
Hola, Khabrovites. Hoy vamos a hablar de RxJava. Sé que sobre ella se ha escrito un vagón y un carrito pequeño, pero me parece que tengo un par de puntos interesantes que vale la pena compartir. Primero, te diré cómo usamos RxJava junto con la arquitectura VIPER para aplicaciones de Android, y al mismo tiempo, veremos la forma "clásica" de usarlo. Después de eso, repasemos las características principales de RxJava y analicemos con más detalle cómo funcionan los programadores. Si ya se ha abastecido de bocadillos, le damos la bienvenida al gato.
Una arquitectura que se adapta a todos
RxJava es una implementación del concepto ReactiveX y fue creado por Netflix. Su blog tiene una serie de artículos sobre por qué lo hicieron y qué problemas resolvieron. Los enlaces (1, 2) se pueden encontrar al final del artículo. Netflix usó RxJava en el lado del servidor (backend) para paralelizar el procesamiento de una solicitud grande. Aunque sugirieron una forma de usar RxJava en el backend, esta arquitectura es adecuada para escribir diferentes tipos de aplicaciones (móviles, de escritorio, backend y muchas otras). Los desarrolladores de Netflix usaron RxJava en la capa de servicio de tal manera que cada método de la capa de servicio devuelve un Observable. La cuestión es que los elementos de un Observable se pueden entregar de forma sincrónica y asincrónica. Esto permite que el método decida por sí mismo si devolver el valor inmediatamente sincrónicamente (por ejemplo,si está disponible en la caché) o primero obtenga estos valores (por ejemplo, de una base de datos o servicio remoto) y devuélvalos de forma asincrónica. En cualquier caso, el control volverá inmediatamente después de llamar al método (con o sin datos).
/**
* , ,
* , ,
* callback `onNext()`
*/
public Observable<T> getProduct(String name) {
if (productInCache(name)) {
// ,
return Observable.create(observer -> {
observer.onNext(getProductFromCache(name));
observer.onComplete();
});
} else {
//
return Observable.<T>create(observer -> {
try {
//
T product = getProductFromRemoteService(name);
//
observer.onNext(product);
observer.onComplete();
} catch (Exception e) {
observer.onError(e);
}
})
// Observable IO
// /
.subscribeOn(Schedulers.io());
}
}
Con este enfoque, obtenemos una API inmutable para el cliente (en nuestro caso, el controlador) y diferentes implementaciones. El cliente siempre interactúa con el Observable de la misma manera. No importa en absoluto si los valores se reciben sincrónicamente o no. Al mismo tiempo, las implementaciones de API pueden cambiar de síncronas a asíncronas, sin afectar la interacción con el cliente de ninguna manera. Con este enfoque, no puede pensar por completo en cómo organizar subprocesos múltiples y centrarse en la implementación de tareas comerciales.
El enfoque es aplicable no solo en la capa de servicio en el backend, sino también en las arquitecturas MVC, MVP, MVVM, etc. Por ejemplo, para MVP podemos hacer una clase Interactor que se encargará de recibir y guardar datos en diversas fuentes, y hacer que todo sus métodos devolvieron Observable. Serán un contrato de interacción con Model. Esto también permitirá a Presenter aprovechar todo el poder de los operadores disponibles en RxJava.
