¿Qué es I-IoT?
Después de la introducción de la máquina de vapor en 1760, el vapor se utilizó para impulsar todo, desde la agricultura hasta los textiles. Esto provocó la Primera Revolución Industrial y la era de la fabricación mecánica. A finales del siglo XIX, surgió la electricidad, nuevas formas de organizar el trabajo y la producción en masa, lo que marcó el comienzo de la Segunda Revolución Industrial. En la segunda mitad del siglo XX, el desarrollo de semiconductores y la introducción de controladores electrónicos dieron lugar a la era de la automatización y la Tercera Revolución Industrial. En la Feria de Hannover 2011, Henning Kagermann, Wolf-Dieter Lucas y Wolfgang Walster acuñaron el término Industria 4.0 para un proyecto para renovar el sistema de producción alemán utilizando la última tecnología digital.

Se espera que Industry 4.0 pueda implementar lo siguiente:
- Combina la producción con las tecnologías de la información y la comunicación.
- Combina datos de clientes con datos de producción.
- Aproveche al máximo la comunicación de máquina a máquina
- Gestione la producción de forma autónoma, flexible y eficiente, ahorrando recursos
El fundador y presidente del Foro Económico Mundial, Klaus Schwab, cree que la independencia de la cuarta revolución industrial puede justificarse por tres factores.
- El ritmo del desarrollo. A diferencia de las anteriores, esta revolución industrial no está progresando linealmente, sino exponencialmente. Este es un producto del mundo multifacético y profundamente interdependiente en el que vivimos, así como el hecho de que la nueva tecnología en sí misma sintetiza tecnologías cada vez más avanzadas y eficientes.
- . , , , . , «» «» , , «» .
- . , , .
Por definición, IoT es la clave para un mayor desarrollo de la industria, incluidas tecnologías como análisis de big data, tecnologías de nube, robótica y, lo más importante, la integración y convergencia entre TI y fabricación.
El término I-IoT (Internet industrial de las cosas) se refiere al subconjunto industrial de IoT, que es la transformación digital de los negocios naturales. I-IoT hace que los negocios sean más flexibles, más rentables, comprensibles y crea nuevas cadenas de valor digital.
Las cadenas de producción tradicionales son pasos sencillos y secuenciales, como el desarrollo de productos, el abastecimiento y el abastecimiento de materias primas, y la fabricación y servicio de productos. La esencia de la nueva transformación digital es que se está creando un ecosistema de servicios y nuevos modelos de negocio en torno a un determinado núcleo digital, lo que da nuevas cualidades a la producción. Como la reducción de costos entre las diferentes etapas de preparación de la producción, puesta en marcha y operación. Los vínculos entre los diferentes departamentos y etapas son cada vez más rápidos, lo que permite trabajar de manera más eficiente y competitiva en el mercado.
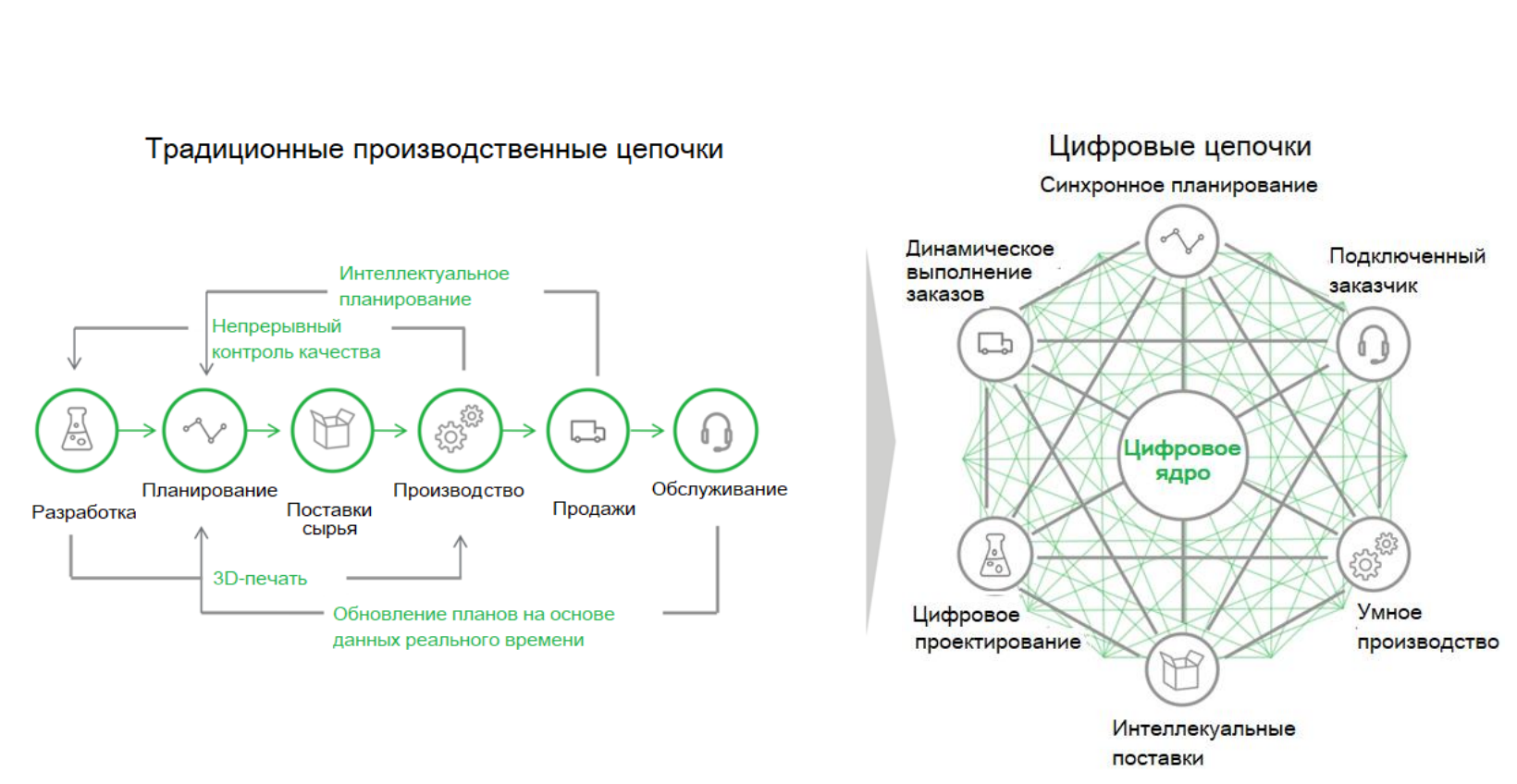
Se espera que I-IoT cree más valor comercial y tenga un impacto tan profundo en la sociedad humana que marcará el comienzo de la Cuarta Revolución Industrial.
