
- ¿Qué es exactamente lo que consume tanta memoria?
- Hay alguna manera de evitar esto?
Aquí quiero hablar sobre cómo estaba buscando respuestas a estas preguntas. Planeo usar este material como referencia siempre que necesite perfilar el código Python.
Comencé a analizar Pylint, comenzando en el punto de entrada del programa (
pylint/__main__.py), y llegué al ciclo "fundamental" forque esperarías en un programa que verifica varios archivos:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Para empezar, solo coloco una declaración en este ciclo
print(«HI»)para asegurarme de que este es realmente el ciclo que comienza cuando ejecuto el comando pylint my_code. Este experimento se desarrolló sin problemas.
A continuación, decidí averiguar qué se almacena exactamente en la memoria durante el trabajo de Pylint. Así que lo usé
heapye hice un simple "volcado de pila", con la esperanza de analizar este volcado para detectar algo inusual:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
El perfil de montón terminó consistiendo casi en su totalidad en marcos de pila de llamadas (
types.FrameType). Yo, por alguna razón, esperaba algo como esto. Tal cantidad de tales objetos en el basurero me hizo pensar que parece haber más de ellos de los que debería haber.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
Fue en este momento que encontré la herramienta Profile Browser , que le permite trabajar cómodamente con dichos datos.
Configuré el motor de volcado para que los datos se escribieran en un archivo cada 10 iteraciones de bucle. Luego construí un diagrama que muestra el comportamiento del programa durante la operación.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
Terminé con lo que se muestra a continuación. Este diagrama confirma que los objetos
type.FrameTypey type.TracebackType(información de seguimiento) consumieron mucha memoria durante la ejecución de Pylint investigada.

Análisis de datos
La siguiente etapa del estudio fue el análisis de objetos
types.FrameType. Dado que los mecanismos de gestión de memoria en Python se basan en contar el número de referencias a objetos, los datos se mantienen en la memoria siempre que algo se refiera a ellos. Decidí averiguar qué es exactamente lo que "contiene" los datos en la memoria.
Aquí utilicé una excelente biblioteca
objgraphque, usando las capacidades del administrador de memoria de Python, brinda información sobre qué objetos están en la memoria y te permite averiguar qué se refiere exactamente a estos objetos.
De hecho, es genial que tengamos la capacidad de hacer este tipo de investigación de software. Es decir, si hay una referencia a un objeto, puede encontrar todo lo que se refiere a este objeto (en el caso de las extensiones C, no todo es tan sencillo, pero, en general,
objgraphproporciona información razonablemente precisa). Tenemos ante nosotros una excelente herramienta para depurar código, dando acceso a un montón de información sobre los mecanismos internos de CPython. Para mí, esta es otra razón para pensar en Python como un lenguaje agradable para trabajar.
Al principio, tropecé con la búsqueda de objetos, ya que el equipo
objgraph.by_type('types.TracebackType')no encontró nada en absoluto. Y esto a pesar de que sabía que hay una gran cantidad de tales objetos. Resultó que se debería utilizar una cadena como nombre de tipo traceback. La razón de esto no está del todo clara para mí, pero lo que es, eso es. El comando correcto, al final, se ve así:
random.choice(objgraph.by_type('traceback'))
Esta construcción selecciona objetos al azar
traceback. Y con la ayuda objgraph.show_backrefspuedes construir un diagrama de lo que se refiere a estos objetos.
Al final, en lugar de lanzar una excepción, decidí investigar qué sucede en el bucle
for( import pdb; pdb.set_trace()) después de 100 iteraciones. Empecé a estudiar objetos seleccionados al azar traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Inicialmente, solo vi cadenas de objetos
traceback, así que decidí escalar a una profundidad de 100 objetos ...

Análisis de objetos de rastreo
Como resultó, algunos objetos se
tracebackrefieren a otros objetos del mismo tipo. Muy bueno. Y había muchas de esas cadenas.
Durante algún tiempo, sin mucho éxito para el negocio, los estudié y luego pasé al estudio de objetos del segundo tipo de interés para mí -
FrameType(frame). También parecían sospechosos. Al analizarlos, llegué a diagramas que se parecen al siguiente.

Analizar objetos de marco
Resulta que los objetos
tracebackcontienen objetosframe(por lo que hay un número similar de tales objetos). Todo esto, por supuesto, parece extremadamente confuso, pero los objetosframeal menos apuntan a líneas específicas de código. Todo esto me llevó a darme cuenta de una cosa ridículamente simple: nunca me molesté en mirar datos usando cantidades tan grandes de memoria. Definitivamente debería mirar los objetos en sítraceback.
Caminé hacia esta meta, al parecer, el más tortuoso de todos los caminos posibles. Es decir, reconoció las direcciones en el volcado creado por
objgraph, luego miró las direcciones en la memoria, luego buscó en Internet "cómo obtener un objeto Python, conociendo su dirección". Después de todos estos experimentos, se me ocurrió el siguiente esquema de acciones:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
De hecho, puede decirle a Python: “Mira este recuerdo. Definitivamente hay al menos un objeto Python normal aquí ".
