Al final del artículo, compartiremos con usted una lista de los materiales más interesantes sobre este tema.

Nuevo enfoque
El aprendizaje de refuerzo de múltiples agentes es un área de investigación creciente y rica. Sin embargo, el uso constante de algoritmos de agente único en contextos de agentes múltiples nos pone en una posición difícil. El aprendizaje es complicado por muchas razones, especialmente debido a:
- No estacionariedad entre agentes independientes;
- Crecimiento exponencial de espacios de acciones y estados.
Los investigadores han encontrado muchas formas de reducir el impacto de estos factores. La mayoría de estos métodos se enmarcan en el concepto de "planificación central con ejecución descentralizada".
Planificación centralizada
Cada agente tiene acceso directo a observaciones locales. Estas observaciones pueden ser muy diversas: imágenes del entorno, posición relativa a ciertos puntos de referencia o incluso posición relativa a otros agentes. Además, durante el entrenamiento, todos los agentes están controlados por un módulo central o crítico.
Aunque cada agente solo tiene información local y políticas locales para capacitación, existe una entidad que monitorea todo el sistema de agentes y les dice cómo actualizar las políticas. Por lo tanto, se reduce el efecto de no estacionariedad. Todos los agentes reciben capacitación mediante un módulo con información global.
Ejecución descentralizada
Durante las pruebas, el módulo central se elimina y los agentes con sus políticas y datos locales permanecen. Esto reduce el daño causado por el aumento de espacios de acciones y estados, ya que las políticas agregadas nunca se estudian. En cambio, esperamos que haya suficiente información en el módulo central para administrar la política de aprendizaje local para que sea óptima para todo el sistema tan pronto como sea el momento de la prueba.
OpenAI
Investigadores de OpenAI, UC Berkeley y McGill University han presentado un nuevo enfoque para la configuración de múltiples agentes utilizando el Gradiente de política determinista profunda de múltiples agentes . Inspirado por su contraparte de agente único de DDPG, este enfoque utiliza la formación de "actor crítico" y muestra resultados muy prometedores.
Arquitectura
Este artículo asume que está familiarizado con la versión de agente único de MADDPG: Gradientes de política deterministas profundos o DDPG. Para refrescar su memoria, puede leer el maravilloso artículo de Chris Yoon .
Cada agente tiene un espacio de observación y un espacio de acción continua. Además, cada agente tiene tres componentes:
- , ;
- ;
- , - Q-.
A medida que el crítico examina los valores Q conjuntos de una función a lo largo del tiempo, envía aproximaciones apropiadas de los valores Q al actor para ayudar en el aprendizaje. Echaremos un vistazo más de cerca a esta interacción en la siguiente sección.
Recuerde que el crítico puede ser una red compartida entre todos los agentes N. En otras palabras, en lugar de entrenar redes N que evalúen el mismo valor, solo entrene una red y úsela para ayudar a entrenar a todos los demás agentes. Lo mismo se aplica a las redes de actores si los agentes son homogéneos.
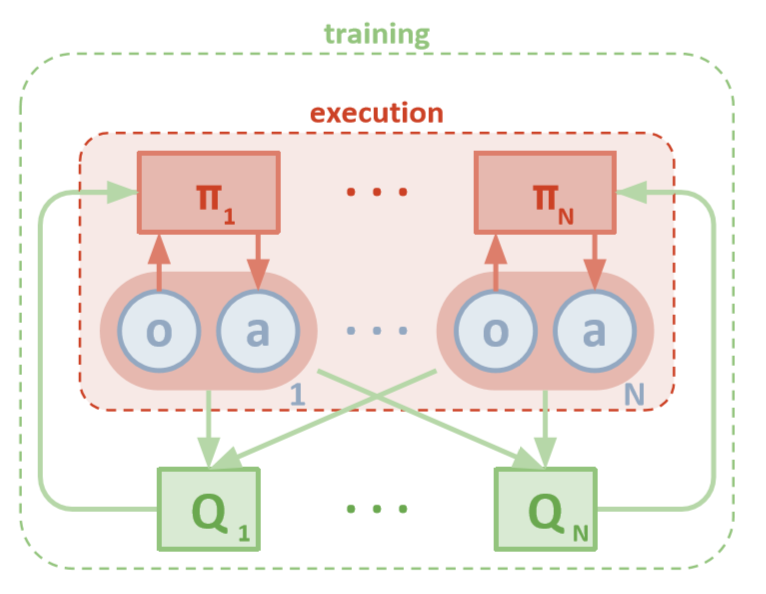
Arquitectura MADDPG (Lowe, 2018)
Formación
Primero, MADDPG utiliza la repetición de la experiencia para un aprendizaje efectivo fuera de la política . En cada intervalo de tiempo, el agente almacena la siguiente transición:
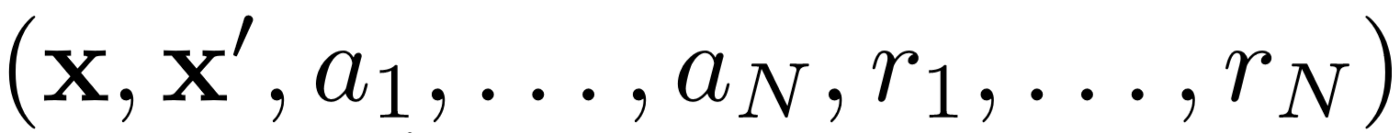
donde almacenamos el estado conjunto, el siguiente estado conjunto, la acción conjunta y cada una de las recompensas recibidas por el agente. Luego tomamos un conjunto de tales transiciones de la repetición de la experiencia para entrenar a nuestro agente.
