En este artículo, aprenderá
- Qué es CNN y cómo funciona
- ¿Qué es un mapa de características?
- ¿Qué es la agrupación máxima?
- Funciones de pérdida para varias tareas de aprendizaje profundo
Pequeña introducción
Esta serie de artículos tiene como objetivo proporcionar una comprensión intuitiva de cómo funciona el aprendizaje profundo, cuáles son las tareas, arquitecturas de red, por qué una es mejor que la otra. Habrá pocas cosas específicas en el espíritu de "cómo implementarlo". Profundizar en cada detalle hace que el material sea demasiado complejo para la mayoría de las audiencias. Ya se ha escrito acerca de cómo funciona el gráfico de cálculo o cómo funciona la propagación inversa a través de capas convolucionales. Y, lo más importante, está escrito mucho mejor de lo que explicaría.
En el artículo anterior, discutimos FCNN: qué es y cuáles son los problemas. La solución a esos problemas radica en la arquitectura de las redes neuronales convolucionales.
Redes neuronales convolucionales (CNN)
Red neuronal convolucional. Se ve así (arquitectura vgg-16):
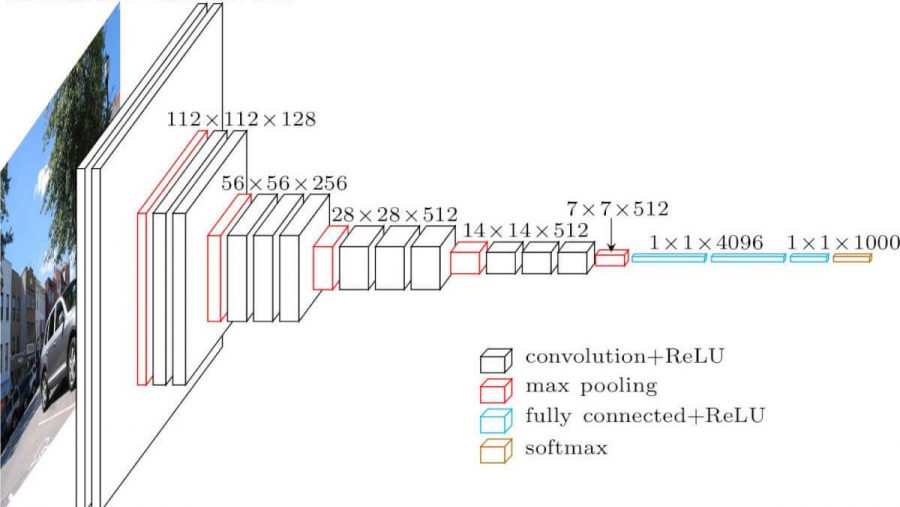
¿Cuáles son las diferencias con una red completamente mallada? Las capas ocultas ahora tienen una operación de convolución.
Así es como se ve la convolución:

Simplemente tomamos una imagen (por ahora, de un solo canal), tomamos el kernel de convolución (matriz), que consta de nuestros parámetros de entrenamiento, "superponemos" el kernel (generalmente 3x3) en la imagen y multiplicamos todos los valores de píxeles de la imagen que golpean el kernel. Luego, todo esto se resume (también necesita agregar el parámetro de sesgo - compensación), y obtenemos un número. Este número es el elemento de la capa de salida. Movemos este núcleo a lo largo de nuestra imagen con algún paso (zancada) y obtenemos los siguientes elementos. Se construye una nueva matriz a partir de dichos elementos y se le aplica el siguiente núcleo de convolución (después de aplicarle la función de activación). En el caso de que la imagen de entrada sea de tres canales, el núcleo de convolución también es de tres canales: un filtro.
Pero aquí no todo es tan sencillo. Las matrices que obtenemos después de la convolución se denominan mapas de características, porque almacenan algunas características de las matrices anteriores, pero en una forma diferente. En la práctica, se utilizan varios filtros de convolución a la vez. Esto se hace para "traer" tantas características como sea posible a la siguiente capa de convolución. Con cada capa de la convolución, nuestras características, que estaban en la imagen de entrada, se presentan cada vez más en formas abstractas.
Un par de notas más:
- Después de plegar, nuestro mapa de características se vuelve más pequeño (en ancho y alto). A veces, para reducir el ancho y la altura más débiles, o para no reducirlos en absoluto (la misma convolución), utilice el método de relleno de ceros: rellenar con ceros "a lo largo del contorno" del mapa de características de entrada.
- Después de la capa convolucional más reciente, las tareas de clasificación y regresión utilizan varias capas completamente conectadas.
¿Por qué es mejor que FCNN?
- Ahora podemos tener menos parámetros entrenables entre capas.
- Ahora, cuando extraemos características de la imagen, tenemos en cuenta no solo un píxel, sino también los píxeles cercanos (identificando ciertos patrones en la imagen).
Agrupación máxima
Se ve así:
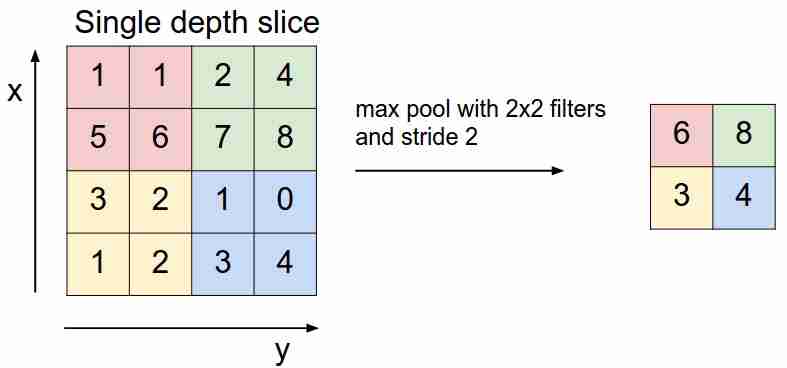
"deslizamos" sobre nuestro mapa de características con un filtro y seleccionamos solo las características más importantes (en términos de la señal entrante, como valor), disminuyendo la dimensión del mapa de características. También hay agrupación promedio (ponderada), cuando promediamos los valores que caen en el filtro, pero en la práctica es la agrupación máxima la que es más aplicable.
- Esta capa no tiene parámetros entrenables
Funciones de pérdida
Alimentamos la red X a la entrada, llegamos a la salida, calculamos el valor de la función de pérdida, realizamos el algoritmo de retropropagación: así es como aprenden las redes neuronales modernas (hasta ahora, solo estamos hablando de aprendizaje supervisado).
Se utilizan diferentes funciones de pérdida en función de las tareas que resuelven las redes neuronales:
- Problema de regresión . En su mayoría, utilizan la función de error cuadrático medio (MSE).
- Problema de clasificación . Utilizan principalmente pérdida de entropía cruzada.
Todavía no consideramos otras tareas; esto se discutirá en los siguientes artículos. ¿Por qué exactamente tales funciones para tales tareas? Aquí debe ingresar la estimación de máxima verosimilitud y las matemáticas. ¿A quién le importa? Escribí sobre eso aquí .
Conclusión
También quiero llamar su atención sobre dos cosas que se usan en las arquitecturas de redes neuronales, incluidas las convolucionales: abandono (puede leerlo aquí ) y normalización por lotes . Recomiendo mucho la lectura.
En el próximo artículo analizaremos la arquitectura de CNN, entenderemos por qué una es mejor que la otra.