En este artículo, quiero hablar sobre cómo nuestro equipo decidió aplicar el enfoque de CQRS y búsqueda de eventos en un proyecto que es un sitio de subastas en línea. Y también sobre lo que surgió de esto, qué conclusiones se pueden extraer de nuestra experiencia y qué rasgo es importante no pisar para aquellos que pasan por CQRS & ES.

Preludio
Para empezar, un poco de historia y experiencia en negocios. Un cliente nos llegó con una plataforma para realizar las llamadas subastas programadas, que ya estaban en producción y sobre las cuales se recopiló una cierta cantidad de comentarios. El cliente quería que creáramos una plataforma para subastas en vivo para él.
Ahora un poco de terminología. Una subasta es cuando se venden ciertos artículos: lotes y compradores (postores) hacen ofertas. El propietario del lote es el comprador que ofreció la oferta más alta. La subasta programada es cuando cada lote tiene un tiempo de cierre predeterminado. Los compradores hacen apuestas, en algún momento el lote está cerrado. Similar a eBay.
La plataforma cronometrada se realizó de manera clásica, utilizando CRUD. Los lotes fueron cerrados por una aplicación separada, comenzando en un horario. Todo esto no funcionó de manera muy confiable: algunas apuestas se perdieron, algunas se hicieron como si fueran en nombre del comprador equivocado, los lotes no se cerraron o cerraron varias veces.
La subasta en vivo es una oportunidad para participar en una subasta real fuera de línea de forma remota a través de Internet. Hay una sala (en nuestra terminología interna - "sala"), que contiene el anfitrión de la subasta con un martillo y la audiencia, y justo al lado de la computadora portátil se encuentra el llamado empleado, quien, al presionar los botones en su interfaz, transmite el curso de la subasta a Internet, y el conectado Al momento de la subasta, los compradores ven las ofertas que se están colocando fuera de línea y pueden presentar sus ofertas.
Ambas plataformas funcionan en principio en tiempo real, pero si en el caso de todos los compradores están en una posición igual, en el caso de live es extremadamente importante que los compradores en línea puedan competir con éxito con los que están en la sala. Es decir, el sistema debe ser muy rápido y confiable. La triste experiencia de la plataforma cronometrada nos dijo en términos inequívocos que el CRUD clásico no era adecuado para nosotros.
No teníamos nuestra propia experiencia de trabajar con CQRS & ES, por lo que consultamos con colegas que lo tenían (tenemos una gran empresa), les presentamos nuestras realidades comerciales y llegamos a la conclusión de que CQRS & ES debería ser adecuado para nosotros.
¿Qué más son los detalles de las subastas en línea?
- — . , « », , . — , 5 . .
- , , .
- — - , , — .
- , .
- La solución debe ser escalable: se pueden realizar varias subastas simultáneamente.
Una breve descripción del enfoque de CQRS y ES
No me detendré en la consideración del enfoque CQRS & ES, hay materiales sobre esto en Internet y en particular en Habré (por ejemplo, aquí: Introducción a CQRS + Event Sourcing ). Sin embargo, te recordaré brevemente los puntos principales:
- Lo más importante en el abastecimiento de eventos: el sistema no almacena datos, sino el historial de sus cambios, es decir, eventos. El estado actual del sistema se obtiene mediante la aplicación secuencial de eventos.
- El modelo de dominio se divide en entidades llamadas agregados. La unidad tiene una versión. Los eventos se aplican a los agregados. La aplicación de un evento a un agregado incrementa su versión.
- write-. , .
- . . , , . «» . .
- , , - ( N- ) . «» . , .
- - , , , , write-.
- write-, read-, , . read- . Read- .
- , — Command Query Responsibility Segregation (CQRS): , , write-; , , read-.

. .
Para ahorrar tiempo, así como debido a la falta de experiencia específica, decidimos que necesitamos usar algún tipo de marco para CQRS y ES.
