
¿Por qué los petroleros necesitan PNL? ¿Cómo se consigue que una computadora comprenda la jerga profesional? ¿Es posible explicarle a la máquina qué es "presión", "respuesta del acelerador", "anular"? ¿Cómo se conectan las nuevas contrataciones y el asistente de voz? Intentaremos dar respuesta a estas preguntas en el artículo sobre la introducción de un asistente digital en el software de apoyo a la producción de petróleo, que facilita el trabajo rutinario de un geólogo-desarrollador.
En el instituto estamos desarrollando nuestro propio software ( https://rn.digital/ ) para la industria petrolera, y para que los usuarios se enamoren de él, no solo debe implementar funciones útiles en él, sino también pensar en la conveniencia de la interfaz todo el tiempo. Una de las tendencias actuales en UI / UX es la transición a interfaces de voz. Después de todo, digan lo que digan, la forma de interacción más natural y conveniente para una persona es el habla. Así que se tomó la decisión de desarrollar e implementar un asistente de voz en nuestros productos de software.
Además de mejorar el componente UI / UX, la implementación del asistente también le permite reducir el "umbral" para que los nuevos empleados trabajen con software. La funcionalidad de nuestros programas es amplia y puede llevar más de un día resolverla. La capacidad de "pedir" al asistente que ejecute el comando deseado reducirá el tiempo dedicado a resolver la tarea, así como también reducirá el estrés de un nuevo trabajo.
Dado que el servicio de seguridad corporativa es muy sensible a la transferencia de datos a servicios externos, pensamos en desarrollar un asistente basado en soluciones de código abierto que nos permitan procesar información de manera local.
Estructuralmente, nuestro asistente consta de los siguientes módulos:
- Reconocimiento de voz (ASR)
- Selección de objetos semánticos (Comprensión del lenguaje natural, NLU)
- Ejecución de comandos
- Síntesis de voz (Text-to-Speech, TTS)
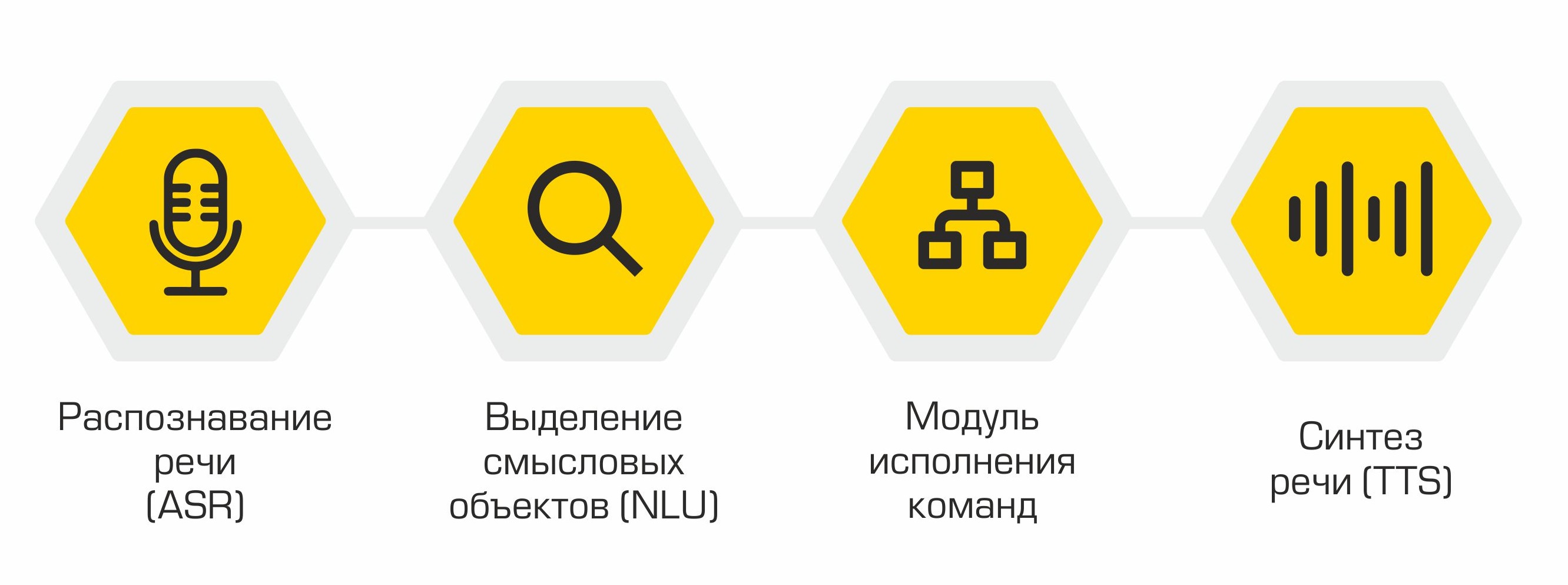
El principio del asistente: ¡de palabras (usuario) a acciones (en software)!
