
En 2020, el aprendizaje automático en plataformas móviles ya no es revolucionario. La integración de funciones inteligentes en aplicaciones se ha convertido en una práctica estándar.
Afortunadamente, esto no significa que Apple haya dejado de desarrollar tecnologías innovadoras.
En esta publicación, compartiré brevemente las noticias sobre la plataforma Core ML y otras tecnologías de inteligencia artificial y aprendizaje automático en el ecosistema de Apple.
Core ML
El año pasado, la plataforma Core ML recibió una actualización importante. Este año, las cosas son mucho más modestas: se han agregado varios tipos nuevos de capas, soporte para modelos de cifrado y la capacidad de publicar actualizaciones de modelos en CloudKit.
Parece que se tomó la decisión de eliminar los números de versión. Después de la actualización del año pasado, la plataforma se conoció como Core ML 3, pero ahora usa el nombre Core ML sin un número de versión. Sin embargo, el paquete coremltools se ha actualizado a la versión 4.
Nota . La especificación interna de mlmodel es ahora la versión 5, lo que significa que aparecerán nuevos modelos en Netron con el nombre "Core ML v5".
Nuevos tipos de capas en Core ML
Se han agregado las siguientes capas:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: Ya hay varios tipos de capas divididas disponibles en Core ML. Esta capa le permite pasar un tensor que contiene el índice desde el cual comenzará la partición. Al mismo tiempo, el tamaño del sector siempre permanece fijo.
Estos tipos de capas se pueden usar a partir de la versión 5, es decir, en iOS 14 y macOS 11.0 o posterior.
Otra mejora útil: operaciones cuantificadas de 8 bits para las siguientes capas:
InnerProductLayerBatchedMatMulLayer
En versiones anteriores de Core ML, los pesos se cuantificaban, pero después de cargar el modelo, se volvían a convertir al formato de punto flotante. La nueva función le
int8DynamicQuantizepermite almacenar los pesos como números enteros de 8 bits y realizar los cálculos reales utilizando también números enteros.
Los cálculos que utilizan INT8 pueden ser mucho más rápidos que las operaciones de coma flotante. Esto proporciona algunas ventajas a la CPU, pero no está claro si el rendimiento de las GPU mejorará, ya que las operaciones de punto flotante son muy eficientes para ellas. Quizás, en una futura actualización del Neural Engine, se implementará soporte integrado para operaciones INT8 (después de todo, Apple adquirió recientemente Xnor.ai ...).
En el lado de la CPU, Core ML ahora también puede usar un punto flotante de 16 bits en lugar de 32 bits (en A11 Bionic y superior). Como discutimos en el video Explore la computación numérica en Swift , Float16 es ahora el tipo de datos de primera clase de Swift. Con soporte nativo para operaciones de punto flotante de 16 bits, ¡Core ML puede duplicar la velocidad!
Nota . En Core ML, el tipo de datos Float16 ya se usaba en GPU y Neural Engine, por lo que las diferencias solo se notarán cuando se usen en la CPU.
Otros cambios (menores):
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
Parece que no hay cambios con respecto al aprendizaje local en los dispositivos: todavía solo se admiten las capas convolucionales y completamente conectadas. La clase
MLParameterKeyen CoreML.framework ahora contiene un parámetro de configuración para el optimizador RMSprop ; sin embargo, esta mejora aún no está incluida en NeuralNetwork.proto . Quizás se agregue en la próxima beta.
Se han agregado los siguientes nuevos tipos de modelos :
VisionFeaturePrint.Object- Unidad de extracción de características optimizada para el reconocimiento de objetos.
SerializedModel... No sé exactamente para qué es esto. Esta es una definición "privada" y está "sujeta a cambios sin previo aviso ni responsabilidad". ¿Quizás así es como Apple incrusta los formatos de modelos propietarios en mlmodel?
Publicar actualizaciones de modelos en CloudKit

Este nuevo componente Core ML le permite actualizar modelos por separado de la aplicación.
En lugar de actualizar toda la aplicación, simplemente puede cargar las instancias implementadas con la nueva versión de mlmodel. Para ser honesto, esta idea no es nueva y algunos proveedores externos ya han desarrollado los SDK correspondientes. Además, no es difícil crear ese paquete usted mismo. La ventaja de la solución de Apple en este caso es la capacidad de alojar modelos en Apple Cloud .
Dado que una aplicación puede tener múltiples modelos, el nuevo concepto de una colección de modelos le permite combinar modelos en un paquete para que la aplicación pueda actualizarlos todos al mismo tiempo. Estas colecciones se pueden crear utilizando el panel de CloudKit.
La aplicación usa la clase para descargar y administrar las actualizaciones del modelo
MLModelCollection. El video de la WWDC muestra los fragmentos de código para realizar esta tarea.
Para preparar un modelo de Core ML para la implementación, el botón Crear archivo de modelo ahora está disponible en Xcode. Al hacer clic en él, se escribe en el archivo .mlarchive . Esta versión del modelo puede enviarse al panel de CloudKit y luego agregarse a la colección de modelos (mlarchive parece un archivo ZIP normal con el contenido de la carpeta mlmodelc agregado).
Es muy conveniente que pueda implementar diferentes colecciones de modelos para diferentes usuarios. Por ejemplo, la cámara del iPhone es diferente de la cámara del iPad, por lo que es posible que deba crear dos versiones del modelo y enviar una a los usuarios de iPhone y otra a los usuarios de iPad.