En general, nuestra pila de tecnología es Microsoft, es decir .NET y C #. Base de datos: Microsoft SQL Server. Todo está alojado en Azure. Se hizo una plataforma cronometrada en esta pila, era lógico hacer una plataforma en vivo en ella.
En ese momento, como recuerdo ahora, Chinchilla era casi la única opción adecuada para nosotros en términos de la pila tecnológica. Entonces la llevamos.
¿Por qué necesitamos un marco CQRS y ES? Él puede "fuera de la caja" resolver problemas y apoyar aspectos de implementación como:
- Entidades agregadas, comandos, eventos, versiones agregadas, rehidratación, mecanismo de instantáneas.
- Interfaces para trabajar con diferentes DBMS. Guardar / cargar eventos e instantáneas de agregados hacia / desde la base de escritura (almacén de eventos).
- Interfaces para trabajar con colas: enviar comandos y eventos a las colas apropiadas, leer comandos y eventos desde la cola.
- Interfaz para trabajar con websockets.
Por lo tanto, teniendo en cuenta el uso de Chinchilla, agregamos a nuestra pila:
- Azure Service Bus como comando y bus de eventos, Chinchilla lo admite de forma inmediata;
- Las bases de datos de escritura y lectura son Microsoft SQL Server, es decir, ambas son bases de datos SQL. No diré que este es el resultado de una elección consciente, sino más bien por razones históricas.
Sí, la interfaz está hecha en angular.
Como ya dije, uno de los requisitos para el sistema es que los usuarios aprendan lo más rápido posible sobre los resultados de sus acciones y las acciones de otros usuarios; esto se aplica tanto a los compradores como al empleado. Por lo tanto, utilizamos SignalR y websockets para actualizar rápidamente los datos en la interfaz. Chinchilla admite la integración SignalR.
Selección de unidades
Una de las primeras cosas que debe hacer al implementar el enfoque CQRS & ES es determinar cómo se dividirá el modelo de dominio en agregados.
En nuestro caso, el modelo de dominio consta de varias entidades principales, algo como esto:
public class Auction
{
public AuctionState State { get; private set; }
public Guid? CurrentLotId { get; private set; }
public List<Guid> Lots { get; }
}
public class Lot
{
public Guid? AuctionId { get; private set; }
public LotState State { get; private set; }
public decimal NextBid { get; private set; }
public Stack<Bid> Bids { get; }
}
public class Bid
{
public decimal Amount { get; set; }
public Guid? BidderId { get; set; }
}
Tenemos dos agregados: Subasta y Lote (con Ofertas). En general, es lógico, pero no tomamos en cuenta una cosa: el hecho de que con tal división el estado del sistema se extendió en dos unidades y, en algunos casos, para mantener la coherencia, debemos realizar cambios en ambas unidades, y no en una. Por ejemplo, una subasta se puede pausar. Si la subasta está en pausa, no puede ofertar por el lote. Sería posible pausar el lote en sí, pero una subasta pausada no puede procesar ningún comando que no sea "pausar".
Alternativamente, solo se podría hacer un agregado, Subasta, con todos los lotes y ofertas dentro. Pero tal objeto será bastante difícil, porque puede haber hasta varios miles de lotes en la subasta y puede haber varias docenas de ofertas por lote. Durante la vigencia de la subasta, dicho agregado tendrá muchas versiones, y la rehidratación de dicho agregado (aplicación secuencial de todos los eventos al agregado), si no se realizan instantáneas de los agregados, llevará bastante tiempo. Lo cual es inaceptable para nuestra situación. Si usa instantáneas (las usamos), las instantáneas en sí pesarán mucho.
Por otro lado, para garantizar que los cambios se apliquen a dos agregados dentro del procesamiento de una sola acción del usuario, debe cambiar ambos agregados dentro del mismo comando utilizando una transacción, o ejecutar dos comandos dentro de la misma transacción. Ambos son, en general, una violación de la arquitectura.
Tales circunstancias deben tenerse en cuenta al dividir el modelo de dominio en agregados.
