
Hoy, le diremos, sin hacer referencia a modelos específicos de equipos de red, cómo el principio "de la automatización a la autonomía" se materializa en las nuevas capacidades del producto FabricInsight. En efecto, en los últimos años no solo ha cambiado su composición, sino que también han aparecido numerosos escenarios nuevos que permiten determinar el estado actual de la red y predecir posibles problemas en la misma.
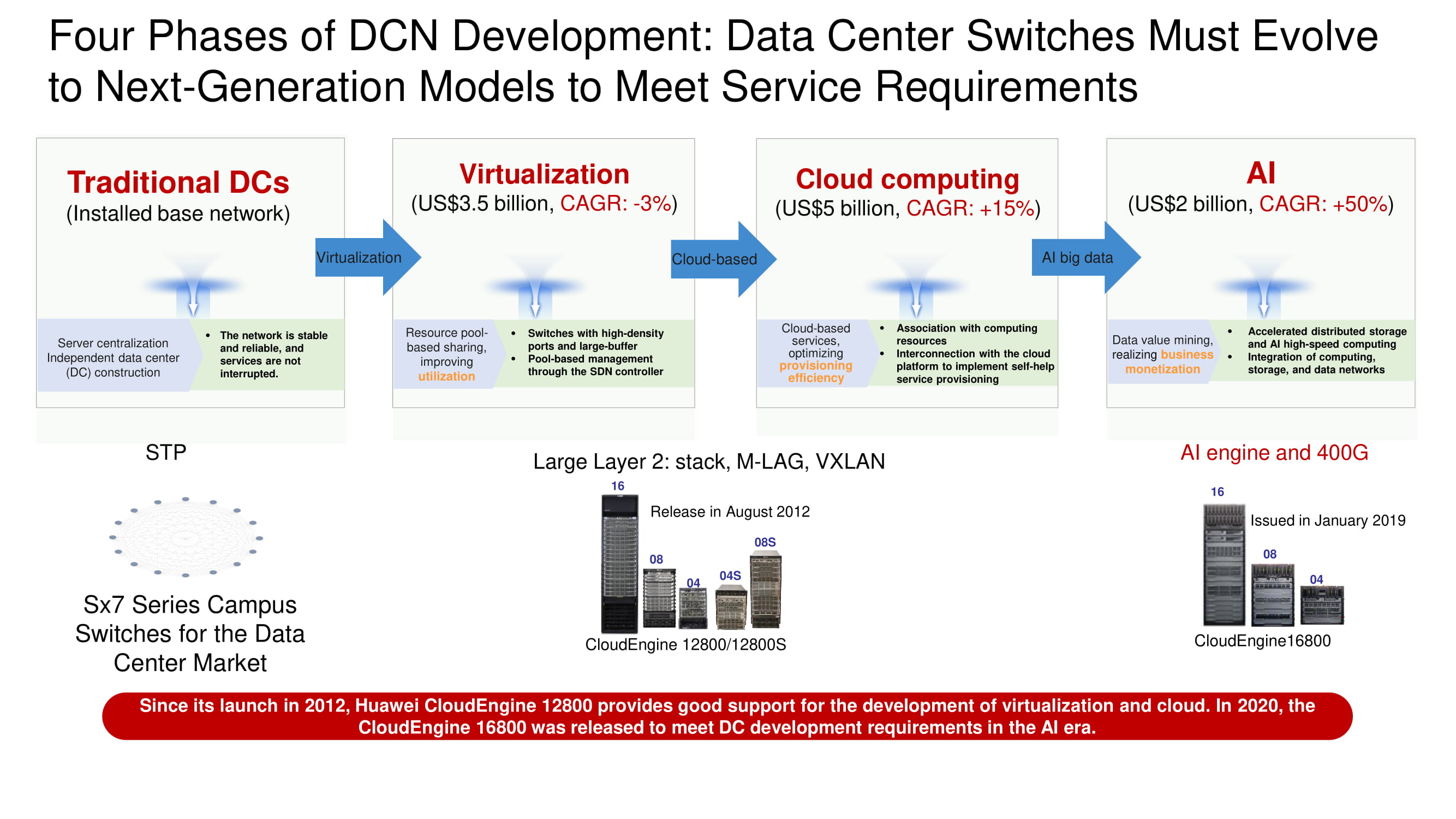
Cuatro etapas del desarrollo del centro de datos
Al determinar el vector de desarrollo de las redes de los centros de datos, es fácil ver cómo las arquitecturas de los centros de datos tradicionales cayeron gradualmente bajo el impacto de los sistemas de virtualización, luego sobrevivieron a una migración masiva de recursos y servicios a las nubes y ahora se acercaron a la introducción generalizada de sistemas de inteligencia artificial e interfaces de alta velocidad de 400 Gbps. Se necesitan capacidades de IA para construir redes Ethernet sin pérdidas y crear aplicaciones que sean completamente inmunes a la latencia.
Otra área de aplicación de la IA es el análisis y el seguimiento del funcionamiento del centro de datos. Tenemos que pasar de una ideología que implica un seguimiento funcionalmente limitado del estado de algunas "cajas negras" al concepto de redes completamente transparentes de las que todo se sabe.

Como las principales unidades de red de infraestructura para la construcción de redes de centros de datos, Huawei ahora ofrece una línea de conmutadores CloudEngine 16800 de cuatro, ocho y dieciséis ranuras con enlaces ascendentes de 400 Gbps; su lanzamiento está programado para el año en curso. También entre los nuevos productos, destacamos los conmutadores CloudEngine 6881 y 6863 ToR construidos sobre nuestra propia base de elementos con interfaces de 10 y 25 Gbps, respectivamente.

La ilustración muestra los modelos de switches de la línea CloudEngine 16800 con arquitectura ortogonal clásica, que están equipados con un sistema de enfriamiento de adelante hacia atrás, así como tarjetas de línea compatibles equipadas con interfaces de 10, 40 y 100 Gb / s.
De las importantes funciones básicas de CloudEngine 16800, destacamos su capacidad para trabajar con NSH (Network Service Header), que permite implementar microsegmentación distribuida a través de varios switches en el centro de datos (aislamiento a nivel de máquina virtual), brindando amplias capacidades de telemetría y analizando el tráfico en el borde de la red (edge intelligence). ) utilizando tecnologías de inteligencia artificial basadas en chips AI de Huawei.
El V1R19C10 será verdaderamente revolucionario. Es en él donde se deben implementar muchas funciones largamente esperadas, incluido EVPN Multihoming sin un "jumper" en forma de M-LAG (Multi-Switch Link Aggregation) basado en el primer y cuarto tipo de rutas en el enrutamiento EVPN VXLAN.
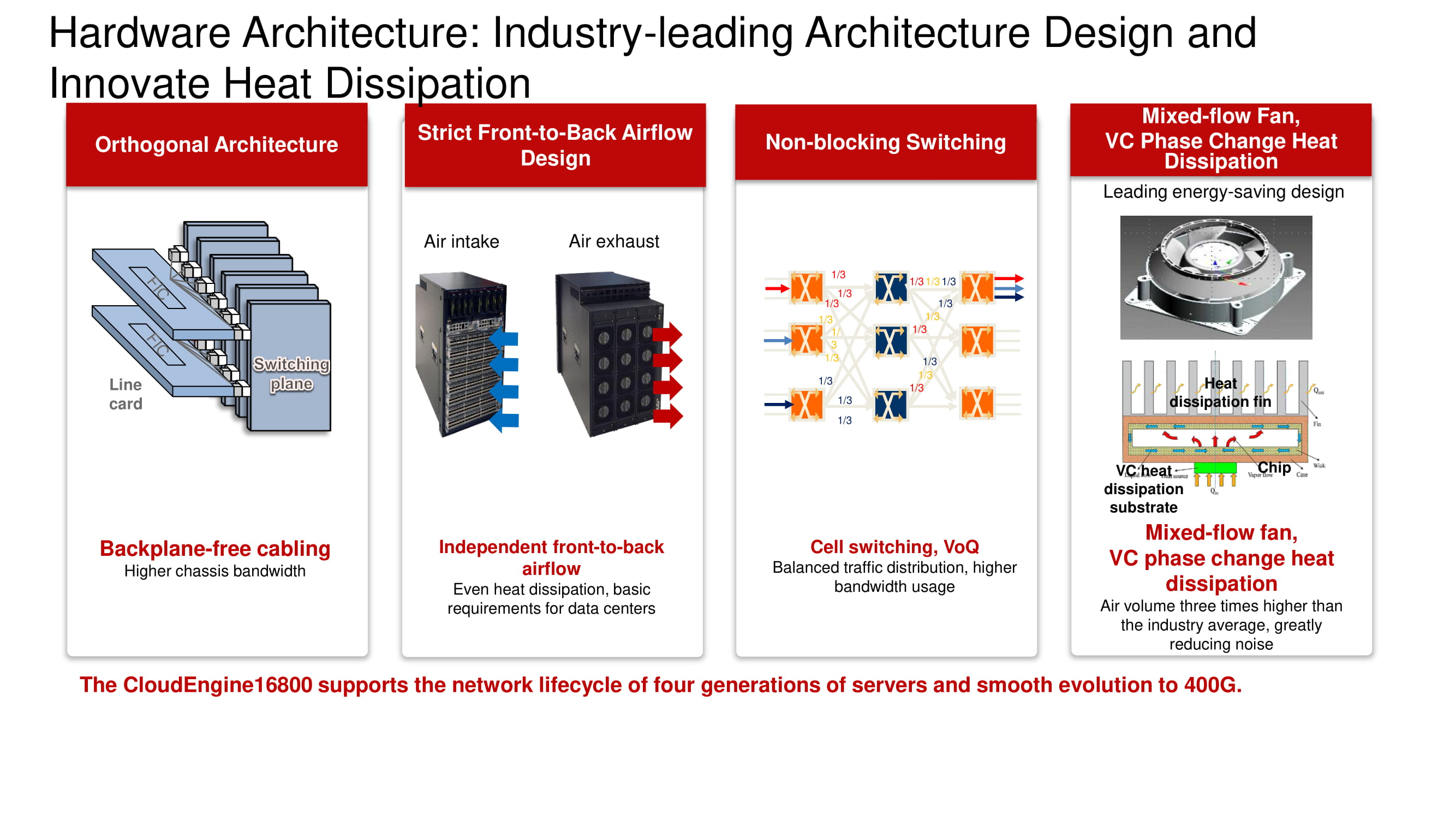
Arquitectura familiar y nuevas posibilidades
El diagrama muestra la conocida arquitectura ortogonal de una conmutación sin bloqueo de "fábrica" de tres niveles. Sus principales ventajas incluyen la disposición óptima de los tableros "factory", tarjetas de línea, conectores y un sistema de soplado basado en ventiladores de velocidad variable.
