
Hay más de 600 pizzerías en Dodo Pizza en 13 países del mundo, y la mayoría de los procesos en pizzerías están controlados por el sistema de información Dodo IS , que nosotros mismos escribimos y mantenemos. Por lo tanto, la fiabilidad y la estabilidad del sistema son importantes para la supervivencia.
Ahora, la estabilidad y la confiabilidad del sistema de información en la compañía son respaldadas por el equipo de SRE ( Ingeniería de confiabilidad del sitio ), pero este no siempre fue el caso.
Antecedentes: mundos paralelos de desarrolladores e infraestructuras
Durante muchos años me desarrollé como un desarrollador típico de fullstack (y un poco como un scrum master), aprendí a escribir un buen código, apliqué las prácticas de Extreme Programming y reduje cuidadosamente la cantidad de WTF en los proyectos que toqué. Pero cuanto más experiencia obtuve en el desarrollo de software, más me di cuenta de la importancia de contar con sistemas confiables de monitoreo y rastreo para aplicaciones, registros de alta calidad, pruebas automáticas totales y mecanismos que garanticen una alta confiabilidad de los servicios. Y cada vez más a menudo comenzó a mirar "por encima de la cerca" al equipo de infraestructura.
Cuanto mejor entendí el entorno en el que funciona mi código, más me sorprendí: las pruebas automatizadas para todo y para todos, CI, lanzamientos frecuentes, refactorización segura y propiedad de código colectivo en el mundo del software han sido comunes y familiares durante mucho tiempo. Al mismo tiempo, en el mundo de la "infraestructura" todavía es normal carecer de pruebas automáticas, realizar cambios en los sistemas de producción en un modo semi-manual, y la documentación a menudo solo está en las cabezas de las personas, pero no en el código.
Esta división cultural y tecnológica no solo causa confusión, sino también problemas: en la intersección del desarrollo, la infraestructura y los negocios. Es difícil lidiar con algunos de los problemas en la infraestructura debido a la proximidad al hardware y las herramientas relativamente poco desarrolladas. Pero el resto puede ser derrotado si comienzas a mirar todos tus libros de jugadas Ansible y scripts Bash como un producto de software completo y les aplicas los mismos requisitos.
Triángulo de problemas de las Bermudas
Sin embargo, comenzaré desde lejos, con los problemas para los que se necesitan todos estos bailes.
Problemas de desarrollador
Hace dos años, nos dimos cuenta de que una gran cadena de pizzas no podía vivir sin su propia aplicación móvil y decidimos escribirla:
- formar un gran equipo;
- durante seis meses escribieron una aplicación conveniente y hermosa;
- respaldamos el gran lanzamiento con deliciosas promociones;
- y el primer día cayeron con seguridad bajo carga.
Hubo, por supuesto, muchos bancos de arena al principio, pero sobre todo recuerdo uno. En el momento del desarrollo, se implementó un servidor débil en producción, casi una calculadora, que procesaba las solicitudes de la aplicación. Antes del anuncio público de la aplicación, tenía que incrementarse: vivimos en Azure, y esto se resolvió con solo hacer clic en un botón.
Pero nadie presionó este botón: el equipo de infraestructura ni siquiera sabía que se estaba lanzando una aplicación hoy. Decidieron que era responsabilidad del equipo de aplicación supervisar la producción del servicio "no crítico". Y el desarrollador de back-end (este fue su primer proyecto en Dodo) decidió que los chicos de la infraestructura lo están haciendo en grandes empresas.
Ese desarrollador era yo. Luego deduje por mí mismo una regla obvia pero importante:
, , , . .
No es difícil ahora. En los últimos años, han aparecido una gran cantidad de herramientas que permiten a los programadores mirar el mundo de la explotación y no romper nada: Prometheus, Zipkin, Jaeger, ELK stack, Kusto.
Sin embargo, muchos desarrolladores todavía tienen serios problemas con los llamados infraestructura / DevOps / SRE. Como resultado, los programadores:
dependen del equipo de infraestructura. Esto causa dolor, malentendidos, a veces odio mutuo.
Diseñan sus sistemas aislados de la realidad y no tienen en cuenta dónde y cómo se ejecutará su código. Por ejemplo, la arquitectura y el diseño de un sistema que se está desarrollando para la vida en la nube diferirá del de un sistema alojado en las instalaciones.
No entienden la naturaleza de los errores y problemas asociados con su código.Esto es especialmente notable cuando los problemas están relacionados con la carga, el equilibrio de consultas, el rendimiento de la red o el disco duro. Los desarrolladores no siempre tienen este conocimiento.
