
Artículos anteriores de la serie.
Tal vez, hoy incluso romperé la tradición y depuraré el proyecto no en el complejo Redd, sino en un diseño regular. En primer lugar, soy consciente de que la gran mayoría de los lectores no tienen acceso a un complejo tan complejo, pero sí tienen acceso a Ali Express. Bueno, y en segundo lugar, soy demasiado vago para cercar un jardín con un par de dispositivos USB y host conectados, y también para lidiar con la interferencia emergente.
En 2017, estaba buscando soluciones listas para usar en la red y encontré algo tan maravilloso , o mejor dicho, su antepasado. Ahora tienen todo en una placa especializada, pero en todas partes había fotografías de una placa de prueba simple de Xilinx, a la que se conectó una placa de WaveShare (puede obtener más información aquí ). Echemos un vistazo a la foto de este tablero.

Tiene dos conectores USB a la vez. Además, el diagrama muestra que están paralelos. Puede enchufar sus dispositivos USB en un enchufe tipo A, y puede conectar un cable al conector mini USB, que conectaremos al host. Y la descripción del proyecto OpenVizsla dice que así funciona. La única pena es que el proyecto en sí es bastante difícil de leer. Puede tomarlo en github, pero le daré un enlace no a la cuenta que se indica en la página, todos lo encontrarán de todos modos, pero se rehizo para MiGen, pero la versión que encontré en 2017: http: // github. com / ultraembedded / cores, está en un Verilog limpio, y está la rama usb_sniffer. Allí, todo no pasa directamente a través de ULPI, sino a través del convertidor ULPI a UTMI (ambas palabras obscenas son microcircuitos de nivel físico que coinciden con el canal USB 2.0 de alta velocidad con buses comprensibles para procesadores y FPGA), y solo entonces funcionan con este UTMI. Cómo funciona todo allí, no lo he descubierto. Por lo tanto, preferí hacer mi desarrollo desde cero, ya que pronto veremos que todo da miedo allí en lugar de ser difícil.
¿En qué hardware puedes trabajar?
La respuesta a la pregunta del título es simple: en cualquier persona con un FPGA y memoria externa. Por supuesto, en esta serie solo consideraremos los FPGA Altera (Intel). Sin embargo, tenga en cuenta que los datos del microcircuito ULPI (está en ese pañuelo) se ejecutan a 60 MHz. Los cables largos no son aceptables aquí. También es importante conectar la línea CLK a la entrada FPGA del grupo GCK, de lo contrario todo funcionará y luego fallará. Mejor no arriesgarse. No le aconsejo que lo reenvíe programáticamente. Lo intenté. Todo terminó con un cable a la pierna del grupo GCK.
Para los experimentos de hoy, a petición mía, un amigo me ha soldado un sistema de este tipo:

Micromódulo con FPGA y SDRAM (búsquelo en ALI express con la frase FPGA AC608) y la misma placa ULPI de WaveShare. Así es como se ve el módulo en las fotos de uno de los vendedores. Soy demasiado vago como para desenroscarlo de la carcasa:

por cierto, los orificios de ventilación, como en la foto de mi carcasa, son muy interesantes. En el modelo, dibuje una capa sólida, y en la rebanadora establezca el relleno, digamos, 40% y diga que necesita hacer cero capas sólidas desde la parte inferior y superior. Como resultado, la impresora 3D dibuja esta ventilación por sí misma. Muy confortablemente.
En general, el enfoque para encontrar hardware es claro. Ahora comenzamos a diseñar el analizador. Más bien, ya hemos hecho el propio analizador en los dos últimos artículos ( aquí se trabajó con el hardware , y aquí - con acceso a ella ), ahora nos limitaremos a diseñar una cabeza orientada hacia los problemas que los datos procedentes de las capturas del microcircuito ULPI.
Lo que la cabeza debería poder hacer
En el caso del analizador lógico, todo fue fácil y simple. Hay datos. Nos conectamos con ellos y comenzamos a empacar y enviarlos al autobús AVALON_ST. Aquí todo es más complicado. La especificación ULPI se puede encontrar aquí . Noventa y tres hojas de texto aburrido. Personalmente, esto me lleva a la desesperación. La descripción del chip USB3300, que está instalado en la placa WaveShare, parece un poco más simple. Puedes conseguirlo aquí . Aunque todavía acumulé coraje desde ese mismo diciembre de 2017, a veces leía el documento y lo cerraba de inmediato, ya que sentía el enfoque de la depresión.