La salida de cada módulo sirve como punto de entrada para el siguiente componente del sistema. Por lo tanto, la voz del usuario se convierte en texto y se envía para su procesamiento a algoritmos de aprendizaje automático para determinar la intención del usuario. Dependiendo de esta intención, la clase requerida se activa en el módulo de ejecución de comandos, que atiende la solicitud del usuario. Una vez completada la operación, el módulo de ejecución de comandos transmite información sobre el estado de ejecución de comandos al módulo de síntesis de voz, que, a su vez, notifica al usuario.
Cada módulo auxiliar es un microservicio. Entonces, si lo desea, el usuario puede prescindir de las tecnologías de voz y recurrir directamente al "cerebro" del asistente, al módulo para resaltar objetos semánticos, a través de la forma de un bot de chat.
Reconocimiento de voz
La primera etapa del reconocimiento de voz es el procesamiento de señales de voz y la extracción de características. La representación más simple de una señal de audio es un oscilograma. Refleja la cantidad de energía en un momento dado. Sin embargo, esta información no es suficiente para determinar el sonido hablado. Es importante para nosotros saber cuánta energía hay en diferentes rangos de frecuencia. Para ello, utilizando la transformada de Fourier, se realiza una transición del oscilograma al espectro.
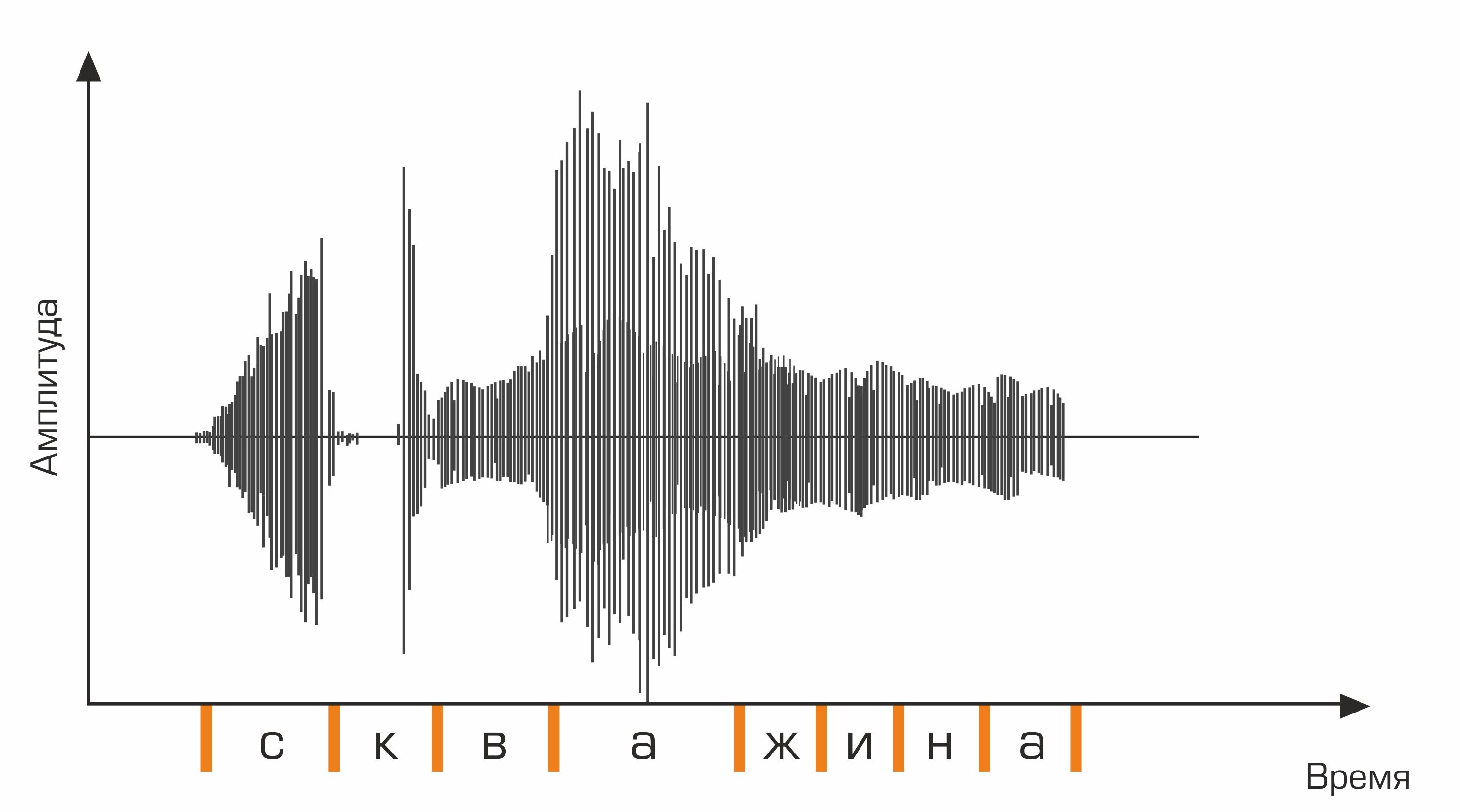
Este es un oscilograma.
