Parte 2
En este artículo, aprenderá:
- Acerca del desafío de reconocimiento visual a gran escala de ImageNet (ILSVRC)
- Acerca de las arquitecturas de CNN:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- Acerca de los problemas que aparecieron con las nuevas arquitecturas de red, cómo fueron resueltos por las siguientes:
- problema de gradiente de fuga
- problema de gradiente explosivo
ILSVRC
El ImageNet Large Scale Visual Recognition Challenge es un concurso anual en el que los investigadores comparan sus cuadrículas para la detección y clasificación de objetos en fotografías.
Esta competencia fue el impulso para el desarrollo de:
- Arquitecturas de redes neuronales
- métodos y prácticas personales que se utilizan hasta el día de hoy
. Este gráfico muestra cómo los algoritmos de clasificación han evolucionado a lo largo del tiempo:
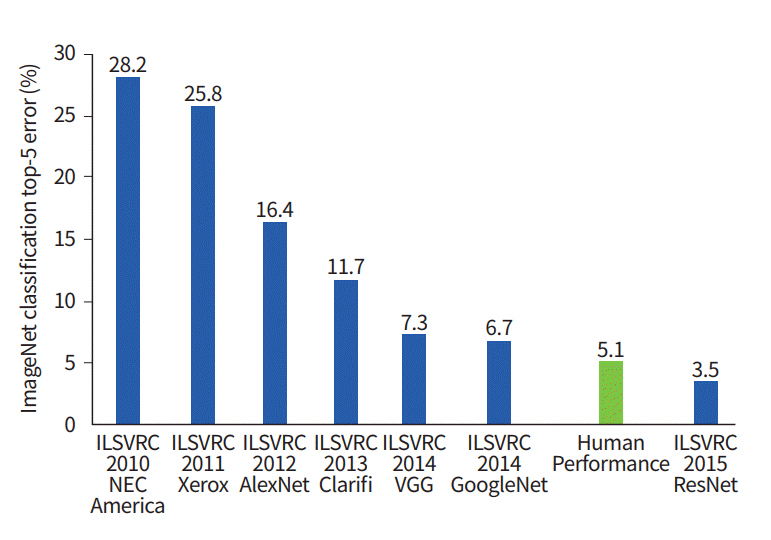
En el eje x - años y algoritmos (desde 2012 - convolucional neural red).
El eje y es el porcentaje de errores en la muestra a partir de los 5 errores principales.
El error de los 5 primeros es una forma de evaluar el modelo: el modelo devuelve una determinada distribución de probabilidad y si entre las 5 probabilidades principales hay un valor verdadero (etiqueta de clase) de la clase, la respuesta del modelo se considera correcta. En consecuencia, (1 - error superior 1) es la precisión familiar.
Arquitecturas CNN
LeNet-5
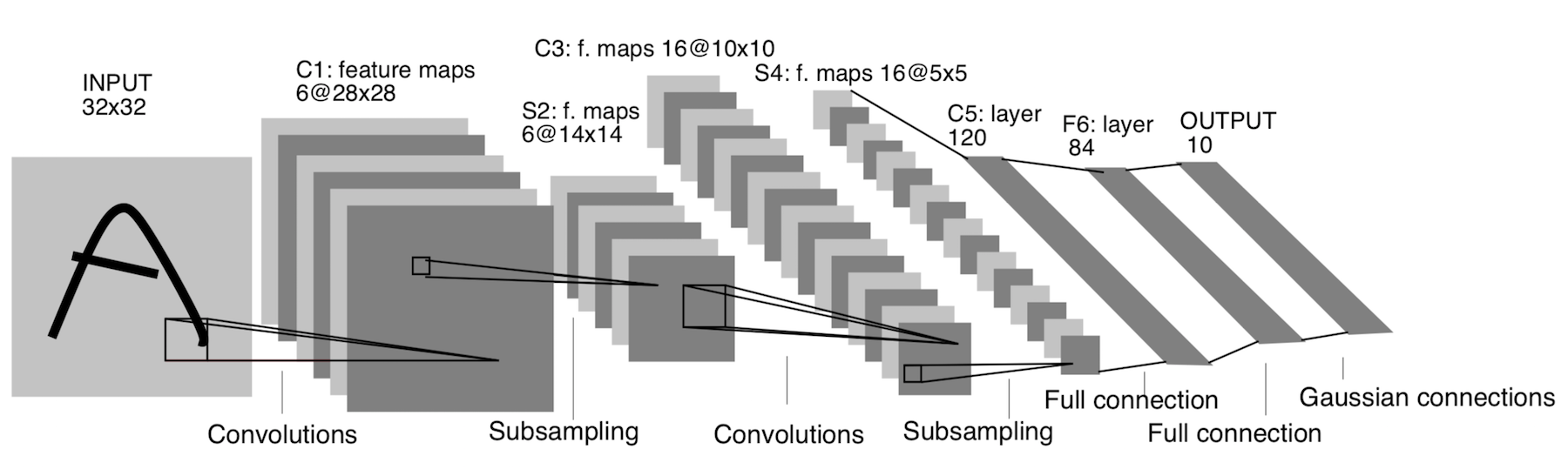
¡Apareció ya en 1998! Fue diseñado para reconocer letras y números escritos a mano. El submuestreo aquí se refiere a la capa de agrupación.