No pueden optimizar el dinero y otros recursos de la empresa que se utilizan para mantener su código. En nuestra experiencia, sucede que el equipo de infraestructura simplemente llena el problema con dinero, por ejemplo, aumentando el tamaño del servidor de base de datos en producción. Por lo tanto, los problemas de código a menudo ni siquiera llegan a los programadores. Solo por alguna razón, la infraestructura está comenzando a costar más.
Problemas de infraestructura
También hay dificultades "en el otro lado".
Es difícil administrar docenas de servicios y entornos sin un código de calidad. Actualmente tenemos más de 450 repositorios en GitHub. Algunos de ellos no requieren soporte operativo, algunos están muertos y guardados para el historial, pero una parte importante contiene servicios que deben ser compatibles. Necesitan hospedarse en algún lugar, necesitan monitoreo, recopilar registros, tuberías de CI / CD uniformes.
Para gestionar todo esto, recientemente utilizamos activamente Ansible. Nuestro repositorio Ansible contenía:
- 60 roles;
- 102 libros de jugadas;
- enlace en Python y Bash;
- Pruebas manuales en Vagrant.
Todo fue escrito por una persona inteligente y bien escrito. Pero, tan pronto como otros desarrolladores de la infraestructura y programadores comenzaron a trabajar activamente con este código, resultó que los libros de jugadas se rompen, y los roles se duplican y "se cubren de musgo".
La razón era que este código no usaba muchas prácticas estándar en el mundo del desarrollo de software. No tenía una canalización de CI / CD, y las pruebas eran complejas y lentas, por lo que todos eran demasiado flojos o "no tenían tiempo" para ejecutarlos manualmente, y aún más escribían otros nuevos. Dicho código está condenado si más de una persona está trabajando en él.
Sin el conocimiento del código, es difícil responder eficazmente a los incidentes.Cuando llega una alerta a PagerDuty a las 3 am, debe buscar un programador que le explique qué y cómo. Por ejemplo, que estos errores 500 afectan al usuario, mientras que otros están relacionados con el servicio secundario, los clientes finales no lo ven y puede dejarlo así hasta la mañana. Pero a las tres de la mañana es difícil despertar a los programadores, por lo que es recomendable comprender cómo funciona el código que admite.
Muchas herramientas requieren incrustación en el código de la aplicación. Los chicos de la infraestructura saben qué monitorear, cómo iniciar sesión y a qué cosas prestar atención para el rastreo. Pero a menudo no pueden incrustar todo esto en el código de la aplicación. Y los que pueden, no saben qué y cómo incrustar.
"Teléfono roto".Explicar qué y cómo monitorear por centésima vez es desagradable. Es más fácil escribir una biblioteca compartida para pasar a los programadores para su reutilización en sus aplicaciones. Pero para esto necesita poder escribir código en el mismo idioma, con el mismo estilo y con los mismos enfoques que utilizan los desarrolladores de sus aplicaciones.
Problemas de negocios
El negocio también tiene dos grandes problemas que deben abordarse.
Pérdidas directas de la inestabilidad del sistema asociadas con la confiabilidad y disponibilidad.
En 2018, tuvimos 51 incidentes críticos, y los elementos críticos del sistema no funcionaron durante más de 20 horas. En términos monetarios, se trata de 25 millones de rublos de pérdidas directas debido a pedidos no entregados y no entregados. Y cuánto hemos perdido en la confianza de los empleados, clientes y franquiciados es imposible de calcular, no está valorado en dinero.
Costos actuales de soporte de infraestructura. Al mismo tiempo, la compañía nos fijó una meta en 2018: reducir los costos de infraestructura en 3 veces en términos de una pizzería. Pero ni los programadores ni los ingenieros de DevOps dentro de sus equipos podrían siquiera acercarse a resolver este problema. Hay razones para esto:
- , ;
- , operations ( DevOps), ;
- , .
?
¿Cómo resolver todos estos problemas? Encontramos la solución en el libro "Site Reliability Engineering" de Google. Cuando leemos, entendimos: esto es lo que necesitamos.
Pero hay un matiz: lleva años implementar todo esto, y hay que comenzar en alguna parte. Considere los datos iniciales que teníamos inicialmente.
Toda nuestra infraestructura vive casi por completo en Microsoft Azure. Existen varios grupos independientes de ventas que se distribuyen en diferentes continentes: Europa, América y China. Hay puestos de carga que repiten la producción, pero viven en un entorno aislado, así como docenas de entornos DEV para equipos de desarrollo.