Actualizaciones críticas
Para actualizar el crítico central del agente, utilizamos un error de TD anticipado:
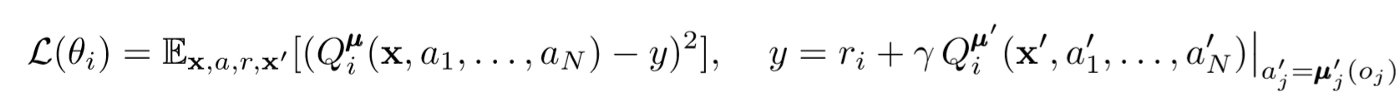
donde μ es un actor. Recuerde que este es un crítico central, es decir, utiliza información general para actualizar sus parámetros. La idea básica es que si conoce las acciones que están tomando todos los agentes, el entorno será estacionario incluso si la política cambia.
Presta atención al lado derecho de la expresión con el cálculo del valor Q. Si bien nunca guardamos nuestra próxima sinergia, utilizamos cada actor objetivo del agente para calcular la siguiente acción durante la actualización para hacer que el aprendizaje sea más estable. Los parámetros del actor objetivo se actualizan periódicamente para que coincidan con los parámetros del actor agente.
Actualizaciones de actores
Similar al agente único DDPG, utilizamos un gradiente de política determinista para actualizar cada parámetro de un agente agente.
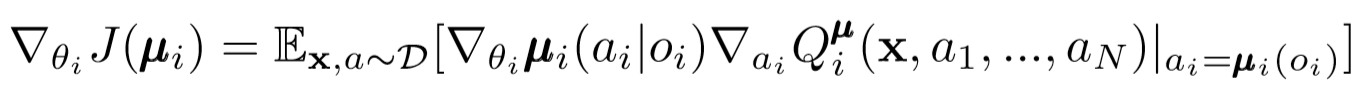
Donde μ es el actor del agente.
Profundicemos un poco más en esta expresión de renovación. Tomamos el gradiente relativo a los parámetros del actor con la ayuda de un crítico central. Lo más importante a lo que debe prestar atención es que, incluso si el actor solo tiene observaciones y acciones locales, durante el entrenamiento usamos un crítico central para obtener información sobre la optimización de sus acciones dentro del sistema en su conjunto. ¡Esto reduce el efecto de no estacionariedad, y la política de aprendizaje permanece en el espacio estatal inferior!
Conclusiones de políticos y conjuntos de políticos.
Podemos dar un paso más en el tema de la descentralización. En actualizaciones anteriores, asumimos que cada agente reconocerá automáticamente las acciones de otros agentes. Sin embargo, MADDPG sugiere extraer conclusiones de las políticas de otros agentes para hacer que el aprendizaje sea aún más independiente. De hecho, cada agente agregará redes N-1 para evaluar la validez de la política de todos los demás agentes. Utilizamos una red probabilística para maximizar la probabilidad logarítmica de inferir la acción observada de otro agente.
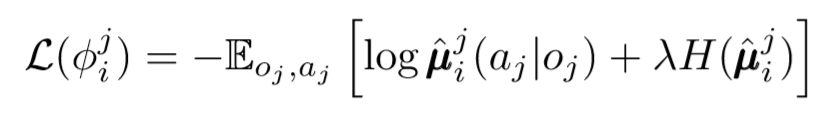
Donde vemos la función de pérdida para el agente i-ésimo evaluando la política del agente j-ésimo usando el regularizador de entropía. Como resultado, nuestro valor Q objetivo se vuelve ligeramente diferente cuando reemplazamos las acciones del agente con nuestras acciones predichas.
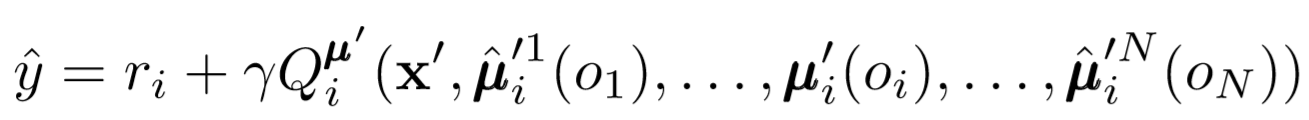
Entonces, ¿qué pasó al final? Eliminamos la suposición de que los agentes conocen las políticas de los demás. En cambio, tratamos de capacitar a los agentes para predecir las políticas de otros agentes con base en una serie de observaciones. De hecho, cada agente aprende de forma independiente, recibe información global del entorno en lugar de tenerla a mano de manera predeterminada.
