
el flujo de datos en esta tabla es un poco complicado de rastrear, así que aquí hay un cuadro equivalente que representa la tabla como un gráfico:

Redondea el costo del burrito super vegi de El Farolito a $ 8, así que en la entrega vale $ 2, la cantidad total será de $ 20.
¡Oh, lo olvidé por completo! Uno de mis amigos no es suficiente para un burrito, necesita dos. Así que realmente quiero pedir tres. Si se actualiza
Num Burritos
, el motor de hoja de cálculo ingenuo puede volver a calcular todo el documento recalculando las celdas sin entrada primero y luego recalculando cada celda con la entrada lista hasta que se agoten las celdas. En este caso, primero calcularemos el precio y la cantidad del burrito, luego el precio del burrito de envío y luego un nuevo total de $ 30.

Esta simple estrategia de recalcular un documento completo puede parecer un desperdicio, pero en realidad es mejor que VisiCalc, las primeras hojas de cálculo de la historia y la primera aplicación llamada asesina que hizo populares las computadoras Apple II. VisiCalc recalculó las celdas de izquierda a derecha y de arriba a abajo muchas veces, escaneando una y otra vez, aunque ninguna de ellas cambió. A pesar de este algoritmo "interesante", VisiCalc siguió siendo el software de hoja de cálculo dominante durante cuatro años. Su reinado terminó en 1983 cuando Lotus 1-2-3 se hizo cargo del mercado con "recálculo de orden natural". Así lo describió Tracy Robnett Licklider en la revista Byte :
Lotus 1-2-3 usó el orden natural, aunque también admitió los modos de fila y columna de VisiCalc. El recálculo natural mantuvo una lista de dependencias de celda y las celdas recalculadas en función de las dependencias.
Lotus 1-2-3 implementó la estrategia de recalcular todas que se muestra arriba. Durante la primera década de desarrollo de hojas de cálculo, este fue el enfoque más óptimo. Sí, recalculamos todas las celdas del documento, pero solo una vez.
Pero ¿qué pasa con el precio de un burrito con entrega?
De Verdad. En mi ejemplo con tres burritos, no hay razón para recalcular el precio de un burrito con entrega, porque cambiar la cantidad de burritos en el pedido no puede afectar el precio del burrito. En 1989, uno de los competidores de Lotus descubrió esto y creó SuperCalc5, presumiblemente nombrándolo después de la teoría del super burrito detrás del algoritmo. SuperCalc5 recalculó "solo las celdas que dependen de las celdas cambiadas", por lo que la actualización del recuento de burritos fue algo como esto:
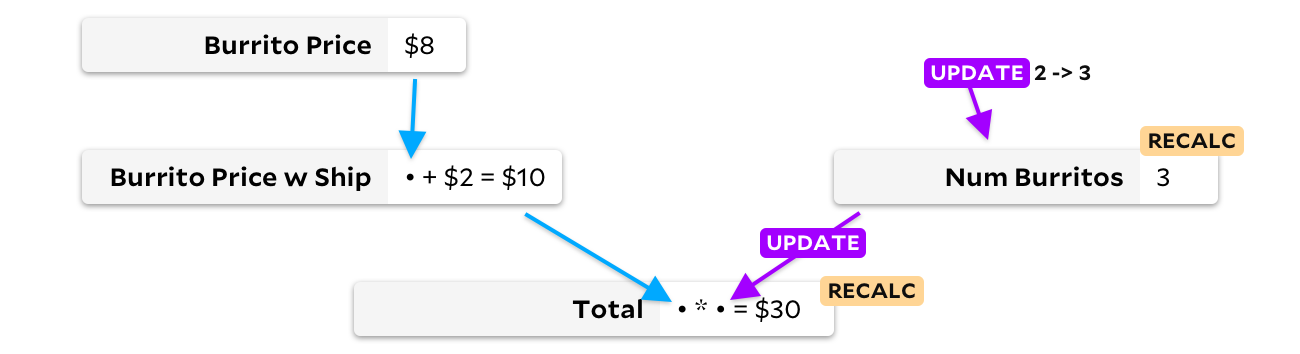
Al actualizar la celda solo cuando cambian los datos de entrada, podemos evitar volver a calcular el precio del burrito con la entrega. En este caso, solo ahorraremos una adición, ¡pero en hojas de cálculo grandes los ahorros pueden ser mucho más significativos! Desafortunadamente, ahora tenemos un problema diferente. Digamos que mis amigos ahora quieren burritos de carne, que son un dólar más caros, y El Farolito agrega $ 2 a su pedido sin importar la cantidad de burritos. Antes de recalcular algo, veamos el gráfico:
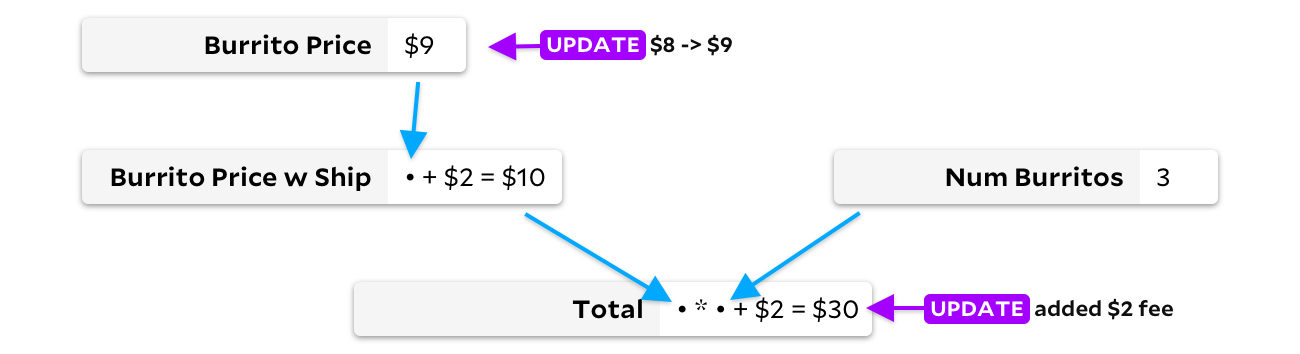
Dado que hay dos celdas actualizándose aquí, tenemos un problema. ¿Debería volver a calcular el precio de un burrito primero o el total? Idealmente, primero calculamos el precio del burrito, notamos el cambio, luego recalculamos el precio del burrito de envío y finalmente recalculamos el total. Sin embargo, si recalculamos el total primero, tendríamos que volver a calcularlo una segunda vez una vez que el nuevo precio del burrito de $ 9 se extienda por las celdas. Si no calculamos las celdas en el orden correcto, este algoritmo no es mejor que volver a calcular todo el documento. ¡Tan lento como VisiCalc en algunos casos!