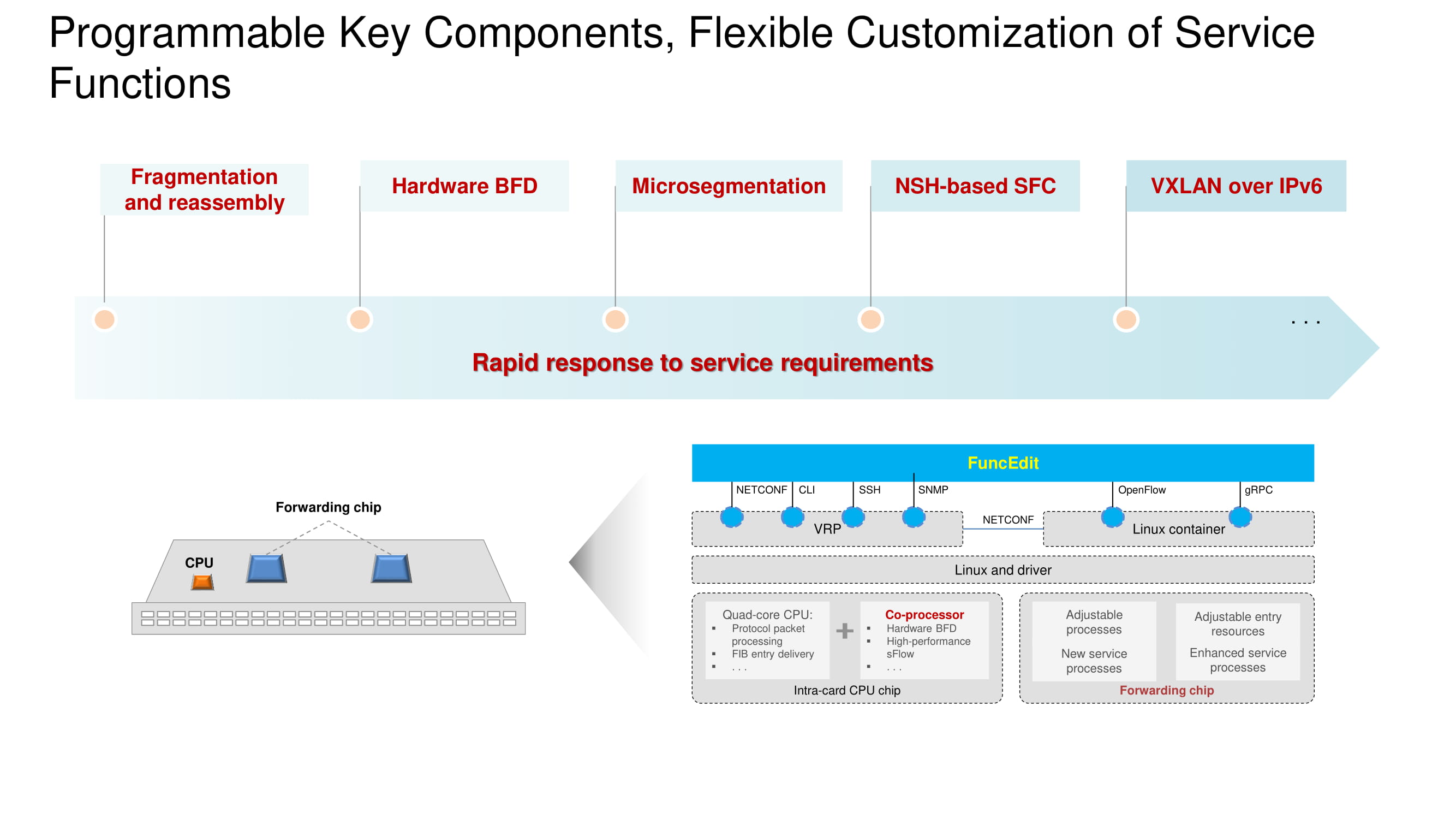
Es importante que el protocolo BFD (Bidirectional Forwarding Detection) esté implementado en hardware en los nuevos modelos de conmutadores y es posible configurar VXLAN en el espacio de direcciones IPv6. La arquitectura básica sigue siendo la misma y se basa en un procesador, coprocesador y chip de reenvío. La funcionalidad de cada uno de los nodos se muestra en el diagrama. El principal cambio en 2020 es la transición a los propios chips de Huawei en los conmutadores insignia, compitiendo completamente con los análogos de Broadcom.
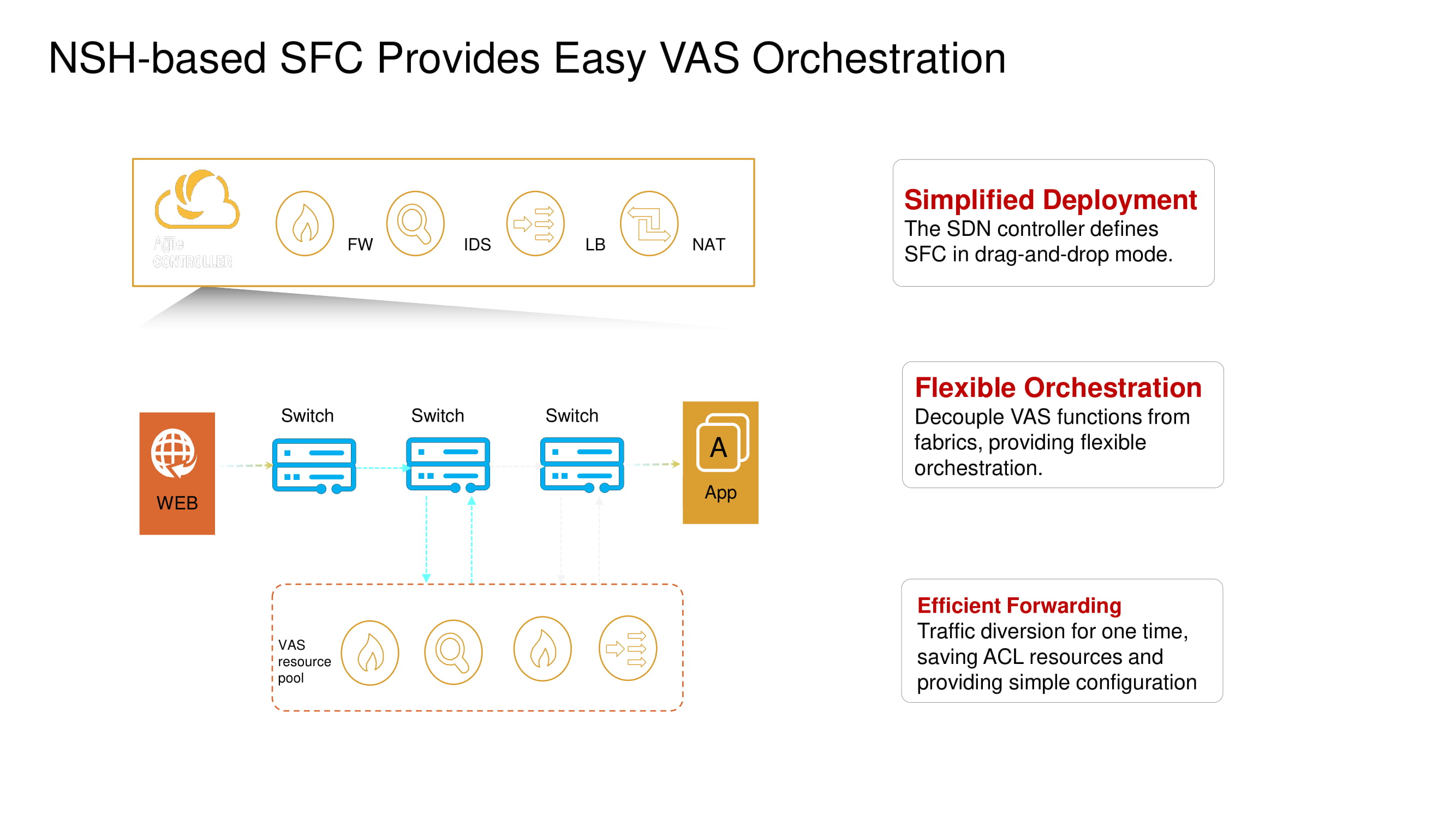
La compatibilidad con las operaciones de encabezado de servicio de red permite que los nuevos conmutadores cambien las rutas de paquetes VXLAN predeterminadas y habiliten servicios como firewalls (FW), sistemas de detección de intrusiones (IDS), equilibradores de carga (SLB) y NAT.
