
Debo decir de inmediato: no soy un especialista en TI, sino un entusiasta en el campo de las estadísticas. Además, he participado en varios concursos de predicción de Fórmula 1 a lo largo de los años. De ahí las tareas que enfrentó mi modelo: emitir pronósticos que no serían peores que los que se crean "a simple vista". E idealmente, el modelo, por supuesto, debería vencer a los oponentes humanos.
Este modelo se centra únicamente en predecir el resultado de las calificaciones, ya que las calificaciones son más predecibles que las razas y son más fáciles de modelar. Sin embargo, por supuesto, en el futuro planeo crear un modelo que permita predecir los resultados de las carreras con suficiente precisión.
Para crear un modelo, resumí en una tabla todos los resultados de las prácticas y calificaciones para las temporadas 2018 y 2019. El año 2018 sirvió como muestra de entrenamiento, y 2019 como muestra de prueba. En base a estos datos, construimos una regresión lineal . Para poner la regresión lo más simple posible, nuestros datos son una colección de puntos en un plano de coordenadas. Hemos dibujado una línea recta que se desvía menos de la totalidad de estos puntos. Y la función, cuyo gráfico es esta línea, esta es nuestra regresión lineal.
De la fórmula conocida del currículo escolarnuestra función se distingue solo por el hecho de que tenemos dos variables. La primera variable (X1) es el retraso en la tercera práctica, y la segunda variable (X2) es el retraso promedio en las calificaciones anteriores. Estas variables no son equivalentes, y uno de nuestros objetivos es determinar el peso de cada variable en el rango de 0 a 1. Cuanto más lejos sea una variable de cero, más importante será para explicar la variable dependiente. En nuestro caso, la variable dependiente es el tiempo de vuelta, expresado en el retraso detrás del líder (o, más precisamente, de un cierto "círculo ideal", ya que este valor fue positivo para todos los pilotos).
Los fanáticos del libro de Moneyball (que no se explica en la película) pueden recordar que, mediante la regresión lineal, determinaron que el porcentaje base, también conocido como OBP (porcentaje en base), está más estrechamente relacionado con las heridas obtenidas que otras estadísticas. Nuestro objetivo es más o menos el mismo: comprender qué factores están más estrechamente relacionados con los resultados de las calificaciones. Una de las grandes ventajas de la regresión es que no requiere un conocimiento avanzado de las matemáticas: simplemente ingresamos los datos y luego Excel u otro editor de hojas de cálculo nos da coeficientes listos.
Básicamente, queremos saber dos cosas con regresión lineal. Primero, la medida en que nuestras variables independientes elegidas explican el cambio en la función. Y segundo, cuán importante es cada una de estas variables independientes. En otras palabras, qué explica mejor los resultados de calificación: los resultados de carreras en pistas anteriores o los resultados de sesiones de entrenamiento en la misma pista.
Hay que señalar un punto importante aquí. El resultado final fue la suma de dos parámetros independientes, cada uno de los cuales resultó de dos regresiones independientes. El primer parámetro es la fuerza del equipo en esta etapa, más precisamente, el retraso del mejor piloto del equipo del líder. El segundo parámetro es la distribución de fuerzas dentro del equipo.
¿Qué significa esto con el ejemplo? Digamos que tomamos el Gran Premio de Hungría de 2019. El modelo muestra que Ferrari estará a 0.218 segundos del líder. Pero este es el retraso del primer piloto, y quiénes serán, Vettel o Leclair, y cuál será la brecha entre ellos, está determinado por otro parámetro. En este ejemplo, el modelo mostró que Vettel se adelantará y Leclair perderá 0.096 segundos para él.
¿Por qué tantas dificultades? ¿No es más fácil considerar a cada piloto por separado en lugar de este desglose en el retraso del equipo y el retraso del primer piloto del segundo dentro del equipo? Quizás esto sea así, pero mis observaciones personales muestran que es mucho más confiable mirar los resultados del equipo que los resultados de cada piloto. Un piloto puede cometer un error, o volar fuera de la pista, o tendrá problemas técnicos: todo esto traerá caos al modelo, a menos que rastree manualmente cada situación de fuerza mayor, lo que lleva demasiado tiempo. La influencia de la fuerza mayor en los resultados del equipo es mucho menor.
Pero volviendo al punto en el que queríamos evaluar qué tan bien nuestras variables explicativas elegidas explican el cambio en la función. Esto se puede hacer usando el coeficiente de determinación... Demostrará en qué medida los resultados de la calificación se explican por los resultados de pasantías y calificaciones previas.
Como construimos dos regresiones, también tenemos dos coeficientes de determinación. La primera regresión es responsable del nivel del equipo en el escenario, el segundo por el enfrentamiento entre los pilotos del mismo equipo. En el primer caso, el coeficiente de determinación es 0,82, es decir, el 82% de los resultados de las calificaciones se explican por los factores que hemos elegido, y otro 18%, por algunos otros factores que no tomamos en cuenta. Este es un muy buen resultado. En el segundo caso, el coeficiente de determinación fue de 0,13.
Estas métricas, en esencia, significan que el modelo predice el nivel de equipo razonablemente bien, pero tiene problemas para determinar la brecha entre compañeros de equipo. Sin embargo, para el objetivo final, no necesitamos conocer la brecha, solo necesitamos saber cuál de los dos pilotos será más alto, y el modelo básicamente hace frente a esto. En el 62% de los casos, el modelo obtuvo una calificación más alta que el piloto que realmente fue más alto en la calificación.
Al mismo tiempo, al evaluar la fuerza del equipo, los resultados del último entrenamiento fueron una vez y media más importantes que los resultados de las calificaciones anteriores, pero en los duelos dentro del equipo fue al revés. La tendencia se manifestó en los datos de 2018 y 2019.