Arquitectura:
CONV 5x5, zancada = 1
PISCINA 2x2, zancada = 2
CONV 5x5, zancada = 1
PISCINA 5x5, zancada = 2
FC (120, 84)
FC (84, 10)
Ahora bien, esta arquitectura solo tiene un significado histórico. Esta arquitectura es fácil de implementar manualmente en cualquier marco moderno de aprendizaje profundo.
AlexNet

La imagen no está duplicada. Así es como se describe la arquitectura, porque la arquitectura AlexNet no encajaba en un dispositivo GPU en ese momento, por lo que "la mitad" de la red se ejecutaba en una GPU y la otra en la otra.
Apareció en 2012. Un gran avance en ese mismo ILSVRC comenzó con ella: derrotó a todos los modelos de última generación de esa época. Después de eso, la gente se dio cuenta de que las redes neuronales realmente funcionan :)
Arquitectura más específicamente:

Si observa de cerca la arquitectura AlexNet, puede ver que durante 14 años (desde la aparición de LeNet-5) casi no ha habido cambios, excepto por el número de capas.
Importante:
- Tomamos nuestra imagen original de 227x227x3 y bajamos su dimensión (en alto y ancho), pero aumentamos el número de canales. Esta parte de la arquitectura "codifica" la representación original del objeto (codificador).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Un registro como Conv 11x11s4, 96 significa que la capa de convolución tiene un filtro 11x11xNc, paso = 4, el número de tales filtros es 96. Ahora el número de tales filtros es el número de canales para la siguiente capa (el mismo Nc). Suponemos que la imagen inicial tiene tres canales (R, G y B).