De las buenas prácticas de SRE que ya teníamos:
- mecanismos para monitorear aplicaciones e infraestructura (spoiler: en 2018 pensamos que eran buenos, pero ahora ya hemos reescrito todo);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
Pero había problemas que quería resolver en primer lugar:
el equipo de infraestructura estaba sobrecargado. No hubo suficiente tiempo y esfuerzo para mejoras globales debido al sistema operativo actual. Por ejemplo, quisimos durante mucho tiempo, pero no pudimos deshacernos de Elasticsearch en nuestra pila, o duplicar la infraestructura de otro proveedor de la nube para evitar riesgos (aquí aquellos que ya lo han intentado en varias nubes pueden reírse).
Caos en el código. El código de infraestructura era caótico, disperso en diferentes repositorios y no estaba documentado en ninguna parte. Todo se basó en el conocimiento de los individuos y nada más. Este fue un gigantesco problema de gestión del conocimiento.
"Hay programadores y hay ingenieros de infraestructura".A pesar de que teníamos una cultura DevOps bastante bien desarrollada, todavía existía esta separación. Dos clases de personas con experiencias completamente diferentes que hablan diferentes idiomas y usan diferentes herramientas. Ellos, por supuesto, son amigos y se comunican, pero a menudo no se entienden debido a experiencias completamente diferentes.
Equipos de incorporación de SRE
Para resolver estos problemas y de alguna manera comenzar a avanzar hacia SRE, lanzamos un proyecto de incorporación. Solo que no fue una incorporación clásica: capacitación de nuevos empleados (recién llegados) para agregar personas al equipo actual. Fue la creación de un nuevo equipo de ingenieros y programadores de infraestructura: el primer paso hacia una estructura SRE completa.
Asignamos 4 meses al proyecto y establecimos tres objetivos:
- Capacite a los programadores en los conocimientos y habilidades que son necesarios para las actividades operativas y de servicio en el equipo de infraestructura.
- Escriba IaC : una descripción de toda la infraestructura en el código. Y debería ser un producto de software completo con CI / CD, pruebas.
- Vuelva a crear toda nuestra infraestructura a partir de este código y olvídese de hacer clic manualmente en máquinas virtuales con un mouse en Azure.
Participantes: 9 personas, 6 de ellas del equipo de desarrollo, 3 de la infraestructura. Durante 4 meses tuvieron que abandonar el trabajo normal y sumergirse en las tareas designadas. Para respaldar la “vida” en los negocios, otras 3 personas de la infraestructura permanecieron de servicio, participaron en sistemas operativos y cubrieron la parte trasera. Como resultado, el proyecto se extendió notablemente y tomó más de cinco meses (de mayo a octubre de 2019).
Dos componentes de la incorporación: capacitación y práctica.
La incorporación consistió en dos partes: capacitación y trabajo en infraestructura en código.
Formación. Se asignaron al menos 3 horas al día para capacitación:
- para leer artículos y libros de la lista de referencias: Linux, redes, SRE;
- en conferencias sobre herramientas y tecnologías específicas;
- a clubes de tecnología, como Linux, donde analizamos casos y casos complejos.
Otra herramienta de aprendizaje es la demostración interna. Esta es una reunión semanal donde todos (que tienen algo que decir) durante 10 minutos hablaron sobre una tecnología o concepto que implementó en nuestro código para la semana. Por ejemplo, Vasya cambió la tubería para trabajar con módulos Terraform, y Petya reescribió el ensamblaje de la imagen usando Packer.
Después de la demostración, comenzamos las discusiones sobre cada tema en Slack, donde los participantes interesados podían discutir todo de forma asincrónica con más detalle. Así que evitamos largas reuniones para 10 personas, pero al mismo tiempo todos en el equipo entendieron bien lo que estaba sucediendo con nuestra infraestructura y hacia dónde íbamos.

Práctica. La segunda parte de la incorporación es crear / describir la infraestructura en código . Esta parte se dividió en varias etapas.
