
Tomaremos como base los scripts del Apéndice B: Ejemplo de gráfico de mitología griega de la documentación de referencia de gráficos de SAP HANA para una plataforma típica de SAP HANA que se implementa localmente en el centro de datos. El objetivo principal de este ejemplo es mostrar las capacidades analíticas de SAP HANA, para mostrar cómo puede analizar la relación de objetos y eventos utilizando algoritmos gráficos. No nos detendremos en esta tecnología en detalle, la idea principal quedará clara en la presentación posterior. Cualquier persona interesada puede resolverlo por sí mismo probando las capacidades de la edición express de SAP HANA o tomando un curso gratuito Analizando datos conectados con SAP HANA Graph .
Coloquemos los datos en la nube relacional de SAP HANA Cloud y veamos las posibilidades para analizar el parentesco de los héroes griegos. Recuerde, en "Mitos y leyendas de la antigua Grecia" había muchos personajes y en el medio ya no recuerda quién es de quién hijo y hermano. Aquí nos haremos un memo y nunca lo olvidaremos.
Primero, creemos una instancia de SAP HANA Cloud. Es bastante simple hacer esto, debe completar los parámetros del sistema futuro y esperar unos minutos para que se implemente la instancia (Fig. 1).

Figura 1
Por lo tanto, hacemos clic en el botón Crear instancia y se nos presenta la primera página del asistente de creación, en la que debemos indicar el nombre corto de la instancia, establecer la contraseña y dar una descripción (Fig. 2)
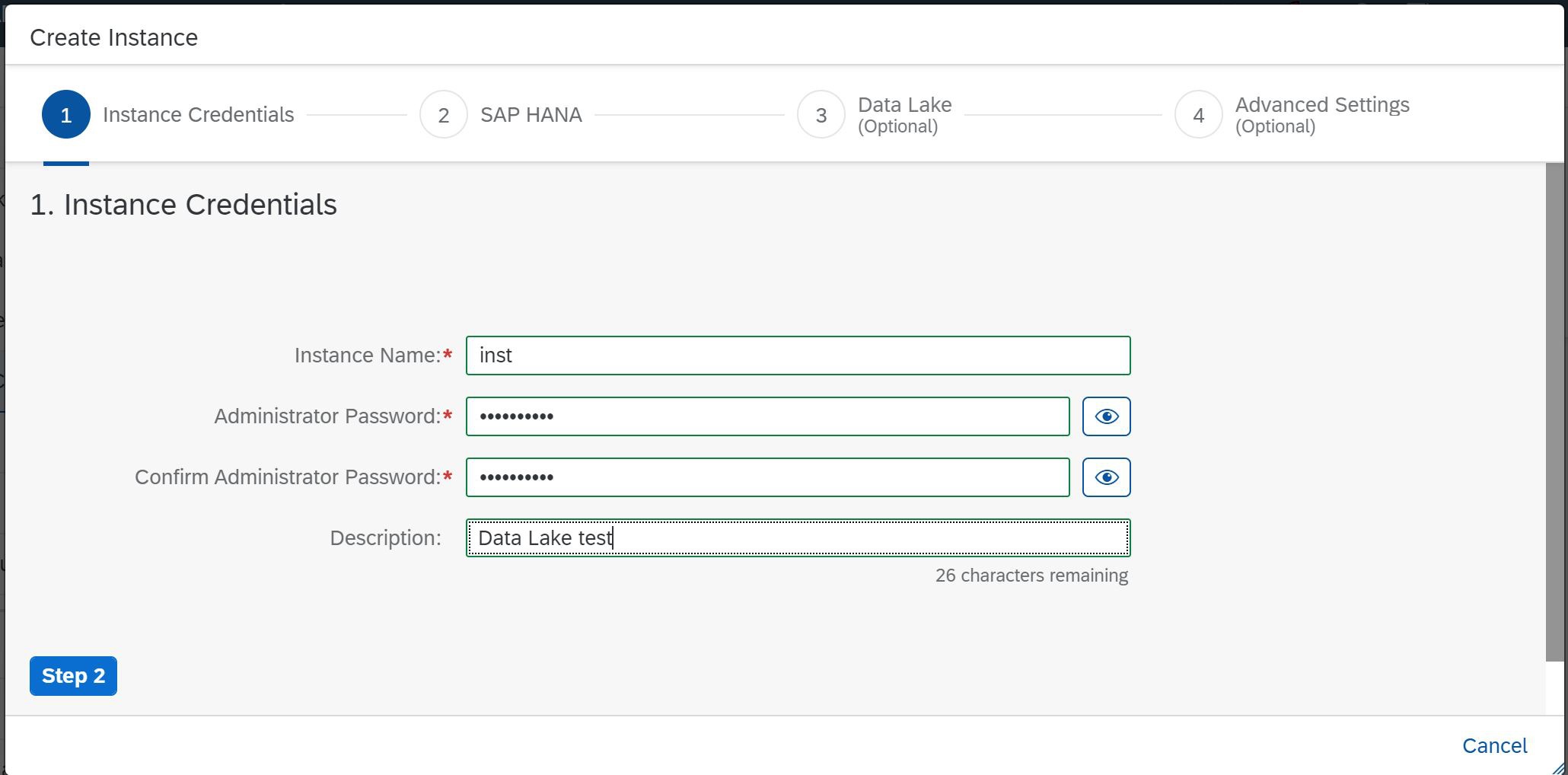
Figura 2
Haga clic en el botón Paso 2, ahora nuestra tarea es especificar los parámetros de la futura instancia de SAP HANA. Aquí solo puede establecer el tamaño de la RAM del sistema futuro, todos los demás parámetros se determinarán automáticamente (Fig. 3).