Puede definir reglas de personalización para diferentes clases de dispositivos (iPhone, iPad, TV, Watch), diferentes sistemas operativos y sus versiones, códigos de región, códigos de idioma y versiones de la aplicación.
No parece haber un mecanismo para dividir a los usuarios en grupos según otros criterios, por ejemplo, para pruebas A / B de actualizaciones de modelos o ajustes para tipos de dispositivos específicos: iPhone X o anterior. Sin embargo, esto aún se puede hacer manualmente creando colecciones con diferentes nombres y luego solicitándolo explícitamente a
MLModelCollectionproporcionando la colección adecuada por el nombre especificado en tiempo de ejecución.
La implementación de una nueva versión de un modelo no siempre es rápida . En algún momento, la aplicación detecta un nuevo modelo disponible y lo descarga automáticamente y lo coloca en el entorno de prueba de la aplicación. Sin embargo, no tiene la capacidad de determinar dónde y cómo sucede esto: Core ML puede descargar en segundo plano, por ejemplo, mientras no está usando su teléfono.
Debido a esto, se recomienda en todos los casos agregar un modelo integrado a la aplicación como respaldo, por ejemplo, un modelo genérico que admita tanto iPhone como iPad.
Si bien esta práctica solución permite a los usuarios no preocuparse por los modelos de autohospedaje, tenga en cuenta que su aplicación ahora usa CloudKit. Según tengo entendido, las colecciones de modelos cuentan para la cuota de almacenamiento total y las cargas de modelos cuentan para las cuotas de tráfico de red.
Ver también:
- Implementación de modelos y protección de Core ML (video WWDC)
- Crear e implementar una colección de modelos
- Recuperar colecciones de modelos expandidas
Nota . Desafortunadamente, la nueva capacidad de actualización que utiliza CloudKit es bastante difícil de combinar con la personalización del modelo local. No hay formas fáciles de transferir el conocimiento adquirido por un modelo personalizado a un nuevo modelo o combinarlos de alguna manera.
Cifrar el modelo
Hasta ahora, cualquier atacante podía robar fácilmente su modelo Core ML e integrarlo en su propia aplicación. A partir de iOS 14 / macOS 11.0, Core ML admite el cifrado y descifrado automático de modelos, lo que limita el acceso de los atacantes a sus carpetas mlmodelc. El cifrado se puede utilizar junto con la nueva función de implementación a través de CloudKit o por separado.

Xcode cifra los modelos compilados ( mlmodelc ), no el mlmodel original. El modelo siempre está encriptado en el dispositivo del usuario. Y solo cuando la aplicación crea una instancia del modelo, Core ML lo descifra automáticamente. La versión descifrada del modelo solo existe en la memoria y no se almacena como un archivo.
Primero, ahora necesita una clave de cifrado. La buena noticia es que no tiene que administrar esta clave usted mismo. El botón Crear clave de cifrado ahora está disponible en Core ML Xcode Model Viewer(Crear clave de cifrado). Al hacer clic en este botón, Xcode genera una nueva clave de cifrado y la asocia con su cuenta del equipo de desarrollo de Apple. No tiene que lidiar con solicitudes de firma de certificados y claves de acceso físico.
Este procedimiento crea un nuevo archivo .mlmodelkey . La clave se almacena en los servidores de Apple, sin embargo, también obtiene una copia local para cifrar los modelos en Xcode. No es necesario que inserte esta clave de cifrado en la aplicación, ¡especialmente porque no debería hacerlo!
Para cifrar un modelo de Core ML, puede agregar una marca de compilador
--encrypt YourModel.mlmodelkeypara ese modelo. Y si planea implementar el modelo usando CloudKit, deberá especificar la clave de cifrado al crear el archivo del modelo.
Para descifrar el modelo después de que la aplicación lo haya instanciado, Core ML deberá recuperar la clave de cifrado de los servidores de Apple a través de la red . Esto, por supuesto, requiere una conexión de red. Core ML solo realiza este procedimiento la primera vez que usa el modelo.
Si no hay conexión de red y la clave de cifrado aún no se ha cargado, la aplicación no podrá crear una instancia del modelo Core ML. Por este motivo, se recomienda utilizar la nueva función
YourModel.load(). Contiene un controlador final que le permite responder a los errores de descarga. Por ejemplo, el código de error modelKeyFetchdice que Core ML no pudo descargar la clave de cifrado de los servidores de Apple.
Esta es una característica muy útil si le preocupa que alguien le robe su tecnología patentada. Además, es fácil de integrar en su aplicación.
Ver también:
- Implementación de modelos y protección de Core ML (video WWDC)
- Generando una clave de cifrado modelo
- Cifrar el modelo en la aplicación
Nota . Según la información proporcionada en esta publicación del foro de desarrolladores , los modelos cifrados no admiten la personalización local. Suena razonable.
CoreML.framework
La API de iOS para trabajar con modelos Core ML no ha cambiado mucho. Y, sin embargo, me gustaría señalar un par de puntos interesantes.
La única clase nueva aquí es
MLModelCollectionuna que está destinada a implementarse con CloudKit.
