Me gustaría compartir la experiencia de implementar redes neuronales de moda en nuestra empresa. Todo comenzó cuando decidimos construir nuestro propio Service Desk. Por qué y por qué el suyo, puede leer a mi colega Alexei Volkov (cface) aquí .
Te cuento una reciente innovación en el sistema: una red neuronal para ayudar al despachador de la primera línea de soporte. Si está interesado, bienvenido a cat.

Aclaración de la tarea
Un dolor de cabeza para cualquier administrador de la mesa de ayuda es una decisión rápida para asignar a una solicitud entrante de un cliente. Aquí están las solicitudes:
Buenas tardes.
Entiendo correctamente: para poder compartir el calendario con un usuario específico, es necesario abrir el acceso a su calendario en la PC del usuario que quiere compartir el calendario e ingresar el correo del usuario al que quiere dar acceso.
De acuerdo con la normativa, el despachador debe responder en dos minutos: registrar una solicitud, determinar la urgencia y designar una unidad responsable. El despachador elige entre 44 divisiones de la empresa.
Las instrucciones de los despachadores describen una solución para las consultas más comunes. Por ejemplo, proporcionar acceso a un centro de datos es una simple solicitud. Pero las solicitudes de servicio incluyen muchas tareas: instalar software, analizar una situación o actividad de la red, conocer los detalles de la facturación de las soluciones, comprobar todo tipo de accesos. A veces es difícil entender de la solicitud a quién del responsable enviar la pregunta:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Hubo situaciones en las que la solicitud se envió al departamento equivocado. La solicitud se llevó al trabajo y luego se reasignó a otros artistas o se envió al despachador. Esto aumentó la velocidad de la solución. El tiempo para resolver las solicitudes está escrito en el acuerdo con el cliente (SLA), y somos responsables de cumplir con los plazos.
Dentro del sistema, decidimos crear un asistente para despachadores. El objetivo principal era agregar indicaciones que ayuden al empleado a tomar una decisión sobre la aplicación más rápido.
Sobre todo, no quería sucumbir a la nueva tendencia y poner al chatbot en la primera línea de soporte. Si alguna vez ha intentado escribir a dicho soporte técnico (que ya no peca con esto), comprende lo que quiero decir.
En primer lugar, te entiende muy mal y no responde en absoluto a solicitudes atípicas, y en segundo lugar, es muy difícil llegar a una persona viva.
En general, definitivamente no planeamos reemplazar a los despachadores con bots de chat, ya que queremos que los clientes aún se comuniquen con una persona en vivo.
Al principio, pensé en salirme barato y alegre y probé el enfoque de palabras clave. Compilamos un diccionario de palabras clave manualmente, pero esto no fue suficiente. La solución solo hizo frente a aplicaciones simples, con las que no hubo problemas.
Durante el trabajo de nuestro Service Desk, hemos acumulado un historial sólido de solicitudes, sobre cuya base podemos reconocer solicitudes entrantes similares y asignarlas de inmediato a los ejecutores correctos. Armado con Google y hace algún tiempo, decidí profundizar en mis opciones.
Teoría del aprendizaje
Resultó que mi tarea es una tarea de clasificación clásica. En la entrada, el algoritmo recibe el texto principal de la aplicación, en la salida lo asigna a una de las clases conocidas anteriormente, es decir, las divisiones de la empresa.
Hubo muchas soluciones. Se trata de una "red neuronal" y un "clasificador bayesiano ingenuo", "vecinos más cercanos", "regresión logística", "árbol de decisión", "impulso" y muchas, muchas otras opciones.
No habría tiempo para probar todas las técnicas. Por lo tanto, me decidí por las redes neuronales (hace tiempo que quería intentar trabajar con ellas). Como resultó más tarde, esta elección estaba plenamente justificada.
Entonces, comencé mi inmersión en las redes neuronales desde aquí . Algoritmos de aprendizaje estudiadosRedes neuronales: con profesor (aprendizaje supervisado), sin profesor (aprendizaje no supervisado), con participación parcial de un profesor (aprendizaje semi-supervisado) o “aprendizaje reforzado”.