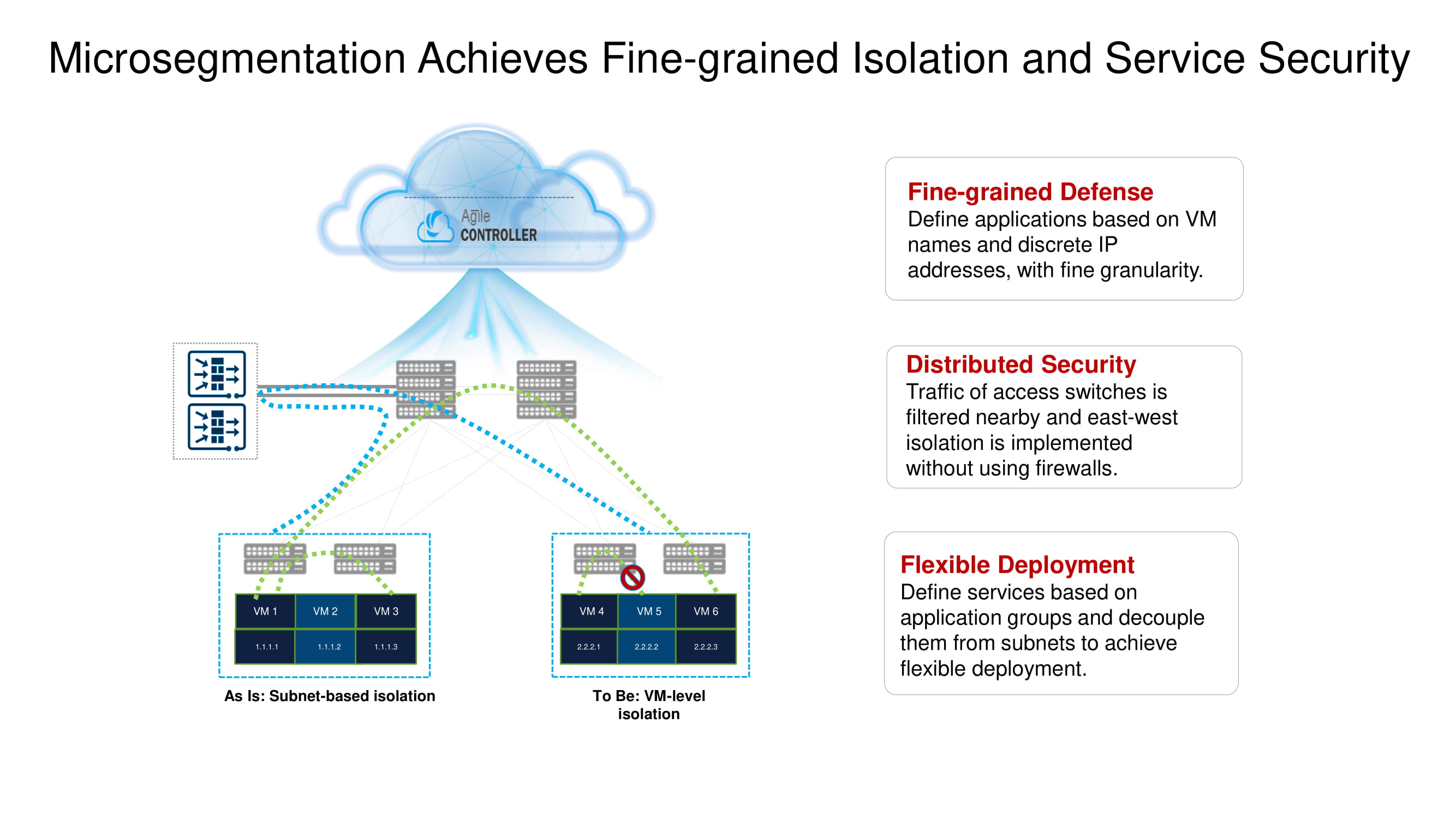
Volvamos brevemente a la microsegmentación dividida mencionada anteriormente. Los nuevos conmutadores ToR de Huawei con la ayuda del mismo NSH le permiten aislar cargas de trabajo a nivel de nombres de máquinas virtuales. Estas máquinas se pueden agrupar aún más a nivel de subred según los números de puerto, protocolos superiores, etc., formando así grupos de aplicaciones.
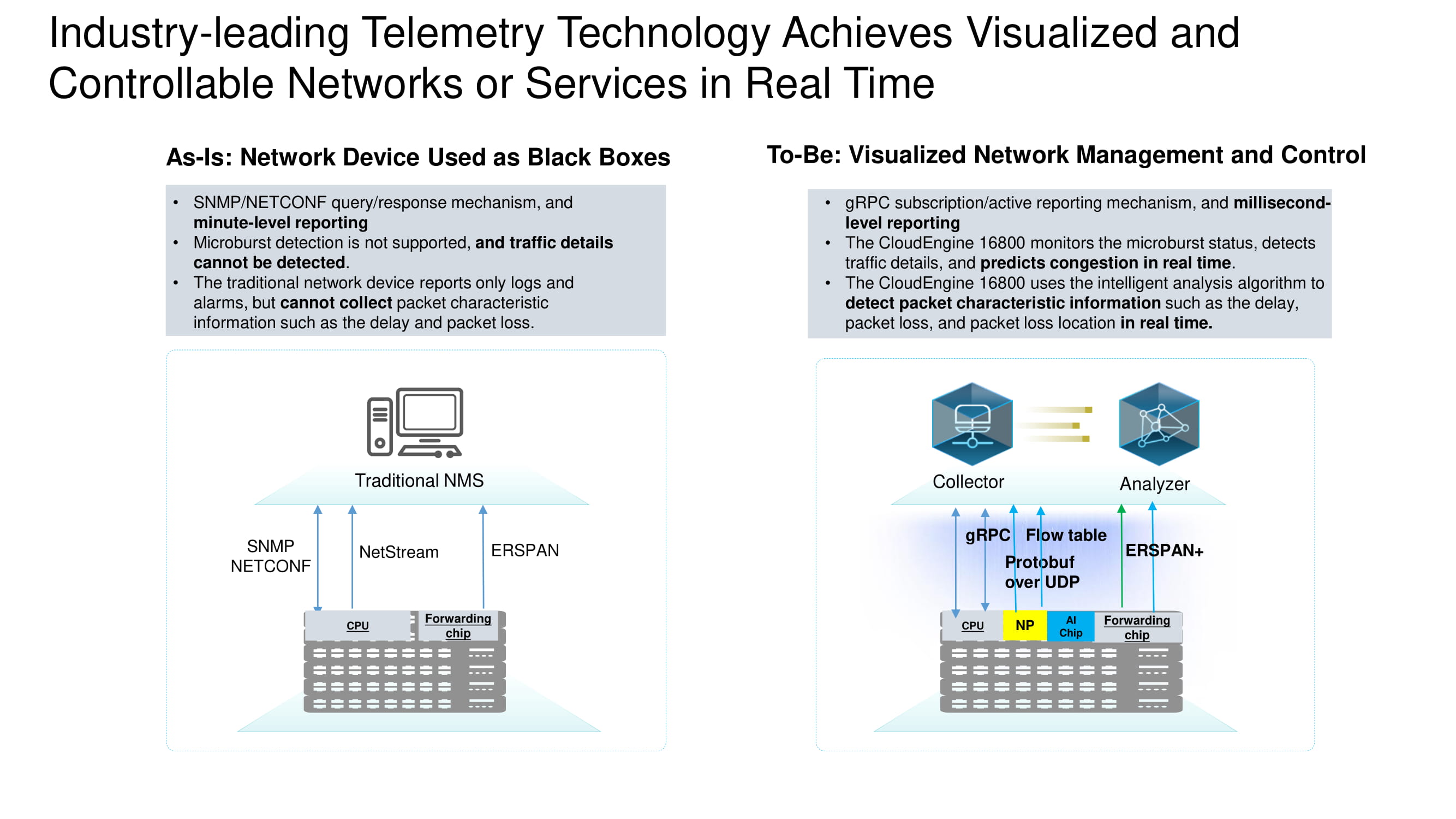
Gama completa de datos de telemetría
La información de los dispositivos se recopila en tiempo real utilizando varios protocolos importantes. La tarea de ERSPAN + es recopilar encabezados TCP para el posterior análisis detallado de los flujos TCP en el centro de datos. Los datos adicionales se extraen utilizando el protocolo gRPC y la tabla de flujo. Todo esto se recopila con Protobuf sobre UDP.