Según Forbes:
- IoT 157 2016 457 2020 , 28,5%
- , , IoT 2020 , 40 .
IoT I-IoT –
- , . , , . , .
- , , ; .
- I-IoT , .
- — , , . I-IoT, , .
- .
- , . , , , .
- . I-IoT .
- , .
CIM (fabricación integrada por computadora) es un modelo lógico para sistemas de fabricación desarrollado en la década de 1990 para integrar procesos de fabricación, sistemas de automatización y sistemas de tecnología de la información a nivel de empresa o empresa. CIM no debe verse como un método de diseño para crear fábricas automatizadas, sino más bien como un modelo de referencia para la implementación de la automatización industrial basada en la recopilación, coordinación, intercambio y transferencia de datos e información entre diferentes sistemas y subsistemas a través de aplicaciones de software y redes de comunicación. El CIM a menudo se representa como una pirámide con seis niveles funcionales como se muestra en el siguiente diagrama
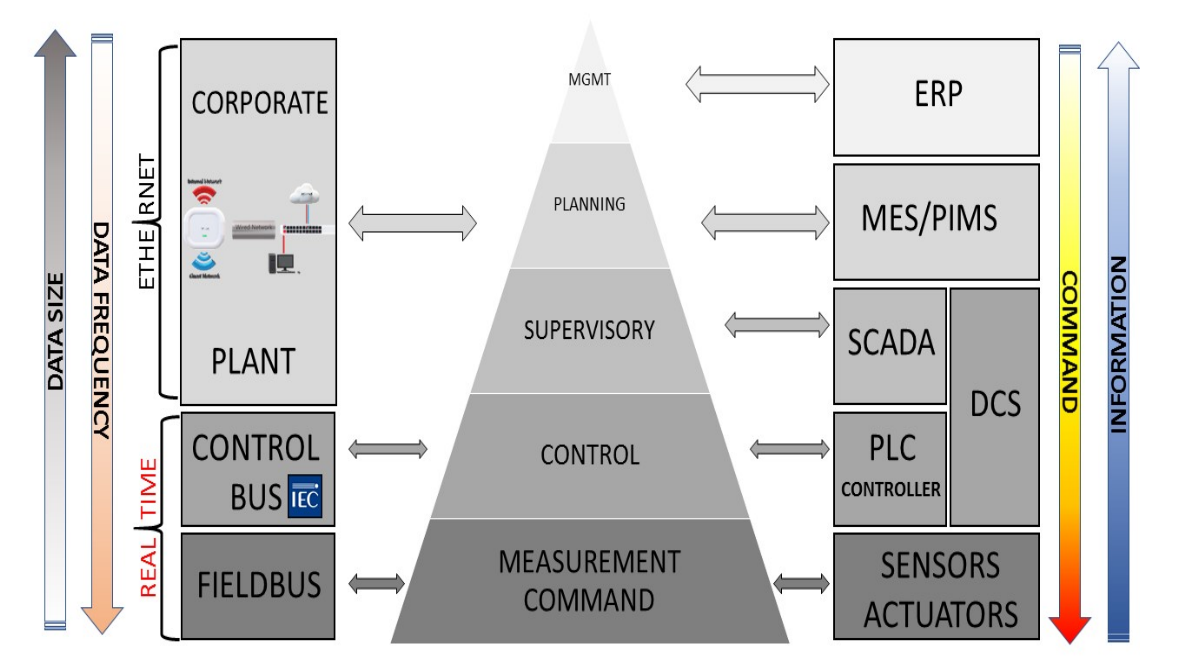
Nivel 1 - Sensores, transductores y actuador
Un sensor electrónico es un instrumento de medición estructuralmente completo capaz de convertir una o más cantidades físicas en una señal eléctrica para posteriores transformaciones, transmisión, procesamiento y visualización de información de medición. Un actuador (actuador) es un dispositivo que convierte un comando de control en un efecto físico en el proceso. De hecho, su función complementa la del sensor. El actuador acepta una señal de control como entrada al sistema de control y transmite energía como salida al mecanismo.
Nivel 2: RTU, microcontroladores, CNC, PLC y DCS
- (Remote terminal unit RTU) — , . , , . , .
- (Embedded controller), , , . .
- (CNC) – , . . , - .
- PLC — , . PLC , , , . , , , . 10 100 .
- Los DCS se usan comúnmente en procesos continuos como refinerías, plantas de energía o plantas químicas. Combinan tanto la función de control implementada en el PLC como la función del sistema de control de supervisión (SCADA). Mientras que PLC y SCADA son dos sistemas separados, cada uno con sus propios espacios de direcciones, en DCS estos sistemas usan las mismas variables y estructuras de datos.
Nivel 3 - SCADA, Historiador
El sistema SCADA es un paquete de software para recopilar, procesar, mostrar y archivar información sobre un objeto de monitoreo o control en tiempo real. Un sistema de recopilación de datos (Historian) recopila información en tiempo real sobre el estado operativo de los equipos. El sistema SCADA implementa las siguientes funciones principales:
- PLC, , RTU , CIM.
- , .
- , , .
- - (HMI).
- HMI PLC.
4 -MES
MES es un sistema de software ubicado entre ERP y SCADA o PLC, diseñado para administrar eficientemente el proceso de producción de una empresa. La función principal de MES es sincronizar la gestión de la empresa y el sistema de fabricación combinando niveles de planificación y control para optimizar procesos y recursos.
Las características principales del sistema MES son:
- Gestión de pedidos y planificación de producción.
- Gestión de materias primas entrantes y productos semiacabados.
- Gestión de activos y monitoreo
- Seguimiento de la producción
- Manejo de mantenimiento
- Control de calidad
Nivel 5 - ERP
ERP incluye paquetes de software que una organización utiliza para administrar las actividades diarias de su negocio, como contabilidad, compras, gestión de proyectos y fabricación. ERP integra y define un conjunto de procesos comerciales que rigen el intercambio de información y datos entre los sistemas involucrados. ERP recopila y transmite datos de transacciones de diferentes departamentos de la organización, asegurando así la integridad de los datos al actuar como una sola fuente.
Redes de producción
Un sistema de producción integrado requiere diferentes tipos de redes de comunicación, cada una dedicada a una tarea específica.
- Nivel 1: bus de campo
- Nivel 2: red de controladores
- Nivel 3, 4, 5: red corporativa
Se han introducido redes de campo para controladores de interfaz, sensores y actuadores, lo que reduce la necesidad de cableado complejo. En el bus de campo, los sensores y actuadores están equipados con un conjunto mínimo de procesamiento para garantizar la transferencia de información de manera determinista.
