recursos. Quizás las próximas actualizaciones realmente permitan recomendar por completo el abandono de YARN y la ejecución de tareas de Spark en Kubernetes, sin temer por la seguridad de su sistema y sin la necesidad de refinar componentes funcionales de forma independiente.
Aleta.