Cabeza antifraude Andrey Popov Nox_andrydio una presentación sobre cómo pudimos cumplir con todos estos requisitos conflictivos. El tema central del informe es un modelo para calcular factores complejos en un flujo de datos y garantizar la tolerancia a fallas del sistema. Andrey también describió brevemente la siguiente iteración, incluso más rápida, de antifraude, que actualmente estamos desarrollando.
El equipo antifraude resuelve esencialmente el problema de clasificación binaria. Por lo tanto, el informe puede ser de interés no solo para los especialistas en lucha contra el fraude, sino también para aquellos que crean varios sistemas que necesitan factores rápidos, confiables y flexibles en grandes cantidades de datos.
- Hola, mi nombre es Andrey. Trabajo en Yandex, estoy a cargo del desarrollo del antifraude. Me dijeron que las personas prefieren usar la palabra "características", por lo que lo mencionaré a lo largo de la charla, pero el título y la introducción permanecieron igual, con la palabra "factores".
¿Qué es el antifraude?
¿Qué es antifraude de todos modos? Es un sistema que protege a los usuarios del impacto negativo en el servicio. Por influencia negativa, me refiero a acciones deliberadas que pueden degradar la calidad del servicio y, en consecuencia, empeorar la experiencia del usuario. Estos pueden ser analizadores y robots bastante simples que empeoran nuestras estadísticas o actividades fraudulentas deliberadamente complejas. El segundo, por supuesto, es más difícil y más interesante de definir.
¿Contra qué lucha el antifraude? Un par de ejemplos
Por ejemplo, imitación de acciones del usuario. Esto lo hacen los chicos que llamamos "SEO negro", aquellos que no quieren mejorar la calidad del sitio y el contenido del sitio. En cambio, escriben robots que van a la búsqueda de Yandex, hacen clic en su sitio. Esperan que su sitio se eleve más alto de esta manera. Por si acaso, le recuerdo que tales acciones contradicen el acuerdo del usuario y pueden dar lugar a sanciones graves por parte de Yandex.

O, por ejemplo, revisiones de trampas. Dicha revisión se puede ver desde la organización en Maps, que coloca ventanas de plástico. Ella misma pagó por esta revisión.
La arquitectura antifraude de nivel superior se ve así: un cierto conjunto de eventos sin procesar caen en el sistema antifraude como una caja negra. A la salida, se generan eventos etiquetados.
Yandex tiene muchos servicios. Todos ellos, especialmente los grandes, de una forma u otra se enfrentan a diferentes tipos de fraude. Búsqueda, mercado, mapas y docenas de otros.
¿Dónde estábamos hace dos o tres años? Cada equipo sobrevivió al ataque del fraude lo mejor que pudo. Ella generó sus equipos contra el fraude, sus sistemas, que no siempre funcionaban bien, no eran muy convenientes para interactuar con los analistas. Y lo más importante, estaban mal integrados entre sí.
Quiero contarles cómo resolvimos esto creando una sola plataforma.

¿Por qué necesitamos una plataforma única? Reutilización de experiencia y datos. La centralización de la experiencia y los datos en un solo lugar le permite responder más rápido y mejor a los ataques de gran envergadura; por lo general, son servicios cruzados.
Kit de herramientas unificado. Las personas tienen las herramientas a las que están acostumbradas. Y obviamente la velocidad de conexión. Si lanzamos un nuevo servicio que está actualmente bajo ataque activo, entonces debemos conectarlo rápidamente con un antifraude de alta calidad.
Podemos decir que no somos únicos en este sentido. Todas las grandes empresas enfrentan problemas similares. Y todos con quienes nos comunicamos llegan a la creación de su plataforma única.
Te contaré un poco sobre cómo clasificamos los antifraude.
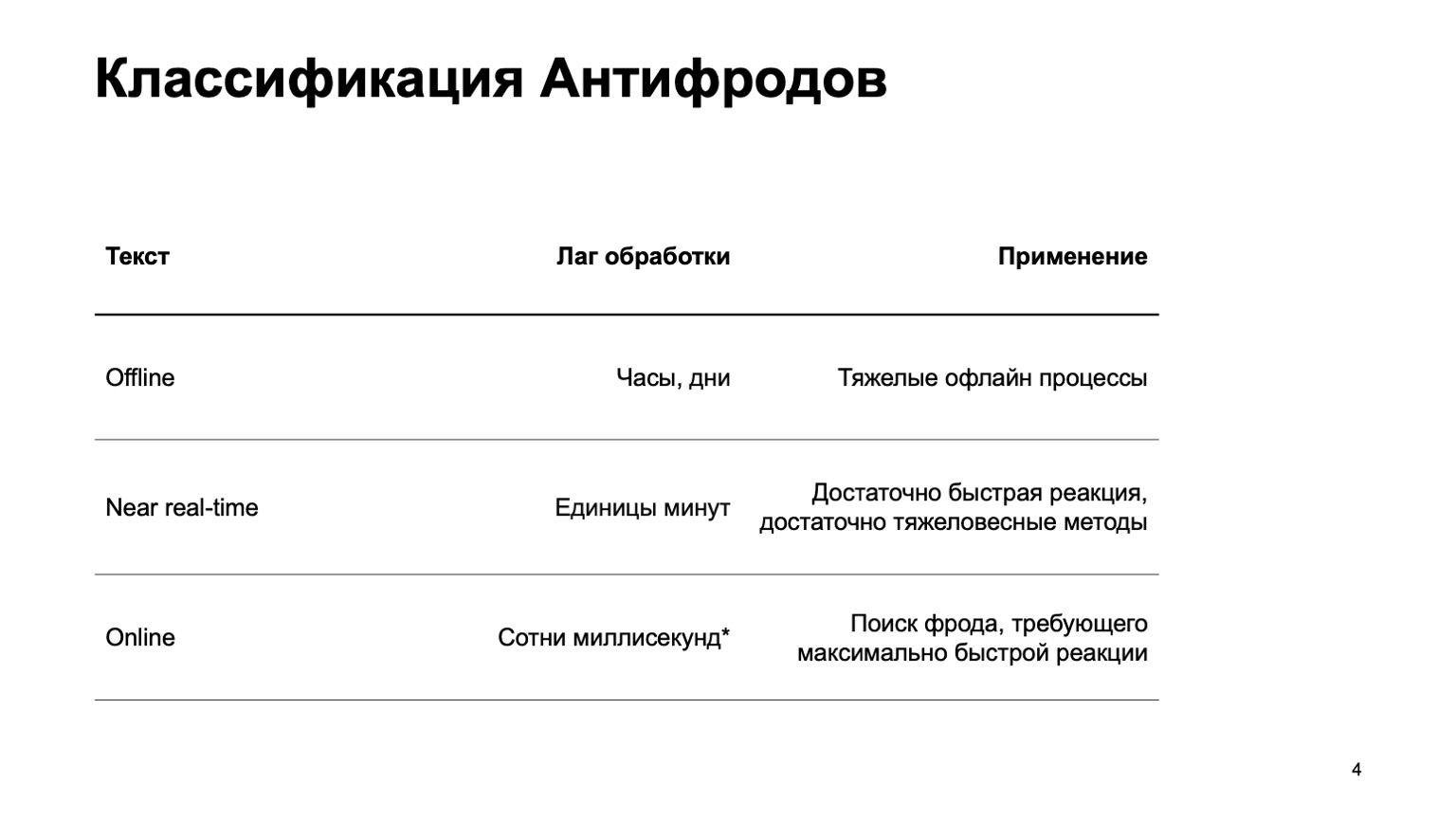
Este puede ser un sistema fuera de línea que cuenta horas, días y procesos fuera de línea pesados: por ejemplo, agrupamiento complejo o reentrenamiento complejo. Prácticamente no tocaré esta parte en el informe. Hay una parte casi en tiempo real que funciona en pocos minutos. Este es un tipo de medio dorado, ella tiene reacciones rápidas y métodos pesados. Primero que nada, me enfocaré en ella. Pero es igualmente importante decir que en esta etapa estamos utilizando datos de la etapa anterior.
También hay piezas en línea que se necesitan en lugares donde se requiere una respuesta rápida y es fundamental eliminar el fraude incluso antes de que hayamos recibido el evento y se lo hayamos pasado al usuario. Aquí reutilizamos datos y algoritmos de aprendizaje automático calculados en niveles superiores nuevamente.
Hablaré sobre cómo está organizada esta plataforma unificada, sobre el lenguaje para describir características e interactuar con el sistema, sobre nuestro camino hacia el aumento de la velocidad, es decir, sobre la transición de la segunda etapa a la tercera.
Difícilmente tocaré los métodos de ML en sí. Básicamente, hablaré sobre plataformas que crean características, que luego usamos en el entrenamiento.
¿Quién podría estar interesado en esto? Obviamente, para aquellos que escriben contra el fraude o luchan contra los estafadores. Pero ML también considera que para aquellos que solo inician el flujo de datos y leen las características. Como hemos creado un sistema bastante general, tal vez le interese algo de esto.
¿Cuáles son los requerimientos del sistema? Hay bastantes, estos son algunos de ellos:
- Gran flujo de datos. Procesamos cientos de millones de eventos en cinco minutos.
- Características totalmente configurables.
- .
- , - exactly-once- , . — , , , , .
- , , .
Además, le contaré sobre cada uno de estos puntos por separado.
Dado que por razones de seguridad no puedo hablar de servicios reales, presentemos un nuevo servicio Yandex. En realidad no, olvídate, este es un servicio ficticio que se me ocurrió para mostrar ejemplos. Que sea un servicio en el que las personas tengan una base de datos de todos los libros existentes. Entran, dan calificaciones de uno a diez, y los atacantes quieren influir en la calificación final para que se compren sus libros.
Todas las coincidencias con los servicios reales son, por supuesto, aleatorias. Consideremos en primer lugar la versión casi en tiempo real, ya que en línea no se necesita específicamente aquí en la primera aproximación.
Big data
Yandex tiene una forma clásica de resolver problemas de big data: use MapReduce. Utilizamos nuestra propia implementación de MapReduce llamada YT . Por cierto, Maxim Akhmedov tiene una historia sobre ella esta noche . Puede usar su implementación o una implementación de código abierto como Hadoop.
¿Por qué no usamos la versión en línea de inmediato? No siempre es necesario, puede complicar los nuevos cálculos en el pasado. Si hemos agregado un nuevo algoritmo, nuevas características, a menudo queremos volver a calcular los datos en el pasado para cambiar los veredictos. Es más difícil usar métodos pesados, creo que está claro por qué. Y la versión en línea, por varias razones, puede ser más exigente en términos de recursos.
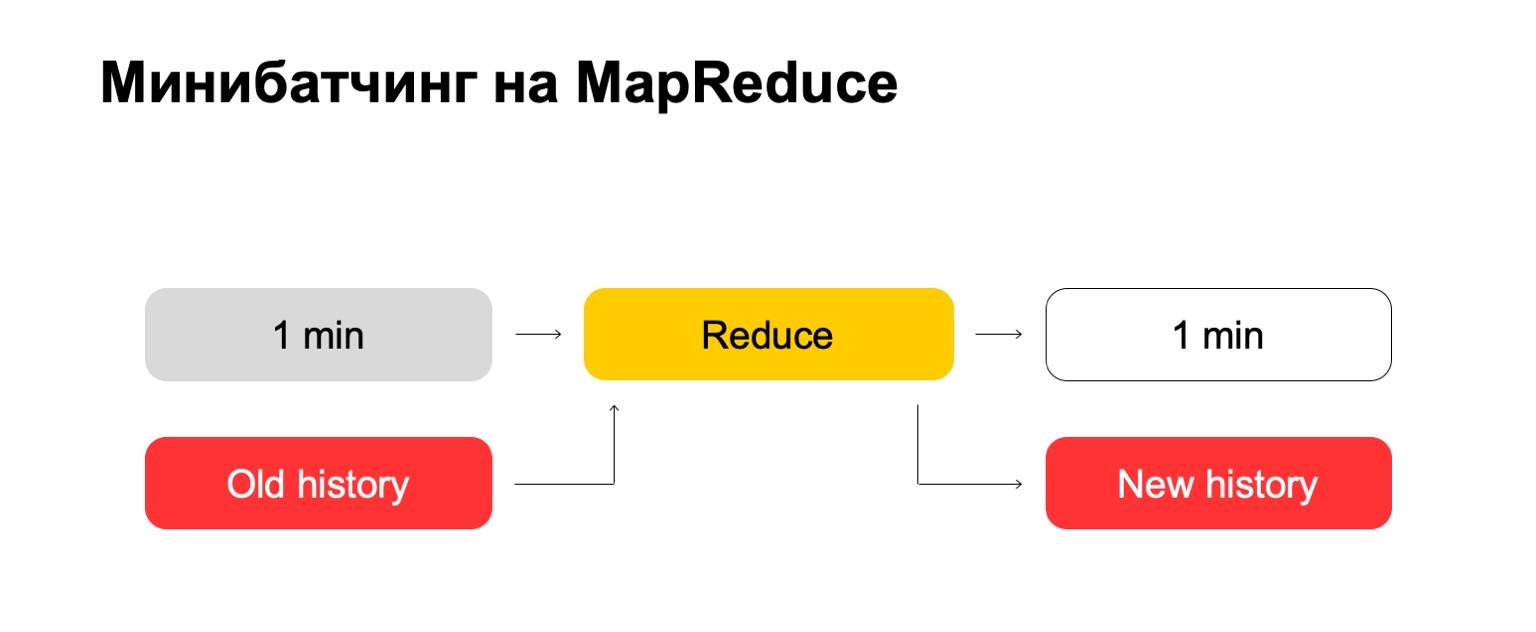
Si usamos MapReduce, obtenemos algo como esto. Usamos una especie de mini-lote, es decir, dividimos el lote en las piezas más pequeñas posibles. En este caso, es un minuto. Pero aquellos que trabajan con MapReduce saben que, probablemente, a menos de este tamaño, ya existen gastos generales demasiado grandes del sistema en sí mismos: gastos generales. Convencionalmente, no podrá hacer frente al procesamiento en un minuto.
A continuación, ejecutamos el conjunto Reducir en este conjunto de lotes y obtenemos un lote marcado.