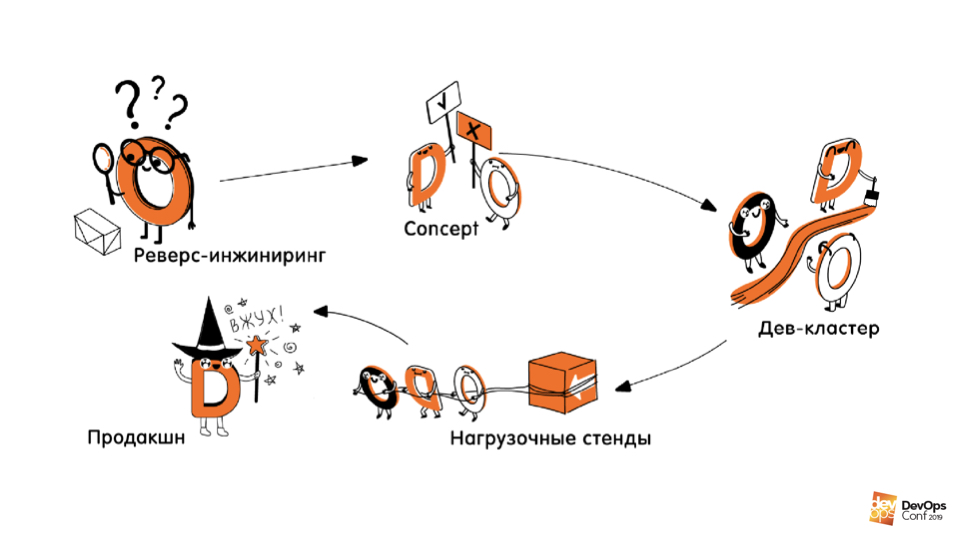
Ingeniería inversa de infraestructura.Esta es la primera etapa en la que descubrimos dónde está arreglado, cómo funciona, dónde funcionan los servicios, dónde qué máquinas y sus tamaños. Todo estaba completamente documentado.
Conceptos. Experimentamos con diferentes tecnologías, lenguajes, enfoques, descubrimos cómo podemos describir nuestra infraestructura, qué herramientas deberían usarse para esto.
Código de ortografía Esto incluía escribir el código en sí, crear canalizaciones de CI / CD, pruebas y crear procesos a su alrededor. Escribimos un código que describía y sabía cómo crear nuestra infraestructura de virgo desde cero.
Reconstrucción de stands para pruebas de carga y producción.Esta es la cuarta etapa, que se suponía que iba después de la incorporación, pero se ha pospuesto por ahora, ya que el beneficio de ella, por extraño que parezca, es mucho menor que el de los entornos de desarrollo que se crean / recrean con mucha frecuencia.
En cambio, cambiamos a las actividades del proyecto: nos dividimos en pequeños sub-equipos y abordamos los proyectos de infraestructura global que nunca habíamos tenido. Y, por supuesto, nos unimos al reloj.
Nuestras herramientas para IaC
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Prácticas de programación extremas en infraestructura
Lo principal que nosotros, como programadores, trajimos con nosotros son las prácticas de Programación Extrema que usamos en nuestro trabajo. XP es una metodología de desarrollo de software ágil que combina una combinación de los mejores enfoques, prácticas y valores de desarrollo.
No hay un solo programador que no haya utilizado al menos algunas de las prácticas de Programación Extrema, incluso si no lo sabe. Al mismo tiempo, en el mundo de la infraestructura, estas prácticas se omiten, a pesar de que se superponen en gran medida con las prácticas de Google SRE.
Hay un artículo separado sobre cómo adaptamos XP para la infraestructura .. En pocas palabras: las prácticas de XP funcionan para el código de infraestructura, aunque con restricciones, adaptaciones, pero funcionan. Si desea aplicarlos en casa, invite a personas con experiencia en la aplicación de estas prácticas. La mayoría de estas prácticas se describen de una forma u otra en el mismo libro sobre SRE .
Todo podría haber funcionado bien, pero no funciona.
Problemas técnicos y antropogénicos en camino
Hubo dos tipos de problemas dentro del proyecto:
- Técnico : limitaciones del mundo "de hierro", falta de conocimiento y herramientas en bruto que tuvieron que ser utilizadas porque no hay otras. Estos son problemas comunes para cualquier programador.
- Humano : la interacción de las personas en un equipo. Comunicación, toma de decisiones, formación. Con esto fue peor, por lo que debemos pensar con más detalle.
Comenzamos a desarrollar el equipo de incorporación como lo haríamos con cualquier otro equipo de programación. Esperábamos que habría las etapas habituales de construir un equipo de Takman : tormenta, normalización, y al final iremos a la productividad y al trabajo productivo. Por lo tanto, no nos preocupaba que al principio hubiera algunas dificultades en la comunicación, la toma de decisiones, dificultades para llegar a un acuerdo.
Pasaron dos meses, pero la fase de tormenta continuó. Solo hacia el final del proyecto nos dimos cuenta de que todos los problemas con los que estábamos luchando y que no percibíamos que estaban relacionados entre sí eran el resultado de un problema raíz común: dos grupos de personas completamente diferentes se unieron en el equipo:
- Programadores experimentados con años de experiencia para los cuales desarrollaron sus enfoques, hábitos y valores en el trabajo.