Como ya sabe, cuando agrega un archivo mlmodel a su proyecto, Xcode genera automáticamente un archivo fuente Swift o Objective-C que contiene clases para facilitar el trabajo con el modelo. Puede notar un par de cambios en estas clases generadas:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
Hay una nueva advertencia en la documentación de MLModel :
use una instancia de MLModel en un solo hilo o en una cola de envío. Para hacer esto, puede serializar llamadas de método al modelo o crear una instancia separada del modelo para cada subproceso y cola de despacho.
Oh lo siento. Me pareció que dentro del MLModel se usaba una cola secuencial para procesar solicitudes, pero podría estar equivocado, o algo cambió. En cualquier caso, es mejor ceñirse a esta recomendación en el futuro.
El
MLMultiArraynuevo inicializador implementadoinit(concatenating:axis:dataType:), que crea una nueva matriz múltiple combinando varias matrices múltiples existentes. Todos deben tener la misma forma excepto el eje especificado a lo largo del cual se realiza la unión. Parece que esta función se agregó específicamente para realizar predicciones a partir de datos de video, como en los nuevos modelos de clasificador de acciones en Create ML. ¡Convenientemente!
Nota . La enumeración
MLMultiArrayDataTypeahora contiene propiedades estáticas .floaty .float64. No sé exactamente para qué sirven, porque esta enumeración ya tiene propiedades .float32y .double. ¿Error beta?
Visor de modelos de Xcode
Xcode ahora muestra mucha más información sobre modelos, como etiquetas de clase y cualquier metadato personalizado agregado. También muestra estadísticas sobre los tipos de capas del modelo.
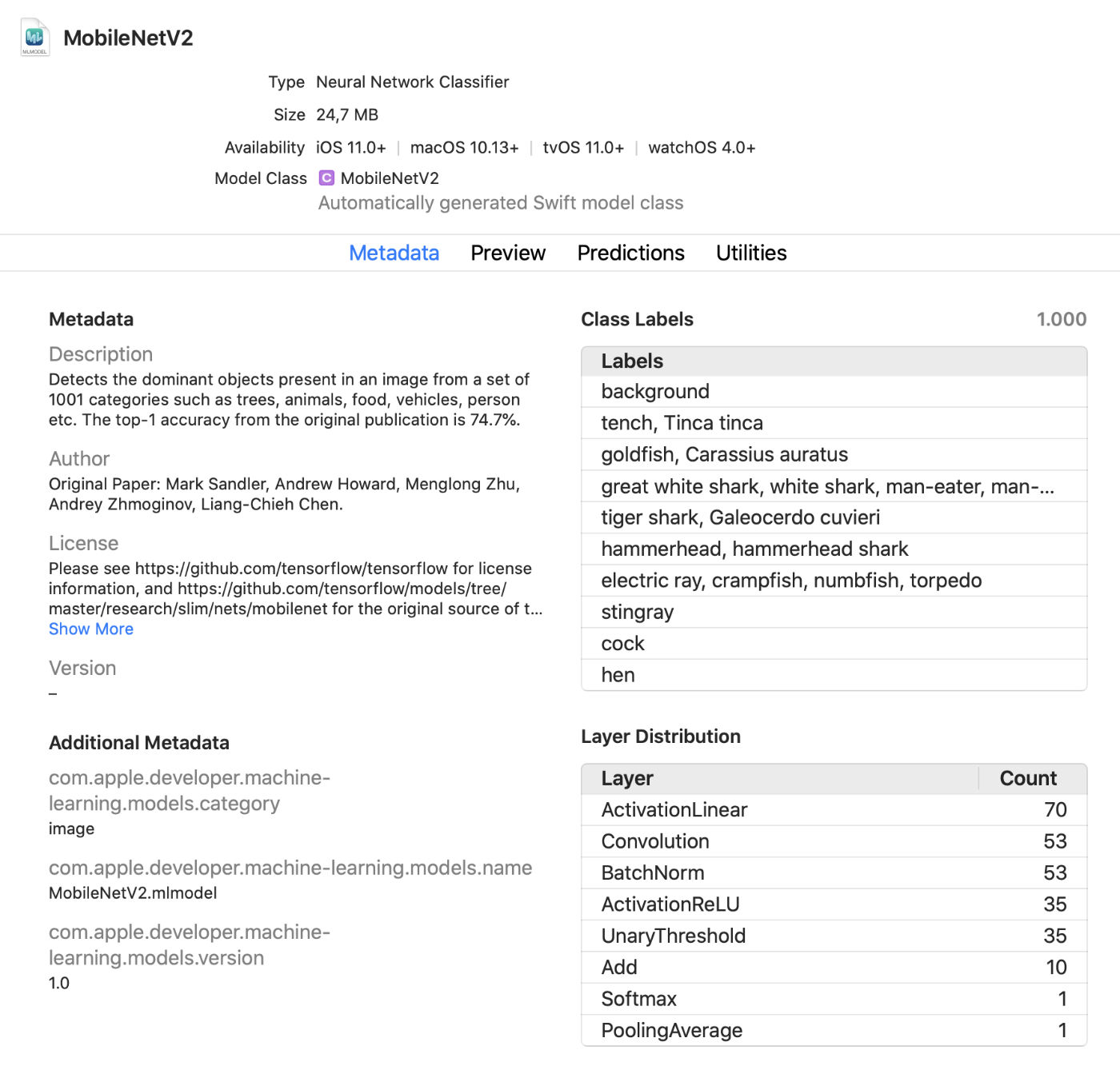
Este es un práctico visor en vivo que le permite realizar cambios en el modelo en modo de prueba sin ejecutar la aplicación. Puede arrastrar imágenes, videos o texto a esta ventana de vista previa y ver las predicciones del modelo de inmediato. ¡Gran actualización!