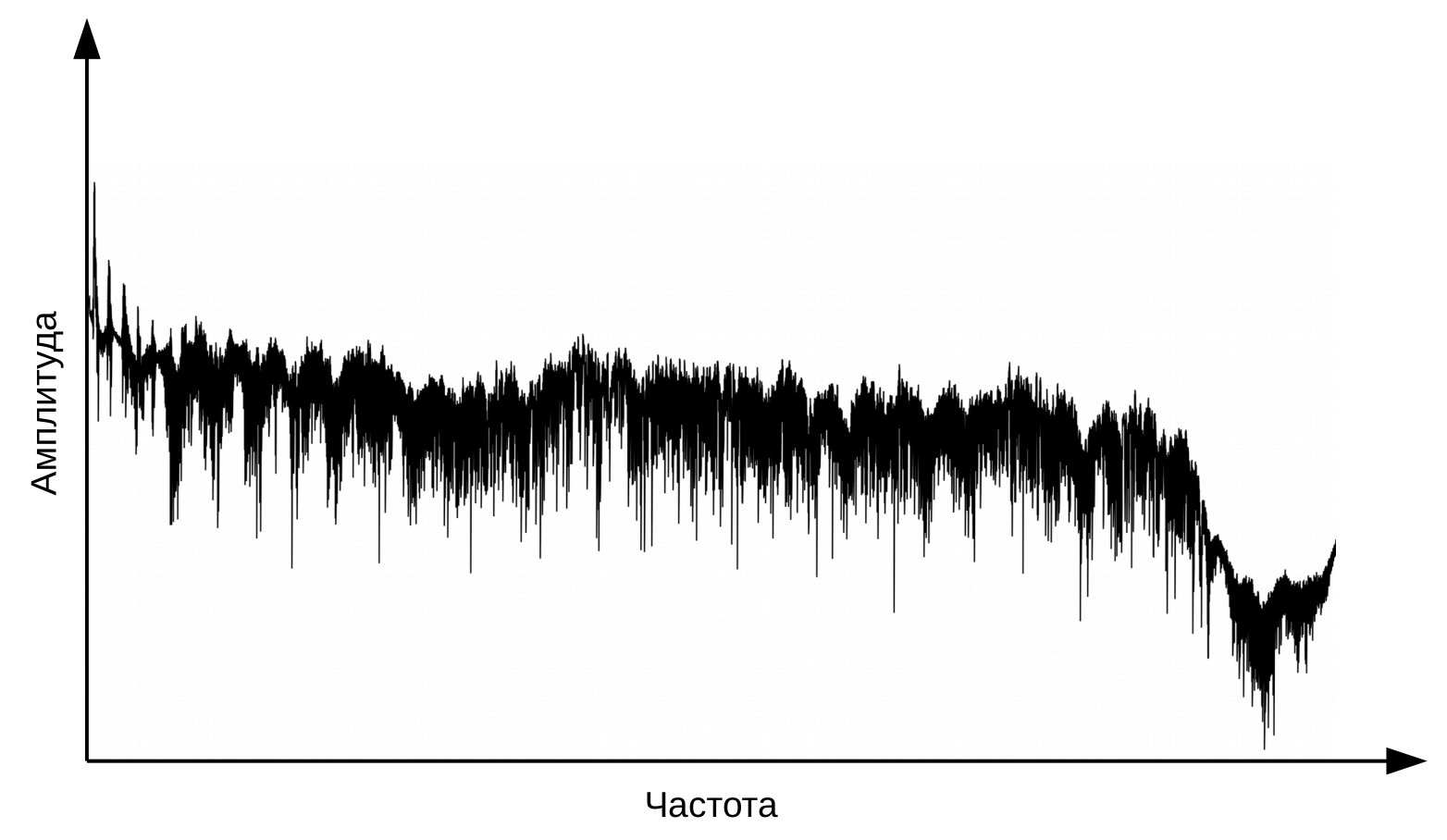
Y este es el espectro de cada momento.
Aquí es necesario aclarar que el habla se forma cuando una corriente de aire vibrante pasa por la laringe (fuente) y el tracto vocal (filtro). Para la clasificación de fonemas, solo necesitamos información sobre la configuración del filtro, es decir, sobre la posición de los labios y la lengua. Esta información se puede distinguir por la transición de espectro a cepstrum (cepstrum - un anagrama de la palabra espectro), realizada utilizando la transformada de Fourier inversa del logaritmo del espectro. Nuevamente, el eje x no es la frecuencia, sino el tiempo. El término "frecuencia" se utiliza para distinguir entre los dominios de tiempo del cepstrum y la señal de audio original (Oppenheim, Schafer. Digital Signal Processing, 2018).