La red del controlador debe proporcionar comunicación entre los nodos del PLC. La transmisión de datos debe ocurrir a intervalos específicos. Las redes de control y los buses de campo a menudo también se denominan redes en tiempo real debido a la sincronización de la transmisión de datos e información.
Una red corporativa es una red ubicada entre sistemas de gestión y sistemas de planificación y gestión. Esta capa de la red debería garantizar el procesamiento de información compleja, pero en períodos de tiempo más cortos. Por lo tanto, no hay necesidad de un marco de tiempo ajustado para esta capa de red.
Servidor OPC
Ningún otro estándar de comunicaciones industriales ha recibido una aceptación tan extendida entre muchas industrias y fabricantes de equipos como OPC. Se utiliza para integrar una amplia variedad de sistemas industriales y comerciales. SCADA, los sistemas de seguridad (SIS), los controladores lógicos programables (PLC) y los sistemas de control distribuido (DCS) utilizan OPC para comunicarse entre sí, así como con las bases de datos Historian, los sistemas MES y ERP. La razón del éxito de OPC es muy simple: es la única interfaz verdaderamente universal que se puede utilizar para comunicarse con varios dispositivos y aplicaciones industriales, independientemente del fabricante, el software o los protocolos utilizados en el sistema de control. Después de la aparición del estándar OPC, casi todos los SCADA fueron rediseñados como clientes OPC,y cada fabricante de hardware comenzó a suministrar sus controladores, módulos de E / S, sensores inteligentes y actuadores con un servidor OPC estándar.
OPC classic (acceso a datos DA)
En 1995, varias compañías decidieron crear un grupo de trabajo para definir el estándar de interoperabilidad. Estas empresas fueron: Fisher Rosemount, Intellution, Intuitive Technology, Opto22, Rockwell, Siemens AG.
Los miembros de Microsoft también fueron invitados a proporcionar el soporte necesario. La tarea del grupo de trabajo era definir el estándar de acceso a la información en el entorno de Windows basado en las tecnologías modernas de la época. La tecnología desarrollada se denominó Vinculación e incrustación de objetos (OLE) para Control de procesos (OPC). En agosto de 1996, se definió la primera versión del OPC.
El siguiente diagrama muestra las diferentes capas de OPC Classic con los principales protocolos de comunicación: COM, DCOM y Llamada a procedimiento remoto (RPC)
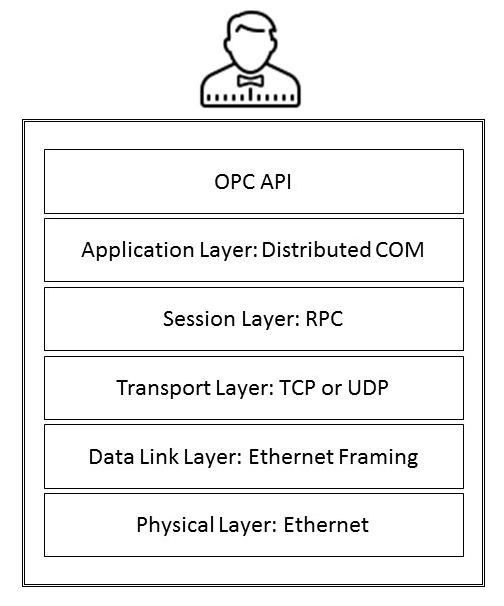
COM es una arquitectura de software desarrollada por Microsoft para crear aplicaciones de componentes. En ese momento, esto permitió a los programadores encapsular piezas de código reutilizables de tal manera que otras aplicaciones pudieran usarlas sin preocuparse por los detalles de su implementación. Los objetos COM se pueden reemplazar con versiones más nuevas sin tener que reescribir las aplicaciones que los usan. DCOM son versiones en red de COM. DCOM intenta ocultar a los desarrolladores de software las diferencias entre los objetos COM que se ejecutan en una computadora y los objetos COM que se ejecutan de forma remota en otra computadora. Para esto, todos los parámetros deben pasarse por valor. Esto significa que cuando se llama a una función proporcionada por un objeto COM, la persona que llama debe pasar los parámetros asociados por valor. Por otra parte,El objeto COM responderá a la persona que llama pasando también los resultados por valor. El proceso de conversión de parámetros en datos transmitidos a través de la red se denomina cálculo de referencias. Una vez que se completa el cálculo de referencias, el flujo de datos se serializa, transmite y restaura a su orden de datos original en el otro extremo de la conexión.
DCOM utiliza el mecanismo RPC para transferir y recibir información de forma transparente entre componentes COM en la misma red. El mecanismo RPC fue desarrollado por Microsoft para permitir a los desarrolladores de sistemas solicitar la ejecución de programas remotos sin tener que desarrollar procedimientos especiales para el servidor. El programa cliente envía un mensaje al servidor con los argumentos adecuados, y el servidor devuelve un mensaje que contiene los resultados del programa ejecutado.
OPC Classic contiene una serie de limitaciones:
- disponible solo en sistemas operativos de la familia Microsoft Windows;
- conexión con tecnología DCOM, cuyo código fuente está cerrado.
- problemas de configuración relacionados con DCOM;
- mensajes de interrupción de comunicaciones DCOM inexactos;
- la incapacidad de DCOM para intercambiar datos a través de Internet;
- incapacidad de DCOM para garantizar la seguridad de la información.
Modelo de adquisición de datos OPC Classic
Los objetivos del estándar OPC Classic son los siguientes:
- Estructura los datos en el lado del servidor para facilitar la recopilación de datos en el lado del cliente.
- Definir servicios de comunicación y mecanismos de comunicación estándar.
En esencia, el estándar OPC Classic funciona de la siguiente manera.
El servidor gestiona todos los datos disponibles.
El servidor envía solicitudes de datos desde dispositivos a pedido y actualiza la memoria caché interna regularmente. El servidor inicializa y administra la memoria caché para cada grupo de variables solicitadas por el cliente OPC. La velocidad de exploración en el lado del cliente OPC no puede ser inferior a la velocidad de exploración en el servidor OPC para recopilar datos de los dispositivos y actualizar su caché interna. Recomendamos que configure el cliente OPC para leer desde el caché y lo actualice al doble de la velocidad que el servidor OPC busca dispositivos. Cada pieza de datos intercambiados tiene su propio significado, indicado por su sello de tiempo y calidad. El intercambio de datos incluye lectura, escritura y actualización automática cuando los valores cambian. La lectura o el sondeo son realizados por el cliente OPC, que envía regularmente solicitudes de datos grupales.La fase de grabación puede ser síncrona o asíncrona. Las actualizaciones automáticas utilizan la tasa de solicitud proporcionada por el cliente OPC. El servidor OPC comprueba cada actualización para ver si el valor absoluto del valor en caché menos el valor actual es mayor que la zona muerta especificada por el cliente multiplicada por el rango configurado para esa variable. Se puede escribir así:
if (abs(last_cached_value – current_value) > (PERCENT_DEAD_BAND/100) * range) {
//cache is updated, and the client is notified through a callback mechanism
}
La información del servidor OPC se organiza en grupos de elementos relacionados para mayor eficiencia. Hay dos tipos diferentes de grupos:
- Grupos públicos: disponibles para cualquier cliente
- Grupos locales: solo disponibles para el cliente que los creó
OPC UA
La primera respuesta de la Fundación OPC a las crecientes limitaciones de la adopción de COM y DCOM fue el desarrollo de OPC XML-DA. Conservó las características de OPC, pero adoptó una infraestructura de comunicaciones que no está asociada ni con el fabricante ni con una plataforma de software específica. La conversión de las especificaciones OPC-DA a versiones basadas en servicios web ha demostrado ser insuficiente para satisfacer las necesidades de las empresas que interactúan e integran cada vez más con el mundo corporativo y externo.