De la descripción está claro que ULPI tiene un conjunto de registros que deben completarse antes de comenzar a trabajar. Esto se debe principalmente a las resistencias pull-up y de terminación. Aquí hay una imagen para explicar el punto:

Dependiendo del rol (host o dispositivo), así como de la velocidad seleccionada, se deben incluir diferentes resistencias. ¡Pero no somos un host ni un dispositivo! ¡Debemos desconectar todas las resistencias para no interferir con los dispositivos principales del bus! Esto se hace escribiendo a los registros.
Bueno, y velocidad. Es necesario elegir una velocidad de trabajo. Para hacer esto, también necesita escribir en los registros.
Cuando tengamos todo configurado, puede comenzar a buscar datos. Pero en nombre de ULPI, las letras "LP" significan "pines bajos". ¡Y esta misma reducción en el número de patas condujo a un protocolo tan furioso que simplemente aguanta! Echemos un vistazo más de cerca al protocolo.
Protocolo ULPI
El protocolo ULPI es algo inusual para el hombre común. Pero si te sientas con un documento y meditas, comienzan a aparecer algunas características más o menos comprensibles. Cada vez está más claro que los desarrolladores han hecho todo lo posible para reducir realmente la cantidad de contactos utilizados.
No volveré a escribir la documentación completa aquí. Limitémonos a las cosas más importantes. El más importante de estos es la dirección de las señales. Es imposible recordarlo, es mejor mirar la imagen cada vez:

ULPI LINK es nuestro FPGA.
Diagrama de tiempos de recepción de datos
En reposo, debemos emitir una constante 0x00 al bus de datos, que corresponde al comando IDLE. Si los datos provienen del bus USB, el protocolo de intercambio se verá así:
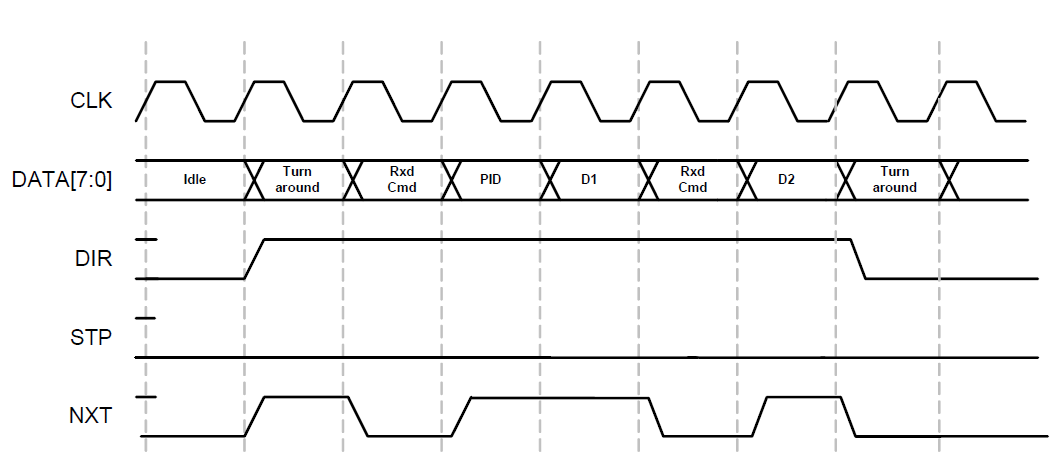
el ciclo comenzará con el hecho de que la señal DIR volará hasta uno. Primero, estará allí un ciclo de reloj para que el sistema tenga tiempo de cambiar la dirección del bus de datos. Además, comienzan los milagros de la economía. ¿Ves el nombre de la señal NXT? Significa SIGUIENTE cuando se transmite de nosotros. Y aquí es una señal completamente diferente. Cuando DIR es uno, llamaría a NXT C / D. Nivel bajo: tenemos un equipo. Alto - datos.