La fórmula final se ve así:
Primer piloto:
Segundo piloto:
Permíteme recordarte que X1 es el retraso en la tercera práctica, y X2 es el retraso promedio en las calificaciones anteriores.
Que significan estos numeros. Significan que el nivel del equipo en la calificación está determinado en un 60% por los resultados de la tercera práctica y en un 40%, por los resultados de las calificaciones en las etapas anteriores. En consecuencia, los resultados de la tercera práctica son un factor una vez y media más significativo que los resultados de las calificaciones anteriores.
Los fanáticos de la Fórmula 1 probablemente sepan la respuesta a esta pregunta, pero por lo demás, deberían comentar por qué tomé los resultados de la tercera práctica. Hay tres prácticas en la Fórmula 1. Sin embargo, es en el último de ellos que los equipos tradicionalmente entrenan calificaciones. Sin embargo, en los casos en que la tercera práctica falla debido a la lluvia u otra fuerza mayor, tomé los resultados de la segunda práctica. Por lo que recuerdo, en 2019 solo hubo uno de esos casos: en el Gran Premio de Japón, cuando debido a un tifón, el escenario se celebró en un formato acortado.
Además, alguien probablemente notó que el modelo usa el retraso promedio en las calificaciones anteriores. ¿Pero qué hay de la primera etapa de la temporada? Utilicé los retrasos del año anterior, pero no los dejé como están, sino que los ajusté manualmente según el sentido común. Por ejemplo, en 2019, Ferrari fue en promedio 0.3 segundos más rápido que Red Bull. Sin embargo, parece que el equipo italiano no tendrá tal ventaja este año, o tal vez estarán completamente atrasados. Por lo tanto, para la primera etapa de la temporada 2020, el Gran Premio de Austria, acerqué manualmente el Red Bull al Ferrari.
De esta manera obtuve el retraso de cada piloto, clasifiqué a los pilotos por el retraso y obtuve la predicción final para la calificación. Sin embargo, es importante comprender que el primer y el segundo piloto son simples convenciones. Volviendo al ejemplo con Vettel y Leclair, en el Gran Premio de Hungría, la modelo consideró a Sebastian como el primer piloto, pero en muchas otras etapas prefirió a Leclair.
resultados
Como dije, la tarea consistía en crear un modelo que permitiera predecir tanto como a las personas. Como base, tomé mis pronósticos y los pronósticos de mis compañeros de equipo, que fueron creados "a simple vista", pero con un estudio cuidadoso de los resultados de las prácticas y la discusión conjunta.
El sistema de calificación fue el siguiente. Solo se tuvieron en cuenta los diez mejores pilotos. Para un golpe preciso, el pronóstico recibió 9 puntos, por una falla en la posición 1, 6 puntos, por una falla en la posición 2, 4 puntos, por una falla en la posición 3, 2 puntos y por una falla en la posición 4, 1 punto. Es decir, si en el pronóstico el piloto está en el 3er lugar, y como resultado tomó la pole position, entonces el pronóstico recibió 4 puntos.
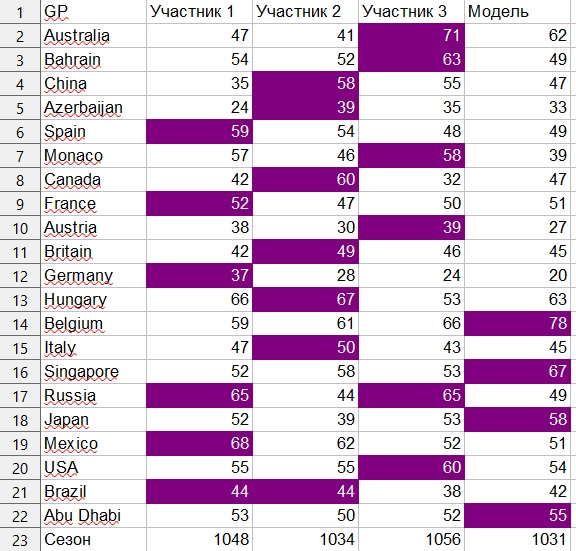
Con este sistema, el número máximo de puntos para 21 Grand Prix es 1890.
Los participantes humanos obtuvieron 1056, 1048 y 1034 puntos, respectivamente.
El modelo obtuvo 1031 puntos, aunque con una ligera manipulación de los coeficientes, también recibí 1045 y 1053 puntos.
Personalmente, estoy satisfecho con los resultados, ya que esta es mi primera experiencia en la construcción de regresiones, y condujo a resultados bastante aceptables. Por supuesto, me gustaría mejorarlos, porque estoy seguro de que con la ayuda de la construcción de modelos, incluso tan simples como este, puede lograr mejores resultados que simplemente evaluar los datos "a simple vista". En el marco de este modelo, sería posible, por ejemplo, tener en cuenta el factor de que algunos equipos son débiles en la práctica, pero "disparan" en las calificaciones. Por ejemplo, hay una observación de que Mercedes a menudo no fue el mejor equipo durante el entrenamiento, pero tuvo un desempeño mucho mejor en las calificaciones. Sin embargo, estas observaciones humanas no se reflejaron en el modelo. Entonces, en la temporada 2020, que comienza en julio (si no sucede nada inesperado), quiero probar este modelo en una competencia contra pronosticadores en vivo y también encontrar,cómo se puede mejorar
Además, espero resonar con la comunidad de fanáticos de la Fórmula 1 y creo que a través del intercambio de ideas podemos entender mejor qué constituye los resultados de las calificaciones y las carreras, y este es, en última instancia, el objetivo de cualquier persona que haga predicciones.