Para obtener información sobre la arquitectura OPC UA, consulte opcfoundation.org/developer-tools/specifications-unified-architecture .
Por lo tanto, el protocolo OPC UA se desarrolló para reemplazar todas las versiones existentes basadas en COM y superar problemas de seguridad y rendimiento. El estándar aborda la necesidad de interfaces independientes de la plataforma y permite la creación de modelos de datos extensibles para describir sistemas complejos sin perder funcionalidad. OPC UA se basa en el enfoque orientado a servicios definido por el estándar IEC 62451. Tiene los siguientes objetivos:
- Uso de componentes OPC en plataformas que no son de Windows
- Le permite integrar sus componentes principales en dispositivos pequeños.
- Implementa comunicación estándar a través de sistemas basados en firewall
Desde un punto de vista técnico, OPC UA funciona de la siguiente manera:
- API aísla el código del cliente y el servidor de la pila OPC UA
- UA stack convierte llamadas de API a mensajes
- UA stack recibe mensajes enviándolos al cliente o servidor a través de API

Modelo de información OPC UA
Principios básicos del modelado de información en OPC UA:
- Uso de métodos orientados a objetos, incluida la jerarquía de herencia.
- Se utiliza el mismo mecanismo para acceder a tipos e instancias.
- La información se pone a disposición mediante el uso de nodos completamente conectados en la red.
- Las jerarquías de tipos de datos y los enlaces entre nodos son extensibles.
- No hay restricciones sobre cómo modelar información.
- El modelado de información siempre se aloja en el lado del servidor.
El conjunto de objetos e información relacionada que el servidor OPC UA pone a disposición de los clientes es el espacio de direcciones. Puede pensar en el espacio de direcciones como una implementación del modelo de información OPC UA.
Un espacio de direcciones OPC UA es una colección de nodos que están vinculados por enlaces. Cada nodo tiene propiedades llamadas atributos. Debe existir un cierto conjunto de atributos en todos los nodos. La relación entre nodos, atributos y enlaces se muestra en el siguiente diagrama
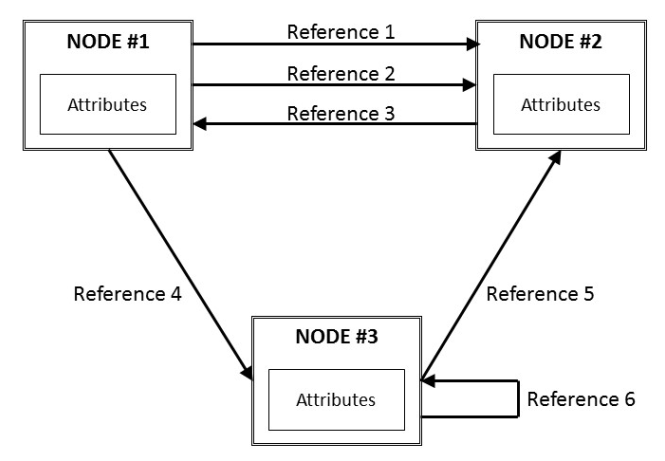
Los nodos pueden pertenecer a diferentes clases de nodos, dependiendo de su propósito específico. Algunos nodos pueden representar instancias, otros pueden representar tipos, etc. OPC UA tiene ocho clases de nodos estándar: variable, objeto, método, vista, tipo de datos, tipo variable, tipo de objeto y tipo de referencia. En OPC UA, las clases de nodo más importantes son objeto, variable y método.
Sesiones de OPC UA
OPC UA proporciona un modelo de comunicación cliente-servidor que incluye información de estado. Esta información de estado está relacionada con la sesión. Una sesión se define como una conexión lógica entre un cliente y un servidor. Cada sesión es independiente del protocolo de comunicación subyacente; cualquier problema a nivel de protocolo no finaliza automáticamente la sesión. La sesión finaliza después de una solicitud explícita del cliente o debido a la inactividad del cliente. Los intervalos de inactividad se establecen durante la creación de la sesión.
Modelo de seguridad OPC UA
El modelo de seguridad OPC UA se implementa definiendo el canal seguro en el que se basa la sesión. El canal seguro intercambia datos de la siguiente manera:
- Asegura la integridad de los datos mediante firmas digitales.
- Proporciona privacidad a través del cifrado.
- Autentica y autoriza aplicaciones con certificados X.509.
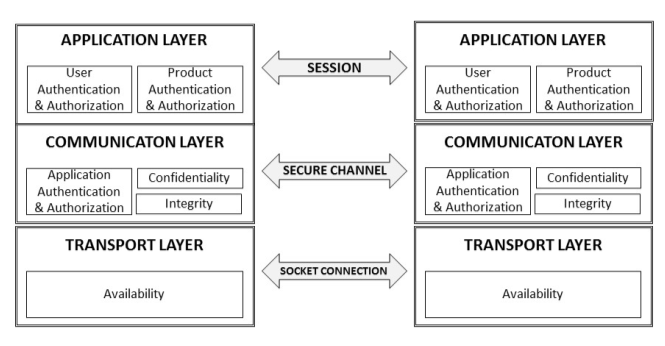
La figura muestra las siguientes capas: capa de aplicación, capa de sesión y capa de transporte.
La capa de aplicación se utiliza para transferir información entre clientes y servidores que han establecido una sesión de OPC UA. La sesión OPC UA se establece en un canal seguro. La capa de transporte es la capa responsable de enviar y recibir datos a través de una conexión de socket, a la que se aplican mecanismos de manejo de errores para garantizar que el sistema esté protegido contra ataques como la denegación de servicio (DoS).