Obviamente, es importante para nosotros determinar el orden correcto de actualización de las celdas. En general, existen dos soluciones a este problema: marcado sucio y clasificación topológica.
La primera solución implica etiquetar todas las celdas aguas abajo de la celda actualizada. Están marcados como sucios. Por ejemplo, cuando actualizamos el precio de un burrito, marcamos las celdas posteriores
Burrito Price w Ship
y
Total
, antes de hacer cualquier recálculo:
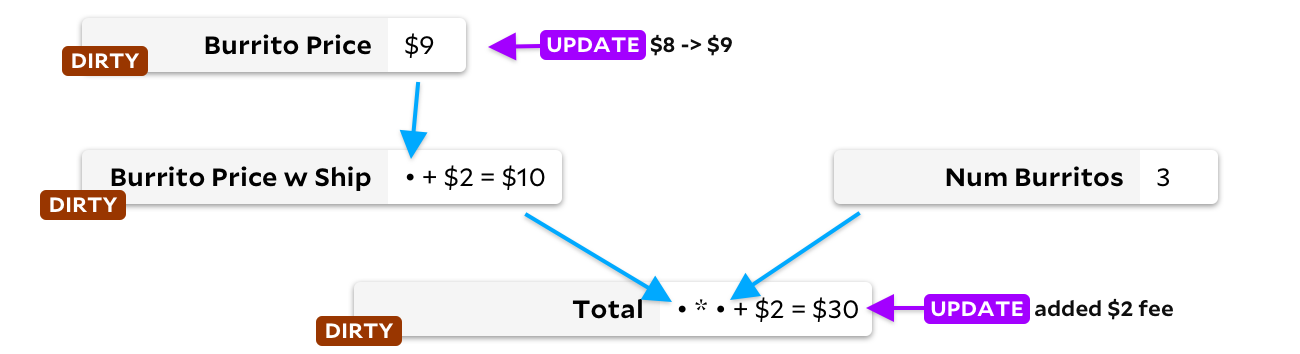
Luego, en un bucle, encontramos una celda sucia sin entradas sucias, y la recalculamos. Cuando no queden celdas sucias, ¡terminamos! Esto resuelve nuestro problema de dependencia. Sin embargo, hay un inconveniente: si se recalcula la celda y encontramos que el nuevo resultado es el mismo que el anterior, ¡seguiremos recalculando las celdas subordinadas! Un poco de lógica adicional ayudará a evitar el problema, pero desafortunadamente todavía pasamos tiempo marcando celdas y eliminando marcas.
La segunda solución es de tipo topológico. Si una celda no tiene entrada, marcamos su altura como 0. Si la tiene, marcamos la altura como el máximo de las celdas de entrada más uno. Esto asegura que cada celda tenga un valor de altura mayor que cualquiera de las celdas entrantes, por lo que solo hacemos un seguimiento de todas las celdas con la entrada modificada, siempre eligiendo la celda con la altura más baja para recalcular primero:
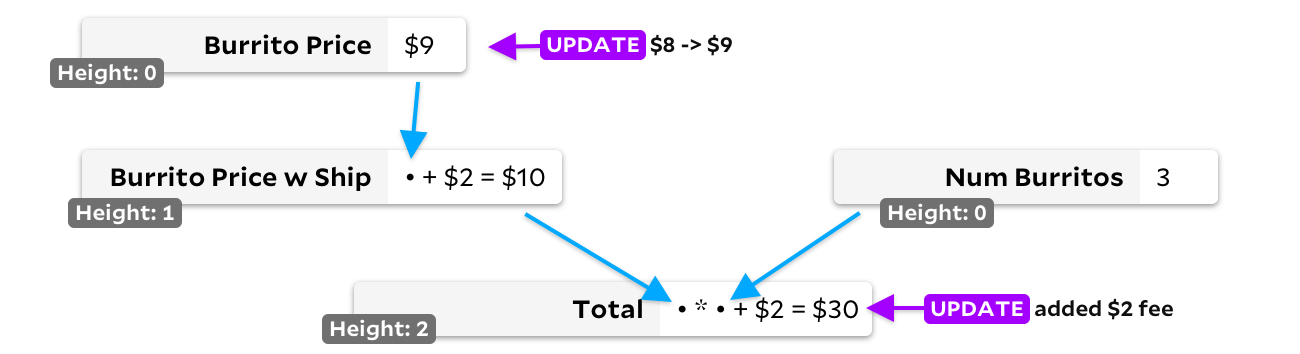
En nuestro ejemplo de actualización doble, el precio del burrito y la cantidad total se agregará inicialmente al montón de conversión. El precio del burrito es más bajo y se volverá a calcular primero. Dado que su resultado ha cambiado, luego agregaremos el precio del burrito de entrega al montón de recálculo, y dado que también tiene una altura menor que
Total
luego se volverá a calcular antes de que finalmente contamos
Total
.
