
Según un chiste bien conocido, todas las memorias en las librerías deberían ubicarse en la sección "Ciencia ficción". Pero en mi caso, ¡esto es cierto! Hace mucho tiempo,
3D Talking Heads: este es un busto de bronce de Max Planck que se pega la lengua y parpadea; un mono que copia tus expresiones faciales en tiempo real; este es un modelo 3D de un jefe completamente reconocible del vicepresidente de Intel, creado de forma totalmente automática a partir de video con su participación, y mucho más ... Pero lo primero es lo primero.
Vídeo sintético: 3D Talking Heads compatible con MPEG-4 es el nombre completo del proyecto llevado a cabo en el Centro de Investigación y Desarrollo Intel Nizhny Novgorod en 2000-2003. El desarrollo fue un conjunto de tres tecnologías principales que se pueden usar juntas y por separado en muchas aplicaciones relacionadas con la creación y animación de personajes de habla tridimensionales sintéticos.
- Reconocimiento y seguimiento automático de expresiones faciales y movimientos de la cabeza humana en la secuencia de video. Al mismo tiempo, no solo se evalúan los ángulos de rotación e inclinación de la cabeza en todos los planos, sino también los contornos externos e internos de los labios y dientes durante la conversación, la posición de las cejas, el grado de cobertura ocular e incluso la dirección de la mirada.
- Animación automática en tiempo real de modelos de cabeza tridimensionales casi arbitrarios de acuerdo con los parámetros de animación obtenidos mediante los algoritmos de reconocimiento y seguimiento desde el primer punto así como desde cualquier otra fuente.
- Creación automática de un modelo 3D fotorrealista de la cabeza de una persona específica utilizando dos fotografías del prototipo (vistas frontal y lateral) o una secuencia de video en la que una persona gira la cabeza de un hombro a otro.
Y otra ventaja: la tecnología, o mejor dicho, algunos trucos de interpretación realista de "cabezas parlantes" en tiempo real, teniendo en cuenta las limitaciones de rendimiento del hardware y las capacidades del software que existían a principios de la década de 2000.
Y el vínculo entre estos tres puntos y medio, así como el vínculo a Intel, son cuatro letras y un número: MPEG-4.
MPEG-4
Pocas personas saben que el estándar MPEG-4 , que apareció en 1998, además de codificar secuencias de audio y video reales y ordinarias, proporciona la codificación de información sobre objetos sintéticos y su animación, el llamado video sintético. Uno de estos objetos es un rostro humano, más precisamente, una cabeza definida como una superficie triangulada, una malla en el espacio 3D. MPEG-4 define 84 puntos especiales en la cara de una persona - Puntos de características (FP): esquinas y puntos medios de los labios, ojos, cejas, punta de la nariz, etc.
Los parámetros de animación facial (FAP) se aplican a estos puntos especiales (o al modelo completo como un todo en el caso de giros e inclinaciones), describiendo el cambio en la posición y la expresión facial en comparación con el estado neutral.
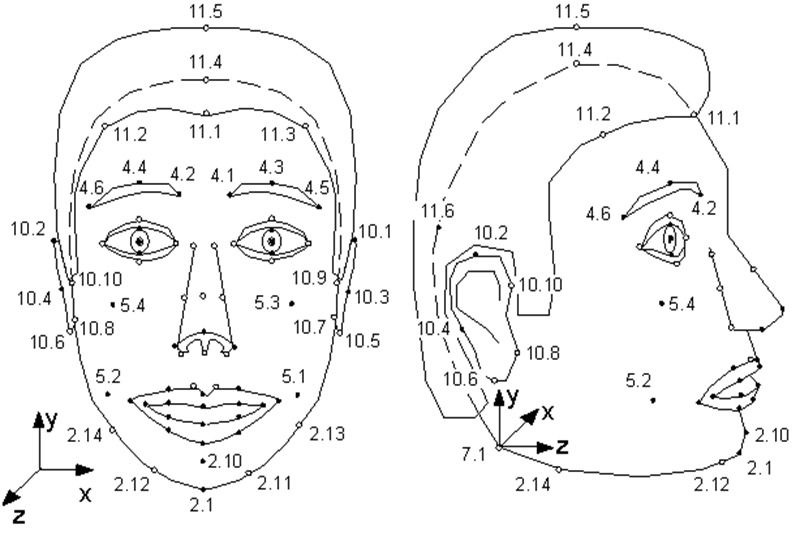
Ilustración de la especificación MPEG-4. Puntos singulares del modelo. Como puede ver, la modelo puede oler y mover las orejas.
Es decir, la descripción de cada fotograma de vídeo sintético que muestra al personaje hablante parece un pequeño conjunto de parámetros mediante los cuales el decodificador MPEG-4 debe animar el modelo.
¿Cual modelo? MPEG-4 tiene dos opciones. O el codificador crea el modelo y lo transmite al decodificador una vez al comienzo de la secuencia, o el decodificador tiene su propio modelo patentado, que se utiliza en la animación.
Al mismo tiempo, los únicos requisitos de MPEG-4 para el modelo: almacenamiento en VRML-formato y presencia de puntos especiales. Es decir, un modelo puede servir como una copia fotorrealista de una persona cuya FAP se usa para la animación, así como un modelo de cualquier otra persona, e incluso una tetera parlante; lo principal es que él, además de una nariz, tiene boca y ojos.