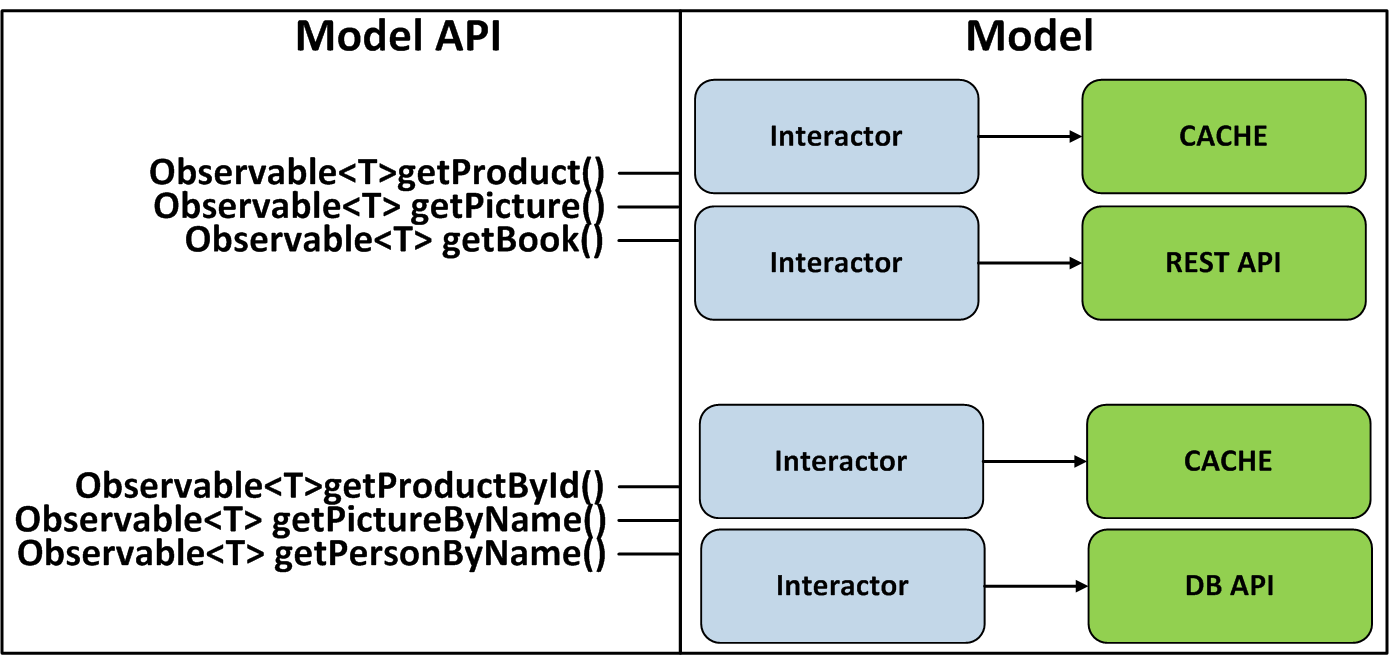
Podemos ir más allá y hacer que la API de Presenter sea reactiva, pero para ello necesitamos implementar correctamente el mecanismo de cancelación de suscripción que permite que todas las Vistas se cancelen simultáneamente de Presenter.
A continuación, veamos un ejemplo de cómo se aplica este enfoque para la arquitectura VIPER, que es un MVP mejorado. También vale la pena recordar que no puede crear objetos Singleton Observable, porque las suscripciones a dicho Observable generarán pérdidas de memoria.
Experiencia en Android y VIPER
En la mayoría de los proyectos de Android actuales y nuevos, utilizamos la arquitectura VIPER. La conocí cuando me incorporé a uno de los proyectos en los que ya estaba acostumbrada. Recuerdo que me sorprendió cuando me preguntaron si estaba mirando hacia iOS. "¿IOS en un proyecto de Android?", Pensé. Mientras tanto, VIPER nos llegó desde el mundo de iOS y, de hecho, es una versión más estructurada y modular de MVP. VIPER está muy bien escrito en este artículo (3).
Al principio todo parecía estar bien: capas correctamente divididas, no sobrecargadas, cada capa tiene su propia área de responsabilidad, lógica clara. Pero después de un tiempo, comenzó a aparecer un inconveniente y, a medida que el proyecto crecía y cambiaba, incluso comenzó a interferir.
El hecho es que usamos Interactor de la misma manera que nuestros colegas en nuestro artículo. Interactor implementa un pequeño caso de uso, por ejemplo, "descargar productos de la red" o "tomar un producto de la base de datos por id", y realiza acciones en el flujo de trabajo. Internamente, el Interactor realiza operaciones usando un Observable. Para "ejecutar" el Interactor y obtener el resultado, el usuario implementa la interfaz ObserverEntity junto con sus métodos onNext, onError y onComplete y lo pasa junto con los parámetros al método execute (params, ObserverEntity).