Esto es mucho mejor que la primera solución: ninguna celda está marcada como sucia a menos que una de las celdas entrantes realmente cambie. Sin embargo, esto requiere almacenar celdas en orden pendiente de recalcular. Cuando se usa en el montón, esto da como resultado una desaceleración
O(n log n)
, que es asintóticamente más lenta en el peor de los casos que la estrategia recalculada de Lotus 1-2-3.
Modern Excel utiliza una combinación de contaminación y clasificación topológica ; consulte su documentación para obtener más detalles.
Evaluación perezosa
Ahora hemos logrado más o menos los algoritmos de recálculo en las hojas de cálculo modernas. Sospecho que, en principio, no existe una justificación comercial para nuevas mejoras, lamentablemente. La gente ya ha escrito suficientes fórmulas de Excel para hacer imposible la migración a cualquier otra plataforma. Afortunadamente, no soy un experto en negocios, por lo que consideraremos nuevas mejoras de todos modos.
Aparte del almacenamiento en caché, uno de los aspectos interesantes de un gráfico computacional estilo hoja de cálculo es que solo podemos calcular las celdas que nos interesan. Esto a veces se denomina evaluación diferida o cálculo impulsado por la demanda. Como ejemplo más específico, aquí hay un gráfico de hoja de cálculo de burrito ligeramente ampliado. El ejemplo es el mismo que antes, pero hemos agregado lo que se describe mejor como "cálculo de salsa". Cada burrito contiene 40 gramos de salsa y hacemos una multiplicación rápida para saber cuánta salsa hay en todo el pedido. Como tenemos tres burritos en nuestro pedido, habrá un total de 120 gramos de salsa.

Por supuesto, los lectores exigentes ya han notado el problema: el peso total de la salsa en un pedido es una métrica bastante inútil. ¿A quién le importa si son 120 gramos? ¿Qué debo hacer con esta información? Desafortunadamente, una hoja de cálculo típica gastará ciclos en cálculos de salsa, incluso si no necesitamos esos cálculos la mayor parte del tiempo.
Aquí es donde el recálculo perezoso puede ayudar. Si de alguna manera indicamos que solo nos interesa el resultado
Total
, podríamos recalcular esta celda, sus dependencias y no tocar la salsa. Llamémoslo una celda
Total
observada ya que estamos tratando de ver su resultado. También podemos llamar a
Total
tres de sus dependencias necesarias.celdas, ya que son necesarias para calcular alguna celda observada.
Salsa In Order
y
Salsa Per Burrito
llamarlo innecesario .
Para resolver este problema, algunos de los compañeros de equipo de Rust crearon el marco de Salsa , nombrándolo explícitamente después del cálculo innecesario de salsa que desperdiciaba sus ciclos de computadora. Seguro que pueden explicar mejor que yo cómo funciona. De manera muy aproximada, el marco utiliza números de revisión para realizar un seguimiento de si una celda necesita un nuevo cálculo. Cualquier mutación en una fórmula o entrada aumenta el número de revisión global y cada celda rastrea dos revisiones:
verified_at
para la revisión cuyo resultado se actualizó y
changed_at
para la revisión cuyo resultado realmente se modificó.
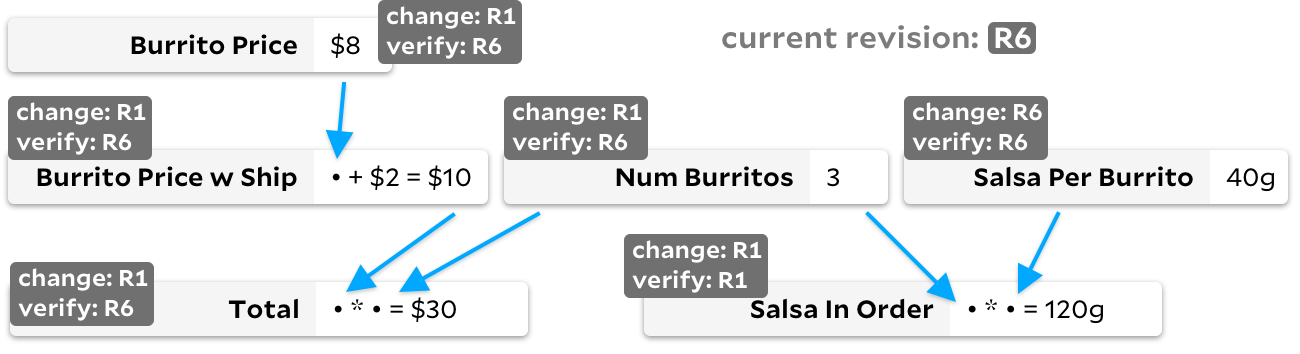
Cuando el usuario indica que necesita un nuevo valor
Total
, primero recalculamos de forma recursiva todas las celdas necesarias
Total
, omitiendo las celdas donde la revisión
last_updated
es igual a la revisión global. Una vez que se
Total
actualizan las dependencias , volvemos a ejecutar la fórmula real
Total
solo si Burrito Price w Ship o tiene una
Num Burrito
revisión
changed_at
mayor que la revisión marcada
Total
... Esto es excelente para Salsa en analizador de óxido, donde la simplicidad es importante y cada celda requiere mucho tiempo para calcular. Sin embargo, en el gráfico con el burrito anterior, puede notar los inconvenientes: si
Salsa Per Burrito
cambia constantemente, entonces nuestro número de revisión global a menudo aumentará. Como resultado, cada observación
Total
requeriría atravesar tres celdas, incluso si ninguna de ellas cambia. No se volverá a calcular ninguna fórmula, pero si el gráfico es grande, la iteración a través de todas las dependencias de celda puede resultar costosa.