Es decir, debemos reparar 9 bits (el bus DATA y la señal NXT) siempre a un DIR alto (luego filtrando el primer reloj por software), o comenzando desde el segundo reloj después de que despegue el DIR. Si la línea DIR cae a cero, cambiamos el bus de datos para escribir y nuevamente comenzamos a transmitir el comando IDLE.
Con recepción de datos, está claro. Ahora analicemos el trabajo con registros.
Diagrama de tiempo de escritura en el registro ULPI
Para escribir en el registro, se utiliza la siguiente casa temporal (deliberadamente cambié a jerga, porque siento que estoy tendiendo a GOST 2.105, y esto es aburrido, así que me
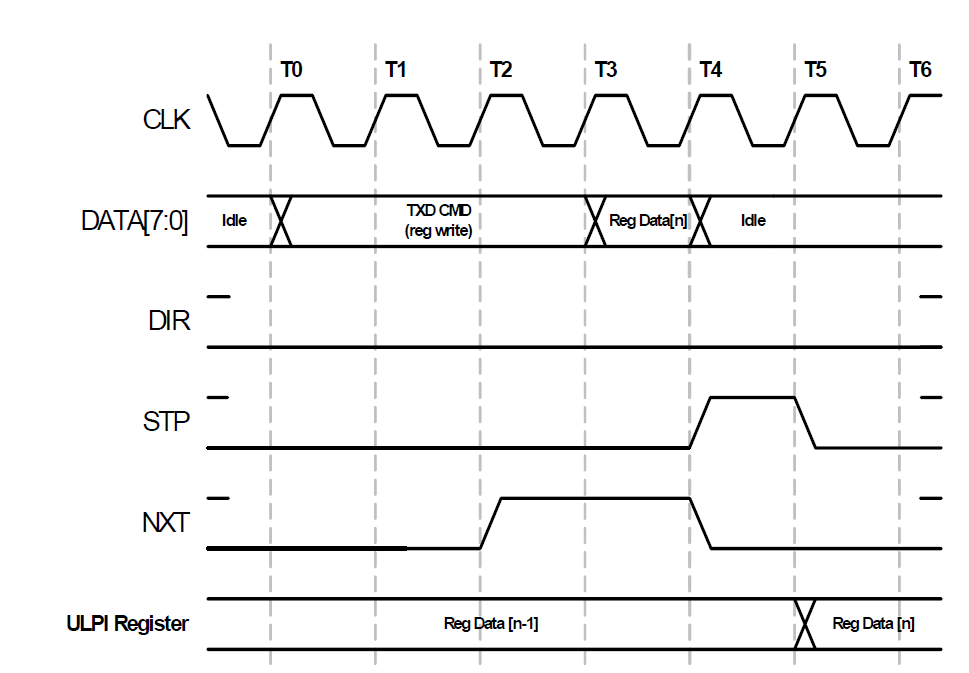
alejaré de él): Primero que nada, debemos esperar el estado DIR = 0. En el reloj T0, debemos establecer la constante TXD CMD en el bus de datos. Qué significa eso? No puede resolverlo de inmediato, pero si profundiza un poco en los documentos, resulta que el valor deseado se puede encontrar aquí:

es decir, los bits de datos altos deben establecerse en el valor "10" (para todo el byte, la máscara es 0x80), y los inferiores, el número de registro.
A continuación, debe esperar a que la señal NXT despegue. Con esta señal, el microcircuito confirma que nos escuchó. En la imagen de arriba, lo esperamos en el reloj T2 y configuramos los datos en el siguiente reloj (T3). En el reloj T4, el ULPI recibirá los datos y eliminará el NXT. Y marcaremos el final del ciclo de intercambio de unidades en STP. En también T5, los datos se engancharán en el registro interno. El proceso ha terminado. Aquí hay una recuperación de la inversión por un pequeño número de conclusiones. Pero necesitaremos escribir los datos solo en el inicio, por lo que, por supuesto, tendremos que sufrir con el desarrollo, pero todo esto no afectará particularmente el trabajo.
Diagrama de tiempos de lectura del registro ULPI
Honestamente, para tareas prácticas, leer registros no es tan importante, pero veámoslo también. La lectura será útil al menos para asegurarse de que hemos implementado el registro correctamente.