Probablemente ya haya notado el problema: la estructura de la interfaz. En la práctica, rara vez necesitamos los tres métodos, a menudo usamos uno o dos de ellos. Debido a esto, pueden aparecer métodos vacíos en su código. Por supuesto, podemos marcar todos los métodos de la interfaz como predeterminados, pero estos métodos son bastante necesarios para agregar nuevas funciones a las interfaces. Además, es extraño tener una interfaz donde todos los métodos son opcionales. También podemos, por ejemplo, crear una clase abstracta que herede una interfaz y anule los métodos que necesitamos. O, finalmente, cree versiones sobrecargadas del método execute (params, ObserverEntity) que acepten de una a tres interfaces funcionales. Este problema es malo para la legibilidad del código, pero, afortunadamente, es bastante fácil de resolver. Sin embargo, ella no es la única.
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
// ,
//
}
@Override
public void onError(Throwable throwable) {
//
// -
}
@Override
public void onComplete() {
//
// -
}
});
Además de los métodos vacíos, existe un problema más molesto. Usamos Interactor para realizar una acción, pero casi siempre esta acción no es la única. Por ejemplo, podemos tomar un producto de una base de datos, luego obtener reseñas y una imagen sobre él, luego guardarlo todo en otro lugar y finalmente ir a otra pantalla. Aquí, cada acción depende de la anterior, y cuando usamos Interactors, obtenemos una enorme cadena de devoluciones de llamada, que puede ser muy tedioso de rastrear.
private void checkProduct(int id, Locale locale) {
getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale), new ObserverEntity<Product>() {
@Override
public void onNext(Product product) {
getProductInfo(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void getProductInfo(Product product) {
getReviewsByProductIdInteractor.execute(product.getId(), new ObserverEntity<List<Review>>() {
@Override
public void onNext(List<Review> reviews) {
product.setReviews(reviews);
saveProduct(productInfo);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
// -
}
});
getImageForProductInteractor.execute(product.getId(), new ObserverEntity<Image>() {
@Override
public void onNext(Image image) {
product.setImage(image);
saveProduct(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void saveProduct(Product product) {
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
goToSomeScreen();
}
});
}
Bueno, ¿qué te parece esta pasta? Al mismo tiempo, tenemos una lógica empresarial simple y un anidamiento único, pero imagine lo que sucedería con un código más complejo. También dificulta la reutilización del método y la aplicación de diferentes programadores para el Interactor.
La solución es sorprendentemente sencilla. ¿Siente que este enfoque está tratando de imitar el comportamiento de un Observable, pero se equivoca y crea restricciones extrañas en sí mismo? Como dije antes, obtuvimos este código de un proyecto existente. Al arreglar este código heredado, usaremos el enfoque que los chicos de Netflix nos legaron. En lugar de tener que implementar un ObserverEntity cada vez, hagamos que el Interactor devuelva un Observable.
private Observable<Product> getProductById(int id, Locale locale) {
return getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale));
}
private Observable<Product> getProductInfo(Product product) {
return getReviewsByProductIdInteractor.execute(product.getId())
.map(reviews -> {
product.set(reviews);
return product;
})
.flatMap(product -> {
getImageForProductInteractor.execute(product.getId())
.map(image -> {
product.set(image);
return product;
})
});
}
private Observable<Product> saveProduct(Product product) {
return saveProductInteractor.execute(product);
}
private doAll(int id, Locale locale) {
//
getProductById (id, locale)
//
.flatMap(product -> getProductInfo(product))
//
.flatMap(product -> saveProduct(product))
//
.ignoreElements()
//
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
//
.subscribe(() -> goToSomeScreen(), throwable -> handleError());
}
¡Voila! Así que no solo nos deshicimos de ese horror engorroso y difícil de manejar, sino que también llevamos el poder de RxJava a Presentador.
Conceptos en el corazón
Muy a menudo vi cómo intentaban explicar el concepto de RxJava usando programación reactiva funcional (en adelante, FRP). De hecho, no tiene nada que ver con esta biblioteca. FRP se trata más de valores (comportamientos) que cambian dinámicamente continuos, tiempo continuo y semántica denotacional. Al final del artículo, puede encontrar un par de enlaces interesantes (4, 5, 6, 7).
RxJava utiliza la programación reactiva y la programación funcional como conceptos centrales. La programación reactiva puede describirse como la transferencia secuencial de información del objeto observado al objeto observador de tal manera que el objeto observador la recibe automáticamente (asincrónicamente) a medida que surge esta información.