Uno de nuestros modelos compatibles con MPEG-4 es el más sonriente
Además del objeto principal "rostro", MPEG-4 describe objetos independientes "mandíbula superior", "mandíbula inferior", "lengua", "ojos", en los que también se establecen puntos especiales. Pero si algún modelo no tiene estos objetos, entonces el decodificador simplemente no utiliza los FAP correspondientes.

- Modelo, modelo, ¿por qué tienes ojos y dientes tan grandes? - ¡Para animarte mejor!
¿De dónde proceden los modelos de animación personalizados? ¿Cómo obtengo la FAP? Y finalmente, ¿cómo implementar animación y renderizado realistas basados en estos FAP? MPEG-4 no da ninguna respuesta a todas estas preguntas, al igual que cualquier estándar de compresión de video no dice nada sobre el proceso de filmación y el contenido de las películas que codifica.
¿Hasta dónde ha llegado el progreso? ¡Hasta milagros sin precedentes!
Por supuesto, tanto el modelo como la animación pueden ser creados manualmente por artistas profesionales, dedicando decenas de horas a ello y recibiendo decenas de cientos de dólares. Pero esto reduce significativamente el alcance de la tecnología, haciéndola inaplicable a escala industrial. Y hay muchos usos potenciales para la tecnología, que en realidad comprime fotogramas de video de alta definición en varios bytes (oh, es una pena que no cualquier video). En primer lugar, la creación de redes: juegos, educación y comunicación (videoconferencia) utilizando caracteres sintéticos.
Estas aplicaciones eran especialmente relevantes hace 20 años, cuando todavía se accedía a Internet mediante módems, y la Internet ilimitada gigabit parecía una especie de teletransportación. Pero, como muestra la vida, en 2020, el ancho de banda de los canales de Internet en muchos casos sigue siendo un problema. E incluso si no existe tal problema, digamos, estamos hablando de uso local, los caracteres sintéticos son capaces de mucho. Digamos, "resucitar" en una película a un actor famoso del siglo pasado, o dar la oportunidad de mirar a los ojos a los ahora populares y todavía incorpóreos asistentes de voz. Pero primero, el proceso de transición de un video real de una persona que habla a uno sintético debe volverse automático, o al menos, con una mínima participación humana.
Esto es exactamente lo que se implementó en Nizhny Novgorod Intel. La idea surgió primero como parte de la implementación de la biblioteca de procesamiento MPEG, desarrollada en un momento por Intel, y luego se convirtió no solo en una escisión completa, sino en un verdadero éxito de taquilla fantástico.
Además, completamente "hecho en Rusia" - este proyecto, al parecer, fue el único durante toda la existencia de Intel ruso, no había curador en Intel USA. A Justin Ratner (jefe de la división de investigación de Intel Labs) le gustó la idea durante su visita a Nizhny Novgorod y dio luz verde para

