bayt.
¿Por qué me este debería preocuparme
Los datos se almacenan en la memoria en forma de estructuras de datos, como objetos, listas, matrices, etc. Pero si desea enviar datos a través de la red o a un archivo, debe codificarlos como una secuencia de baytov. las representaciones en la memoria en una secuencia de bytes se denomina codificación y transformación inversa: dekodirovaniem. Con el tiempo, el diagrama de datos procesado por la aplicación o almacenado en la memoria puede evolucionar, se pueden agregar o quitar nuevos campos al starye. Utilizado codificación debe,,, , so and direct (antiguo code debe be capable read data wrotenewcode) compatibility.
En
este artículo, discutiremos una variedad de formatos de codificación, descubriremos por qué la codificación binaria es mejor que JSON, XML, y también como los métodos de codificación binaria admiten esquemas de cambios
dannyh.
Tipos de codificación de formatos
Haydos tipos de formatos de codificación:
- Texto formatos
- Binario formatos
Texto formatos
Formatos de texto Ejemplos de formatos comunes son JSON, CSV y XML. Los formatos de texto son fáciles de usar y comprender, pero tienen ciertos problemas:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Los formatos de texto ocupan más espacio que la codificación binaria. Por ejemplo, una de las razones es que JSON y XML no tienen esquema y, por lo tanto, deben contener nombres de campo.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}La codificación JSON de este ejemplo toma 82 bytes después de que se haya eliminado todo el espacio en blanco.
Codificación binaria
Para el análisis de datos que solo se usa internamente, puede elegir un formato más compacto o más rápido. A pesar de que JSON es menos detallado que XML, ambos ocupan mucho espacio en comparación con los formatos binarios. En este artículo, discutiremos tres formatos diferentes de codificación binaria:
- Ahorro
- Tampones de protocolo
- Avro
Todos ellos proporcionan una serialización eficiente de datos utilizando esquemas y tienen herramientas para generar código, así como soporte para trabajar con diferentes lenguajes de programación. Todos admiten la evolución del esquema, proporcionando compatibilidad con versiones anteriores y posteriores.
Buffers de ahorro y protocolo
Thrift es desarrollado por Facebook y Protocol Buffers es desarrollado por Google. En ambos casos, se requiere un esquema para codificar los datos. Thrift define un esquema utilizando su propio lenguaje de definición de interfaz (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Esquema equivalente para memorias intermedias de protocolo:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Como puede ver, cada campo tiene un tipo de datos y un número de etiqueta (1, 2 y 3). Thrift tiene dos formatos de codificación binarios diferentes: BinaryProtocol y CompactProtocol. El formato binario es simple como se muestra a continuación y toma 59 bytes para codificar los datos anteriores.
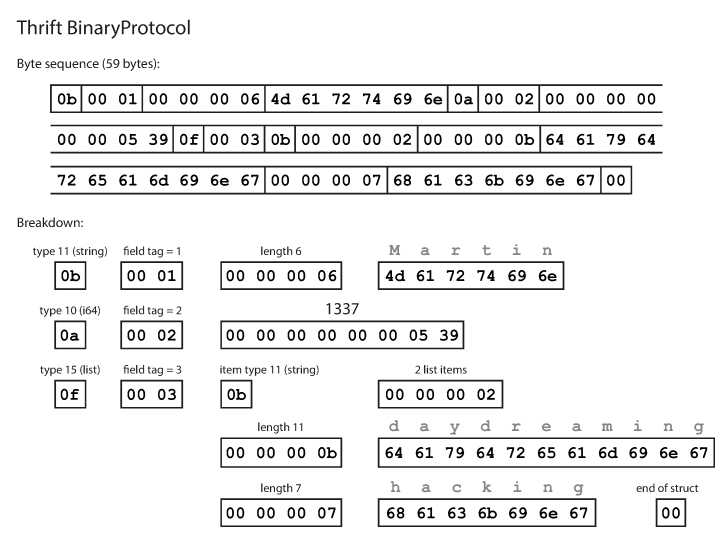
Codificación utilizando el protocolo binario Thrift El protocolo
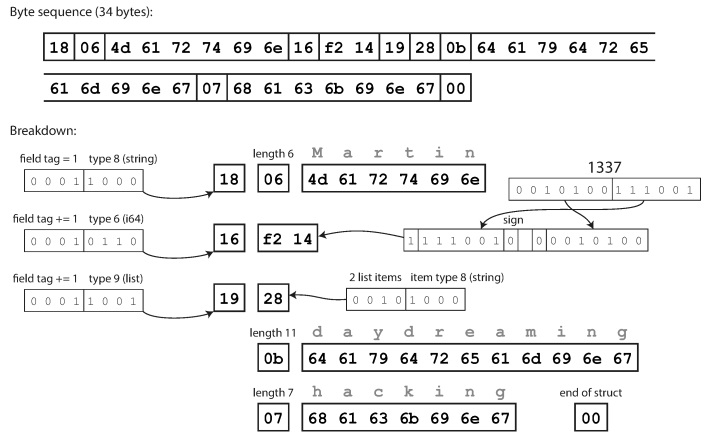
compacto es semánticamente equivalente al binario, pero contiene la misma información en solo 34 bytes. Se logran ahorros al empacar el tipo de campo y el número de etiqueta en un byte.