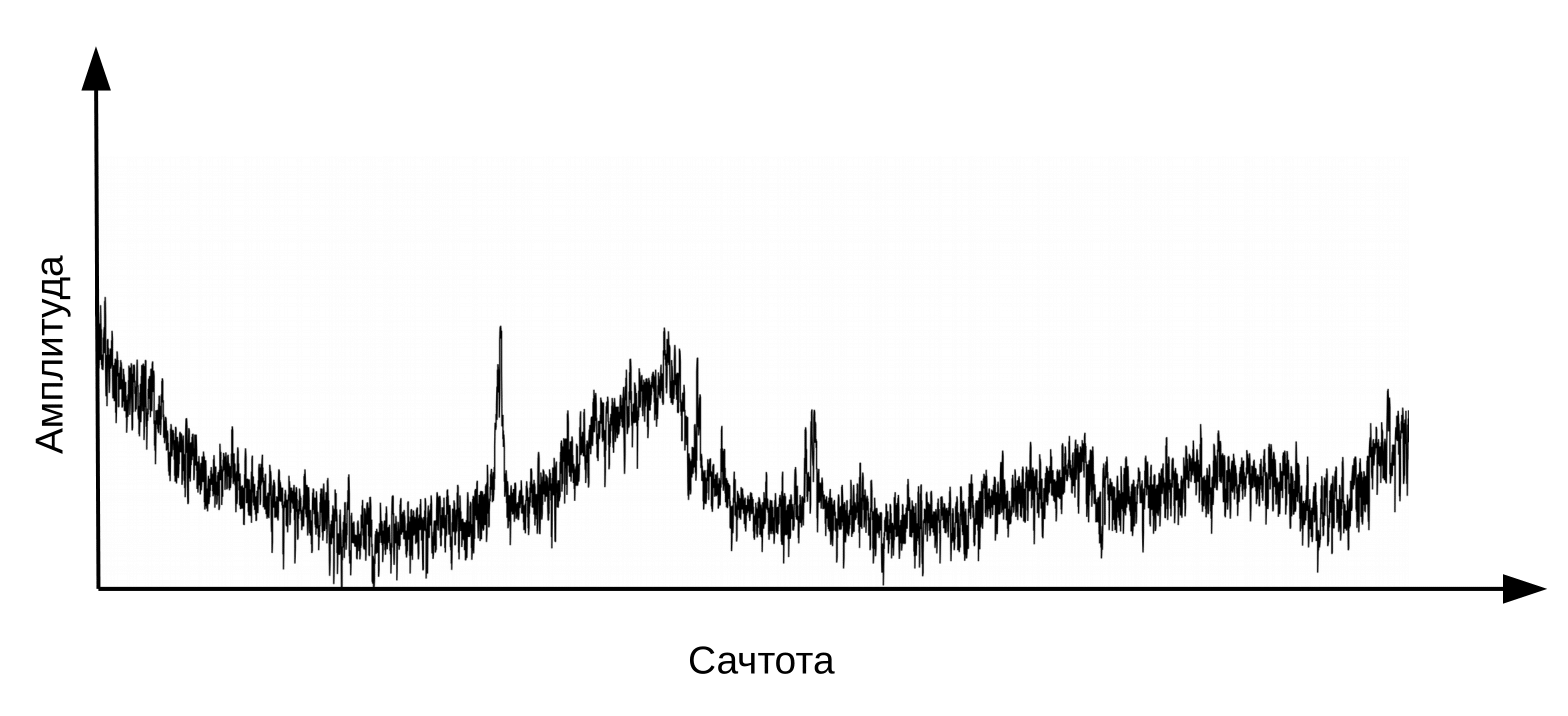
Cepstrum, o simplemente "espectro del logaritmo del espectro". Sí, sí, común es un término , no un error tipográfico
La información sobre la posición del tracto vocal se encuentra en los primeros 12 coeficientes cepstrum. Estos 12 coeficientes cepstrales se complementan con características dinámicas (delta y delta-delta) que describen los cambios en la señal de audio. (Jurafsky, Martin. Procesamiento del habla y el lenguaje, 2008). El vector de valores resultante se denomina vector MFCC (coeficientes cepstrales de frecuencia Mel) y es la característica acústica más común utilizada en el reconocimiento de voz.
¿Qué pasa después con las señales? Se utilizan como entrada al modelo acústico. Muestra qué unidad lingüística es más probable que "genere" tal vector MFCC. En diferentes sistemas, estas unidades lingüísticas pueden ser parte de fonemas, fonemas o incluso palabras. Por tanto, el modelo acústico transforma una secuencia de vectores MFCC en una secuencia de fonemas más probables.
Además, para la secuencia de fonemas, es necesario seleccionar la secuencia apropiada de palabras. Aquí es donde entra en juego el diccionario de idiomas, que contiene la transcripción de todas las palabras reconocidas por el sistema. La compilación de dichos diccionarios es un proceso laborioso que requiere un conocimiento experto en fonética y fonología de un idioma en particular. Un ejemplo de una línea de un diccionario de transcripciones:
bueno skv aa zh yn ay
En el siguiente paso, el modelo de lenguaje determina la probabilidad previa de la oración en el lenguaje. En otras palabras, el modelo da una estimación de la probabilidad de que una oración de este tipo aparezca en un idioma. Un buen modelo de lenguaje determinará que la frase "Graficar la tasa de petróleo" es más probable que la frase "Graficar el petróleo nueve".