Además, ahora puede utilizar los modelos Core ML en un entorno interactivo . Xcode genera automáticamente una clase para esto, que puede usar normalmente. Esta es otra forma de probar modelos de forma interactiva antes de agregarlos a la aplicación.
coremltools 4
Si bien crear tus propios modelos para proyectos simples es conveniente con Create ML, TensorFlow y PyTorch se usan más comúnmente para entrenamiento. Para utilizar un modelo de este tipo en Core ML, primero debe convertirlo al formato mlmodel. Esto es para lo que se utiliza la caja de herramientas de coremltools.
Buenas noticias: la documentación es mucho mejor . Te recomiendo que te familiarices con él. Con suerte, el manual del usuario se actualizará regularmente porque la documentación no siempre estaba actualizada en el pasado.
Nota . Desafortunadamente, los cuadernos de muestra de Jupyter ya no están. Ahora se incluyen en el manual del usuario, pero no como portátiles.
La forma de transformar modelos ha cambiado drásticamente... Los convertidores de redes neuronales usados anteriormente están desactualizados y han sido reemplazados por versiones más nuevas y flexibles.
Hay tres tipos de convertidores disponibles en la actualidad:
- Convertidores modernos para TensorFlow (tanto 1.xy 2.x), tf.keras y PyTorch. Todos estos convertidores se basan en las mismas tecnologías y utilizan el llamado lenguaje de modelo intermedio (MIL). Ya no necesita usar tfcoreml o onnx-coreml para tales modelos.
- Convertidores antiguos para redes neuronales Keras 1.x, Caffe y ONNX. Se proporciona un conversor especializado para cada uno de ellos. Su desarrollo posterior se ha descontinuado y solo se planean arreglos para el futuro. Ya no se recomienda utilizar ONNX para convertir modelos de PyTorch.
- Convertidores para modelos de redes no neuronales como scikit-learn y XGBoost.
Se utiliza una nueva API de conversión uniforme para transformar los modelos de TensorFlow 1.x, 2.x, PyTorch o tf.keras . Se aplica de la siguiente manera:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
La función
ct.convert()comprueba el archivo del modelo para determinar su formato y luego selecciona automáticamente el convertidor apropiado. Los argumentos son ligeramente diferentes de los que se usaban antes: los argumentos de preprocesamiento se pasan usando un objeto ImageType, las etiquetas de clasificador se pasan usando un objeto , ClassifierConfigy así sucesivamente.
La nueva API de transformación convierte el modelo en una representación intermedia , la llamada. MIL . Actualmente, hay convertidores disponibles para convertir TensorFlow 1.xa MIL, TensorFlow 2.xa MIL (incluido tf.keras) y PyTorch a MIL. Si la nueva plataforma de aprendizaje profundo gana popularidad, recibirá su propio convertidor a MIL.

Después de convertir el modelo al formato MIL, se puede optimizar de acuerdo con las reglas generales, por ejemplo, eliminar operaciones innecesarias o combinar varias capas diferentes. Luego, el modelo se convierte de MIL a formato mlmodel.
No he estudiado todo esto en detalle todavía, pero el nuevo enfoque da esperanzas de que coremtools 4 pueda crear archivos mlmodel más eficientes que antes, especialmente para gráficos TF 2.x.
En MIL, me gusta especialmente la capacidad del convertidor de manejar capas que aún no ha analizado . Si su modelo contiene una capa que no se admite directamente en Core ML, es posible que deba subdividirla en operaciones MIL más simples, como multiplicación de matrices u otras operaciones aritméticas.
Después de eso, el convertidor podrá utilizar las llamadas "operaciones compuestas" para todas las capas de este tipo. Esto es mucho más fácil que agregar operaciones no admitidas mediante capas personalizadas, aunque es posible. La documentación proporciona un buen ejemplo del uso de tales operaciones compuestas.
Ver también:
- Obtenga modelos en el dispositivo usando Core ML Converters (video WWDC)
- Documentación de Coremltools
Otras plataformas de Apple que utilizan el aprendizaje automático
Varios otros marcos de alto nivel en los SDK de iOS y macOS también se utilizan para tareas de aprendizaje automático. Veamos qué hay de nuevo en esta área.
Visión
La plataforma de visión artificial Vision ha recibido una serie de funciones nuevas.
La plataforma Vision ya ha utilizado modelos para reconocer rostros, rasgos distintivos y cuerpos humanos. La nueva versión agrega las siguientes características:
Reconocimiento de posición de la mano (
VNDetectHumanHandPoseRequest)
Reconocimiento de pose de varias personas (
VNDetectHumanBodyPoseRequest)
Es genial que Apple haya incluido funciones de reconocimiento de pose en el sistema operativo. Varios modelos de código abierto admiten esta función, pero no son tan eficientes ni rápidos. Las soluciones comerciales son caras. ¡Las herramientas de reconocimiento de pose de alta calidad ahora están disponibles de forma gratuita!
Ahora, a diferencia de la visualización de imágenes estáticas, se presta más atención areconocimiento de objetos en la grabación de video tanto fuera de línea como en tiempo real. Para mayor comodidad, puede utilizar objetos
CMSampleBufferdirectamente desde la cámara mediante controladores de solicitudes.
Además,
VNImageBasedRequestse ha agregado una subclase a la clase VNStatefulRequest, que es responsable de la pronta confirmación del descubrimiento del objeto deseado. A diferencia de la clase estándar, VNImageBasedRequestreutiliza una consulta con estado que abarca varios marcos. Esta solicitud realiza un análisis cada N fotogramas del video.
Cuando se encuentra el objetivo, se llama a un controlador final que contiene el objeto
VNObservation, que ahora tiene una propiedad timeRangeque indica las horas de inicio y finalización de la videovigilancia.
La clase
VNStatefulRequestno se usa directamente . Es una clase base abstracta y actualmente solo se subclasifica mediante consultas VNDetectTrajectoriesRequestcon fines de reconocimiento de ruta. Esto hace posible reconocer formas que se mueven a lo largo de una ruta parabólica, como cuando se lanza o patea una pelota (esta parece ser la única tarea incorporada relacionada con el video en la actualidad).
Para el análisis de video sin conexión, puede usar
VNVideoProcessor.Este objeto agrega una URL al video local y realiza una o más solicitudes de Vision cada N cuadros o N segundos.
Una de las técnicas tradicionales de visión por computadora más importantes para analizar grabaciones de video es el flujo óptico.... Ahora hay disponible una consulta en Vision
VNGenerateOpticalFlowRequestque calcula la dirección en la que cada píxel se mueve de un fotograma a otro (flujo óptico denso). Como resultado, se crea un objeto que VNPixelBufferObservationcontiene una nueva imagen, en la que cada píxel corresponde a dos valores de coma flotante de 32 o 16 bits.
Además, se ha agregado una nueva consulta
VNDetectContoursRequestpara reconocer los contornos de los objetos en una imagen. Estas rutas se devuelven como rutas vectoriales. VNGeometryUtilsproporciona herramientas auxiliares para el procesamiento posterior de contornos reconocidos, por ejemplo, simplificándolos a formas geométricas básicas.
Y la última innovación en Vision es una nueva versión del extractor de funciones incorporado VisionFeaturePrint. IOS ya implementó el bloqueVisionFeaturePrint.Scene , que es especialmente útil para crear clasificadores de imágenes. Además, ahora está disponible un nuevo modelo VisionFeaturePrint.Object, que está optimizado para resaltar las funciones utilizadas en el reconocimiento de objetos.
Este modelo admite imágenes de entrada de 299x299 y devuelve dos matrices múltiples de la forma (288, 35, 35) y (768, 17, 17), respectivamente. Este todavía no es un marco limitante claro, sino solo características "crudas". Para el reconocimiento de objetos en toda regla, debe agregar lógica que convierta estas características en cuadros delimitadores y etiquetas de clase. Create ML realiza esta tarea si está entrenando una herramienta de reconocimiento de objetos mediante la transferencia de entrenamiento.
Ver también:
- Explore las API de Computer Vision (video de la WWDC)
- Detectar la postura del cuerpo y la mano con la visión (video WWDC)
- Explore la aplicación Action & Vision (video WWDC)
Procesamiento natural del lenguaje
Para las tareas de procesamiento del lenguaje natural, puede utilizar la plataforma Natural Language. Ella usa activamente los modelos entrenados en Create ML.
Este año se han añadido muy pocas funciones nuevas:
NLTaggeryNLModelahora encuentre varias etiquetas y prediga su validez. Anteriormente, la validez de una etiqueta se determinaba solo por el número de puntos obtenidos.- Insertar oraciones. La inserción de palabras podría haberse utilizado antes, pero ahora
NLEmbeddingadmite oraciones completas.
Al insertar oraciones, se utiliza una red neuronal incorporada para codificar la oración completa en un vector de 512 dimensiones. Esto le permite obtener el contexto en el que se usan las palabras en una oración (la inserción de palabras no admite esta función).
Ver también:
- Haga que las aplicaciones sean más inteligentes con Natural Language (video de la WWDC)
Análisis del habla y los sonidos.
No hubo cambios en esta área.
Entrenamiento de modelos
Los modelos de trenes que utilizan las API de Apple estuvieron disponibles por primera vez en iOS 11.3 y en la plataforma Metal Performance Shaders. En los últimos años, se han agregado muchas API de entrenamiento nuevas, y este año no fue una excepción: según mis cálculos, ahora tenemos hasta 7 API diferentes para entrenar redes neuronales en plataformas iOS y macOS.
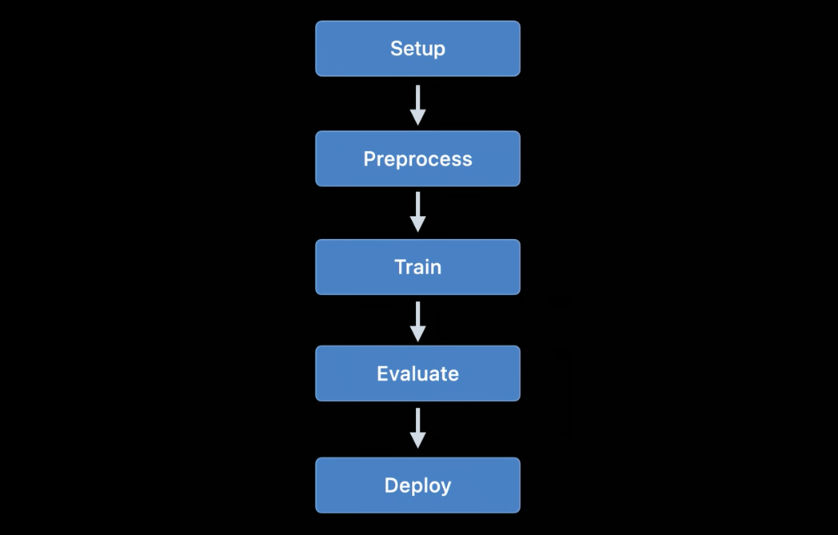
Actualmente, las siguientes API de Apple se pueden usar para entrenar modelos de aprendizaje automático, particularmente redes neuronales, en iOS y macOS:
- Aprendizaje local en Core ML.
- Crear ML : esta interfaz puede ser conocida como una aplicación, pero también es una plataforma disponible en macOS.
- Metal Performance Shaders : API para inferencia y entrenamiento en una GPU. De hecho, estas son dos API diferentes, bastante difíciles de usar si eres nuevo en Metal. Además, también está disponible un nuevo marco de trabajo Metal Performance Shaders Graph que parece reemplazar estas API heredadas.
- BNNS : parte de la plataforma Accelerate. Anteriormente, solo las rutinas de inferencia estaban disponibles en BNNS, pero este año también se agregó soporte de capacitación.
- ML Compute : una plataforma fundamentalmente nueva que parece muy prometedora.
- Turi Create : esta es en realidad la versión Python de Create ML. Recientemente, sus creadores se han olvidado de él, aunque el soporte de la plataforma aún no ha terminado.
Echemos un vistazo más de cerca a las innovaciones en estas API.
Aprendizaje local en Core ML
De hecho, aquí no hay cambios importantes. Se podría haber agregado soporte de actualización para varios tipos de capas más, pero aún no he visto ninguna documentación sobre esto.
Una de las innovaciones importantes que se esperan en una versión beta futura es el optimizador RMSprop. No está incluido en la versión beta actual.
Crear AA
La plataforma Create ML inicialmente solo estaba disponible para macOS. Se puede ejecutar en Swift Playground para que pueda usarse para entrenar modelos con solo un par de líneas de código.

El año pasado, Create ML se transformó en una aplicación bastante limitada y me complace ver mejoras significativas este año. Dicho esto, Create ML sigue siendo una plataforma que aún se puede utilizar desde el código subyacente. De hecho, la aplicación es solo una interfaz gráfica conveniente para trabajar con la plataforma.
En la versión anterior de Create ML, podía entrenar un modelo solo una vez. Para cambiar algo, tenías que volver a entrenarlo desde cero, y esto llevó mucho tiempo.
La nueva versión de Xcode 12 permitepausar el entrenamiento y reanudarlo más tarde , guardar puntos de control del modelo (instantáneas) y ver vistas previas del entrenamiento del modelo. Ahora tenemos muchas más herramientas a nuestra disposición para gestionar el proceso de aprendizaje. ¡Con esta actualización, Create ML es realmente útil!
Las nuevas API también están disponibles en la plataforma CreateML.framework para configurar sesiones de capacitación, manejar puntos de interrupción del modelo y más. Supongo que la mayoría de la gente solo usará la aplicación Create ML, pero es bueno ver que esta función ahora está disponible en la plataforma.
Nuevas funciones de Create ML (tanto en la plataforma como en la aplicación):
- Transferencia de un estilo para imágenes y videos
- Clasificación de acciones humanas en videos
Echemos un vistazo más de cerca al nuevo modelo de clasificación de acciones. Utiliza el modelo de reconocimiento de postura disponible en la plataforma Vision. El clasificador de acciones es una red neuronal que toma la forma (
window_size, 3, 18) como entrada , donde el primer valor representa la duración del fragmento de video, indicado en el número de cuadros (generalmente se usan fragmentos de aproximadamente 2 segundos), y (3, 18) representan los puntos clave de la pose.
En lugar de capas repetidas, la red neuronal utiliza convoluciones unidimensionales. Lo más probable es que se trate de una variación de una red convolucional de gráfico de espacio-tiempo (STGCN), un tipo de modelo diseñado específicamente para el pronóstico de series de tiempo. Estos detalles no deberían preocuparle cuando utilice dichos modelos en una aplicación. Sin embargo, siempre quiero saber cómo funciona todo.
En cuanto a los modelos de reconocimiento de objetos, puede optar por entrenar toda la red basada en TinyYOLOv2, o utilizar el nuevo modo de transferencia de entrenamiento, que utiliza la nueva unidad de extracción de características VisionFeaturePrint.Object . El resto del modelo todavía se parece a YOLO y SSD, sin embargo, gracias a la transferencia, su entrenamiento será mucho más rápido que entrenar todo el modelo basado en YOLO.
