Hoy quiero hablar sobre otra cosa, sobre algo que de ninguna manera pertenece a las mejores prácticas, con la ayuda de la cual es muy fácil dispararse en el pie y hacer que una consulta ejecutada previamente sea más lenta, o ya no se ejecute en absoluto debido a un error ... Se trata de consejos y guías de plan.
Las sugerencias son sugerencias para el optimizador de consultas, se puede encontrar una lista completa en MSDN . Algunos de ellos son realmente sugerencias (por ejemplo, puede especificar OPTION (MAXDOP 4)) para que la consulta se pueda ejecutar con un grado máximo de paralelismo = 4, pero no hay garantía de que SQL Server genere un plan paralelo con esta sugerencia.
La otra parte es una guía directa de acción. Por ejemplo, si escribe OPTION (HASH JOIN), SQL Server creará un plan sin NESTED LOOPS y MERGE JOINs. ¿Y sabes lo que sucederá si resulta que es imposible construir un plan solo con uniones hash? El optimizador lo dirá: no puedo crear un plan y la consulta no se ejecutará.
El problema es que no se sabe con certeza (al menos para mí) qué sugerencias son sugerencias que el optimizador puede utilizar; y qué sugerencias son sugerencias manuales que pueden hacer que la solicitud se bloquee si algo sale mal. Seguramente ya hay una colección preparada donde se describe esto, pero en cualquier caso no es información oficial y puede cambiar en cualquier momento.
Plan Guide es una cosa (que no sé cómo traducir correctamente) que le permite vincular un conjunto específico de sugerencias a una solicitud específica, cuyo texto usted conoce. Esto puede ser relevante si no puede influir directamente en el texto de solicitud generado por el ORM, por ejemplo.
Tanto las sugerencias como las guías de plan no son mejores prácticas, sino que es una buena práctica omitir las sugerencias y estas guías, porque la distribución de datos puede cambiar, los tipos de datos pueden cambiar y pueden ocurrir un millón de cosas más, debido a lo cual sus consultas con sugerencias funcionarán peor que sin ellas, y en algunos casos dejarán de funcionar por completo. Debe ser cien por ciento consciente de lo que está haciendo y por qué.
Ahora una pequeña explicación de por qué incluso me metí en esto.
Tengo una mesa amplia con un montón de campos nvarchar de diferentes tamaños, desde 10 hasta máx. Y hay un montón de consultas en esta tabla, que CHARINDEX busca ocurrencias de subcadenas en una o más de estas columnas. Por ejemplo, hay una solicitud que se ve así:
SELECT *
FROM table
WHERE CHARINDEX(N' ', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLYLa tabla tiene un índice agrupado en Id y un índice no agrupado no único en la columna. Como usted mismo comprende, todo esto no tiene sentido, ya que en DONDE usamos CHARINDEX, que definitivamente no es SARGable. Para evitar posibles problemas con el SB, simularé esta situación en la base de datos abierta StackOverflow2013, que se puede encontrar aquí .
Considere la tabla dbo.Posts, que solo tiene un índice agrupado por Id y una consulta como esta:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYPara que coincida con mi base de datos real, creo un índice en la columna Título:
CREATE INDEX ix_Title ON dbo.Posts (Title);Como resultado, por supuesto, obtenemos un plan de ejecución absolutamente lógico, que consiste en escanear el índice agrupado en la dirección opuesta:
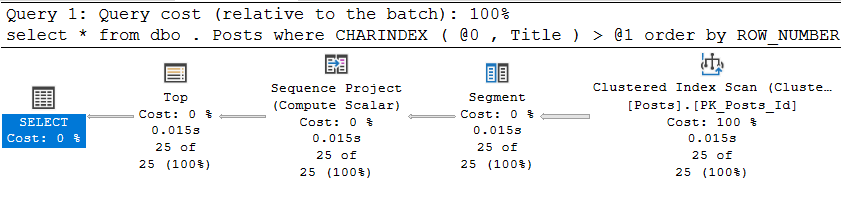

y, ciertamente, se realiza bastante bien:
Tabla 'Publicaciones'. Recuento de escaneo 1, lecturas lógicas 516, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 16 ms
Pero, ¿qué sucede si, en lugar de la palabra común 'Datos', buscamos algo más raro? Por ejemplo, N'Aptana '(no tengo idea de qué es). El plan, por supuesto, seguirá siendo el mismo, pero las estadísticas de ejecución, ejem, cambiarán algo:
Tabla 'Publicaciones'. Recuento de escaneo 1, lecturas lógicas 253191, lecturas físicas 113, lecturas anticipadas 224602, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 2563 ms
Y esto también es lógico: la palabra es mucho menos común y SQL Server tiene que escanear muchos más datos para encontrar 25 filas con ella. Pero de alguna manera no es genial, ¿verdad?