OPC UA intercambio de datos
La forma más fácil de intercambiar datos entre un cliente OPC UA y un servidor es usar servicios de lectura y escritura. Los servicios de lectura y escritura están optimizados para transferir un grupo de datos, en lugar de una sola pieza de datos o valores múltiples. Le permiten leer y escribir los valores o los atributos de los nodos. El servicio de lectura tiene los siguientes parámetros:
maxAge: es el tiempo máximo que se tarda en obtener los valores. Esto lo indica el cliente. Obliga al servidor a contactar un dispositivo (como un sensor) si la copia en su caché es anterior al parámetro maxAge configurado por el cliente. Si maxAge se establece en cero, el servidor debe proporcionar el valor actual, siempre leyéndolo directamente desde el dispositivo.
Tipo de marca de tiempo: OPC UA define dos marcas de tiempo: la marca de tiempo de origen y la marca de tiempo del servidor. La marca de tiempo original es la marca de tiempo que proviene del dispositivo, y la marca de tiempo del servidor es la marca de tiempo que proviene del sistema operativo en el que se ejecuta el servidor OPC UA.
La lista de nodos y atributos se ve así:
- NodeId
- AttributeId para valor de instancia
- Codificación de datos: esto permite al cliente elegir una codificación de datos adecuada, y los valores predeterminados son XML, binario UA
Características del protocolo OPC
El protocolo OPC no se puede llamar completamente libre. Para desarrollar software utilizando el SDK de OPC, debe ser miembro de la Fundación OPC. Sin embargo, ahora hay implementaciones gratuitas de la biblioteca de cliente y servidor, por ejemplo freeopcua.github.io , pero aún no tienen una implementación de pub / sub.
En comparación con otros protocolos como MQTT, OPC no es ligero.
Controlador lógico programable PLC
El término PLC (Controlador lógico programable, PLC) se definió posteriormente en las normas EN 61131 (IEC 61131). PLC es un sistema de control electrónico digital unificado especialmente diseñado para su uso en entornos industriales. El PLC monitorea constantemente el estado de los dispositivos de entrada y toma decisiones basadas en el programa del usuario para controlar el estado de los dispositivos de salida.
Requisitos para PLC:
- Debe poder funcionar en condiciones industriales duras, como temperaturas extremas, suciedad, red de suministro de energía de baja calidad.
- Debe funcionar con señales de entrada y salida discretas de 24 V CC o 240 V CA específicas de la industria, así como señales analógicas (± 10 V, 4-20 mA, etc.)
- El lenguaje de programación debe ser entendido por los ingenieros de automatización.
- El PLC debe monitorear continuamente el funcionamiento de la instalación industrial.
- El sistema operativo debe ser lo suficientemente rápido como para realizar un ciclo de exploración (20 - 100 ms)
La siguiente figura muestra la estructura del modo operativo básico del PLC (utilizando el ejemplo de CPU Simatic).

OPC UA con SIMATIC S7-1500
Requisitos previos: se debe instalar Simatic TIA Portal V13-16
Para simular un controlador con un servidor OPC, se debe instalar y configurar SIMATIC S7-PLCSIM Advanced versión 2 o 3.
Support.industry.siemens.com/cs/document/109772889/trial -download% 3A-simatic-s7-plcsim-advanced-v3-0? dti = 0 & lc = es-WWHe instalado la versión 3 del simulador en un sistema con un paquete existente de Simatic TIA Portal V14 SP1. Antes de la instalación, el instalador notificó que PLCSIM V14 no es compatible con SIMATIC S7-PLCSIM V3 y debe eliminarse. Seguí estos pasos, después de lo cual se suspendió la instalación. Se ha creado un proyecto de prueba en el TIA Portal con la CPU 1512C-1 PN. Una característica especial fue que se hizo imposible realizar la simulación usando el botón "Iniciar simulación", pero el botón "Descargar al dispositivo" funciona cuando se ejecuta PLCSIM Advanced.
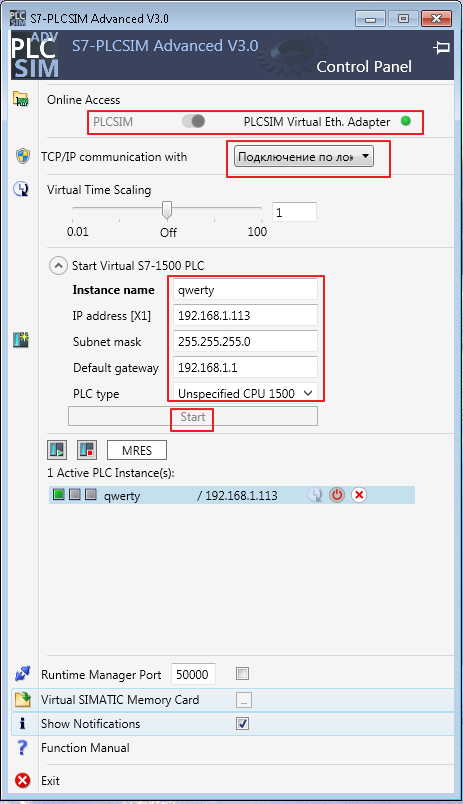
Para acceder al simulador a través de la red, debe habilitar PLCSIM Virtual Eth. Adaptador, para el cual primero debe instalar el software WinPcap. A continuación se encuentran las configuraciones estándar de Ethernet.
Después de presionar el botón "Inicio", el simulador se vuelve activo y visible en la red
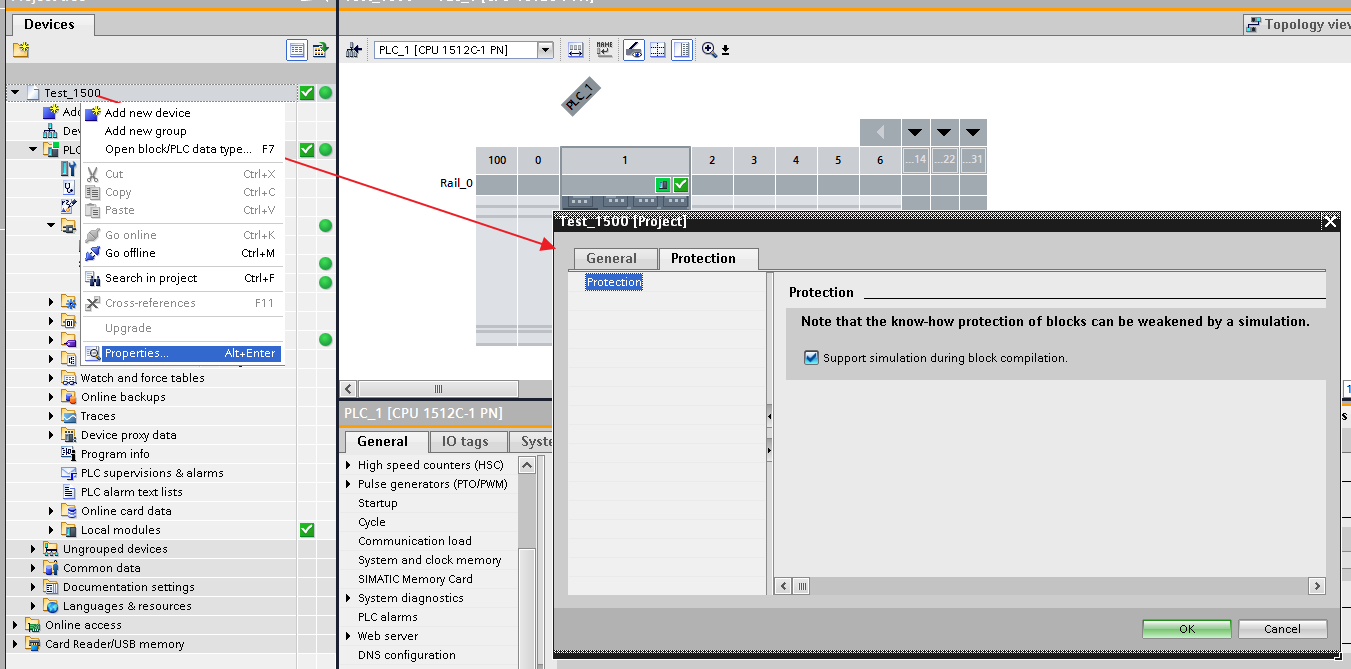
A continuación, debe configurar la casilla de verificación "Simulación de soporte durante la compilación de bloques" en la pestaña "Protección" en el cuadro de diálogo para llamar al menú contextual "Propiedades" en la raíz del proyecto
El siguiente paso es activar el servidor OPC en el proyecto y seleccionar el tipo de licencia (puede pasarlo por alto, después de lo cual el proyecto no se compilará)

Además, el proceso de carga de software a PLCSIM Advanced es similar a la carga a un simulador estándar, con la excepción del descrito anteriormente.
En el proyecto de prueba del TIA Portal, DB1 se creó con una etiqueta "presión" y se asignó la salida digital "Q0.1 Tag_2".
Para conectarse al servidor OPC y monitorear la red, los nodos y las etiquetas, puede usar el cliente UaExpert OPC, que se puede descargar desde www.unified-automation.com/products/development-tools/uaexpert.html .
Para conectarse al servidor OPC, debe agregar una nueva conexión y registrar la URL de punto final, previamente establecida en la configuración del proyecto del servidor OPC en TIA Portale, en mi caso es opc.tcp: //192.168.1.113: 4840

Cuando conecta el cliente OPC al servidor del simulador, puede observar los nodos y las etiquetas creadas.

Para la implementación programática de la interacción del cliente y servidor OPC, puede usar la implementación de código abierto de la biblioteca en Python github.com/FreeOpcUa/python-opcua , también hay ejemplos con código. Antes de usar, debe instalar las dependencias necesarias:
pip install freeopcua
pip install cryptography
El ejemplo más simple de crear un servidor OPC con tres etiquetas
from opcua import Server
from random import randint
import datetime
import time
class Opc:
def __init__(self):
self.server = Server()
self.url = "opc.tcp://127.0.0.1:4848"
self.server.set_endpoint(self.url)
self.namespace_uri = "OPCUA_SIMULATION_SERVER"
self.namespace = self.server.register_namespace(self.namespace_uri)
self.root_node = self.server.get_objects_node()
self.parameters = self.root_node.add_object(self.namespace, "Parameters")
def create_variable(self, name, initial=0):
variable = self.parameters.add_variable(self.namespace, name, initial)
variable.set_writable()
return variable
def main():
opc = Opc()
tag_1 = opc.create_variable("Temperature", 25)
tag_2 = opc.create_variable("Pressure")
tag_3 = opc.create_variable("Time")
opc.server.start()
print("Server started at {}".format(opc.url))
while True:
#tag_1.set_value(randint(10, 50))
tag_2.set_value(randint(200, 999))
tag_3.set_value(datetime.datetime.now())
time.sleep(2)
if __name__ == '__main__':
main()
El mismo ejemplo más simple de la parte del cliente.
from opcua import Client
import time
url = "opc.tcp://127.0.0.1:4848"
client = Client(url)
client.connect()
print("Client connected")
Temp = client.get_node("ns=2;i=2")
Temp.set_value(25)
if __name__ == '__main__':
while True:
temperature = Temp.get_value()
print(temperature)
time.sleep(1)
También es posible observar la conexión utilizando el cliente UaExpert

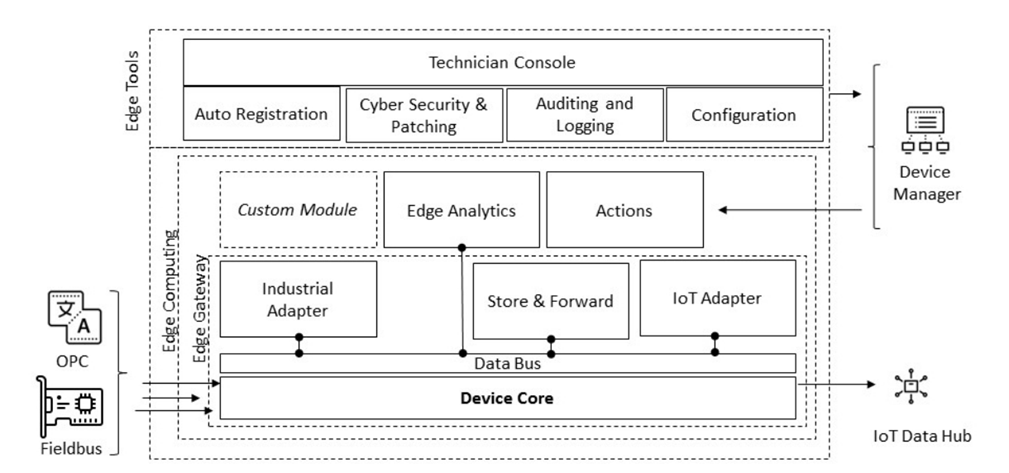
Concepto de borde I-IoT
Edge es el centro entre el entorno de producción y el mundo de IoT en la nube. Edge se puede descomponer en tres componentes macro: Edge Gateway, herramientas Edge, Edge Computing
En 2017, Gartner anunció lo siguiente: "The Edge se comerá la nube". Si bien esta declaración puede sonar un poco controvertida, destaca el papel que Edge ha desempeñado a lo largo de los años. Las empresas industriales, después de una fase de transición a la nube, se dieron cuenta de que no siempre es posible hacer todo en una ubicación remota. Las razones para esto son las siguientes:
- . . , , . .