En nuestras tareas, a menudo es necesario calcular el valor exacto de las características. Por ejemplo, si queremos calcular el número exacto de libros que un usuario ha leído en el último mes, calcularemos este valor para cada lote y debemos almacenar todas las estadísticas recopiladas en un solo lugar. Y luego elimine los valores antiguos y agregue los nuevos.
¿Por qué no usar métodos de conteo aproximado? Respuesta corta: también los usamos, pero a veces en problemas contra el fraude es importante tener exactamente el valor exacto para algunos intervalos. Por ejemplo, la diferencia entre dos y tres libros leídos puede ser bastante significativa para ciertos métodos.
Como consecuencia, necesitamos un gran historial de datos en el que almacenaremos estas estadísticas.
Probemos "de frente". Tenemos un minuto y una gran historia antigua. Lo ponemos en la entrada y salida Reducir un historial actualizado y un registro marcado, datos.
Para aquellos de ustedes que han trabajado con MapReduce, probablemente sepan que esto puede funcionar bastante mal. Si el historial puede ser cientos, o incluso miles, decenas de miles de veces más grande que el lote en sí, entonces dicho procesamiento puede funcionar en proporción al tamaño del historial y no al tamaño del lote.
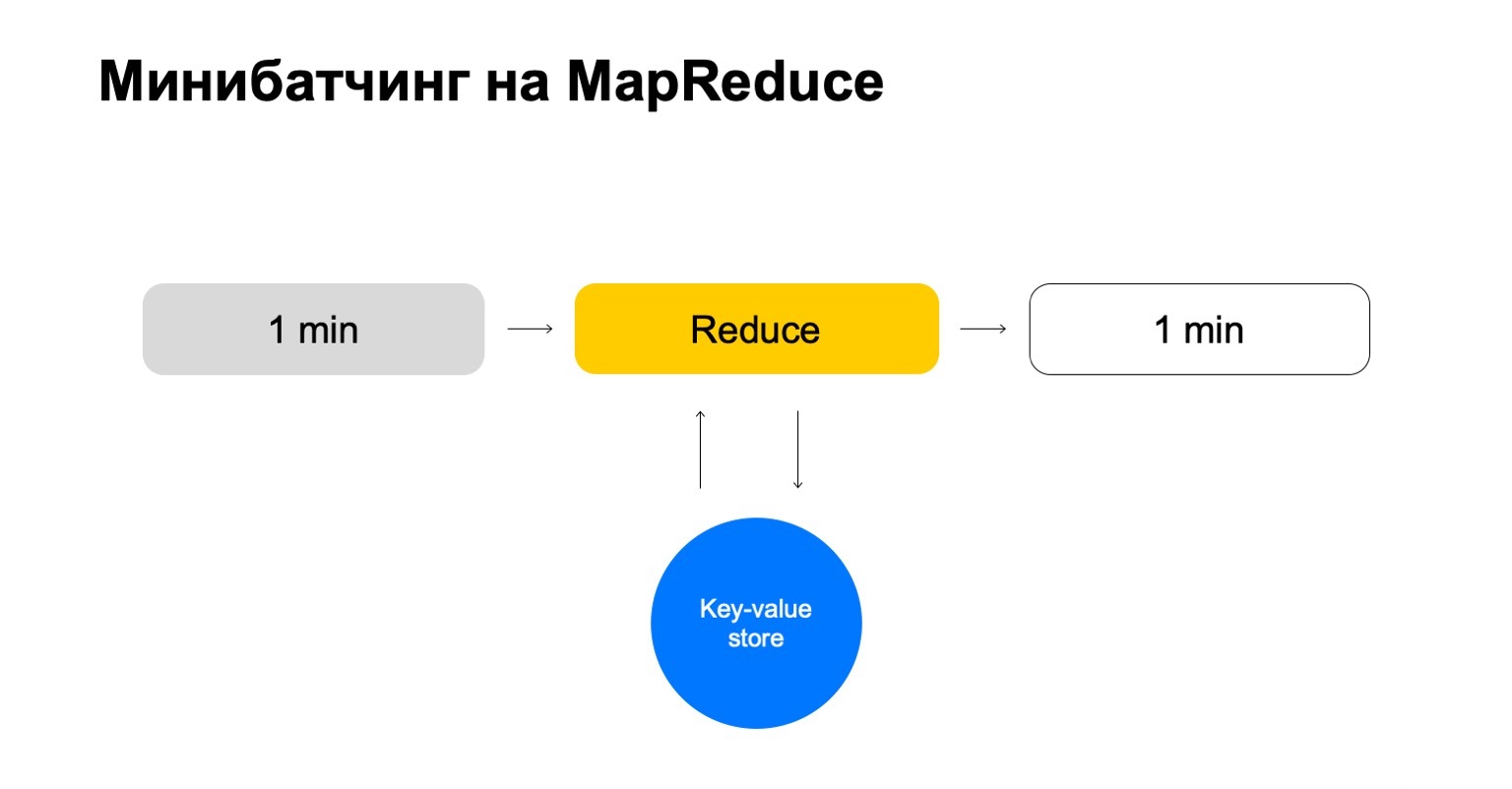
Reemplacemos esto con alguna tienda de valores clave. Esta es nuevamente nuestra propia implementación, almacenamiento de valores clave, pero almacena datos en la memoria. Probablemente el análogo más cercano es algún tipo de Redis. Pero tenemos una pequeña ventaja aquí: nuestra implementación del almacén de valores clave está muy estrechamente integrada con MapReduce y el clúster MapReduce en el que se ejecuta. Resulta una transaccionalidad conveniente, conveniente transferencia de datos entre ellos.
Pero el esquema general es que en cada trabajo de esta Reducción iremos a este almacenamiento de valores clave, actualizaremos los datos y los volveremos a escribir después de emitir un veredicto sobre ellos.
Terminamos con una historia que solo maneja las teclas que necesitamos y escala fácilmente.
Características configurables
Un poco sobre cómo configuramos las funciones. Los contadores simples a menudo no son suficientes. Para buscar estafadores, necesita una variedad de características, necesita un sistema inteligente y conveniente para configurarlos.
Vamos a dividirlo en tres pasos:
- Extracto, donde extraemos datos para la clave dada y del registro.
- Fusionar, donde fusionamos estos datos con las estadísticas que están en el historial.
- Construir, donde formamos el valor final de la característica.
Por ejemplo, calculemos el porcentaje de historias de detectives leídas por un usuario.
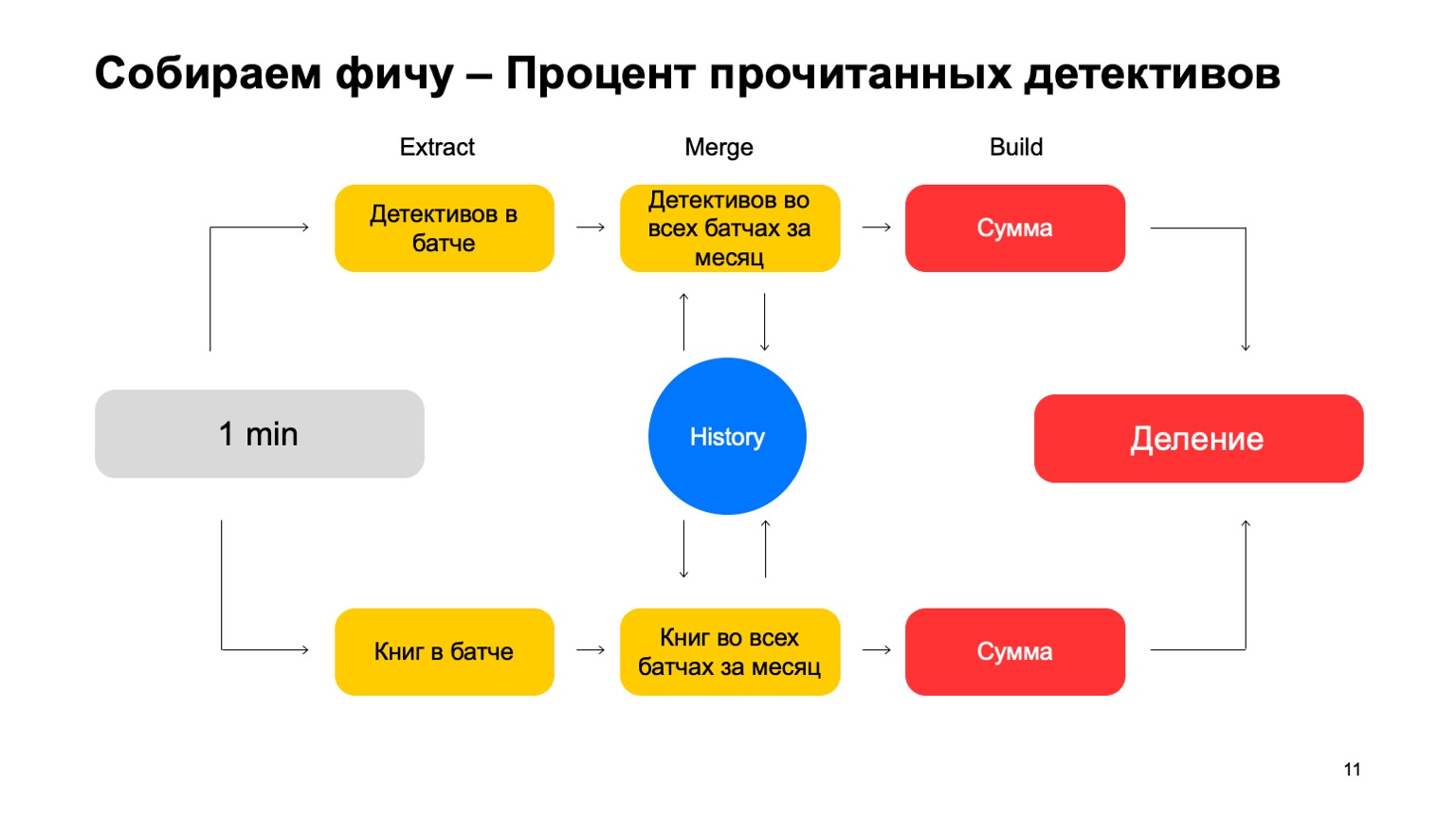
Si el usuario lee demasiadas historias de detectives, sospecha demasiado. Nunca está claro qué esperar de él. Luego, Extraer es la eliminación de la cantidad de detectives que el usuario leyó en este lote. Fusionar: tomar todos los detectives, todos estos datos de lotes por un mes. Y Build es una cantidad.
Luego hacemos lo mismo por el valor de todos los libros que leyó, y terminamos con la división.
¿Qué sucede si queremos contar valores diferentes, por ejemplo, el número de autores diferentes que lee un usuario?
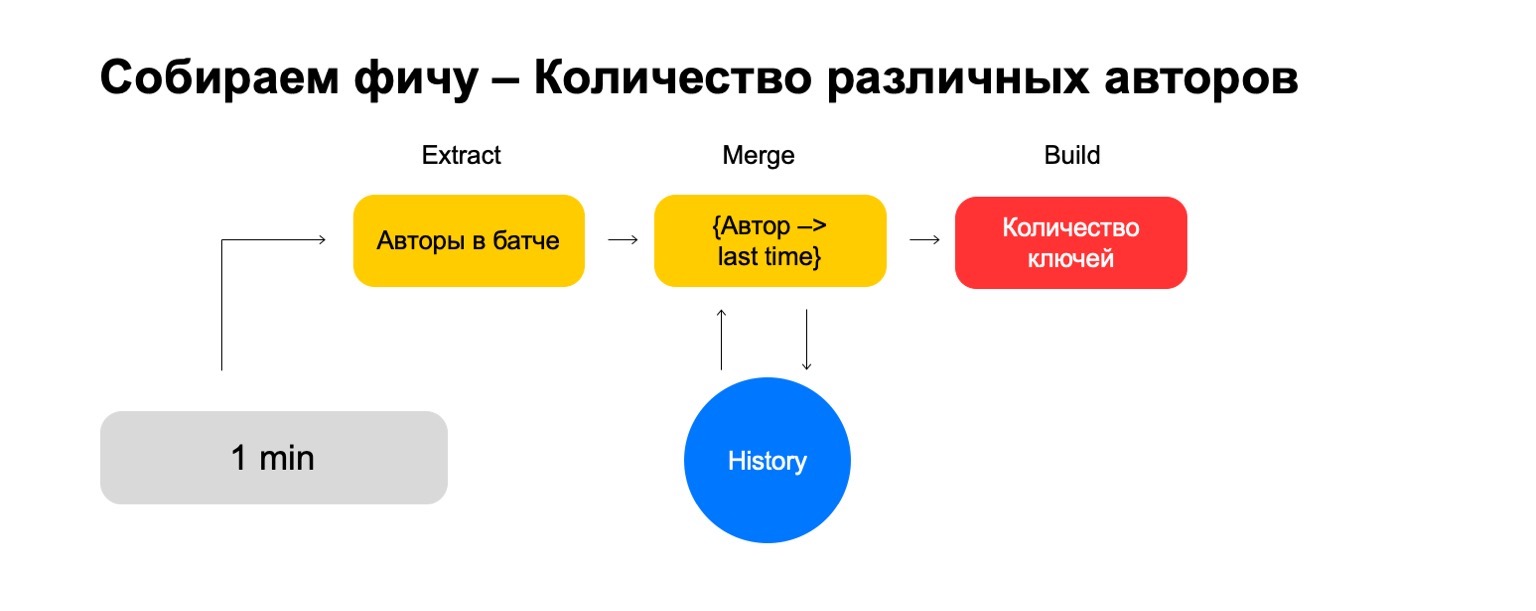
Luego podemos tomar el número de autores diferentes que el usuario ha leído en este lote. Además, almacene alguna estructura donde hagamos una asociación de autores recientemente, cuando el usuario los lea. Por lo tanto, si nos encontramos nuevamente con este autor en el usuario, esta vez lo actualizamos. Si necesitamos eliminar eventos antiguos, sabemos qué eliminar. Para calcular la función final, simplemente contamos el número de claves que contiene.

