
Por supuesto, NSPK no es una startup, pero esa atmósfera prevaleció en la empresa en los primeros años de su existencia, y estos fueron años muy interesantes. Mi nombre es Dmitry Kornyakov , he apoyado la infraestructura de Linux con requisitos de alta disponibilidad durante más de 10 años. Se unió al equipo NSPK en enero de 2016 y, desafortunadamente, no vio el comienzo de la existencia de la compañía, pero llegó a la etapa de grandes cambios.
En general, podemos decir que nuestro equipo suministra 2 productos para la empresa. El primero es la infraestructura. El correo debería funcionar, el DNS debería funcionar y los controladores de dominio deberían permitirle en servidores que no deberían caerse. ¡El panorama de TI de la empresa es enorme! Estos son sistemas comerciales y de misión crítica, los requisitos de disponibilidad para algunos son 99,999. El segundo producto son los propios servidores, físicos y virtuales. Los existentes deben ser monitoreados, y los nuevos se suministran regularmente a los clientes de muchos departamentos. En este artículo, quiero centrarme en cómo desarrollamos la infraestructura responsable del ciclo de vida de los servidores.
El comienzo de la ruta
Al comienzo de la ruta, nuestra pila de tecnología se veía así: Controladores de dominio
OS CentOS 7
FreeIPA
Automation - Ansible (+ Tower), Cobbler
Todo esto estaba ubicado en 3 dominios, distribuidos en varios centros de datos. En un centro de datos: sistemas de oficina y sitios de prueba, en el resto PROD.
En algún momento, la creación de servidores se veía así:
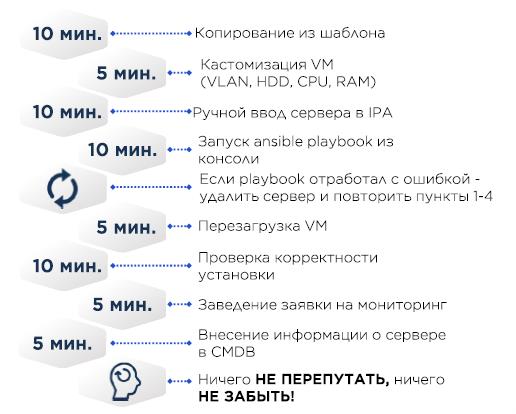
en la plantilla mínima VM CentOS y el mínimo requerido, como el /etc/resolv.conf correcto, el resto viene a través de Ansible.
CMDB - Excel.
Si el servidor es físico, entonces, en lugar de copiar la máquina virtual, el SO se instaló usando Cobbler: las direcciones MAC del servidor de destino se agregan a la configuración de Cobbler, el servidor recibe una dirección IP a través de DHCP y luego se vierte el SO.
Al principio, incluso intentamos hacer algún tipo de gestión de configuración en Cobbler. Pero con el tiempo, esto comenzó a traer problemas con la portabilidad de las configuraciones tanto a otros centros de datos como al código Ansible para preparar la VM.
En ese momento, muchos de nosotros percibimos a Ansible como una extensión conveniente de Bash y no escatimamos en las construcciones que usan el shell, sed. En general Bashsible. En última instancia, esto condujo al hecho de que si el libro de jugadas por alguna razón no funcionaba en el servidor, era más fácil eliminarlo, arreglarlo y volver a ejecutarlo. De hecho, no había versiones de script, portabilidad de configuración también.
Por ejemplo, queríamos cambiar alguna configuración en todos los servidores:
- Cambiamos la configuración en los servidores existentes en el segmento lógico / centro de datos. A veces no de la noche a la mañana: los requisitos de disponibilidad y la ley de grandes números no permiten que todos los cambios se apliquen a la vez. Y algunos cambios son potencialmente destructivos y requieren reiniciar cualquier cosa, desde los servicios hasta el sistema operativo.
- Arreglando en Ansible
- Fijación en Zapatero
- Repita N veces para cada segmento lógico / centro de datos
Para que todos los cambios se realicen sin problemas, se tuvieron que considerar muchos factores, y los cambios ocurren constantemente.
- Refactorización de código ansible, archivos de configuración
- Cambio de mejores prácticas internas
- Cambios posteriores al análisis de incidentes / accidentes
- Cambios en los estándares de seguridad, tanto internos como externos. Por ejemplo, PCI DSS se actualiza con nuevos requisitos cada año.
Crecimiento de la infraestructura y el comienzo de la ruta La
cantidad de servidores / dominios lógicos / centros de datos creció y, con ellos, la cantidad de errores en las configuraciones. En algún momento, llegamos a tres direcciones, hacia las cuales debemos desarrollar la gestión de la configuración:
- Automatización. En la medida de lo posible, se debe evitar el factor humano en las operaciones repetitivas.
- . , . . – , .
- configuration management.
Queda por agregar un par de herramientas
Elegimos GitLab CE como nuestro repositorio de código, especialmente para los módulos CI / CD integrados.
Bóveda de los secretos - Bóveda de Hashicorp, incl. por la gran API.
Configuraciones de prueba y roles ansibles: Molecule + Testinfra. Las pruebas se ejecutan mucho más rápido si está conectado a mitógeno ansible. Paralelamente, comenzamos a escribir nuestro propio CMDB y un orquestador para la implementación automática (en la imagen de arriba Cobbler), pero esta es una historia completamente diferente, que mi colega y el principal desarrollador de estos sistemas contarán en el futuro.
Nuestra elección:
Molecule + Testinfra
Ansible + Tower + AWX Server
World + DITNET (In-house)
Cobbler
Gitlab + GitLab runner
Hashicorp Vault