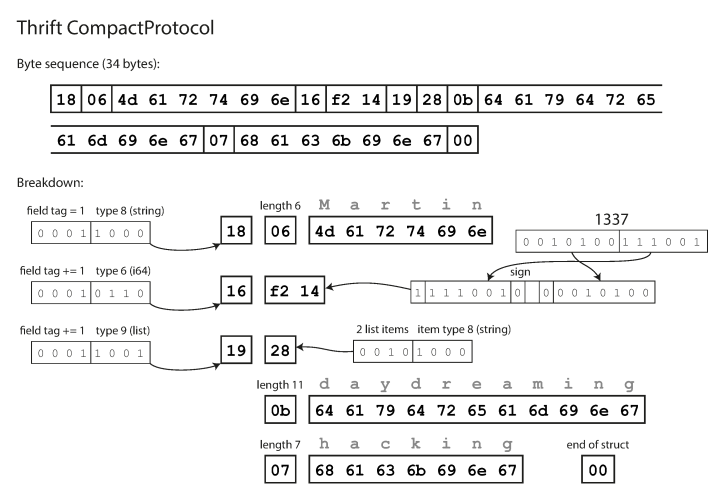
La codificación con el
protocolo de memoria intermedia Thrift Compact codifica los datos de manera similar al protocolo compacto de Thrift, y después de la codificación, los mismos datos son 33 bytes.
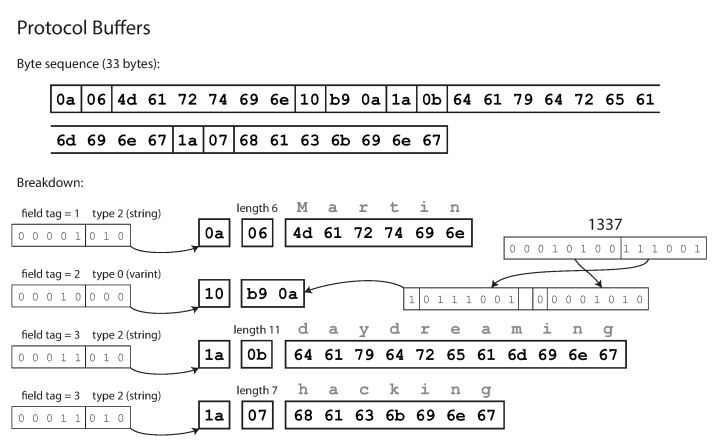
Codificación utilizando búferes de protocolo
Los números de etiqueta admiten la evolución de los esquemas en Thrift y Protocol Buffers. Si el código anterior intenta leer los datos escritos con el nuevo esquema, simplemente ignorará los campos con los nuevos números de etiqueta. Del mismo modo, el nuevo código puede leer datos escritos en el esquema anterior marcando los valores como nulos para los números de etiqueta faltantes.
Avro
Avro es diferente de Protocol Buffers y Thrift. Avro también usa un esquema para definir datos. El esquema se puede definir utilizando Avro IDL (formato legible por humanos):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
O JSON (un formato más legible por máquina):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Tenga en cuenta que los campos no tienen números de etiqueta. Los mismos datos codificados con Avro toman solo 32 bytes.