Figura 3
Vemos que ahora tenemos la oportunidad de elegir el valor mínimo de 30 GB y el máximo de 900 GB. Seleccionamos 30 GB y se determina automáticamente que con esta cantidad de memoria, se necesitan dos procesadores virtuales para admitir cálculos y 120 GB para almacenar datos en el disco. Aquí se asigna más espacio, ya que podemos usar la tecnología SAP HANA Native Storage Extension (NSE). Si elige un tamaño de memoria más grande, por ejemplo, 255 GB, necesitará 17 procesadores virtuales y 720 GB de memoria de disco (Fig. 4).
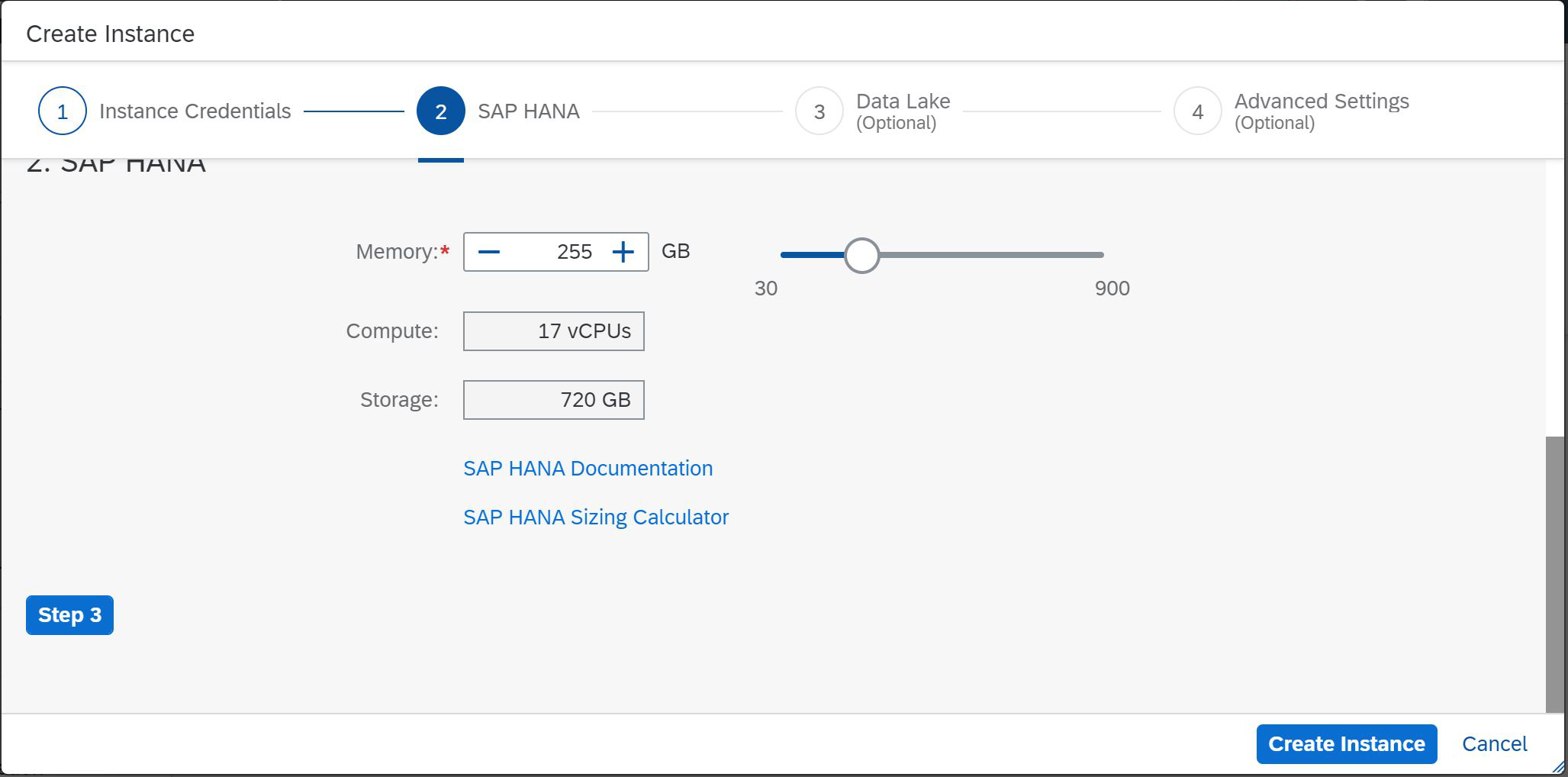
Figura 4
Pero no necesitamos tanta memoria como ejemplo. Devolvemos los parámetros a sus valores originales y hacemos clic en el Paso 3. Ahora debemos elegir si usar el lago de datos. La respuesta es obvia para nosotros. Claro que lo haremos. También queremos llevar a cabo tal experimento (Fig. 5).

Figura 5
En este paso, tenemos muchas más oportunidades y libertad para crear una instancia del lago de datos. Puede elegir el tamaño de los recursos informáticos necesarios y el almacenamiento en disco. Los parámetros de los componentes / nodos utilizados se seleccionarán automáticamente. El sistema determinará los recursos informáticos necesarios para los nodos "coordinador" y "funcional". Si desea obtener más información sobre estos componentes, es mejor recurrir a los recursos de SAP IQ y al lago de datos SAP HANA Cloud .... Y seguimos, haga clic en el Paso 4.
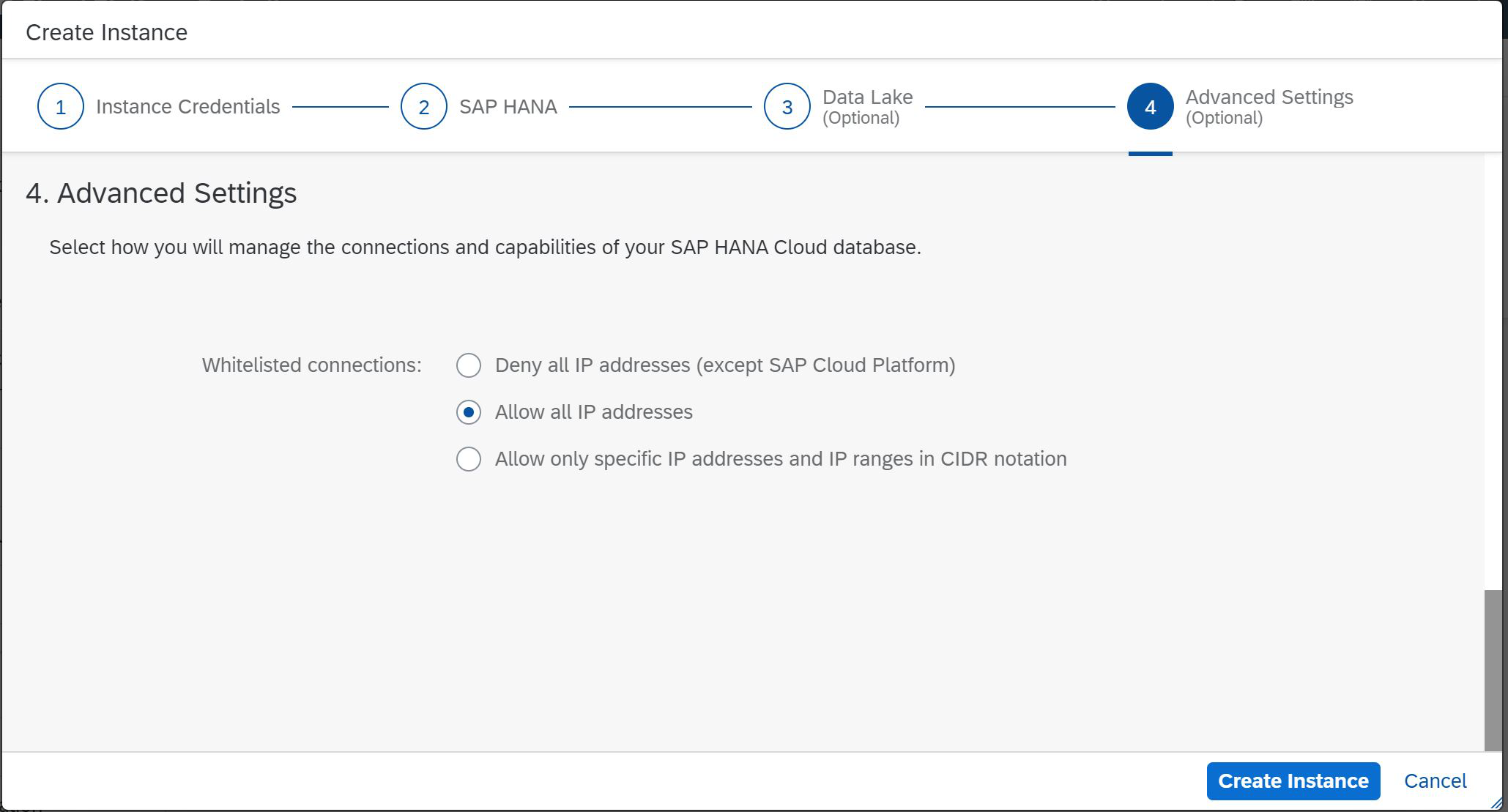
Figura 6
En este paso, determinaremos o restringiremos las direcciones IP que pueden acceder a la instancia futura de SAP HANA. Como puede ver, este es el último paso de nuestro maestro (Fig. 6), queda hacer clic en Crear instancia e ir a servirse café.

Figura 7
El proceso se inicia (Fig. 7) y pasará muy poco tiempo, solo tuvimos tiempo de tomar café fuerte, a pesar de la noche. ¿Y cuándo más puedes experimentar con calma con el sistema y atornillar diferentes chips? Entonces, nuestro sistema es creado (Fig. 8).