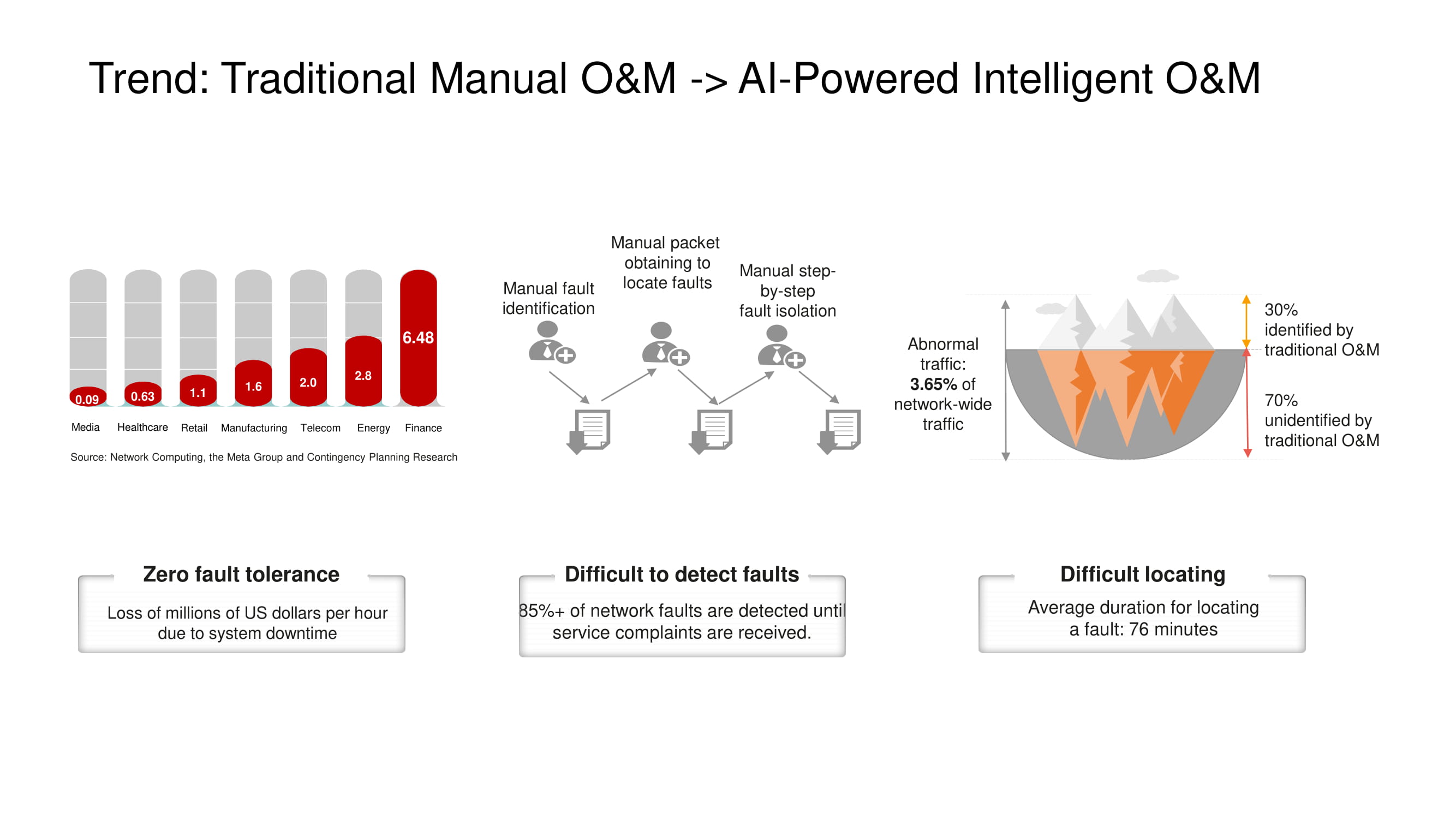
La dirección principal del desarrollo de herramientas de O&M en Huawei es la transición del control de red manual o semiautomático a completamente automático , basado en tecnologías de inteligencia artificial. Un sistema de telemetría que lo abarca todo de un sitio bastante grande produce grandes cantidades de datos, cuyo análisis en poco tiempo solo es posible con el uso de IA. Esto es especialmente importante en aquellos centros de datos, donde las fallas y el tiempo de inactividad son simplemente inaceptables.
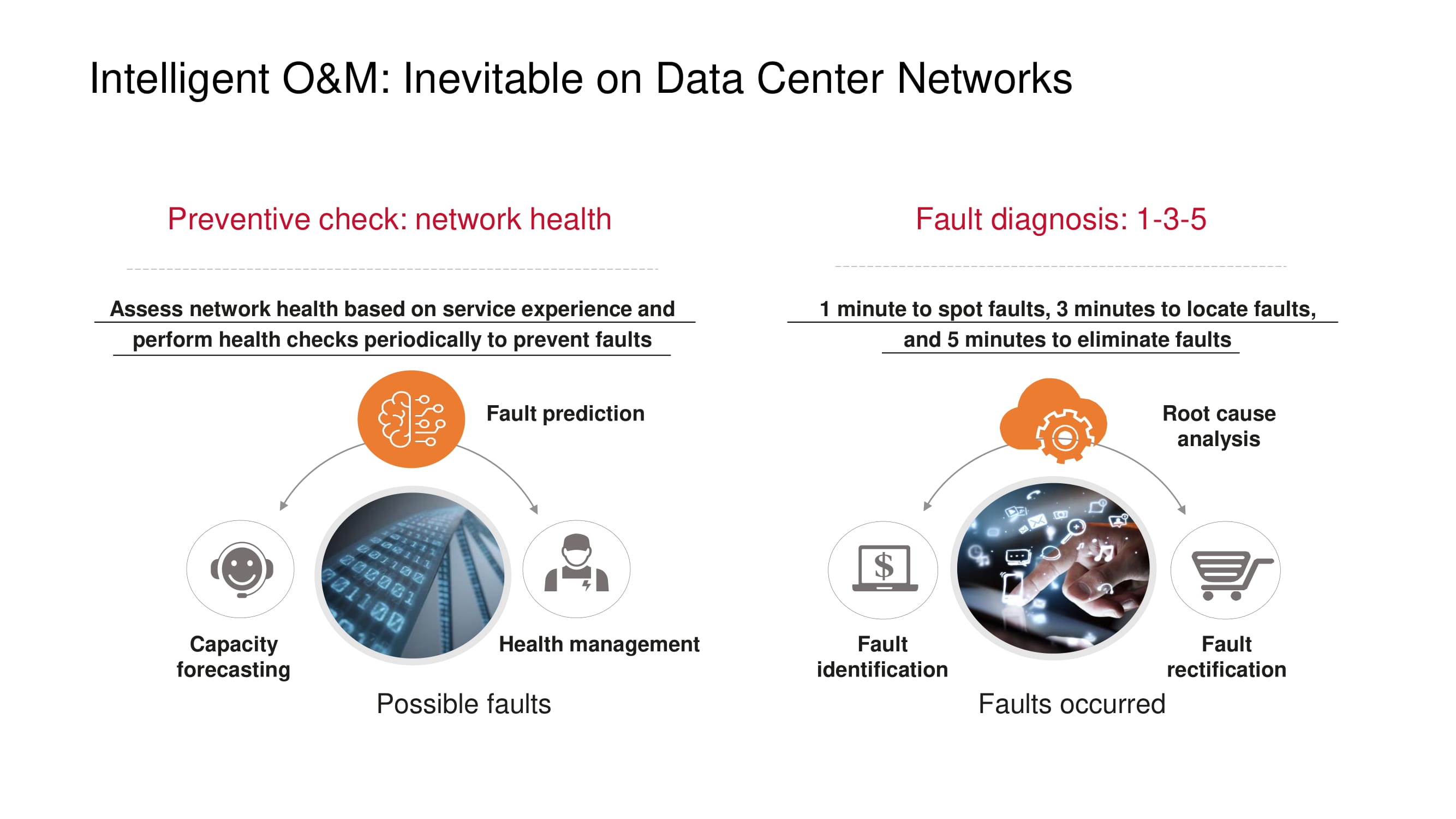
Las medidas preventivas diseñadas para evitar problemas con la red, en primer lugar, incluyen monitorear el "estado" de la red: monitorear la carga del canal, identificar las razones de la pérdida de paquetes (por ejemplo, buscar una correlación con la hora del día o períodos de operación de una aplicación), detectar " cuellos de botella (pronóstico de capacidad), etc.
Si aún se observan problemas, el principio 1-3-5 propuesto por Huawei ayuda a minimizar el tiempo de diagnóstico y recuperación: un minuto para buscar, tres minutos para localizar, cinco minutos para eliminar el problema. Para mantenerse dentro de este marco, los productos de Huawei admiten una lista cada vez mayor de fallas típicas que se detectan automáticamente.

Modelo V100R019C10 para pequeños centros de datos
Una de las principales innovaciones de V100R019C10 es la compatibilidad con la visualización basada en datos de telemetría en todo tipo de escenarios. De hecho, estamos hablando de una visualización visual de cualquier cambio en la red. Además, el dispositivo ahora puede identificar más de 75 causas raíz de ciertos problemas y ayuda a delinear acciones para eliminarlos (lanzar scripts, etc.).
Una noticia importante fue la aparición de la versión Standalone, que incluye tanto iMaster NCE como FabricInsight y está destinada principalmente a pequeños centros de datos que no requieren varios servidores para administrar la red.
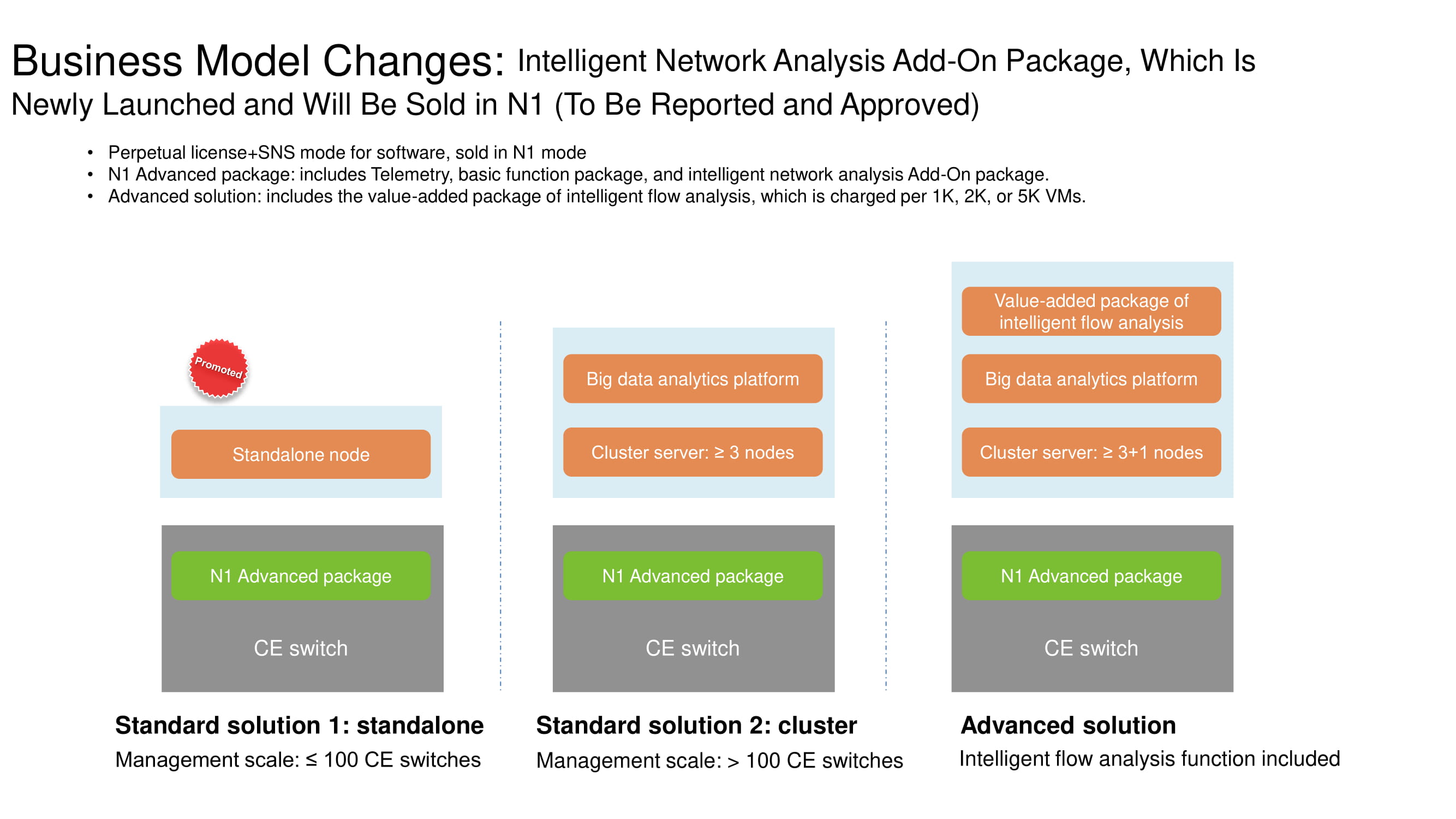
Cambios en el sistema de licencias
Para comprender mejor las características funcionales de FabricInsight, debe explicarse qué cambios se han producido en el modelo comercial para la distribución de productos de red de Huawei. Si el número de conmutadores no llega a cien, esta opción se clasifica como edición independiente e implica una licencia N1. Un clúster de tres o más servidores ya viene incluido con una plataforma de análisis de big data. Se recomienda utilizar la solución avanzada, que incluye varios cientos de conmutadores, junto con herramientas para analizar los flujos de red. Las tres opciones permiten las capacidades de FabricInsight con una licencia N1.