VGGNet
Arquitectura:
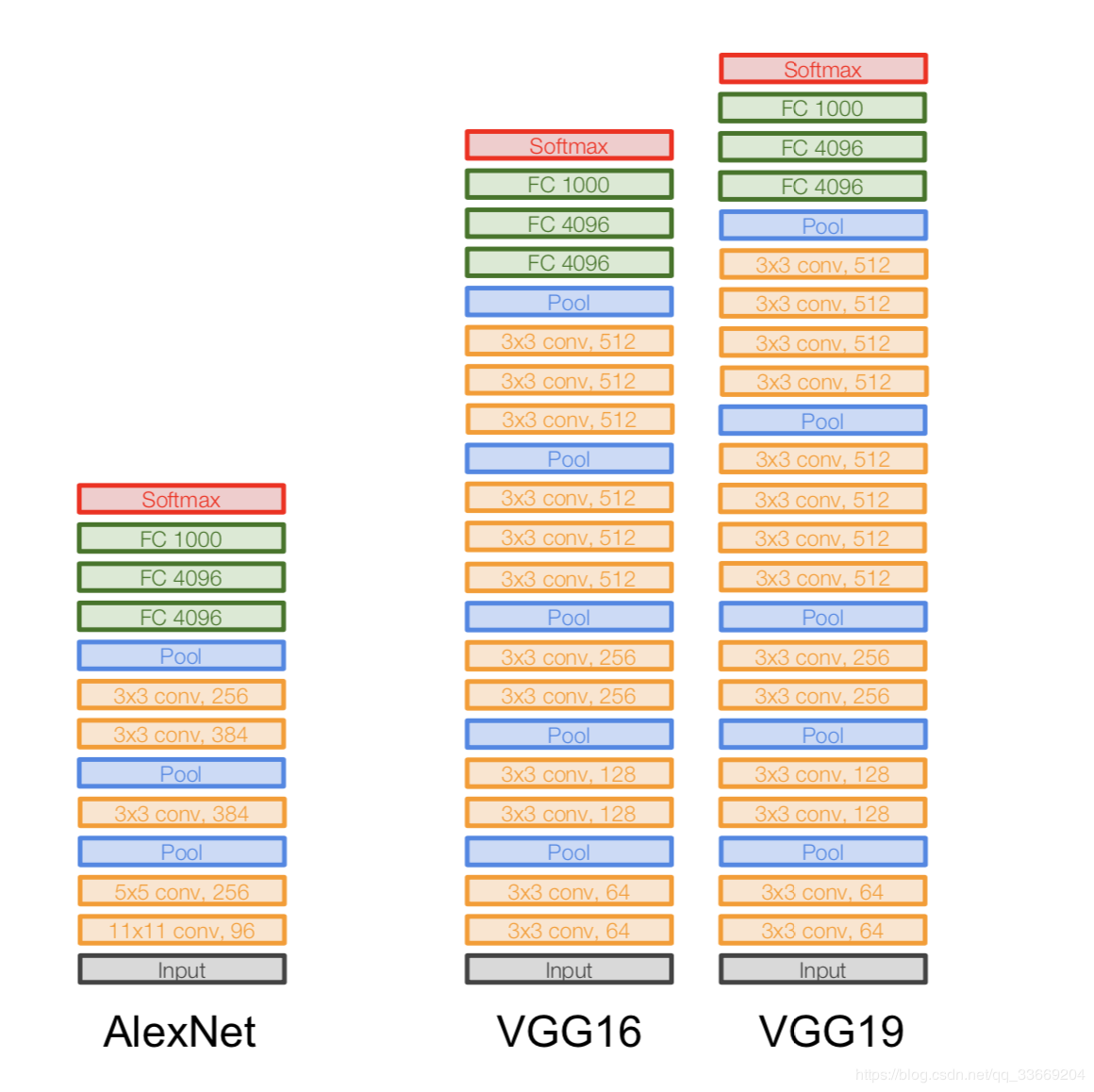
introducida en 2014.
Dos versiones: VGG16 y VGG19. La idea principal es utilizar pequeños (3x3) en lugar de grandes (11x11 y 5x5). La intuición para usar grandes convoluciones es simple: queremos obtener más información de los píxeles vecinos, pero es mucho mejor usar filtros pequeños con más frecuencia .
Y es por eso:
- . , . .. , , .
- => .
- — , — , — , .