Como parte de mi tarea surgió el método de enseñanza con un profesor. Hay datos más que suficientes para el entrenamiento: más de 100k de aplicaciones resueltas.
Elección de implementación
Elegí la biblioteca Encog Machine Learning Framework para la implementación . Viene con documentación accesible y comprensible con ejemplos . Además, la implementación para Java, que está cerca de mí.
Brevemente, la mecánica del trabajo se ve así:
- El marco de la red neuronal está preconfigurado: varias capas de neuronas conectadas por conexiones de sinapsis.

- Se carga en la memoria un conjunto de datos de entrenamiento con un resultado predeterminado.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
Probé varios ejemplos del marco, me di cuenta de que la biblioteca hace frente a los números en la entrada con una explosión. Entonces, el ejemplo con la definición de la clase de iris por el tamaño del cuenco y los pétalos ( Fisher's Irises ) funcionó bien .
Pero tengo algo de texto. Esto significa que las letras deben convertirse de alguna manera en números. Así que pasé a la primera etapa preparatoria: "vectorización".
La primera opción de vectorización: por letra
La forma más fácil de convertir texto en números es tomar el alfabeto en la primera capa de la red neuronal. Se obtienen 33 letras-neuronas:
A cada uno se le asigna un número: la presencia de una letra en una palabra se toma como uno y la ausencia se considera cero.
Entonces, la palabra "hola" en esta codificación tendrá un vector:

tal vector ya se puede dar a la red neuronal para entrenamiento. Después de todo, este número es 001001000100000011010000000000000 = 1216454656 Habiendo profundizado
en la teoría, me di cuenta de que no tiene sentido analizar letras. No tienen ningún significado semántico. Por ejemplo, la letra "A" estará en cada texto de la propuesta. Tenga en cuenta que esta neurona está siempre encendida y no tendrá ningún efecto sobre el resultado. Como todas las demás vocales. Y en el texto de la aplicación estarán la mayoría de las letras del alfabeto. Esta opción no es adecuada.
La segunda variante de vectorización: por diccionario
¿Y si no tomas letras, sino palabras? Digamos el diccionario explicativo de Dahl. Y contar como 1 ya la presencia de una palabra en el texto, y la ausencia - como 0.
Pero aquí me encontré con el número de palabras. El vector resultará muy grande. Una neurona con 200k neuronas de entrada tardará una eternidad y necesitará mucha memoria y tiempo de CPU. Tienes que hacer tu propio diccionario. Además, los textos contienen características específicas de TI que Vladimir Ivanovich Dal no conocía.
Volví a la teoría. Para acortar el vocabulario al procesar textos, utilice los mecanismos de N-gramas , una secuencia de N elementos.
La idea es dividir el texto de entrada en algunos segmentos, componer un diccionario a partir de ellos y alimentar a la red neuronal con la presencia o ausencia de una frase en el texto original como 1 o 0. Es decir, en lugar de una letra, como en el caso del alfabeto, no solo una letra, sino una frase completa se tomará como 0 o 1.
Los más populares son unigramas, bigramas y trigramas. Usando la frase "Bienvenido a DataLine" como ejemplo, le contaré sobre cada uno de los métodos.
- Unigram: el texto se divide en las palabras: "bueno", "bienvenido", "v", "DataLine".
- Bigram: lo dividimos en pares de palabras: "bienvenido", "bienvenido a", "a DataLine".
- Trigram: de manera similar, 3 palabras cada una: "bienvenido a", "bienvenido a DataLine".
- N-gramas - entiendes la idea. Cuántas N, tantas palabras seguidas.
- N-. , . 4- N- : «»,« », «», «» . . .
Decidí limitarme al unigrama. Pero no solo un unigrama, las palabras aún salieron demasiado.
El algoritmo "Porter's Stemmer" vino al rescate , que se utilizó para unificar palabras en 1980.