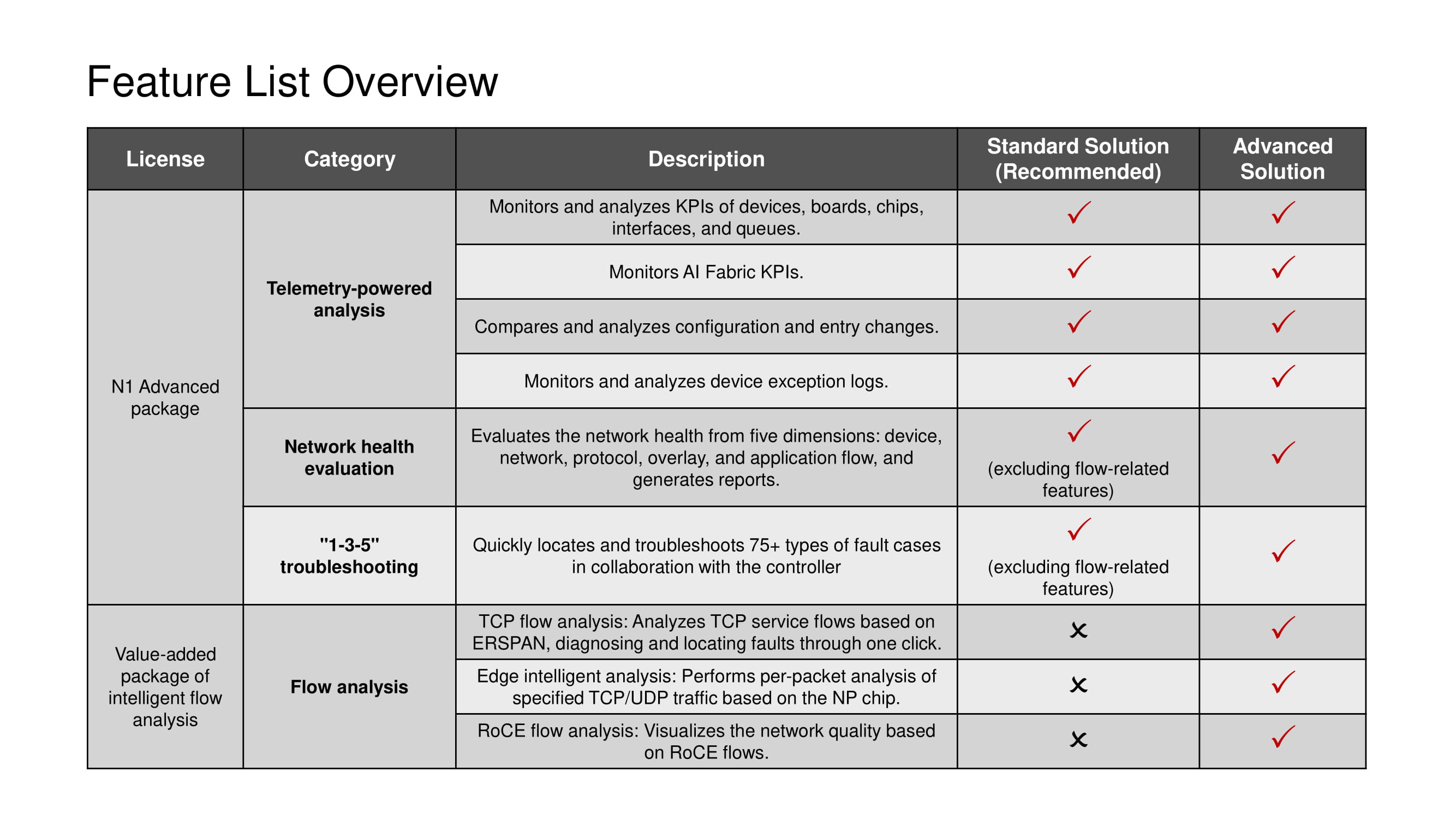
Cualquier licencia implica el uso de todo el conjunto de herramientas de telemetría y escenarios 1-3-5, con la excepción de las herramientas de análisis de flujo TCP disponibles solo en la solución avanzada.
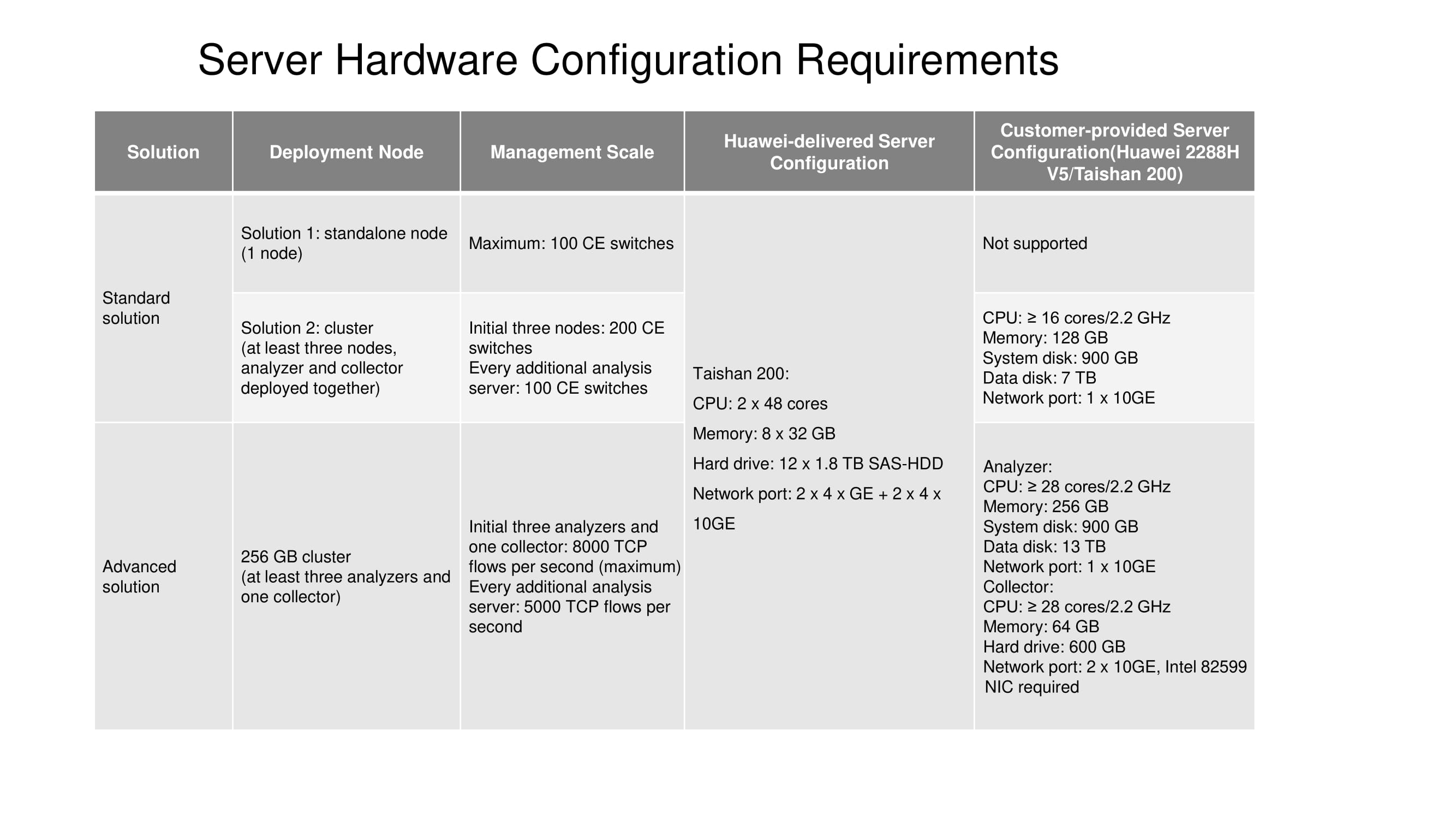
Queda por informarle sobre las configuraciones de servidor diseñadas para soluciones estándar y avanzadas. Actualmente, un nodo independiente (un nodo) está disponible solo en el servidor Taishan 200. Un clúster de tres nodos requiere 16 o más núcleos informáticos, 128 GB de RAM, etc. (ver diagrama). El tamaño del disco de datos depende directamente de cuánto tiempo se deben almacenar las estadísticas.