Opciones más rápidas para una evaluación perezosa
En lugar de inventar nuevos algoritmos perezosos, probemos los dos algoritmos clásicos de hoja de cálculo mencionados anteriormente: etiquetado y clasificación topológica. Como puede imaginar, el modelo perezoso complica ambas tareas, pero ambas siguen siendo viables.
Veamos primero las marcas. Como antes, cuando cambiamos la fórmula de una celda, marcamos todas las celdas posteriores como sucias. Entonces, al actualizar,
Salsa Per Burrito
se verá así:

pero en lugar de recalcular inmediatamente todas las celdas sucias, esperamos hasta que el usuario observe la celda. Luego ejecutamos el algoritmo Salsa en él, pero en lugar de volver a verificar las dependencias con números de versión desactualizados
verified_at
, solo volvemos a verificar las celdas que están marcadas como sucias. Adapton utiliza esta técnica . En tal situación, observar la celda
Total
revela que no está sucia y, por lo tanto, ¡podemos omitir la pasada gráfica que habría realizado Salsa!
Si lo observa
Salsa In Order
, entonces está marcado como sucio y, por lo tanto, volveremos a verificar y recalcularemos y
Salsa Per Burrito
, y
Salsa In Order
. Incluso aquí, existen ventajas sobre el uso de solo números de revisión, ya que podemos saltar recursivamente a través de una celda aún en blanco
Num Burritos
.
El etiquetado sucio perezoso funciona fantástico para cambiar con frecuencia el conjunto de células que estamos tratando de observar. Desafortunadamente, tiene las mismas desventajas que el anterior algoritmo de marcado sucio. Si una celda con muchas celdas descendentes cambia, entonces pasamos mucho tiempo marcando las celdas y desmarcando, incluso si la entrada no cambia realmente cuando vamos al recálculo. En el peor de los casos, cada cambio conduce al hecho de que marcamos todo el gráfico como sucio, lo que nos da aproximadamente el mismo orden de rendimiento que el algoritmo Salsa.
Además del etiquetado sucio, también podemos adaptar la clasificación topológica para una evaluación perezosa. Este método usa la biblioteca incrementalde Jane Street, y se necesitan algunos trucos serios para que funcione correctamente. Antes de implementar la evaluación diferida, nuestro algoritmo de clasificación topológica usó un montón para determinar qué celda recalcular a continuación. Pero ahora queremos volver a calcular solo las celdas necesarias. ¿Cómo? No queremos caminar todo el árbol desde las células observadas como Adapton, ya que un paseo completo a través del árbol destruye todo el propósito del tipo topológico y nos da características de rendimiento similares a Adapton.
En su lugar, Incremental mantiene un conjunto de celdas que el usuario ha marcado como observadas, así como el conjunto de celdas necesarias para cualquier celda observada. Siempre que una celda se marca como observable o no observable, Incremental recorre las dependencias de esa celda para asegurarse de que las etiquetas requeridas se apliquen correctamente. Luego, agregamos celdas al montón de recálculo solo si están marcadas como necesarias. En nuestro gráfico de burrito, siempre que
Total
sea parte de un conjunto observable, el cambio
Salsa in Order
no resultará en ningún paso a través del gráfico, ya que solo se recalculan las celdas necesarias: ¡

Esto resuelve nuestro problema sin que los impacientes anden por el gráfico para marcar celdas como sucias! Aún debemos recordar que la celda
Salsa per Burrito
Es complicado contarlo más tarde si es necesario. Pero a diferencia del algoritmo de Adapton, no es necesario que apliquemos esa única etiqueta sucia en todo el gráfico.
Anchors, una solución híbrida
Tanto Adapton como Incremental recorren el gráfico incluso si no vuelven a calcular las celdas. Incremental recorre el gráfico cuando cambia el conjunto de celdas observadas y Adapton recorre el gráfico cuando cambia la fórmula. Con gráficos pequeños, el alto costo de estas pasadas puede no ser evidente de inmediato. Pero si el gráfico es grande y las celdas son relativamente baratas de calcular, a menudo este es el caso de las hojas de cálculo, encontrará que la mayor parte del cálculo se desperdicia en caminar innecesariamente alrededor del gráfico. Cuando las celdas son baratas, etiquetar un poco en una celda puede costar aproximadamente lo mismo que simplemente recalcular una celda desde cero. Por lo tanto, idealmente, si queremos que nuestro algoritmo sea significativamente más rápido que un simple cálculo, deberíamos evitar caminar innecesariamente alrededor del gráfico tanto como sea posible.
Cuanto más pensaba en este problema, más me di cuenta de que están perdiendo el tiempo recorriendo el gráfico en situaciones más o menos opuestas. En nuestro gráfico de burrito, imaginemos que las fórmulas de las celdas rara vez cambian, pero cambiamos rápidamente, observando primero
Total
y luego
Salsa in Order
.
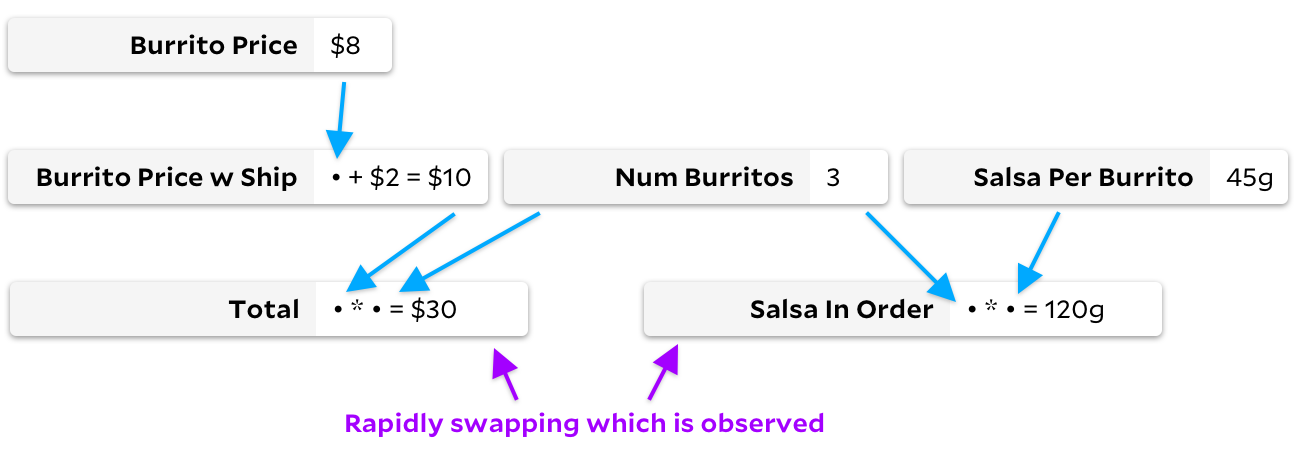
En este caso, Adapton no caminará por el árbol. Ninguno de los datos de entrada cambia y, por lo tanto, no es necesario marcar ninguna celda. Dado que no hay nada marcado, cada observación es barata porque podemos devolver inmediatamente el valor almacenado en caché desde una celda en blanco. Sin embargo, Incremental no funciona bien en este ejemplo. Aunque no se recalculan valores, Incremental marcará y desmarcará repetidamente muchas celdas según sea necesario o innecesario.
De lo contrario, imaginemos un gráfico en el que nuestras fórmulas cambian rápidamente, pero no cambiamos la lista de celdas observadas. Por ejemplo, podríamos imaginarnos observando
Total
cambiando rápidamente el precio de un burrito de
4+4
a
2*4
.
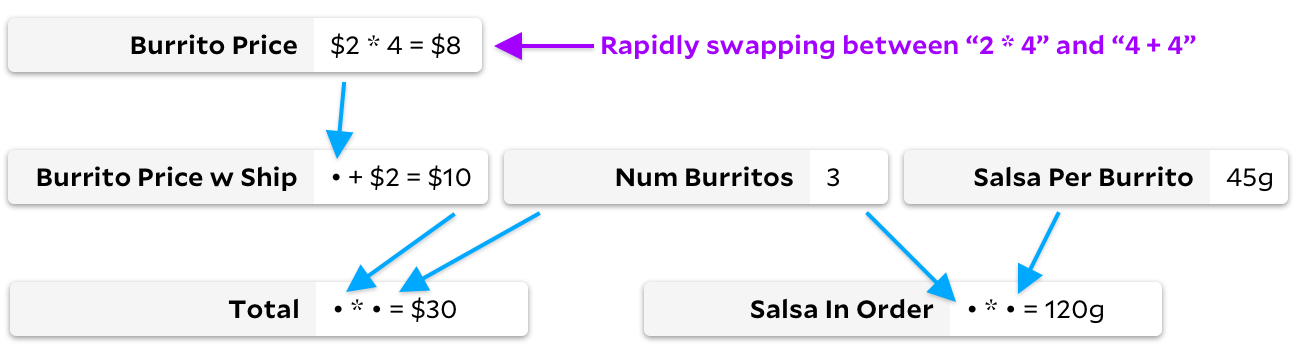
Como en el ejemplo anterior, en realidad no recalculamos muchas celdas:
4+4
y
2*4
es igual a
8
, por lo que idealmente solo recalculamos esta aritmética cuando el usuario realiza este cambio. Pero a diferencia del ejemplo anterior, Incremental ahora evita caminar por los árboles. Con Incremental, hemos almacenado en caché el hecho de que el precio del burrito es una celda obligatoria, por lo que cuando cambia, podemos volver a calcularlo sin pasar por el gráfico. Con Adapton, perdemos tiempo marcando
Burrito Price w Ship
y
Total
desordenado, incluso si el resultado
Burrito Price
no cambia.
Dado que cada algoritmo funciona bien en los casos degenerados del otro, ¿por qué no idealmente simplemente detectar esos casos degenerados y cambiar a un algoritmo más rápido? Esto es lo que intenté implementar en mi propia biblioteca. Anclas . ¡Ejecuta ambos algoritmos simultáneamente en el mismo gráfico! Si suena loco, innecesario y demasiado complicado, probablemente sea porque lo es.
En muchos casos, los Anchors siguen exactamente el algoritmo incremental, evitando así el caso Adapton degenerado anterior. Pero cuando las células se marcan como no observables, su comportamiento diverge ligeramente. Veamos qué está pasando. Comencemos por marcarla
Total
como una celda observada:
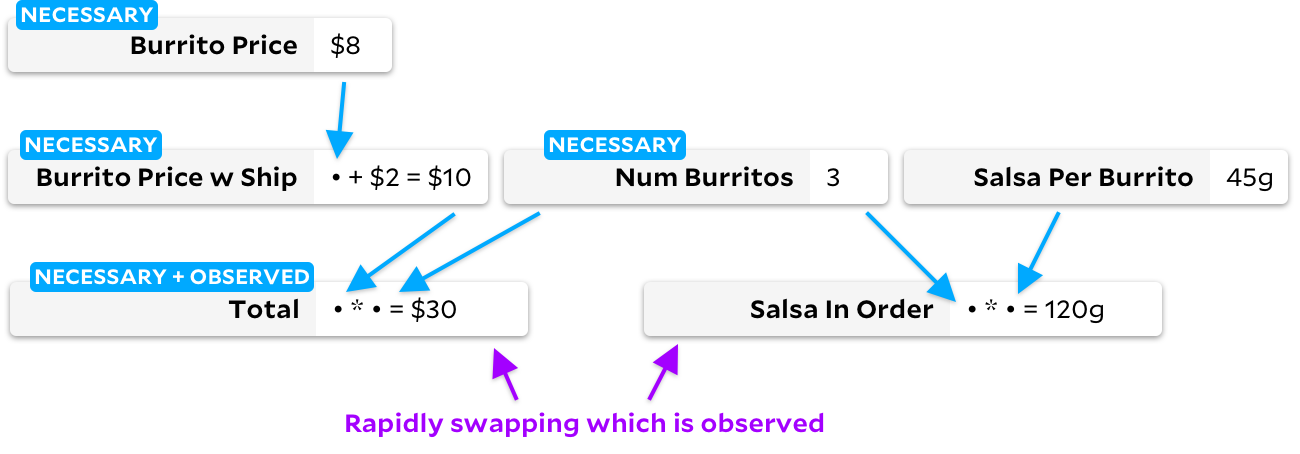
si luego la marcamos
Total
como una celda no observable, y
Salsa in Order
como una observable, el algoritmo incremental tradicional cambiará el gráfico, pasando por todas las celdas en el proceso: los
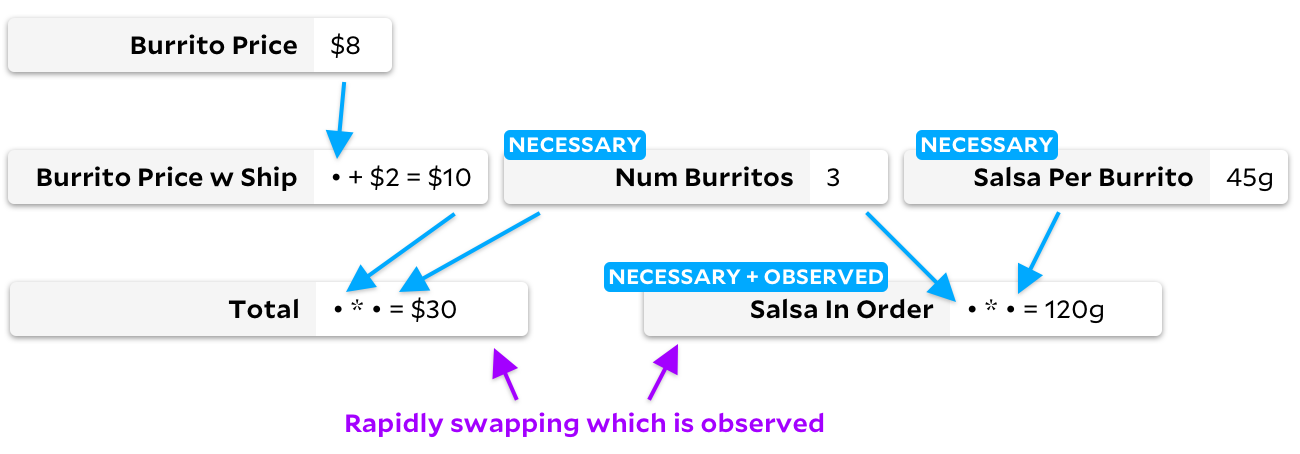
anclajes para este cambio también pasa por todas las celdas, pero crea otro gráfico:
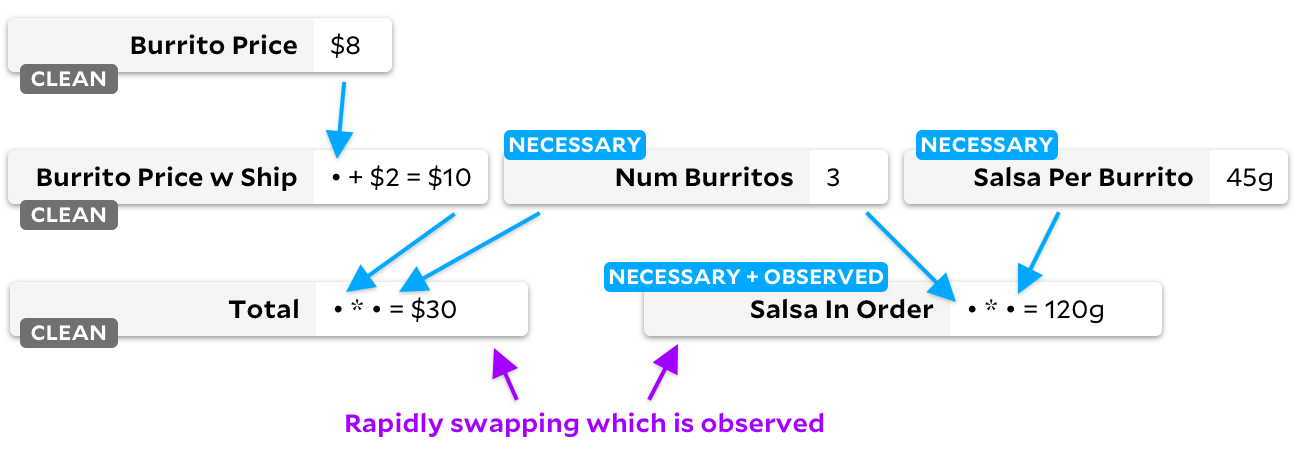
¡Preste atención a las banderas de las células "limpias"! Cuando una celda ya no es necesaria, la marcamos como en blanco. Veamos qué sucede cuando pasamos de la observación
Salsa in Order
a
Total
:
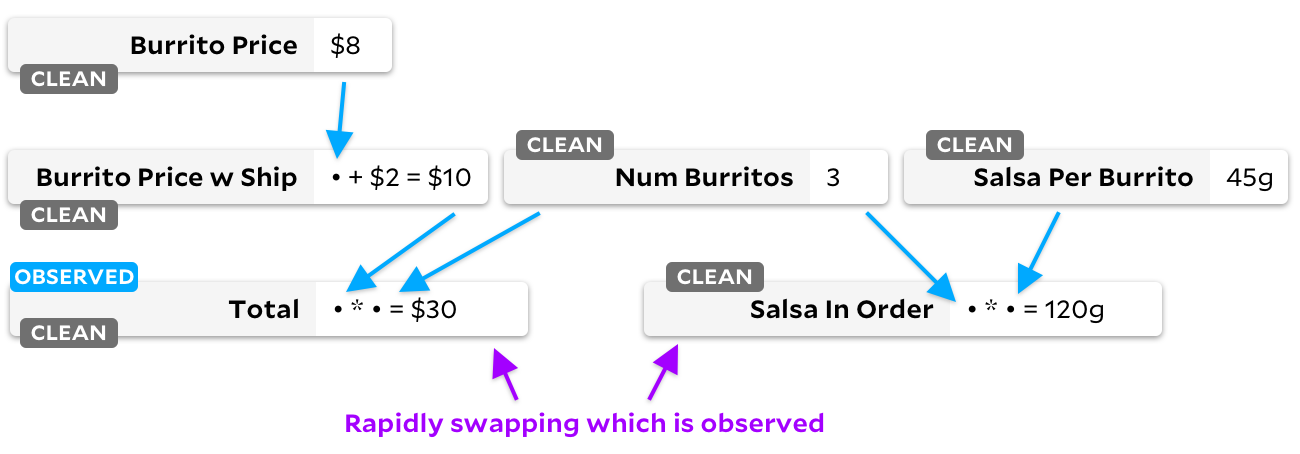