Más tarde me di cuenta de que ya tenía enlaces a objetos de mi interés gracias a
objgraph. Es decir, podría usarlos. Parecía que
la biblioteca
astroid, el analizador AST utilizado en Pylint, estaba creando objetos en todas partes a tracebacktravés del código de manejo de excepciones. Creo que cuando alguien usa algo que se puede llamar un "truco interesante" en algún lugar, simultáneamente se olvida de cómo se puede hacer lo mismo con mayor facilidad. Así que realmente no me quejo de eso.
Los objetos
tracebacktienen muchos datos relacionados con astroid. ¡Ha habido algunos avances en mi investigación! Bibliotecaastroides bastante similar a un programa que puede almacenar grandes cantidades de datos en la memoria, ya que analiza archivos.
Revolví el código y encontré las siguientes líneas en el archivo
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
"Esto es", pensé, "¡esto es exactamente lo que estoy buscando!" Es una secuencia de excepciones que da como resultado las cadenas de objetos más largas
traceback. Y aquí, entre otras cosas, se analizan los archivos, por lo que también se pueden encontrar mecanismos recursivos aquí. Y algo que se asemeja a una construcción lo raise thing from other_thingune todo.
Me quité
from exy ... no pasó nada. La cantidad de memoria consumida por el programa se ha mantenido prácticamente al mismo nivel, los objetos tracebacktampoco se han ido a ningún lado.
Sabía que las excepciones almacenan sus enlaces locales en objetos
traceback, para que pueda acceder a ex. Como resultado, la memoria de ellos no se puede borrar.
Hice una refactorización masiva del código, tratando de deshacerme básicamente del bloque
except, o al menos desde un enlace a ex. Pero, de nuevo, no tengo nada. Aunque
estaba a punto de estallar, no podía "incitar" al recolector de basura sobre los objetos
traceback, incluso considerando que no había referencias a estos objetos. Pensé que la razón de esto era que había algún otro vínculo en alguna parte.
De hecho, tomé un rastro falso en ese entonces. No sabía si esta era la causa de la pérdida de memoria, porque en un momento comencé a darme cuenta de que no tenía evidencia para apoyar mi "teoría de las cadenas de excepción". Solo tenía un montón de conjeturas y millones de objetos
traceback.
Luego comencé a mirar estos objetos al azar en busca de algunas pistas adicionales. Traté de "escalar" manualmente la cadena de eslabones, pero al final solo encontré el vacío.
Entonces caí en la cuenta: todos estos objetos
tracebackestán ubicados "uno encima del otro", pero debe haber un objeto que esté "por encima" de todos los demás. Uno al que no hace referencia ninguno de los otros objetos similares.
Los enlaces se hicieron a través de una propiedad
tb_next, la secuencia de dichos enlaces era una cadena simple. Así que decidí echar un vistazo a los objetos tracebackal final de las respectivas cadenas:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Hay algo mágico en abrirse camino a través de medio millón de objetos con una sola línea y encontrar lo que necesita.
En general, encontré lo que buscaba. Encontré la razón por la que Python tenía que mantener todos estos objetos en la memoria.

Encontrar el origen del problema ¡
Todo se trataba de la caché de archivos!
El punto es que la biblioteca
astroidalmacena en caché los resultados de la carga de módulos. Si el código necesita un módulo que ya se ha utilizado, la biblioteca simplemente le proporcionará el resultado de cargar este módulo que ya tiene. Esto también conduce a la reproducción de errores al almacenar las excepciones lanzadas.
En este punto, tomé una decisión audaz, razonando así: “Tiene sentido almacenar en caché algo que no contenga errores. Pero, en mi opinión, no tiene sentido almacenar objetos
tracebackgenerados por nuestro código ".
Decidí deshacerme de la excepción, mantener mi propia clase
Errory simplemente reconstruir las excepciones cuando fuera necesario. Los detalles se pueden encontrar en estePR, pero realmente resultó no ser particularmente interesante.
Como resultado, pude reducir el consumo de memoria al trabajar con nuestro código base de 500 MB a 100 MB.