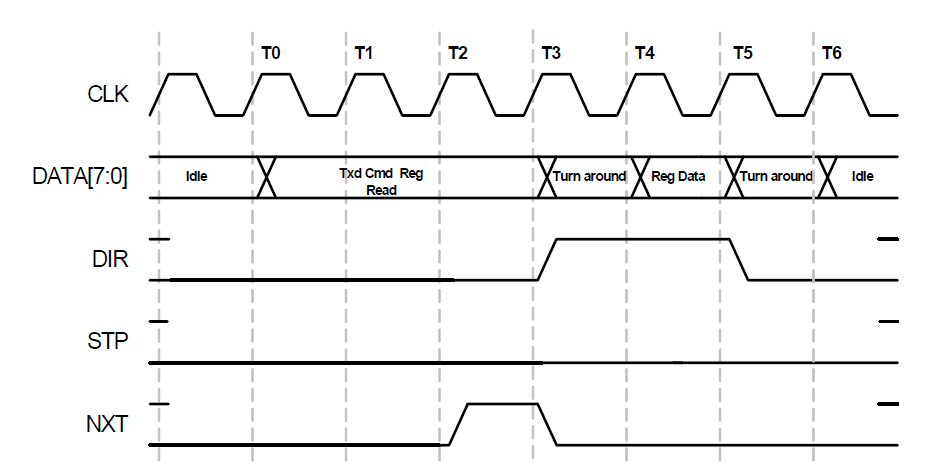
Vemos que ante nosotros hay una mezcla explosiva de las dos casas temporales anteriores. Establecemos la dirección como lo hicimos para escribir en el registro, y tomamos los datos de acuerdo con las reglas para leer datos.
¿Bien? ¿Comencemos a diseñar un autómata que moldeará todo esto para nosotros?
Diagrama estructural de la cabeza.
Como puede ver en la descripción anterior, el cabezal debe estar conectado a dos buses a la vez: AVALON_MM para acceder a los registros y AVALON_ST para enviar los datos que se almacenarán en la RAM. Lo principal en la cabeza es el cerebro. Por lo tanto, debería ser una máquina de estados que generará los diagramas de tiempo que consideramos anteriormente.

Comencemos su desarrollo con la función de recibir datos. Debe tenerse en cuenta aquí que no podemos influir en el flujo del bus ULPI de ninguna manera. Datos de allí, si comenzó a irse, irá. No les importa si el bus AVALON_ST está listo o no. Por lo tanto, simplemente ignoraremos la falta de disponibilidad del bus. En un analizador real, será posible agregar una indicación de alarma en caso de salida de datos sin preparación. Todo debería ser simple en el marco del artículo, así que recordemos esto para el futuro. Y para garantizar la disponibilidad del bus, como en un analizador lógico, tendremos un bloque FIFO externo. En total, el gráfico de transición del autómata para recibir el flujo de datos es el siguiente:
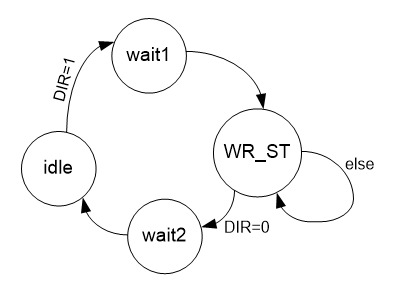
DIR despegó - comenzó a recibir. Colgamos un reloj en wait1, luego lo aceptamos mientras DIR es igual a uno. Cayó a cero: después de un reloj (aunque no es el hecho de que sea necesario, pero por ahora estableceremos el estado wait2) regresó a inactivo.
Hasta ahora, todo es simple. No olvide que no solo las líneas D0_D7, sino también la línea NXT deben ir al bus AVALON_ST, ya que determina lo que se transmite ahora: un comando o datos.
Un ciclo de escritura de registro puede tener un tiempo de ejecución impredecible. Desde el punto de vista del bus AVALON_MM, esto no es muy bueno. Por lo tanto, lo haremos un poco más complicado. Creemos un registro de búfer. Los datos entrarán en él, después de lo cual el bus AVALON_MM se liberará de inmediato. Desde el punto de vista del autómata que se está desarrollando, aparece la señal de entrada have_reg (se han recibido datos en el registro, que deben enviarse) y la señal de salida reg_served (lo que significa que el proceso de emisión del registro se ha completado). Agregue la lógica de la escritura al registro en el gráfico de transición del autómata.