En esta etapa de la evolución del proyecto, vivimos con dos unidades, Auction y Lot, y rompemos la arquitectura cambiando ambas unidades dentro de algunos comandos.
Aplicar un comando a una versión específica de un agregado
Si varios compradores hacen una oferta en el mismo lote al mismo tiempo, es decir, envían un comando de "hacer una oferta" al sistema, solo una de las ofertas tendrá éxito. Mucho es un agregado, tiene una versión. Durante el procesamiento del comando, se generan eventos, cada uno de los cuales incrementa la versión del agregado. Hay dos caminos a seguir:
- Envíe un comando que especifique a qué versión del agregado queremos aplicarlo. Luego, el controlador de comandos puede comparar inmediatamente la versión en el comando con la versión actual de la unidad y no continuar si no coincide.
- No especifique la versión de la unidad en el comando. Luego, el agregado se rehidrata con alguna versión, se ejecuta la lógica de negocios correspondiente, se generan eventos. Y solo cuando se guardan puede aparecer una ejecución emergente de que tal versión de la unidad ya existe. Porque alguien más lo hizo antes.
Usamos la segunda opción. Esto le da a los equipos una mejor oportunidad de ser ejecutados. Debido a que en la parte de la aplicación que envía comandos (en nuestro caso, esta es la interfaz), la versión actual del agregado con cierta probabilidad va a la zaga de la versión real en el back-end. Especialmente en condiciones en las que se envían muchos comandos y la versión de la unidad cambia con frecuencia.
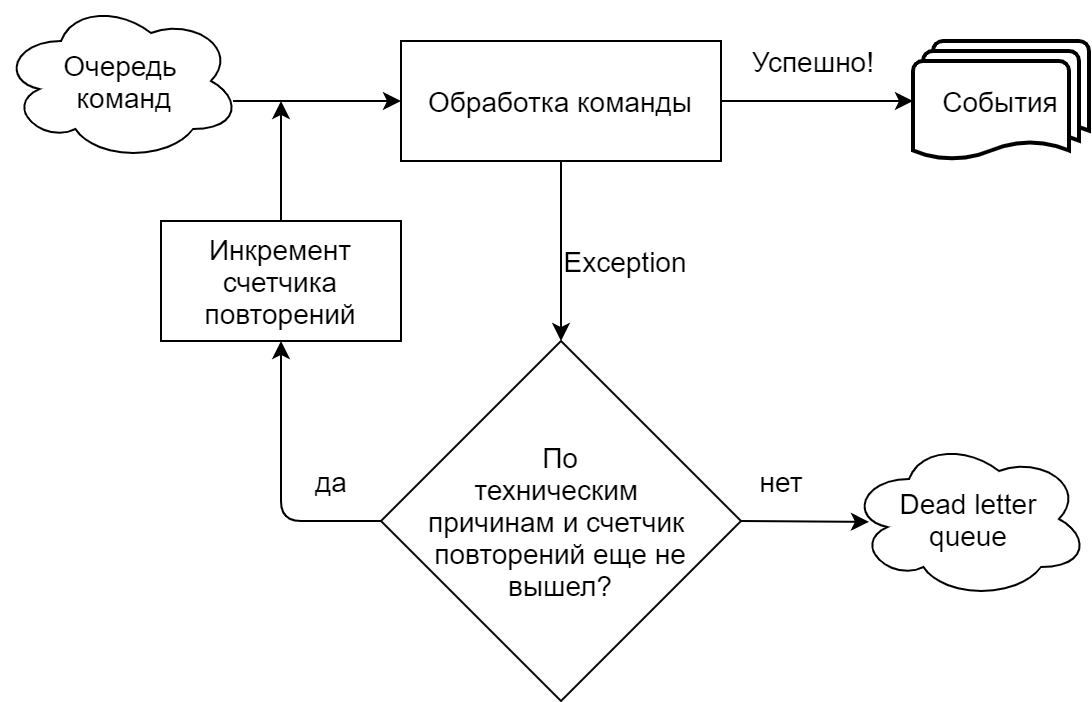
Errores al ejecutar un comando usando una cola
En nuestra implementación, fuertemente impulsada por Chinchilla, el controlador de comandos lee los comandos de una cola (Microsoft Azure Service Bus). Distinguimos claramente las situaciones en las que el equipo falló por razones técnicas (tiempos de espera, errores al conectarse a la cola / base) y cuando por razones comerciales (un intento de hacer una oferta por un lote de la misma cantidad que ya se había aceptado, etc.). En el primer caso, el intento de ejecutar el comando se repite hasta que se alcanza el número de repeticiones especificado en la configuración de la cola, después de lo cual el comando se envía a la Cola de letra muerta (un tema separado para los mensajes no procesados en el Bus de servicio de Azure). En el caso de una ejecución comercial, el equipo se envía a la Cola de mensajes muertos inmediatamente.
