
De hecho, esta es la historia de la búsqueda de un defecto en el diseño de un sitio bancario, lo que condujo a una visualización inexacta de su página principal en la búsqueda. A menudo se encuentra un problema similar en un sitio ensamblado, por ejemplo, en un constructor en línea, o diseñado, por ejemplo, por un diseñador de diseño que no está familiarizado con los conceptos básicos de la optimización de motores de búsqueda.
Y esta historia habría seguido siendo interesante solo para un círculo estrecho de practicantes de seoshniks, si no hubiera tocado una característica indocumentada de indexación, que otros especialistas en mantenimiento de sitios web probablemente hubieran querido conocer. Los invito debajo del gato.
Breve introducción
Cualquier experto en SEO con experiencia conoce las reglas del análisis semántico de una página del sitio mediante robots indexadores de búsqueda. Estas reglas están sujetas a ciertas disposiciones de ciertas normas técnicas de Internet. Por ejemplo:
- la etiqueta <title> es un nombre único para todo el documento y se usa solo en su sección de encabezado, y solo una vez;
- la etiqueta <h1> nombra una sección específica del documento y puede reutilizarse, pero solo en una sección diferente y manteniendo la unicidad entre todas las etiquetas <h1> del mismo documento;
- la etiqueta <h2> es un subtítulo de sección que se puede reutilizar incluso en la misma sección si es única entre los subtítulos de su sección;
- la etiqueta <h3> es el subtítulo del subtítulo principal;
- ... etc.
Por supuesto, hay diferentes matices en estas reglas para analizar páginas antes de indexarlas, que cada servidor de búsqueda interpreta a su manera:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
Estas reglas de análisis semántico y matices aún no son importantes para nosotros. Y si está tan interesado en las disposiciones de las normas técnicas en las que se basa la indexación de contenido, entonces la parte principal de estas disposiciones está claramente establecida en la publicación de revisión [1] sobre la permisibilidad de varias etiquetas <h1> en una página de un sitio.
Solo noto que los maestros de SEO están acostumbrados a tales matices, esta no es la primera vez que verifican su imparcialidad en su propia experiencia, y durante mucho tiempo han estado promoviendo sitios web en búsqueda teniendo en cuenta una visión similar sobre la prioridad de las etiquetas. De hecho, la comprensión de los principios de indexación hace posible "administrar" parcialmente el texto que el fragmento de búsqueda de un sitio mostrará en respuesta a una solicitud del usuario.
Pero hace unos días, apareció información privilegiada de que en los resultados de búsqueda orgánicos relacionados con el sitio web oficial del Monobank de Ucrania, se reveló un comportamiento de fragmento incomprensible: los motores de búsqueda no lo titulan en absoluto con la etiqueta <title> o <h1>. Es decir, un redactor podría escribir el título y el texto más exclusivos, un administrador de contenido podría insertar texto en el sitio, pero la búsqueda aún sería incorrecta.
Era necesario averiguar la razón, de la que hablaré más adelante.
El primer paso de la investigación
Entonces, primero, borré el historial del caché y del navegador, lo reinicié, abrí el cuadro de búsqueda de Google e ingresé el nombre del banco. Para que incluso una persona SEO sin experiencia pudiera entender cada uno de mis pasos, tomé una foto del primer paso.
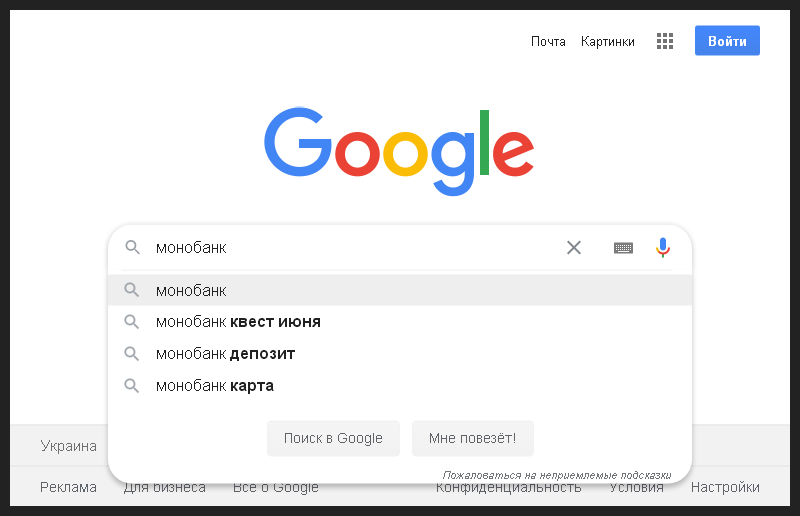
Esta es una solicitud de información de marca, lo que significa que, en primer lugar de los resultados orgánicos, es lógico esperar que aparezca un fragmento para la página de inicio del banco.
Todo sucedió como se esperaba, el fragmento fue el primero en la búsqueda y también contenía un bloque de enlaces rápidos a las secciones principales del sitio. Capturé este momento en la siguiente foto.
Hasta ahora, todo parecía normal.