Hablando de roles ansibles. Al principio estaba solo, después de varias refactorizaciones hay 17 de ellas. Recomiendo dividir el monolito en roles idempotentes, que luego se pueden ejecutar por separado, además puede agregar etiquetas. Dividimos los roles por funcionalidad: red, registro, paquetes, hardware, molécula, etc. En general, nos adherimos a la estrategia a continuación. No insisto en que esta sea la única verdad, pero funcionó para nosotros.
- ¡Copiar servidores de la "imagen dorada" es malo!
La principal desventaja es que no sabe exactamente en qué estado están las imágenes ahora, y que todos los cambios se producirán en todas las imágenes en todas las granjas de virtualización. - Utilice los archivos de configuración predeterminados al mínimo y acuerde con otros departamentos acerca de los archivos principales del sistema de los que es responsable , por ejemplo:
- /etc/sysctl.conf , /etc/sysctl.d/. , .
- override systemd .
- , sed
- :
- ! Ansible-lint, yaml-lint, etc
- ! bashsible.
- Ansible molecule .
- , ( 100) 70000 . .

Nuestra implementación
Por lo tanto, los roles ansibles estaban listos, modelados y comprobados por linters. E incluso los gits se crían en todas partes. Pero la cuestión de la entrega confiable de código a diferentes segmentos permaneció abierta. Decidimos sincronizar con los scripts. Se ve así:

después de que ha llegado el cambio, se lanza CI, se crea un servidor de prueba, se desarrollan roles, se prueban con una molécula. Si todo está bien, el código va a la rama de producción. Pero no estamos aplicando el nuevo código a los servidores existentes en la máquina. Este es un tipo de tapón que es necesario para la alta disponibilidad de nuestros sistemas. Y cuando la infraestructura se vuelve enorme, la ley de los grandes números entra en juego, incluso si está seguro de que el cambio es inofensivo, puede tener graves consecuencias.
También hay muchas opciones para crear servidores. Terminamos eligiendo scripts de python personalizados. Y para CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Esto es a lo que hemos llegado, el sistema continúa viviendo y desarrollándose.
- 17 roles ansibles para configurar el servidor. Cada uno de los roles está diseñado para resolver una tarea lógica separada (registro, auditoría, autorización del usuario, monitoreo, etc.).
- Prueba de roles. Molécula + TestInfra.
- Desarrollo propio: CMDB + Orchestrator.
- Tiempo de creación del servidor ~ 30 minutos, automatizado y prácticamente independiente de la cola de tareas.
- El mismo estado / denominación de la infraestructura en todos los segmentos: libros de jugadas, repositorios, elementos de virtualización.
- Comprobación diaria del estado de los servidores con generación de informes sobre discrepancias con el estándar.
Espero que mi historia sea útil para aquellos que están al comienzo del viaje. ¿Qué pila de automatización estás usando?