Errores al manejar eventos usando una cola
Los eventos generados como resultado de la ejecución del comando, dependiendo de la implementación, también se pueden enviar a la cola y los manejadores de eventos pueden tomar de la cola. Y cuando se manejan eventos, también ocurren errores.
Sin embargo, en contraste con la situación con un comando no ejecutado, todo es peor aquí: puede suceder que el comando se haya ejecutado y los eventos se hayan escrito en la base de escritura, pero los procesadores fallaron su procesamiento. Y si uno de estos controladores actualiza la base de lectura, entonces la base de lectura no se actualizará. Es decir, estará en un estado inconsistente. Debido al mecanismo para volver a intentar el evento de lectura, la base de datos casi siempre se actualiza al final, pero la probabilidad de que, después de todos los intentos, permanezca rota aún permanece.
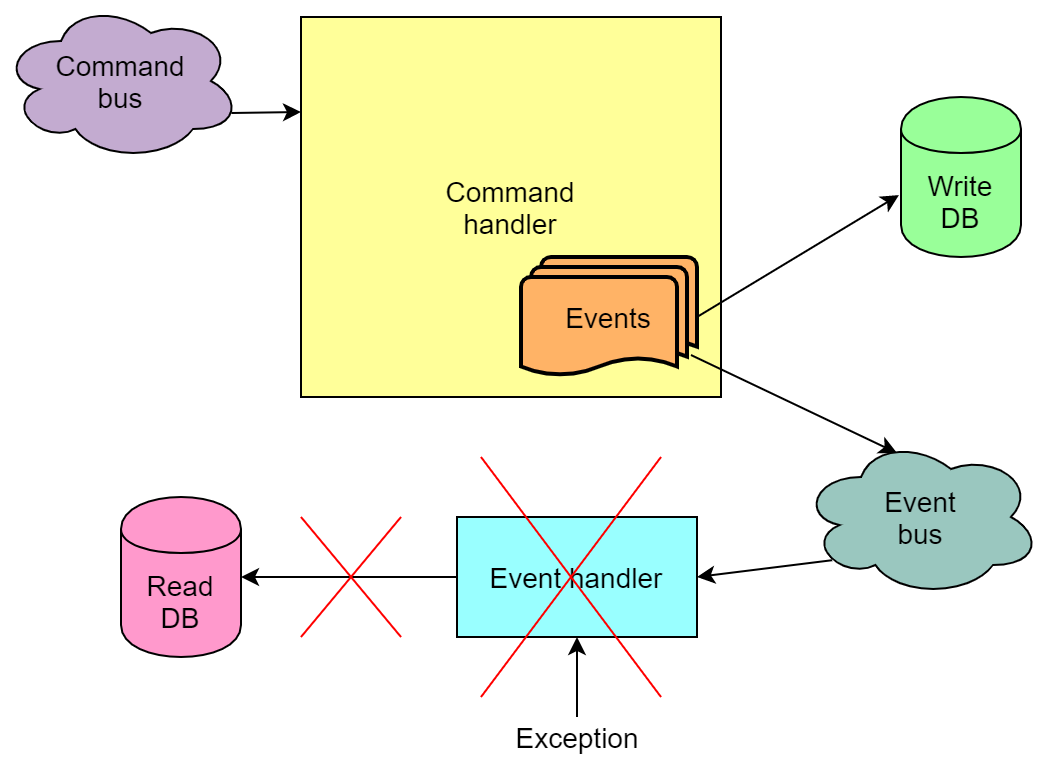
Hemos encontrado este problema en casa. La razón, sin embargo, se debió en gran parte al hecho de que teníamos cierta lógica comercial en el procesamiento del evento, que, con un intenso flujo de apuestas, tiene una buena probabilidad de fallar de vez en cuando. Desafortunadamente, nos dimos cuenta de esto demasiado tarde, no era posible rehacer la implementación comercial de manera rápida y sencilla.