Synthetic Valery Fedorovich Kuryakin, productor, director, guionista y, en algunos lugares, el doble de acción del proyecto, en ese momento el jefe del grupo de desarrollo de Intel.
En primer lugar, la combinación de tecnologías tan diferentes en un pequeño proyecto, en el que solo trabajaron de tres a siete personas al mismo tiempo, fue fantástica. En esos años, al menos una docena de empresas ya existían en el mundo que se dedicaban tanto al reconocimiento facial como al rastreo, y la creación y animación de "cabezas parlantes". Todos ellos, por supuesto, tuvieron logros en algunas áreas: algunos tuvieron una excelente calidad de modelo, algunos mostraron animaciones muy realistas, algunos tuvieron éxito en el reconocimiento y seguimiento. Pero ni una sola empresa ha podido ofrecer todo el conjunto de tecnologías que permite crear de forma totalmente automática un vídeo sintético, en el que un modelo, muy similar a su prototipo, copia bien sus expresiones faciales y movimientos.
El proyecto Intel 3D Talking Heads fue la primera y en ese momento la única implementación de un ciclo completo de comunicación por video basado en todos los elementos del perfil sintético MPEG-4.

Transmisor del proyecto para la producción de clones sintéticos del modelo 2003.
En segundo lugar, la combinación del hardware que existía en ese momento y las soluciones tecnológicas implementadas en el proyecto, así como los planes para su uso, fue fantástica. Entonces, al comienzo del proyecto, tenía un Nokia 3310 en mi bolsillo, había un Pentium III-500MHz en mi escritorio y los algoritmos que eran especialmente críticos para el rendimiento para el trabajo en tiempo real se probaron en un servidor Pentium 4-1.7GHz con 128 Mb de RAM.
Al mismo tiempo, esperábamos que pronto nuestros modelos funcionaran en dispositivos móviles, y la calidad no sería peor que la de los héroes de la película de animación por computadora fotorrealista " Final Fantasy " estrenada en ese momento (2001) .

137 millones de dólares fue el costo para una película creada en una granja de procesamiento de ~ 1000 computadoras Pentium III. Póster de www.thefinalfantasy.com
Pero veamos qué pasó con nosotros.
Reconocimiento y seguimiento facial, adquisición de FAP.
Esta tecnología se presentó en dos versiones:
- modo en tiempo real (25 cuadros por segundo en el procesador Pentium 4-1.7GHz ya mencionado), cuando se rastrea a una persona que está directamente frente a una cámara de video conectada a una computadora;
- ( 1 ), .
Al mismo tiempo, se monitoreó la dinámica de los cambios en la posición / estado del rostro humano en tiempo real; pudimos estimar aproximadamente los ángulos de rotación e inclinación de la cabeza en todos los planos, el grado aproximado de apertura y estiramiento de la boca y el levantamiento de las cejas, y reconocer el parpadeo. Para algunas aplicaciones, una estimación tan aproximada es suficiente, pero si necesita rastrear con precisión las expresiones faciales de una persona, entonces se necesitan algoritmos más complejos, lo que significa más lentos.
En modo fuera de línea, nuestra tecnología hizo posible evaluar no solo la posición de la cabeza en su conjunto, sino también reconocer y rastrear con absoluta precisión los contornos externos e internos de los labios y los dientes durante una conversación, la posición de las cejas, el grado de cobertura de los ojos e incluso el desplazamiento de las pupilas: la dirección de la mirada.
Para el reconocimiento y seguimiento, se utilizó una combinación de conocidos algoritmos de visión por computadora, algunos de los cuales ya se habían implementado en la biblioteca OpenCV recién lanzada , por ejemplo, Optical Flow, así como nuestros propios métodos originales basados en el conocimiento a priori de la forma de los objetos correspondientes. En particular, en nuestra versión mejorada del método de plantillas deformables , para el cual los participantes del proyecto recibieron una patente .
La tecnología se implementó en forma de biblioteca de funciones que recibían cuadros de video con un rostro humano como entrada y salida de los FAP correspondientes.
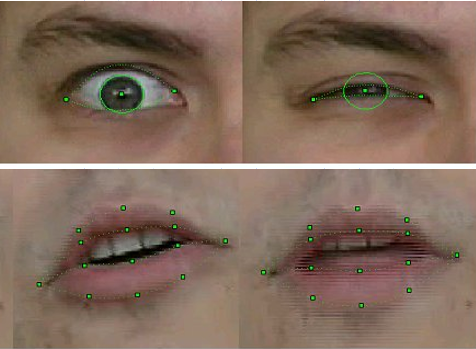
Calidad de reconocimiento y seguimiento de la muestra FP 2003
Por supuesto, la tecnología era imperfecta. El reconocimiento y el seguimiento fallaban si la persona en el marco tenía bigote, anteojos o arrugas profundas. Pero durante tres años de trabajo, la calidad ha mejorado significativamente. Si en las primeras versiones para los modelos de reconocimiento de movimiento al grabar un video había que pegar marcas especiales en los puntos FP correspondientes de la cara (círculos de papel blanco obtenidos con un punzón de oficina), entonces en la final del proyecto no se requirió nada de eso, por supuesto. Además, logramos rastrear de manera bastante constante la posición de los dientes y la dirección de la mirada, ¡y esto es en la resolución del video de las cámaras web de esa época, donde tales detalles apenas se distinguían!