Importante:
- Al entrenar una red neuronal para un algoritmo de retropropagación de errores, es importante preservar las representaciones de objetos (para nosotros, la imagen original) en todas las etapas (convoluciones, grupos) de propagación hacia adelante (el paso hacia adelante es cuando alimentamos la imagen a la entrada y la movemos a la salida, al resultado). Esta representación de un objeto puede resultar cara en términos de memoria. Eche un vistazo:
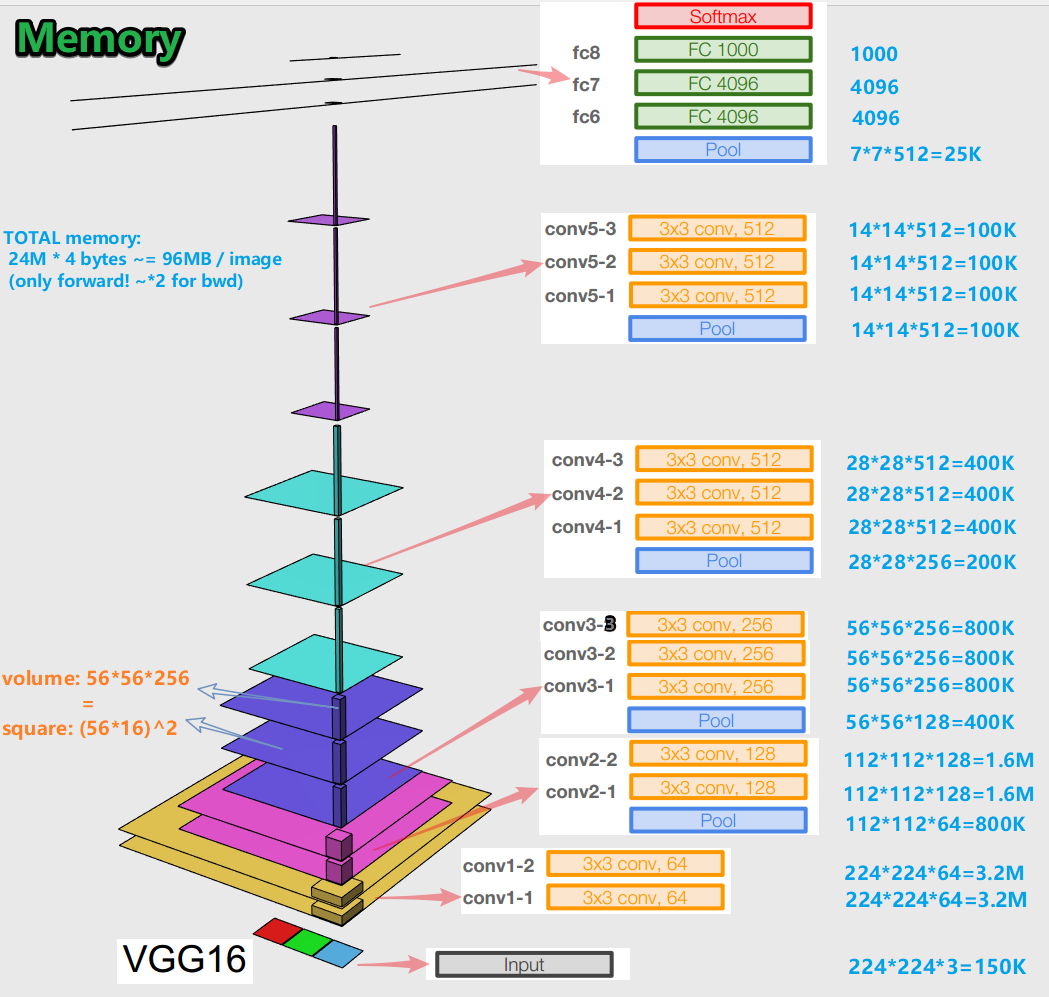
resultan unos 96 MB por imagen, y eso es solo para la pasada hacia adelante. Para el pase hacia atrás (bwd en la imagen), durante el cálculo de gradientes, aproximadamente el doble. Surge una imagen interesante: la mayor cantidad de parámetros entrenados se encuentra en capas completamente conectadas y la mayor memoria está ocupada por representaciones de objetos después de capas convolucionales y agrupadas . C - sinergia.
- La red tiene 138 millones de parámetros entrenables en variación de 16 capas y 143 millones de parámetros en variación de 19 capas.