Y estaba creando un índice no agrupado. ¿Quizás sería mejor si SQL Server lo usa? Él mismo no lo usará, así que agrego una pista:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));Y, algo es de alguna manera completamente triste. Estadísticas de ejecución:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
y el plan:

ahora el plan de ejecución es paralelo y tiene dos tipos, ambos con derrames en tempdb. Por cierto, preste atención al primer tipo, que se realiza después de un escaneo de índice no agrupado, antes de la Búsqueda de clave: esta es una optimización especial de SQL Server que intenta reducir el número de E / S aleatorias: las búsquedas de teclas se realizan en orden ascendente de la clave de índice agrupado. Puedes leer más sobre esto aquí .
El segundo orden es necesario para seleccionar 25 líneas en orden descendente Id. Por cierto, SQL Server podría haber adivinado que tendrá que ordenar por Id nuevamente, solo en orden descendente y realizar búsquedas de claves en la dirección "opuesta", ordenando en orden descendente, no ascendente, de la clave de índice agrupada al principio.
No proporciono estadísticas sobre la ejecución de una consulta con una pista sobre un índice no agrupado con una búsqueda por la entrada 'Datos'. En mi disco duro medio muerto en una computadora portátil, me llevó más de 16 minutos y no pensé en tomar una captura de pantalla. Lo siento, ya no quiero esperar tanto.
¿Pero qué hay de la solicitud? ¿Es un escaneo de índice agrupado el último sueño y no puedes hacer nada más rápido?
¿Qué pasaría si tratara de evitar todo tipo? Pensé y creé un índice no agrupado, que, en general, contradice lo que generalmente se considera las mejores prácticas para los índices no agrupados:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Ahora usamos la pista para decirle a SQL Server que lo use:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));Oh, funcionó bien:

Tabla 'Publicaciones'. Cuenta de escaneo 1, lecturas lógicas 6259, lecturas físicas 0, lecturas anticipadas 7816, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 1734 ms
La ganancia en tiempo de procesador no es excelente, pero hay que leer mucho menos, no está mal. ¿Qué pasa con los frecuentes 'Datos'?
Tabla 'Publicaciones'. Cuenta de escaneo 1, lecturas lógicas 208, lecturas físicas 0, lecturas de lectura anticipada 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas de lectura lob 0. 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 0 ms
Wow, eso también es bueno. Ahora, dado que la solicitud proviene del ORM y no podemos cambiar su texto, necesitamos descubrir cómo "clavar" este índice a la solicitud. Y la guía del plan viene al rescate.
El procedimiento almacenado sp_create_plan_guide ( MSDN ) se usa para crear una guía de plan .