Figura 8
Tenemos dos opciones: abrir SAP HANA Cockpit o SAP HANA Database Explorer. Sabemos que el segundo producto se puede lanzar desde Cockpit. Por lo tanto, abrimos SAP HANA Cockpit, al mismo tiempo, y vemos qué hay allí. Pero primero, deberá proporcionar un usuario y su contraseña. Tenga en cuenta que el usuario del SISTEMA no está disponible para usted, debe usar DBADMIN. En este caso, especifique la contraseña que estableció al crear la instancia, como en la Fig.9.
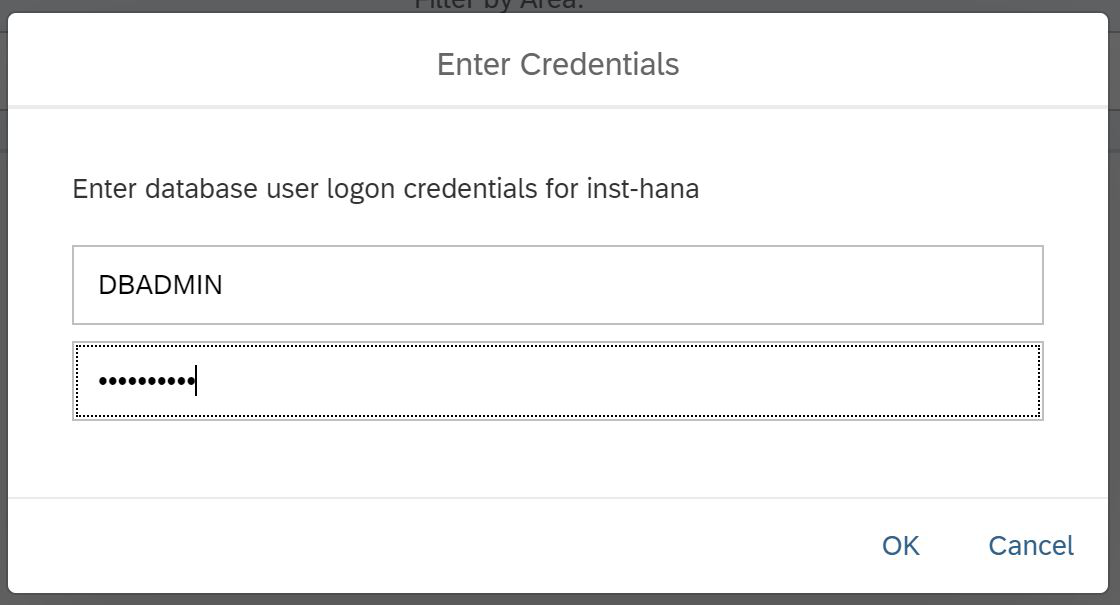
Figura 9
Entramos en Cockpit y vemos la interfaz tradicional de SAP en forma de mosaicos, cuando cada uno de ellos es responsable de su tarea. En la esquina superior derecha vemos un enlace a la Consola SQL (Fig. 10).
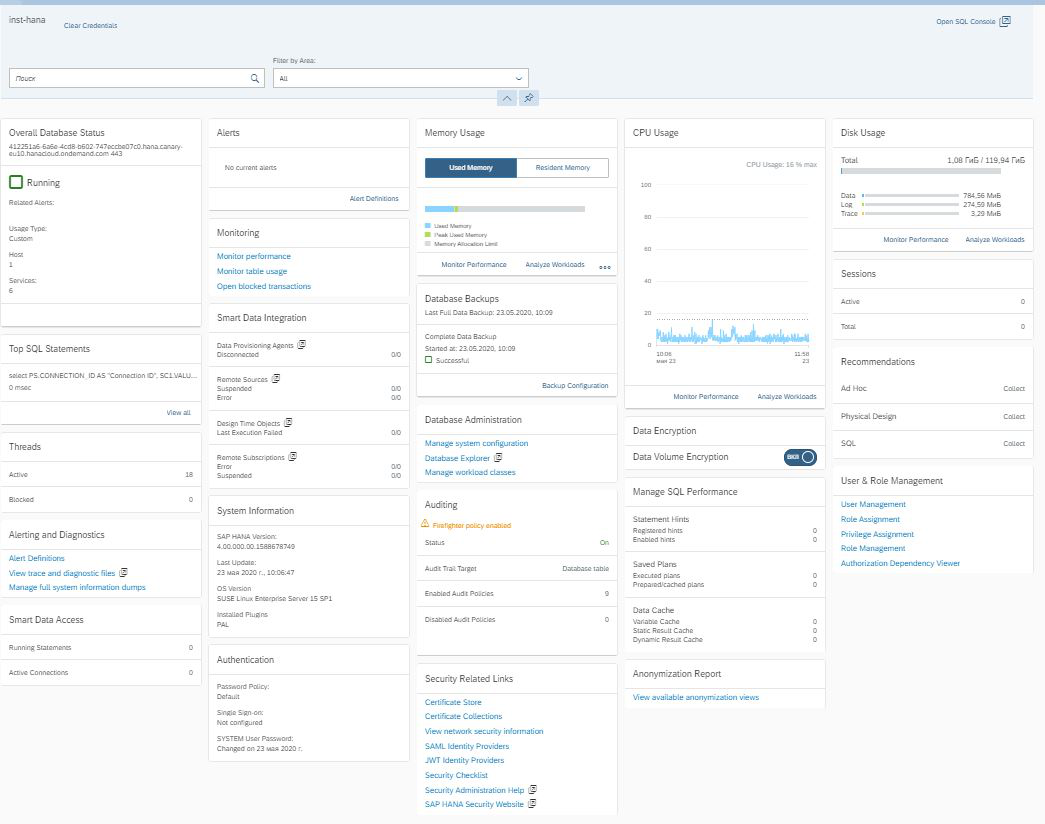
Figura 10
Es ella quien nos permite ir al Explorador de bases de datos SAP HANA.
La interfaz de esta herramienta es similar a SAP Web IDE, pero solo para trabajar con objetos de base de datos. En primer lugar, por supuesto, estamos interesados en cómo ingresar al lago de datos. Después de todo, ahora hemos abierto una herramienta para trabajar con HANA. Vayamos al elemento Fuente remota en el navegador y veamos un enlace al lago (SYSRDL, RDL - Lago de datos de relación). Este es el acceso deseado (Fig. 11).

Figura 11
Continuando, no tenemos que trabajar bajo un administrador. Necesitamos crear un usuario de prueba, bajo el cual realizaremos un experimento con el motor gráfico HANA, pero colocaremos los datos en un lago de datos relacionales.
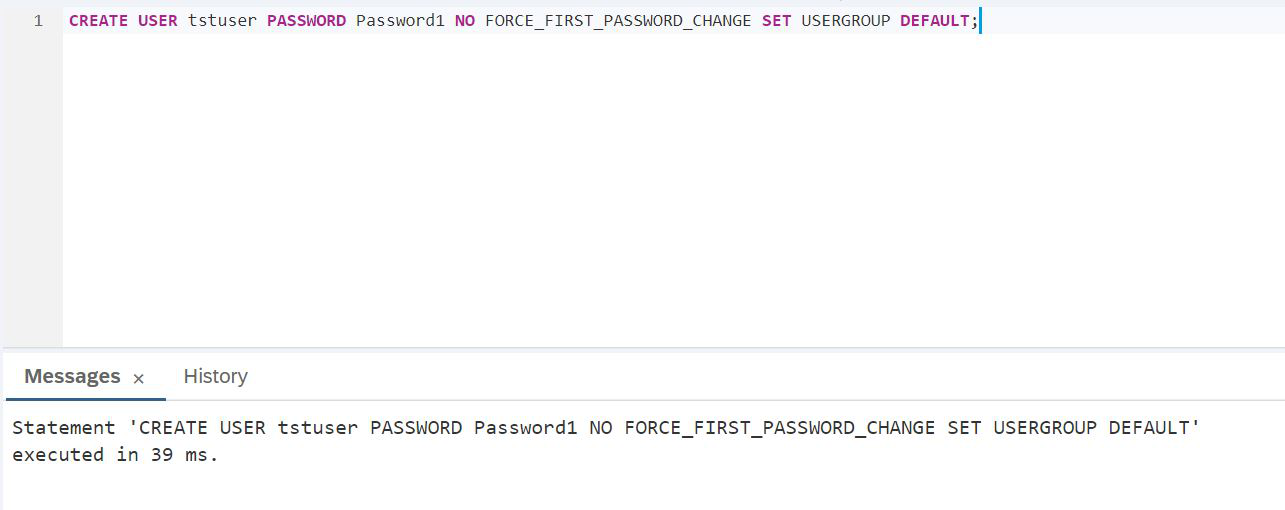
GUIÓN:
CREATE USER tstuser PASSWORD Password1 NO FORCE_FIRST_PASSWORD_CHANGE SET USERGROUP DEFAULT;Planeamos trabajar con un lago de datos, por lo que definitivamente debe otorgar derechos, por ejemplo, HANA_SYSRDL # CG_ADMIN_ROLE, para que pueda crear objetos libremente y hacer lo que quiera.
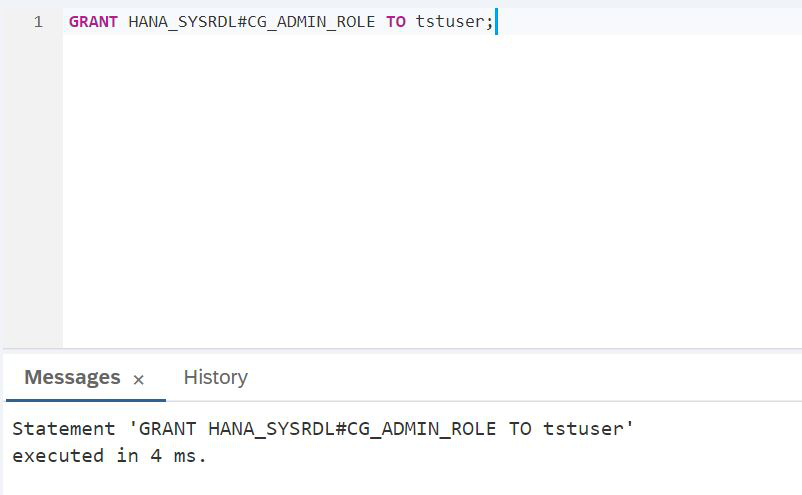
GUIÓN:
GRANT HANA_SYSRDL#CG_ADMIN_ROLE TO tstuser;Ahora que el trabajo bajo el administrador de SAP HANA está completo, el Explorador de base de datos de SAP HANA puede cerrarse y necesitamos iniciar sesión con el nuevo usuario creado: tstuser. Por simplicidad, regresemos a SAP HANA Cockpit y finalicemos la sesión de administración. Para hacer esto, en la esquina superior izquierda hay un enlace Borrar credenciales (Fig. 12).

Figura 12
Después de hacer clic en él, necesitamos iniciar sesión nuevamente, pero ahora bajo el usuario tstuser (Figura 13).
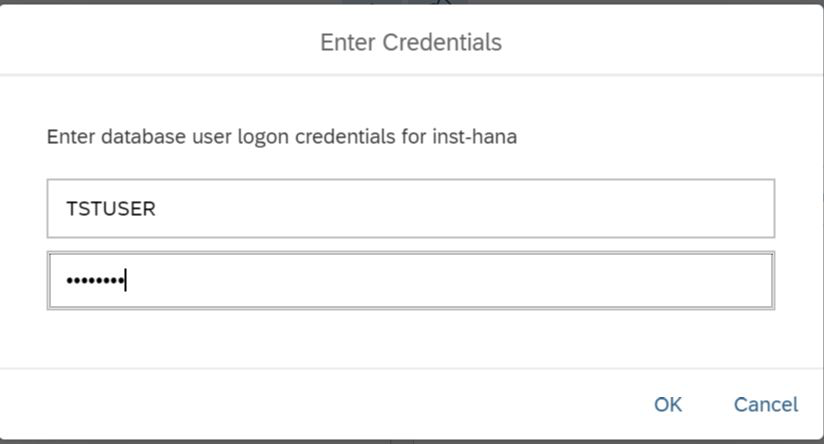
Figura 13
Y podemos abrir nuevamente la Consola SQL para volver al Explorador de base de datos SAP HANA, pero bajo un nuevo usuario (Figura 14).

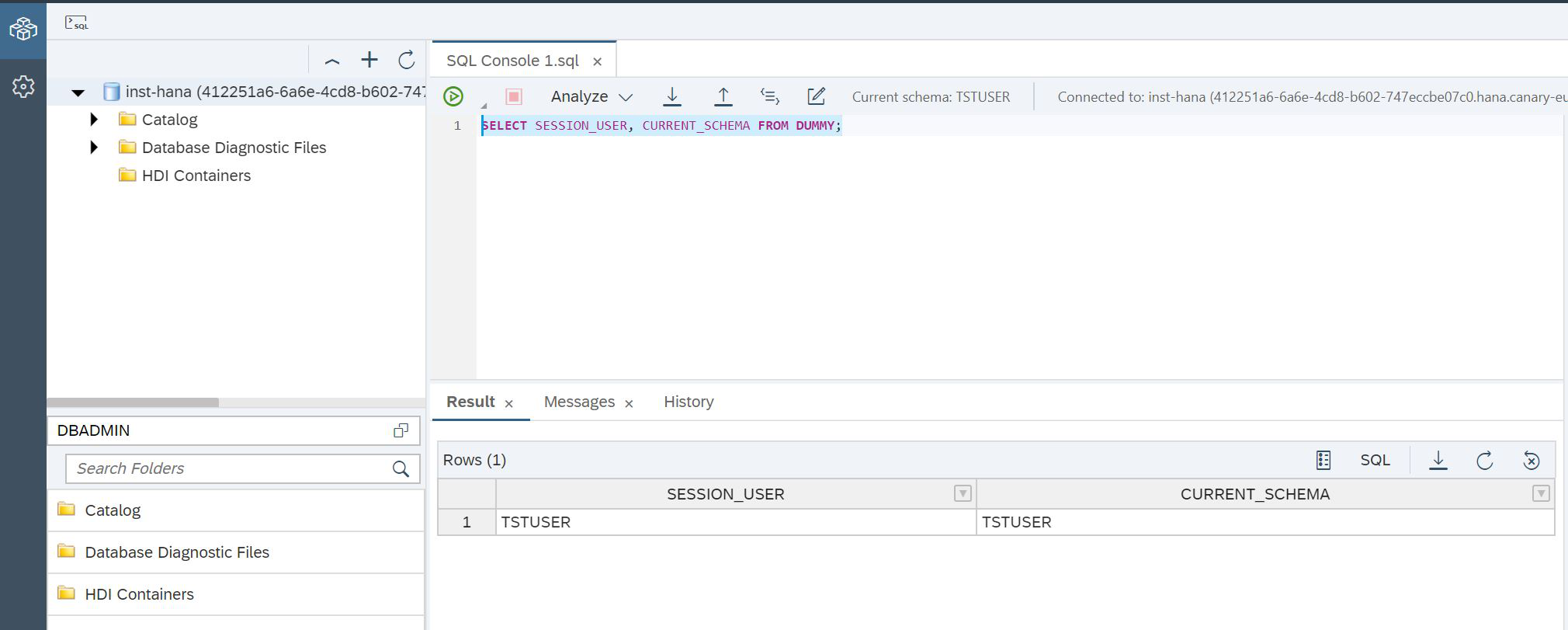
Figura 14
SCRIPT:
SELECT SESSION_USER, CURRENT_SCHEMA FROM DUMMY;Eso es todo, ahora estamos seguros de que estamos trabajando con HANA bajo el usuario correcto. Es hora de crear tablas en el lago de datos. Para hacer esto, hay un procedimiento especial SYSRDL # CG.REMOTE_EXECUTE, en el que debe pasar un parámetro: línea = comando. Con esta función, creamos una tabla en el lago de datos (Fig. 15), que almacenará todos nuestros personajes: héroes, dioses griegos y titanes.