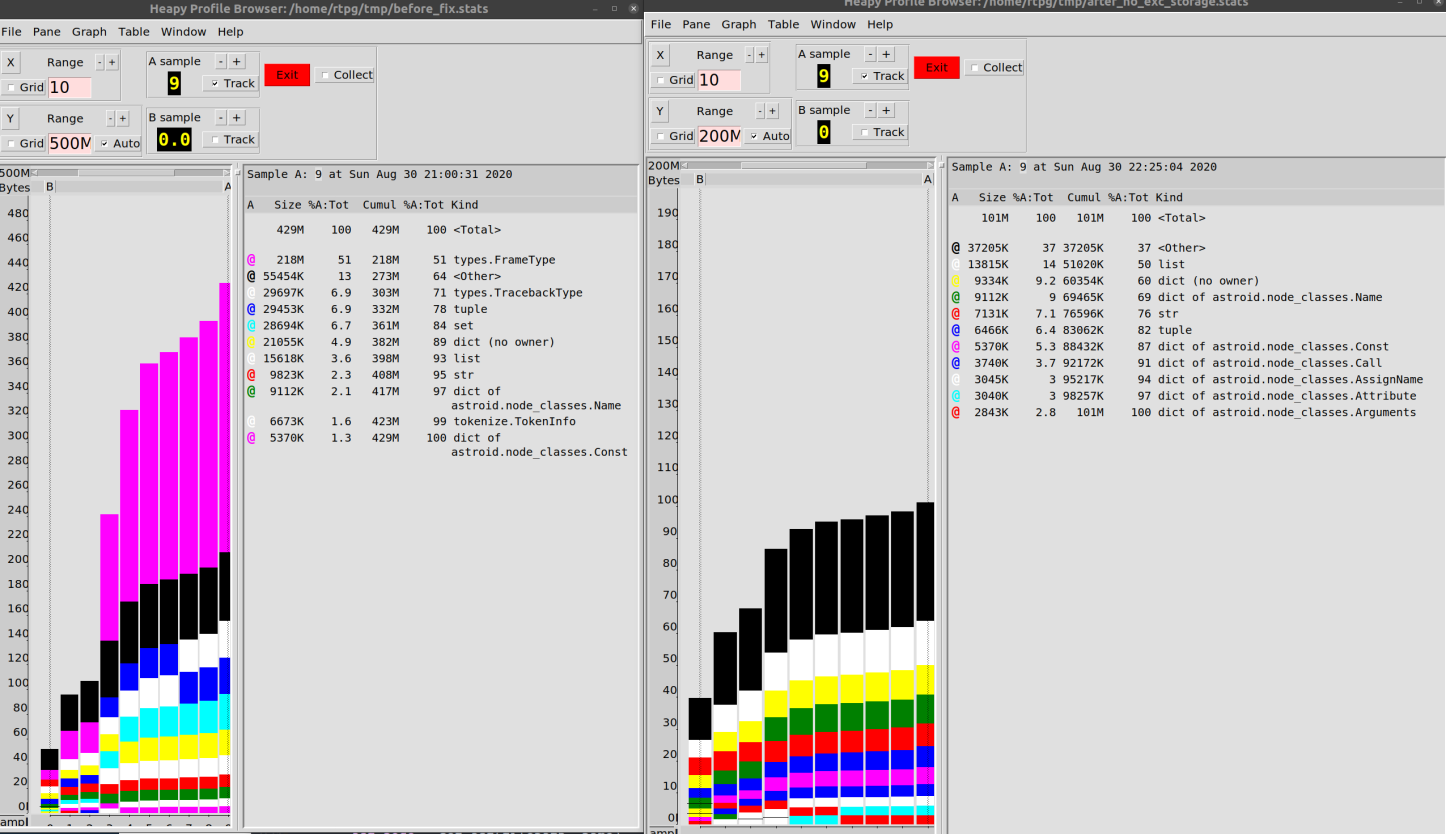
Yo diría que la mejora del 80% no es tan mala,
hablando de relaciones públicas, no estoy seguro de si se incluirá en el proyecto. Los cambios que trae en sí mismo no solo están relacionados con el rendimiento. Creo que la forma en que funciona puede, en algunas situaciones, reducir el valor de los datos de seguimiento de la pila. Esto es, considerando todos los detalles, un cambio bastante grande, aunque esta solución pasa todas las pruebas.
Como resultado, saqué las siguientes conclusiones para mí:
- Python nos brinda excelentes capacidades de análisis de memoria. Debería utilizar estas funciones con más frecuencia al depurar código.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
Mientras escribía esto, me di cuenta de que ya me había olvidado mucho de lo que me permitió llegar a ciertas conclusiones. Así que terminé revisando algunos de los fragmentos de código nuevamente. Luego realicé mediciones en una base de código diferente y descubrí que las rarezas de la memoria son específicas de un solo proyecto. Pasé mucho tiempo buscando y solucionando esta molestia, pero es muy probable que esto sea solo una característica del comportamiento de las herramientas que usamos, que se manifiesta solo en un pequeño número de quienes usan estas herramientas.
Es muy difícil decir algo definitivo sobre el rendimiento incluso después de tomar tales medidas.
Intentaré transferir la experiencia obtenida de los experimentos que describí a otros proyectos. Creo que hay muchos de estos problemas de rendimiento en proyectos de Python de código abierto que son fáciles de solucionar. El hecho es que la comunidad de desarrolladores de Python generalmente presta relativamente poca atención a este problema (esto es, si no hablamos de proyectos que son extensiones de Python, escritos en C).
¿Alguna vez ha tenido que optimizar el rendimiento de su código Python?

