Enfoque de motivación
El enfoque generalmente aceptado para las tareas de visión por computadora es usar imágenes como una matriz 3D (alto, ancho, número de canales) y aplicarles convoluciones. Este enfoque tiene varias desventajas:
- no todos los píxeles son iguales. Por ejemplo, si tenemos una tarea de clasificación, entonces el objeto en sí es más importante para nosotros que el fondo. Curiosamente, los autores no dicen que la atención ya se esté utilizando en tareas de visión por computadora;
- Las convoluciones no funcionan lo suficientemente bien con píxeles que están muy separados. Hay enfoques con convoluciones dilatadas y agrupación promedio global, pero no resuelven el problema en sí;
- Las convoluciones no son lo suficientemente eficientes en redes neuronales muy profundas.
Como resultado, los autores proponen lo siguiente: convertir imágenes en una especie de tokens visuales y enviarlas al transformador.

- Primero, se usa una red troncal normal para obtener mapas de características
- A continuación, el mapa de características se convierte en tokens visuales.
- Las fichas se alimentan a los transformadores.
- La salida del transformador se puede utilizar para problemas de clasificación
- Y si combina la salida del transformador con un mapa de características, puede obtener predicciones para las tareas de segmentación.
Entre los trabajos en direcciones similares, los autores aún mencionan Atención, pero notan que generalmente la Atención se aplica a los píxeles, por lo tanto, aumenta en gran medida la complejidad computacional. También hablan de trabajos de mejora de la eficiencia de las redes neuronales, pero creen que en los últimos años han aportado cada vez menos mejoras, por lo que hay que buscar otros enfoques.
Transformador visual
Ahora echemos un vistazo más de cerca a cómo funciona el modelo.
Como se mencionó anteriormente, la red troncal recupera mapas de características y se pasan a las capas del transformador visual.
Cada transformador visual consta de tres partes: un tokenizador, un transformador y un proyector.
Tokenizer

El tokenizador recupera tokens visuales. De hecho, tomamos un mapa de características, hacemos una remodelación en (H * W, C) y de esto obtenemos tokens. La

visualización de los coeficientes para tokens se ve así:

Codificación de posición
Como es habitual, los transformadores no solo necesitan tokens, sino también información sobre su posición.

Primero, hacemos una reducción de resolución, luego multiplicamos por los pesos de entrenamiento y concatenamos con tokens. Para ajustar el número de canales, puede agregar convolución 1D.
Transformador
Finalmente, el propio transformador.

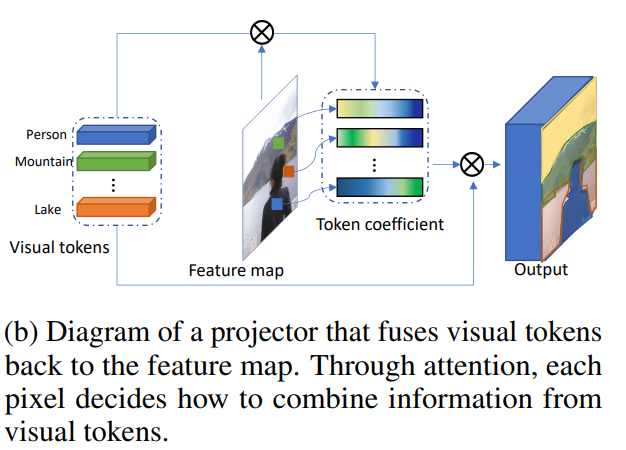
Combinando tokens visuales y mapa de características
Esto hace proyector.

Tokenización dinámica
Después de la primera capa de transformadores, no solo podemos extraer nuevos tokens visuales, sino también utilizar los extraídos de los pasos anteriores. Se utilizan pesos entrenados para combinarlos:

Usando transformadores visuales para construir modelos de visión por computadora
Además, los autores describen cómo se aplica el modelo a los problemas de visión por computadora. Los bloques de transformadores tienen tres hiperparámetros: el número de canales en el mapa de características C, el número de canales en el token visual Ct y el número de tokens visuales L.
Si el número de canales resulta inadecuado al cambiar entre los bloques del modelo, entonces se utilizan convoluciones 1D y 2D para obtener el número requerido de canales.
Para acelerar los cálculos y reducir el tamaño del modelo, utilice convoluciones de grupo.
Los autores adjuntan bloques de ** pseudocódigo ** en el artículo. Se promete que el código completo se publicará en el futuro.
Clasificación de imágenes
Tomamos ResNet y creamos ResNets de transformadores visuales (VT-ResNet) basados en él.
Dejamos la etapa 1-4, pero en lugar de la última ponemos transformadores visuales.
Salida de la red troncal: mapa de características de 14 x 14, número de canales 512 o 1024 según la profundidad de VT-ResNet. Se crean 8 tokens visuales para 1024 canales a partir del mapa de características. La salida del transformador va al cabezal para su clasificación.