Ver también:
- Construya un clasificador de acciones con Create ML (video WWDC)
- Cree modelos de transferencia de estilo de imagen y video en Create ML (video WWDC)
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) es una plataforma basada en los núcleos informáticos de rendimiento de Metal, que se utiliza principalmente para el procesamiento de imágenes, pero que desde 2016 también ofrece soporte para redes neuronales. Ya he escrito mucho sobre esto.
Hoy en día, la mayoría de los usuarios elegirán Core ML en lugar de MPS. Por supuesto, Core ML todavía usa el poder de MPS cuando ejecuta modelos en la GPU. Sin embargo, MPS también se puede usar directamente, especialmente si el usuario planea realizar capacitación por su cuenta (por cierto, ahora está disponible una nueva plataforma ML Compute, que se recomienda usar en lugar de MPS. Su descripción se da a continuación).
Hay pocas funciones nuevas en MPSCNN este año, pero se han realizado varias mejoras a las existentes.
Añadidas nuevas clases
MPSImageCannypara reconocimiento de bordes y MPSImageEDLines para reconocimiento de segmentos de línea. Son muy útiles cuando se trabaja con problemas de visión por computadora.
También vale la pena señalar una serie de otros cambios:
- Se
MPSCNNConvolutionDataSourceha agregado una nueva propiedadkernelWeightsDataTypeque le permite usar un tipo de datos diferente para los coeficientes de ponderación que el usado para la convolución. Curiosamente, los pesos no pueden ser del tipo de datos INT8, aunque Core ML permite que este tipo de datos se utilice para capas individuales. - Si
kernelWeightsDataTyperetorna.float32, las capas convolucionales y completamente conectadas se realizan usando un punto flotante de 32 bits en lugar de 16 bits. Anteriormente, solo se admitían 16 bits. - Las funciones de pérdida ahora pueden usar un parámetro
reduceAcrossBatch.
Aún puedes usar MPSCNN si Metal no te asusta. Sin embargo, ahora está disponible una nueva plataforma que simplifica enormemente la creación y ejecución de tales gráficos: MPS Graph.
Nota . El video de la WWDC afirma que MPSNDArray es una nueva API, pero de hecho salió el año pasado. Es una estructura de datos mucho más flexible que MPSImage, ya que no todos los tensores de su modelo pueden ser imágenes.
Nuevo: Gráfico de sombreadores de rendimiento de metal

Una API ha estado disponible durante mucho tiempo en MPS
MPSNNGraph, pero tales gráficos, de hecho, describen solo redes neuronales. Sin embargo, no todos los gráficos tienen que ser redes neuronales, y en este caso la plataforma Metal Performance Shaders Graph será útil.
Esta nueva plataforma se puede utilizar para crear gráficos de cálculo de GPU de uso general. La plataforma MPS Graph no depende de Metal Performance Shaders, aunque se construyó sobre esta base.
En la versión anterior de la API obsoleta
MPSNNGraph, era imposible agregar operaciones personalizadas al gráfico. La nueva plataforma es mucho más flexible en este sentido. Sin embargo, no puede agregar sus propios núcleos de metal. Deberá expresar todos los cálculos utilizando las primitivas existentes.
Por suerte el compilador
MPSGraphadmite la integración de tales primitivas en un solo núcleo computacional, lo que asegura el trabajo más eficiente en el procesador gráfico. Sin embargo, este esquema no funcionará si es imposible o difícil utilizar las primitivas proporcionadas para alguna operación. Simplemente no entiendo por qué Apple, al crear una nueva API como esta, nunca permite funciones personalizadas completas. Pero no se puede hacer nada.
La nueva plataforma
MPSGraphes una estructura bastante simple y lógica que describe la relación entre operaciones en un conjunto MPSGraphOperationsusando tensoresMPSGraphTensorsque contiene los resultados de las operaciones. Además, puede definir dependencias de control para obligar a los nodos individuales a comenzar antes que los demás. Después de configurar el gráfico, debe ejecutarse o transferirse al búfer de comando y luego esperar el resultado.
MPSGraphproporciona un conjunto completo de métodos de instancia que le permiten agregar cualquier operación matemática o de red neuronal al gráfico.
Además, se admite el entrenamiento, lo que implica agregar una operación de procesamiento de pérdida al gráfico y luego realizar las operaciones de gradiente para todas las capas en el orden inverso, como en la antigua
MPSNNGraph. Para mayor comodidad, también está disponible un modo de diferenciación automática, dentro del cual MPSGraphrealiza automáticamente operaciones de gradiente para el gráfico. Esto ahorra mucho esfuerzo.
Me encanta que ahora haya una API nueva, simple y directa para crear tales gráficos computacionales. Es mucho más fácil de usar que las versiones anteriores. Y no es necesario ser un experto en metales para trabajar con él. Por cierto, es en muchos aspectos similar a los gráficos de TensorFlow 1.x, pero tiene una gran ventaja en términos de optimización, que le permite minimizar los costos. Y, sin embargo, no hay suficientes oportunidades para agregar núcleos computacionales arbitrarios al gráfico.
Ver también:
- Cree modelos de AA personalizados con Metal Performance Shaders Graph (vídeo de la WWDC)
- Agregar funciones personalizadas al gráfico de sombreado
BNNS (subrutinas de redes neuronales básicas)
Si Core ML se está ejecutando en la CPU, entonces usa rutinas BNSS que son parte de la plataforma Accelerate. Ya he escrito sobre BNNS en este artículo . La mayoría de estas características de BNNS ahora se descontinúan en gran medida y se reemplazan con un nuevo conjunto de características.
Anteriormente, solo se admitían las funciones de capas, plegado, agrupación y activación completamente conectadas. Esta actualización agrega compatibilidad con BNNS para arreglos de n dimensiones, prácticamente todos los tipos de capas Core ML y versiones de compatibilidad con versiones anteriores de dichas capas de entrenamiento (incluidas las capas que actualmente no admiten el entrenamiento Core ML, como LSTM).
También cabe destacar la presencia de una capa de atención múltiple.... Estas capas se utilizan a menudo en modelos Transformer como BERT. Otro punto interesante son las convoluciones tensoras.
Es posible que no utilice estas funciones BNNS usted mismo, al igual que no utilizaría MPS para el entrenamiento de GPU. En cambio, ahora está disponible una plataforma de computación ML de nivel superior que abstrae el procesador utilizado. ML Compute se basa en BNNS y MPS, pero los desarrolladores no tienen que preocuparse por cosas tan pequeñas.
Ver también: documentación de la plataforma BNNS
Nuevo: ML Compute
ML Compute es una plataforma fundamentalmente nueva para entrenar redes neuronales en una CPU o GPU (pero aparentemente no en procesadores Neural Engine). En una Mac Pro con varias GPU, esta plataforma puede usarlas todas automáticamente para entrenar.
Me sorprendió un poco la presencia de otra plataforma de aprendizaje, pero esta plataforma realmente simplifica todo, porque te permite ocultar componentes de bajo nivel de BNNS y MPS, y en el futuro, tal vez del Neural Engine.
Lo mejor de todo es que ML Compute también es compatible con los sistemas iOS, no solo con Mac. Es curioso que Core ML no se mencione en ninguna parte. ML Compute parecía haberse creado completamente por separado. Este marco no se puede utilizar para crear modelos Core ML.
Desde mi propia experiencia, puedo decir que la tarea de ML Compute es, en primer lugar, acelerar el trabajo de las herramientas de aprendizaje profundo de terceros . No tiene que escribir ningún código para trabajar directamente con ML Compute. Parece que se supone (o los desarrolladores lo esperan) que herramientas como TensorFlow comenzarán a usar esta plataforma para habilitar el soporte de aprendizaje acelerado por hardware en Mac.
Aproximadamente el mismo conjunto de capas disponibles que en BNNS. Las capas deben agregarse al gráfico y luego ejecutarse (aquí, no se usa el modo "ocupado esperando").
Para crear un gráfico, primero debe crear una instancia de un objeto
MLCGraphy agregarle nodos. Un nodo es una subclase MLCLayer. Los nodos están conectados entre sí a través de objetos.MLCTensorque contienen la salida de otras capas.
Curiosamente, las operaciones de división, concatenación, reformateo y transferencia no son tipos separados de capas, sino operaciones directamente en el gráfico.
Excelente función de depuración -
summarizedDOTDescription. Devuelve una descripción DOT para un gráfico, a partir de la cual puede crear un gráfico utilizando, por ejemplo, Graphviz u OmniGraffle (por cierto, Keras genera gráficos de modelo de esta manera).
ML Compute distingue entre gráficos de inferencia y gráficos de aprendizaje. Este último contiene nodos adicionales, por ejemplo, una capa de pérdida y un optimizador.
Parece que no hay formas de crear capas personalizadas aquí, por lo que solo tiene que arreglárselas con los tipos disponibles en ML Compute.
Es extraño que no haya sesiones de WWDC en esta nueva plataforma y la documentación también está bastante dispersa. De todos modos, seguiré siguiendo su desarrollo, porque parece que esta es exactamente la API que mejor se adapta para entrenar modelos en dispositivos Apple.
Consulte también: Documentación de la plataforma informática ML
Conclusión
El Core ML agregó una serie de funciones nuevas útiles, como la actualización automática de modelos y el cifrado. Los nuevos tipos de capas realmente no son realmente necesarios, porque las capas agregadas el año pasado pueden resolver casi cualquier problema. En general, me gusta esta actualización.
En coremltools 4 se agregaron mejoras importantes: la nueva arquitectura del convertidor y la compatibilidad integrada con TensorFlow 2 y PyTorch. Me alegra que ya no tengamos que usar ONNX para transformar los modelos de PyTorch.
En visiónagregó muchas funciones nuevas y útiles. Y me encanta que Apple haya agregado la funcionalidad de análisis de video. Aunque los sistemas de aprendizaje automático se pueden aplicar a fotogramas de video individuales, en este caso, el tiempo no se cuenta. Dado que los dispositivos móviles son lo suficientemente rápidos hoy en día para realizar aprendizaje automático basado en datos de video en tiempo real, creo que el video desempeñará un papel más importante en el desarrollo de tecnologías de visión por computadora en el futuro cercano.
Con respecto a la formación... no estoy seguro de si necesitamos siete API diferentes para esta tarea. Supongo que Apple simplemente no quería retirar las interfaces obsoletas hasta que las nuevas estuvieran completamente refinadas. Se sabe poco sobre la plataforma ML Compute. Sin embargo, en el momento de escribir este artículo, solo se ha lanzado la primera versión beta. Quién sabe lo que nos espera ...
La imagen de la conferencia utiliza el icono de Freepik de flaticon.com.