Como resultado, como medida temporal, dejamos de usar Azure Service Bus para transferir eventos desde la parte de escritura de la aplicación a la parte de lectura. En su lugar, se utiliza el denominado Bus en memoria, que le permite procesar el comando y los eventos en una transacción y, en caso de falla, revertir todo.
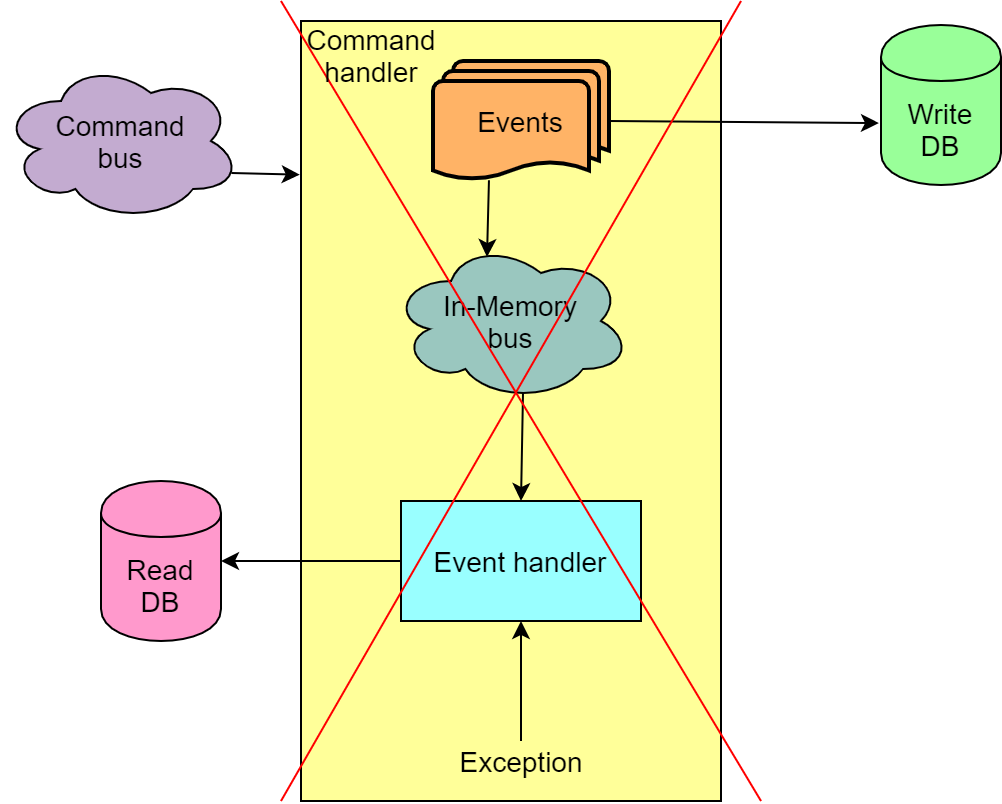
Dicha solución no contribuye a la escalabilidad, pero, por otro lado, excluimos situaciones en las que nuestra base de lectura se rompe, lo que a su vez rompe las interfaces y la continuación de la subasta sin volver a crear la base de lectura mediante la reproducción de todos los eventos se vuelve imposible.