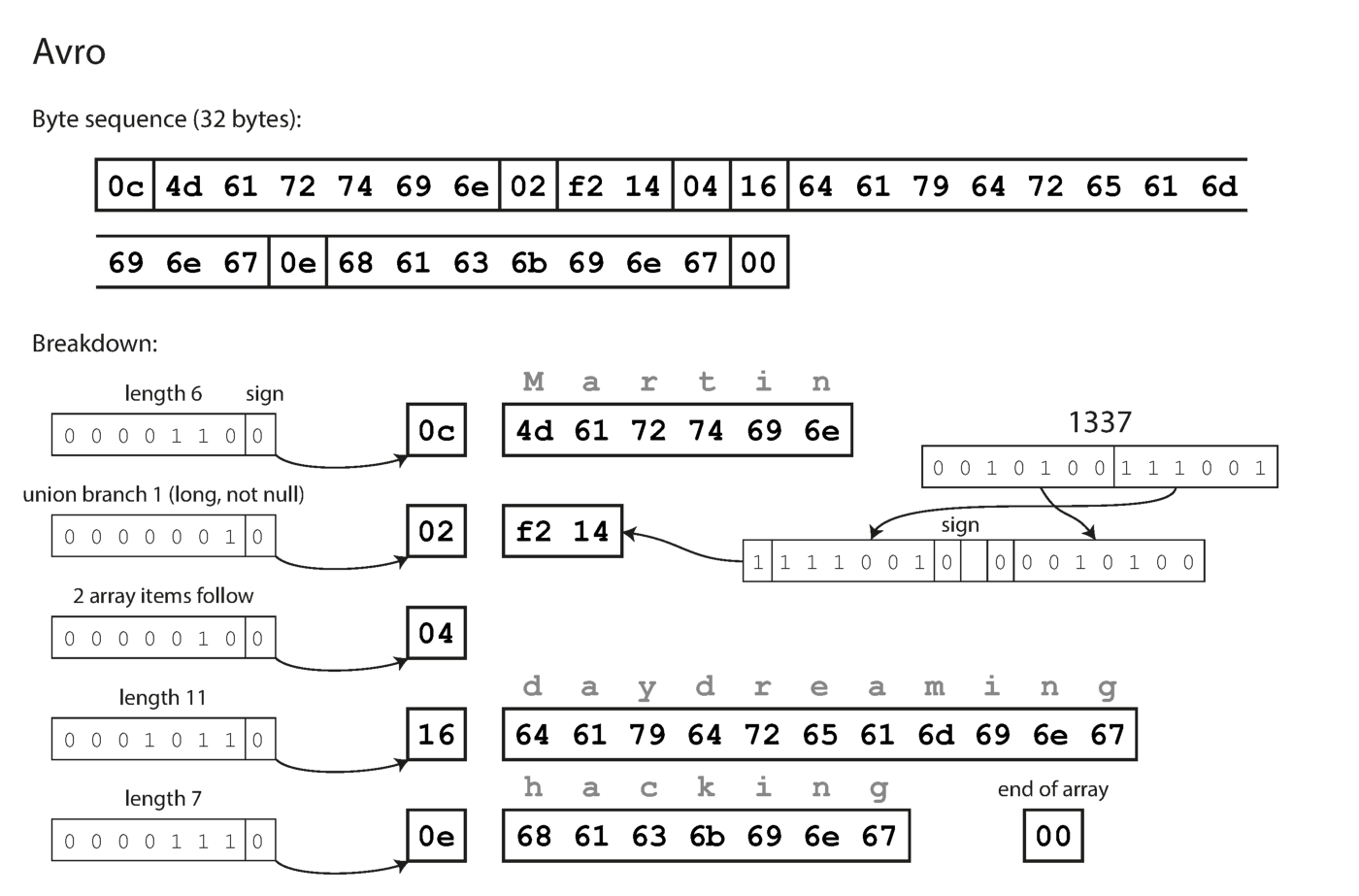
Codificación con Avro.
Como puede ver en la secuencia de bytes anterior, los campos no se pueden identificar (en las etiquetas de Thrift y Protocol Buffers con números se usan para esto), también es imposible determinar el tipo de datos del campo. Los valores simplemente se ponen juntos. ¿Significa esto que cualquier cambio en el circuito durante la decodificación generará datos incorrectos? La idea clave de Avro es que el esquema para escribir y leer no tiene que ser el mismo, pero debe ser compatible. Cuando se decodifican los datos, la biblioteca Avro resuelve este problema observando ambos circuitos y traduciendo los datos desde el circuito del registrador al circuito del lector.