Consideremos en detalle:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
} nombre - nombre claro y único de la guía del plan
stmt- esta es la solicitud a la que debe agregar la sugerencia. Es importante saber aquí que esta solicitud debe escribirse EXACTAMENTE igual que la solicitud que proviene de la aplicación. ¿Espacio extraño? La Guía del plan no se utilizará. ¿Salto de línea incorrecto? La Guía del plan no se utilizará. Para hacerte las cosas más fáciles, hay un "truco de vida" al que volveré un poco más tarde (y que encontré aquí ).
tipo - indica dónde se encuentra la solicitud especificada en stmt... Si es parte de un procedimiento almacenado, debería ser OBJETO; Si esto es parte de un lote de varias solicitudes, o es una solicitud ad-hoc, o un lote de una solicitud, debe haber SQL. Si se indica TEMPLATE aquí, esta es una historia separada sobre la parametrización de consultas, sobre la que puede leer en MSDN .
@module_or_batch depende detipo. Si untipo= 'OBJETO', este debería ser el nombre del procedimiento almacenado. Si untipo= 'BATCH': debe haber el texto del lote completo, palabra por palabra especificada con lo que proviene de las aplicaciones. ¿Espacio extraño? Pues ya lo sabes. Si es NULL, consideramos que se trata de un lote de una solicitud y coincide con lo especificado enstmt con todas las restricciones
params- todos los parámetros que se pasan a la solicitud junto con los tipos de datos deben enumerarse aquí.
@hints es finalmente la mejor parte, aquí debe especificar qué sugerencias agregar a la solicitud. Aquí puede insertar explícitamente el plan de ejecución requerido en formato XML, si lo hay. Este parámetro también puede ser NULL, lo que conducirá al hecho de que SQL Server no utilizará sugerencias que se especifican explícitamente en la consulta enstmt...
Entonces, creamos una Guía de plan para la consulta:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Y tratamos de ejecutar la solicitud:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYWow, funcionó:
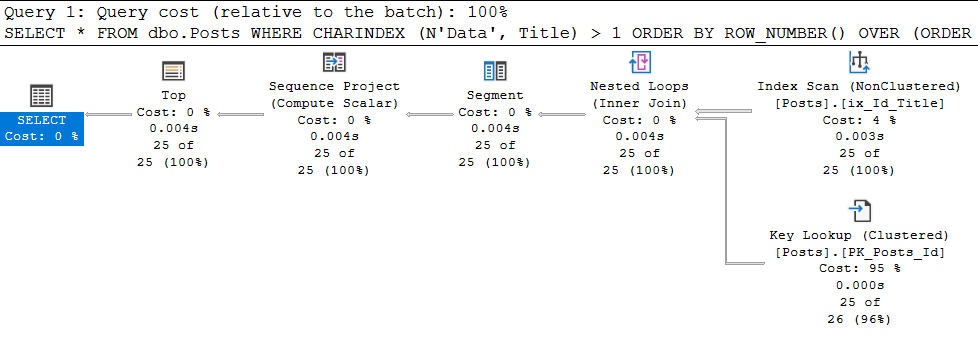
en las propiedades de la última instrucción SELECT, vemos:

Genial, se ha aplicado el plan giude. ¿Qué pasa si buscas 'Aptana' ahora? Y todo será malo: volveremos nuevamente al análisis del índice agrupado con todas las consecuencias. ¿Por qué? Y porque, la guía del plan se aplica a una consulta ESPECÍFICA, cuyo texto coincide uno a uno con el que se ejecuta.
Afortunadamente para mí, la mayoría de las solicitudes en mi sistema vienen parametrizadas. No trabajé con consultas no parametrizadas y espero no tener que hacerlo. Para ellos, puede usar plantillas (vea un poco más arriba sobre PLANTILLA), puede habilitar PARAMETRIZACIÓN FORZADA en la base de datos ( ¡no haga esto sin comprender lo que está haciendo! ) Y, tal vez, después de eso, podrá vincular la Guía del Plan. Pero realmente no lo he probado.