Enviar un comando en respuesta a un evento
Esto es, en principio, apropiado, pero solo en el caso de que la falla al ejecutar este segundo comando no rompa el estado del sistema.
Manejo de múltiples eventos de un comando
En general, la ejecución de un comando da como resultado varios eventos. Sucede que para cada uno de los eventos necesitamos hacer algún cambio en la base de datos de lectura. También sucede que la secuencia de eventos también es importante, y en la secuencia incorrecta, el procesamiento de eventos no funcionará como debería. Todo esto significa que no podemos leer de la cola y procesar los eventos de un comando de forma independiente, por ejemplo, con diferentes instancias de código que lee los mensajes de la cola. Además, necesitamos una garantía de que los eventos de la cola se leerán en la misma secuencia en que fueron enviados allí. O debemos estar preparados para el hecho de que no todos los eventos de comando se procesarán con éxito en el primer intento.
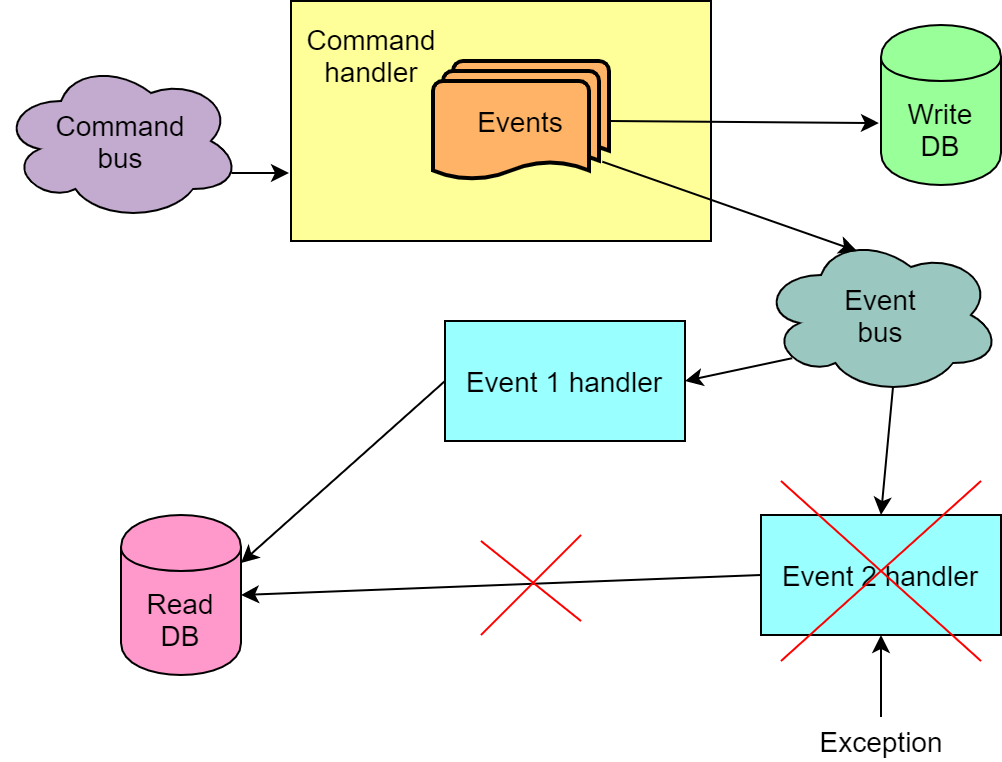
Manejando un evento con múltiples manejadores
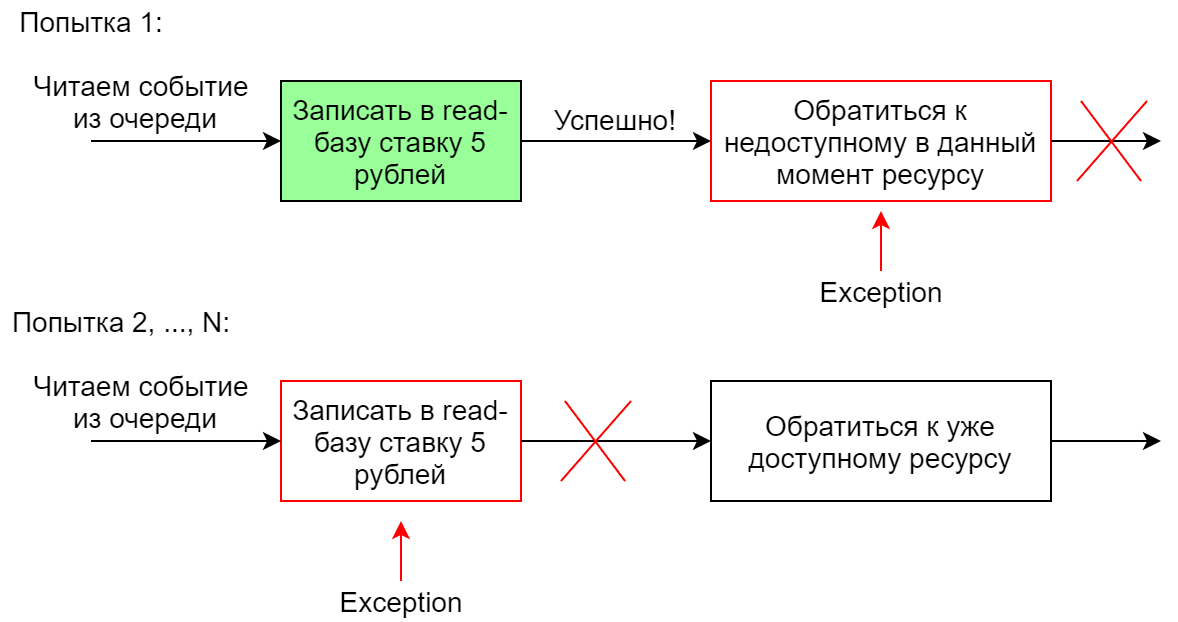
Si el sistema necesita realizar varias acciones diferentes en respuesta a un evento, generalmente se realizan varios controladores para este evento. Pueden trabajar en paralelo o secuencialmente. En el caso de un lanzamiento secuencial, si uno de los controladores falla, la secuencia completa se reinicia (este es el caso en Chinchilla). Con tal implementación, es importante que los manejadores sean idempotentes para que la segunda ejecución de un manejador ejecutado con éxito no falle. De lo contrario, cuando el segundo controlador se caiga de la cadena, definitivamente, la cadena no funcionará por completo, porque el primer controlador caerá en el segundo (y posteriores) intentos.
Por ejemplo, un controlador de eventos en la base de lectura agrega una oferta por muchos 5 rublos. El primer intento de hacer esto será exitoso, y el segundo no permitirá la ejecución de restricciones en la base de datos.
Conclusiones / Conclusión
Ahora nuestro proyecto se encuentra en una etapa en la que, como nos parece, ya hemos pisado la mayoría de los rastrillos existentes que son relevantes para nuestros detalles comerciales. En general, consideramos que nuestra experiencia es bastante exitosa, CQRS & ES es muy adecuado para nuestra área temática. El desarrollo posterior del proyecto se ve en el abandono de Chinchilla en favor de otro marco que brinde más flexibilidad. Sin embargo, también es posible negarse a usar el marco. También es probable que haya algunos cambios en la dirección de encontrar un equilibrio entre la confiabilidad por un lado y la velocidad y escalabilidad de la solución por el otro.
En cuanto al componente comercial, aquí también quedan algunas preguntas abiertas, por ejemplo, dividir el modelo de dominio en agregados.
Me gustaría esperar que nuestra experiencia sea útil para alguien, ayude a ahorrar tiempo y evite un rastrillo. Gracias por tu atención.