Le presentamos una traducción de una investigación interesante de la compañía Crowdstrike. El material está dedicado al uso del lenguaje Rust en el campo de la ciencia de datos (en relación con el análisis de malware) y demuestra cómo Rust puede competir en dicho campo incluso con NumPy y SciPy, sin mencionar Python puro .

¡Disfruta leyendo!
Python es uno de los lenguajes de programación de ciencia de datos más populares, y por una buena razón. El Python Package Index (PyPI) tiene una tonelada de impresionantes bibliotecas de ciencia de datos como NumPy, SciPy, Natural Language Toolkit, Pandas y Matplotlib. Con una gran cantidad de bibliotecas analíticas de alta calidad disponibles y una extensa comunidad de desarrolladores, Python es la opción obvia para muchos científicos de datos.
Muchas de estas bibliotecas se implementan en C y C ++ por razones de rendimiento, pero proporcionan interfaces de funciones externas (FFI) o enlaces de Python para que las funciones puedan llamarse desde Python. Estas implementaciones de lenguaje de nivel inferior están destinadas a mitigar algunas de las deficiencias más visibles de Python, en particular en términos de tiempo de ejecución y consumo de memoria. Si puede limitar el tiempo de ejecución y el consumo de memoria, la escalabilidad se simplifica enormemente, lo que es fundamental para reducir los costos. Si podemos escribir código de alto rendimiento que resuelva problemas de ciencia de datos, la integración de dicho código con Python será una ventaja significativa.
Cuando se trabaja en la intersección de la ciencia de datos y el análisis de malwareno solo se requiere una ejecución rápida, sino también un uso eficiente de los recursos compartidos, nuevamente, para escalar. El escalado es uno de los problemas clave en Big Data, como el manejo eficiente de millones de ejecutables en múltiples plataformas. Lograr un buen rendimiento en los procesadores modernos requiere paralelismo, generalmente implementado usando subprocesos múltiples; pero también es necesario mejorar la eficiencia de la ejecución del código y el consumo de memoria. Al resolver estos problemas, puede ser difícil equilibrar los recursos del sistema local, y es aún más difícil implementar correctamente sistemas de subprocesos múltiples. La esencia de C y C ++ es que no se proporciona seguridad de subprocesos. Sí, hay bibliotecas externas específicas de la plataforma, pero garantizar la seguridad de los hilos es obviamente un deber del desarrollador.
Analizar malware es inherentemente peligroso. El software malicioso a menudo manipula estructuras de datos de formato de archivo de manera no intencionada, lo que paraliza las utilidades de análisis. Una trampa relativamente común que nos espera en Python es la falta de una buena seguridad de tipos. Python, que acepta generosamente los valores
Nonecuando se espera en su lugar bytearray, puede caer en un caos completo, que solo puede evitarse rellenando el código con comprobaciones None. Tales suposiciones de "escritura de pato" a menudo conducen a accidentes.
Pero hay óxido. Rust se posiciona de muchas maneras como la solución ideal para todos los problemas potenciales descritos anteriormente: el tiempo de ejecución y el consumo de memoria son comparables a C y C ++, y se proporciona una seguridad de tipo extensa. Rust también proporciona servicios adicionales, como fuertes garantías de seguridad de memoria y sin sobrecarga de tiempo de ejecución. Como no existe tal sobrecarga, facilita la integración del código Rust con el código de otros lenguajes, en particular Python. En este artículo, haremos un recorrido rápido por Rust para ver si vale la pena la publicidad asociada con él.
Aplicación de muestra para ciencia de datos
La ciencia de datos es un área temática muy amplia con muchos aspectos aplicados, y es imposible discutirlos todos en un solo artículo. Una tarea simple para la ciencia de datos es calcular la entropía informativa para secuencias de bytes. En Wikipedia se proporciona una fórmula general para calcular la entropía en bits :
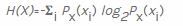
para calcular la entropía de una variable aleatoria
X, primero contamos cuántas veces se produce cada valor de byte posible 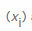 y luego dividimos ese número por el número total de elementos encontrados para calcular la probabilidad de encontrar un valor específico
y luego dividimos ese número por el número total de elementos encontrados para calcular la probabilidad de encontrar un valor específico 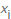 , respectivamente
, respectivamente 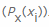 . Luego contamos el valor negativo de la suma ponderada de las probabilidades de que ocurra un valor particular xi , así como la llamada información propia
. Luego contamos el valor negativo de la suma ponderada de las probabilidades de que ocurra un valor particular xi , así como la llamada información propia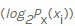 ... Como estamos calculando la entropía en bits, se usa aquí
... Como estamos calculando la entropía en bits, se usa aquí 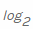 (observe la raíz 2 para bits).
(observe la raíz 2 para bits).
Probemos a Rust y veamos cómo maneja el cálculo de entropía versus Python puro, así como algunas de las bibliotecas populares de Python mencionadas anteriormente. Esta es una estimación simplificada del rendimiento potencial de la ciencia de datos de Rust; Este experimento no es una crítica a Python ni a las excelentes bibliotecas que contiene. En estos ejemplos, generaremos nuestra propia biblioteca C a partir del código Rust que podemos importar desde Python. Todas las pruebas se ejecutaron en Ubuntu 18.04.
Pitón puro
Comencemos con una simple función de Python pura (c
entropy.py) para calcular la entropía bytearray, utilizando solo el módulo matemático de la biblioteca estándar. Esta función no está optimizada, así que tomemos como un punto de partida para modificaciones y mediciones de rendimiento.
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
Python con NumPy y SciPy
Como era de esperar, SciPy proporciona una función para calcular la entropía. Pero primero, usaremos una función
unique()de NumPy para calcular las frecuencias de bytes. Comparar el rendimiento de la función de entropía SciPy con otras implementaciones es un poco injusto, ya que la implementación SciPy tiene una funcionalidad adicional para calcular la entropía relativa (distancia de Kullback-Leibler). Nuevamente, haremos una prueba de manejo (con suerte no demasiado lenta) para ver cuál será el rendimiento de las bibliotecas compuestas de Rust importadas de Python. Seguiremos con la implementación de SciPy incluida en nuestro script entropy.py.
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)Pitón con óxido
A continuación, exploraremos nuestra implementación de Rust un poco más, en comparación con implementaciones anteriores, en aras de ser sólidos y sólidos. Comencemos con el paquete de biblioteca predeterminado generado con Cargo. Las siguientes secciones muestran cómo modificamos el paquete Rust.
cargo new --lib rust_entropy
Cargo.tomlComenzamos con un archivo de manifiesto obligatorio
Cargo.tomlque define el paquete Cargo y especifica un nombre de biblioteca rust_entropy_lib. Usamos el contenedor público de cpython (v0.4.1) disponible en crates.io, en el Rust Package Registry. Para este artículo, estamos utilizando Rust v1.42.0, la última versión estable disponible en el momento de la redacción.
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]lib.rs
La implementación de la biblioteca Rust es bastante sencilla. Al igual que con nuestra implementación pura de Python, inicializamos la matriz de conteos para cada valor de byte posible e iteramos sobre los datos para completar los conteos. Para completar la operación, calcule y devuelva la suma negativa de probabilidades multiplicada por las
probabilidades.
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
Todo lo que nos queda
lib.rses un mecanismo para llamar a una función Rust pura desde Python. Incluimos en lib.rsuna función CPython-tuned (compute_entropy_cpython())para llamar a nuestra función Rust "pura" (compute_entropy_pure_rust()). Al hacerlo, solo nos beneficiamos al mantener una única implementación de Rust pura y al proporcionar un contenedor compatible con CPython.
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);Llamar a Rust Code desde Python
Finalmente, llamamos a la implementación Rust desde Python (nuevamente, desde
entropy.py). Para hacer esto, primero importamos nuestra propia biblioteca de sistema dinámico compilada de Rust. Luego, simplemente llamamos a la función de biblioteca proporcionada que especificamos previamente al inicializar el módulo Python usando una macro py_module_initializer!en nuestro código Rust. En esta etapa, solo tenemos un módulo Python ( entropy.py), que incluye funciones para llamar a todas las implementaciones de cálculo de entropía.
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)Estamos construyendo el paquete de la biblioteca Rust anterior en Ubuntu 18.04 usando Cargo. (Este enlace puede ser útil para usuarios de OS X).
cargo build --releaseCuando terminamos con el ensamblaje, cambiamos el nombre de la biblioteca resultante y la copiamos al directorio donde se encuentran nuestros módulos de Python, para que pueda importarse desde los scripts. Se nombra la biblioteca que creó con Cargo
librust_entropy_lib.so, pero debe cambiarle el nombre rust_entropy_lib.sopara poder importar con éxito como parte de estas pruebas.
Comprobación de rendimiento: resultados
Medimos el rendimiento de la implementación de cada función utilizando los puntos de corte de pytest, calculando la entropía para más de 1 millón de bytes aleatorios. Todas las implementaciones se muestran en los mismos datos. Los puntos de referencia (también incluidos en entropy.py) se muestran a continuación.
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)Finalmente, creamos scripts de controladores simples por separado para cada método necesario para calcular la entropía. El siguiente es un script de controlador representativo para probar la implementación pura de Python. El archivo contiene
testdata.bin1,000,000 bytes aleatorios utilizados para probar todos los métodos. Cada método repite el cálculo 100 veces para facilitar la captura de datos de uso de memoria.
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)Las implementaciones para SciPy / NumPy y Rust han mostrado un buen rendimiento, superando fácilmente una implementación de Python pura no optimizada en más de 100 veces. La versión de Rust funcionó solo un poco mejor que la versión de SciPy / NumPy, pero los resultados confirmaron nuestras expectativas: Python puro es mucho más lento que los lenguajes compilados, y las extensiones escritas en Rust pueden competir con bastante éxito con sus contrapartes C (superando incluso en tales microtesting).
También hay otros métodos para mejorar la productividad. Podríamos usar módulos
ctypeso cffi. Puede agregar sugerencias de tipo y usar Cython para generar una biblioteca que podría importar desde Python. Todas estas opciones requieren soluciones de compromiso específicas para ser consideradas.

También medimos el uso de memoria para cada implementación de características utilizando la aplicación GNU
time(que no debe confundirse con el comando de shell incorporado time). En particular, medimos el tamaño máximo del conjunto residente.
Mientras que en las implementaciones puras de Python y Rust los tamaños máximos para esta porción son bastante similares, la implementación SciPy / NumPy consume significativamente más memoria para este punto de referencia. Esto se debe presumiblemente a características adicionales cargadas en la memoria durante la importación. Sea como fuere, llamar al código Rust desde Python no parece introducir una sobrecarga de memoria significativa.

Salir
Estamos extremadamente impresionados con el rendimiento que obtenemos cuando llamamos a Rust desde Python. En nuestra evaluación francamente breve, la implementación de Rust pudo competir en rendimiento con la implementación de base C de los paquetes SciPy y NumPy. El óxido parece ser excelente para un procesamiento eficiente a gran escala.
Rust ha demostrado no solo excelentes tiempos de ejecución; Cabe señalar que la sobrecarga de memoria en estas pruebas también fue mínima. Estas características de tiempo de ejecución y uso de memoria parecen ser ideales para fines de escalabilidad. El rendimiento de las implementaciones de SciPy y NumPy C FFI es definitivamente comparable, pero con Rust obtenemos ventajas adicionales que C y C ++ no nos brindan. La seguridad de la memoria y las garantías de seguridad del hilo son un beneficio muy atractivo.
Mientras que C proporciona un tiempo de ejecución comparable a Rust, C en sí no proporciona seguridad para el hilo. Hay bibliotecas externas que proporcionan esta funcionalidad para C, pero es responsabilidad del desarrollador asegurarse de que se usan correctamente. Rust monitorea problemas de seguridad de roscas, como carreras, en tiempo de compilación, gracias a su modelo de propiedad, y la biblioteca estándar proporciona un conjunto de mecanismos de concurrencia como tuberías, cerraduras y punteros inteligentes contados por referencia.
No estamos abogando por portar SciPy o NumPy a Rust, ya que estas bibliotecas de Python ya están bien optimizadas y respaldadas por comunidades de desarrolladores geniales. Por otro lado, recomendamos encarecidamente portar código de Python puro a Rust que no se proporciona en bibliotecas de alto rendimiento. En el contexto de las aplicaciones de ciencia de datos utilizadas para el análisis de seguridad, Rust parece ser una alternativa competitiva a Python, dada su velocidad y garantías de seguridad.