- : . , , , , 1 50 .
- Latencia de red: los controles de proceso avanzados o análisis asociados con cambios de datos en el comportamiento del equipo de perfil en una ventana de tiempo pequeña sufren de latencia de red alta y variable. La optimización del equipo es necesaria para la ejecución más rápida dentro de un cierto intervalo de tiempo.
- Conección de datos. Para optimizar el flujo de trabajo o mantener el equipo, debe reemplazar los componentes sin acceso a la conexión a Internet.
Edge Gateway
La puerta de enlace de borde es el núcleo del dispositivo de borde. El deber principal de la puerta de enlace perimetral es conectarse a una fuente industrial para recopilar y enviar datos al centro I-IoT mediante un protocolo de transmisión como MQTT, CoAP, HTTPS o AMQP.
Los componentes más importantes de una puerta de enlace perimetral son el adaptador industrial y el adaptador IoT. Un adaptador industrial generalmente se suscribe a los datos del área de campo y los publica en el bus de datos. Por lo general, implementa el conector para el dispositivo seleccionado, actuando como una fuente en el flujo de datos I-IoT y haciéndolo disponible en el bus de datos Edge. Un adaptador IoT, por otro lado, recibe valores del bus de datos y los transmite al IoT Data Hub. Una parte importante de Gateway Edge es el componente Almacenar y reenviar. Es un mecanismo general para almacenar datos en almacenamiento local temporal. Proporciona robustez en la transmisión de datos contra la inestabilidad de la red. En la red global, la inestabilidad y la latencia del canal de comunicación son muy altas. El mecanismo de almacenamiento y reenvío puede ser el siguiente:
- Memoria intermedia limitada que cubre un corto período de inactividad
- Un área de almacenamiento dedicada en el disco que puede acomodar largos períodos de inactividad o gran tráfico de datos.
El rango del intervalo de tiempo durante el cual debe garantizarse la transferencia de datos depende de los escenarios específicos y los recursos físicos de la memoria y el almacenamiento perimetrales.
Utilidades de configuración (herramientas Edge)
Las herramientas de borde deben tener las siguientes características:
- La capacidad de gestionar y configurar fácilmente la recopilación de datos de forma remota y local
- Posibilidad de registrarse para correcciones y actualizaciones
- Posibilidad de iniciar sesión acciones
- Capacidad para ver y modificar datos utilizando la interfaz de usuario
- Autoconfiguración y autoinscripción en la nube al inicio
- Capacidad para recibir y ejecutar comandos desde la nube
Computación de borde
Edge computing tiene las siguientes características:
- Capacidad para realizar acciones utilizando el software I-IoT (middleware), tanto fuera de línea como en línea.
- Posibilidad de alojar aplicaciones personalizadas.
- La capacidad de ejecutar análisis sin conexión, junto con el middleware I-IoT o de forma remota.
- Capacidad para realizar acciones o cargar análisis desde el middleware I-IoT
- Capacidad para enviar datos no estructurados y específicos a middleware I-IoT a pedido o en inicio condicional
Implementaciones de borde
Los proveedores de la nube y los fabricantes de equipos originales (OEM) desarrollan diversas soluciones basadas en su propio sistema operativo u ofrecen kits de desarrollo de software (SDK) independientes de la nube.
Azure IoT Edge
Azure IoT Edge es la solución Edge de Microsoft para Azure IoT. La plataforma admite almacenamiento y reenvío, Edge Analytics y múltiples adaptadores para convertir protocolos nativos o estándar a protocolos de Internet. Azure IoT Edge también admite el servidor OPC en sus implementaciones OPC Classic y OPC-UA. Descripción del producto:
- Funciona con dispositivos Linux o Windows que admiten subsistemas de contenedores.
- Tiempo de ejecución gratuito, de código abierto y con licencia MIT
- Contenedores compatibles con Docker de los servicios de Azure o de la interfaz de nube de socios de Microsoft. Le permite administrar e implementar de forma remota cargas de trabajo desde la nube utilizando IoT Hub
Césped verde
Greengrass es la próxima generación de IoT Edge de AWS. AWS proporciona el SDK para construir AWS Edge y extiende las capacidades de la nube a dispositivos de borde con Greengrass. Esto permite que los dispositivos tomen medidas localmente mientras aún usan la nube para la administración, análisis y almacenamiento persistente. Greengrass es compatible con OPC UA y no es compatible con OPC Classic. Beneficios:
- Respuesta a eventos casi en tiempo real
- Trabajar sin conexión
- AWS IoT Greengrass autentica y cifra los datos del dispositivo, tanto a través de la LAN como con la nube
- Programación simplificada de dispositivos con soporte de contenedores
Cosas de Android
Google proporciona un SDK para el desarrollo de Edge. Patrocina Android como la próxima generación de dispositivos Edge. Características de la plataforma:
- Desarrollo con Android SDK y Android Studio
- Acceso a hardware como pantalla y cámara a través de la plataforma Android
- Conectar la aplicación a los servicios de Google
- Integración de periféricos adicionales a través de API periférica de E / S (GPIO, I2C, SPI, UART, PWM)
- Uso de Android Things Console para enviar actualizaciones por aire y actualizaciones de seguridad
Nodo-ROJO
Es una herramienta de programación visual para Internet de las cosas que permite que dispositivos, API y servicios en línea se conecten entre sí. El tiempo de ejecución de Node-RED está construido sobre Node.js y, por lo tanto, aprovecha al máximo su modelo sin bloqueo controlado por eventos. Node-RED es una herramienta de programación de transmisión desarrollada originalmente por el equipo de IBM Emerging Technology Services y que actualmente forma parte de la Fundación JS.
caracteristicas:
- Crear lógica de programa directamente en el navegador
- El tiempo de ejecución de Node-RED está construido sobre Node.js
- Las secuencias (unidades lógicas) creadas en Node-RED se guardan en archivos JSON que se pueden exportar e importar fácilmente
- La ejecución es posible en cualquier dispositivo que admita node.js
- Una gran cantidad de extensiones
Intel IoT Gateway
caracteristicas:
- Nube y conectividad empresarial.
- Conectable a sensores y controladores existentes.
- Prefiltrando los datos seleccionados para la entrega.
- Toma de decisiones locales para garantizar una fácil conectividad a los sistemas heredados.
- Cifrado de datos de hardware y bloqueo de software.
- Computación local y análisis en el dispositivo.
Flogo iot
Project Flogo es un ecosistema ligero y de código abierto basado en Go para crear aplicaciones basadas en eventos. Los disparadores y las acciones se utilizan para procesar eventos entrantes. La interfaz de interacción proporciona capacidades clave como integración de aplicaciones, procesamiento de flujo, etc.