Figura 15
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "MEMBERS" (
"NAME" VARCHAR(100) PRIMARY KEY,
"TYPE" VARCHAR(100),
"RESIDENCE" VARCHAR(100)
);
END');Y luego creamos una tabla en la que almacenaremos las relaciones de estos personajes (Fig. 16).

Figura 16
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "RELATIONSHIPS" (
"KEY" INTEGER UNIQUE NOT NULL,
"SOURCE" VARCHAR(100) NOT NULL,
"TARGET" VARCHAR(100) NOT NULL,
"TYPE" VARCHAR(100),
FOREIGN KEY RELATION_SOURCE ("SOURCE") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT,
FOREIGN KEY RELATION_TARGET ("TARGET") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT
);
END');No trataremos los problemas de integración ahora, esta es una historia separada. El ejemplo original contiene comandos INSERT para crear los dioses griegos y su parentesco. Usamos estos comandos. Solo necesita recordar que pasamos el comando a través del procedimiento al lago de datos, por lo que debemos duplicar las comillas, como se muestra en la figura 17.

Figura 17
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Chaos'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Gaia'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Uranus'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Rhea'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Cronus'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Zeus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Poseidon'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hades'', ''god'', ''Underworld'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hera'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Demeter'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Athena'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Ares'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Aphrodite'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hephaestus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Persephone'', ''god'', ''Underworld'');
END');Y la segunda tabla (Fig. 18)
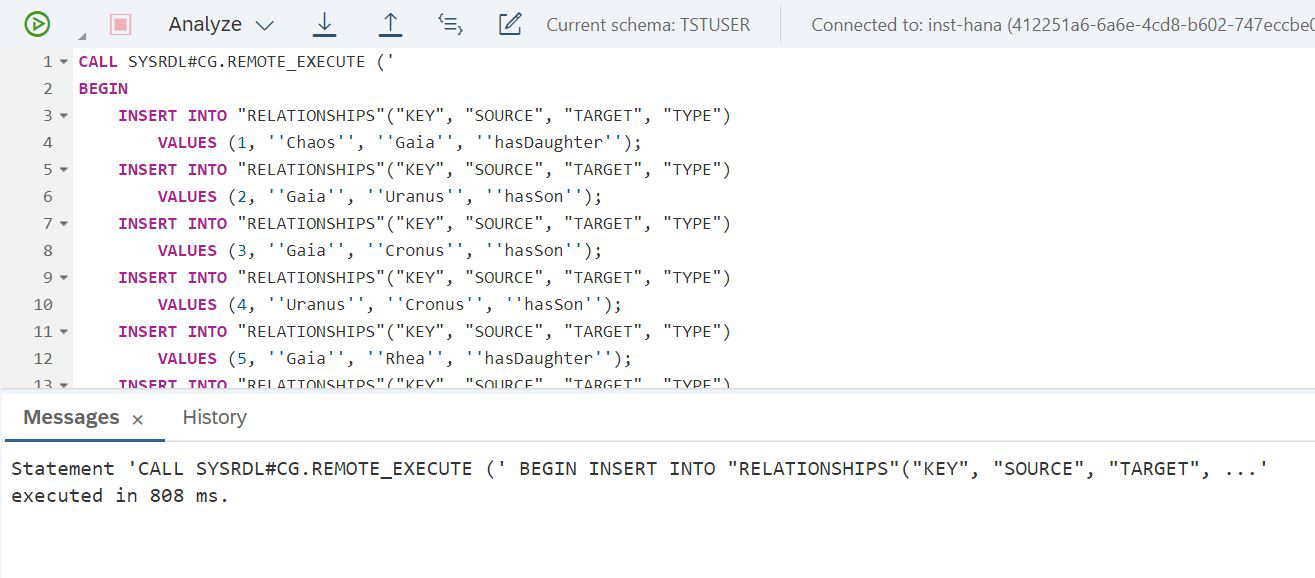
Figura 18
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (1, ''Chaos'', ''Gaia'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (2, ''Gaia'', ''Uranus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (3, ''Gaia'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (4, ''Uranus'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (5, ''Gaia'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (6, ''Uranus'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (7, ''Cronus'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (8, ''Rhea'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (9, ''Cronus'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (10, ''Rhea'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (11, ''Cronus'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (12, ''Rhea'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (13, ''Cronus'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (14, ''Rhea'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (15, ''Cronus'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (16, ''Rhea'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (17, ''Zeus'', ''Athena'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (18, ''Zeus'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (19, ''Hera'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (20, ''Uranus'', ''Aphrodite'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (21, ''Zeus'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (22, ''Hera'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (23, ''Zeus'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (24, ''Demeter'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (25, ''Zeus'', ''Hera'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (26, ''Hera'', ''Zeus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (27, ''Hades'', ''Persephone'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (28, ''Persephone'', ''Hades'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (29, ''Aphrodite'', ''Hephaestus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (30, ''Hephaestus'', ''Aphrodite'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (31, ''Cronus'', ''Rhea'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (32, ''Rhea'', ''Cronus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (33, ''Uranus'', ''Gaia'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (34, ''Gaia'', ''Uranus'', ''marriedTo'');
END');Ahora abra Remote Source nuevamente. Necesitamos crear tablas virtuales en HANA basadas en la descripción de las tablas en el lago de datos (Fig. 19).
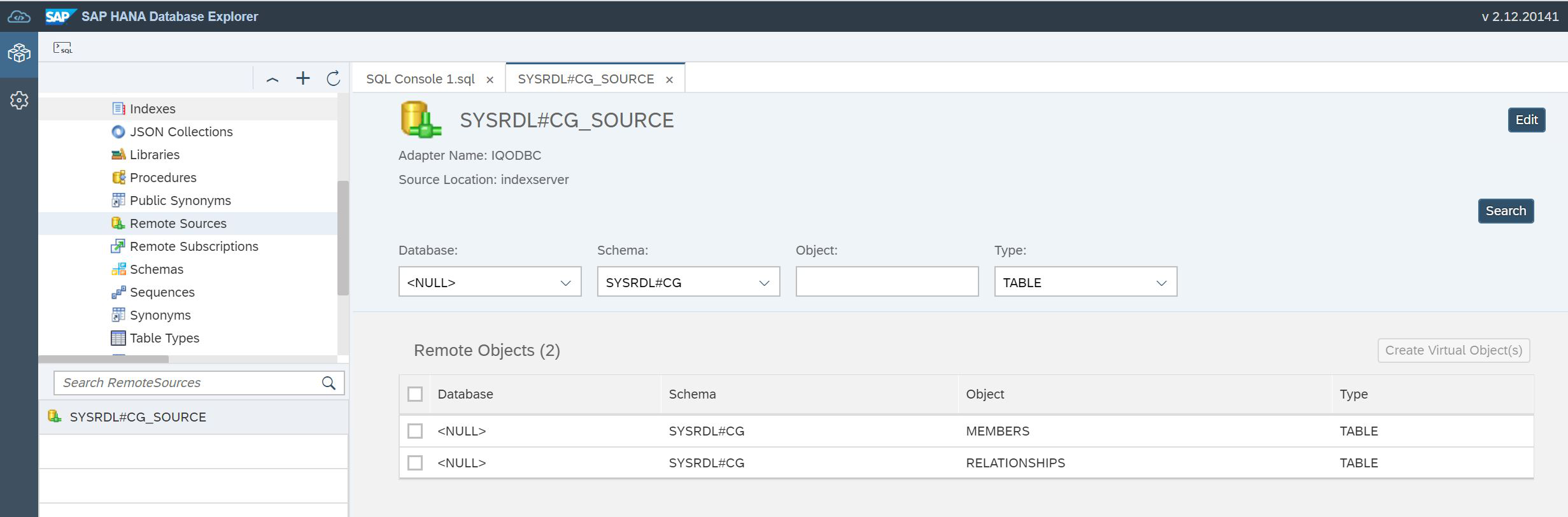
Figura 19
Encontramos ambas tablas, establecemos las "casillas de verificación" opuestas a las tablas y hacemos clic en el botón Crear objetos virtuales, como se muestra en la Fig. 20.
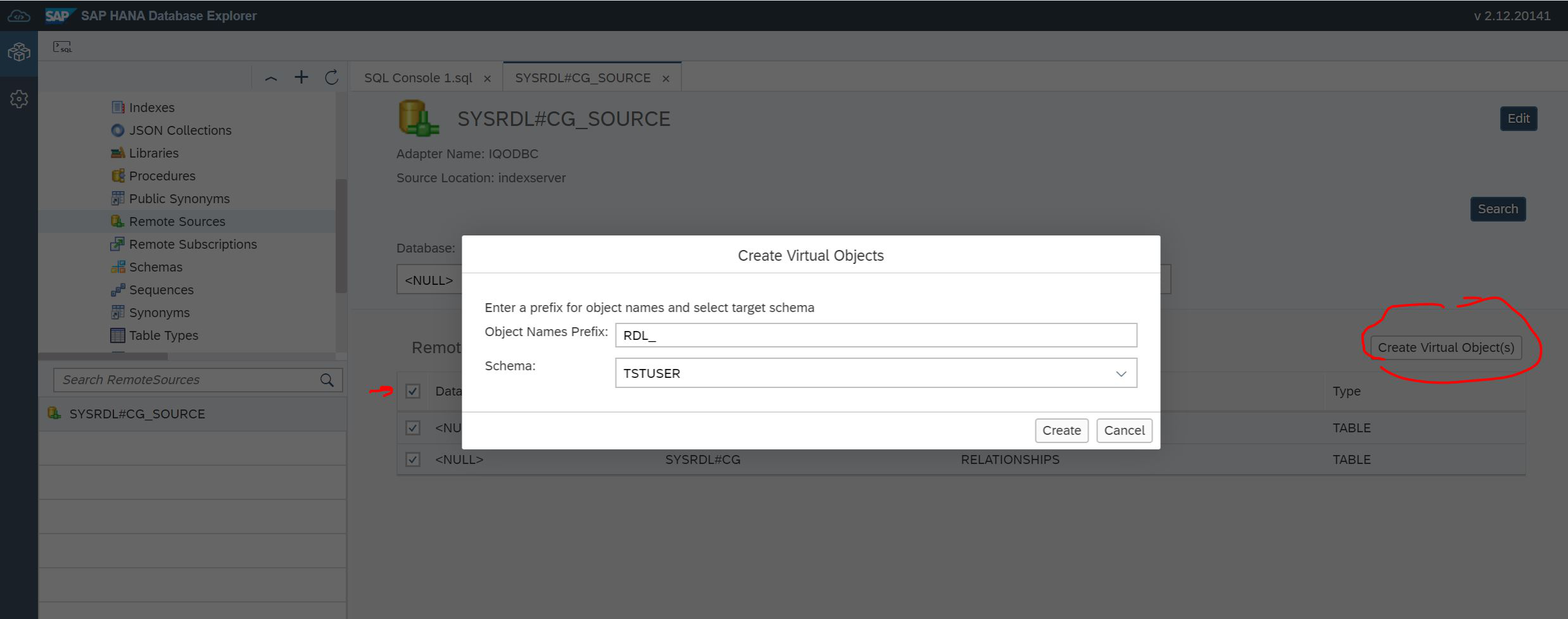
Figura 20
Tenemos la capacidad de especificar el esquema en el que se crearán las tablas virtuales. Y allí debe especificar un prefijo para que estas tablas sean más fáciles de encontrar. Después de eso, podemos seleccionar Tabla en el navegador, ver nuestras tablas y ver los datos (Fig. 21).

Figura 21
En este paso, es importante prestar atención al filtro en la parte inferior izquierda. Debe haber nuestro nombre de usuario o nuestro esquema TSTUSER.
Estas casi listo. Creamos tablas en el lago y cargamos datos en ellas, y para acceder a ellas desde el nivel HANA, tenemos tablas virtuales. Estamos listos para crear un nuevo objeto: un gráfico (Fig. 22).
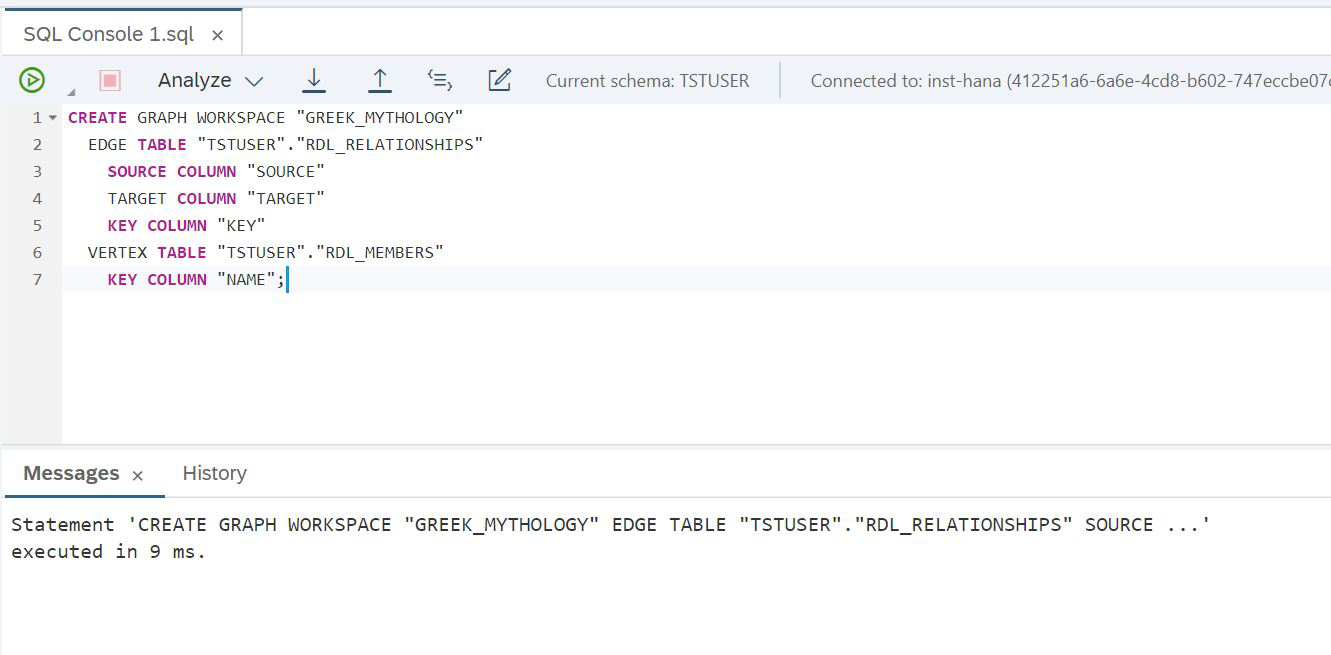
Figura 22
SCRIPT:
CREATE GRAPH WORKSPACE "GREEK_MYTHOLOGY"
EDGE TABLE "TSTUSER"."RDL_RELATIONSHIPS"
SOURCE COLUMN "SOURCE"
TARGET COLUMN "TARGET"
KEY COLUMN "KEY"
VERTEX TABLE "TSTUSER"."RDL_MEMBERS"
KEY COLUMN "NAME";Todo funcionó, el gráfico está listo. E inmediatamente puede intentar hacer una consulta simple en los datos del gráfico, por ejemplo, para encontrar todas las hijas del Caos y todas las hijas de estas hijas. Para hacer esto, Cypher, un lenguaje de análisis gráfico, nos ayudará. Fue creado especialmente para trabajar con gráficos, conveniente, simple y ayuda a resolver problemas complejos. Solo necesitamos recordar que la secuencia de comandos Cypher debe incluirse en una consulta SQL utilizando una función de tabla. Vea cómo se resuelve nuestra tarea en este lenguaje (Fig. 23).