GoogLeNet
Arquitectura:
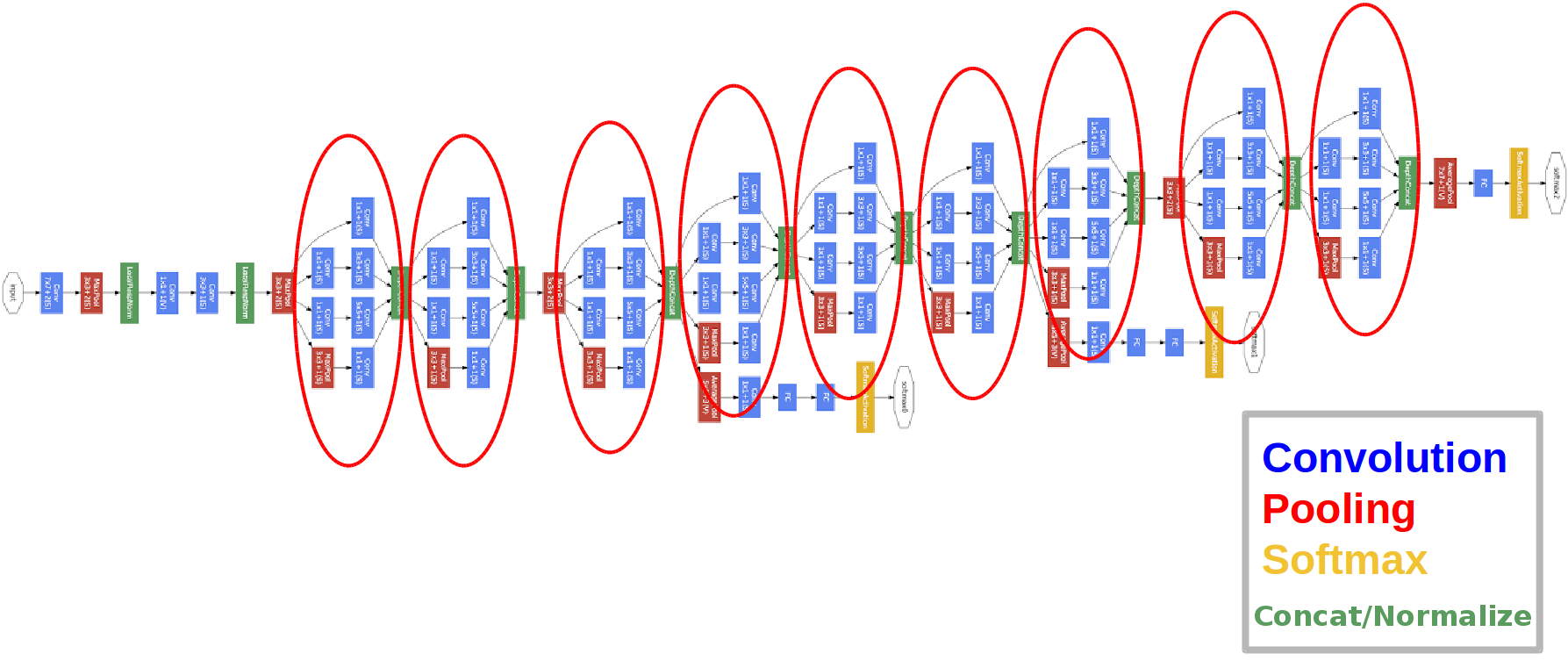
introducida en 2014.
Los círculos rojos son el llamado módulo Inception.
Echemos un vistazo más de cerca:
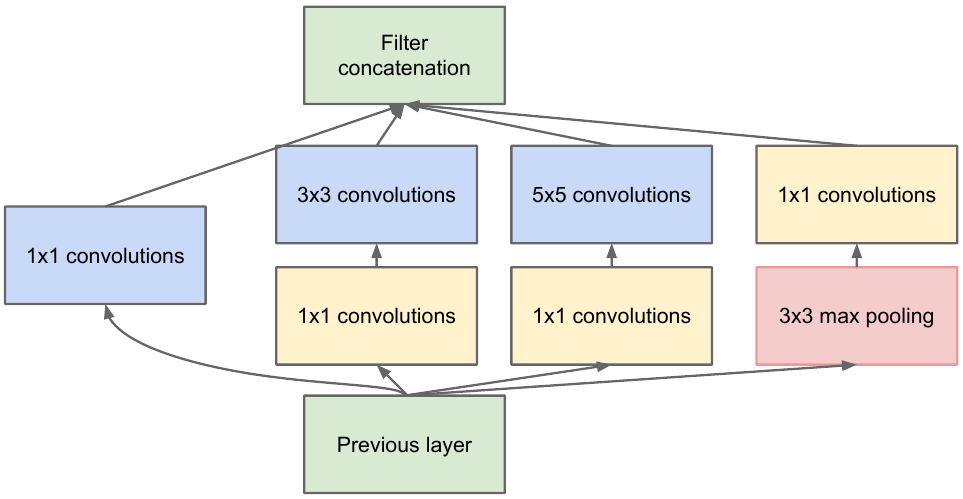
tomamos un mapa de características de la capa anterior, le aplicamos una serie de convoluciones con diferentes filtros y luego concatenamos el resultante. La intuición es simple: queremos obtener diferentes representaciones de nuestro mapa de características utilizando filtros de diferentes tamaños. Las convoluciones 1x1 se utilizan para no aumentar tanto el número de canales después de cada bloque inicial. Aquellos. cuando el mapa de características tiene una gran cantidad de canales y quieren reducir este número sin cambiar la altura y el ancho del mapa de características, use la convolución 1x1.
También hay tres bloques clasificadores en la red, así es como se ve uno de ellos (el de la derecha para nosotros):

Con esta construcción, el gradiente "mejor" llega desde las capas de salida a las capas de entrada durante la propagación del error.
¿Por qué necesitamos dos salidas de red adicionales? Se trata del llamado problema del gradiente de desaparición :
la conclusión es que cuando se propaga hacia atrás un error, el gradiente tiende trivialmente a cero. Cuanto más profunda es la red, más susceptible es a este fenómeno. ¿Por qué sucede? Cuando retrocedemos, pasamos de la salida a la entrada, calculando los gradientes de funciones complejas. Derivada de una función compleja ( regla de la cadena) Es, de hecho, multiplicación. Y así, multiplicando algunos valores en el camino desde la salida hasta la entrada, encontramos números que están cerca de cero y, como resultado, los pesos de la red neuronal prácticamente no se actualizan. Esto es en parte un problema con las funciones de activación sigmoidea que tienen su salida en un rango fijo. Bueno, este problema se resuelve parcialmente utilizando la función de activación de ReLu. ¿Por qué parcialmente? Porque nadie da garantías sobre los valores de los parámetros entrenados y la representación del objeto de entrada en todos los mapas de características.
Importante:
- La red tiene 22 capas (esto es un poco más que la red anterior).
- El número de parámetros entrenados es igual a cinco millones, que es varias veces menor que en las dos redes anteriores.
- La aparición del paquete 1x1.
- Se utilizan bloques de inicio.
- En lugar de capas completamente conectadas, ahora convoluciones 1x1, que reducen la profundidad y, como resultado, reducen la dimensión de las capas completamente conectadas y la denominada agrupación avegare global (puede leer más aquí ).
- La arquitectura tiene 3 salidas (se pesa la respuesta final).