Segmentación semántica
Para esta tarea, las redes piramidales de características panópticas (FPN) se toman como modelo base.
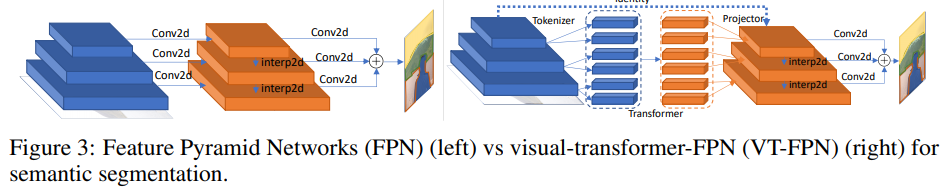
En FPN, las convoluciones funcionan en imágenes de alta resolución, por lo que el modelo es pesado. Los autores reemplazan estas operaciones con transformador visual. Nuevamente, 8 tokens y 1024 canales.
Experimentos
Clasificación de ImageNet
Entrene 400 épocas con RMSProp. Comienzan con una tasa de aprendizaje de 0.01, aumentan a 0.16 durante 5 épocas de calentamiento y luego multiplican cada época por 0.9875. Se utilizan la normalización de lote y el tamaño de lote 2048. Suavizado de etiquetas, AutoAugment, probabilidad de supervivencia de profundidad estocástica 0.9, deserción 0.2, EMA 0.99985.
Esta es la cantidad de experimentos que tuve que ejecutar para encontrar todo esto ...
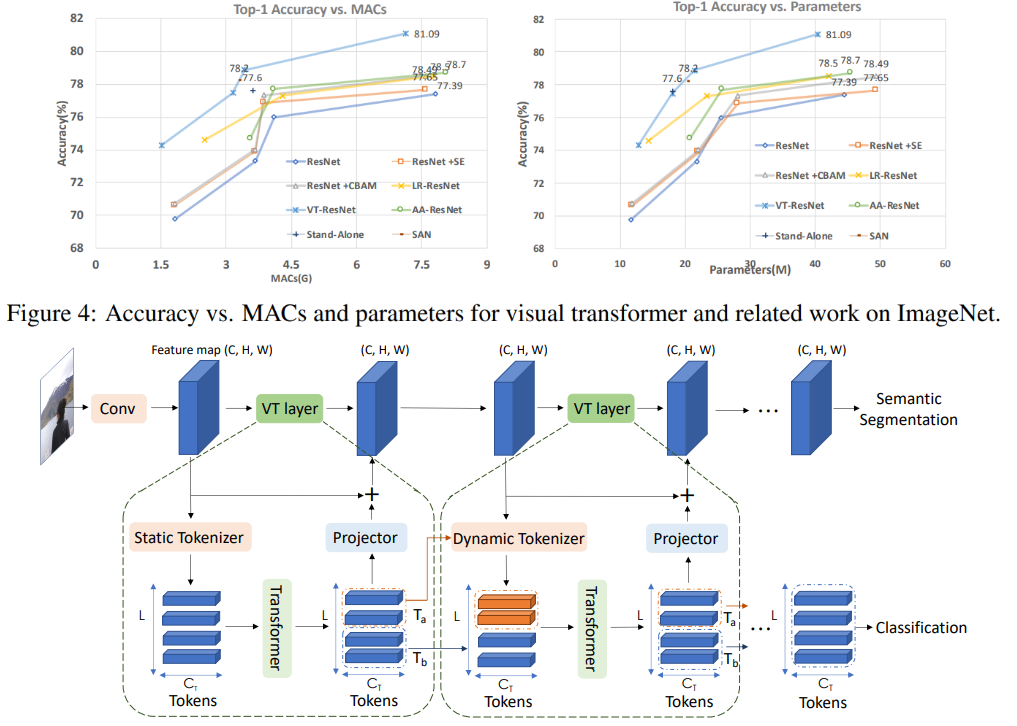
En este gráfico se puede ver que el enfoque da una mayor calidad con un número reducido de cálculos y el tamaño del modelo.
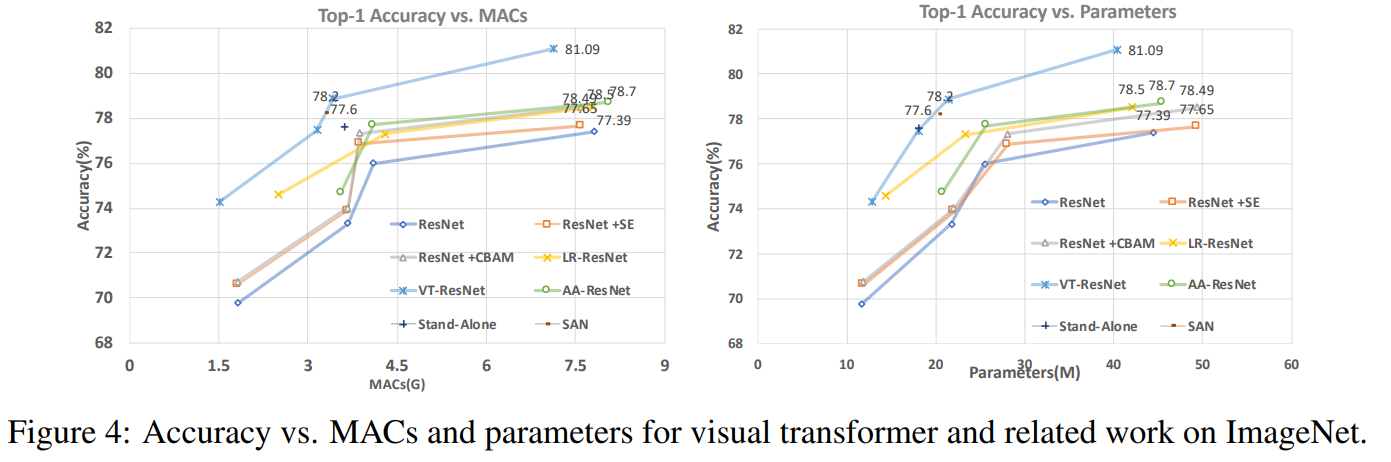
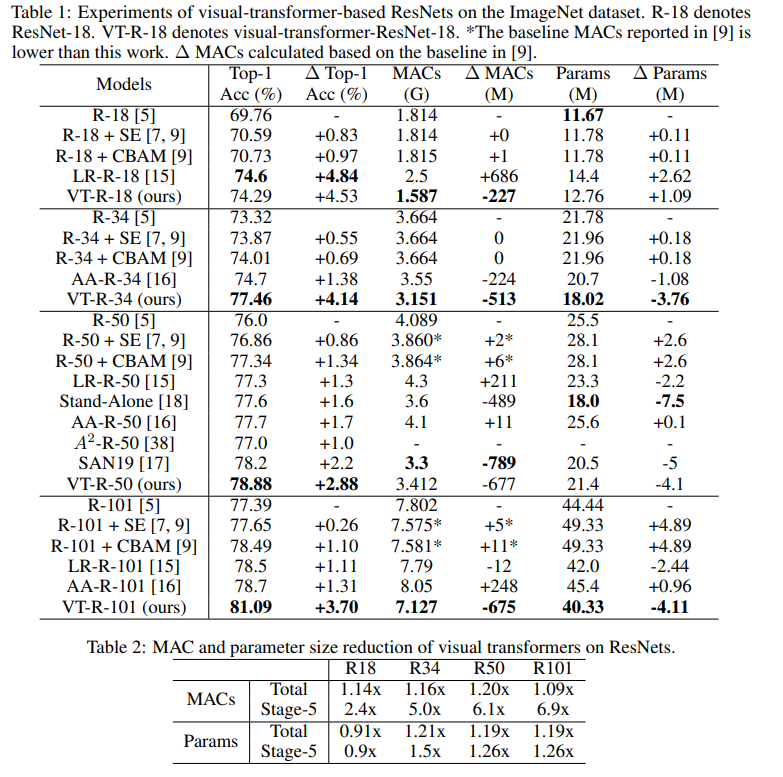
Títulos de artículos para modelos comparados:
ResNet + CBAM - Módulo de atención de bloques convolucionales ResNet + SE - Redes de compresión
y excitación
LR-ResNet - Redes de relación local para reconocimiento de imágenes
StandAlone: auto-atención autónoma en modelos de visión
AA-ResNet: redes convolucionales aumentadas de atención
SAN: exploración de la auto-atención para el reconocimiento de imágenes
Estudio de ablación
Para acelerar los experimentos, tomamos VT-ResNet- {18, 34} y entrenamos 90 épocas.
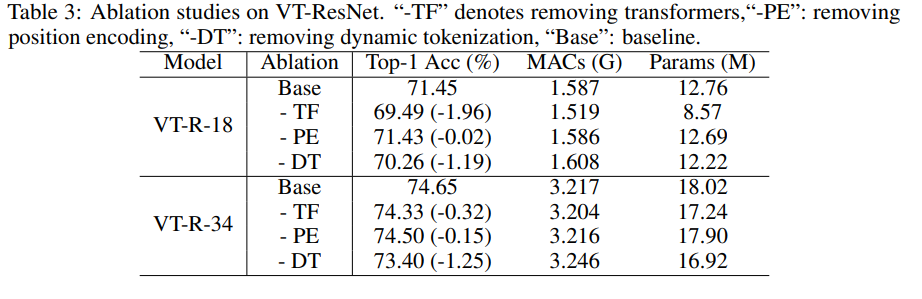
El uso de transformadores en lugar de convoluciones proporciona la mayor ganancia. La tokenización dinámica en lugar de la tokenización estática también da un gran impulso. La codificación de posición proporciona solo una ligera mejora.
Resultados de segmentación

Como puede ver, la métrica ha crecido solo ligeramente, pero el modelo consume 6.5 veces menos MAC.
Futuro potencial del enfoque
Los experimentos han demostrado que el enfoque propuesto permite crear modelos más eficientes (en términos de costos computacionales), que al mismo tiempo logran una mejor calidad. La arquitectura propuesta funciona con éxito para varias tareas de visión por computadora, y se espera que su aplicación ayude a mejorar los sistemas que utilizan la visión del exterior: AR / VR, automóviles autónomos y otros.
La revisión fue preparada por Andrey Lukyanenko, el desarrollador líder de MTS.