- Otro grupo del mundo de la infraestructura con experiencia propia. Tienen protuberancias diferentes, hábitos diferentes y también piensan que saben cómo vivir bien.
Hubo un choque de dos puntos de vista sobre la vida en un equipo. No vimos esto de inmediato y no comenzamos a trabajar con él, como resultado de lo cual perdimos mucho tiempo, fuerza y nervios.
Pero esta colisión no se puede evitar. Si llama al proyecto programadores fuertes e ingenieros de infraestructura débiles, entonces tendrá un intercambio de conocimiento unidireccional. Por el contrario, tampoco funciona: algunos se tragan a otros y eso es todo. Y necesita obtener algún tipo de mezcla, por lo que debe estar preparado para el hecho de que la "molienda" puede ser muy larga (en nuestro caso, pudimos estabilizar el equipo solo un año después, mientras nos despedíamos de uno de los ingenieros técnicamente más fuertes).
Si quieres formar un equipo así, no olvides llamar a un entrenador ágil fuerte, scrum master o psicoterapeuta, lo que más te guste. Quizás ellos ayuden.
Resultados de la incorporación
Según los resultados del proyecto de incorporación (finalizó en octubre de 2019), nosotros:
- Hemos creado un producto de software completo que gestiona nuestra infraestructura DEV, con su propia tubería de CI, pruebas y otros atributos de un producto de software de calidad.
- Duplicamos el número de personas que están listas para estar de servicio y le quitamos la carga al equipo actual. Seis meses después, estas personas se convirtieron en SRE de pleno derecho. Ahora pueden apagar un incendio en el mercado, consultar a un equipo de programadores en NTF o escribir su propia biblioteca para desarrolladores.
- SRE. , , .
- : , , , .
: ,
Varias ideas del desarrollador. No pises nuestro rastrillo, sálvate a ti mismo y a los que te rodean nervios y tiempo.
La infraestructura es cosa del pasado. Cuando estaba en mi primer año (hace 15 años) y comencé a aprender JavaScript, tenía NotePad ++ y Firebug para la depuración de mis herramientas. Incluso entonces, era necesario hacer algunas cosas complejas y hermosas con estas herramientas.
Casi de la misma manera que me siento ahora cuando trabajo con infraestructura. Las herramientas actuales solo se están formando, muchas de ellas aún no se han lanzado y tienen la versión 0.12 (hola, Terraform), y muchas veces rompen la compatibilidad con versiones anteriores.
Para mí, como desarrollador empresarial, es absurdo usar tales cosas en la producción. Pero simplemente no hay otros.
Lee la documentación.Como programador, rara vez accedía a muelles. Conocía mis herramientas bastante profundamente: mi lenguaje de programación favorito, mi marco y base de datos favoritos. Todas las herramientas adicionales, por ejemplo, las bibliotecas, generalmente están escritas en el mismo idioma, lo que significa que siempre puede mirar la fuente. El IDE siempre le dirá qué parámetros son necesarios y dónde. Incluso si me equivoco, lo entenderé rápidamente al ejecutar pruebas rápidas.
Esto no funcionará en infraestructura, hay una gran cantidad de tecnologías diferentes que necesita saber. Pero es imposible saber todo profundamente, y mucho está escrito en idiomas desconocidos. Por lo tanto, lea cuidadosamente (y escriba) la documentación; no vivirán aquí por mucho tiempo sin este hábito.
Los comentarios del código de infraestructura son inevitables.En el mundo del desarrollo, los comentarios son una señal de mal código. Rápidamente se vuelven obsoletos y comienzan a mentir. Esta es una señal de que el desarrollador no pudo expresar sus pensamientos de otra manera. Cuando se trabaja con infraestructura, los comentarios también son un signo de código incorrecto, pero no puede prescindir de ellos. Para las herramientas dispares que están conectadas entre sí y no saben nada el uno del otro, el comentario es indispensable.
A menudo, bajo el código, las configuraciones normales y DSL están ocultas. En este caso, toda la lógica tiene lugar en algún lugar más profundo donde no hay acceso. Esto cambia enormemente el enfoque del código, probando y trabajando con él.
No tenga miedo de dejar que los desarrolladores entren en la infraestructura.Pueden aportar prácticas y enfoques útiles (y frescos) del mundo del desarrollo de software. Utilice las prácticas y enfoques de Google, descritos en el libro sobre SRE, benefíciese y sea feliz.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .