Hay una leyenda del Antiguo Testamento acerca de cómo la gente en la antigua ciudad de Babilonia comenzó a construir una torre, pero el Todopoderoso se mezcló en sus lenguas y la torre no se completó. De hecho, la torre fue construida por cientos de pequeños grupos, que juntos no se entendían entre sí. Y sin entenderse, es imposible interactuar. De hecho, es simplemente una locura llamar a una y la misma cosa, lo que implica lo mismo, con diferentes palabras. Y no hay nada sorprendente aquí.
La leyenda del Antiguo Testamento se puede transferir fácilmente a las grandes empresas modernas que implementan soluciones de TI modernas. Un ejemplo de tales empresas, sin duda, se puede atribuir a los bancos rusos modernos, que tienen docenas o incluso cientos de unidades comerciales, que tienen su propia subcultura de comunicación, construida sobre sus propias reglas y un estilo único de facturación comercial. Naturalmente, a la hora de conformar la infraestructura de TI se tiene en cuenta el estilo de nomenclatura de las entidades comerciales que se ha establecido en el equipo. En los últimos diez años han aparecido muchos trabajos sobre este tema, por ejemplo éste [1]. Quienes se han encontrado con la analítica de sistemas de información en los bancos saben lo que significa hacer el llamado "mapeo" de datos, especialmente si los sistemas finales fueron realizados por diferentes equipos de analistas, desarrolladores y clientes o proveedores. Generalmente,La compilación del 60% del mapeo es una comprensión de la esencia y la semántica de los datos transmitidos.
La tendencia actual es utilizar un conjunto de metodologías ágiles. Todo el mundo habla de Agile . Puede discutir hasta el punto de la ronquera si es bueno para los negocios o perjudicial. Pero una cosa no hará que nadie la rechace. En el curso de Agile, muchos equipos diferentes, tanto dentro del banco como de diferentes proveedores, crean una variedad de soluciones de TI para negocios y, a menudo, sin interactuar entre sí, los equipos crean su propia terminología bien establecida. Y en el momento en que ocurre la integración, ocurre la misma situación descrita en el Antiguo Testamento. ¿Cómo no se parece al bazar babilónico con sus miles de comerciantes, tiendas, bienes, santos tontos, faquires y tragafuegos? Y así, todas estas personas, armadas con diferentes ideas y diferentes pensamientos, comienzan a construir la Torre.
XSD ( JSON ) , - . , , «» , Confluence, Zoom Webex, « » , — .
, ESB ( ) -, , , «-» , . … , , . , , - , Kafka. , , , . XML , XSD , , , , JSON, - , «» «». , , , JSON . . , . XSD , . JSON . .
? , - . , ?
.
- . , . MS Excel, , , «» . ( JSON path), — . «». . , :
« »
« »
«20- »
«12- »
« , »
, , , , -. , : , . – “ ”. , , , , , , .
, , , PIP! xslx , . , , Python, .
, – Python. , Python. , , - . , , . – , , . : « , ». — - PyQt Tkinter. , . .
, JSONpath , . , , , Python. , .
. JSON.
. “” 33- . 33 ? – “33” . «». . , , , [2]. . «» . : , , 33- . . . , ABC :
donde cada coordenada x en la posición correspondiente es el número de la letra correspondiente del comentario de campo en el archivo de Excel. Por ejemplo, tenemos el comentario "Número de cuenta individual". Comparemos para él un vector que emerge del origen de coordenadas del sistema cartesiano en un espacio alfabético de 33 dimensiones, se verá así: coordenada X A - corresponde al número de letras "a". Y es igual a dos. X B - en este caso será igual a cero, ya que no hay letra "b" en esta declaración. Lo mismo se aplica a x B - no hay letra "c". Pero x AND - será igual a 3, ya que la letra "y" en el comentario aparece tres veces.

Figura 1 . , « » . «»= 2, «» =3. – xA=2, x=3.
, , ( ) , 33- « », :
, , « «»» ( , , «» «») « ». :
Ahora encontraremos la diferencia entre los vectores en el sistema de coordenadas cartesianas del espacio alfabético, se encuentra, respectivamente, según la fórmula conocida de la geometría analítica:
Dónde y las correspondientes coordenadas vectoriales para el eje correspondiente a la letra.
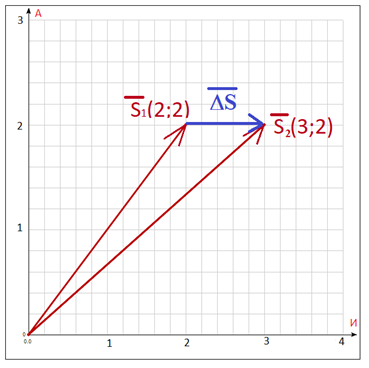
Figura 2. El color azul muestra la diferencia entre vectoresen el plano de las letras - del espacio alfabético.
Así, el vector correspondiente a la diferencia entre las declaraciones "Número de cuenta de un individuo" y "Número de cuenta de un físico" se verá así:
, el
vector correspondiente a la diferencia entre los estados de cuenta "Número de cuenta individual" y "Número de cuenta del cliente" se verá así:
Además, la longitud de los vectores de diferencia calculada obtenidos por la fórmula:
Si realiza un cálculo aritmético, obtiene:
Esto supone matemáticamente que la frase "Número de cuenta de un individuo" tiene un significado más cercano a "Número de cuenta de un físico" que a "Número de cuenta de una entidad legal". Esto está indicado por las longitudes de los vectores de diferencia. Cuanto más corta sea la longitud, más cercanas serán las declaraciones entre sí. Si, por ejemplo, tomamos y comparamos las declaraciones “Número de cuenta de un particular” y “número de la sucursal en la que se abre la cuenta de un particular”, obtenemos la figura 6.63. Esto indicará que si las dos primeras declaraciones tienen un significado cercano al original (la diferencia en los vectores 3.32 y 4.00, respectivamente), entonces la tercera, obviamente, incluso tendrá una esencia comercial diferente, a pesar del conjunto idéntico de palabras aparentemente visible. ...
Puede ir más allá e intentar, mediante la vectorización, cuantificar la cercanía de los comentarios en el significado. Para hacer esto, sugiero usar proyecciones vectoriales una encima de la otra. Luego, encuentre la relación entre la proyección larga del viento comparado y la longitud del viento con el que se compara. Esta relación siempre será menor o igual a uno. Y en consecuencia, si las declaraciones son idénticas entre sí, la proyección se fusionará con el vector sobre el que se realiza la proyección. Cuanto más significativo sea el enunciado comparado, menor será la proyección. Si lo multiplica por 100%, puede obtener el grado de correspondencia de las declaraciones vectorizadas en porcentaje. Por tanto, la proyección del vector declaración comparada en el vector de la declaración original se encontrará mediante la siguiente fórmula:
Por tanto, el grado de cumplimiento se calculará mediante la siguiente fórmula:

Figura 3. Ilustración de una proyección vector por vector ...
Es este parámetro el que se propone tomar como base para determinar la correspondencia semántica.
Implementación del algoritmo en Python . Un poco de albaricoque. Cómo configurar y manejar vectores
Llamé al algoritmo Jerdella . Nada extraño, solo soy de Rostov-on-Don.
. , --, , , . , , -, -, -, “”. , .
, , Python , . , . , NumPy. , , NumPy? , – , , - « », . , NumPy. — . , , PIP... Por lo tanto, nuestro Jerdella utilizará los paquetes estándar incluidos en PyCharm Community Edition para el intérprete de Python 3 .
Entonces, lo bueno de Python es que tiene la capacidad de implementar una amplia variedad de estructuras de datos. ¿Y por qué no estamos satisfechos con una lista para registrar un vector? Una lista de elementos de tipo int es lo que necesita para definir un vector en el espacio alfabético y otras operaciones con él.
Hemos escrito una serie de procedimientos fundamentales, que describiré brevemente a continuación.
¿Cómo configurar un vector?
Configuré el vector con el siguiente procedimiento de vector:
def vector(self,a):
vector=[]
abc = ["", '', "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", "", ""]
for char in abc:
count=a.count(char)
vector.append(count)
return(vector)Es decir, en el bucle for sobre los elementos de la lista abc previamente preparada , utilicé la operación estándar para encontrar archivos adjuntos a la cadena de conteo . Después de eso, usando el método de agregar, completé una nueva lista de vectores , que será el vector para futuros cálculos.
¿Cómo calcular la diferencia en vectores?
Para ello, he creado un delta procedimiento que toma dos listas como entrada - una y b .
def delta(self, a, b):
delta = []
for char1, char2 in zip(a, b):
d = char1 - char2
delta.append(d)
return (delta)En el ciclo for , al iterar sobre ambas listas, se calculó la diferencia y se agregó en cada paso de la iteración al final de la lista delta , que el procedimiento finalmente devolvió como un vector.
¿Cómo calcular la longitud de un vector y así estimar la diferencia?
Para hacer esto, creé un procedimiento len_delta , que toma una lista como entrada, y al iterar sobre cada elemento de esta lista (también es una coordenada en el espacio alfabético), usando la regla de encontrar el módulo de vector, calcula la longitud del vector.
def len_delta(self, a):
len = 0
for d in a:
len += d * d
return round(math.sqrt(len), 2)¿Cómo calcular la relación de la proyección sobre un vector y así estimar el porcentaje de coincidencia?
Para ello, se creó un procedimiento simplificado que toma dos listas como entrada. En él, implementé la fórmula (6). Y aquí un punto importante es determinar qué vector tiene la mayor longitud. Para mayor claridad en la evaluación de la coincidencia, es más conveniente proyectar un vector más pequeño sobre uno más grande.
def simplify(self, a, b):
len1 = 0
len2 = 0
scalar = 0
for x in a: len1 += x * x
for y in b: len2 += y * y
for x, y in zip(a, b): scalar += x * y
if len1 > len2:
return (scalar / len1) * 100
else:
return (scalar / len2) * 100Discusión de los resultados obtenidos. Conquistar el espacio semántico estructurándolo
, , Jerdella . : 1) , , . 2) -. , CRM Siebel ESB, -. , , , -. , , . … . , , , …
… 2 , Agile, , point-to-point, , .
. , , . 2-3 , , . , , , : « » « », « », « », « », , . , 3000 , 500 ? – ? . , - 3000 ?
. «» , . . Python . «». “” , . « ». , , , – .
, :
{'Número de cuenta de una persona': [{4.69: 'Cuenta bancaria del cliente'}, {6.0: 'Apellido'}, {4.8: 'Número de cuenta de metal'}, {4.8: 'Número de cliente'}]}.
Este diagrama también se puede visualizar en forma de gráfico. Puedes hacer mucho con los diccionarios en Python ... Para visualizar y demostrar los resultados, usamos el proyecto de Internet abierto www.graphonline.ru . Esta plataforma le permite crear rápidamente un gráfico escrito con GraphML .

Figura 4. Gráfico de la relación de la entidad "Número de un individuo". Una ilustración de la presencia de "órbitas de correspondencia semántica" en una entidad.
«» , (3) , , «» , . « » « ». , . , , , . .
? , « » «-». ( ( 3) (5)), . , « » . , « ».
, , , . . .

5. , .
, . … , , . , – ? ? ? — . 80%, , . , . , … - – . , .
, , , , . , , «» ( 6), . «», «», «», - -. , 30% . . , . , , , .

6. «» . , .
. .
«-» . , , - . ? , -.
. - . , . : « - ». , , . « » . , , , . – « ! - »…
, , - , , « », « » « », « », « ». , « ». , . ? ? « »?
, , , , , . – .
, :
[1] . . : . . 2010.
[2]. , . , . . Python. . – . , 2019, — 368 .
P.S. Accenture — ,