Para asegurarme de que la situación poco clara ocurra solo en los resultados de Google, repetí la misma consulta en la búsqueda de Yandex y noté gratamente que este gigante de búsqueda se adhiere a las reglas habituales: el fragmento se tituló monobanco, un banco móvil , exactamente como está escrito en la etiqueta <title> del deseado páginas

La respuesta en la instantánea de búsqueda de Google fue fundamentalmente diferente, al menos en términos del título. Bueno, y además, estaba un poco confundido por los textos ridículos bajo los títulos del fragmento de Google.
Supuse que esto es solo una consecuencia del hecho de que después de la promoción SMM de la marca y su aplicación móvil, que promovió Promodo en 2017-2018 [2] para el antiguo dominio monobank.com.ua , contratar a más maestros SEO para mantener el nuevo dominio monobanco .ua ya no tenía sentido. Después de todo, la campaña publicitaria ha dado los resultados esperados. Y lo más probable es que la administración del banco haya marcado un gol en la promoción de motores de búsqueda del nuevo dominio, o haya asignado la responsabilidad a especialistas de TI a tiempo completo.
Por lo tanto, atribuí la torpeza de los textos actuales a la comprensible renuencia de los empleados regulares a verificar el resultado de la solicitud, que un usuario bancario típico nunca marcará.
Después de todo, la clientela del banco va al sitio en su mayor parte a través de una aplicación móvil, prácticamente sin observar cómo se ven las páginas del banco en la búsqueda. Y la parte de los clientes que realizan búsquedas en Internet utiliza principalmente consultas del formulario:
- tasa de dólar monobanco;
- tipo de cambio monobanco;
- abrir una cuenta monobanco;
- hacer una tarjeta monobanco;
- crear una tarjeta monobanco;
- tarjeta de crédito monobanco;
- solicitar un préstamo de monobanco;
- sacar un préstamo de monobanco;
- ... etc.
Cualquier banco conoce una lista completa de tales frases de búsqueda que coinciden con los patrones "qué encontrar + dónde" o "dónde + qué" y generan el mayor tráfico entrante de la búsqueda orgánica.
Comprobación de consultas "sabrosas"
Me sorprendió cuando, para la mayoría de estas consultas, apareció el mismo fragmento en los resultados de búsqueda con el mismo título y, a menudo, texto estúpido que casi no coincidía con la consulta ingresada.
Fotografié un ejemplo de tal solicitud en la siguiente imagen e indiqué el área del problema.

Además, la dirección de destino (URL) del fragmento para casi todas las solicitudes condujo a la parte superior de la página principal, sin siquiera anclar su sección en la dirección relevante a la solicitud actual.
Bueno, digamos, si la solicitud fuera sobre el tipo de cambio y la sección correspondiente estuviera presente en la página de destino, sería lógico anclar el enlace a la sección con algún hash como monobank.ua/#kurs-valut con la canonización de la misma URL anclada para que el robot de búsqueda entienda que la página de aterrizaje tiene varios puntos de aterrizaje para las frases de búsqueda correspondientes que los SEO habituales registrarían en el texto de anclaje de los enlaces que colocan en algún lugar del sitio o fuera del sitio, por ejemplo, en las redes sociales.
De lo contrario, parecía que los desarrolladores del sitio web asignaban a la página principal el papel de una página de destino multiseccional, pero no se lo decían a los proveedores de servicios de SEO y ponían enlaces promocionales con el texto de anclaje planeado, pero sin los anclajes de sección. Como resultado, todos los enlaces para diferentes tipos de solicitudes parecían estar en el punto de entrada de la página principal e inevitablemente recibían un solo fragmento con un encabezado con respecto a la sección principal de la página principal.
Pequeña digresión
Por si acaso, mostraré en la siguiente imagen un ejemplo de marcado HTML, cómo usan el diseño semántico para resolver los problemas de múltiples puntos de aterrizaje en una página de aterrizaje de un solo sitio.