Monitoreo de KPI
Echemos un vistazo más de cerca al monitoreo de KPI. Para usarlo, es suficiente establecer un intervalo de tiempo y valores de umbral específicos, cuyo logro se verificará en función de los datos de telemetría recibidos. Hay muchos tipos de métricas disponibles, que incluyen:
- Uso de CPU y memoria;
- uso de FIB / MAC;
- uso de memoria asociativa ternaria (TCAM) del chip;
- parámetros del puerto;
- el tamaño del búfer de la cola;
- diferentes métricas de AI Fabric;
- nivel de señal, temperatura y otros parámetros del módulo óptico;
- paquete perdido.
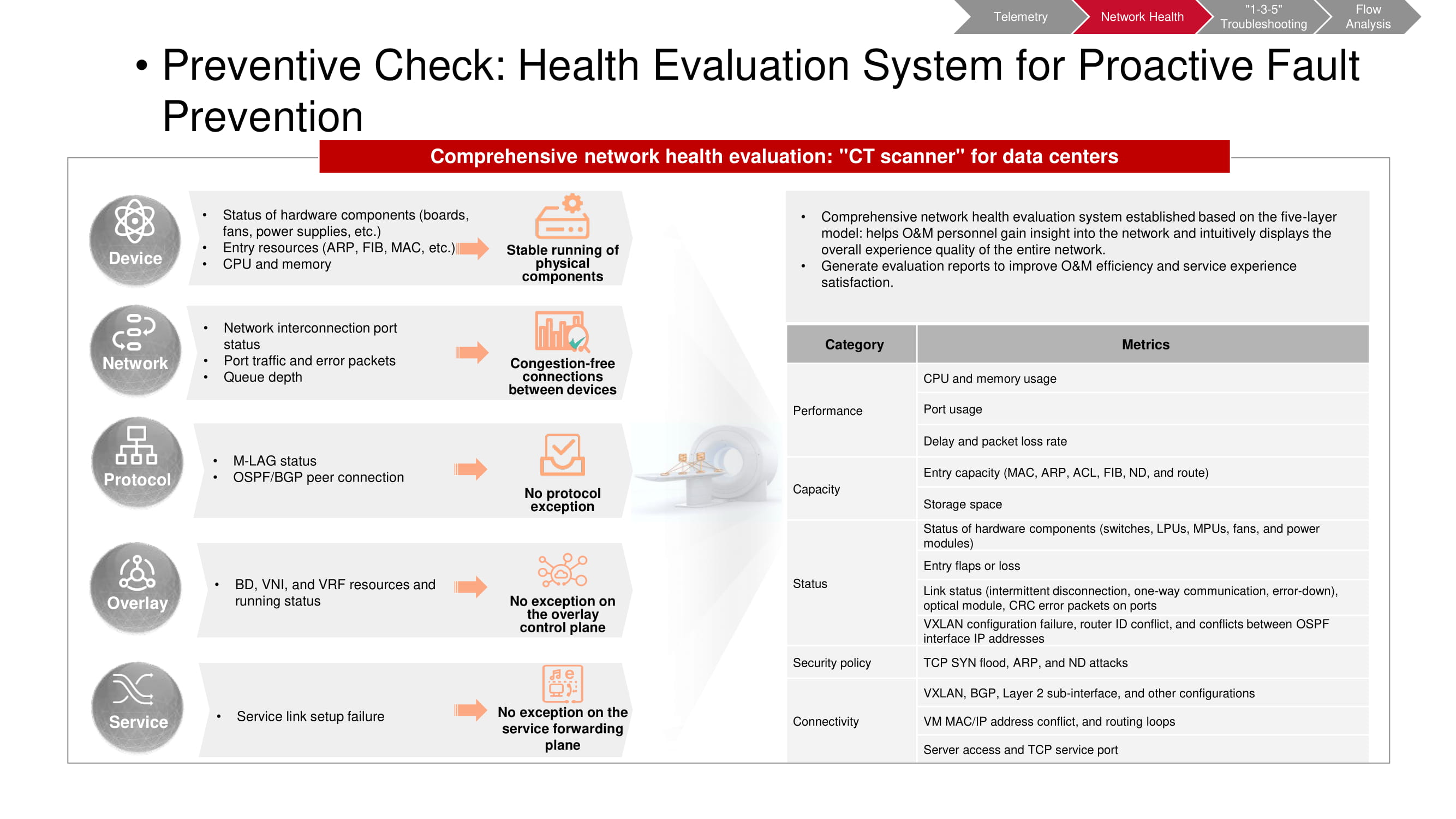
Control preliminar
La herramienta de validación previa también funciona con datos de telemetría. El escáner CT le permite comprender si se han producido ciertos eventos no deseados en la red. Algunas de las métricas coinciden con las métricas de seguimiento de KPI de la "fábrica" (principalmente relacionadas con la capacidad y el rendimiento). El resto se basa en los resultados de análisis de alto nivel (VXLAN, BGP, etc.) y análisis de configuración. Después de iniciar el escáner CT, recopila la información necesaria y genera un informe completo sobre el estado de la red.
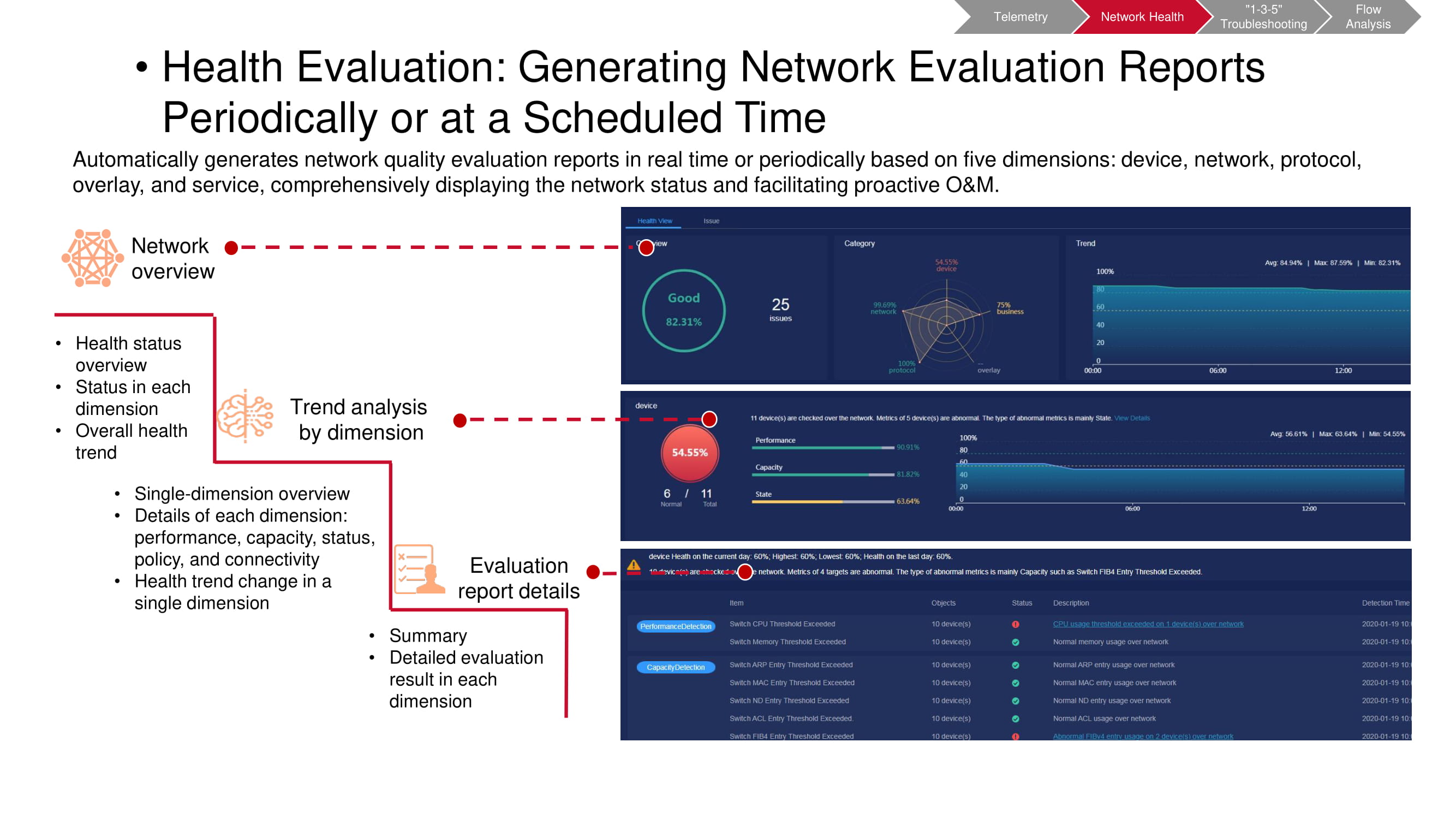
Es necesario realizar dichos controles con regularidad, habiendo predeterminado los intervalos de tiempo entre ellos. Esto hace que sea más fácil detectar las tendencias emergentes en la red a tiempo, incluidos los cambios periódicos y no periódicos. Esto le permite comprender mucho más completa y rápidamente lo que está sucediendo exactamente. Además, se puede seleccionar cualquier parámetro de particular interés para un seguimiento más detallado.