La programación funcional utiliza el concepto de funciones puras, es decir, aquellas que no utilizan ni cambian de estado externo; dependen completamente de sus entradas para obtener sus salidas. La ausencia de efectos secundarios para funciones puras hace posible utilizar los resultados de una función como parámetros de entrada para otra. Esto hace posible crear una cadena ilimitada de funciones.
La combinación de estos dos conceptos, junto con los patrones GoF Observer e Iterator, le permite crear flujos de datos asincrónicos y procesarlos con un enorme arsenal de funciones muy útiles. También hace posible el uso de subprocesos múltiples de manera muy simple y, lo que es más importante, de manera segura, sin pensar en sus problemas como la sincronización, inconsistencia de memoria, superposición de subprocesos, etc.
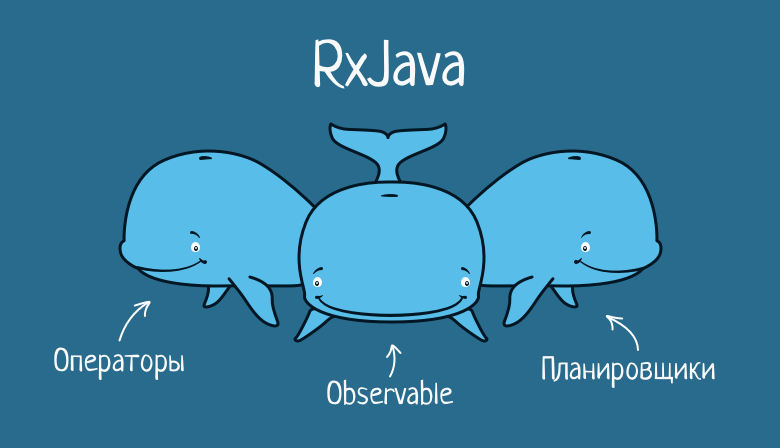
Tres ballenas de RxJava
Los tres componentes principales sobre los que se basa RxJava son Observable, operadores y programadores.
Observable en RxJava se encarga de implementar el paradigma reactivo. Los observables a menudo se denominan flujos porque implementan tanto el concepto de flujos de datos como la propagación de cambios. Observable es un tipo que logra una implementación de paradigma reactivo mediante la combinación de dos patrones de la Banda de los Cuatro: Observador e Iterador. Observable agrega dos semánticas faltantes a Observer, que están en Iterable:
- La capacidad del productor de indicar al consumidor que no hay más datos disponibles (el ciclo foreach en Iterable termina y simplemente regresa; el Observable en este caso llama al método onCompleate).
- La capacidad del productor de informar al consumidor que ha ocurrido un error y el Observable ya no puede emitir elementos (Iterable lanza una excepción si ocurre un error durante la iteración; Observable llama a onError en su observador y sale).
Si el Iterable usa el enfoque "pull", es decir, el consumidor solicita un valor del productor, y el hilo se bloquea hasta que llega ese valor, entonces el Observable es su equivalente "push". Esto significa que el productor solo envía valores al consumidor cuando están disponibles.
Observable es solo el comienzo de RxJava. Le permite obtener valores de forma asincrónica, pero el poder real viene con "extensiones reactivas" (de ahí ReactiveX) - operadoresque le permiten transformar, combinar y crear secuencias de elementos emitidos por un Observable. Aquí es donde el paradigma funcional pasa a primer plano con sus funciones puras. Los operadores aprovechan al máximo este concepto. Te permiten trabajar de forma segura con las secuencias de elementos que emite un Observable, sin miedo a los efectos secundarios, a menos que, por supuesto, los crees tú mismo. Los operadores permiten el subproceso múltiple sin preocuparse por problemas como seguridad de subprocesos, control de subprocesos de bajo nivel, sincronización, errores de inconsistencia de memoria, superposiciones de subprocesos, etc. Al tener un gran arsenal de funciones, puede operar fácilmente con varios datos. Esto nos da una herramienta muy poderosa. Lo principal para recordar es que los operadores modifican los elementos emitidos por el Observable, no el Observable en sí.Los observables nunca cambian desde que fueron creados. Al pensar en hilos y operadores, es mejor pensar en gráficos. Si no sabe cómo resolver el problema, piense, mire la lista completa de operadores disponibles y vuelva a pensar.