La combinación de un modelo acústico, un modelo de lenguaje y un diccionario de pronunciación crea una “cuadrícula” de hipótesis: todas las posibles secuencias de palabras a partir de las cuales se puede encontrar la más probable utilizando el algoritmo de programación dinámica. Su sistema lo ofrecerá como texto reconocido.
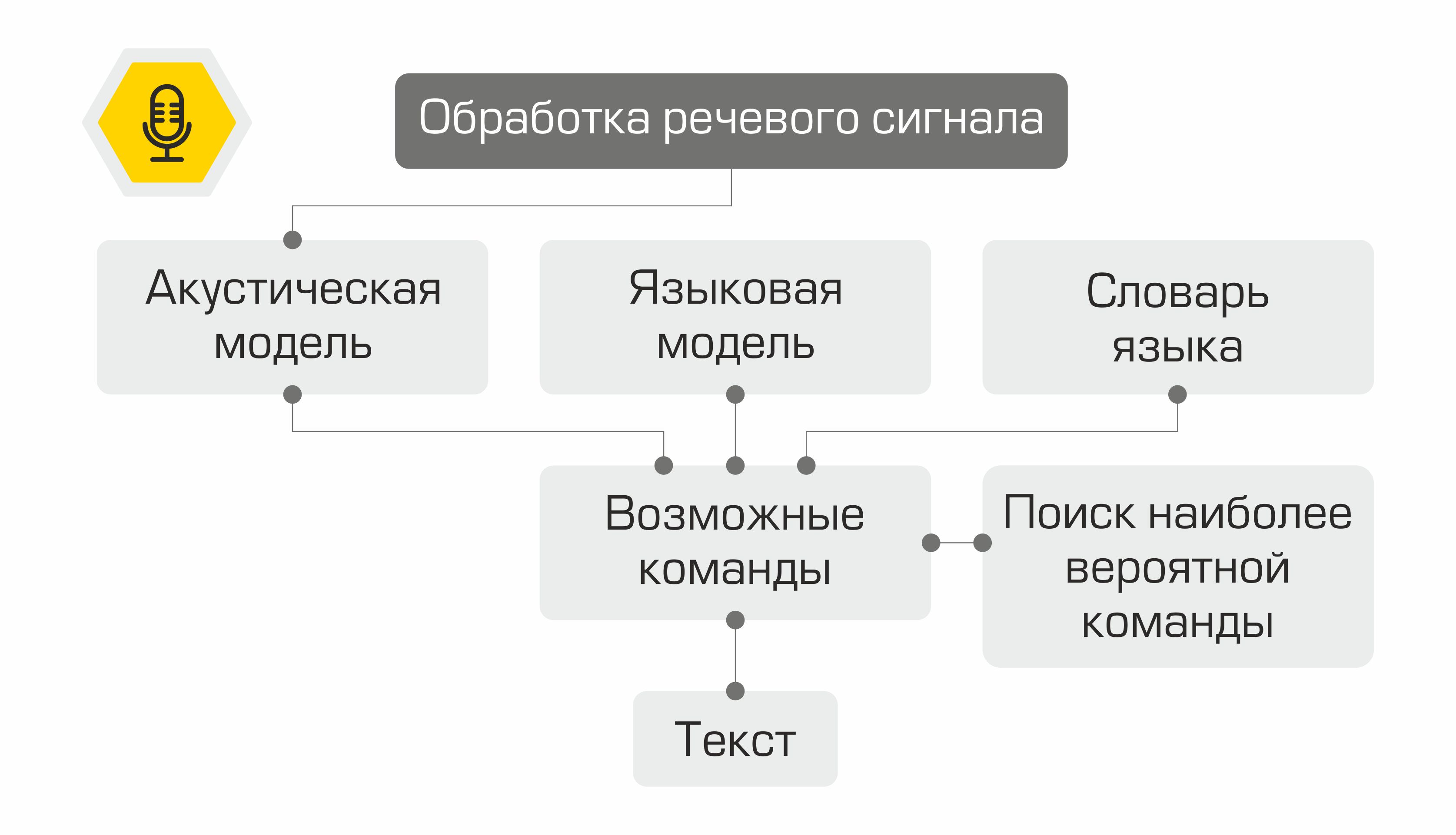
Representación esquemática del funcionamiento del sistema de reconocimiento de voz.
No sería práctico reinventar la rueda y escribir una biblioteca de reconocimiento de voz desde cero, por lo que nuestra elección recayó en el marco kaldi . La indudable ventaja de la biblioteca es su flexibilidad, permitiendo, si es necesario, crear y modificar todos los componentes del sistema. Además, la licencia Apache 2.0 le permite utilizar libremente la biblioteca en el desarrollo comercial.
Como datos para entrenar un modelo acústico se utilizó el conjunto de datos de audio gratuito VoxForge . Para convertir una secuencia de fonemas en palabras, utilizamos el diccionario ruso proporcionado por la biblioteca CMU Sphinx . Dado que el diccionario no contenía la pronunciación de términos específicos de la industria petrolera, se basó en él, utilizando la utilidadg2p-seq2seq entrenó un modelo de grafema a fonema para crear rápidamente transcripciones de nuevas palabras. El modelo de lenguaje se entrenó tanto en transcripciones de audio de VoxForge como en un conjunto de datos que creamos, que contiene los términos de la industria del petróleo y el gas, los nombres de los campos y las empresas mineras.
Selección de objetos semánticos
Entonces, reconocimos el habla del usuario, pero esto es solo una línea de texto. ¿Cómo le dices a la computadora qué hacer? Los primeros sistemas de control por voz utilizaban un conjunto de comandos muy limitado. Habiendo reconocido una de estas frases, fue posible llamar a la operación correspondiente. Desde entonces, las tecnologías en el procesamiento y la comprensión del lenguaje natural (NLP y NLU, respectivamente) han avanzado. Ya hoy en día, los modelos entrenados en grandes cantidades de datos pueden comprender bien el significado de una declaración.
Para extraer significado del texto de una frase reconocida, es necesario resolver dos problemas de aprendizaje automático:
- Clasificación del equipo de usuarios (clasificación por intención).
- Asignación de entidades nombradas (reconocimiento de entidad nombrada).
Al desarrollar los modelos, utilizamos la biblioteca Rasa de código abierto , distribuida bajo la Licencia Apache 2.0.
Para resolver el primer problema, es necesario presentar el texto como un vector numérico que puede ser procesado por una máquina. Para tal transformación, se utiliza el modelo neuronal StarSpace , que le permite " anidar " el texto de solicitud y la clase de solicitud en un espacio común.

Modelo neuronal StarSpace
Durante el entrenamiento, la red neuronal aprende a comparar entidades, para minimizar la distancia entre el vector de solicitud y el vector de la clase correcta y maximizar la distancia a los vectores de diferentes clases. Durante la prueba, se selecciona la clase y para la consulta x de modo que:
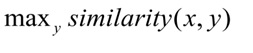
La distancia del coseno se usa como una medida de la similitud de los vectores:,
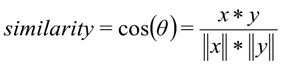
donde
x es la solicitud del usuario, y es la categoría de solicitud.
Se etiquetaron 3000 consultas para entrenar al clasificador de intenciones del usuario. En total, nos graduamos de 8 clases. Dividimos la muestra en muestras de entrenamiento y de prueba en una proporción de 70/30 utilizando el método de estratificación de variables objetivo. La estratificación nos permitió conservar la distribución original de clases en el tren y la prueba. La calidad del modelo entrenado se evaluó mediante varios criterios a la vez:
- Recordar: la proporción de solicitudes clasificadas correctamente para todas las solicitudes de esta clase.
- La proporción de solicitudes correctamente clasificadas (precisión).
- Precisión: la proporción de solicitudes clasificadas correctamente en relación con todas las solicitudes que el sistema asignó a esta clase.
- F1 – .
Además, la matriz de errores del sistema se utiliza para evaluar la calidad del modelo de clasificación. El eje y es la clase verdadera de la declaración, el eje x es la clase predicha por el algoritmo.
En la muestra de control, el modelo mostró los siguientes resultados:
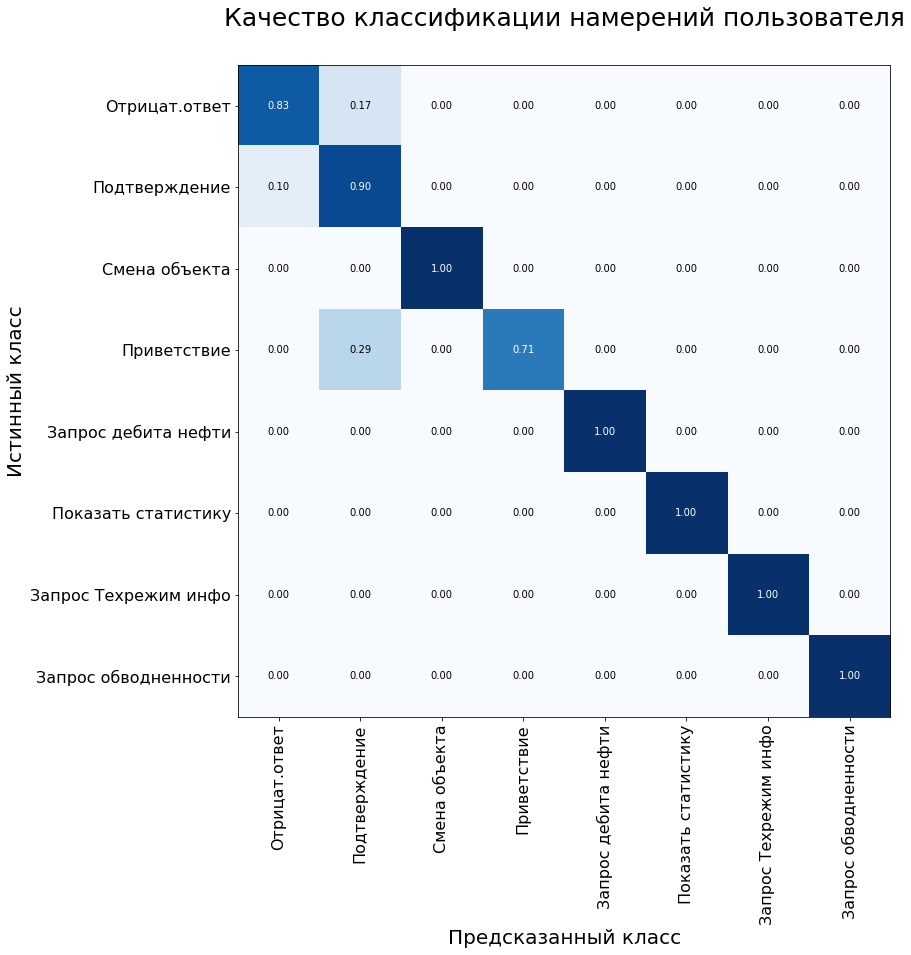
Métricas del modelo en el conjunto de datos de prueba: Precisión - 92%, F1 - 90%.
La segunda tarea, la selección de entidades nombradas, es identificar palabras y frases que denotan un objeto o fenómeno específico. Estas entidades pueden ser, por ejemplo, el nombre de un depósito o una empresa minera.
Para resolver el problema, utilizamos un algoritmo de campos aleatorios condicionales, que son una especie de campos de Markov. CRF es un modelo discriminativo, es decir, modela la probabilidad condicional P(Y | X) estado latente Y (clase de palabra) de la observación X (palabra).
Para satisfacer las solicitudes de los usuarios, nuestro asistente debe resaltar tres tipos de entidades nombradas: nombre de campo, nombre de pozo y nombre de objeto de desarrollo. Para entrenar el modelo, preparamos un conjunto de datos e hicimos una anotación: a cada palabra de la muestra se le asignó una clase correspondiente.

Un ejemplo del conjunto de entrenamiento para el problema de reconocimiento de entidades nombradas.
Sin embargo, todo resultó no ser tan simple. La jerga profesional es bastante común entre los desarrolladores de campo y los geólogos. No es difícil para la gente entender que el "inyector" es un pozo de inyección, y "Samotlor", muy probablemente, significa el campo Samotlor. Para un modelo entrenado con una cantidad limitada de datos, todavía es difícil trazar tal paralelo. Una característica maravillosa de la biblioteca Rasa, como la creación de un diccionario de sinónimos, ayuda a superar esta limitación.
## sinónimo: Samotlor
- Samotlor
- Samotlor
- el campo petrolero más grande de Rusia
La adición de sinónimos también nos permitió ampliar ligeramente la muestra. El volumen de todo el conjunto de datos fue de 2000 solicitudes, que dividimos en entrenar y probar en una proporción de 70/30. La calidad del modelo se evaluó utilizando la métrica F1 y fue del 98% cuando se probó en una muestra de control.
Ejecución de comandos
Dependiendo de la clase de solicitud del usuario definida en el paso anterior, el sistema activa la clase correspondiente en el kernel del software. Cada clase tiene al menos dos métodos: un método que ejecuta directamente la solicitud y un método para generar una respuesta para el usuario.
Por ejemplo, al asignar un comando a la clase "request_production_schedule", se crea un objeto de la clase RequestOilChart, que descarga información sobre la producción de petróleo de la base de datos. Las entidades con nombre dedicadas (por ejemplo, nombres de pozos y campos) se utilizan para llenar los espacios en las consultas para acceder a la base de datos o al kernel del software. El asistente responde con la ayuda de plantillas preparadas, los espacios en los que se llenan con los valores de los datos cargados.

Un ejemplo de funcionamiento de un prototipo de asistente.
Síntesis de voz

Cómo funciona la síntesis de voz concatenada
El texto de notificación de usuario generado en la etapa anterior se muestra en la pantalla y también se utiliza como entrada para el módulo de síntesis de voz oral. La generación de voz se lleva a cabo utilizando la biblioteca RHVoice... La licencia GNU LGPL v2.1 permite que el marco se utilice como un componente de software comercial. Los componentes principales de un sistema de síntesis de voz son un procesador lingüístico que procesa el texto proporcionado como entrada. Se normaliza el texto: se reducen los números a representación escrita, se descifran las abreviaturas, etc. Luego, utilizando el diccionario de pronunciación, se crea una transcripción del texto, que luego se transmite a la entrada del procesador acústico. Este componente es responsable de seleccionar elementos de sonido de la base de datos de voz, concatenando los elementos seleccionados y procesando la señal de sonido.