Derecha: nuestro gráfico ahora no tiene celdas "necesarias". Si una celda tiene una bandera "limpia", nunca la marcamos como observable. A partir de ahora, no importa qué celda marquemos como observada o no, Anchors nunca perderá el tiempo recorriendo el gráfico; sabe que ninguna de las entradas ha cambiado.
¡Parece que El Farolito ha anunciado un descuento! Reduzcamos el precio del burrito en un dólar. ¿Cómo sabe Anchors volver a calcular la cantidad? Antes de cualquier nuevo cálculo, veamos cómo Anchors ve el gráfico inmediatamente después de que cambie el precio del burrito:

si la celda tiene una bandera clara, ejecutamos el algoritmo Adapton tradicional en ella, marcando voluntariamente las celdas posteriores como sucias. Cuando más tarde ejecutamos el algoritmo incremental, podemos decir rápidamente que hay una celda observable marcada como sucia y sabemos que tenemos que volver a calcular sus dependencias. El gráfico final se verá así:
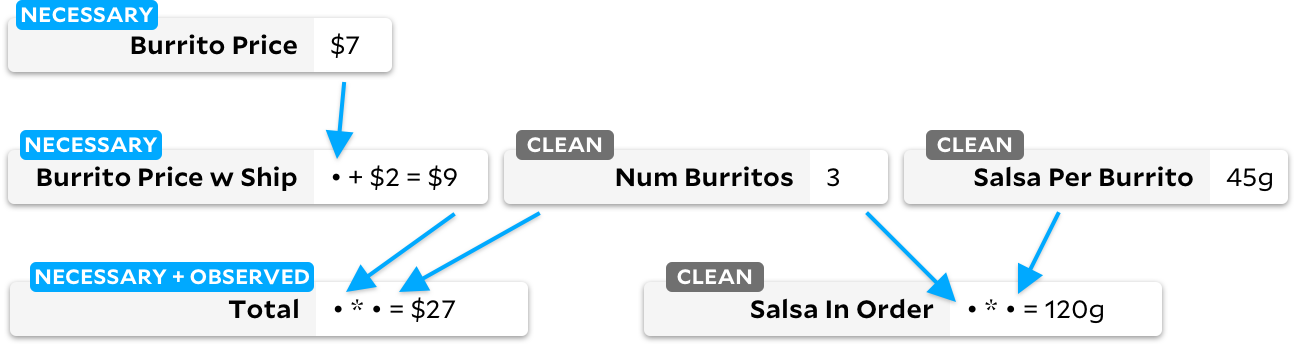
Recalculamos las celdas solo cuando es necesario, por lo que siempre que recalculamos una celda sucia, también la marcamos según sea necesario. En un nivel alto, puede pensar en estos tres estados de las celdas como una máquina de estados cíclicos:

En las celdas requeridas, ejecute el algoritmo de clasificación topológica incremental. En el resto, ejecutamos el algoritmo Adapton.
