
Que está sucediendo en el campo de las redes condicionales sin pérdidas
A lo largo de los años, cuando los medios de transmisión de datos experimentaron un rápido desarrollo, los ingenieros lograron encontrar muchos fenómenos que dificultan la implementación exitosa de redes de almacenamiento y clústeres informáticos de alto rendimiento en Ethernet: pérdidas, entrega de información no garantizada, interbloqueos, microrráfagas y otras cosas desagradables.
Como resultado, se consideró correcto construir una red dedicada de referencia para un escenario específico:
- IB para clústeres de informática de alta carga;
- FC para red de almacenamiento clásica;
- Ethernet para tareas de servicio.
Los intentos de lograr versatilidad se parecían a la ilustración.

Para algunas tareas, los vectores pudieron coincidir (similar al de un cisne y un cangrejo de río), y se logró la versatilidad situacional, aunque con menor eficiencia que al elegir un escenario altamente especializado.
Hoy, Huawei ve el futuro en las fábricas convergentes multitarea y ofrece a sus clientes una solución AI Fabric diseñada, por un lado, para escenarios de aumento del rendimiento de la red sin pérdidas (hasta 200 Gbps por puerto del servidor en 2020), por otro lado, para aumentar el rendimiento del aplicaciones (migración a RoCEv2).
Por cierto, teníamos una publicación detallada separada sobre el componente técnico de AI Fabric .
Qué necesita optimización
Antes de hablar de algoritmos, tiene sentido aclarar para qué están diseñados exactamente para mejorar.
La ECN estática lleva al hecho de que con un aumento en el número de servidores remitentes con un solo destinatario, surge una imagen de tráfico subóptima (para decirlo suavemente, estamos tratando con el llamado modelo de incast de muchos a uno).
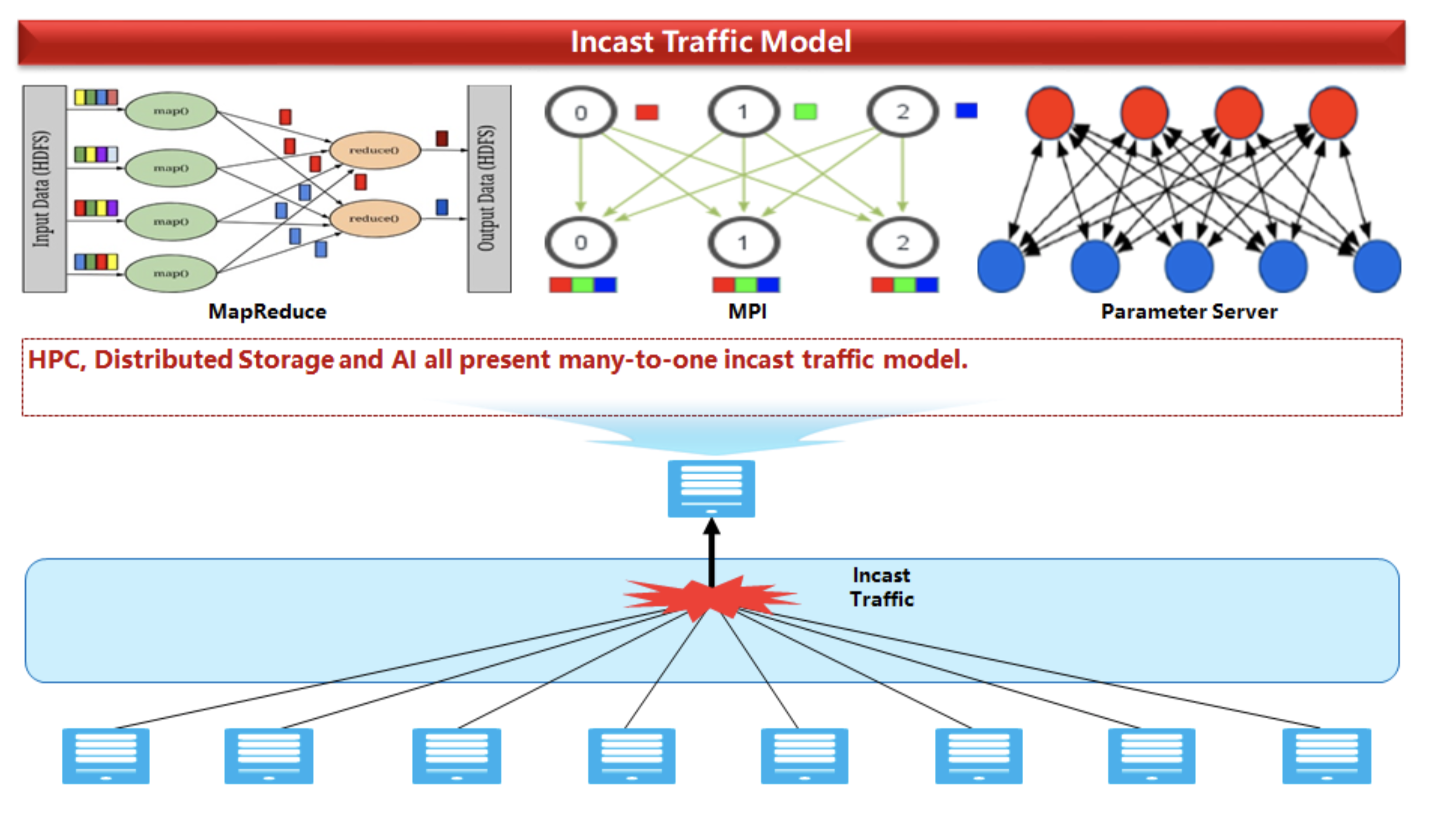
En Ethernet tradicional , tenemos que equilibrar manualmente las probabilidades de pérdida en la red y el bajo rendimiento de la propia red.

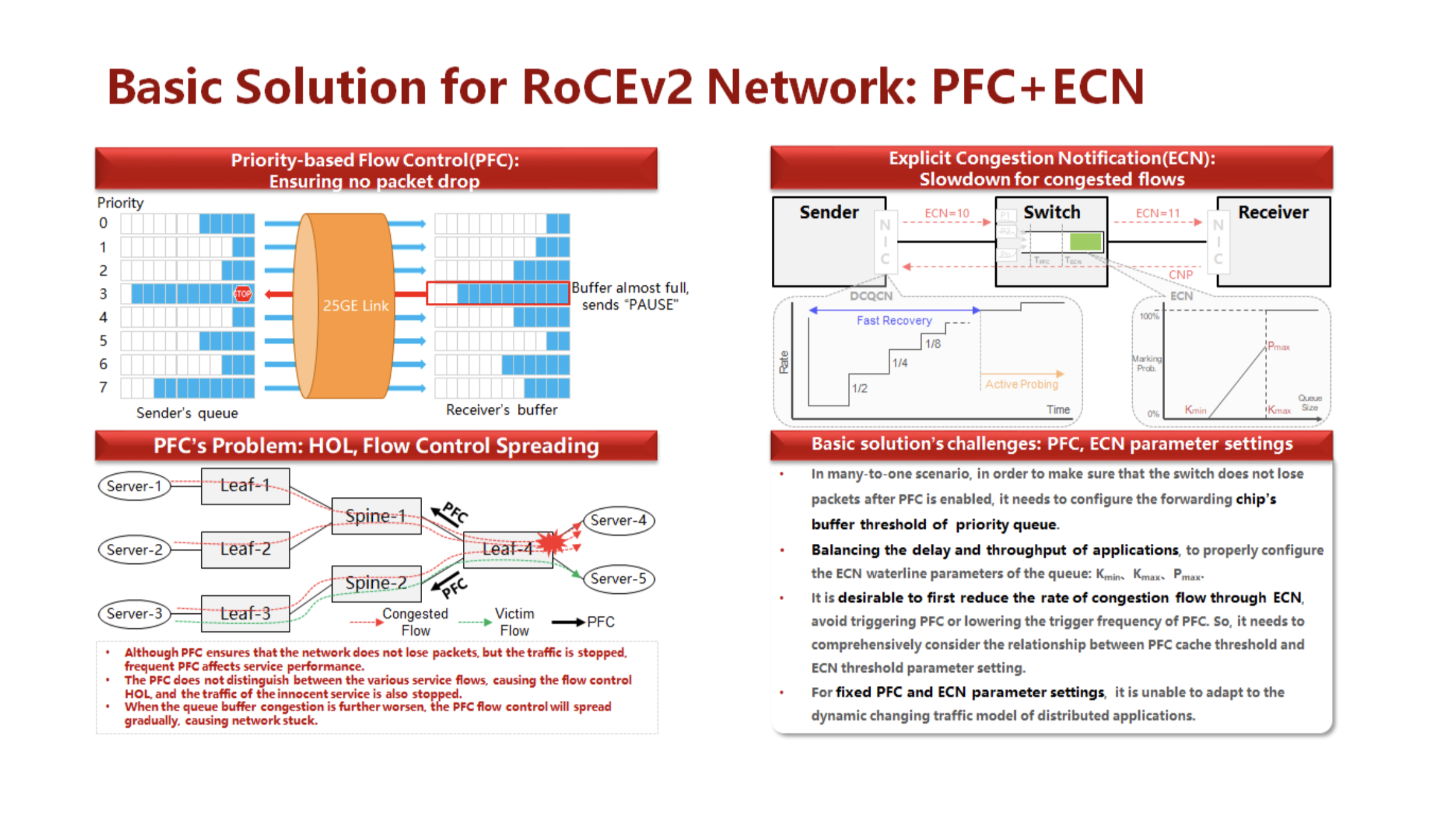
También veremos los mismos requisitos previos al usar el paquete PFC / ECN en el caso de implementación sin ajuste constante (ver la figura siguiente).
Para resolver los problemas descritos, utilizamos el algoritmo AI ECN, cuya esencia es cambiar los umbrales ECN de manera oportuna. Su aspecto se muestra en el siguiente diagrama.
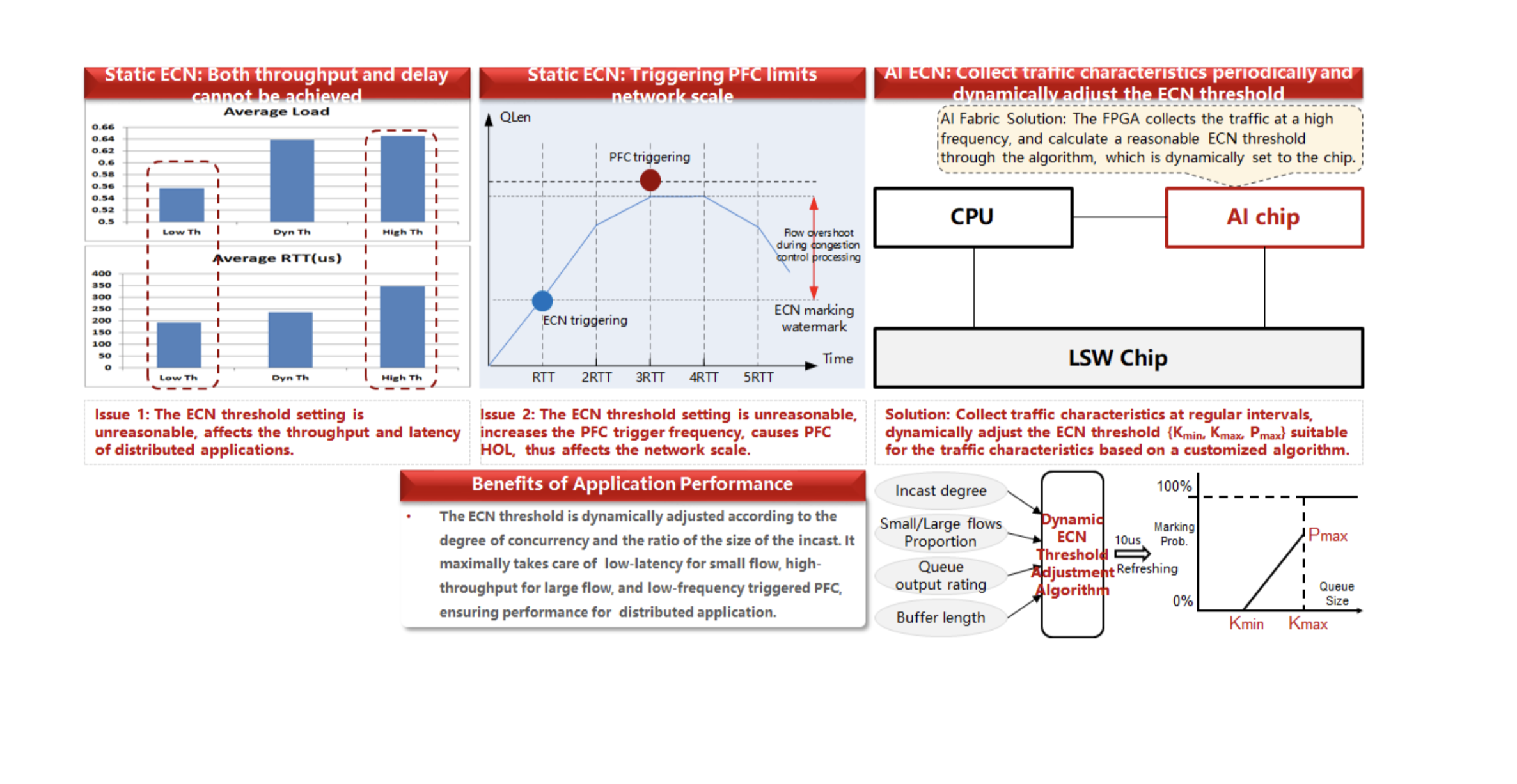
Anteriormente, cuando usamos el conjunto de chips Broadcom + el paquete de procesador Ascend 310 AI, teníamos un número limitado de opciones para ajustar dichos parámetros.
Podemos llamar condicionalmente a tal variante Software AI ECN, ya que la lógica se realiza en un chip separado y ya está "derramado" en un chipset comercial.Los modelos equipados con el chipset Huawei P5 tienen "capacidades de IA" mucho más amplias (especialmente en la última versión), debido al hecho de que implementa una parte significativa de la funcionalidad necesaria para ello.

Cómo usamos los algoritmos
Usando el Ascend 310 (o el módulo integrado de la tarjeta P), comenzamos a analizar el tráfico y lo comparamos con un punto de referencia de aplicaciones conocidas.

En el caso de aplicaciones conocidas, los indicadores de tráfico se optimizan sobre la marcha, en el caso de aplicaciones desconocidas, se lleva a cabo la transición al siguiente paso.

Puntos clave:
- Se lleva a cabo el aprendizaje reforzado de DDQN, la exploración, la acumulación de muchas configuraciones de referencia y la exploración de la mejor estrategia de cumplimiento de ECN.
- El clasificador de CNN identifica escenarios y determina si el umbral de DDQN recomendado es confiable.
- Si el umbral de DDQN recomendado no es confiable, se utiliza un método heurístico para corregirlo y garantizar que la solución sea generalizada.
Este enfoque le permite ajustar los mecanismos para trabajar con aplicaciones desconocidas y, si realmente lo desea, puede establecer un modelo para su aplicación utilizando la API de Northbound para el sistema de administración de conmutadores.

Puntos clave:
- DDQN acumula una gran cantidad de muestras de memoria de configuración de línea base y examina en profundidad el estado de la red y la lógica de reconciliación de la configuración de línea base para aprender las políticas.
- El clasificador de redes neuronales de CNN identifica escenarios para evitar los riesgos que pueden surgir cuando se recomiendan configuraciones ECN no confiables en escenarios desconocidos.
Que obtenemos
Después de tal ciclo de adaptación y de cambiar los umbrales y configuraciones de red adicionales, es posible eliminar varios tipos de problemas a la vez.
- Problemas de rendimiento: ancho de banda bajo, latencia larga, pérdida de paquetes, jitter.
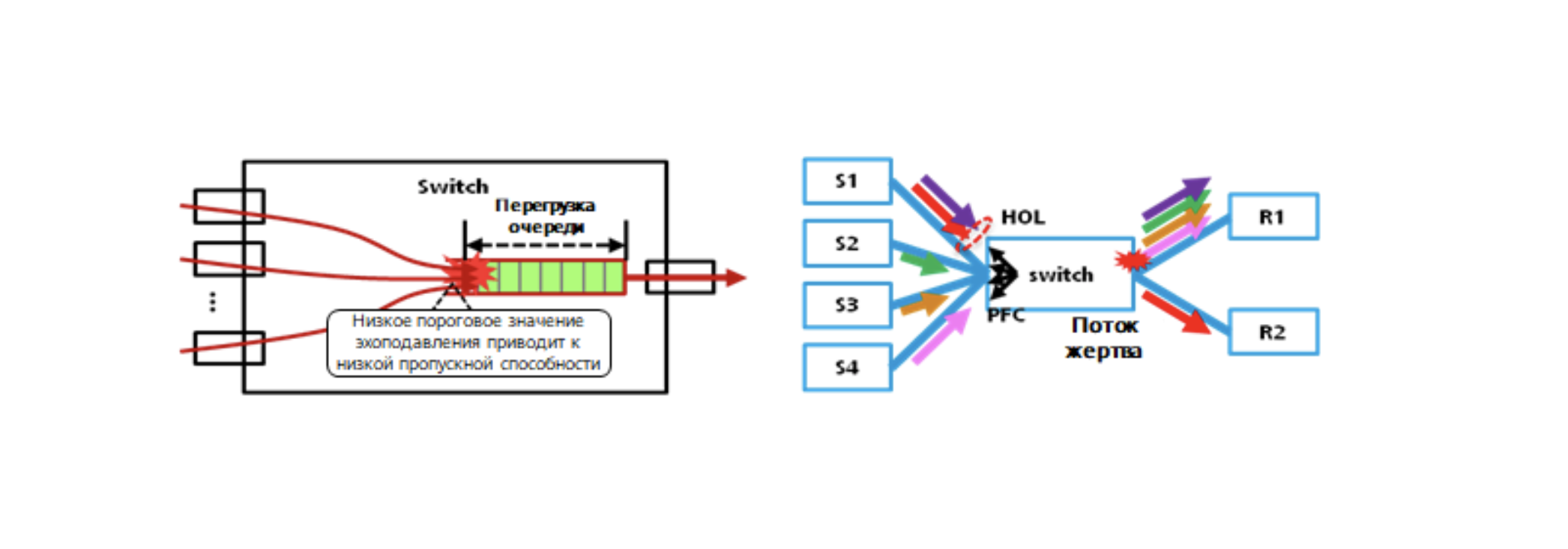
- Problemas de PFC: interbloqueo de PFC, HOL, tormentas, etc. La tecnología PFC causa muchos problemas a nivel del sistema.
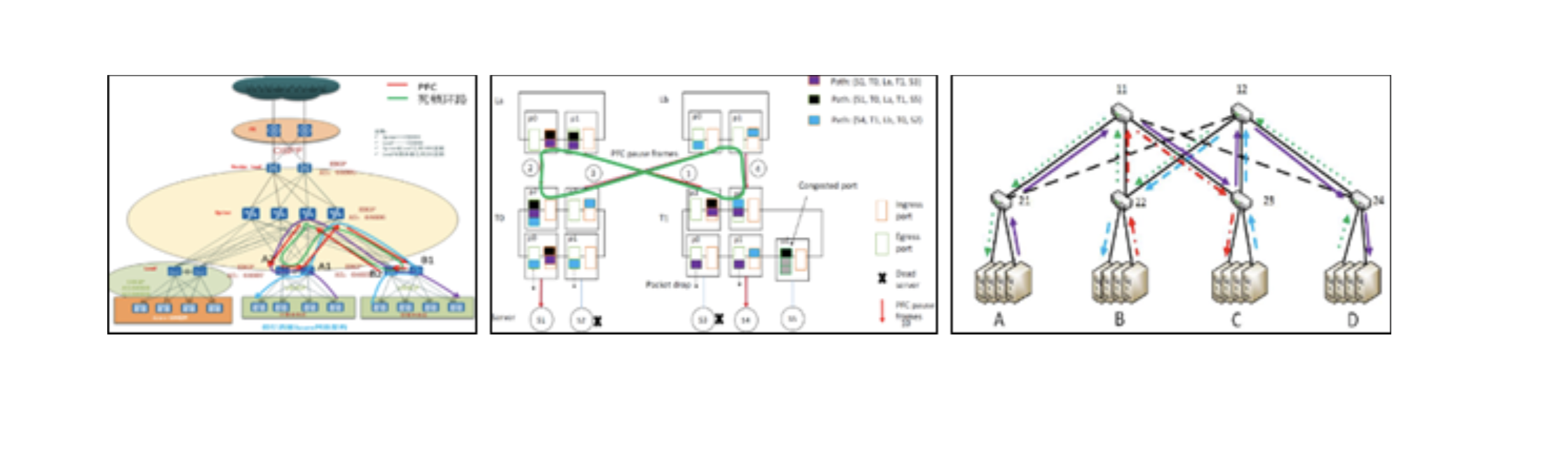
- Desafíos de la aplicación RDMA: IA / Computación de alto rendimiento, almacenamiento distribuido y combinaciones. Las aplicaciones RDMA son sensibles al rendimiento de la red.