Si bien el concepto de programación reactiva en sí es asíncrono (no debe confundirse con subprocesos múltiples), de forma predeterminada, todos los elementos de un Observable se envían al suscriptor de forma sincrónica, en el mismo hilo en el que se llamó al método subscribe (). Para introducir esa asincronía, debe llamar a los métodos onNext (T), onError (Throwable), onComplete () usted mismo en otro hilo de ejecución, o usar programadores. Por lo general, todos analizan su comportamiento, así que echemos un vistazo a su estructura.
Planificadoresabstraer al usuario de la fuente de paralelismo detrás de su propia API. Garantizan que proporcionarán propiedades específicas independientemente del mecanismo de concurrencia subyacente (implementación), como subprocesos, bucle de eventos o ejecutor. Los planificadores utilizan subprocesos demoníacos. Esto significa que el programa terminará con la terminación del hilo principal de ejecución, incluso si ocurre algún cálculo dentro del operador Observable.
RxJava tiene varios programadores estándar que son adecuados para propósitos específicos. Todos ellos extienden la clase de Programador abstracto e implementan su propia lógica para administrar trabajadores. Por ejemplo, ComputationScheduler, en el momento de su creación, forma un grupo de trabajadores, cuyo número es igual al número de subprocesos del procesador. ComputationScheduler luego usa trabajadores para realizar tareas ejecutables. Puede pasar el Runnable al planificador utilizando los métodos scheduleDirect () y schedulePeriodicallyDirect (). Para ambos métodos, el programador toma el siguiente trabajador del grupo y le pasa el Runnable.
El trabajador está dentro del programador y es una entidad que ejecuta objetos (tareas) ejecutables utilizando uno de varios esquemas de concurrencia. En otras palabras, el programador obtiene el Runnable y lo pasa al trabajador para su ejecución. También puede obtener de forma independiente un trabajador del programador y transferirle uno o más Runnables, independientemente de otros trabajadores y del programador mismo. Cuando un trabajador recibe una tarea, la pone en la cola. El trabajador garantiza que las tareas se ejecutan secuencialmente en el orden en que fueron enviadas, pero el orden puede verse alterado por tareas pendientes. Por ejemplo, en ComputationScheduler, el trabajador se implementa mediante un solo hilo ScheduledExecutorService.
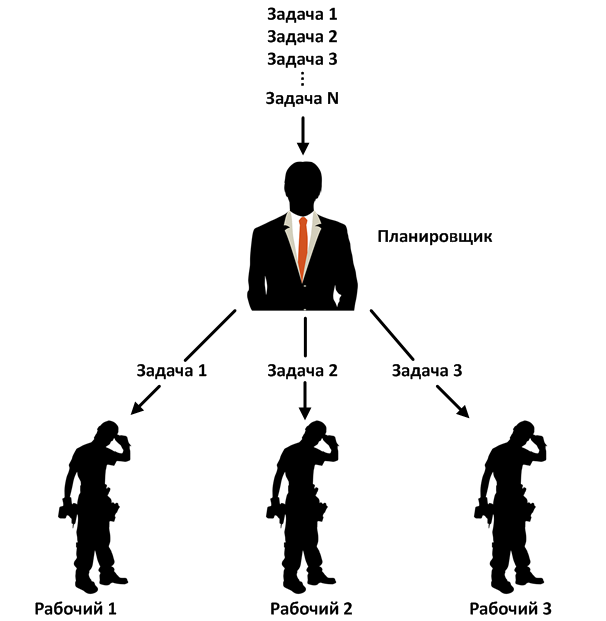
Por lo tanto, tenemos trabajadores abstractos que pueden implementar cualquier esquema de paralelismo. Este enfoque ofrece muchas ventajas: modularidad, flexibilidad, una API, diferentes implementaciones. Vimos un enfoque similar en ExecutorService. Además, podemos usar programadores separados de Observable.
Conclusión
RxJava es una biblioteca muy poderosa que se puede usar de una amplia variedad de formas en muchas arquitecturas. Las formas de usarlo no se limitan a las existentes, así que siempre intente adaptarlo usted mismo. Sin embargo, recuerde SOLID, DRY y otros principios de diseño, y no olvide compartir su experiencia con sus colegas. Espero que hayas podido aprender algo nuevo e interesante del artículo, ¡nos vemos!