Figura 23
SCRIPT:
SELECT * FROM OPENCYPHER_TABLE( GRAPH WORKSPACE "GREEK_MYTHOLOGY" QUERY
'
MATCH p = (a)-[*1..2]->(b)
WHERE a.NAME = ''Chaos'' AND ALL(e IN RELATIONSHIPS(p) WHERE e.TYPE=''hasDaughter'')
RETURN b.NAME AS Name
ORDER BY b.NAME
'
)Veamos cómo funciona la herramienta visual de análisis gráfico SAP HANA. Para hacer esto, seleccione Graph Workspace en el navegador (Fig. 24).
Figura 24
Y ahora puedes ver nuestro gráfico (fig. 25).
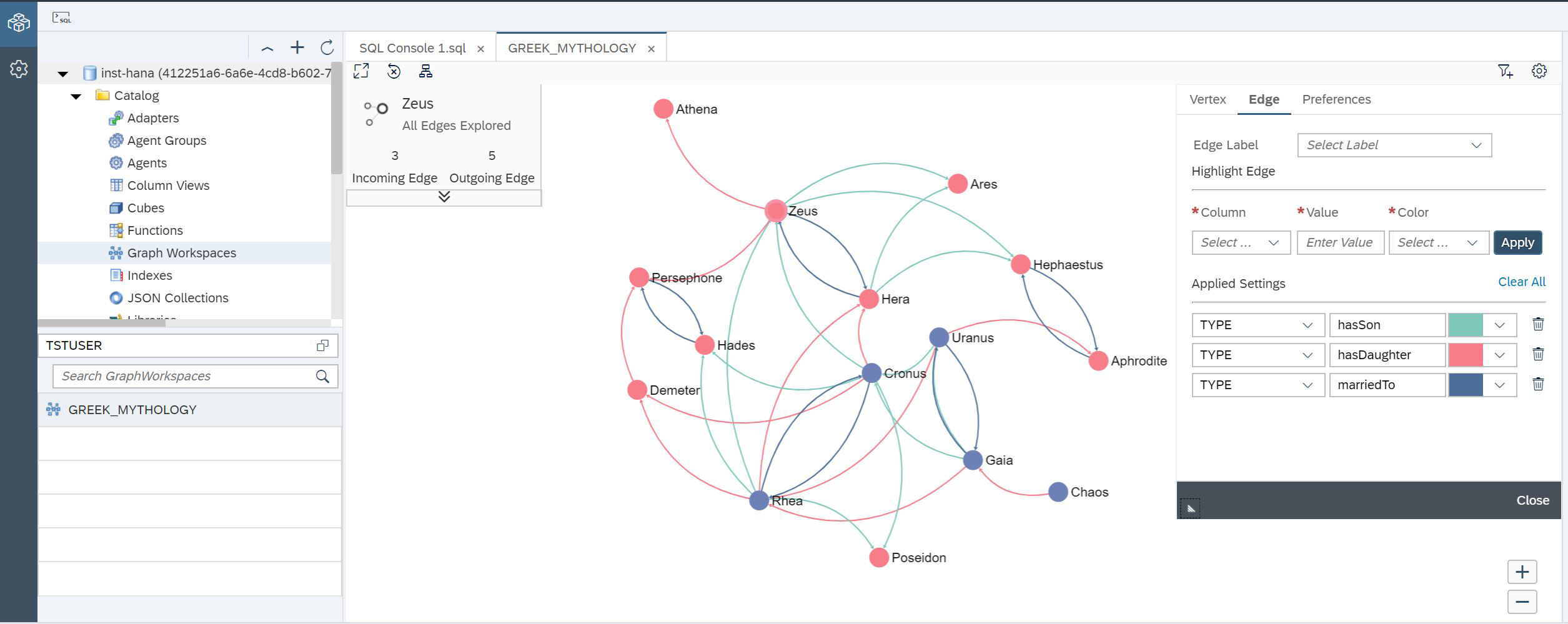
Figura 25
Verá un gráfico que ya ha sido coloreado. Lo hicimos usando la configuración en el lado derecho de la pantalla. En la esquina superior izquierda, se muestra información detallada sobre el nodo que está seleccionado actualmente.
Bueno ... lo hicimos. Los datos están en el lago de datos, y los analizamos utilizando herramientas en SAP HANA. Una tecnología calcula los datos, mientras que la otra es responsable de almacenarlos. Cuando se procesan los datos del gráfico, se solicitan del lago de datos y se transfieren a SAP HANA. ¿Podemos acelerar nuestras solicitudes? ¿Cómo asegurarse de que los datos se almacenan en la RAM y no se cargan desde el lago de datos? Hay una manera simple pero no muy hermosa: crear una tabla en la que cargar el contenido de la tabla del lago de datos (Fig. 26).