En mi caso, la solicitud se ejecuta en algo como esto:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;Por lo tanto, creo una guía de plan correspondiente:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Y, hurra, todo funciona según lo requerido: al
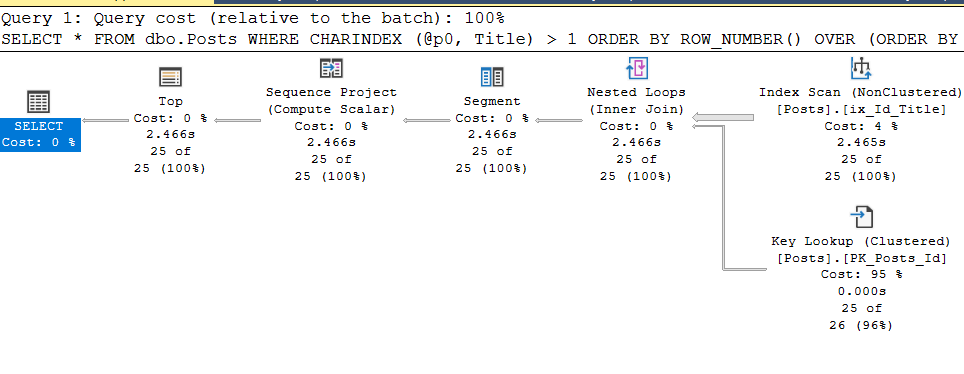

estar fuera de las condiciones del invernadero, no siempre es posible especificar correctamente el parámetrostmtpara adjuntar una guía de plan a una solicitud, y para esto hay un "truco de vida" que mencioné anteriormente. Borramos el caché del plan, eliminamos las guías, ejecutamos la consulta parametrizada nuevamente y obtenemos su plan de ejecución y su plan_handle del caché.
Se puede utilizar una solicitud para esto, por ejemplo, así:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
Ahora podemos usar el procedimiento almacenado sp_create_plan_guide_from_handle para crear una guía de plan a partir de un plan existente.
Toma como parámetrosnombre- el nombre de la guía creada, @plan_handle - el identificador del plan de ejecución existente y @statement_start_offset - que define el comienzo de la declaración en el lote para el que debe crearse la guía.
Molesto:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;Y ahora en SSMS miramos lo que tenemos en Programabilidad -> Guías de plan:

ahora el plan de ejecución actual se ha "clavado" a nuestra solicitud utilizando la Guía de plan 'PG_dboPosts_from_handle', pero, lo mejor de todo, ahora, como casi cualquier objeto en SSMS, podemos escribir y recrear la forma en que lo necesitamos.
RMB, Script -> Drop AND Create y obtenemos un script listo para usar en el que necesitamos reemplazar el valor del parámetro @hints con el que necesitamos, por lo que obtenemos:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GOEjecutamos y volvemos a ejecutar la solicitud. Hurra, todo funciona:

si reemplaza el valor del parámetro, todo funciona de la misma manera.
Tenga en cuenta que solo una guía puede corresponder a una declaración. Si intenta agregar otra guía a la misma declaración, recibirá un mensaje de error.
Msg 10502, Nivel 16, Estado 1, Línea 1
No se puede crear la guía de plan 'PG_dboPosts_from_handle2' porque la declaración especificada porstmty @module_or_batch, o por @plan_handle y @statement_start_offset, coincide con la guía de plan existente 'PG_dboPosts_from_handle' en la base de datos. Descarte la guía de plan existente antes de crear la nueva guía de plan.
Lo último que me gustaría mencionar es el procedimiento almacenado sp_control_plan_guide .
Con su ayuda, puede eliminar, deshabilitar y habilitar las Guías del plan, tanto una a la vez, que indica el nombre como todas las guías (no estoy seguro, todo en absoluto. O todo en el contexto de la base de datos en la que se ejecuta el procedimiento). Los valores se utilizan para esto @ parámetro de operación: DROP ALL, DESABLE ALL, ENABLE ALL. Un ejemplo del uso de HP para un plan específico se proporciona justo arriba: se elimina una guía de plan específica con el nombre especificado.
¿Era posible prescindir de pistas y una guía de plan?