Pero en una señal ruidosa, tales características no son suficientes para un corte, necesitamos un sistema para pegar sus uniones, pegando estas características desde diferentes cortes.
Vamos, por ejemplo, a introducir tales recortes: usuario, autor y género.

Calculemos algo difícil. Por ejemplo, lealtad promedio del autor. Por lealtad, quiero decir que los usuarios que leen al autor casi solo lo leen. Además, este valor promedio es bastante bajo para el número promedio de autores leídos por los usuarios que lo leen.
Esto podría ser una señal potencial. Él, por supuesto, puede significar que el autor es así: solo hay admiradores a su alrededor, todos los que lo leen leen solo a él. Pero también puede significar que el propio autor está tratando de engañar al sistema y crear estos usuarios falsos que supuestamente lo leen.
Intentemos calcularlo. Vamos a contar una característica que cuenta el número de autores diferentes durante un intervalo largo. Por ejemplo, aquí el segundo y el tercer valor nos parecen sospechosos, hay muy pocos de ellos.
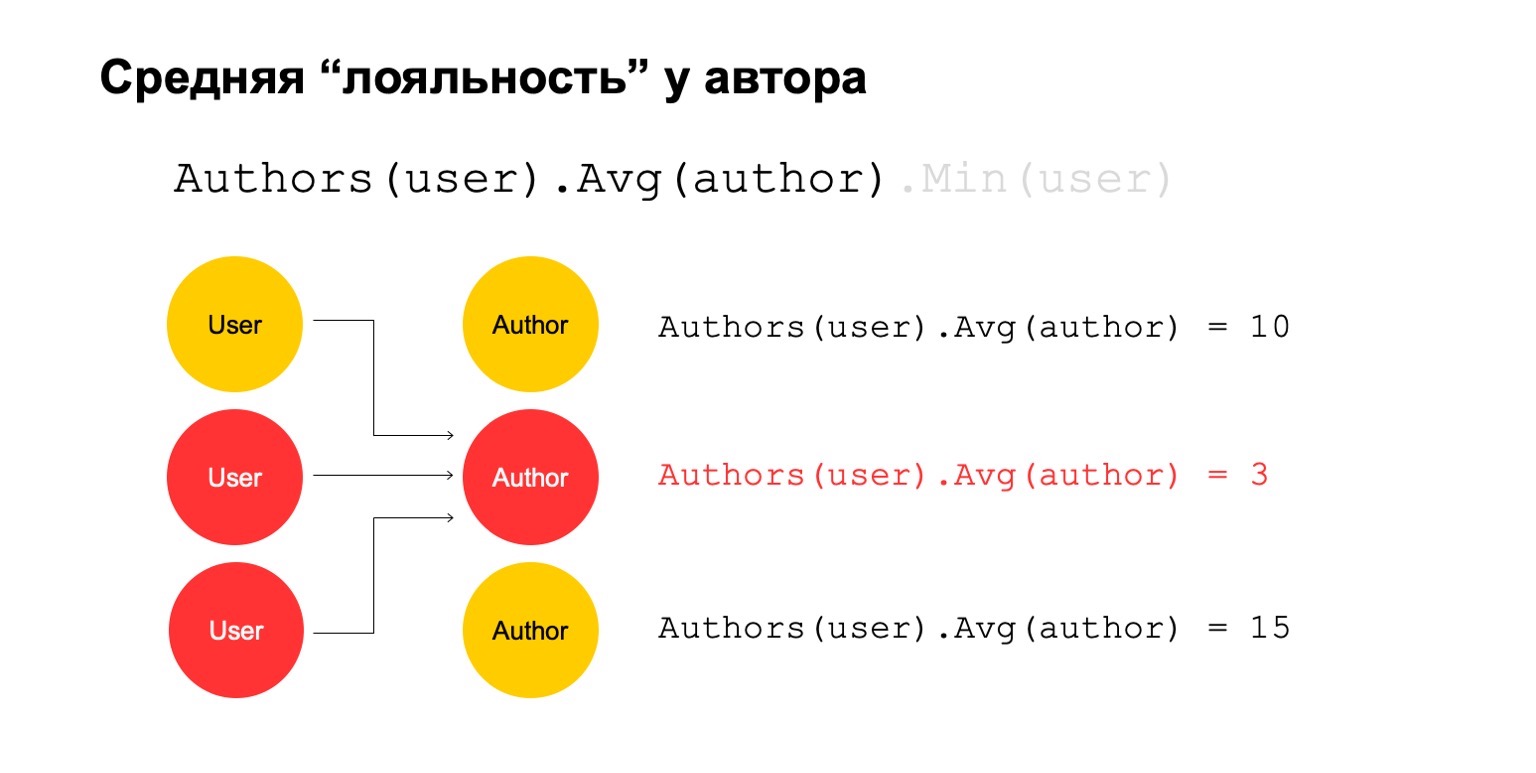
Luego, calculemos el valor promedio de los autores que están relacionados durante un intervalo grande. Y luego aquí el valor promedio es nuevamente bastante bajo: 3. Por alguna razón, este autor nos parece sospechoso.
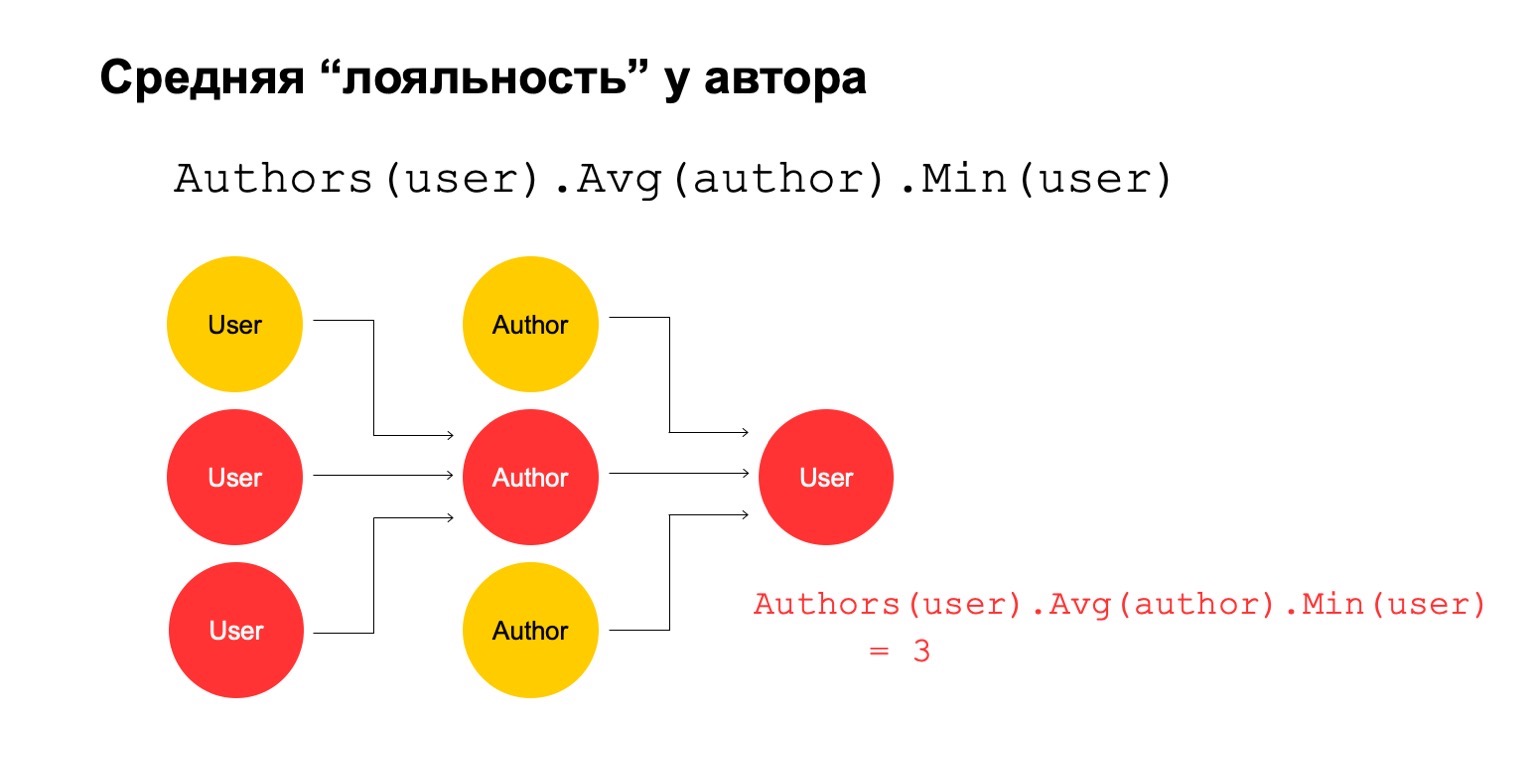
Y podemos devolverlo al usuario para comprender que este usuario en particular tiene una conexión con el autor, lo que nos parece sospechoso.
Está claro que esto en sí mismo no puede ser un criterio explícito de que el usuario deba ser filtrado o algo así. Pero esta podría ser una de las señales que podemos usar.
¿Cómo hacer esto en el paradigma de MapReduce? Hagamos varias reducciones consecutivas y las dependencias entre ellas.