Figura 26
SCRIPT:
CREATE COLUMN TABLE MEMBERS AS (SELECT * FROM "TSTUSER"."RDL_MEMBERS")Pero hay otra forma: esta es la aplicación de la replicación de datos a la RAM de SAP HANA. Esto puede proporcionar un mejor rendimiento para las consultas SQL que acceder a los datos almacenados en un lago de datos utilizando una tabla virtual. Puede cambiar entre tablas virtuales y de replicación. Para hacer esto, agregue una tabla de réplica a la tabla virtual. Esto se puede hacer usando la instrucción ALTER VIRTUAL TABLE. Después de eso, una consulta que usa una tabla virtual accede automáticamente a la tabla de réplica, que se encuentra en la RAM de SAP HANA. Veamos cómo hacer esto, hagamos un experimento. Ejecutemos tal solicitud (fig. 27).
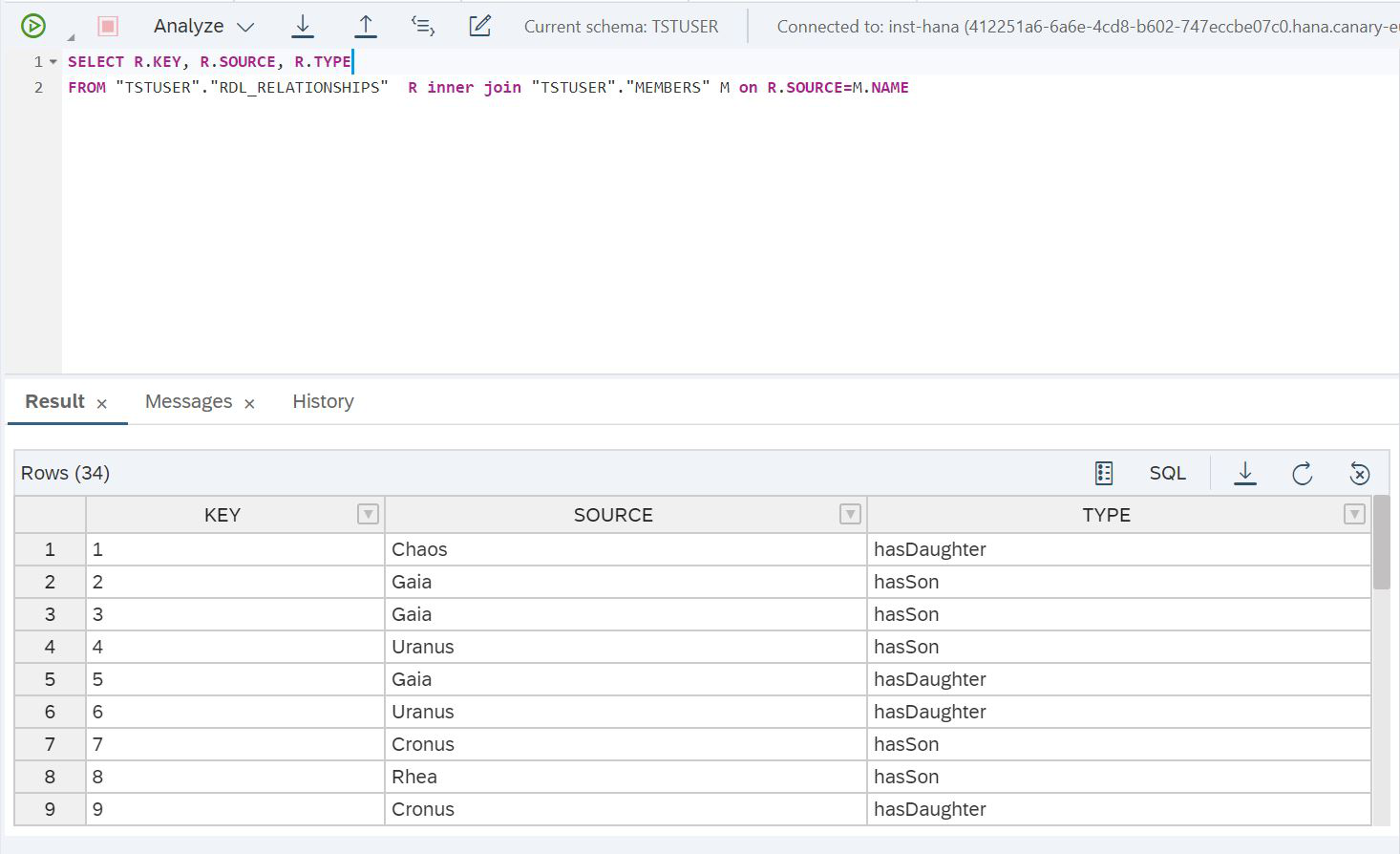
Figura 27
SCRIPT:
SELECT R.KEY, R.SOURCE, R.TYPE
FROM "TSTUSER"."RDL_RELATIONSHIPS" R inner join "TSTUSER"."MEMBERS" M on R.SOURCE=M.NAMEY veamos cuánto tiempo tardó en cumplir esta solicitud (Fig. 28).
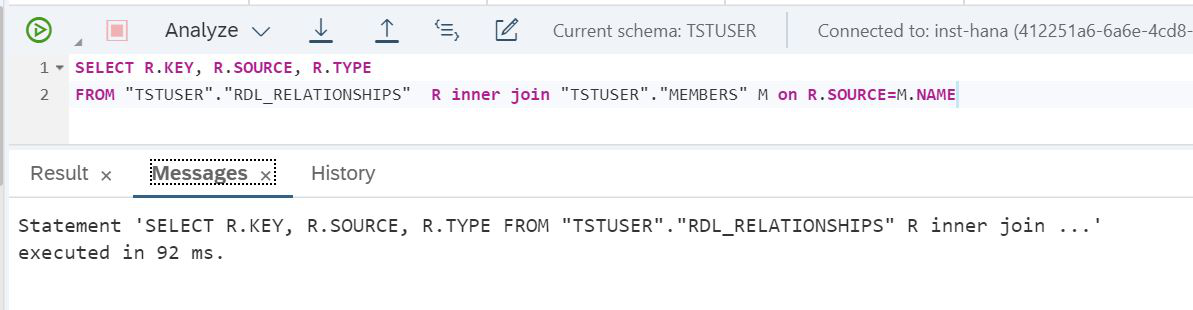
Figura 28
Podemos ver que tomó 92 milisegundos. Habilitemos el mecanismo de replicación. Para hacer esto, debe hacer ALTERAR TABLA VIRTUAL de la tabla virtual, después de lo cual los datos de Lake se replicarán en la RAM de SAP HANA.
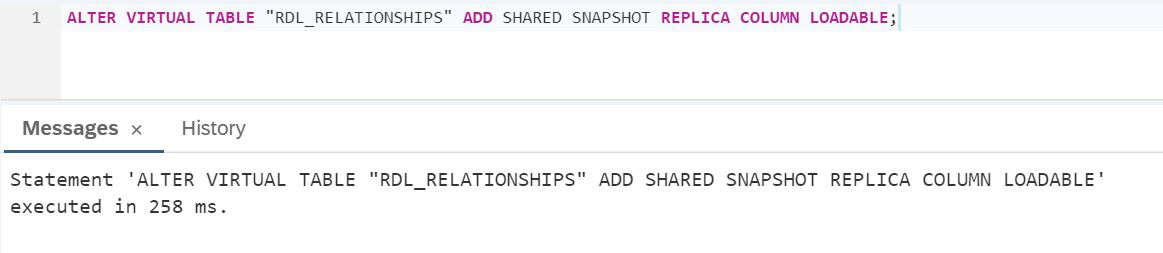
GUIÓN:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" ADD SHARED SNAPSHOT REPLICA COLUMN LOADABLE;Verifiquemos el tiempo de ejecución como en la Figura 29.

Figura 29
Tenemos 7 milisegundos. Este es un gran resultado! Con un mínimo esfuerzo, trasladamos los datos a la RAM. Además, si ha finalizado el análisis y está satisfecho con el rendimiento, puede volver a desactivar la replicación (Fig. 30).

Figura 30
SCRIPT:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" DROP REPLICA;Ahora los datos se descargan nuevamente del Lago solo bajo solicitud, y la RAM SAP HANA es gratuita para nuevas tareas. Hoy hicimos, en mi opinión, un trabajo interesante y probamos SAP HANA Cloud para la organización rápida y fácil de un único punto de acceso a los datos. El producto continuará evolucionando y esperamos una conexión directa con el lago de datos en un futuro próximo. La nueva capacidad permitirá descargas más rápidas de grandes cantidades de información, eliminará gastos generales innecesarios y mejorará el rendimiento de las operaciones específicas del lago de datos. Crearemos y ejecutaremos procedimientos almacenados directamente en la nube de datos utilizando la tecnología SAP IQ, es decir, podremos aplicar el procesamiento y la lógica comercial donde se encuentran los datos.
Alexander Tarasov, Arquitecto Comercial Senior SAP CIS