Hubo mucha controversia sobre cómo crear software con mayor confiabilidad, se discutieron metodologías, enfoques para la organización del desarrollo, herramientas. Pero entre todas estas discusiones, lo que se pierde es que el desarrollo de software es un proceso , y bastante bien estudiado y formalizado. Y si observa este proceso, notará que este proceso se centra no solo en cómo se escribe / genera el código, sino en cómo se verifica este código. Más importante aún, el desarrollo requiere el uso de herramientas en las que pueda "confiar".
Este breve recorrido ha terminado y veamos cómo se ha demostrado que el código es confiable. Primero, debe comprender las características del código que cumple con los requisitos de confiabilidad. El mismo término "fiabilidad del código" parece bastante vago y contradictorio. Por lo tanto, prefiero no inventar nada, y al evaluar la confiabilidad del código sigo los estándares de la industria, por ejemplo, GOST R ISO 26262 o KT-178C. La redacción es diferente, pero la idea es la misma: se desarrolla un código confiable de acuerdo con un único estándar (el llamado estándar de codificación ) y se minimiza el número de errores en tiempo de ejecución. Sin embargo, aquí no todo es tan simple: los estándares prevén situaciones en las que, por ejemplo, el cumplimiento del estándar de codificación no es posible y dicha desviación debe documentarse
Ciénaga peligrosa MISRA y similares
Los estándares de codificación están destinados a restringir el uso de construcciones de lenguaje de programación que pueden ser potencialmente peligrosas. En teoría, esto debería mejorar la calidad del código, ¿verdad? Sí, esto asegura la calidad del código, pero siempre es importante recordar que el 100% de cumplimiento de las reglas de codificación no es un fin en sí mismo. Si el código es 100% compatible con las reglas de algún MISRA, entonces esto no significa en absoluto que sea bueno y correcto. Puede pasar mucho tiempo refactorizando, limpiando violaciones del estándar de codificación, pero todo esto se desperdiciará si el código termina funcionando incorrectamente o contiene errores de tiempo de ejecución. Además, las reglas de MISRA o CERT suelen ser solo una parte del estándar de codificación adoptado en la empresa.
El análisis estático no es una panacea
Los estándares prescriben una revisión sistemática del código para encontrar defectos en el código y analizar el código para los estándares de codificación.
Las herramientas de análisis estático comúnmente utilizadas para este propósito son buenas para detectar fallas, pero no prueban que el código fuente esté libre de errores en tiempo de ejecución. Y muchos de los errores detectados por los analizadores estáticos son en realidad falsos positivos de las herramientas. Como resultado, el uso de estas herramientas no reduce en gran medida el tiempo dedicado a verificar el código debido a la necesidad de verificar los resultados de la verificación. Peor aún, es posible que no detecten errores en tiempo de ejecución, lo cual es inaceptable para aplicaciones que requieren alta confiabilidad.
Verificación de código formal
Por lo tanto, los analizadores estáticos no siempre pueden detectar errores en tiempo de ejecución. ¿Cómo se pueden detectar y eliminar? En este caso, se requiere una verificación formal del código fuente.
En primer lugar, debe comprender qué tipo de animal es. La verificación formal es la prueba del código libre de errores utilizando métodos formales. Suena aterrador, pero de hecho, es como una prueba de un teorema de matan. No hay magia aquí. Este método se diferencia del análisis estático tradicional, ya que utiliza una interpretación abstractaen lugar de heurística. Esto nos da lo siguiente: podemos demostrar que no hay errores de tiempo de ejecución específicos en el código. ¿Cuáles son estos errores? Se trata de todo tipo de desbordamientos de matrices, división por cero, desbordamiento de enteros, etc. Su mezquindad radica en el hecho de que el compilador recopilará código que contenga tales errores (ya que dicho código es sintácticamente correcto), pero aparecerán cuando se ejecute el código.
Echemos un vistazo a un ejemplo. A continuación, en los spoilers, se encuentra el código para un controlador PI simple:
Ver código
pictrl.c
#include "pi_control.h"
/* Global variable definitions */
float inp_volt[2];
float integral_state;
float duty_cycle;
float direction;
float normalized_error;
/* Static functions */
static void pi_alg(float Kp, float Ki);
static void process_inputs(void);
/* control_task implements a PI controller algorithm that ../
*
* - reads inputs from hardware on actual and desired position
* - determines error between actual and desired position
* - obtains controller gains
* - calculates direction and duty cycle of PWM output using PI control algorithm
* - sets PWM output to hardware
*
*/
void control_task(void)
{
float Ki;
float Kp;
/* Read inputs from hardware */
read_inputs();
/* Convert ADC values to their respective voltages provided read failure did not occur, otherwise do not update input values */
if (!read_failure) {
inp_volt[0] = 0.0048828125F * (float) inp_val[0];
inp_volt[1] = 0.0048828125F * (float) inp_val[1];
}
/* Determine error */
process_inputs();
/* Determine integral and proprortional controller gains */
get_control_gains(&Kp,&Ki);
/* PI control algorithm */
pi_alg(Kp, Ki);
/* Set output pins on hardware */
set_outputs();
}
/* process_inputs computes the error between the actual and desired position by
* normalizing the input values using lookup tables and then taking the difference */
static void process_inputs(void)
{
/* local variables */
float rtb_AngleNormalization;
float rtb_PositionNormalization;
/* Normalize voltage values */
look_up_even( &(rtb_AngleNormalization), inp_volt[1], angle_norm_map, angle_norm_vals);
look_up_even( &(rtb_PositionNormalization), inp_volt[0], pos_norm_map, pos_norm_vals);
/* Compute error */
normalized_error = rtb_PositionNormalization - rtb_AngleNormalization;
}
/* look_up_even provides a lookup table algorithm that works for evenly spaced values.
*
* Inputs to the function are...
* pY - pointer to the output value
* u - input value
* map - structure containing the static lookup table data...
* valueLo - minimum independent axis value
* uSpacing - increment size of evenly spaced independent axis
* iHi - number of increments available in pYData
* pYData - pointer to array of values that make up dependent axis of lookup table
*
*/
void look_up_even( float *pY, float u, map_data map, float *pYData)
{
/* If input is below range of lookup table, output is minimum value of lookup table (pYData) */
if (u <= map.valueLo )
{
pY[1] = pYData[1];
}
else
{
/* Determine index of output into pYData based on input and uSpacing */
float uAdjusted = u - map.valueLo;
unsigned int iLeft = uAdjusted / map.uSpacing;
/* If input is above range of lookup table, output is maximum value of lookup table (pYData) */
if (iLeft >= map.iHi )
{
(*pY) = pYData[map.iHi];
}
/* If input is in range of lookup table, output will interpolate between lookup values */
else
{
{
float lambda; // fractional part of difference between input and nearest lower table value
{
float num = uAdjusted - ( iLeft * map.uSpacing );
lambda = num / map.uSpacing;
}
{
float yLeftCast; // table value that is just lower than input
float yRghtCast; // table value that is just higher than input
yLeftCast = pYData[iLeft];
yRghtCast = pYData[((iLeft)+1)];
if (lambda != 0) {
yLeftCast += lambda * ( yRghtCast - yLeftCast );
}
(*pY) = yLeftCast;
}
}
}
}
}
static void pi_alg(float Kp, float Ki)
{
{
float control_output;
float abs_control_output;
/* y = integral_state + Kp*error */
control_output = Kp * normalized_error + integral_state;
/* Determine direction of torque based on sign of control_output */
if (control_output >= 0.0F) {
direction = TRUE;
} else {
direction = FALSE;
}
/* Absolute value of control_output */
if (control_output < 0.0F) {
abs_control_output = -control_output;
} else if (control_output > 0.0F) {
abs_control_output = control_output;
}
/* Saturate duty cycle to be less than 1 */
if (abs_control_output > 1.0F) {
duty_cycle = 1.0F;
} else {
duty_cycle = abs_control_output;
}
/* integral_state = integral_state + Ki*Ts*error */
integral_state = Ki * normalized_error * 1.0e-002F + integral_state;
}
}
pi_control.h
/* Lookup table structure */
typedef struct {
float valueLo;
unsigned int iHi;
float uSpacing;
} map_data;
/* Macro definitions */
#define TRUE 1
#define FALSE 0
/* Global variable declarations */
extern unsigned short inp_val[];
extern map_data angle_norm_map;
extern float angle_norm_vals[11];
extern map_data pos_norm_map;
extern float pos_norm_vals[11];
extern float inp_volt[2];
extern float integral_state;
extern float duty_cycle;
extern float direction;
extern float normalized_error;
extern unsigned char read_failure;
/* Function declarations */
void control_task(void);
void look_up_even( float *pY, float u, map_data map, float *pYData);
extern void read_inputs(void);
extern void set_outputs(void);
extern void get_control_gains(float* c_prop, float* c_int);
Ejecutemos la prueba con Polyspace Bug Finder , un analizador estático certificado y calificado, y obtengamos los siguientes resultados:
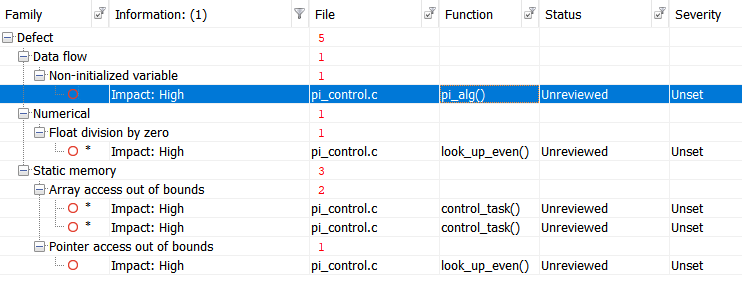
Para mayor comodidad, tabulemos los resultados:
Ver resultados
|
|
|
|
| Non-initialized variable
|
Local variable 'abs_control_output' may be read before being initialized.
|
159
|
| Float division by zero
|
Divisor is 0.0.
|
99
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
38
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
39
|
| Pointer access out of bounds
|
Attempt to dereference pointer outside of the pointed object at offset 1.
|
93
|
Ahora verifiquemos el mismo código usando la herramienta de verificación formal Polyspace Code Prover:
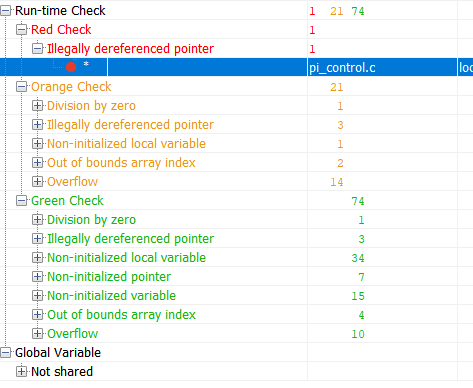
Verde en los resultados es un código que ha demostrado estar libre de errores de tiempo de ejecución. Rojo: error comprobado. Naranja: la herramienta no tiene datos. Los resultados marcados en verde son los más interesantes. Si para una parte del código se ha demostrado la ausencia de un error en tiempo de ejecución, entonces para esta parte del código la cantidad de pruebas se puede reducir significativamente (por ejemplo, las pruebas de robustez ya no se pueden realizar) Y ahora, veamos la tabla resumen de errores potenciales y probados:
Ver resultados
|
|
|
|
| Out of bounds array index
|
38
|
Warning: array index may be outside bounds: [array size undefined]
|
| Out of bounds array index
|
39
|
Warning: array index may be outside bounds: [array size undefined]
|
| Overflow
|
70
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
93
|
Error: pointer is outside its bounds
|
| Overflow
|
98
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Division by zero
|
99
|
Warning: float division by zero may occur
|
| Overflow
|
99
|
Warning: operation [conversion from float32 to unsigned int32] on scalar may overflow (on MIN or MAX bounds of UINT32)
|
| Overflow
|
99
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
104
|
Warning: pointer may be outside its bounds
|
| Overflow
|
114
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Overflow
|
114
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
115
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
121
|
Warning: pointer may be outside its bounds
|
| Illegally dereferenced pointer
|
122
|
Warning: pointer may be outside its bounds
|
| Overflow
|
124
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Non-uninitialized local variable
|
159
|
Warning: local variable may be non-initialized (type: float 32)
|
| Overflow
|
166
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
166
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
Esta tabla me dice lo siguiente:
Hubo un error de tiempo de ejecución en la línea 93 que está garantizado. El resto de las advertencias me dicen que configuré la verificación incorrectamente, o necesito escribir un código de seguridad o superarlas de otra manera.
Puede parecer que la verificación formal es muy buena y todo el proyecto debe verificarse sin control. Sin embargo, como con cualquier instrumento, existen limitaciones, principalmente relacionadas con los costos de tiempo. En resumen, la verificación formal es lenta. Muy lento. El rendimiento está limitado por la complejidad matemática tanto de la interpretación abstracta en sí misma como del volumen del código a verificar. Por lo tanto, no debe intentar verificar rápidamente el kernel de Linux. Todos los proyectos de verificación en Polyspace se pueden dividir en módulos que se pueden verificar de forma independiente entre sí, y cada módulo tiene su propia configuración. Es decir, podemos ajustar la minuciosidad de la verificación para cada módulo por separado.
"Confianza" en las herramientas
Cuando trabaja con estándares de la industria como KT-178C o GOST R ISO 26262, constantemente se encuentra con cosas como "confianza en la herramienta" o "calificación de la herramienta". ¿Qué es? Este es un proceso en el que demuestra que se puede confiar en los resultados de las herramientas de desarrollo o prueba que se utilizaron en el proyecto y que sus errores están documentados. Este proceso es un tema para un artículo separado, ya que no todo es obvio. Lo principal aquí es lo siguiente: las herramientas utilizadas en la industria siempre vienen con un conjunto de documentos y pruebas que ayudan en este proceso.
Salir
Con un ejemplo simple, observamos la diferencia entre el análisis estático clásico y la verificación formal. ¿Se puede aplicar fuera de los proyectos que requieren el cumplimiento de los estándares de la industria? Sí por supuesto que puedes. Incluso puede solicitar una versión de prueba aquí .
Por cierto, si está interesado, puede hacer un artículo aparte sobre la certificación de instrumentos. Escriba en los comentarios si necesita un artículo de este tipo.