Sintaxis de burrito
En conclusión, me gustaría responder a la última pregunta: hasta ahora, hemos discutido muchos problemas que causa el modelo perezoso para nuestra estrategia de recálculo de tablas. Pero los problemas no están solo en el algoritmo: también hay problemas sintácticos. Por ejemplo, vamos a armar una mesa para elegir un burrito emoji para nuestro cliente. Nos gustaría escribir una declaración
IF
en una tabla como esta:

dado que las hojas de cálculo tradicionales no son perezosas, podemos calcular
B1
,
B2
y
B3
en cualquier orden, y luego calcular la celda
IF
... Sin embargo, en un mundo perezoso, si podemos calcular primero el valor de B1, podemos mirar el resultado para averiguar qué valor debe recalcularse: B2 o B3. Desafortunadamente, las hojas de cálculo tradicionales
IF
no pueden expresar esto.
Problema:
B2
simultáneamente hace referencia a una celda
B2
y recupera su valor. La mayoría de las bibliotecas perezosas mencionadas en el artículo distinguen explícitamente entre una referencia de celda y el acto de recuperar su valor real. En Anchors lo llamamos ancla de referencia de celda. Al igual que en la vida real, un burrito envuelve un montón de ingredientes, un tipo
Anchor<T>
envuelve
T
. Así que supongo que nuestra celda de burrito vegano se convierte
Anchor<Burrito>
, una especie de burrito ridículo. Las funciones pueden transferir las nuestras
Anchor<Burrito>
tanto como quieran. Pero cuando realmente desenvuelven el burrito para acceder al
Burrito
interior, creamos un borde de dependencia en nuestro gráfico, lo que indica al algoritmo de recálculo que la celda puede ser necesaria y necesita un nuevo cálculo.
El enfoque adoptado por Salsa y Adapton es utilizar llamadas a funciones y el flujo de control normal como una forma de expandir estos valores. Por ejemplo, en Adapton, podríamos escribir la celda Burrito for Customer algo como esto:
let burrito_for_customer = cell!({
if get!(is_vegetarian) {
get!(vegi_burrito)
} else {
get!(meat_burrito)
}
});
Al distinguir entre una referencia de celda (aquí
vegi_burrito
) y el acto de expandir su valor (
get!
), Adapton puede ejecutarse sobre declaraciones de flujo de control de Rust como
if
. ¡Esta es una gran solución! Sin embargo, se necesita un poco de estado global mágico para conectar correctamente las llamadas
get!
a las celdas
cell!
cuando se cambia
is_vegetarian
. La biblioteca de Anclas con influencia incremental adopta un enfoque menos mágico. Al igual que async-pre / await
Future
, Anchors permite iniciar
Anchor<T>
operaciones como
map
y
then
. Entonces, el ejemplo anterior se vería así:
let burrito_for_customer: Anchor<Burrito> = is_vegetarian.then(|is_vegetarian: bool| -> Anchor<Burrito> {
if is_vegetarian {
vegi_burrito
} else {
meat_burrito
}
});
Otras lecturas
En este artículo ya largo y florido, no había suficiente espacio para tantos temas. Con suerte, estos recursos pueden arrojar un poco más de luz sobre este problema tan interesante.
- Siete implementaciones de Incremental , una gran mirada en profundidad a los aspectos internos de Incremental, así como un montón de optimizaciones como alturas en constante aumento de las que no tuve tiempo de hablar, además de formas inteligentes de manejar las celdas de cambio de dependencia. También vale la pena leer de Ron Minsky: FRP Parsing .
- Video que explica cómo funciona la salsa.
- Este es un boleto de salsa donde Matthew Hammer, creador de Adapton, explica pacientemente los cortes a un transeúnte aleatorio (yo) que no tiene idea de cómo funcionan.
- Rustlab . , « » «: DX CS» — .
- , « », Materialize. , . , (!) « », , . Noira .
- Adapton .
- Resulta que esta forma de pensar también se aplica a los sistemas de construcción . Este es uno de los primeros artículos científicos sobre las similitudes entre los sistemas de compilación y las hojas de cálculo.
- El trazado de rayos ligeramente incremental es un trazado de rayos ligeramente incremental escrito en Ocaml.
- Solo miré "Estado parcial en vistas materializadas basadas en flujo de datos" y parece relevante.
- Skip e Imp también se ven muy interesantes.
Y, por supuesto, siempre puedes consultar mi marco de Anchors .