Por supuesto, este esquema funcionará siempre que vinculemos la página de destino con un ancla correspondiente al caso de información. Es decir:
- monobank.ua - información básica;
- monobank.ua/#kurs-valut - acerca de los tipos de cambio;
- monobank.ua/#otkryt-schet - acerca de abrir una cuenta;
- monobank.ua/#kreditnaja-karta - sobre tarjetas de crédito.
Pero volviendo a la jamba SEO detectada
Aunque el error no es tan grave, el flujo principal de clientes aún pasa por la aplicación móvil, sin embargo, debido a este error, el banco pierde parte del tráfico de búsqueda. Debido a que los usuarios de búsqueda se dividen en 2 tipos: la mayoría apresurada y la minoría pausada:
- el primero lee solo los encabezados de los fragmentos y hace clic en ellos si el significado del encabezado y la solicitud ingresada coinciden;
- este último lee atentamente el título y el texto debajo y también hace clic solo cuando el significado coincide.
Está claro que el significado del mensaje en el fragmento de búsqueda osificado de la página del banco coincidió solo con un porcentaje muy pequeño de solicitudes. Era necesario entender dónde se cometió el error.
Ver el diseño de la página de inicio
Abrí la página principal del banco siguiendo el enlace del fragmento. En el código fuente de esta página, había una sola etiqueta <h1>, generalmente utilizada para escribir el título principal de la página, que generalmente también termina en el título del fragmento.
Además, esta etiqueta de encabezado principal se utilizó en el código de la página antes que el resto de las etiquetas de encabezado <h>. Entonces, a primera vista, parecía que no tenía errores de SEO.
Tomé una foto de esa página y marqué la posición de las dos primeras etiquetas de encabezado <h> en ella.
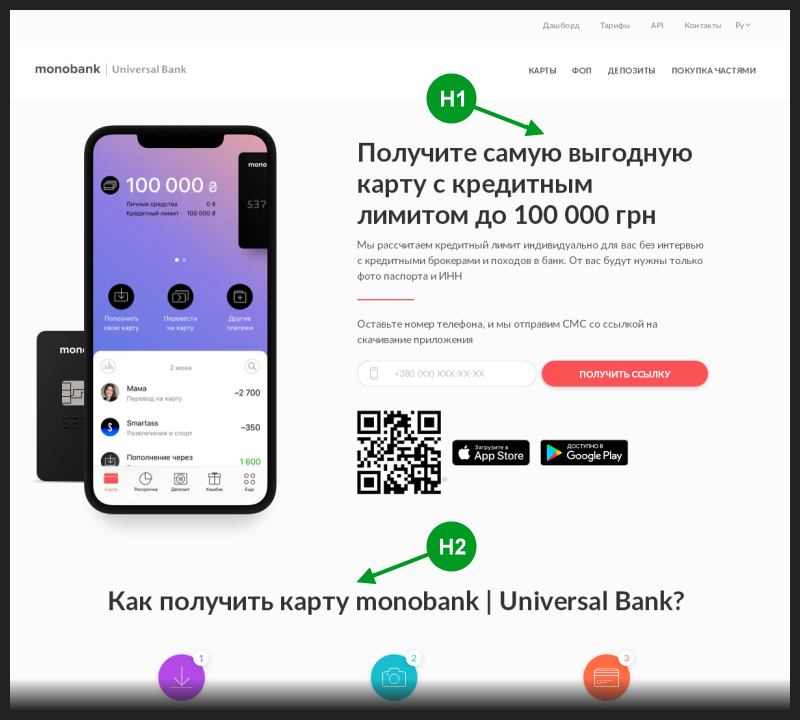
Era lógico esperar que la etiqueta <h1> tomara el lugar del encabezado del fragmento de búsqueda. Pero por alguna razón, una etiqueta de un rango inferior llegó allí cada vez.
Al principio supuse que el caso solo se refería a consultas que incluían el nombre del banco. En la etiqueta <h1> no lo es, pero en la etiqueta <h2> existe, por lo tanto, esa etiqueta, a pesar del rango inferior, todavía tiene la ventaja de tomar el título del fragmento.
Sin embargo, esta suposición es fácil de verificar: debe escribir una solicitud exactamente igual a la etiqueta <h1>, y luego se garantiza que esta etiqueta de encabezado tendrá el derecho de ocupar el título del fragmento en función de la coincidencia absoluta con la solicitud. Lo cual hice, mientras capturaba simultáneamente el resultado en la siguiente imagen.

De la imagen se deduce que el servidor de búsqueda aún ve y comprende el texto de la etiqueta <h1>, por alguna razón no considera que sea el encabezado principal en el sitio de este banco. Esto es posible en 2 casos:
- o el SEO-master agregó una micromarcación semántica específica al diseño de la página, requiriendo que otra etiqueta se convierta en el encabezado principal;
- o existe el llamado "problema de los constructores en línea", cuando, debido a la falta de optimización de la búsqueda de bloques de construcción, sus etiquetas de texto aparecen en diferentes secciones de un documento HTML, y la etiqueta de encabezado principal se omite más profundamente que la etiqueta de encabezado no principal del contorno de su sección.
Decidí comprobar primero el primer caso y abrí el sitio en la herramienta de validación de datos estructurados. Sin embargo, solo se encontró el marcado de Open Graph, no hay indicios de reasignación forzada de la semántica de etiquetas.
Capturé este momento en la siguiente imagen.

Luego abrí el código fuente de la página del problema, formateé los espacios para facilitar el estudio, eliminé los atributos de la etiqueta con el mismo propósito y luego noté la esencia del problema en la siguiente imagen.

Como resultado, tenemos el estado de las cosas, interpretado a continuación, desde el cual escribiré una conclusión importante de antemano : después de un mes (este es aproximadamente el tiempo promedio para rastrear mediante robots de indexación) desde el lanzamiento del sitio, asegúrese de verificar algunas consultas clave sobre cómo el motor de búsqueda tomó el diseño de sus páginas, es decir, qué partes contenido que realmente indexó.
Interpretación del resultado.
Yandex, al analizar la página en el nuevo dominio de Monobank, no encontró el diseño semántico (ya que todo se presenta con <div> s) y, al no tener instrucciones para analizar la semántica implícita, no comenzó a adivinar por las clases de etiquetas, y al seleccionar el título del fragmento, simplemente utilizó la regla de la especificación: etiqueta <título> es el título principal del documento.
Google, al analizar la misma página, tampoco encontró un diseño semántico, pero su inteligencia artificial puede analizar características semánticas ocultas, por lo que notó cuatro <div> s con un contenido de clase semántica implícito, que denota el contorno de la sección en la situación de marcado actual. En consecuencia, la regla sobre la etiqueta <title> fue rechazada, y el motor de búsqueda usó la regla de la especificación del esquema de la sección, tratando de encontrar una sección adecuada de las cuatro declaradas. La primera sección no es adecuada, ya que su etiqueta de título está más lejos del contorno que la etiqueta de título en las secciones 2, 3 y 4. De estas secciones más adecuadas, la segunda sección se seleccionó en función de su proximidad al comienzo del documento. Así es como su título se metió en el fragmento.
De hecho, la lógica de selección de encabezado para el fragmento era idéntica para ambos motores de búsqueda. Fue solo que Yandex seleccionó la primera etiqueta de encabezado del primer esquema (la etiqueta <head> se usa implícitamente) en el documento, y Google eligió la primera etiqueta de encabezado del esquema semánticamente marcado (claramente era la etiqueta <div class = "content">).
Esta es la característica sorprendente de la búsqueda, llamada "indocumentada" al comienzo de mi investigación. La etiqueta <h1> realmente no tiene ninguna importancia significativa. Según la consulta de búsqueda del usuario, se selecciona un esquema de sección coincidente en el documento y el primer encabezado del esquema sin tener en cuenta el nivel de encabezado numérico utilizado.
Materiales usados
[1] Un H1 o más: ¿por qué es correcto de esta manera? , Marzo de 2020. Impera, SEO Documents. Los extractos de las especificaciones del estándar HTML muestran que escribir una o más etiquetas H1 en una página se considera correcto en ambos casos.
[2] Caso Monobank sobre promoción de aplicaciones móviles , agosto de 2017 - marzo de 2018. Promodo, casos. Un ejemplo de los eventos utilizados por la agencia explica cómo promocionar una aplicación móvil en iOS y Android usando AdWords, Facebook, Instagram, Twitter, YouTube, y también los optimizó en la App Store y Google Play.