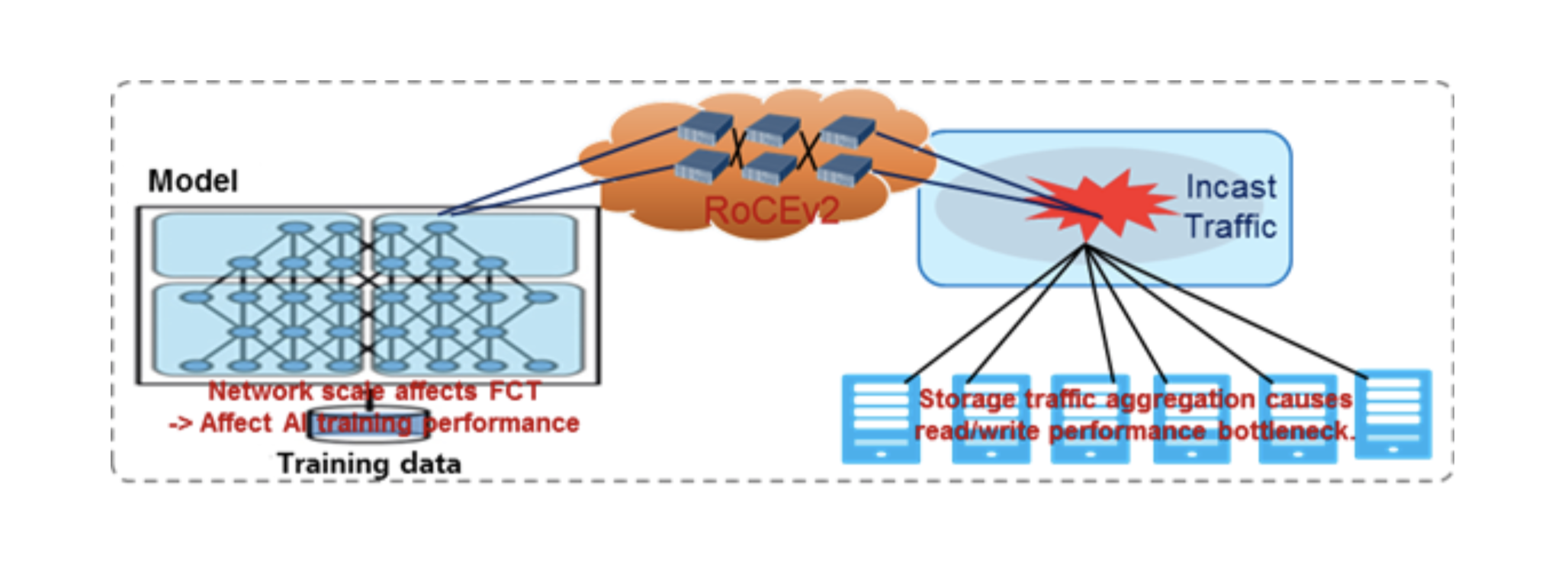
Resumen
En última instancia, los algoritmos de aprendizaje automático adicionales nos ayudan a resolver los problemas clásicos del entorno de red Ethernet "que no responde". Por lo tanto, estamos un paso más cerca de un ecosistema de servicios de red de extremo a extremo transparentes y convenientes, en contraposición a un conjunto de tecnologías y productos dispares.
***
Las soluciones de Huawei continúan apareciendo en nuestra biblioteca en línea . Incluyendo los temas cubiertos en esta publicación (por ejemplo, antes de construir soluciones de IA de tamaño completo para varios escenarios de centros de datos "inteligentes"). Puede encontrar una lista de nuestros seminarios web para las próximas semanas aquí .