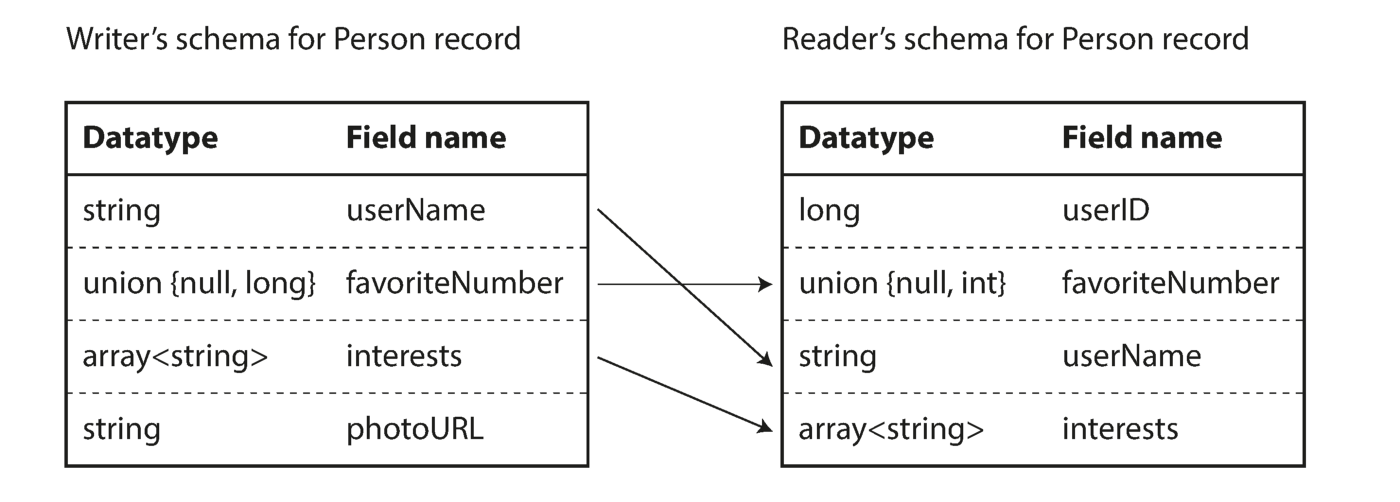
Eliminando la diferencia entre el circuito del lector y el escritor
Probablemente esté pensando en cómo el lector sabe sobre el circuito del escritor. Se trata del escenario de uso de codificación.
- Al transferir archivos o datos grandes, la grabadora puede incluir el circuito al principio del archivo una vez.
- En una base de datos con registros individuales, cada fila se puede escribir con su propio esquema. La solución más simple es incluir un número de versión al comienzo de cada entrada y mantener una lista de esquemas.
- Para enviar un registro a través de la red, el lector y el escritor pueden acordar un esquema cuando se establece la conexión.
Una de las principales ventajas de utilizar el formato Avro es la compatibilidad con esquemas generados dinámicamente. Como no se generan etiquetas numeradas, puede usar un sistema de control de versiones para almacenar diferentes entradas codificadas con diferentes esquemas.
Conclusión
En este artículo, analizamos los formatos de codificación binaria y de texto, discutimos cómo los mismos datos pueden ocupar 82 bytes con JSON codificado, 33 bytes codificados con Thrift y Protocol Buffers, y solo 32 bytes con codificación Avro. Los formatos binarios ofrecen varias ventajas distintas sobre JSON cuando se transfieren datos a través de la red entre servicios de fondo.
Recursos
Para obtener más información sobre la codificación y el diseño de aplicaciones con uso intensivo de datos, le recomiendo leer el libro Diseño de aplicaciones con uso intensivo de datos de Martin Kleppman.

Aprenda los detalles de cómo obtener una profesión solicitada desde cero o subir de nivel en habilidades y salario completando los cursos en línea pagos de SkillFactory:
- Curso de aprendizaje automático (12 semanas)
- Aprendizaje de ciencia de datos desde cero (12 meses)
- Profesión analítica con cualquier nivel inicial (9 meses)
- Curso de Python para desarrollo web (9 meses)
Lee mas
- Tendencias en el escenario de datos 2020
- La ciencia de datos está muerta. Larga vida a la ciencia empresarial
- Geniales científicos de datos no pierden el tiempo en estadísticas
- Cómo convertirse en un científico de datos sin cursos en línea
- 450 cursos gratuitos de la Ivy League
- Data Science : «data»
- Data Sciene : Decision Intelligence