ResNet
Arquitectura (variante ResNet-34): introducida
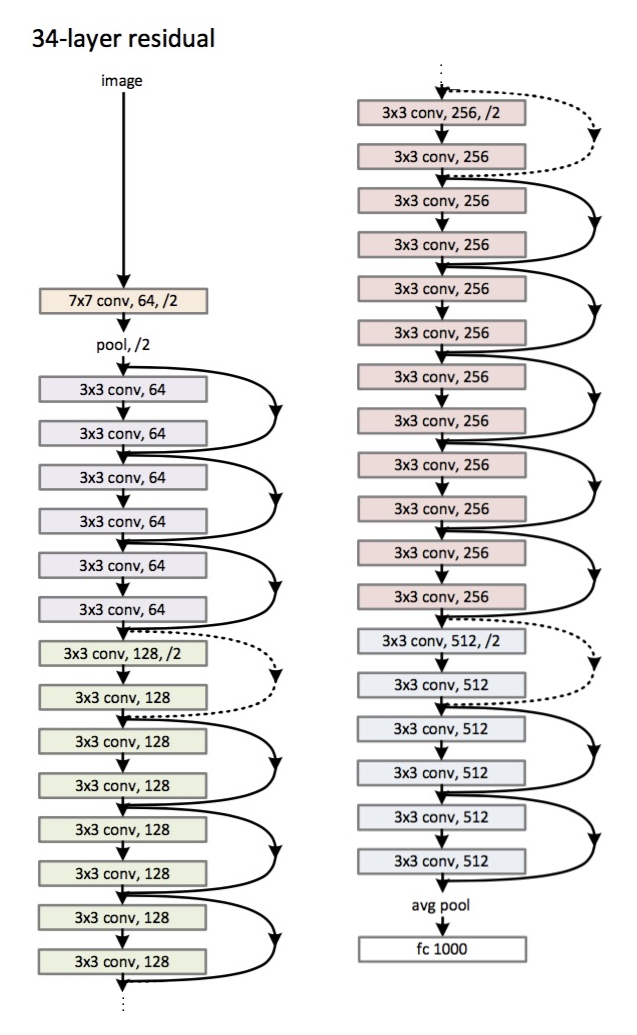
en 2015.
La principal innovación es una gran cantidad de capas y los llamados bloques residuales. Estos bloques se utilizan para combatir el problema del degradado. La conexión entre dichos bloques residuales se llama atajo (flechas en la imagen). Ahora, usando estos atajos, el gradiente alcanzará todos los parámetros necesarios, entrenando así la red :)
Importante:
- En lugar de capas completamente conectadas, agrupación global promedio.
- Bloques residuales.
- La red ha superado a los humanos en el reconocimiento de imágenes en el conjunto de datos de ImageNet (error top-5).
- La normalización por lotes se utilizó por primera vez.
- Se utiliza la técnica de inicializar pesos (intuición: a partir de una cierta inicialización de pesos, la red converge (aprende) más rápido y mejor).
- ¡La profundidad máxima es de 152 capas!
Una pequeña digresión
El problema del gradiente de desvanecimiento es relevante para todas las redes neuronales profundas.
También está su antagonista: el problema del gradiente explosivo, que también es relevante para todas las redes neuronales profundas. La esencia es clara por el nombre: el gradiente se vuelve demasiado grande, lo que causa NaN (no un número, infinito). La solución es obvia: limitar el valor del gradiente, de lo contrario, disminuir su valor (normalizar). Esta técnica se llama "recorte".
Conclusión
En 2019, apareció un artículo sobre una nueva familia de arquitecturas: EfficientNet.
Recomiendo seguir las últimas tendencias en diversas tareas y áreas relacionadas con Machine Learning aquí . En este recurso, puede seleccionar una tarea (por ejemplo, clasificación de imágenes) y un conjunto de datos (por ejemplo, ImageNet) y observar la calidad de ciertas arquitecturas, información adicional sobre ellas. Por ejemplo, la cuadrícula FixEfficientNet-L2 ocupa el honorable primer lugar en la clasificación de imágenes en el conjunto de datos de ImageNet (precisión de primer nivel).
En los próximos artículos, hablaremos sobre el aprendizaje por transferencia, la detección de objetos y la segmentación.