Conjuntos Políticos
Hay un gran problema con el enfoque anterior. En muchos entornos de múltiples agentes, especialmente los competitivos, los agentes pueden crear políticas que pueden volver a entrenar el comportamiento de otros agentes. Esto hará que la política sea frágil, inestable y, como regla, no óptima. Para compensar esta deficiencia, MADDPG entrena una colección de subpolíticas K para cada agente. En cada paso de tiempo, el agente selecciona aleatoriamente una de las subpolíticas para seleccionar una acción. Y luego lo realiza.
El gradiente de la política está cambiando un poco. Tomamos el promedio sobre la subpolítica K, utilizamos la linealidad de espera y propagamos las actualizaciones utilizando la función de valor Q.
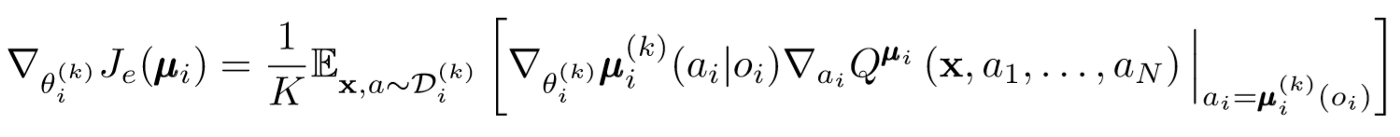
Da un paso atrás
Así es como se ve todo el algoritmo en términos generales. Ahora tenemos que regresar y darnos cuenta de lo que hemos hecho y comprender intuitivamente por qué esto funciona. Básicamente, hicimos lo siguiente:
- Actores definidos para agentes que solo usan observaciones locales. De esta manera, se pueden controlar los efectos negativos del aumento exponencial de los espacios de estado y acción.
- Identificó un crítico central para cada agente que usa información compartida. Así que pudimos reducir la influencia de la no estacionariedad y ayudamos al actor a ser óptimo para el sistema global.
- Redes de inferencia de políticas definidas para evaluar las políticas de otros agentes. De esta manera, pudimos limitar la interdependencia de los agentes y eliminar la necesidad de que los agentes tengan información perfecta.
- Identificamos conjuntos de políticas para reducir el efecto y la posibilidad de volver a capacitar sobre las políticas de otros agentes.
Cada componente del algoritmo tiene un propósito específico y separado. Lo que hace que MADDPG sea poderoso es lo siguiente: sus componentes están diseñados específicamente para superar los principales obstáculos que los sistemas de múltiples agentes suelen enfrentar. A continuación, hablaremos sobre el rendimiento del algoritmo.
resultados
MADDPG ha sido probado en muchos entornos. Una revisión completa de su trabajo se puede encontrar en el artículo [1]. Aquí solo hablaremos sobre el problema de la comunicación cooperativa.
Resumen del entorno
Hay dos agentes: el hablante y el oyente. En cada iteración, el oyente recibe un punto coloreado en el mapa para moverse y recibe una recompensa proporcional a la distancia a ese punto. Pero aquí está el truco: el oyente solo conoce su posición y el color de los puntos finales. No sabe a qué punto debería moverse. Sin embargo, el hablante conoce el color del punto correcto para la iteración actual. Como resultado, los dos agentes deben interactuar para realizar esta tarea.
Comparación
Para resolver este problema, el artículo contrasta MADDPG y los métodos modernos de agente único. Se observan mejoras significativas con el uso de MADDPG.
También se demostró que las inferencias de las políticas, incluso si los políticos no fueron capacitados idealmente, lograron los mismos resultados que se pueden lograr utilizando la observación verdadera. Además, no hubo una desaceleración significativa en la convergencia.
Finalmente, conjuntos de políticas han mostrado resultados muy prometedores. El artículo [1] explora el impacto de los conjuntos en un entorno competitivo y demuestra una mejora significativa del rendimiento sobre los agentes con una sola política.
Conclusión
Eso es todo. Aquí observamos un nuevo enfoque para reforzar el aprendizaje de múltiples agentes. Por supuesto, hay un número infinito de métodos relacionados con MARL, pero MADDPG proporciona una base sólida para los métodos que resuelven los problemas más globales de los sistemas de múltiples agentes.
Fuentes
[1] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch, Actor-crítico multiagente para entornos competitivos y cooperativos mixtos (2018).
Lista de artículos útiles.
- 3 trampas en las que los científicos de datos principiantes caen
- Algoritmo AdaBoost
- ¿Cómo fue 2019 en Matemáticas e Informática?
- El aprendizaje automático enfrenta un problema matemático sin resolver
- Comprender el teorema de Bayes
- Busque contornos faciales en un milisegundo usando un conjunto de árboles de regresión
, , , . .