La esencia del algoritmo: eliminar sufijos y terminaciones de la palabra, dejando solo la parte semántica básica. Por ejemplo, las palabras "importante", "importante", "importante", "importante", "importante", "importante" se llevan a la base "importante". Es decir, en lugar de 6 palabras, habrá una en el diccionario. Y esta es una reducción significativa.
Además, eliminé del diccionario todos los números, signos de puntuación, preposiciones y palabras raras, para no crear "ruido". Como resultado, para 100 mil textos, obtuvimos un diccionario de 3 mil palabras. Ya puedes trabajar con esto.
Entrenamiento de redes neuronales
Entonces ya tengo:
- Diccionario de 3k palabras.
- Representación de diccionario vectorizado.
- Los tamaños de las capas de entrada y salida de la red neuronal. Según la teoría, se proporciona un diccionario en la primera capa (entrada) y la capa final (salida) es el número de clases de solución. Tengo 44 de ellos, según el número de divisiones de la empresa.
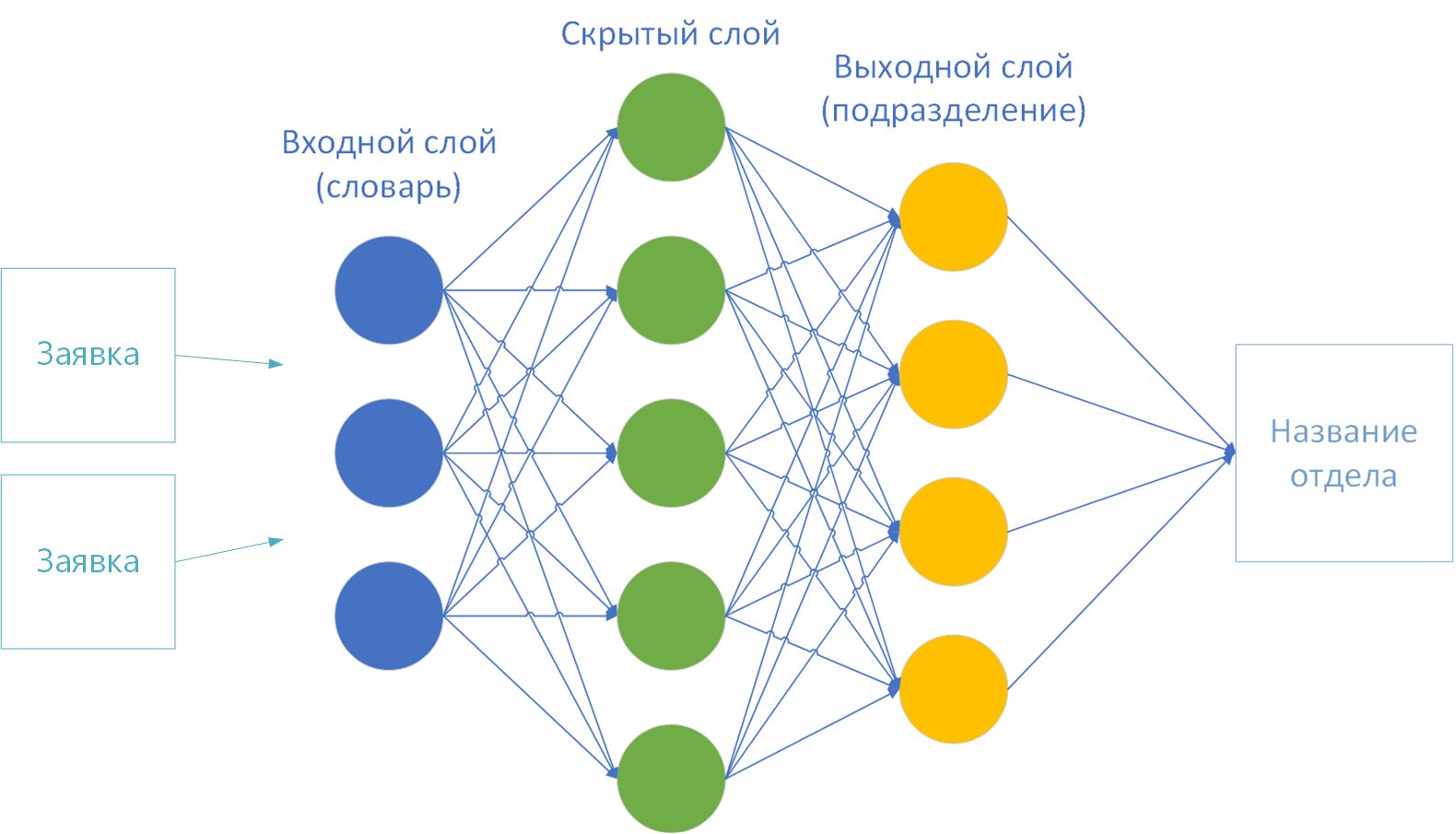
Para entrenar una red neuronal, queda muy poco para elegir:
- Método de enseñanza.
- Función de activación.
- El número de capas ocultas.
Cómo elegí los parámetros . Los parámetros siempre se seleccionan empíricamente para cada tarea específica. Este es el proceso más largo y tedioso, ya que requiere mucha experimentación.
Entonces, tomé una muestra de referencia de 11k aplicaciones e hice el cálculo de una red neuronal con varios parámetros:
- En 10k entrené una red neuronal.
- En 1k verifiqué la red ya entrenada.
Es decir, en 10k construimos un vocabulario y aprendemos. Y luego mostramos la red neuronal entrenada 1k textos desconocidos. El resultado es el porcentaje de error: la proporción de unidades adivinadas sobre el número total de textos.
Como resultado, logré una precisión de aproximadamente el 70% en datos desconocidos.
Empíricamente, descubrí que el entrenamiento puede continuar indefinidamente si se eligen los parámetros incorrectos. Un par de veces, la neurona entró en un ciclo de cálculo sin fin y colgó la máquina en funcionamiento durante la noche. Para evitar esto, por mí mismo, acepté el límite de 100 iteraciones o hasta que el error de red deje de disminuir.
Estos son los parámetros:
Método de enseñanza . Encog ofrece varias opciones para elegir: Retropropagación, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Estas son diferentes formas de determinar los pesos en las sinapsis. Algunos de los métodos funcionan más rápido, otros son más precisos, es mejor leer más en la documentación. La propagación resiliente funcionó bien para mí .
Función de activación . Es necesario determinar el valor de la neurona en la salida, dependiendo del resultado de la suma ponderada de las entradas y el valor umbral.
Elegí entre 16 opciones . No tuve tiempo suficiente para verificar todas las funciones. Por lo tanto, consideré las más populares: tangente sigmoidea e hiperbólica en varias implementaciones.
Al final, me decidí por ActivationSigmoid .
Número de capas ocultas... En teoría, cuantas más capas ocultas, más largo y difícil es el cálculo. Comencé con una capa: el cálculo fue rápido, pero el resultado fue inexacto. Me decidí por dos capas ocultas. Con tres capas, se consideró mucho más largo y el resultado no difirió mucho de uno de dos capas.
Sobre esto terminé los experimentos. Puede preparar la herramienta para la producción.
¡A la producción!
Además es una cuestión de tecnología.
- Arruiné a Spark para poder comunicarme con la neurona a través de REST.
- Enseñado a guardar los resultados del cálculo en un archivo. No siempre para volver a calcular al reiniciar el servicio.
- Se agregó la capacidad de leer datos reales para capacitación directamente desde el Service Desk. Entrenado previamente en archivos csv.
- Se agregó la capacidad de volver a calcular la red neuronal para adjuntar el nuevo cálculo al programador.
- Recogí todo en un frasco grueso.
- Les pedí a mis colegas un servidor más potente que una máquina de desarrollo.
- Zadeploil y zashedulil cuentan una vez a la semana.
- Atornillé el botón en el lugar correcto en el Service Desk y les escribí a mis colegas cómo usar este milagro.
- Recopilé estadísticas sobre lo que elige la neurona y lo que elige la persona (estadísticas a continuación).
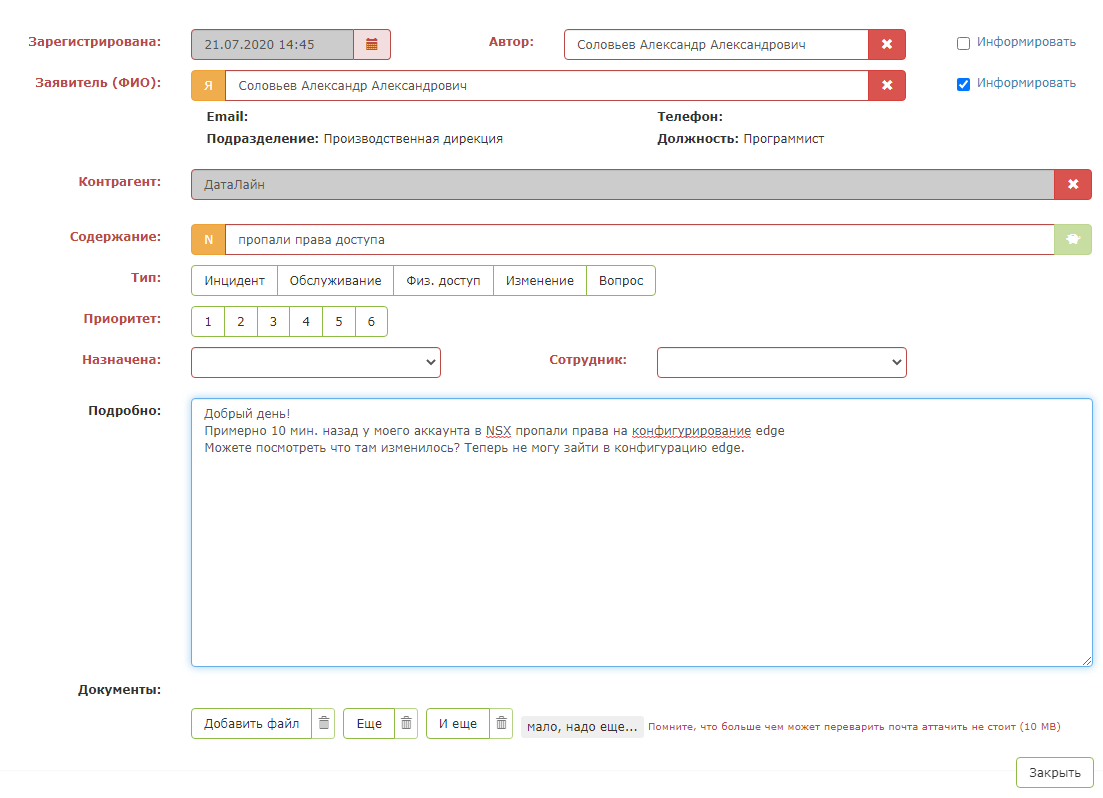
Así es como se ve una aplicación de prueba:
Pero tan pronto como presionas el "botón verde mágico", ocurre la magia: los campos de la tarjeta se completan. El despachador debe asegurarse de que el sistema solicita correctamente y guardar la solicitud.
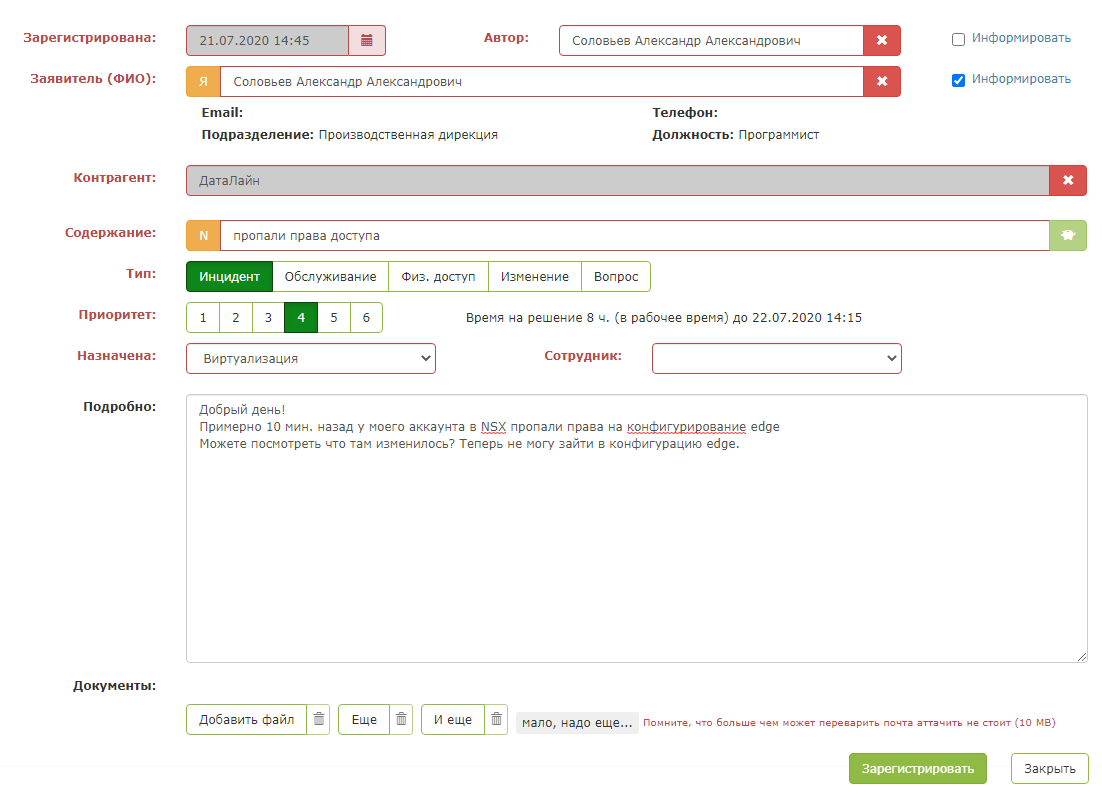
El resultado es un asistente tan inteligente para el despachador.
Por ejemplo, estadísticas de principios de año.
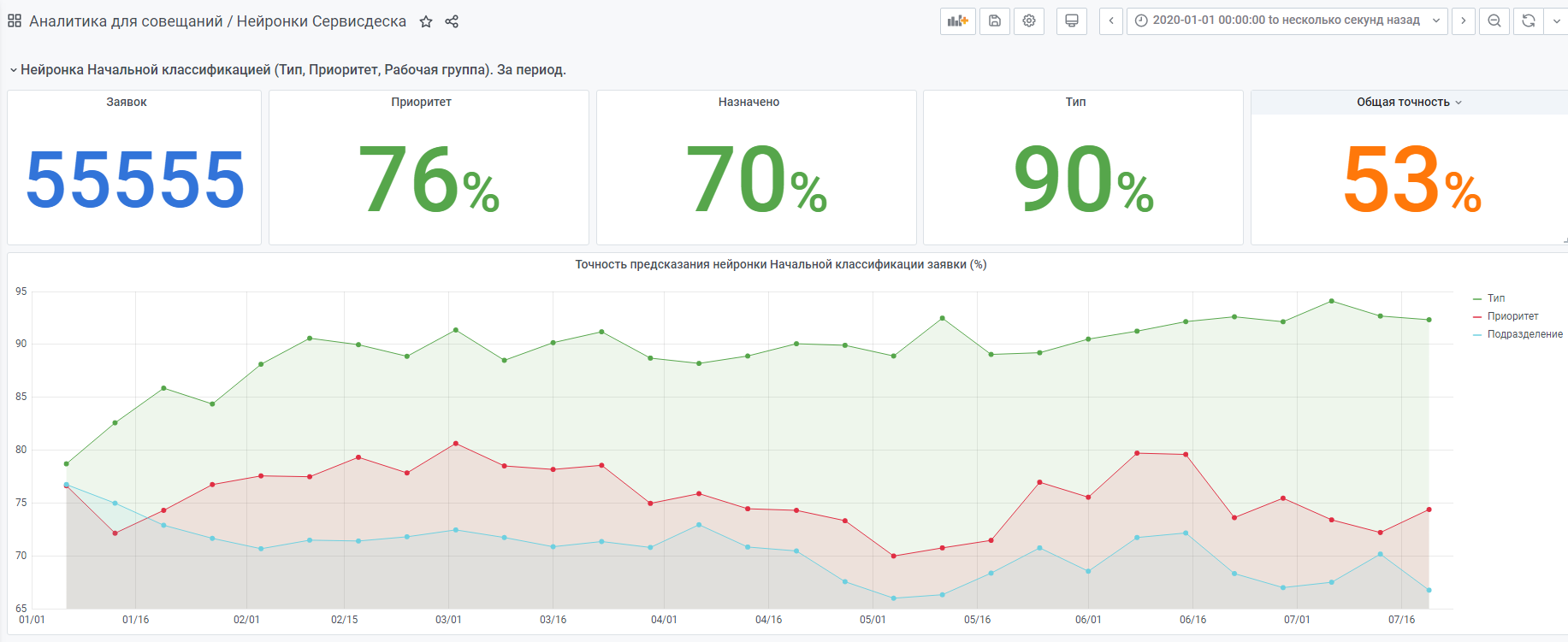
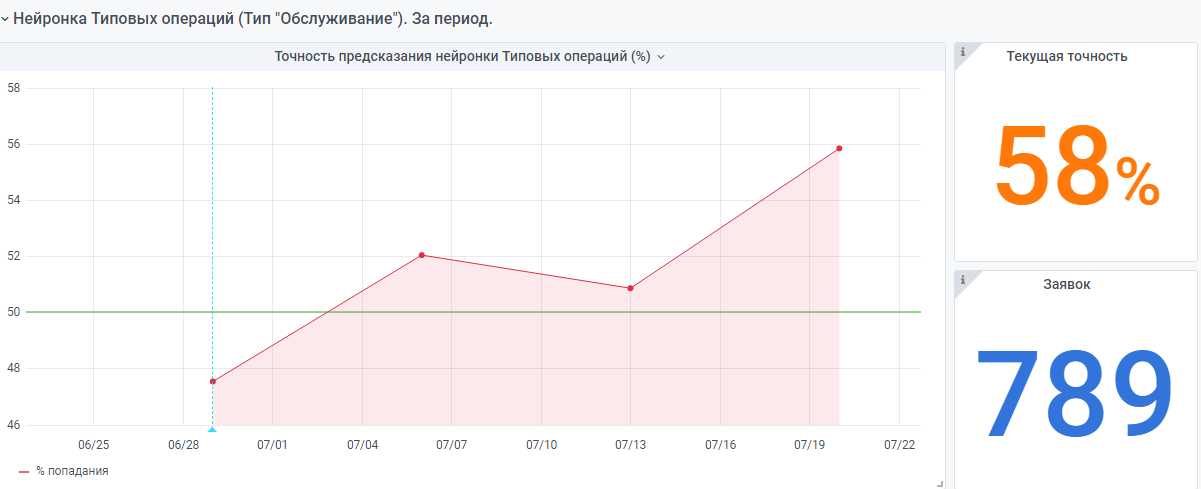
También hay una red neuronal "muy joven" hecha de acuerdo con el mismo principio. Pero todavía hay pocos datos, todavía está ganando experiencia.
Me alegrará que mi experiencia ayude a alguien a crear su propia red neuronal.
Si tienes alguna pregunta, estaré encantado de responderte.