- Motor de aplicación de flujos de integración con ramificación condicional y entorno de desarrollo visual
- La transmisión es una acción simple de procesamiento de transmisión basada en canalizaciones con la capacidad de agregar eventos a través de múltiples disparadores y agregar a través de ventanas de tiempo.
- Reglas declarativas para decisiones contextuales en tiempo real.
- Patrón Microgateway para enrutamiento condicional basado en contenido, validación JWT, limitación de velocidad, interrupción de circuito y más
Eclipse kura
Eclipse Kura es un IoT Edge Framework extensible de código abierto basado en Java / OSGi. Kura ofrece acceso API a las interfaces de hardware de la puerta de enlace IoT (puertos seriales, GPS, temporizador de vigilancia, GPIO, I2C, etc.). Incluye protocolos de campo listos para usar (incluidos Modbus, OPC-UA, S7), contenedor de aplicaciones y programación visual basada en web para la adquisición, procesamiento y publicación de datos en plataformas en la nube.
Fundición EdgeX
EdgeX FoundryTM es un proyecto de código abierto neutral para proveedores respaldado por la Fundación Linux que crea un entorno abierto común para la informática de borde de IoT. En el corazón del proyecto hay una infraestructura de interoperabilidad alojada en una plataforma de software de referencia independiente del sistema operativo completa para crear un ecosistema plug-and-play que unifique el mercado y acelere el despliegue de soluciones de IoT.
Opciones de conectividad perimetral para fuentes de datos industriales
- Borde en bus de campo
- Edge en OPC DCOM
- Edge en el proxy OPC
- Edge en OPC UA
- OPC UA en el controlador
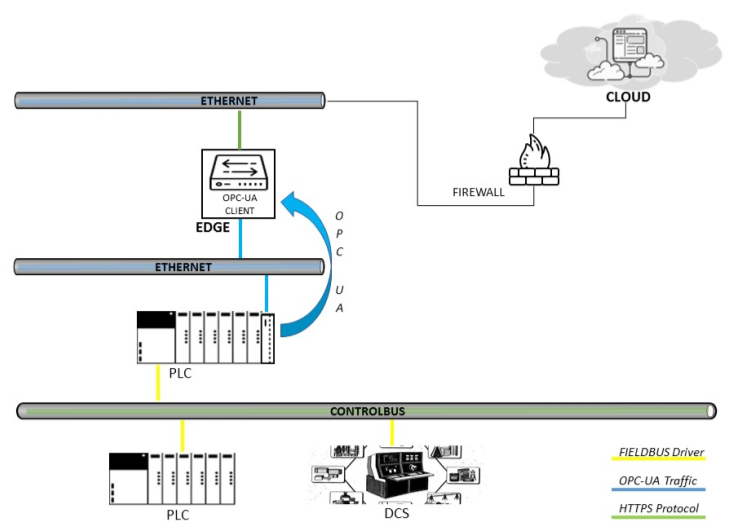
Edge en OPC UA y en el controlador
La conexión a un servidor OPC UA es el escenario preferido ya que maximiza las capacidades de OPC UA. La conexión al servidor OPC se puede implementar de dos maneras diferentes. En el primer caso, Edge se conecta al servidor OPC UA a través de su interfaz de cliente OPC UA. La fuente de datos puede ser una de: PLC, DCS, SCADA o Historian.

En el segundo caso, Edge se conecta al servidor OPC instalado directamente en el PLC, como se discutió anteriormente con la CPU Simatic 1500.
Protocolo MQTT
Pub / sub es una forma de separar un cliente que envía un mensaje de otro cliente que recibe un mensaje. A diferencia del modelo cliente-servidor, los clientes no conocen ningún identificador físico, como una dirección IP o un puerto. MQTT es una arquitectura de pub / sub, no una cola de mensajes. Las colas de mensajes, por su propia naturaleza, almacenan mensajes, mientras que MQTT no. En MQTT, si nadie se suscribe (o escucha) un tema, simplemente se ignora y se pierde.

El cliente que envía el mensaje se llama editor; el cliente que recibe el mensaje se llama suscriptor. En el centro está el agente MQTT, que es responsable de conectar clientes y filtrar datos. Dichos filtros proporcionan:
- Filtrado por temas: por diseño, los clientes se suscriben a temas y a ciertas ramas de temas y no reciben más datos de los que desean. Cada mensaje publicado debe contener un asunto y el corredor es responsable de retransmitir este mensaje a los suscriptores o ignorarlo;
- filtrado de contenido: los corredores tienen la capacidad de verificar y filtrar los datos publicados. Por lo tanto, cualquier información que no esté encriptada puede ser administrada por el agente antes de ser almacenada o transferida a otros clientes;
- filtrado por tipo: un cliente que escucha una secuencia de datos a la que está suscrito también puede aplicar sus propios filtros. Los datos entrantes se pueden analizar y, dependiendo de esto, el flujo de datos se procesa más o se ignora.
Hay tres niveles de calidad de servicio en MQTT:
- QoS-0 ( ) – QoS. « », . ;
- QoS-1 ( ) – . , PUBACK;
- QoS-2 ( ) – QoS, , . - . QoS-2, PUBREC. , PUBREL. PUBREL . PUBREL PUBCOMP. PUBCOMP , .
Por el momento, hay dos versiones de la especificación del protocolo MQTT: 3.1.1 y 5.0 . Puede encontrar una descripción más detallada del protocolo aquí o una grabación de mi presentación github.com/vladipirogov/Message-Queue-Telemetry-Transport , www.youtube.com/watch?v=fYoGubQFz5c&t=5s y www.youtube.com/watch?v=8mupuCjedlc .
En el próximo artículo intentaré mostrar un ejemplo de la implementación de una plataforma Edge I-IoT personalizada usando Node-red como Edge Gateway, Apache Kafka como administrador de datos y almacenamiento temporal, Kafka Streams como Rule Engine, Mosquitto (es posible otra implementación) como un conector MQTT ... Las tecnologías InfluxData se utilizarán para almacenar datos de series temporales.
Enlace al video de la reunión.
Fuentes de información
- Plataforma de transformación digital
- Especificación de arquitectura unificada OPC
- Enciclopedia de ACS TP
- FreeOpcUa es un proyecto para implementar una pila OPC-UA de código abierto (LGPL) y herramientas asociadas.
- GR Kanagachidambaresan Internet de las Cosas para la Industria 4.0
- Max Hoffmann Agentes inteligentes para la industria 4.0
- Arquitectura unificada de Wolfgang Mahnke OPC
- Klaus Schwab Cuarta Revolución Industrial
- Perry Lee Arquitectura de Internet de las cosas
- Ismail Butun IoT industrial
- Especificaciones MQTT