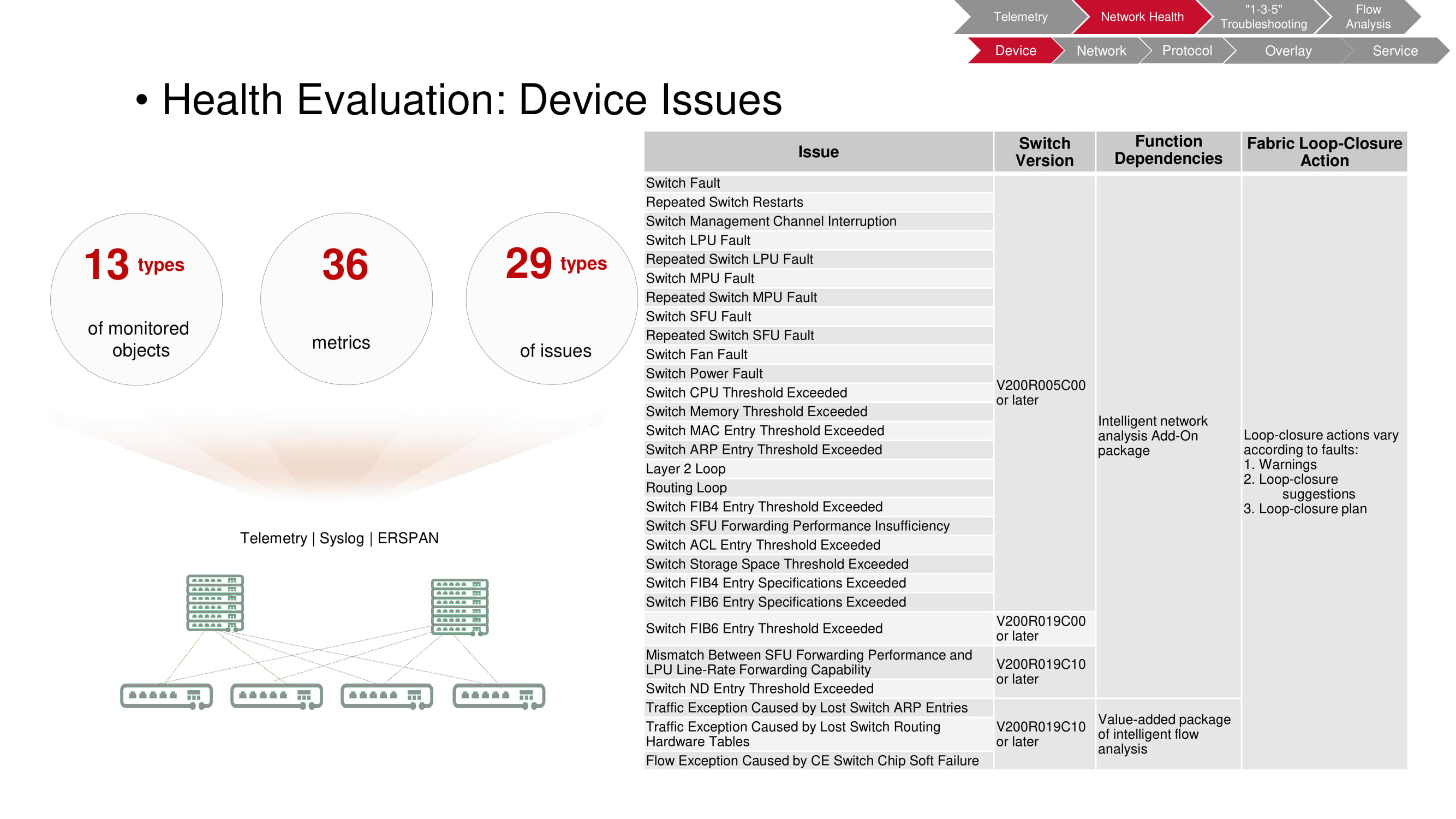
Problemas de dispositivo
El monitoreo le permite identificar una amplia variedad de problemas que surgen a nivel de dispositivo. En este caso, el objeto de verificación es un interruptor, 36 de cuyos parámetros de funcionamiento registrados permiten detectar 29 tipos de averías.
La tabla del diagrama enumera los tipos de fallas; cambie de modelo que permita a FabricInsight detectar el problema; funciones utilizadas por FabricInsight; acciones automáticas tomadas cuando se detectan problemas (advertencias, recomendaciones, lanzamiento de script).
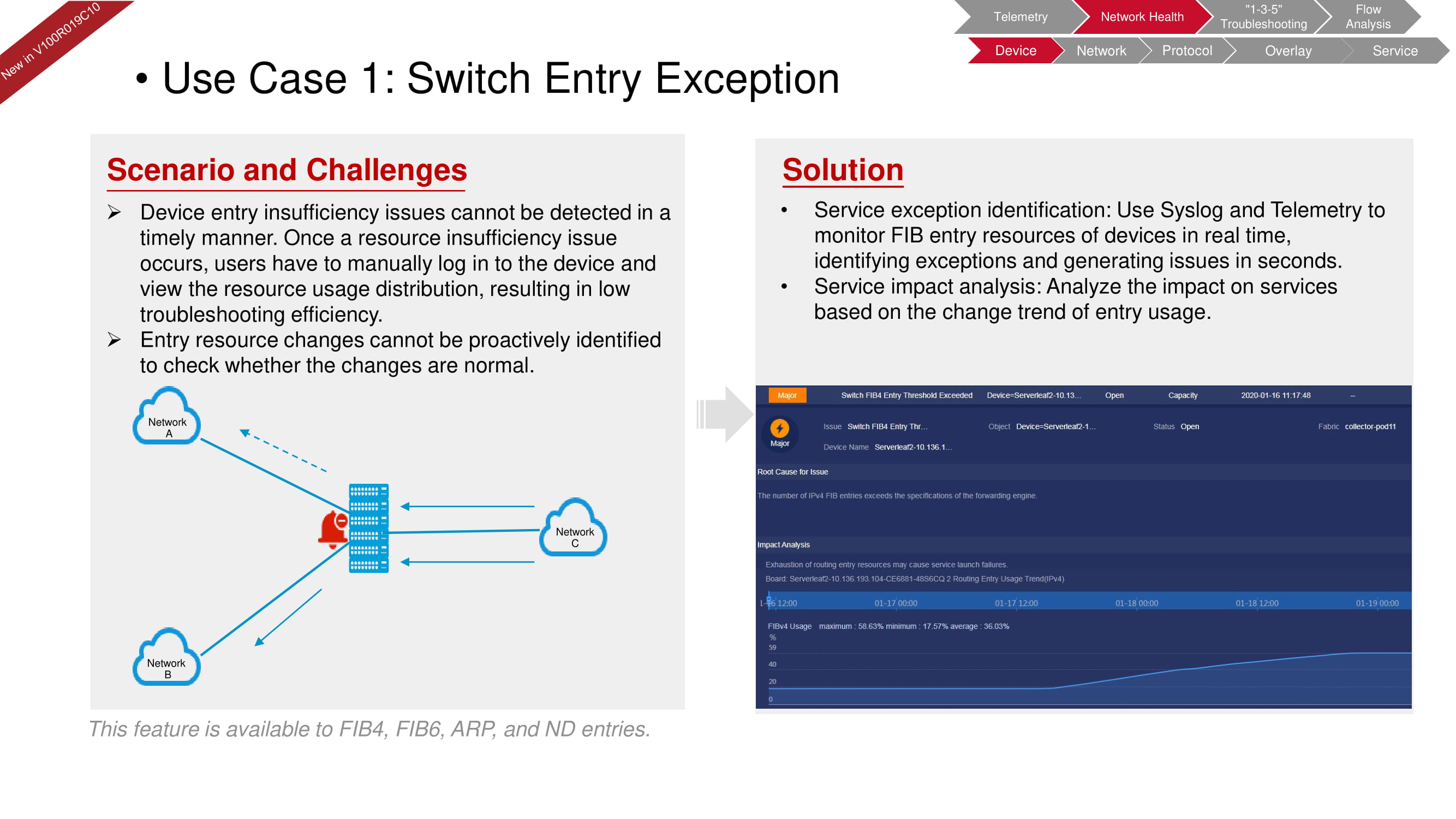
Digamos que el dispositivo tiene una escasez de recursos que conduce a una caída en el nivel de servicio. Los datos del registro del sistema, combinados con los datos de telemetría de los recursos FIB, le permiten evaluar rápidamente la situación en el modo de verificación manual.
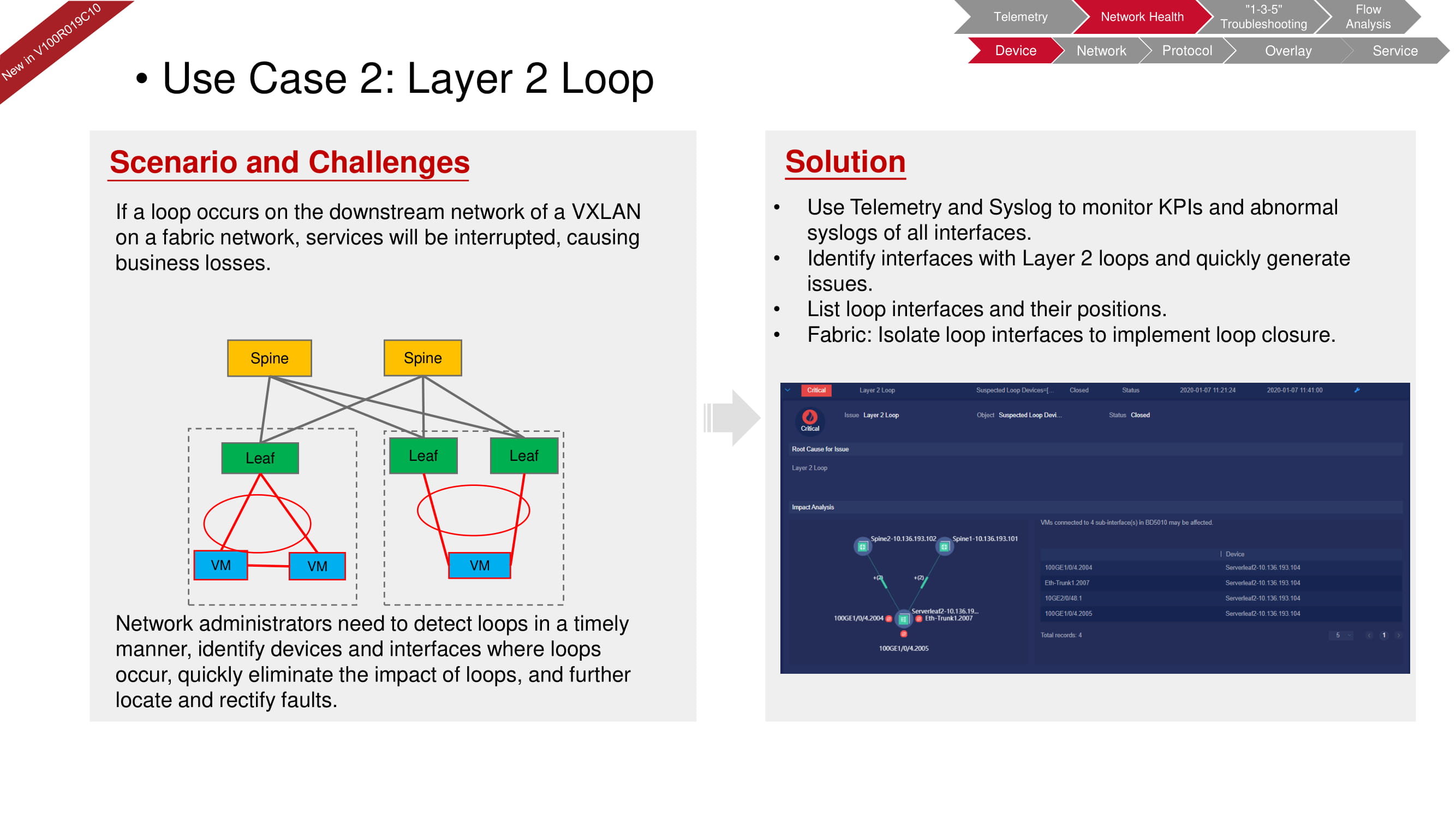
Simplemente no es posible que se produzca un bucle a nivel de hardware, ya que el dispositivo no permitirá que se introduzca tal error en la configuración. Sin embargo, puede ocurrir un bucle, por ejemplo, en el segundo nivel (en el nivel de la máquina virtual) debido a un conmutador de software configurado incorrectamente, como en el diagrama anterior. Con FabricInsight, no solo puede detectar un problema, sino también aislar la sección deseada de la red para eliminar su impacto en el funcionamiento de todo el "tejido".

Problemas de red
Basado en 18 métricas disponibles para análisis, FabricInsight identifica 10 tipos de problemas de red. El diagrama proporciona una lista completa de ellos, así como, como en el caso de problemas de dispositivos, los modelos de conmutador que permiten a FabricInsight detectar el problema, las funciones utilizadas y las acciones automáticas disponibles.

Suponga que la degradación o el mal funcionamiento de un módulo óptico conduce a un deterioro en su rendimiento: el enlace se vuelve inestable. Estas situaciones ocurren de manera irregular y son difíciles de reproducir. Esto puede llevar mucho tiempo para encontrar el problema. Con FabricInsight, puede notar inmediatamente una caída en el nivel de la señal o un cambio en el voltaje en un módulo.
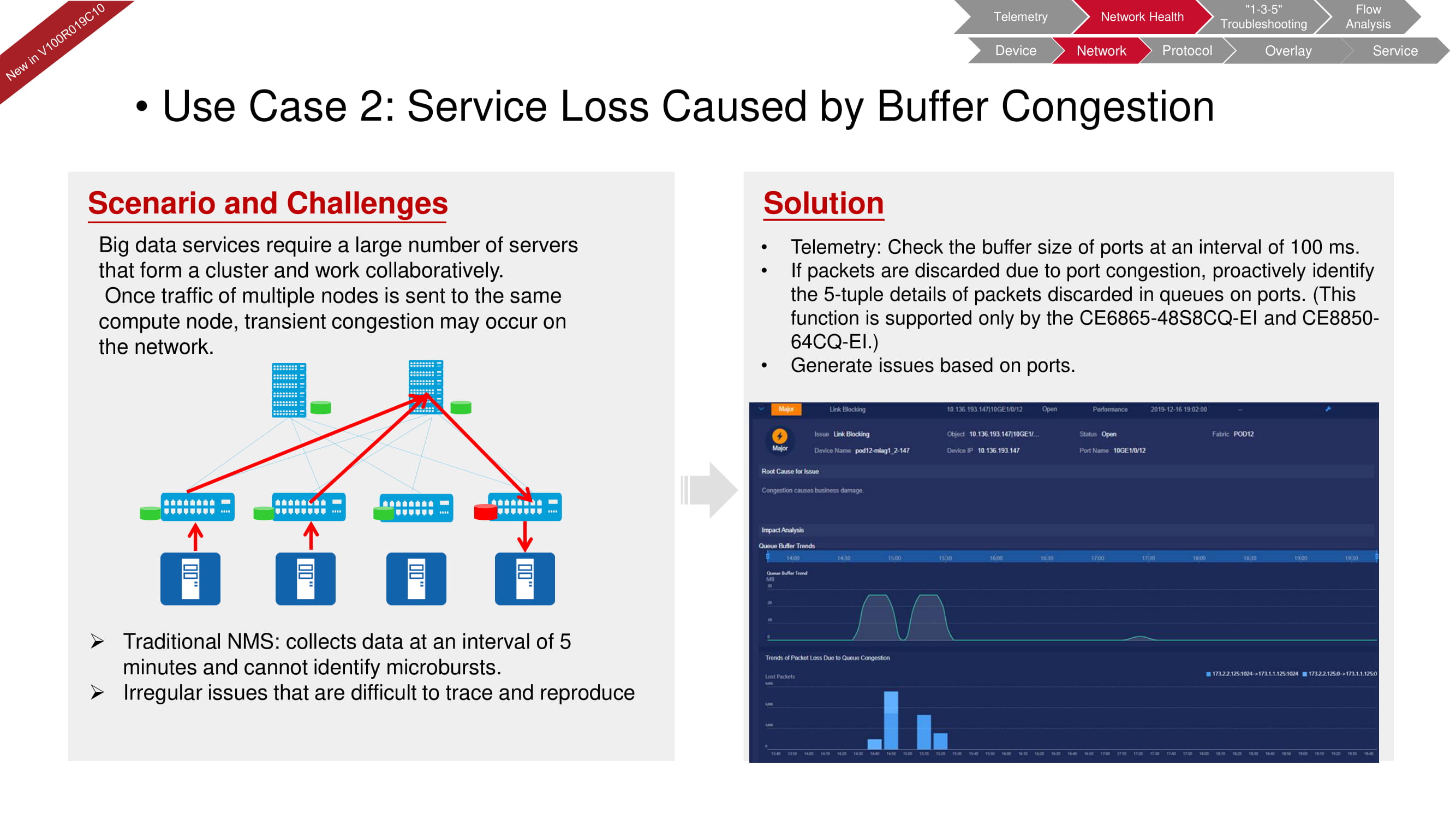
Los diagnósticos de red de fabricInsight también pueden identificar rápidamente problemas de búfer que a menudo ocurren en sistemas con una gran cantidad de servidores dedicados al procesamiento de big data. El NMS (sistema de gestión de red) tradicional comprueba los parámetros relacionados con el búfer cada cinco minutos. Las capacidades de telemetría de FabricInsight pueden reducir estos intervalos a 100 ms y detectar incluso los microincidentes más breves.

Problemas a nivel de protocolo
Aquí FabricInsight puede identificar seis tipos de problemas, incluido un conflicto entre dos conmutadores maestros en el M-LAG; problemas con la interacción de conmutadores vecinos, etc. Esta funcionalidad está disponible cuando se utilizan conmutadores V200R005C00 y posteriores.

Considere el conflicto de interruptores maestros. Con todas las ventajas de la tecnología M-LAG, en caso de rotura de un enlace y falla de la red de igual a igual, aparecen dos conmutadores maestros en el sistema. FabricInsight es capaz de responder de forma proactiva a tal situación al monitorear constantemente el estado del peer-link y DFS.

Problemas de red de superposición
Se pueden identificar siete tipos de problemas de redes superpuestas mediante la supervisión de diez métricas diferentes. FabricInsight puede verificar el estado de la licencia VXLAN, encontrar errores de configuración, detectar fallas de subinterfaces, etc. Las opciones de respuesta son similares a las descritas anteriormente.

Problemas de servicio
Se monitorean siete métricas para identificar seis tipos de problemas a nivel de servicio. Se pueden detectar conflictos de direcciones IP, problemas de conexión, ataques de inundación TCP SYN, etc. Tenga en cuenta que para admitir estas capacidades de FabricInsight, es posible que necesite un analizador de flujo TCP.
Con una mirada más amplia a la resolución de problemas, FabricInsight es más que un simple recopilador de dispositivos, sino una biblioteca extensible de scripts que abordan una amplia variedad de tipos de problemas.

De la automatización a la autonomía
A modo de resumen, diremos que la ideología de Intent-Driven Network se basa en un modelo de respuesta en tres etapas, que incluye la recolección de información, su análisis mediante IA y propuestas para cambiar el estado de la red, incluso en modo automático.
***
Le recordamos que nuestros expertos organizan seminarios web con regularidad sobre los productos Huawei y las tecnologías que utilizan. Una lista de seminarios web para las próximas semanas está disponible aquí .