Esto no es varicela, sino imágenes de la "infancia" de la tecnología de reconocimiento. El ingeniero principal de Intel, y en ese momento, el empleado novato de Intel, Alexander Bovyrin, enseña un modelo sintético para leer poesía.
Animación
Como se ha dicho muchas veces, la animación de un modelo en MPEG-4 está completamente determinada por la FAP. Y todo sería sencillo, si no fuera por un par de problemas.
Primero, el hecho de que los FAP de las secuencias de video se extraen en 2D, y el modelo es 3D, y se requiere completar de alguna manera la tercera coordenada. Es decir, una sonrisa de bienvenida en el perfil (y los usuarios deberían poder ver este perfil, de lo contrario tiene poco sentido en 3D) no debería convertirse en una sonrisa ominosa.
En segundo lugar, como también se dijo, los FAP describen el movimiento de puntos singulares, de los cuales hay alrededor de ochenta en el modelo, mientras que al menos un modelo algo realista en su conjunto consta de varios miles de vértices (en nuestro caso, de cuatro a ocho mil), y se necesitan algoritmos que calculen el desplazamiento de todos los demás puntos en el modelo basándose en los desplazamientos FP.
Es decir, está claro que cuando se gira la cabeza en un ángulo igual, todos los puntos girarán, pero al sonreír, aunque sea hasta las orejas, la “indignación” por el desplazamiento de la comisura de la boca debe desvanecerse gradualmente y mover la mejilla, pero no las orejas. Además, debería suceder de forma automática y realista para cualquier modelo con cualquier ancho de boca y geometría de malla a su alrededor. Para resolver estos problemas, se crearon algoritmos de animación en el proyecto. Se basaron en un modelo pseudomuscular, que simplemente describe los músculos que controlan las expresiones faciales.
Y luego, para cada modelo y cada FAP, se determinó preliminarmente automáticamente la "zona de influencia" - los vértices involucrados en la acción correspondiente, cuyos movimientos se calcularon teniendo en cuenta la anatomía y geometría - manteniendo la suavidad y conectividad de la superficie. Es decir, la animación constaba de dos partes: preliminar, realizada fuera de línea, donde se crearon ciertos coeficientes para los vértices de malla y se ingresaron en la tabla, y en línea, donde, teniendo en cuenta los datos de la tabla, se aplicó animación en tiempo real al modelo.

Sonreír no es fácil para un modelo 3D y sus creadores
Creación de un modelo 3D de una persona concreta.
En el caso general, la tarea de reconstruir un objeto tridimensional a partir de sus imágenes bidimensionales es muy difícil. Es decir, los algoritmos para su solución son conocidos por la humanidad desde hace mucho tiempo, pero en la práctica, debido a muchos factores, el resultado obtenido está lejos del deseado. Y esto es especialmente notable en el caso de la reconstrucción de la forma de la cara de una persona: aquí puede recordar nuestros primeros modelos con ojos en forma de ocho (la sombra de las pestañas en las fotos originales no tuvo éxito) o una ligera bifurcación de la nariz (la razón no se puede restaurar después de años)
Pero en el caso de los parlantes MPEG-4, la tarea se simplifica enormemente, porque el conjunto de rasgos faciales humanos (nariz, boca, ojos, etc.) es el mismo para todas las personas, y las diferencias externas por las que todos (y los programas de visión por computadora) distinguimos personas unas de otras "geométricas" - el tamaño / proporciones y ubicación de estas características y "textura" - colores y relieve. Por tanto, uno de los perfiles de vídeo sintético MPEG-4, la calibración, que se implementó en el proyecto, asume que el decodificador tiene un modelo generalizado de una “persona abstracta” que se personaliza para una persona específica mediante una secuencia de foto o video.
Nuestro "hombre esférico en el vacío": un modelo de personalización
Es decir, se producen deformaciones globales y locales de la malla 3D para coincidir con las proporciones de los rasgos faciales del prototipo resaltados en su foto / video, después de lo cual se aplica la "textura" del prototipo al modelo, es decir, la textura creada a partir de las mismas imágenes de entrada. El resultado es un modelo sintético. Esto se hace una vez para cada modelo, por supuesto sin conexión y, por supuesto, no es tan fácil.
En primer lugar, se requiere el registro o la rectificación de las imágenes de entrada, llevándolas a un sistema de coordenadas que coincida con el sistema de coordenadas del modelo 3D. Además, es necesario detectar puntos especiales en las imágenes de entrada y, según su ubicación, deformar el modelo 3D, por ejemplo, utilizando el método de funciones de base radial.y luego, usando algoritmos de cosido panorámico , generar una textura a partir de dos o más imágenes de entrada, es decir, "mezclarlas" en la proporción correcta para obtener la máxima información visual, además de compensar la diferencia de iluminación y tono, que siempre está presente incluso en las fotos tomadas con la misma configuración de cámara (que no siempre es el caso), y muy notoria al combinar estas fotos.