Obtenemos un gráfico de reducciones. Influye en las secciones con las que contamos las características, qué combinaciones generalmente se permiten, en la cantidad de recursos consumidos: obviamente, cuantas más reducciones, más recursos. Y latencia, rendimiento.
Construyamos, por ejemplo, un gráfico de este tipo.
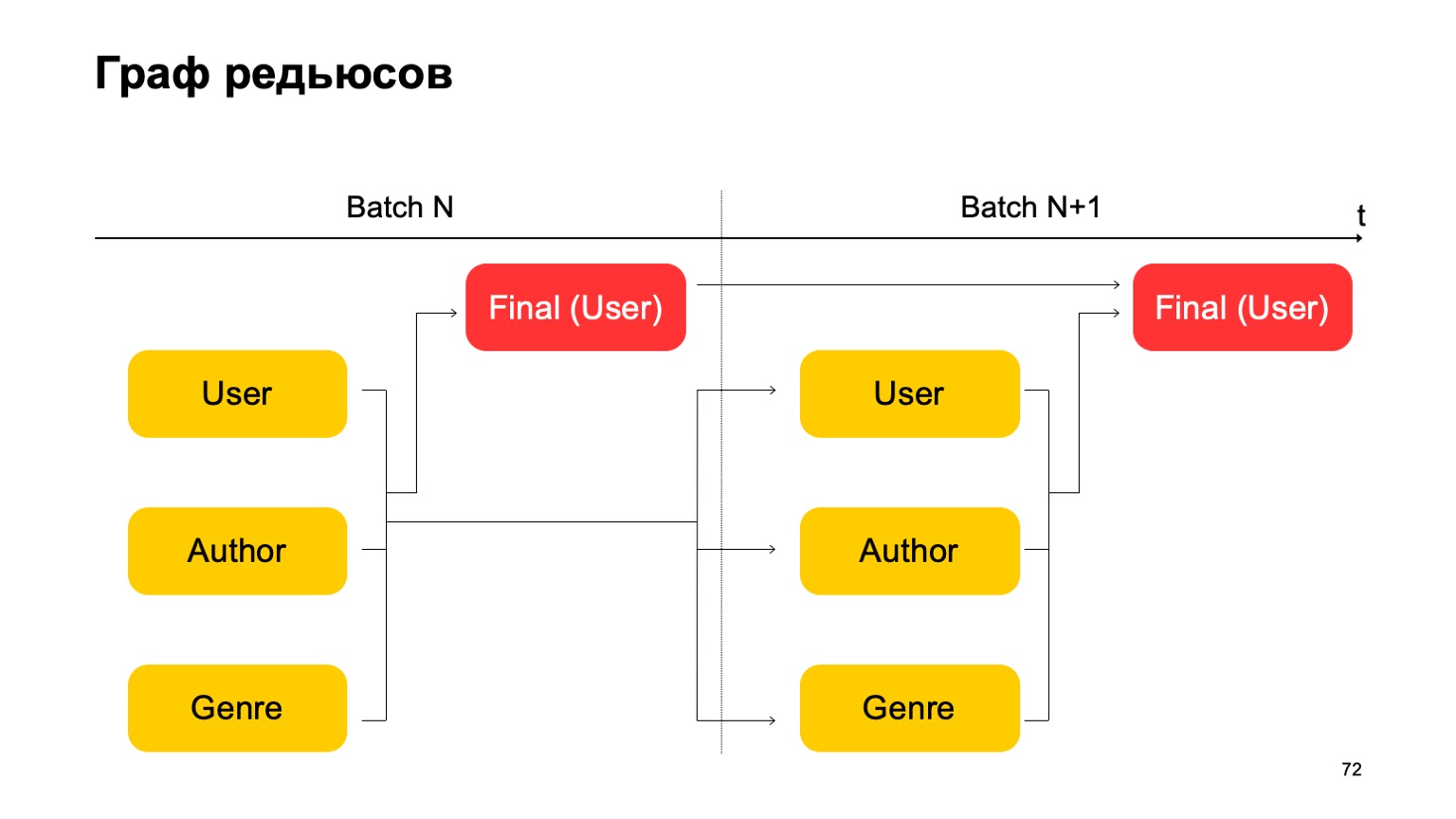
Es decir, dividiremos las reducciones que tenemos en dos etapas. En la primera etapa, calcularemos diferentes reducciones en paralelo para diferentes secciones: nuestros usuarios, autores y género. Y necesitamos algún tipo de segunda etapa, donde recopilaremos características de estas diferentes reducciones y aceptaremos el veredicto final.
Para el próximo lote, hacemos lo mismo. Además, tenemos una dependencia de la primera etapa de cada lote en la primera etapa del pasado y la segunda etapa en la segunda etapa del pasado.
Es importante aquí que no tengamos tal dependencia:
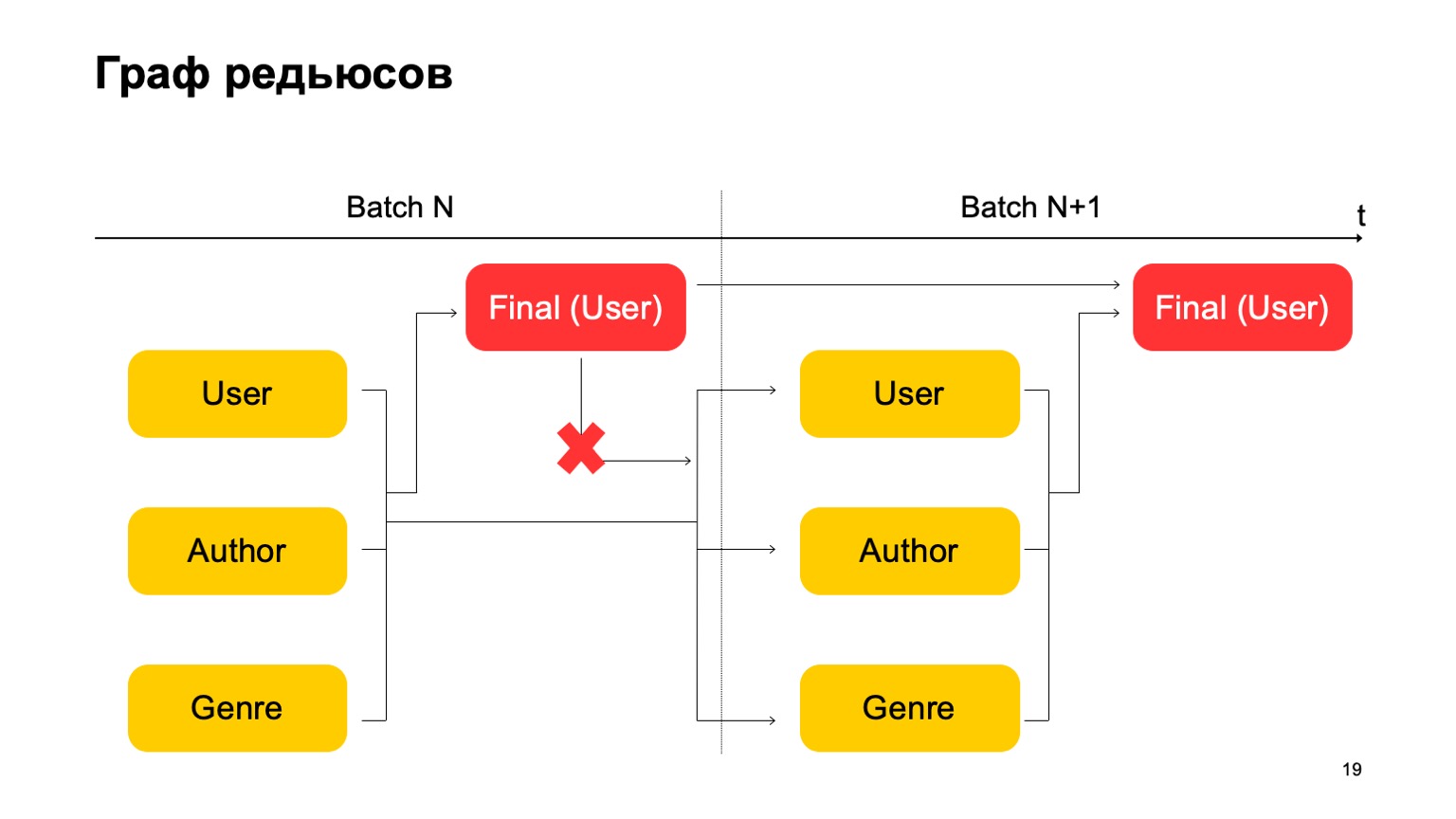
Es decir, en realidad tenemos un transportador. Es decir, la primera etapa del siguiente lote puede funcionar en paralelo con la segunda etapa del primer lote.
¿Cómo podemos hacer las estadísticas de tres etapas en esto, que di anteriormente, si solo tenemos dos etapas? Muy simple. Podemos leer el primer valor en la primera etapa del lote N.
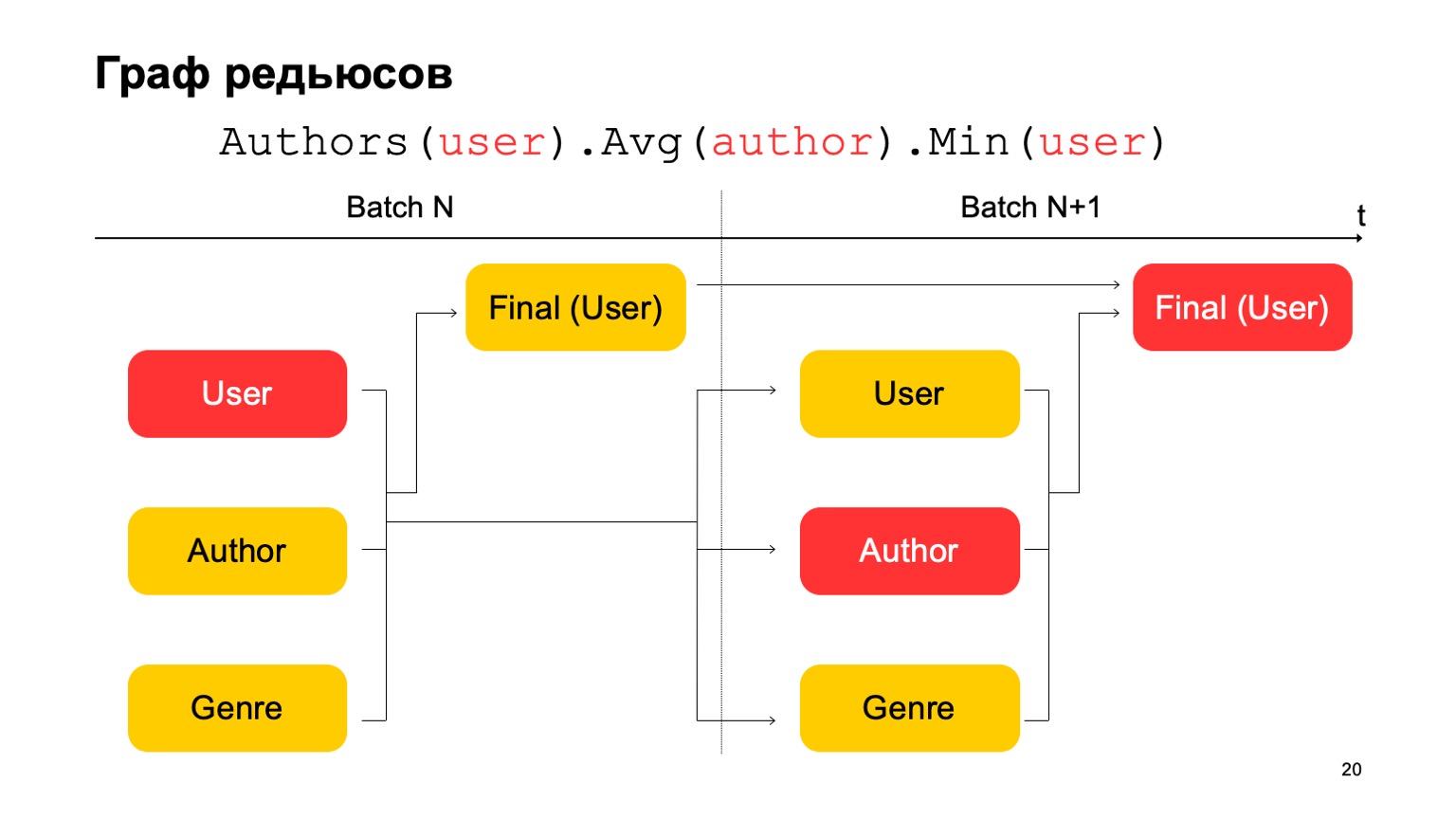
El segundo valor en la primera etapa del lote es N + 1, y el valor final debe leerse en la segunda etapa del lote N + 1. Por lo tanto, durante la transición entre la primera etapa y la segunda, habrá, quizás, estadísticas no bastante precisas para el lote N + 1. Pero generalmente esto es suficiente para tales cálculos.

Teniendo todas estas cosas, puede construir características más complejas a partir de cubos. Por ejemplo, la desviación de la calificación actual del libro de la calificación promedio del usuario. O la proporción de usuarios que califican un libro de manera muy positiva o muy negativa. También sospechoso O la calificación promedio de libros de los usuarios que tienen más de N calificaciones para diferentes libros. Esta es quizás una evaluación más precisa y justa desde algún punto de vista.

A esto se agrega lo que llamamos la relación entre eventos. A menudo aparecen duplicados en los registros o en los datos que nos envían. Estos pueden ser eventos técnicos o comportamiento robótico. También encontramos tales duplicados. O, por ejemplo, algunos eventos relacionados. Supongamos que su sistema muestra recomendaciones de libros y los usuarios hacen clic en estas recomendaciones. Para que las estadísticas finales que afectan la clasificación no se echen a perder, debemos asegurarnos de que si filtramos la impresión, también debemos filtrar el clic en la recomendación actual.
Pero dado que nuestro flujo puede llegar de manera desigual, primero un clic, debemos posponerlo hasta que veamos el programa y aceptemos un veredicto basado en él.
Lenguaje de descripción de funciones
Te contaré un poco sobre el lenguaje utilizado para describir todo esto.

No tienes que leerlo, esto es por ejemplo. Comenzamos con tres componentes principales. La primera es una descripción de unidades de datos en la historia, en general, de tipo arbitrario.

Esta es una especie de característica, un número anulable.

Y algún tipo de regla. ¿Qué llamamos una regla? Este es un conjunto de condiciones para estas características y algo más. Teníamos tres archivos separados.
El problema es que aquí una cadena de acciones se extiende sobre diferentes archivos. Una gran cantidad de analistas necesitan trabajar con nuestro sistema. Estaban incómodos.
El lenguaje resulta imperativo: describimos cómo calcular los datos, y no declarativos, cuando describiríamos lo que necesitamos calcular. Esto tampoco es muy conveniente, es bastante fácil cometer un error y un umbral de entrada alto. Vienen nuevas personas, pero no entienden cómo trabajar con ellas.
Solución: hagamos nuestro propio DSL. Describe nuestro escenario más claramente, es más fácil para las personas nuevas, es más de alto nivel. Nos inspiramos en SQLAlchemy, C # Linq y similares.
Daré un par de ejemplos similares a los que mencioné anteriormente.

Porcentaje de historias de detectives leídas. Contamos la cantidad de libros leídos, es decir, los agrupamos por usuario. Agregamos filtros a esta condición, y si queremos calcular el porcentaje final, simplemente calculamos la calificación. Todo es simple, claro e intuitivo.

Si contamos el número de autores diferentes, los agrupamos por usuario y establecemos autores distintos. A esto podemos agregar algunas condiciones, por ejemplo, una ventana de cálculo o un límite en el número de valores que almacenamos debido a restricciones de memoria. Como resultado, contamos el recuento, el número de claves que contiene.

O la lealtad promedio de la que estaba hablando. Es decir, nuevamente, tenemos algún tipo de expresión calculada desde arriba. Agrupamos por autor y establecemos un valor promedio entre estas expresiones. Luego lo reducimos nuevamente al usuario.