En general, si le parece que el optimizador de consultas es estúpido y hace algún tipo de juego, y sabe cómo hacerlo mejor, con una probabilidad del 99% de que está haciendo algún tipo de juego (como en mi caso). Sin embargo, en el caso de que no tenga la capacidad de influir directamente en el texto de la solicitud, una guía del plan que le permite agregar una pista a la solicitud puede salvarle la vida. Supongamos que tenemos la capacidad de reescribir el texto de la solicitud según lo necesitemos. ¿Puede esto cambiar algo? ¡Por supuesto! Incluso sin el uso de "exótico" en forma de búsqueda de texto completo, que, de hecho, debería usarse aquí. Por ejemplo, dicha consulta tiene un plan completamente normal (para una consulta) y estadísticas de ejecución:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabla 'Publicaciones'. Recuento de escaneo 1, lecturas lógicas 6250, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 1500 ms
SQL Server primero encuentra los 25 identificadores requeridos por el índice "torcido" ix_Id_Title, y solo entonces realiza una búsqueda en el índice agrupado para los identificadores seleccionados, ¡incluso mejor que con la guía! Pero, ¿qué sucede si ejecutamos una consulta en 'Datos' y mostramos 25 líneas, comenzando desde la línea 20,000?
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabla 'Publicaciones'. Cuenta de escaneo 1, lecturas lógicas 5914, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 11, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución del servidor SQL:
tiempo de CPU = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;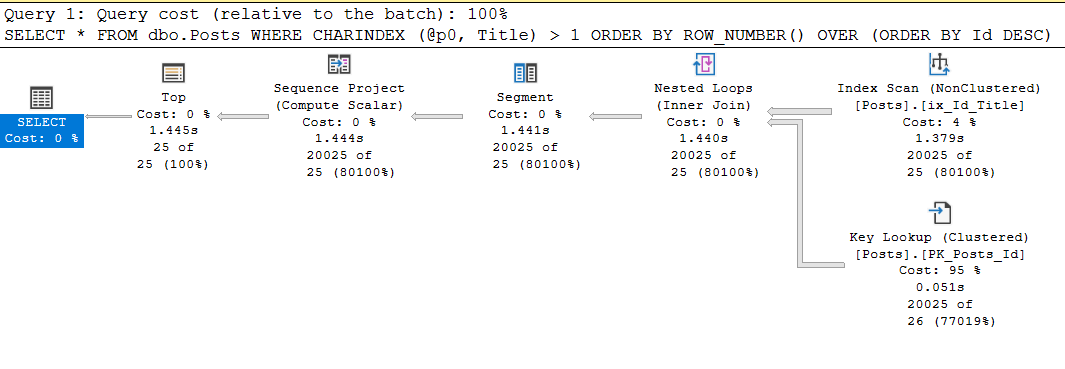
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Sí, el tiempo del procesador es el mismo, ya que se gasta en charindex, pero la solicitud con la guía hace un pedido de magnitud más lecturas, y esto puede convertirse en un problema.
Permítanme resumir el resultado final. Las sugerencias y guías pueden ayudarlo mucho aquí y ahora, pero pueden empeorar las cosas fácilmente. Si especifica explícitamente una pista con un índice en el texto de la solicitud y luego elimina el índice, la consulta simplemente no se puede ejecutar. En mi SQL Server 2017, la consulta con la guía, después de eliminar el índice, se ejecuta bien: la guía se ignora, pero no puedo estar seguro de que siempre será así y en todas las versiones de SQL Server.
No hay mucha información sobre la guía del plan en ruso, así que decidí escribirla yo mismo. Puedes leer aquisobre las limitaciones en el uso de guías de plan, en particular sobre el hecho de que a veces una indicación explícita del índice con una sugerencia usando PG puede conducir al hecho de que las solicitudes caerán. Desearía que nunca los usaras, y si tienes que, bueno, buena suerte, sabes a dónde puede llevarte esto.