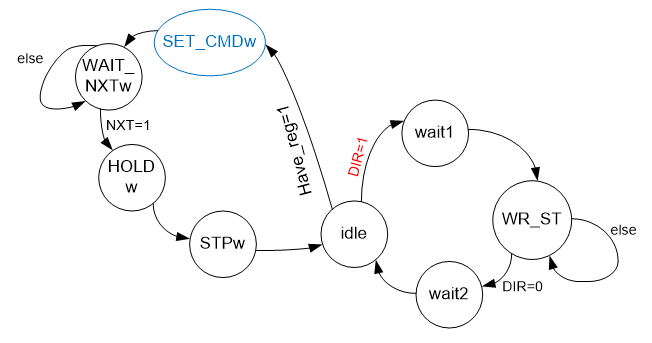
He resaltado la condición DIR = 1 en rojo para dejar en claro que tiene la máxima prioridad. Entonces es posible excluir la expectativa del valor cero de la señal DIR en la nueva rama del autómata. Iniciar sesión en una rama con un valor diferente simplemente no será posible. El estado SET_CMDw es azul, ya que es más probable que sea puramente virtual. ¡Estas son solo acciones a realizar! ¡Nadie se molesta en establecer la constante correspondiente en el bus de datos y solo durante la transición! En el estado STPw, entre otras cosas, la señal reg_served también puede ser activada durante un ciclo de reloj para borrar la señal BSY para el bus AVALON_MM, permitiendo un nuevo ciclo de escritura.
Bueno, queda agregar una rama para leer el registro ULPI. Aquí, lo contrario es cierto. La máquina del servicio de autobuses nos envía una solicitud y espera nuestra respuesta. Cuando se reciben los datos, puede procesarlos. Y funcionará con la suspensión o el sondeo del autobús, estos ya son los problemas de esa máquina. Hoy decidí trabajar en una encuesta. Solicitando datos - BSY apareció. Cómo desapareció BSY: puede recibir datos leídos. En total, el gráfico toma la forma:
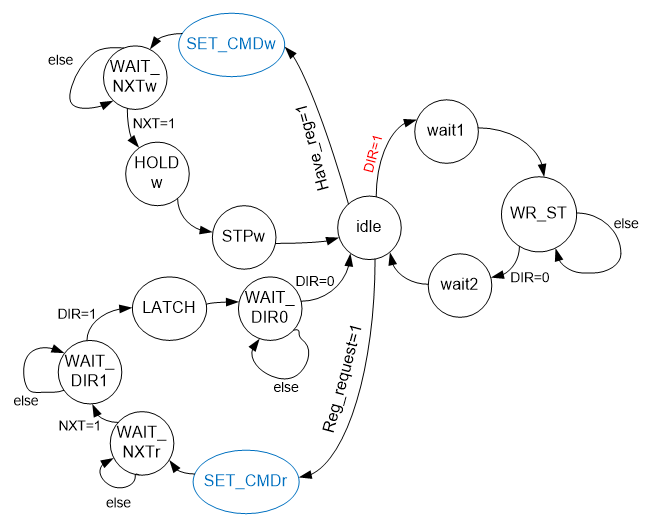
tal vez, en el curso del desarrollo, habrá algunos ajustes, pero por ahora, nos adheriremos a este gráfico. Después de todo, este no es un informe, sino una instrucción sobre la metodología de desarrollo. Y la técnica es tal que primero debe dibujar un gráfico de transición y luego, hacer la lógica, de acuerdo con esta figura, ajustada para los detalles emergentes.
Características de la implementación del autómata desde el lado AVALON_MM
Al trabajar con el bus AVALON_MM, puede ir de dos maneras. El primero es crear demoras en el acceso al autobús. Exploramos este mecanismo en uno de los artículos anteriores , y advertí que está plagado de problemas. La segunda forma es clásica. Ingrese el registro de estado. Al comienzo de la transacción, configure la señal BSY, al finalizar - restablecer. Y asigne la responsabilidad de todo a la lógica maestra del bus (procesador Nios II o puente JTAG). Cada una de las opciones tiene sus propias ventajas y desventajas. Como ya hemos hecho variantes con demoras en el bus, hagamos todo hoy, para variar, a través del registro de estado.