A esto podemos agregar una condición de filtro. Es decir, nuestro filtro puede ser, por ejemplo, el siguiente: la lealtad no es demasiado alta y el porcentaje de detectives está entre 80 de cada 100.
¿Qué utilizamos para esto bajo el capó?
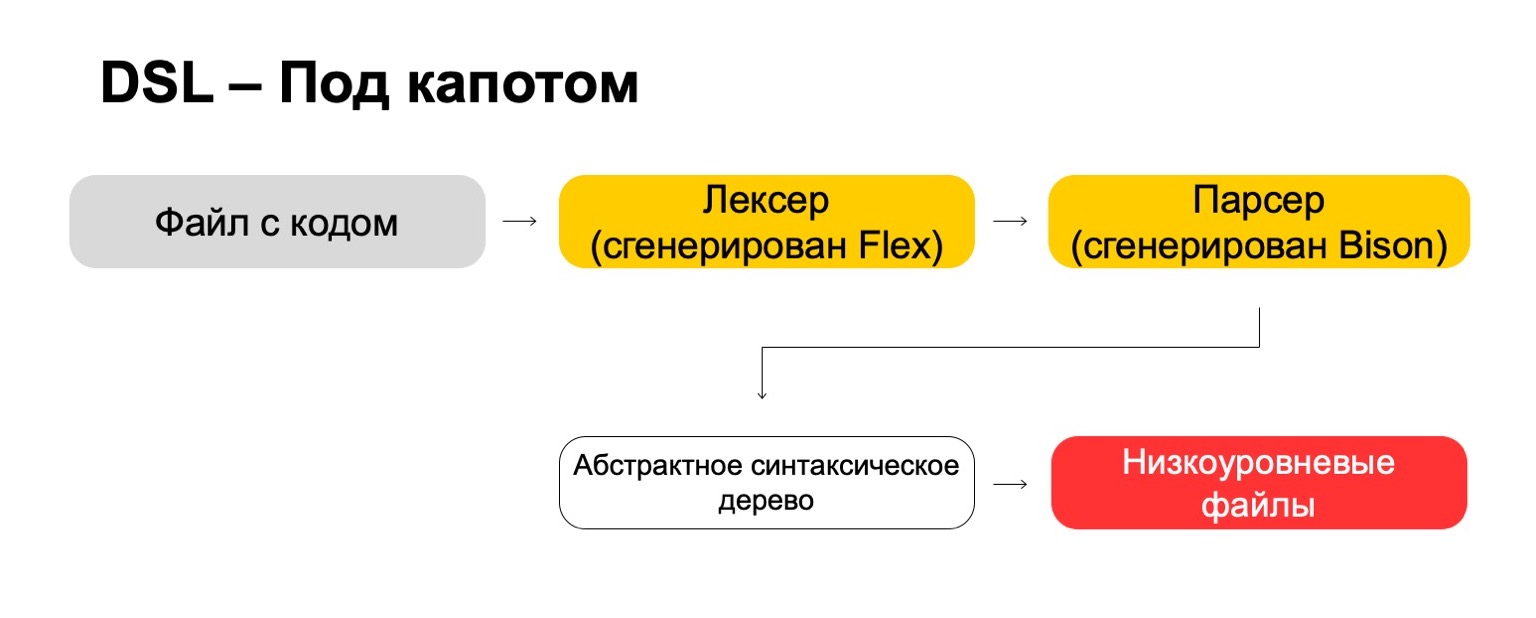
Bajo el capó, utilizamos las tecnologías más modernas directamente de los años 70, como Flex, Bison. Tal vez lo escuchaste. Generan código. Nuestro archivo de código pasa por nuestro lexer, que se genera en Flex, y por el analizador, que se genera en Bison. El lexer genera símbolos terminales o palabras en el lenguaje, el analizador genera expresiones de sintaxis.
De esto obtenemos un árbol de sintaxis abstracta, con el que ya podemos hacer transformaciones. Y al final, lo convertimos en archivos de bajo nivel que el sistema comprende.
Cual es el resultado? Esto es más complicado de lo que parece a primera vista. Se necesitan muchos recursos para pensar en las pequeñas cosas como las prioridades para las operaciones, los casos límite y cosas por el estilo. Necesita aprender tecnologías raras que es poco probable que le sean útiles en la vida real, a menos que escriba compiladores, por supuesto. Pero al final vale la pena. Es decir, si usted, como nosotros, tiene una gran cantidad de analistas que a menudo provienen de otros equipos, al final esto les da una ventaja significativa, porque les resulta más fácil trabajar.
Fiabilidad
Algunos servicios requieren tolerancia a fallas: procesamiento cruzado de CC y exactamente una vez. Una violación puede causar discrepancias en las estadísticas y las pérdidas, incluidas las pérdidas monetarias. Nuestra solución para MapReduce es tal que leemos los datos a la vez en un solo clúster y los sincronizamos en el segundo.
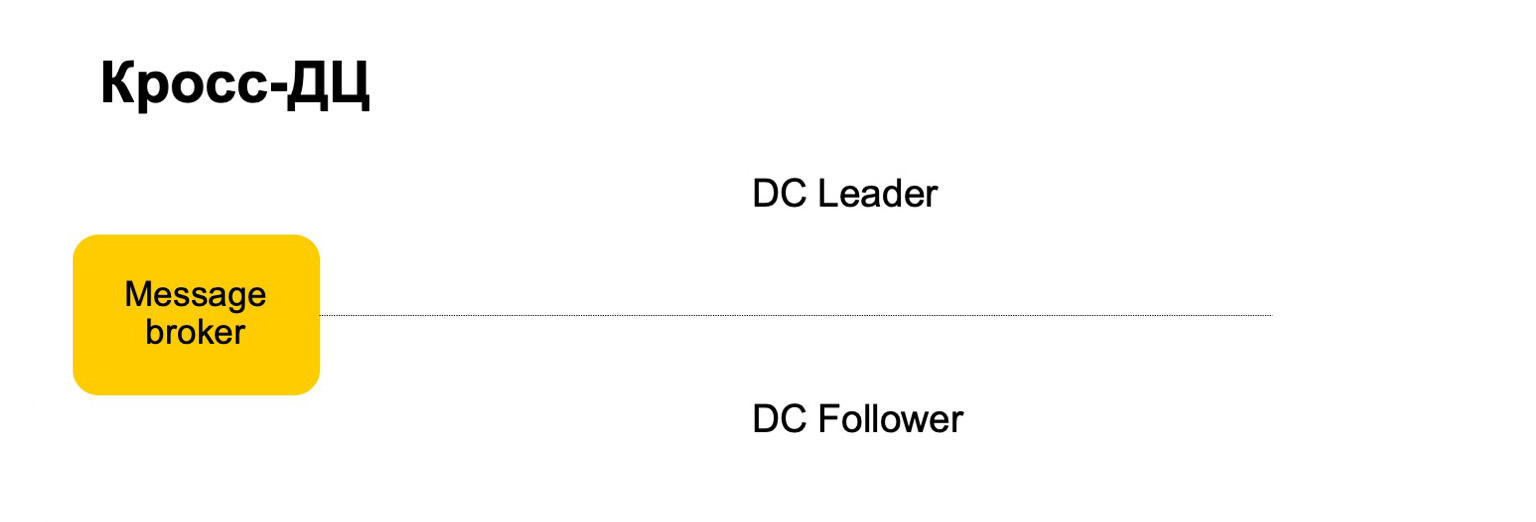
Por ejemplo, ¿cómo nos comportaríamos aquí? Hay un líder, seguidor y agente de mensajes. Se puede considerar que este es un kafka condicional, aunque aquí, por supuesto, su propia implementación.
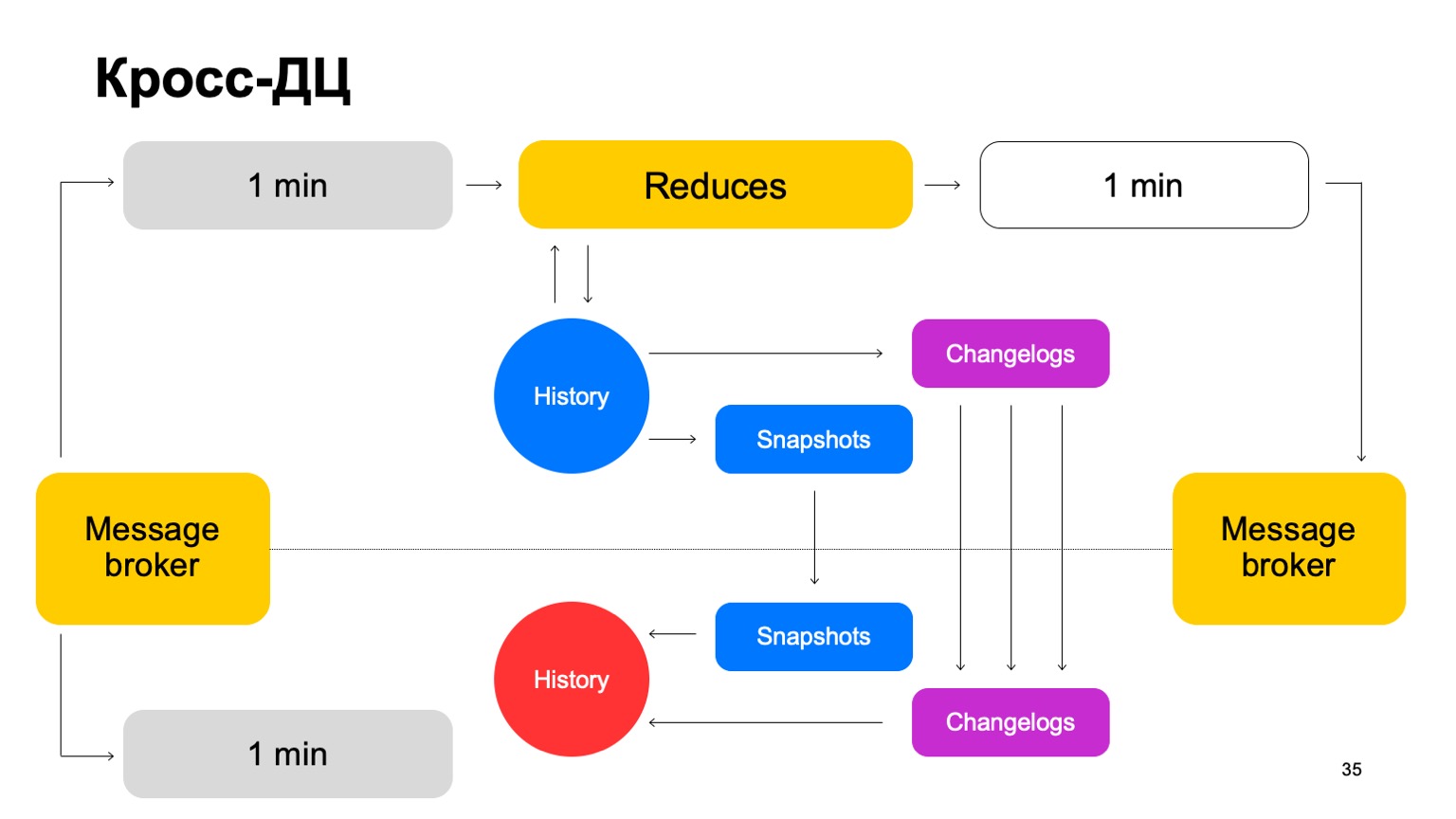
Entregamos nuestros lotes a ambos grupos, lanzamos un conjunto de reducciones sobre el mismo líder, aceptamos los veredictos finales, actualizamos el historial y enviamos los resultados al servicio al agente de mensajes.
De vez en cuando, naturalmente tenemos que hacer la replicación. Es decir, recopilamos instantáneas, recopilamos cambios, cambios para cada lote. Sincronizamos ambos con el segundo seguidor de clúster. Y también trayendo una historia que es tan candente. Déjame recordarte que la historia se guarda en la memoria aquí.
Por lo tanto, si un DC no está disponible por alguna razón, podemos pasar lo suficientemente rápido, con un retraso mínimo, al segundo cluster.
¿Por qué no contar con dos grupos en paralelo? Los datos externos pueden diferir en dos grupos, pueden ser suministrados por servicios externos. ¿Qué son los datos externos de todos modos? Esto es algo que surge de este nivel superior. Es decir, agrupamiento complejo y similares. O simplemente datos auxiliares para los cálculos.
Necesitamos una solución acordada. Si contamos los veredictos en paralelo usando datos diferentes y cambiamos periódicamente entre los resultados de dos grupos diferentes, la consistencia entre ellos disminuirá drásticamente. Y, por supuesto, ahorrando recursos. Como utilizamos los recursos de la CPU en un solo clúster a la vez.
¿Qué pasa con el segundo grupo? Cuando trabajamos, él está prácticamente inactivo. Usemos sus recursos para una preproducción completa. Por preproducción completa, me refiero a una instalación completa que acepta el mismo flujo de datos, funciona con los mismos volúmenes de datos, etc.

Si el clúster no está disponible, cambiamos estas instalaciones de la venta a la preproducción. Por lo tanto, tenemos un preprod por algún tiempo, pero está bien.
La ventaja es que podemos contar con más funciones en el preproceso. ¿Por qué es esto necesario? Debido a que está claro que si queremos contar una gran cantidad de funciones, a menudo no necesitamos contarlas todas a la venta. Allí, solo contamos lo que se necesita para obtener veredictos finales.
(00:25:12)
Pero al mismo tiempo, tenemos una especie de caché en caliente en el preproceso, grande, con una amplia variedad de características. En caso de un ataque, podemos usarlo para cerrar el problema y transferir estas características a producción.
A esto se suman los beneficios de las pruebas B2B. Es decir, todos implementamos, por supuesto, primero para la preventa. Comparamos completamente cualquier diferencia y, por lo tanto, no nos equivocaremos, minimizamos la probabilidad de que podamos cometer un error al ponerlo a la venta.
Un poco sobre el planificador. Está claro que tenemos algún tipo de máquinas que ejecutan la tarea en MapReduce. Estos son algún tipo de trabajadores. Regularmente sincronizan sus datos con la base de datos Cross-DC. Este es solo el estado de lo que han logrado calcular en este momento.
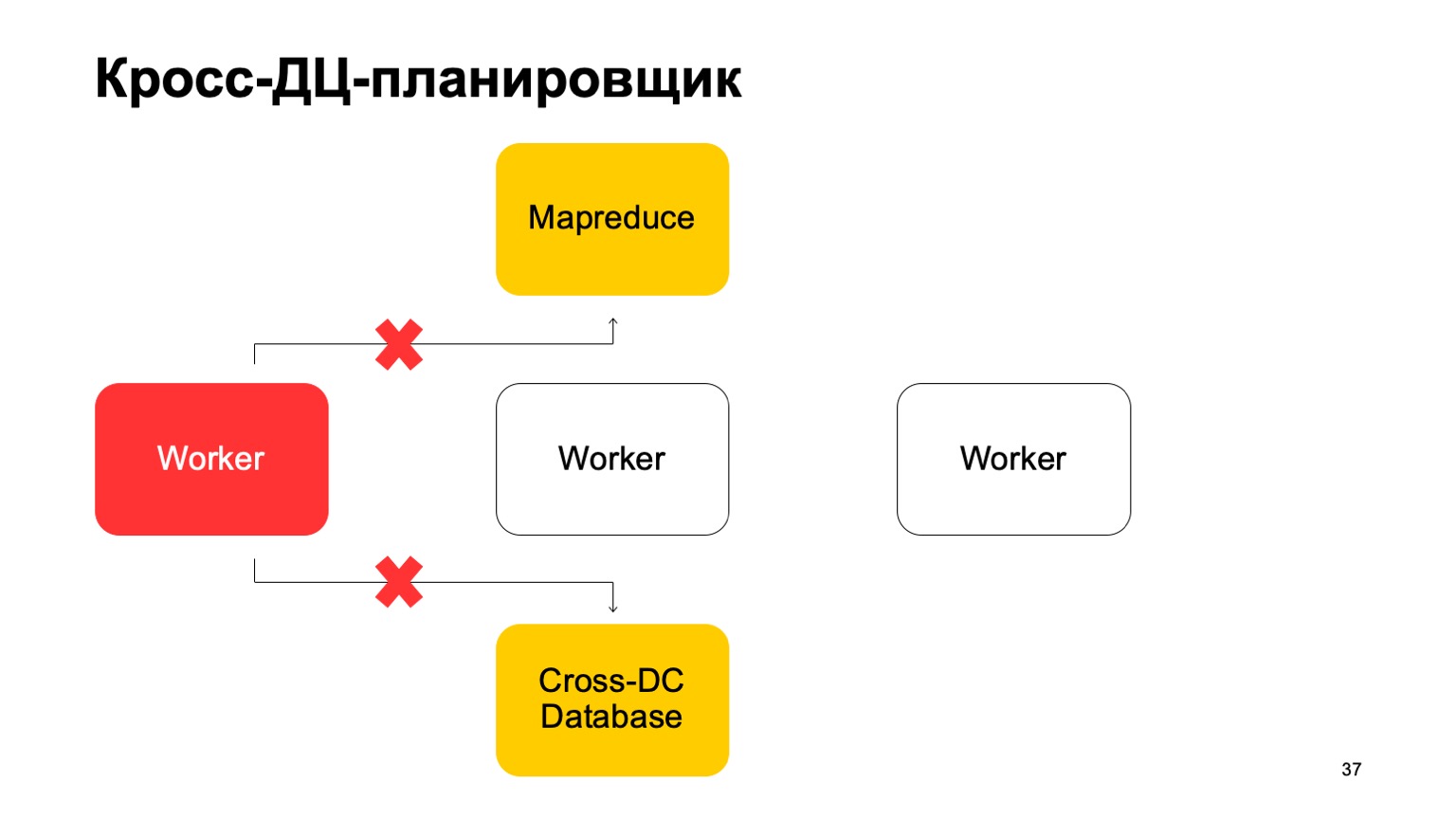
Si un trabajador deja de estar disponible, otro trabajador intenta capturar el registro y tomar el estado.
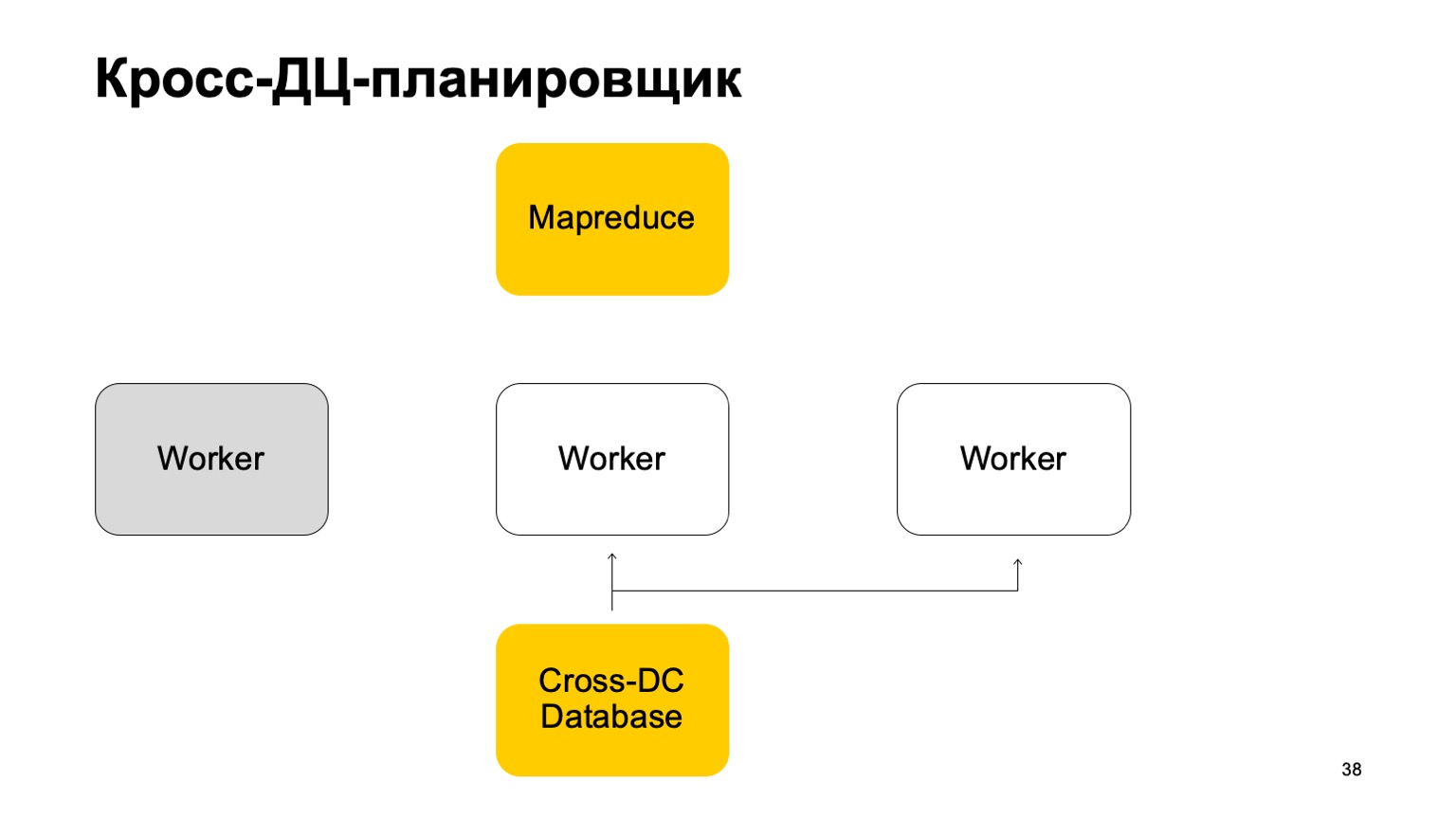
Levántate y sigue trabajando. Continúe configurando tareas en este MapReduce.
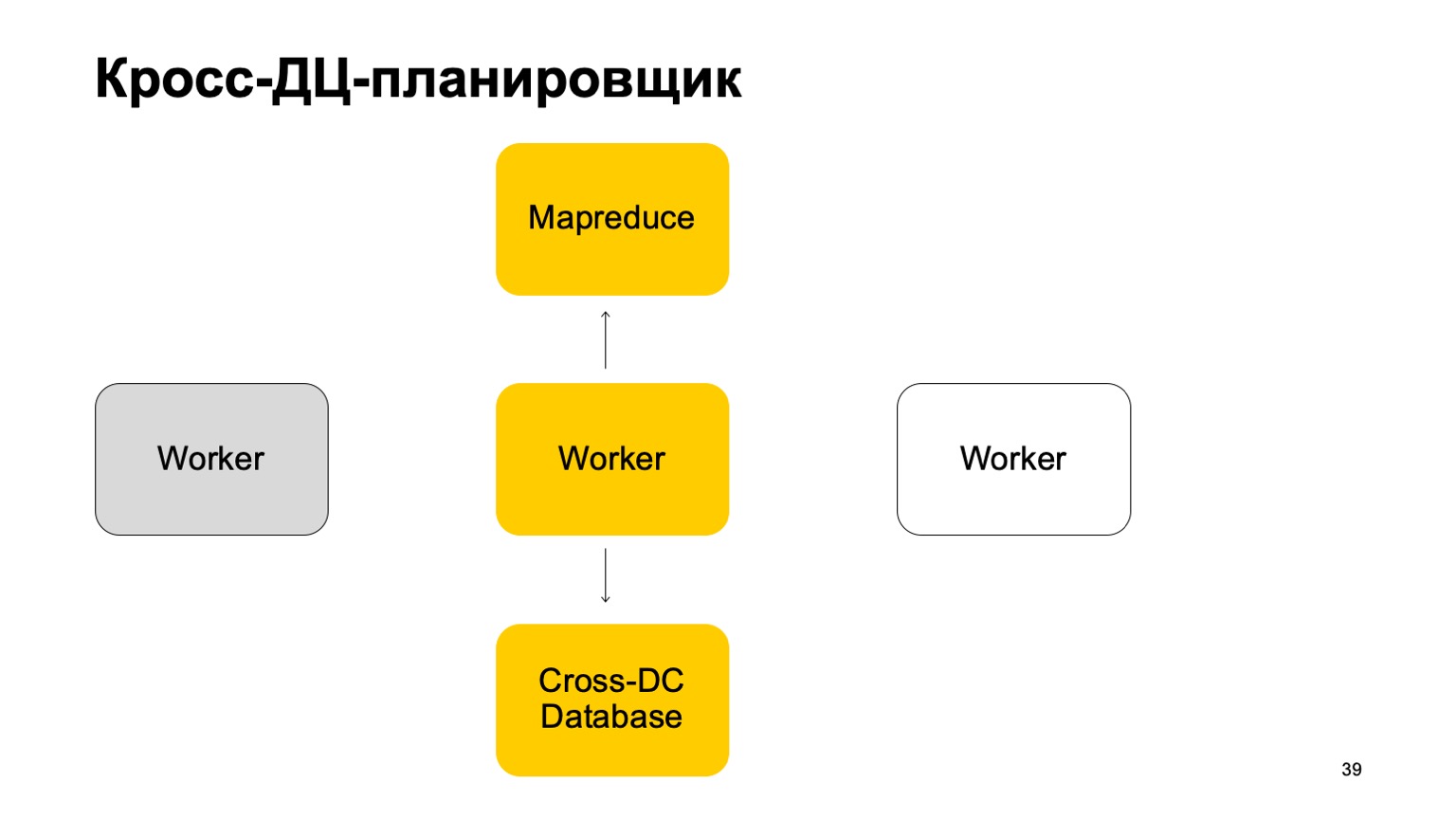
Está claro que en caso de anular estas tareas, algunas de ellas pueden reiniciarse. Por lo tanto, aquí tenemos una propiedad muy importante: la idempotencia, la capacidad de reiniciar cada operación sin consecuencias.
Es decir, todo el código debe estar escrito de tal manera que funcione bien.

Te contaré un poco sobre exactamente una vez. Estamos llegando a un veredicto en concierto, esto es muy importante. Utilizamos tecnologías que nos dan tales garantías y, naturalmente, controlamos todas las discrepancias, las reducimos a cero. Incluso cuando parece que esto ya se ha reducido, de vez en cuando surge un problema muy complicado que no tomamos en cuenta.
Instrumentos
Muy brevemente sobre las herramientas que utilizamos. Mantener múltiples antifraude para diferentes sistemas es una tarea difícil. Tenemos literalmente docenas de servicios diferentes, necesitamos algún tipo de lugar único donde pueda ver el estado de su trabajo en este momento.
Aquí está nuestro puesto de comando, donde puede ver el estado de los clústeres con los que estamos trabajando actualmente. Puede alternar entre ellos, lanzar un lanzamiento, etc.
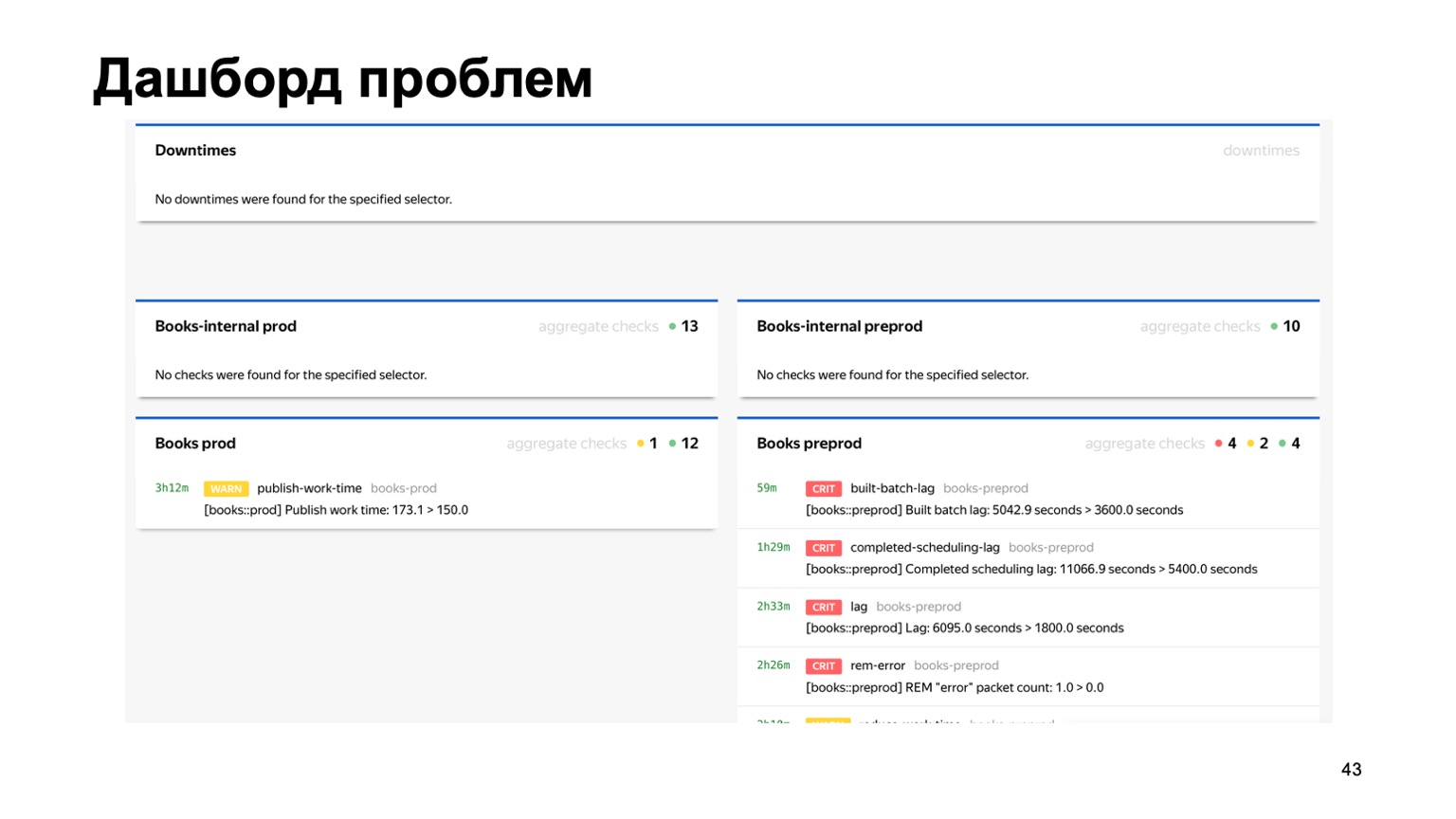
O, por ejemplo, un panel de problemas, donde vemos de inmediato en una página todos los problemas de todos los antifraudes de diferentes servicios que están conectados a nosotros. Aquí puede ver que algo está claramente mal con nuestro servicio de libros en este momento. Pero el monitoreo funcionará, y la persona de turno lo verá.
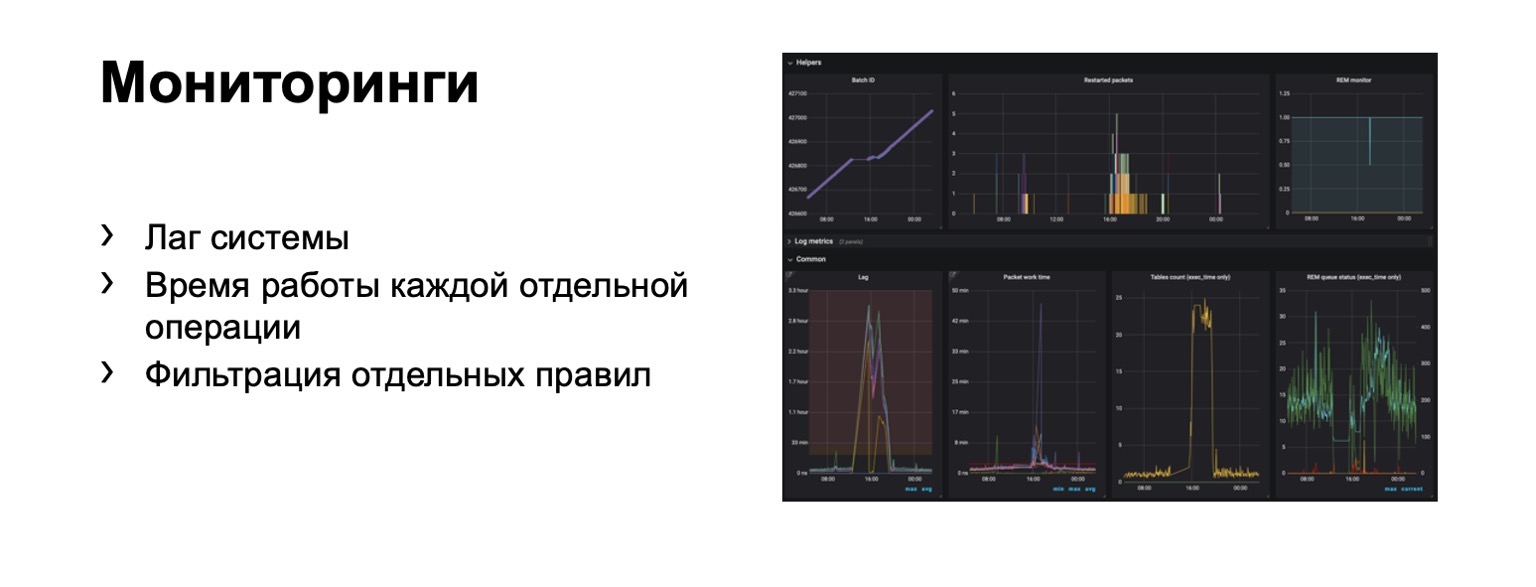
¿Qué estamos monitoreando en absoluto? Obviamente, el retraso del sistema es extremadamente importante. Obviamente, el tiempo de ejecución de cada etapa individual y, por supuesto, el filtrado de las reglas individuales. Este es un requisito comercial.
Cientos de gráficos y paneles aparecen. Por ejemplo, en este tablero, puede ver que el contorno era lo suficientemente malo ahora que tuvimos un retraso significativo.
Velocidad
Te contaré sobre la transición a la parte en línea. El problema aquí es que el retraso en un circuito completo puede alcanzar algunos minutos. Está en el esquema de MapReduce. En algunos casos, debemos prohibir, detectar estafadores más rápido.
¿Qué podría ser? Por ejemplo, nuestro servicio ahora tiene la capacidad de comprar libros. Y al mismo tiempo, ha aparecido un nuevo tipo de fraude de pagos. Necesitas reaccionar a eso más rápido. Surge la pregunta: ¿cómo transferir todo este esquema, idealmente preservando tanto como sea posible el lenguaje de interacción familiar para los analistas? Intentemos transferirlo "a la frente".
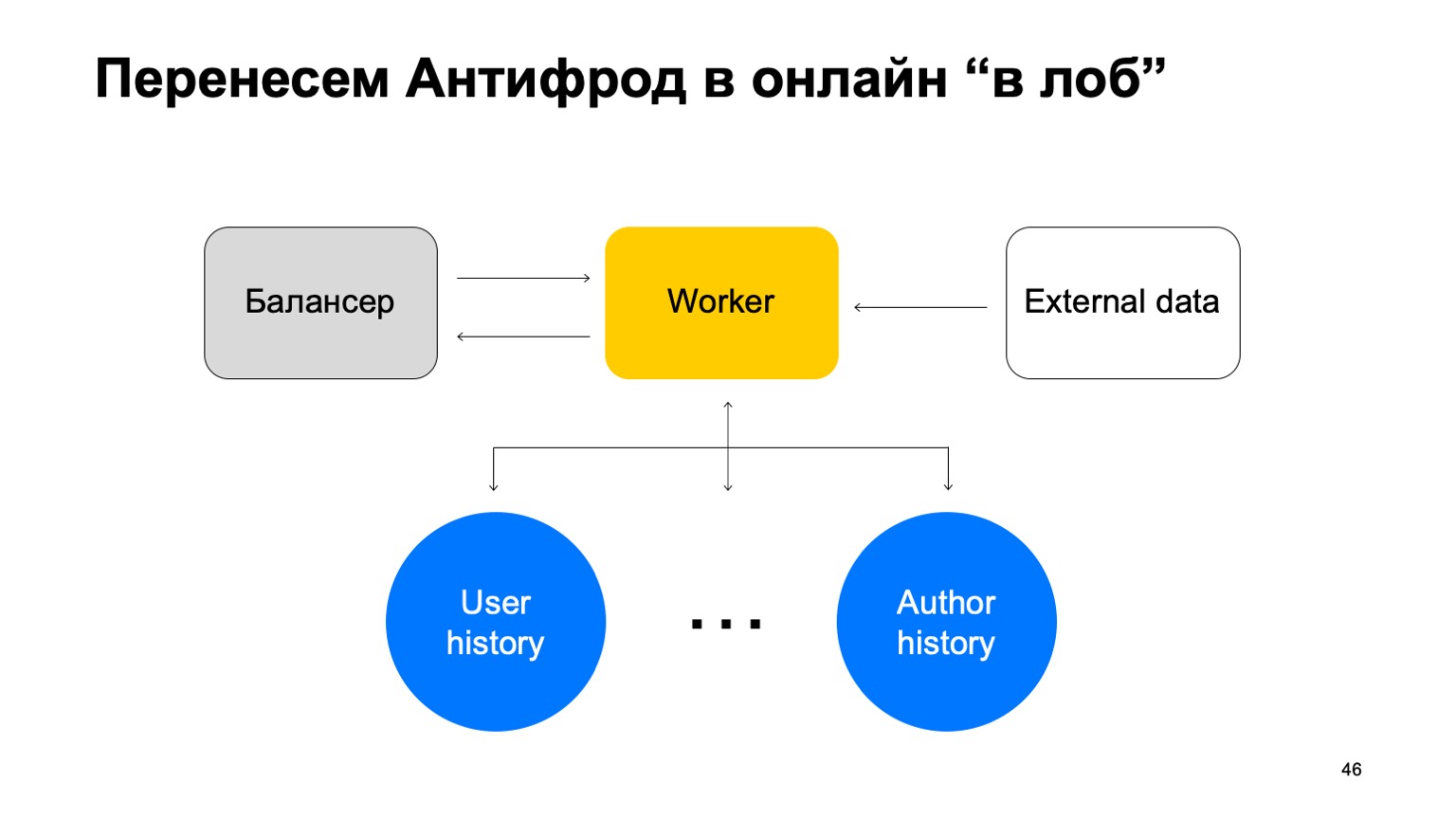
Digamos que tenemos un equilibrador con datos del servicio y una cierta cantidad de trabajadores a los que compartimos datos del equilibrador. Hay datos externos que usamos aquí, son muy importantes y un conjunto de estas historias. Permíteme recordarte que cada una de esas historias es diferente para diferentes reducciones, porque tiene diferentes claves.
En tal esquema, puede surgir el siguiente problema.
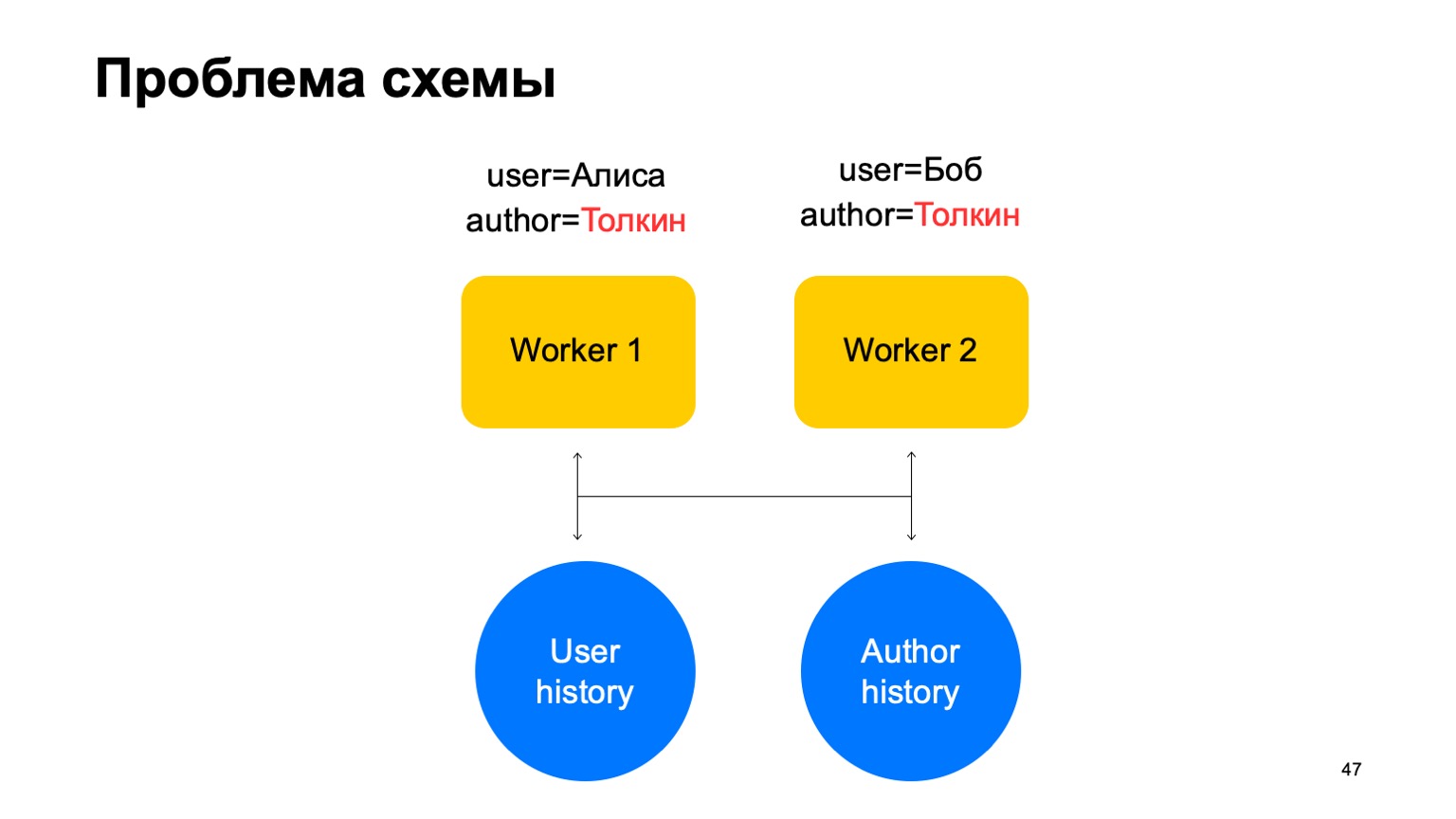
Digamos que tenemos dos eventos en nuestro trabajador. En este caso, con cualquier desguace de estos trabajadores, puede surgir una situación cuando una clave llega a diferentes trabajadores. En este caso, este es el autor Tolkien, se metió en dos trabajadores.