Este no es un fotograma de películas de terror, sino la textura de un modelo 3D de Pat Gelsinger , creado con su permiso cuando el proyecto se demostró en el Intel Developer Forum en 2003.
La versión inicial de la tecnología para personalizar el modelo basada en dos fotos fue implementada por los propios participantes del proyecto en Intel. Pero al alcanzar un cierto nivel de calidad y darse cuenta de las limitaciones de sus capacidades, se decidió transferir esta parte del trabajo al grupo de investigación de la Universidad Estatal de Moscú, que tenía experiencia en esta área. El resultado del trabajo de investigadores de la Universidad Estatal de Moscú bajo el liderazgo de Denis Ivanov fue la aplicación "Head Calibration Environment", que realizó todas las operaciones anteriores para crear un modelo personalizado de una persona a partir de su foto en rostro completo y perfil.
El único punto sutil es que la aplicación no se integró con la unidad de reconocimiento facial descrita anteriormente, la cual fue desarrollada en nuestro proyecto, por lo que los puntos especiales en la foto necesarios para que los algoritmos funcionen debían marcarse manualmente. Por supuesto, no todos los 84, sino solo los principales, y dado que la aplicación contaba con una interfaz de usuario adecuada, esta operación solo tomó unos segundos.
Además, se implementó una versión completamente automática de la reconstrucción del modelo a partir de una secuencia de video, en la que una persona gira la cabeza de un hombro a otro. Pero, como puede adivinar, la calidad de la textura extraída del video fue significativamente peor que la textura creada a partir de fotografías de cámaras digitales de esa época con una resolución de ~ 4K (3-5 megapíxeles), lo que significa que el modelo resultante parecía menos atractivo. Por lo tanto, también hubo una versión intermedia con varias fotos de diferentes ángulos de rotación de la cabeza.

La fila superior es gente virtual, la fila inferior es real.
¿Qué tan bueno fue el resultado logrado? La calidad del modelo resultante debe evaluarse no en estática, sino directamente en el video sintético por su similitud con el video correspondiente del original. Pero los términos "similar y no similar" no son matemáticos, dependen de la percepción de una persona en particular, y es difícil entender cómo nuestro modelo sintético y su animación difieren del prototipo. A algunas personas les gusta, a otras no. Pero el resultado de tres años de trabajo fue que al demostrar los resultados en varias exposiciones, el público tuvo que explicar en qué ventana estaba el video real frente a ellos, y en cuál - el sintético.
Visualización.
Para demostrar los resultados de todas las tecnologías anteriores, se creó un reproductor de video sintético MPEG-4 especial. El reproductor recibió como entrada un archivo VRML con un modelo, un stream (o archivo) con FAP, así como streams (archivos) con video y audio real para visualización sincronizada con video sintético con soporte para el modo "imagen en imagen". Al mostrar un video sintético, el usuario tuvo la oportunidad de hacer zoom en el modelo y también mirarlo desde todos los lados, simplemente girando el mouse en un ángulo arbitrario.