Diseñamos la maquina principal
Lo primero que me gustaría llamar su atención son mis disparadores RS favoritos. Tenemos dos maquinas. El primero sirve al bus AVALON_MM, el segundo, la interfaz ULPI. Descubrimos que la conexión entre ellos pasa por un par de banderas. Solo un proceso puede escribir en cada bandera. Cada autómata se implementa mediante su propio proceso. ¿Cómo ser? Desde hace algún tiempo, comencé a agregar un disparador RS. Tenemos dos bits, por lo que deben ser generados por dos flip-flops RS. Aquí están:
//
always_ff @(posedge ulpi_clk)
begin
//
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
//
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
Un proceso de gallos reg_served, el segundo de gallos have_reg. Y el flip-flop RS en su propio proceso genera la señal write_busy sobre su base. Del mismo modo, read_busy se forma a partir de read_finished y reg_request. Puede hacerlo de manera diferente, pero en esta etapa del camino creativo, me gusta este método.
Así es como se establecen las banderas BSY. El amarillo es para el proceso de escritura, el azul para el proceso de lectura. El proceso de Verilogov tiene una característica muy interesante. En él, puede asignar valores no una vez, sino varias veces. Por lo tanto, si quiero que una señal despegue para un ciclo de reloj, la anulo al comienzo del proceso (vemos que ambas señales están anuladas allí) y la configuro en una por una condición que se ejecuta durante un ciclo de reloj. Introducir la condición anulará el valor predeterminado. En todos los demás casos, funcionará. Por lo tanto, escribir en el puerto de datos inicia el despegue de la señal have_reg para un ciclo de reloj, y escribir el bit 0 en el puerto de control inicia el despegue de la señal reg_request.

El mismo texto
// AVALON_MM
always_ff @(posedge ulpi_clk)
begin
// ,
//
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
//
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
//
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
Como vimos anteriormente, un ciclo de reloj es suficiente para que el flip-flop RS correspondiente se establezca en uno. Y a partir de este momento, la señal BSY establecida comienza a leerse desde el registro de estado:

El mismo texto
// AVALON_MM
always_comb
begin
case (address)
// ( )
0 : readdata <= {26'b0, addr_to_ulpi};
//
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - , -
//
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
En realidad, así que, naturalmente, nos familiarizamos con los procesos que sirven para trabajar con el bus AVALON_MM.
Permítame recordarle también los principios de trabajar con el bus ulpi_data. Este autobús es bidireccional. Por lo tanto, debe usar una técnica estándar para trabajar con ella. Así es como se declara el puerto correspondiente:
inout [7:0] ulpi_data,
Podemos leer desde este autobús, pero no podemos escribir directamente. En cambio, creamos una copia para el registro.
logic [7:0] ulpi_d = 0;
Y conectamos esta copia al bus principal a través del siguiente multiplexor:
// inout-
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
Traté de comentar sobre la lógica de la máquina principal tanto como sea posible dentro del código Verilog. Como esperaba durante el desarrollo del gráfico de transición, en la implementación real, la lógica ha cambiado un poco. Algunos de los estados fueron expulsados. Sin embargo, al comparar el gráfico y el texto fuente, espero que comprenda todo lo que se hace allí. Por lo tanto, no hablaré sobre esta máquina. Es mejor dar como referencia el texto completo del módulo, relevante en el momento anterior a la modificación basado en los resultados de experimentos prácticos.
Texto completo del módulo.
module ULPIhead
(
input reset,
output clk66,
// AVALON_MM
input [1:0] address,
input write,
input [31:0] writedata,
input read,
output logic [31:0] readdata = 0,
// AVALON_ST
input logic source_ready,
output logic source_valid = 0,
output logic [15:0] source_data = 0,
// ULPI
inout [7:0] ulpi_data,
output logic ulpi_stp = 0,
input ulpi_nxt,
input ulpi_dir,
input ulpi_clk,
output ulpi_rst
);
logic have_reg = 0;
logic reg_served = 0;
logic reg_request = 0;
logic read_finished = 0;
logic [5:0] addr_to_ulpi;
logic [7:0] data_to_ulpi;
logic [7:0] data_from_ulpi;
logic write_busy = 0;
logic read_busy = 0;
logic [7:0] ulpi_d = 0;
logic force_reset = 0;
//
always_ff @(posedge ulpi_clk)
begin
//
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
//
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
// AVALON_MM
always_comb
begin
case (address)
// ( )
0 : readdata <= {26'b0, addr_to_ulpi};
//
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - , -
//
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
// AVALON_MM
always_ff @(posedge ulpi_clk)
begin
// ,
//
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
//
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
//
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
//
enum {idle,
wait1,wr_st,
wait_nxt_w,hold_w,
wait_nxt_r,wait_dir1,latch,wait_dir0
} state = idle;
always_ff @ (posedge ulpi_clk)
begin
if (reset)
begin
state <= idle;
end else
begin
//
source_valid <= 0;
reg_served <= 0;
ulpi_stp <= 0;
read_finished <= 0;
case (state)
idle: begin
if (ulpi_dir)
state <= wait1;
else if (have_reg)
begin
// ,
// ,
//
ulpi_d [7:6] <= 2'b10;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_w;
end
else if (reg_request)
begin
// -
ulpi_d [7:6] <= 2'b11;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_r;
end
end
// TURN_AROUND
wait1 : begin
state <= wr_st;
// ,
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end
// DIR - AVALON_ST
wr_st : begin
if (ulpi_dir)
begin
// ,
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end else
// wait2,
// , - .
state <= idle;
end
wait_nxt_w : begin
if (ulpi_nxt)
begin
ulpi_d <= data_to_ulpi;
state <= hold_w;
end
end
hold_w: begin
// , ULPI
// . NXT
// ...
if (ulpi_nxt) begin
// , AVALON_MM
reg_served <= 1;
ulpi_d <= 0; // idle
ulpi_stp <= 1; // STP
state <= idle; // - idle
end
end
// STPw ...
// ...
// . , NXT
// ,
wait_nxt_r : begin
if (ulpi_nxt)
begin
ulpi_d <= 0; //
state <= wait_dir1;
end
end
// ,
wait_dir1: begin
if (ulpi_dir)
state <= latch;
end
//
// -
latch: begin
data_from_ulpi <= ulpi_data;
state <= wait_dir0;
end
// ,
wait_dir0: begin
if (!ulpi_dir)
begin
state <= idle;
read_finished <= 1;
end
end
default: begin
state <= idle;
end
endcase
end
end
// inout-
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
// reset ,
assign ulpi_rst = reset | force_reset;
assign clk66 = ulpi_clk;
endmodule
Guía del programador
Puerto de dirección de registro ULPI (+0)
La dirección del registro ULPI del bus, con el que irá el trabajo, debe colocarse en el puerto con desplazamiento +0
Puerto de datos de registro ULPI (+4)
Al escribir en este puerto: el proceso de escritura en el registro ULPI, cuya dirección se estableció en el puerto de la dirección del registro, se inicia automáticamente. Está prohibido escribir en este puerto hasta que el proceso de la escritura anterior haya finalizado.
Al leer: este puerto devolverá el valor obtenido de la última lectura del registro ULPI.
Puerto de control ULPI (+8)
La lectura siempre es cero. La asignación de bits para la escritura es la siguiente:
Bit 0: al escribir un solo valor, se inicia el proceso de lectura del registro ULPI, cuya dirección se establece en el puerto de dirección del registro ULPI.
Bit 31: al escribir uno, envía una señal RESET al chip ULPI.
El resto de los bits están reservados.
Puerto de estado (+ 0x0C)
Solo lectura.
Bit 0 - WRITE_BUSY. Si es igual a uno, el proceso de escritura en el registro ULPI está en progreso.
Bit 1 - READ_BUSY. Si es igual a uno, el proceso de lectura del registro ULPI está en progreso.
El resto de los bits están reservados.
Conclusión
Nos familiarizamos con el método de organización física del cabezal analizador USB, diseñamos un autómata básico para trabajar con el microcircuito ULPI e implementamos un borrador del módulo SystemVerilog para este cabezal. En los siguientes artículos, veremos el proceso de modelado, simularemos este módulo y luego realizaremos experimentos prácticos con él, de acuerdo con los resultados de los cuales finalizaremos limpiamente el código. Es decir, hasta el final tenemos al menos cuatro artículos más.