Luego leemos los datos de este almacenamiento de valores clave a ambos trabajadores del historial, los actualizaremos de manera diferente y surgirá una carrera cuando intentemos escribir de nuevo.
Solución: supongamos que la lectura y la escritura pueden separarse, que la escritura puede realizarse con un ligero retraso. Esto generalmente no es muy importante. Por un pequeño retraso, me refiero a unidades de segundos aquí. Esto es importante, en particular, porque nuestra implementación de este almacén de valores clave lleva más tiempo escribir datos que leerlos.
Actualizaremos las estadísticas con un retraso. En promedio, esto funciona más o menos bien, dado el hecho de que mantendremos el estado en caché en las máquinas.
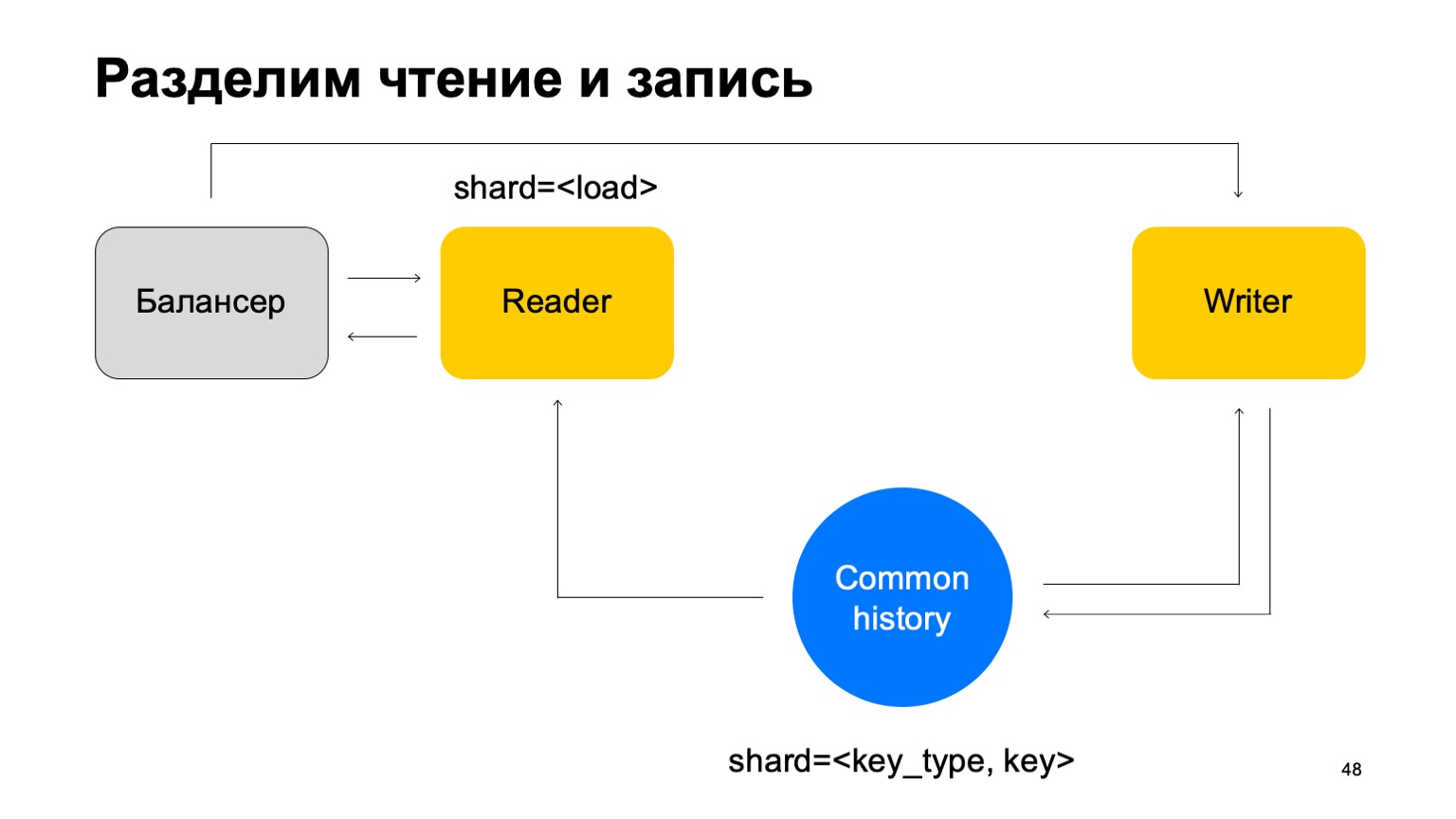
Y otra cosa. Para simplificar, fusionemos estas historias en una y anotémoslas por tipo y clave del corte. Tenemos algún tipo de historia común.
Luego, agregaremos nuevamente el equilibrador, agregaremos las máquinas de los lectores, que pueden dividirse de cualquier forma, por ejemplo, simplemente por carga. Simplemente leerán estos datos, aceptarán los veredictos finales y los devolverán al equilibrador.
En este caso, necesitamos un conjunto de máquinas de escritura a las que se enviarán estos datos directamente. Los escritores actualizarán la historia en consecuencia. Pero aquí todavía surge el problema, sobre el que escribí anteriormente. Cambiemos un poco la estructura del escritor entonces.
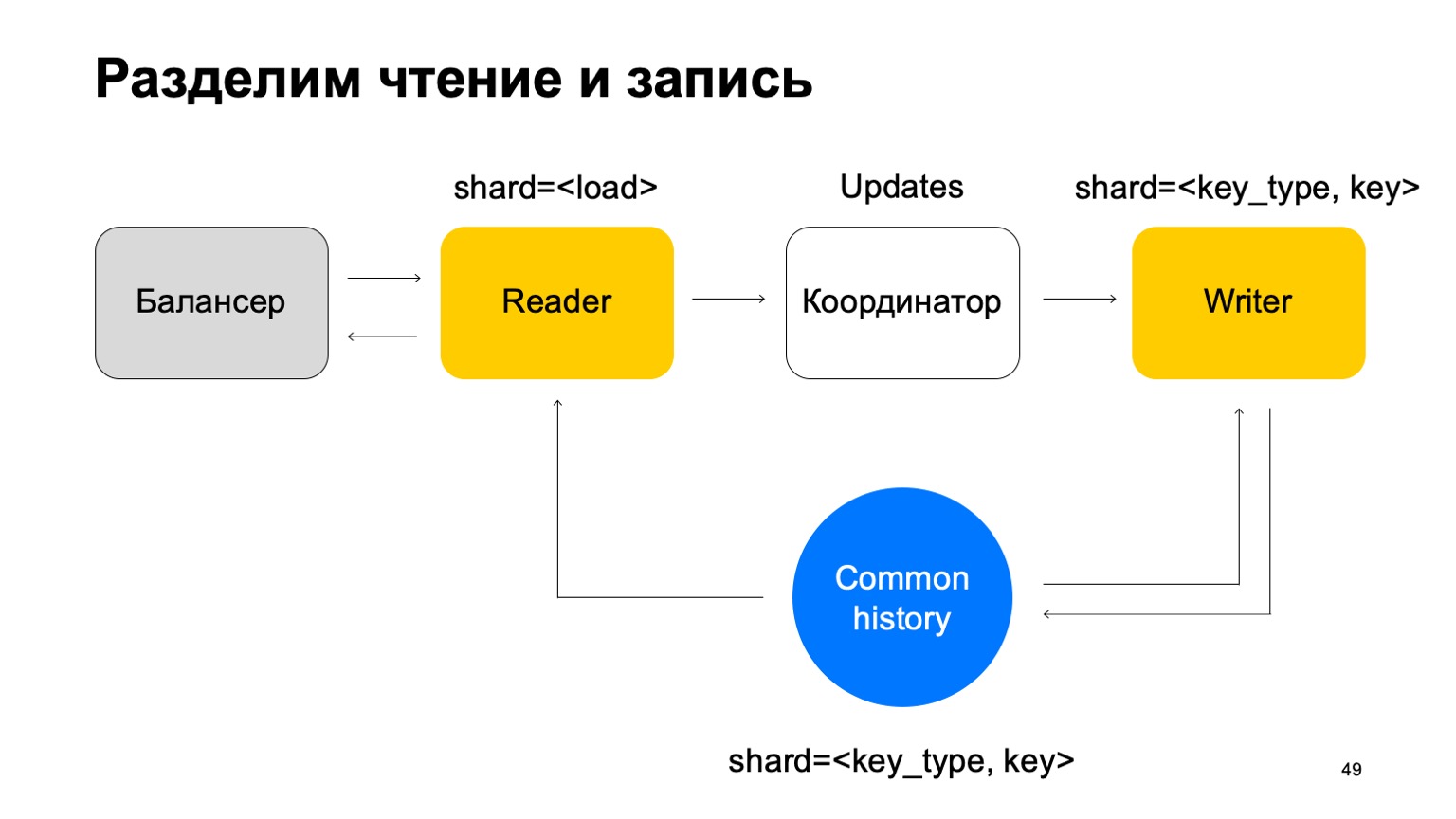
Lo haremos para que esté fragmentado de la misma manera que el historial, por el tipo y el valor de la clave. En este caso, cuando su fragmentación es la misma que la historia, no tendremos el problema que mencioné anteriormente.
Aquí su misión cambia. Ya no acepta veredictos. En cambio, solo acepta actualizaciones del Reader, las mezcla y las aplica correctamente al historial.
Está claro que aquí se necesita un componente, un coordinador que distribuya estas actualizaciones entre lectores y escritores.
A esto, por supuesto, se agrega el hecho de que el trabajador necesita mantener un caché actualizado. Como resultado, resulta que somos responsables de cientos de milisegundos, a veces menos, y actualizamos las estadísticas en un segundo. En general funciona bien, para los servicios es suficiente.

¿Qué obtuvimos en absoluto? Los analistas comenzaron a hacer su trabajo más rápido y de la misma manera para todos los servicios. Esto ha mejorado la calidad y la conectividad de todos los sistemas. Puede reutilizar datos entre antifraude de diferentes servicios, y los nuevos servicios obtienen alta calidad contra el fraude rápidamente.

Un par de pensamientos al final. Si escribe algo así, piense inmediatamente en la conveniencia de los analistas en términos de soporte y extensibilidad de estos sistemas. Haga que todo sea configurable, lo necesita. A veces, las propiedades de DC cruzado y exactamente una vez son difíciles de lograr, pero pueden. Si cree que ya lo ha logrado, vuelva a verificarlo. Gracias por tu atención.