Poniendolo todo junto
Entonces, todos los componentes del asistente de voz están listos. Solo queda "recopilarlos" en la secuencia correcta y probarlos. Como mencionamos anteriormente, cada módulo es un microservicio. El marco RabbitMQ se utiliza como bus para conectar todos los módulos. La ilustración muestra claramente el trabajo interno del asistente utilizando el ejemplo de una solicitud de usuario típica:
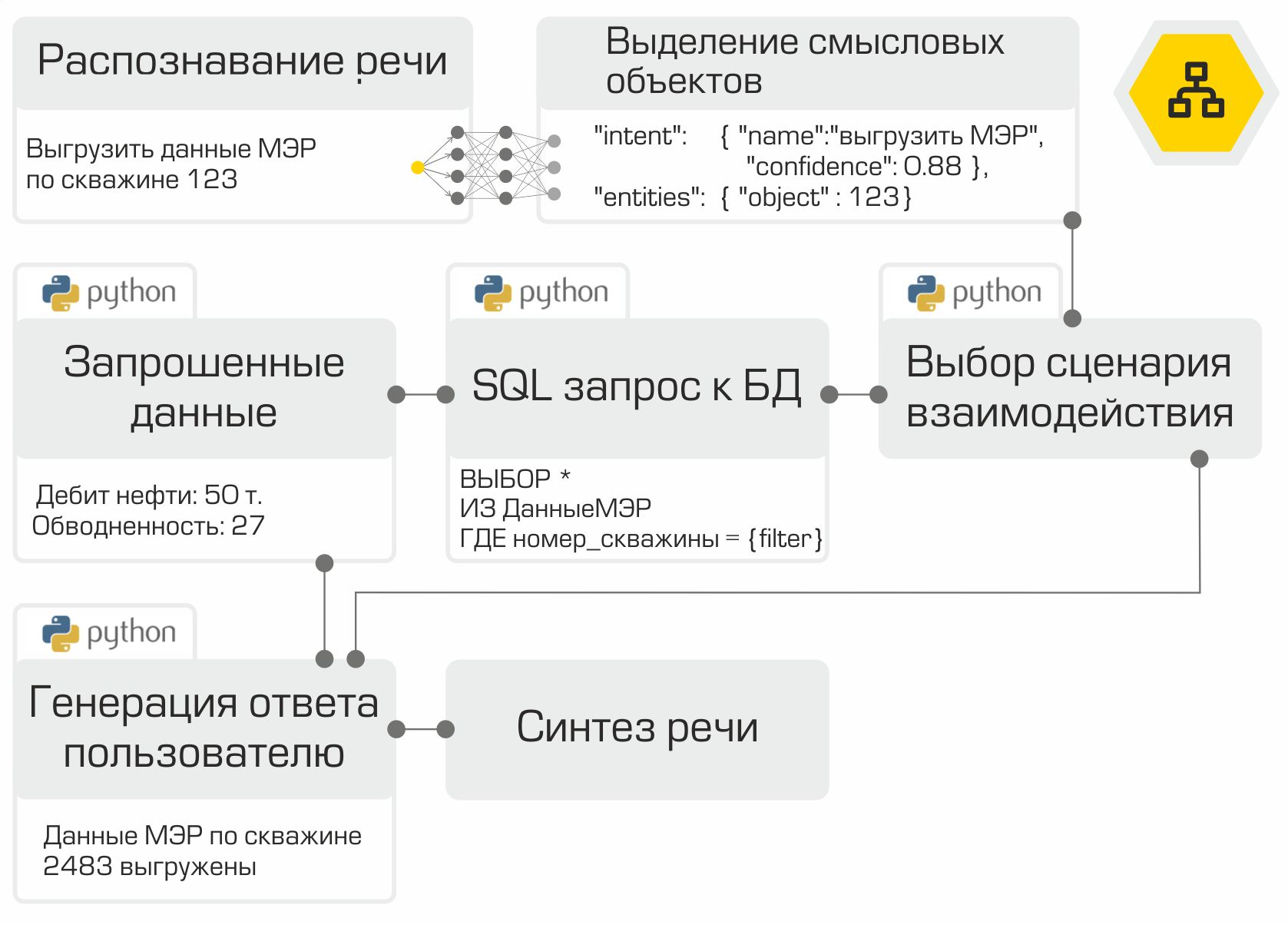
la solución creada permite colocar toda la infraestructura en la red de la empresa. El procesamiento de información local es la principal ventaja del sistema. Sin embargo, debe pagar por la autonomía porque debe recopilar datos, entrenar y probar modelos usted mismo, y no usar el poder de los principales proveedores en el mercado de asistentes digitales.
Actualmente estamos integrando el asistente en uno de nuestros productos.
¡Qué conveniente será buscar tu pozo o tu arbusto favorito con una sola frase!
En la siguiente etapa, está previsto recopilar y analizar los comentarios de los usuarios. También hay planes para expandir los comandos reconocidos y ejecutados por el asistente.
El proyecto descrito en el artículo está lejos de ser el único ejemplo del uso de métodos de aprendizaje automático en nuestra Compañía. Por ejemplo, el análisis de datos se utiliza para seleccionar automáticamente los pozos candidatos para medidas geológicas y técnicas, cuyo propósito es estimular la producción de petróleo. En uno de los próximos artículos, le diremos cómo resolvimos este interesante problema. ¡Suscríbete a nuestro blog para no perdértelo!