Aunque el reproductor fue escrito para Windows, pero teniendo en cuenta la posible migración en el futuro a otros sistemas operativos, incluidos los móviles. Por lo tanto, se eligió el "clásico" OpenGL 1.1 sin extensiones como biblioteca 3D.
Al mismo tiempo, el jugador no solo mostró el modelo, sino que también trató de mejorarlo, pero no de retocarlo, como ahora es costumbre con los modelos fotográficos, sino, por el contrario, hacerlo lo más realista posible. Es decir, permaneciendo dentro del marco de la iluminación Phong más simple y sin sombreadores, pero con estrictos requisitos de rendimiento, la unidad de reproducción del jugador creaba automáticamente modelos sintéticos: imitaban arrugas, pestañas, capaces de estrechar y dilatar las pupilas de manera realista; coloque vasos de un tamaño adecuado en el modelo; y también utilizando el trazado de rayos más simple, calculó la iluminación (sombreado) de la lengua y los dientes al hablar.
Por supuesto, ahora tales métodos ya no son relevantes, pero recordarlos es bastante interesante. Entonces, para la síntesis de arrugas mímicas, es decir, pequeñas curvas del relieve de la piel en la cara, visibles durante la contracción de los músculos faciales, los tamaños relativamente grandes de los triángulos de la malla del modelo no permitieron crear pliegues reales. Por lo tanto, se aplicó una especie de tecnología de mapeo de relieve: mapeo normal. En lugar de cambiar la geometría del modelo, la dirección de las normales a la superficie en los lugares correctos cambió y la dependencia del componente difuso de iluminación en cada punto de la normal creó el efecto deseado.

Este es el realismo sintético.
Pero el jugador no se detuvo ahí. Para la conveniencia de usar tecnologías y transferirlas al mundo exterior, se creó la biblioteca de objetos Intel Facial Animation Library, que contiene funciones para animación (transformación 3D) y visualización del modelo, de modo que cualquiera que quiera (y tenga una fuente FAP) llame a varias funciones - "Crear escena", " CreateActor ”,“ Animate ”podría animar y mostrar su modelo en su aplicación.
Salir
¿Qué me aportó la participación en este proyecto personalmente? Por supuesto, la oportunidad de colaborar con gente maravillosa en tecnologías interesantes. Me llevaron al proyecto por mi conocimiento de métodos y bibliotecas para renderizar modelos 3D y optimizar el rendimiento para x86. Pero, naturalmente, no era posible limitarnos al 3D, por lo que tuvimos que ir a otras dimensiones. Para escribir un reproductor, era necesario lidiar con el parsing VRML (no existían bibliotecas listas para este propósito), dominar el trabajo nativo con subprocesos en Windows, asegurando el trabajo conjunto de varios subprocesos con sincronización 25 veces por segundo, sin olvidar la interacción del usuario, e incluso pensar e implementar interfaz. Posteriormente, esta lista se complementó con la participación en la mejora de los algoritmos de seguimiento facial. Y la necesidad de integrar y combinar constantemente componentes escritos por otros miembros del equipo con el jugador,y también presentar el proyecto al mundo exterior mejoró en gran medida mis habilidades de comunicación y coordinación.
¿Qué aportó la participación de Intel en este proyecto? Como resultado, nuestro equipo ha creado un producto que puede servir como una buena prueba y demostración de las capacidades de las plataformas y productos Intel. Además, tanto el hardware (CPU y GPU, como el software) de nuestras cabezas (tanto reales como sintéticas) han contribuido a la mejora de la biblioteca OpenCV.
Además, podemos decir con seguridad que el proyecto dejó una marca visible en la historia: como resultado de su trabajo, sus participantes escribieron artículos y presentaron informes en conferencias especializadas en visión por computadora y gráficos por computadora, rusa ( GraphiCon ) e internacional.
Intel ha mostrado las aplicaciones de demostración de 3D Talking Heads en decenas de ferias, foros y congresos en todo el mundo.
En el tiempo transcurrido, la tecnología, por supuesto, ha avanzado mucho, lo que facilita la creación y animación automática de personajes sintéticos. Hubo una definición de profundidad de cámara Intel Real Sense , y redes neuronales basadas en grandes datos aprendieron cómo generar imágenes realistas de personas, incluso inexistentes.
Sin embargo, los desarrollos del proyecto 3D Talking Heads, publicados en el dominio público, continúan viéndose hasta ahora.
Mire nuestro altavoz MPEG-4 sintético joven, de casi veinte años, y usted: