
Editor de datos
Editor de gran valor
Hemos adjuntado un editor completo a las celdas. Si una celda contiene un valor largo, como XML o JSON, es conveniente abrirlo en un panel separado. Para hacer esto, haga clic en
Maximizar en el menú contextual.
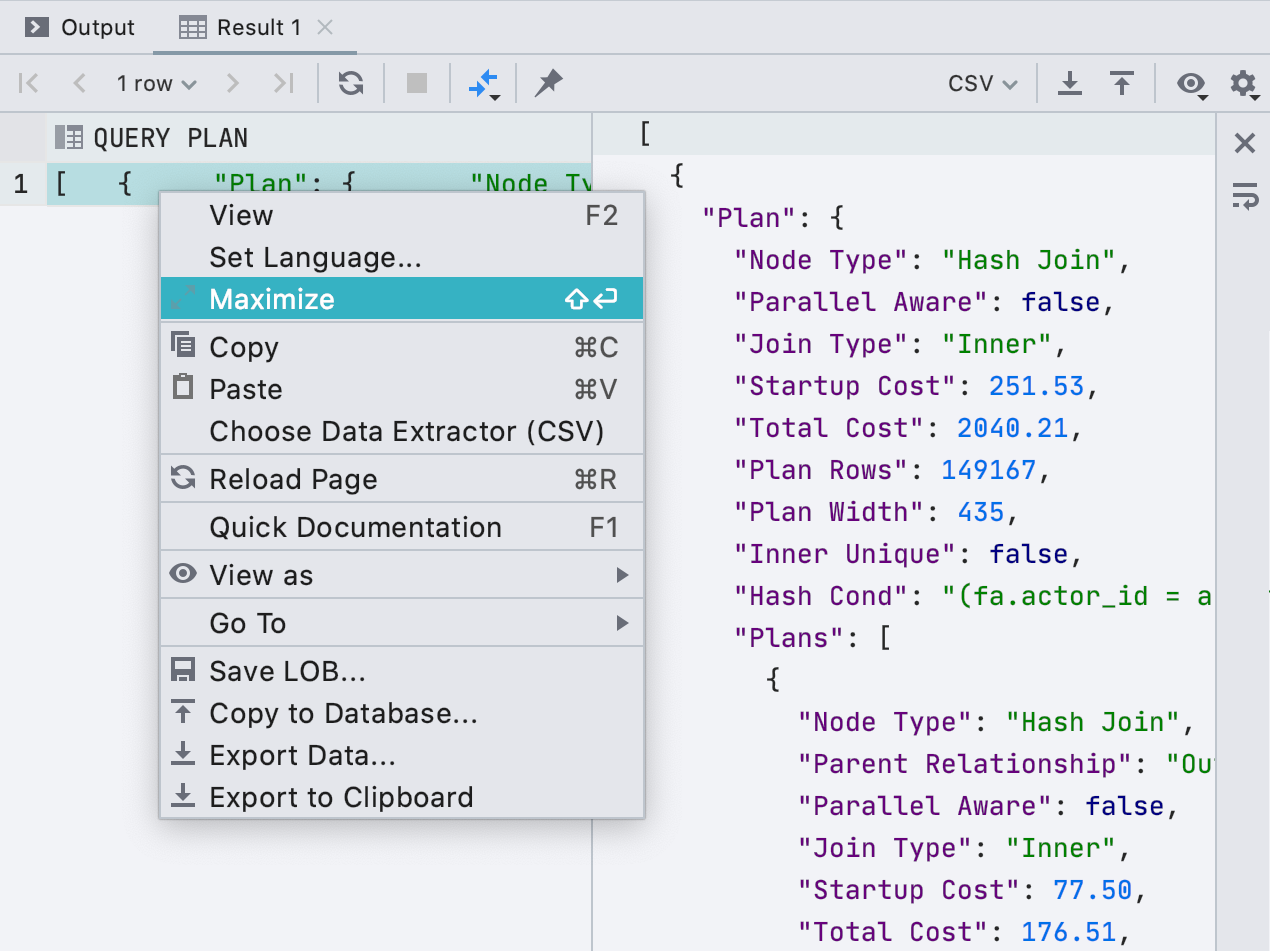
Vista previa de una consulta mientras se edita
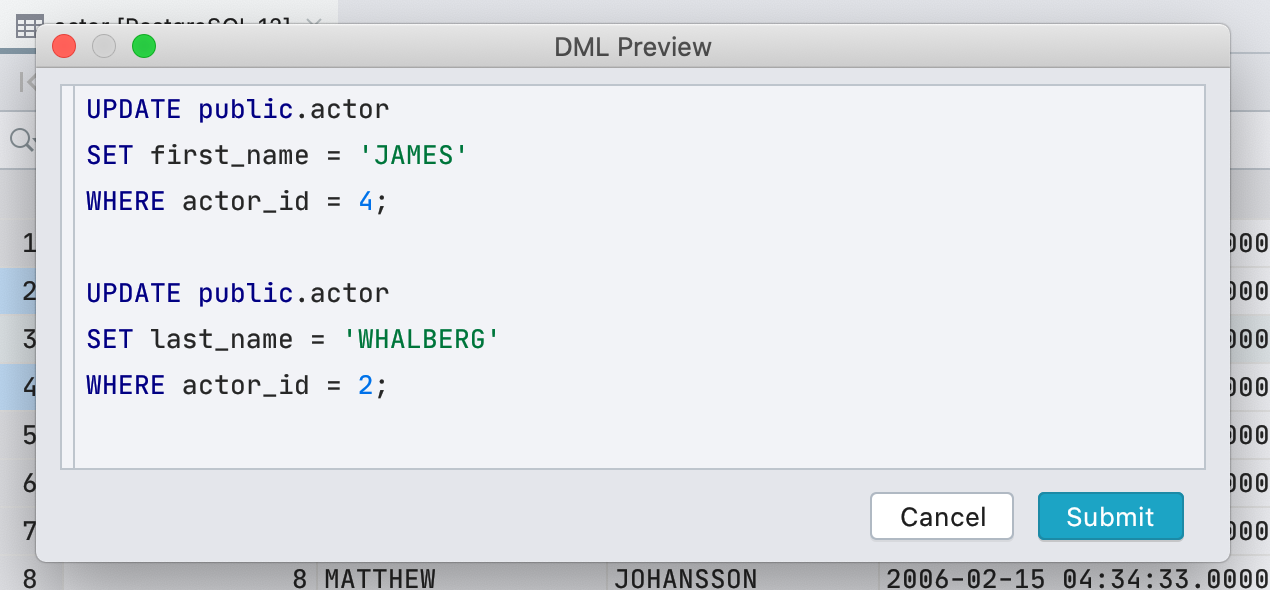
ahora, antes de escribir nuevos valores en el editor de datos, puede ver qué consulta se ejecutará. Para hacer esto, haga clic en el botón DML en la barra de herramientas.
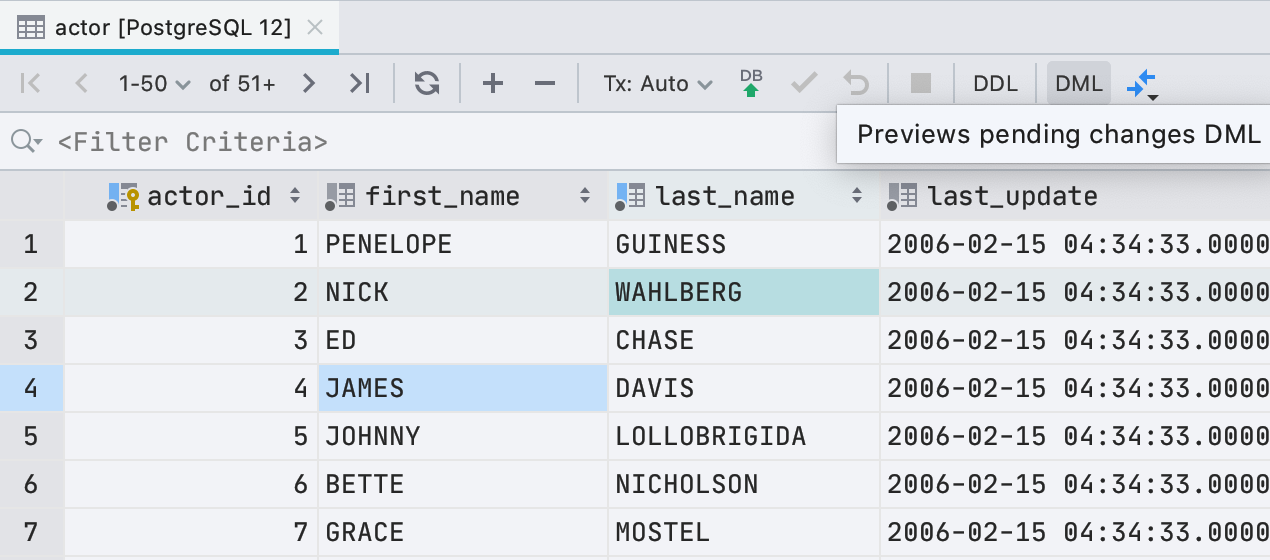
Para ser honesto, no es solo la consulta que ejecutamos porque para editar datos, DataGrip usa JDBC-driver. Pero en la mayoría de los casos, lo que mostramos coincidirá con lo que realmente comienza.
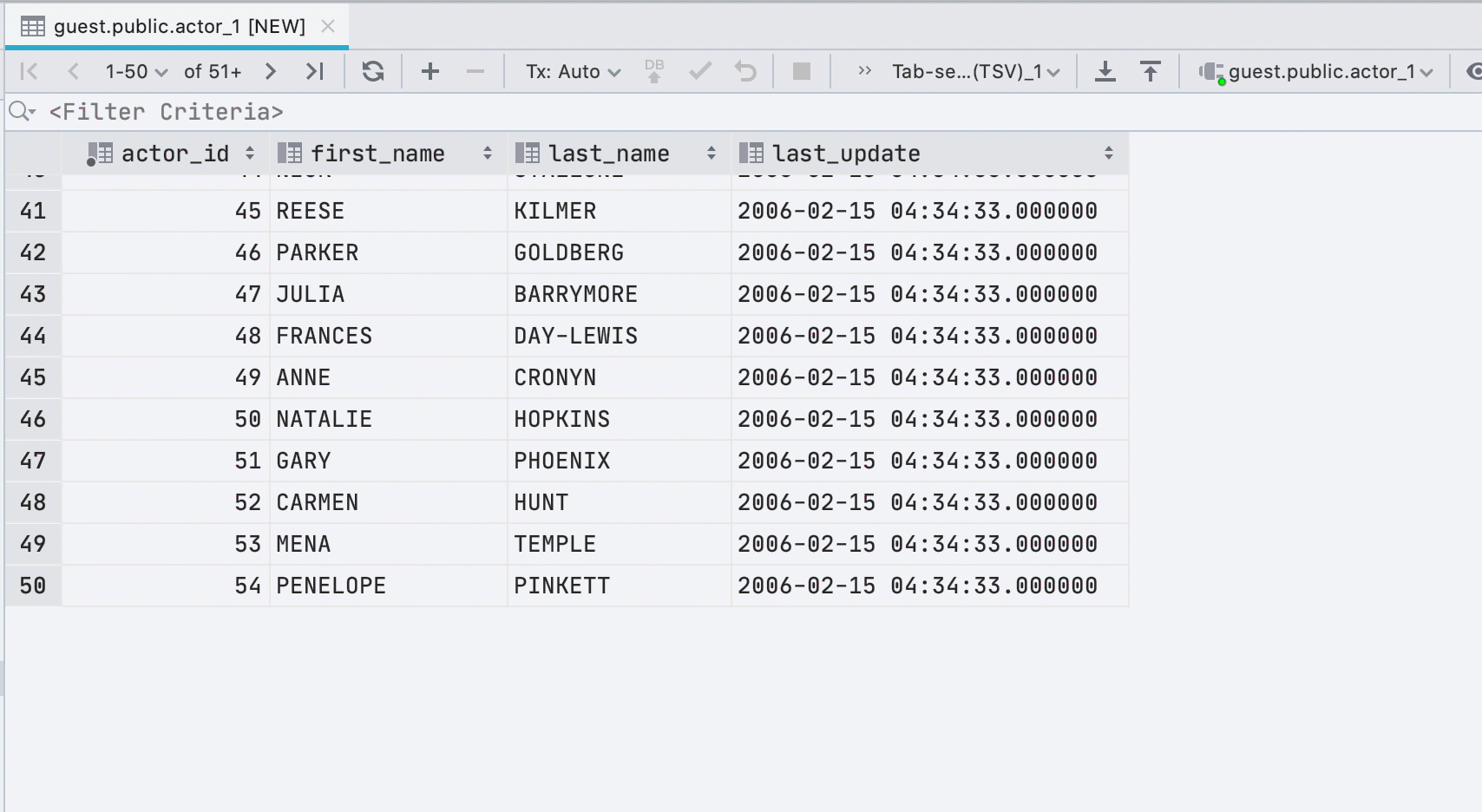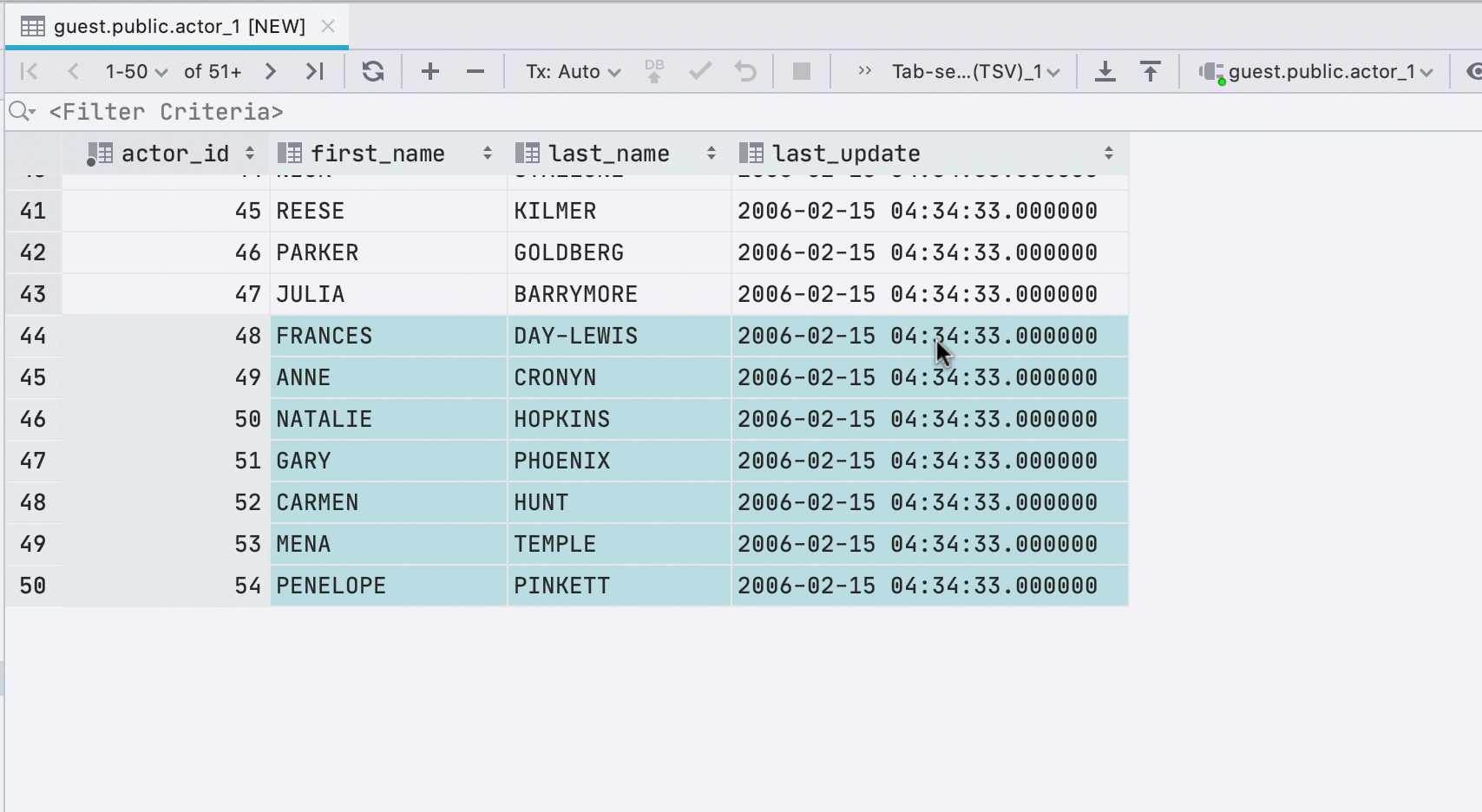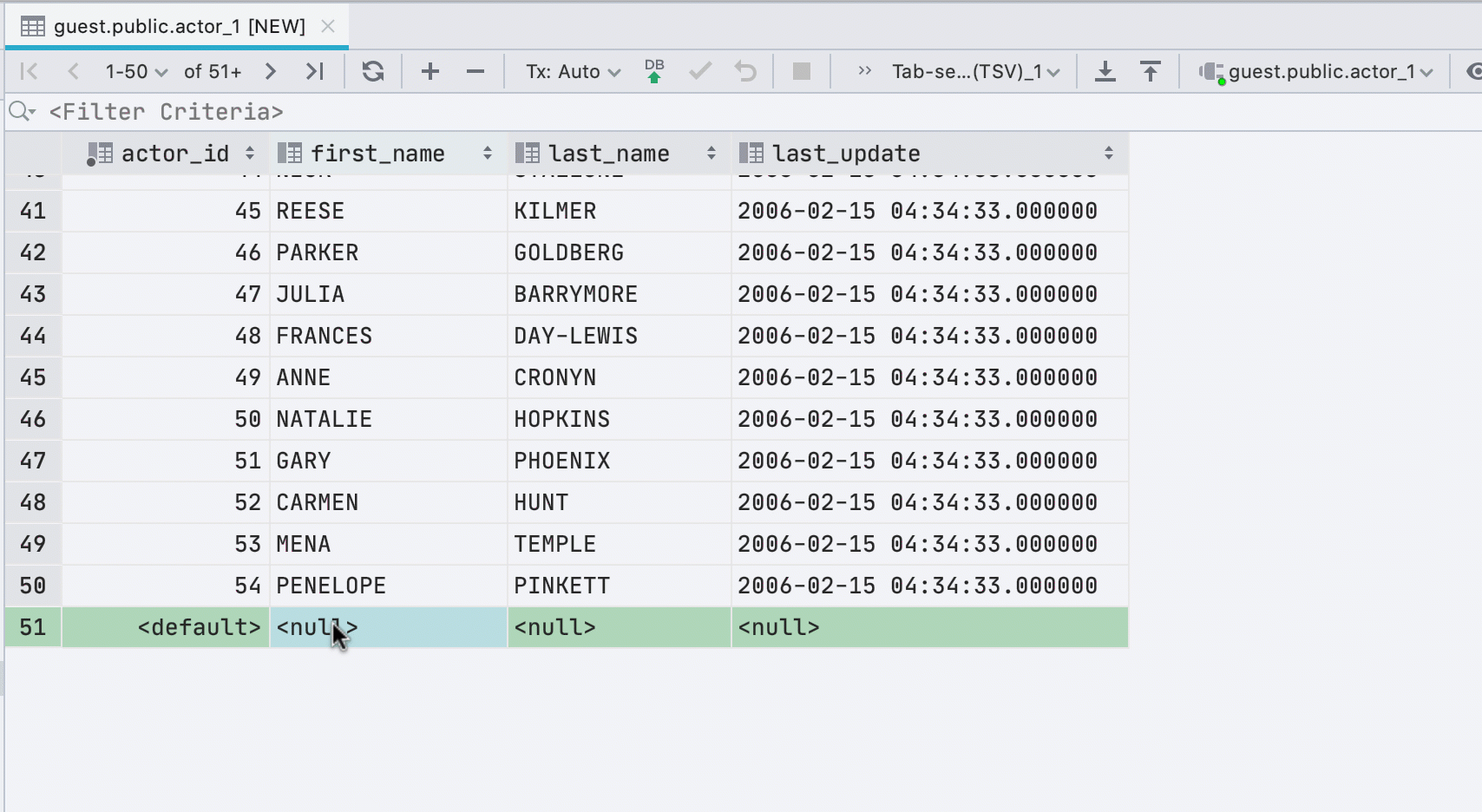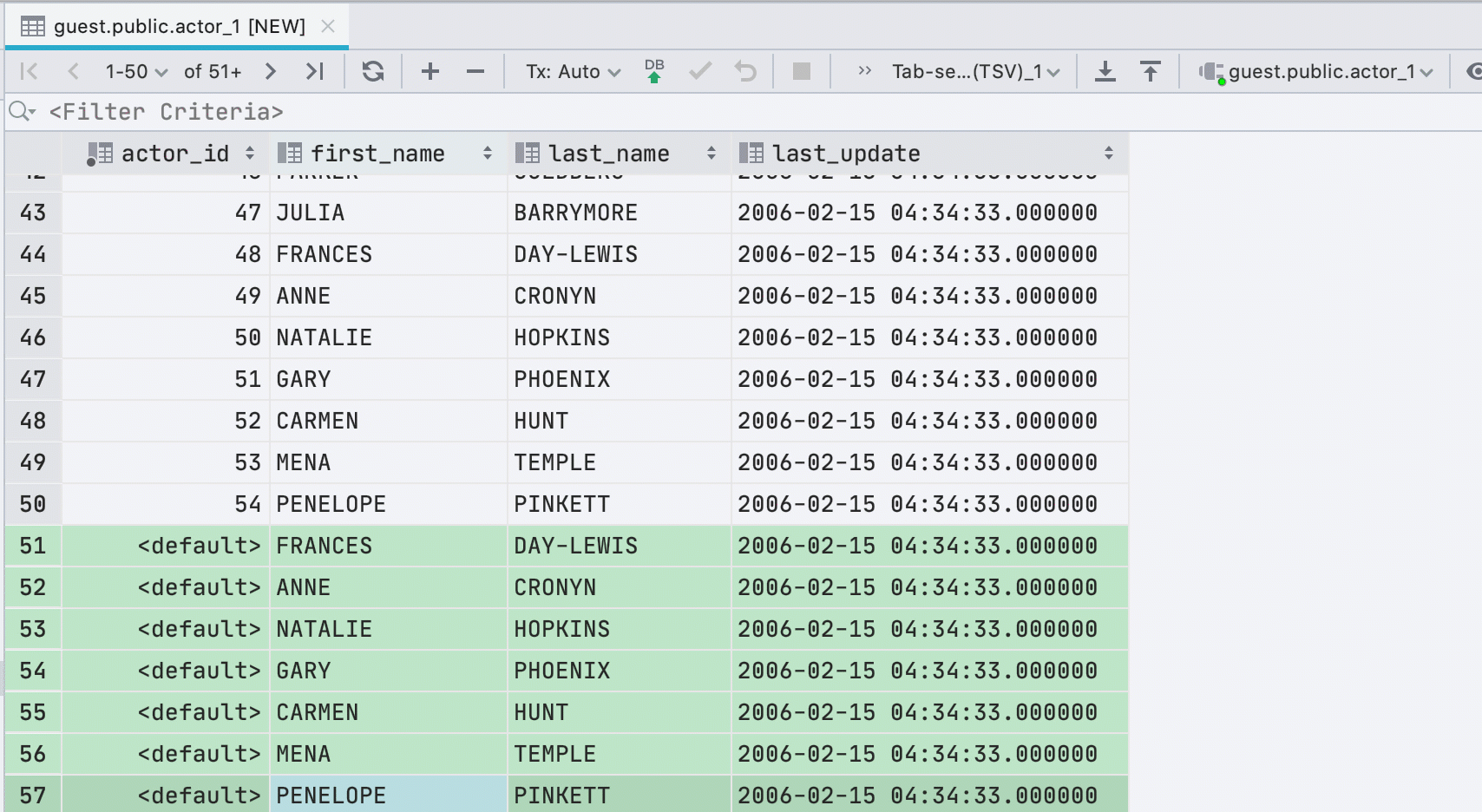
Nueva visualización de celdas lógicas
Anteriormente, usamos una casilla de verificación para mostrar celdas con el tipo booleano . Esto fue un inconveniente: no todos entendieron cómo distinguir nulo de falso , y los valores predeterminados, calculados y nulos se mostraban de la misma manera. Decidimos no ser inteligentes y escribir el significado en el texto.
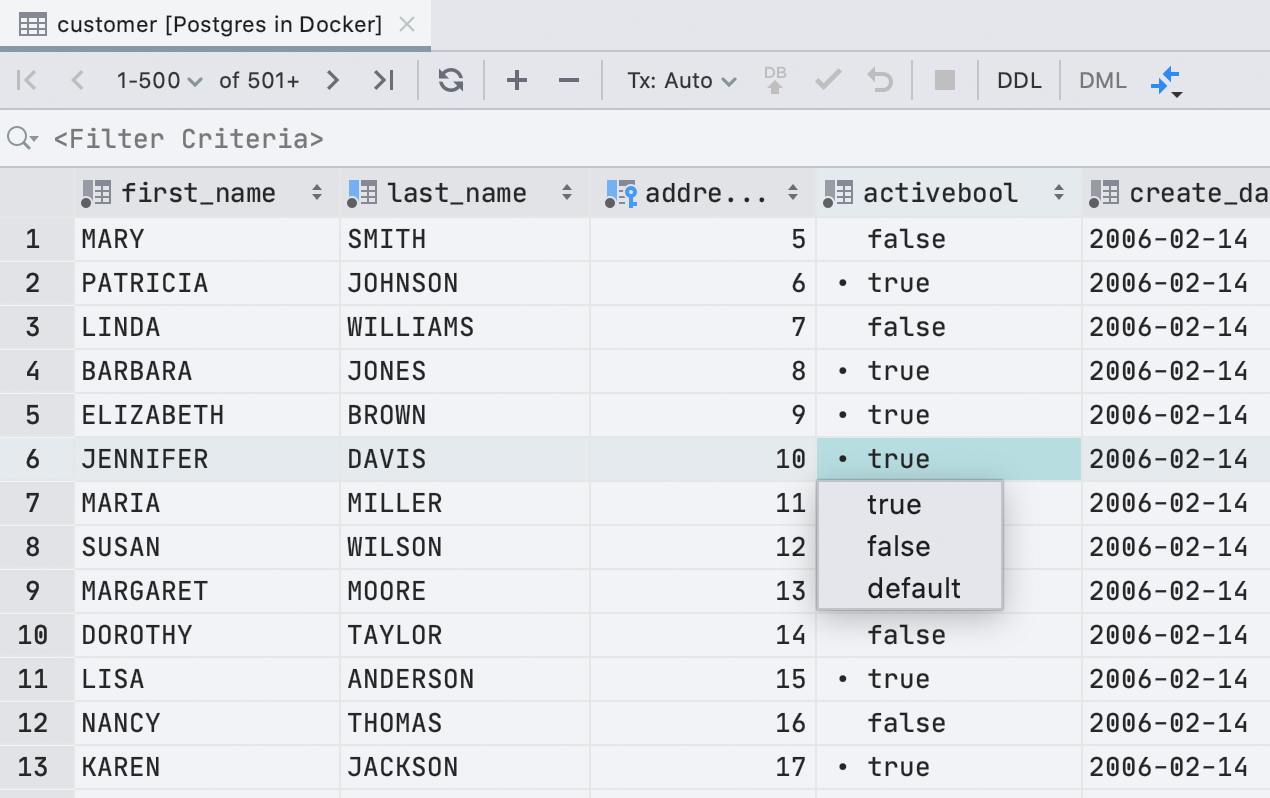
La casilla de verificación tenía una ventaja: es fácil encontrar visualmente valores verdaderos . En la nueva interfaz, el punto realiza esta tarea.
Tenemos suerte: en inglés, todos los significados posibles comienzan con letras diferentes. Por lo tanto, para editar, sólo tiene que pulsar la primera letra del valor que necesita: f, t, d, n, g , o c.Si imprimimos algo más, mostraremos una lista desplegable. Y la barra espaciadora alterna entre los valores disponibles.
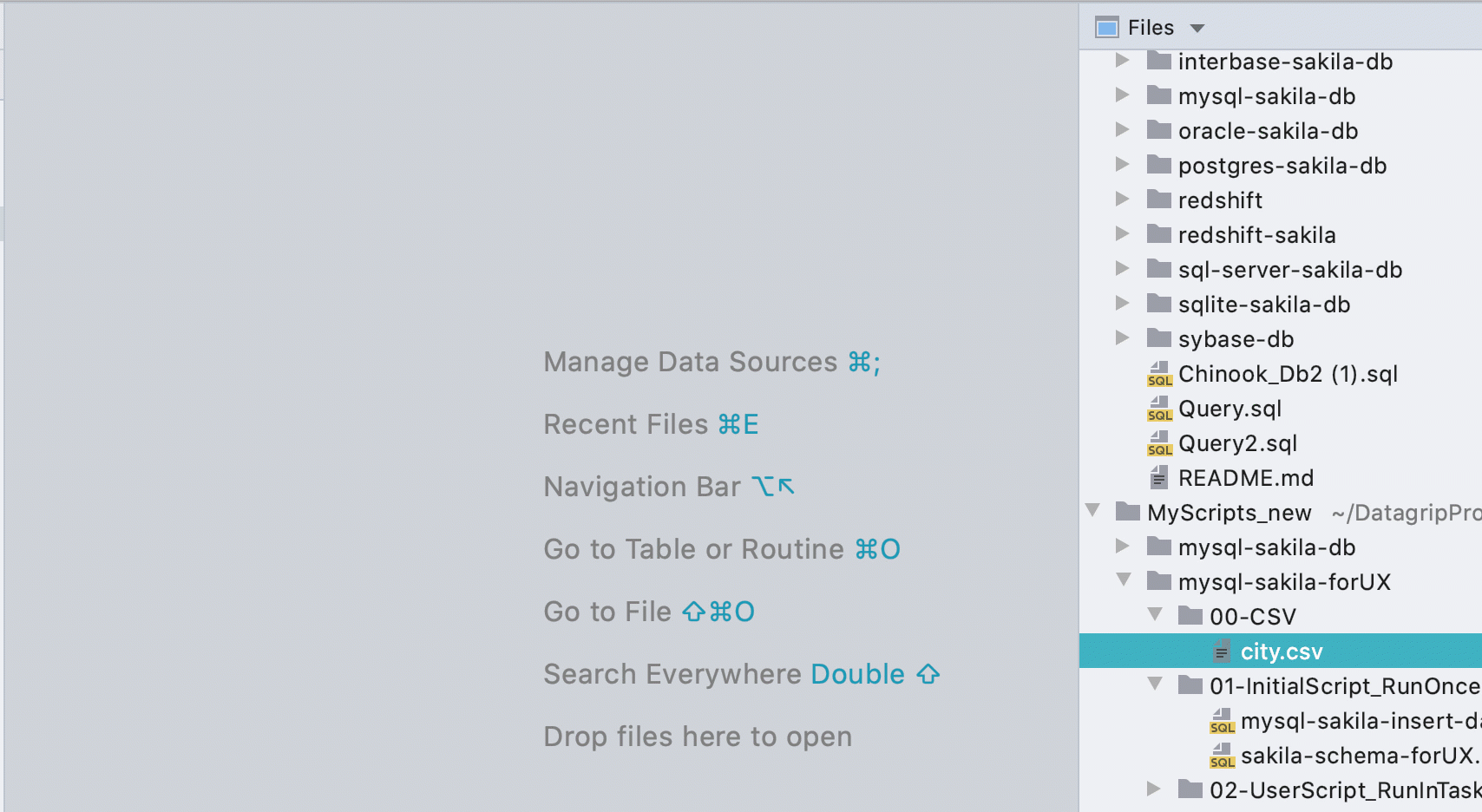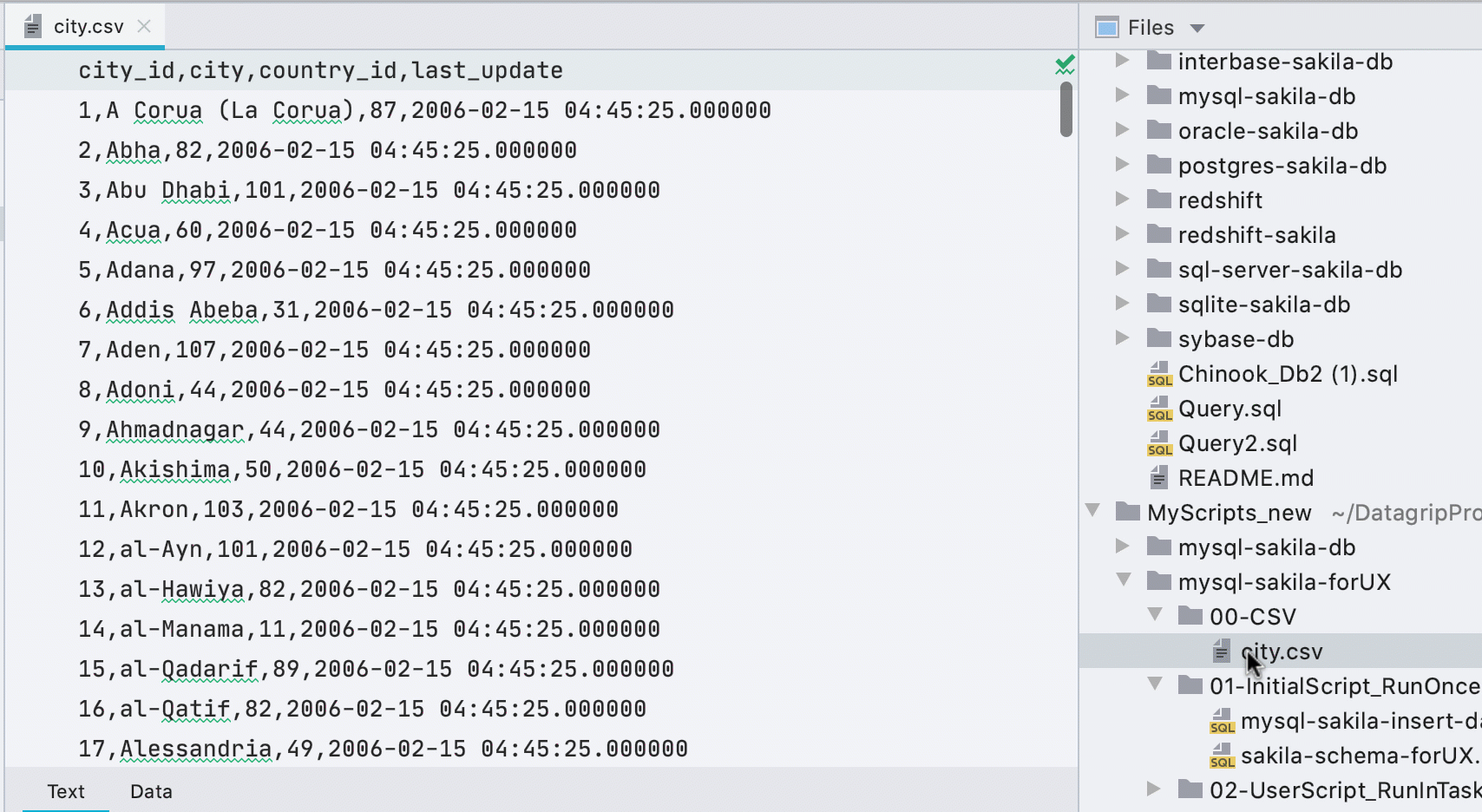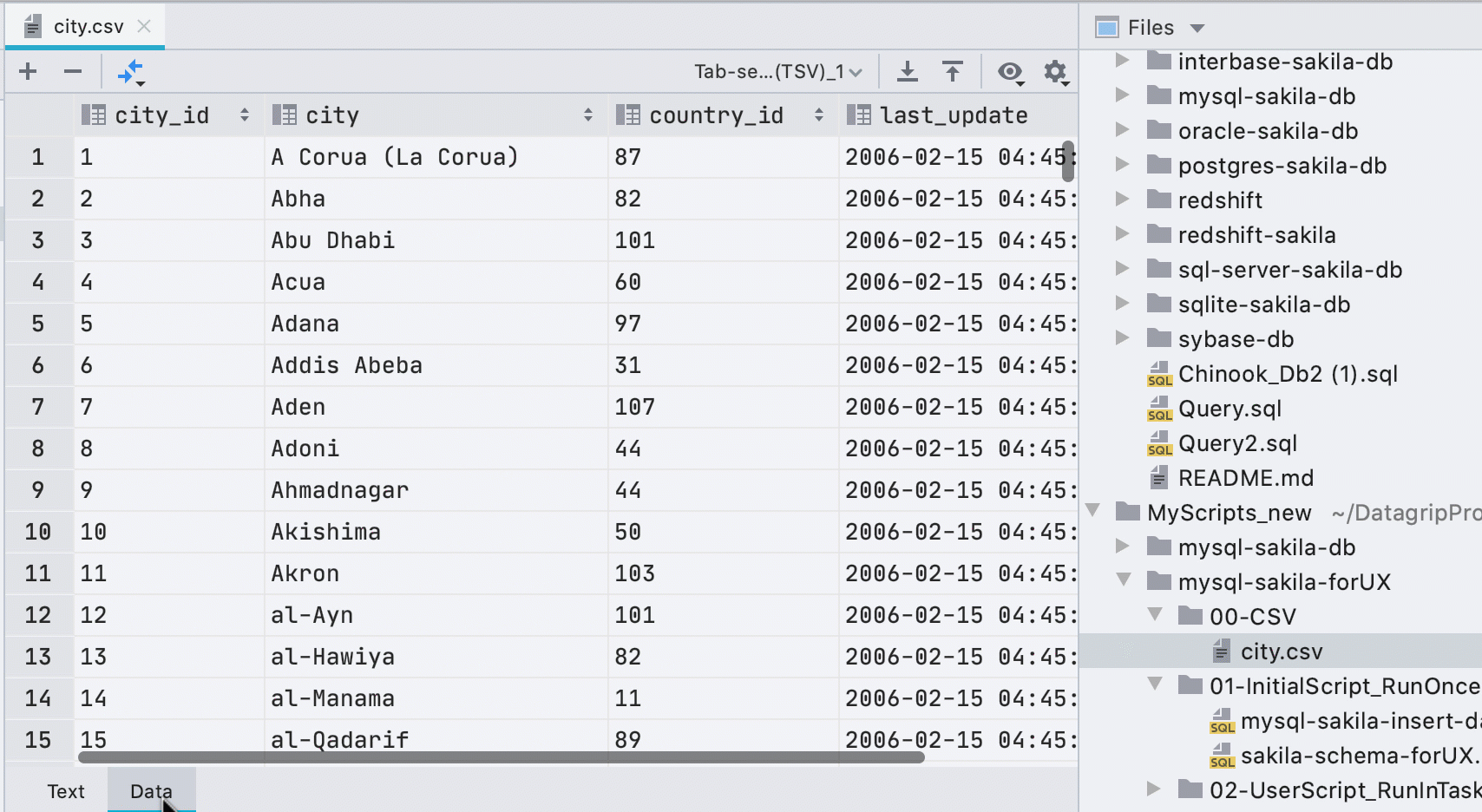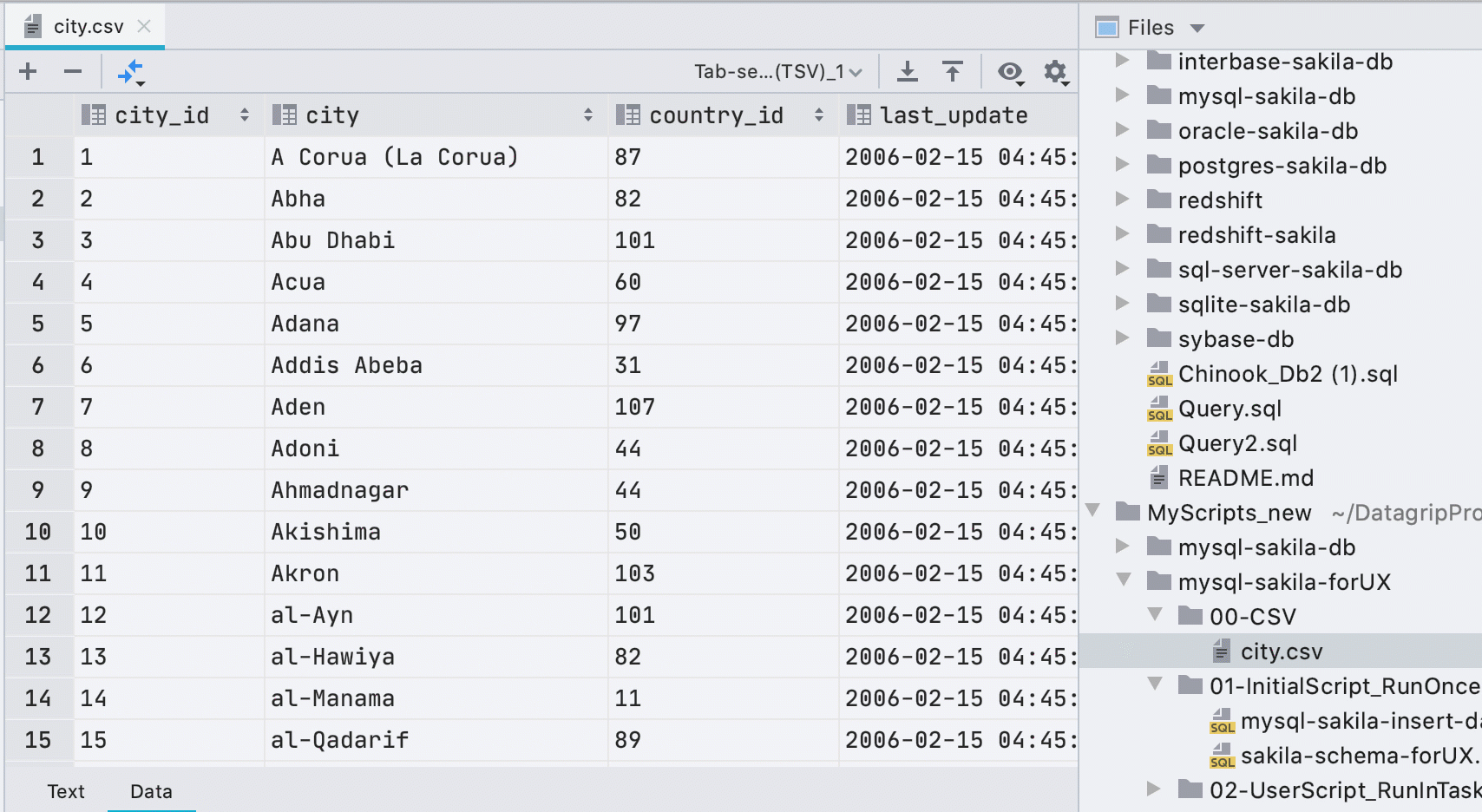
Editor de datos automático para archivos CSV
Anteriormente, tenía que llamar al editor de datos desde el menú contextual y una pequeña barra amarilla anunciaba un complemento de terceros al abrir archivos CSV. Ahora averiguamos qué es lo que nosotros mismos y mostramos la pestaña Datos para archivos CSV.
Nuevas filas al pegar valores
Si pega datos en una tabla desde el portapapeles, crearemos automáticamente el número requerido de nuevas filas.
Nueva interfaz para datos
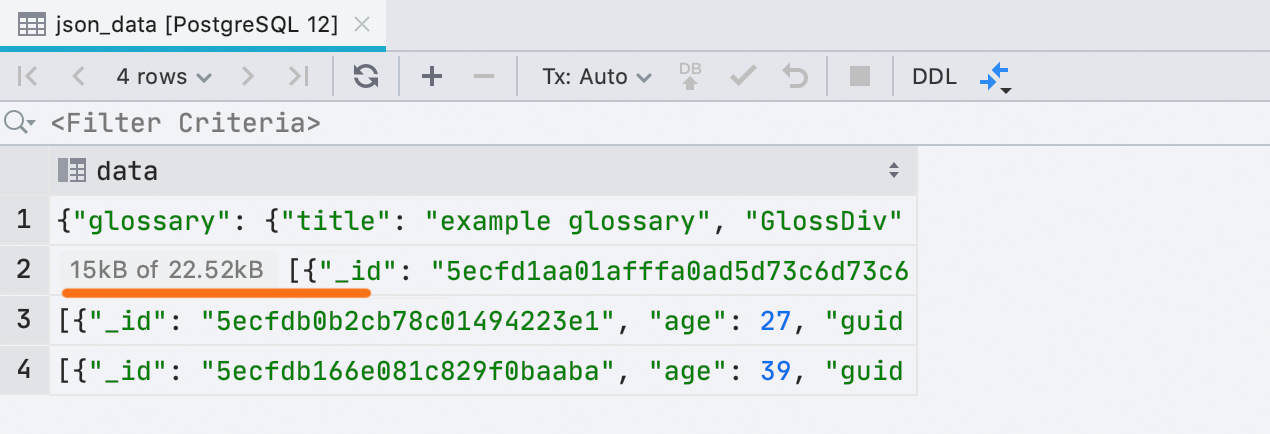
subcargados A veces, DataGrip no puede cargar todos los datos en una celda si ocupa mucha memoria. Esto está determinado por la base de datos | Vistas de datos | Longitud máxima de LOB.Anteriormente, insertamos texto sobre esto directamente en el valor de la celda, y esto es un inconveniente. Ahora es una pequeña placa separada:
Exportar al portapapeles desde el menú contextual
En la última versión, creamos un cuadro de diálogo para exportar, dejando un pequeño caso: se volvió menos conveniente copiar todo el resultado al portapapeles con el mouse. Ahora, esto se puede hacer desde el menú contextual.

Recuerde que esta acción copia todo el resultado o la tabla. Y Ctrl / Cmd + C o la acción
Copiar copia solo la selección.
Mejoras de filtrado para MongoDB
Además de ObjectId e ISODate , ahora puede filtrar por UUID , NumberDecimal , NumberLongy
BinData . Además, si tiene un valor adecuado para UUID / ObjectId / ISODate en su portapapeles, DataGrip le ofrecerá usarlo para el filtrado.
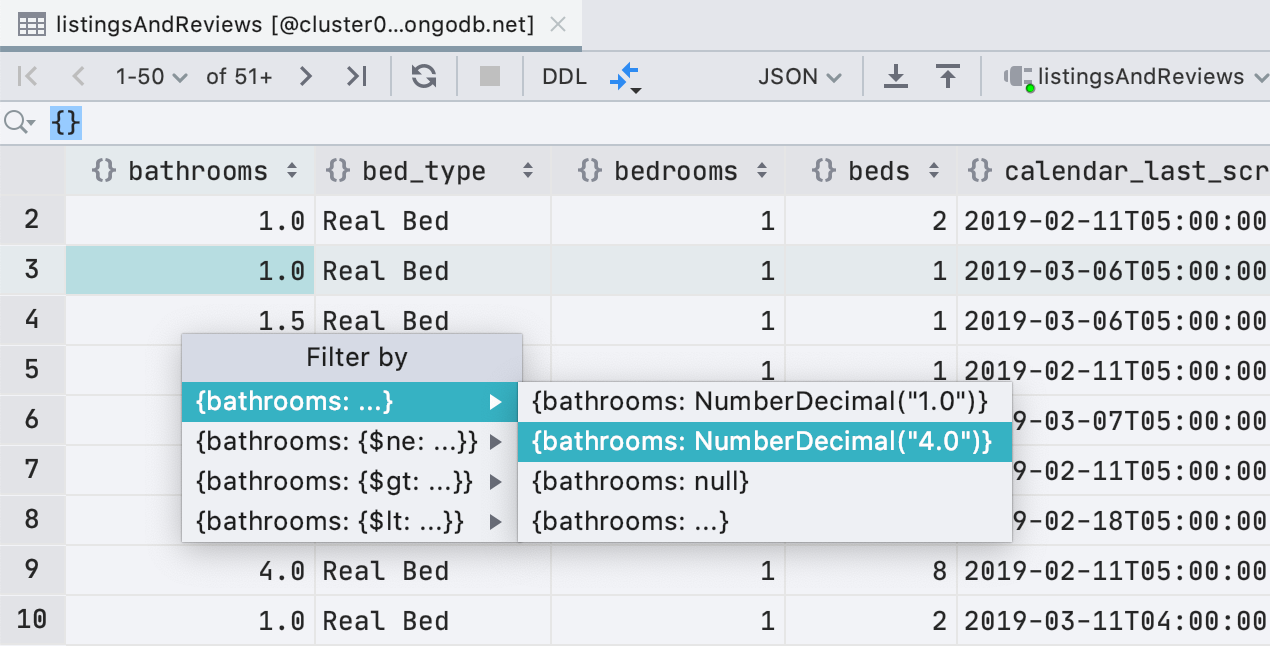
También agregamos expresiones regulares a las condiciones del filtro para que no se pierda demasiado el filtro
LIKE en las bases de datos relacionales.

Editor de SQL
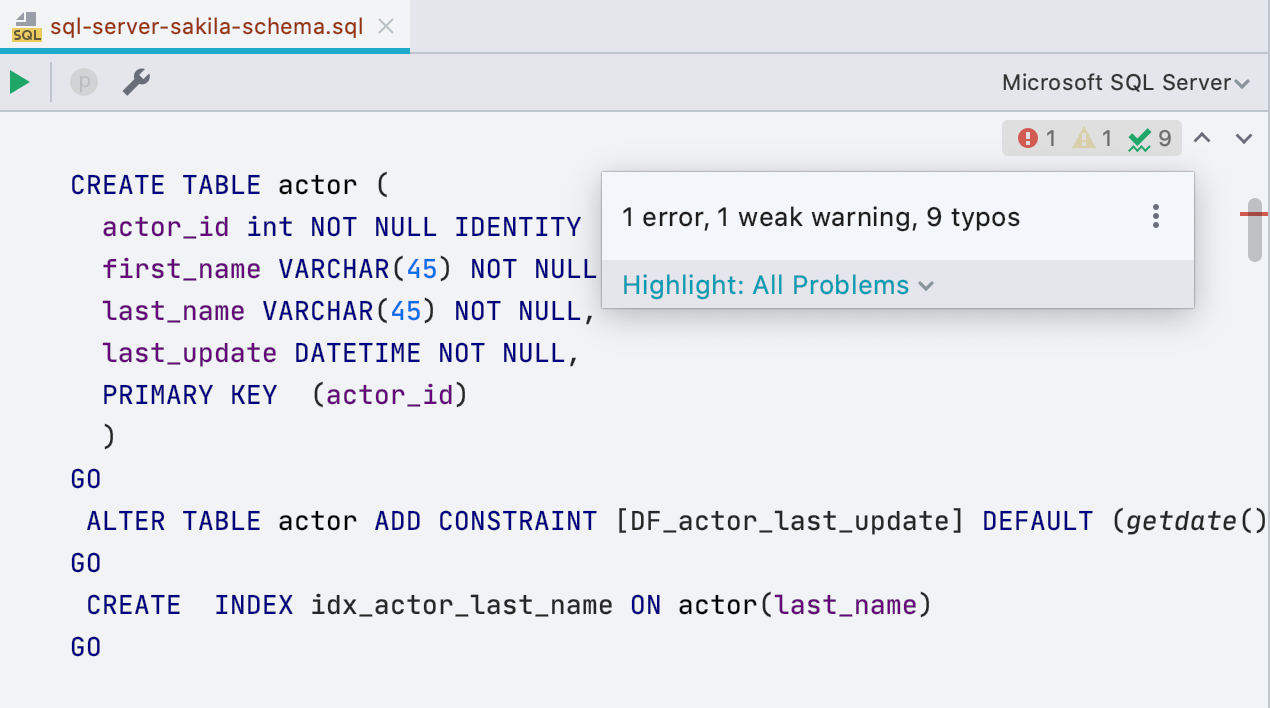
Nuevo widget con inspecciones
Apareció un pequeño panel a la derecha del editor: le dirá cuántos errores hay en el script y cuántos lugares son sospechosos. Desde allí puede navegar o elegir qué resaltar y qué no. El atajo de teclado F2 todavía funciona para el mismo.
Sugerencia para cambiar el nombre
Esto apareció en muchos de nuestros IDE: si cambió el nombre de algo sin usar la refactorización incorporada, pero cambió el nombre en el código, se le pedirá que refactorice y cambie el nombre y todos los usos. Por ejemplo, así es como funciona con los alias: La

finalización de JOIN acaba de mejorar.
Anteriormente, para poder ofrecer una condición JOIN completa, teníamos que escribir esta palabra clave. Ahora entendemos lo que se necesita tan pronto como haya escrito
'J'.

También aprendimos a ofrecer condiciones dobles si las claves de la mesa se configuran así.

Actualizar la información de la base de datos
Si DataGrip no sabe nada acerca de los objetos de sus consultas, se lo informará. A veces esto sucede si simplemente te sellaste. También sucede que el archivo se asoció con la fuente de datos incorrecta. Otra razón para tal evento es que el objeto ya apareció, pero DataGrip no ha recibido información sobre él de la base de datos. Para hacer esto, agregamos la capacidad de comenzar a actualizar la estructura de la base de datos desde el editor si el objeto es desconocido.

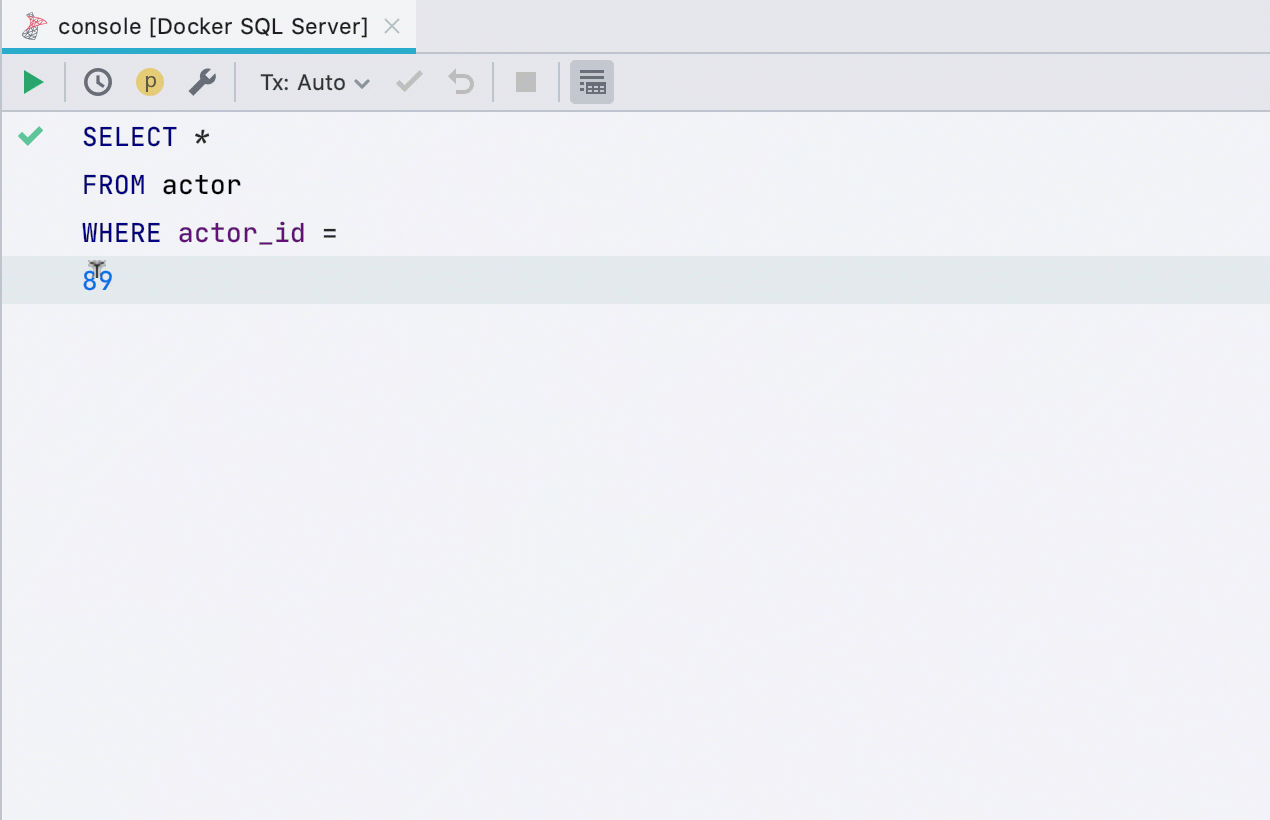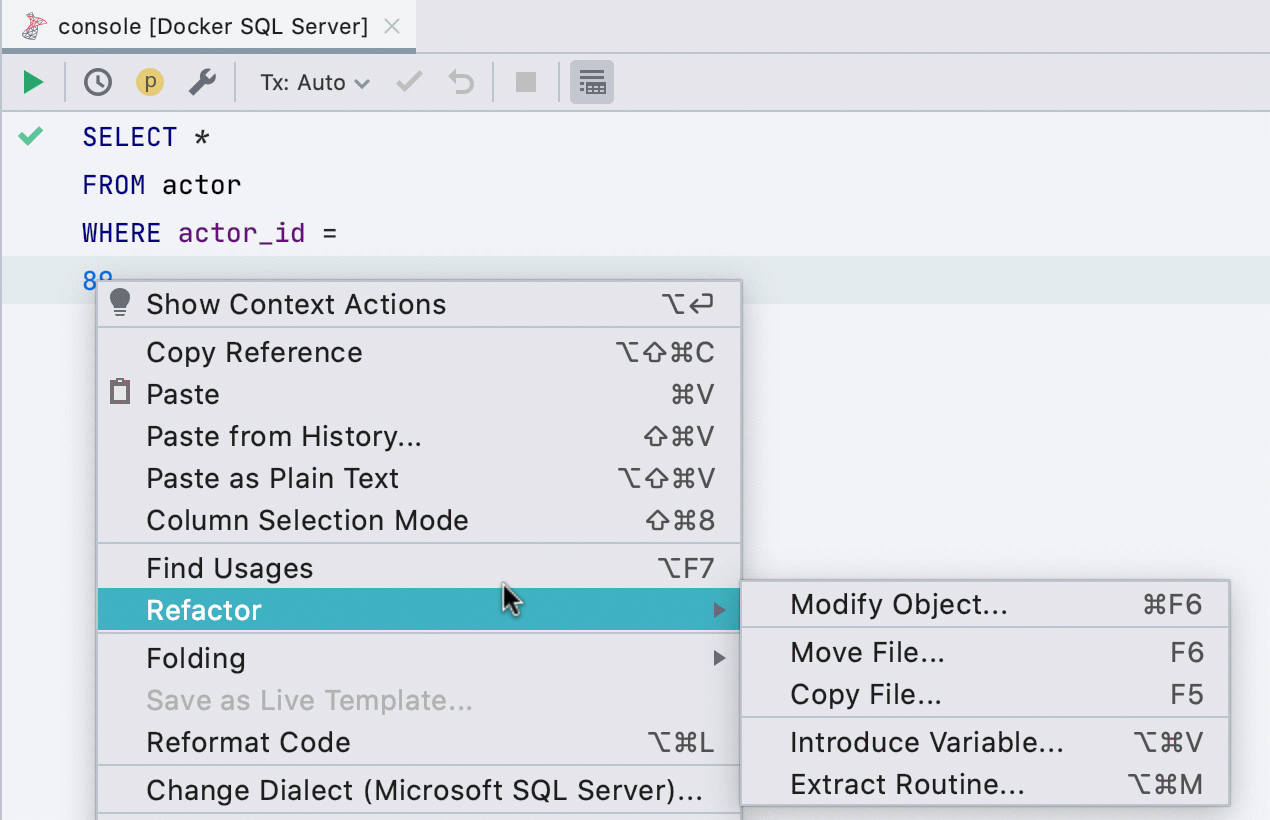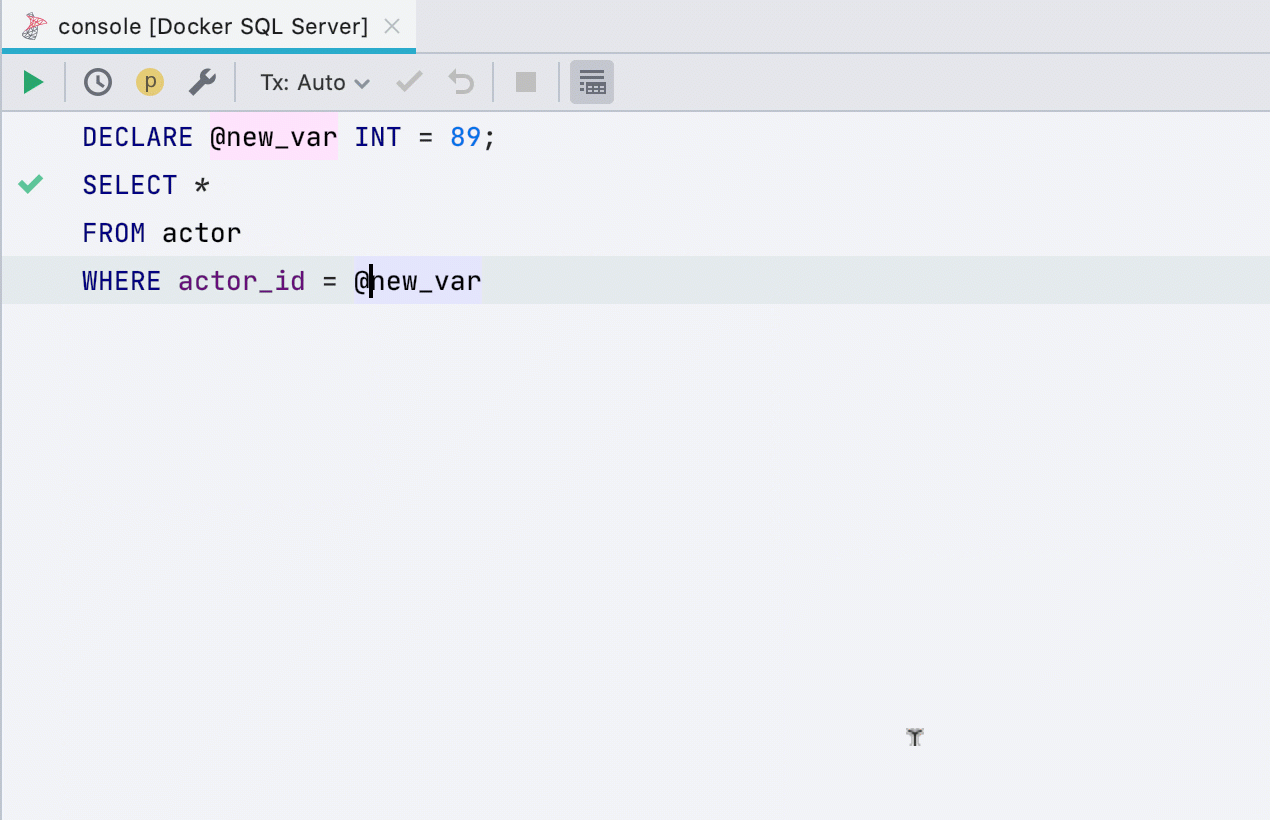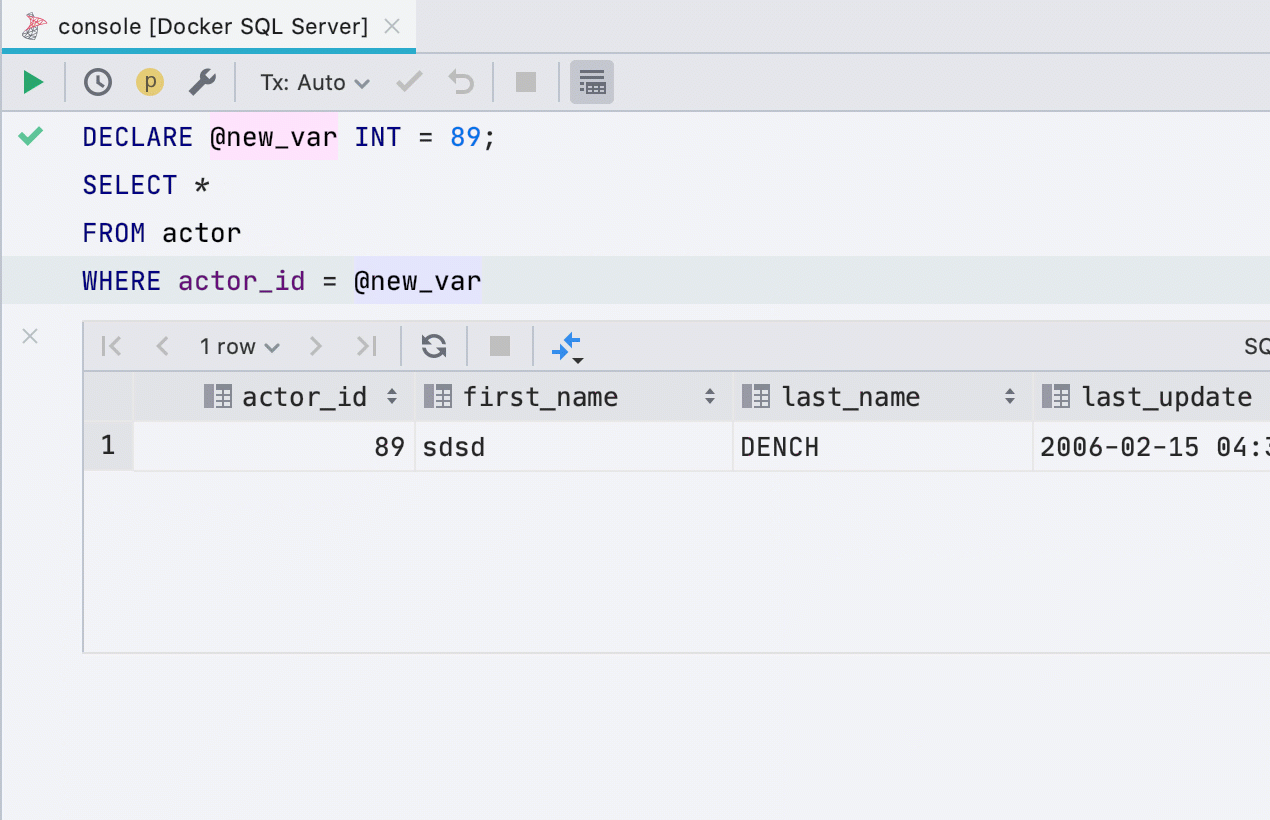
Asignar variable
Esta refactorización anteriormente no funcionaba para todas las bases de datos, ahora funciona en SQL Server, Db2, Exasol, HSQL, Redshift y Sybase .
Destacado de Google BigQuery
Se agregaron nuevos dialectos: Google BigQuery. Hasta ahora, esto no es un soporte de base de datos completo, sino solo un resaltado de código correcto. En consecuencia, no necesita seleccionar código para ejecutar consultas, nosotros mismos determinaremos qué ejecutar.

Resaltado de TextMate
Al igual que nuestros otros IDE, DataGrip ahora puede resaltar el código utilizando el complemento TextMate. Puede ser útil si tiene scripts en Python, lua, javascript. Una lista completa de idiomas está disponible en Configuración / Preferencias | Editor | Paquetes TextMate .

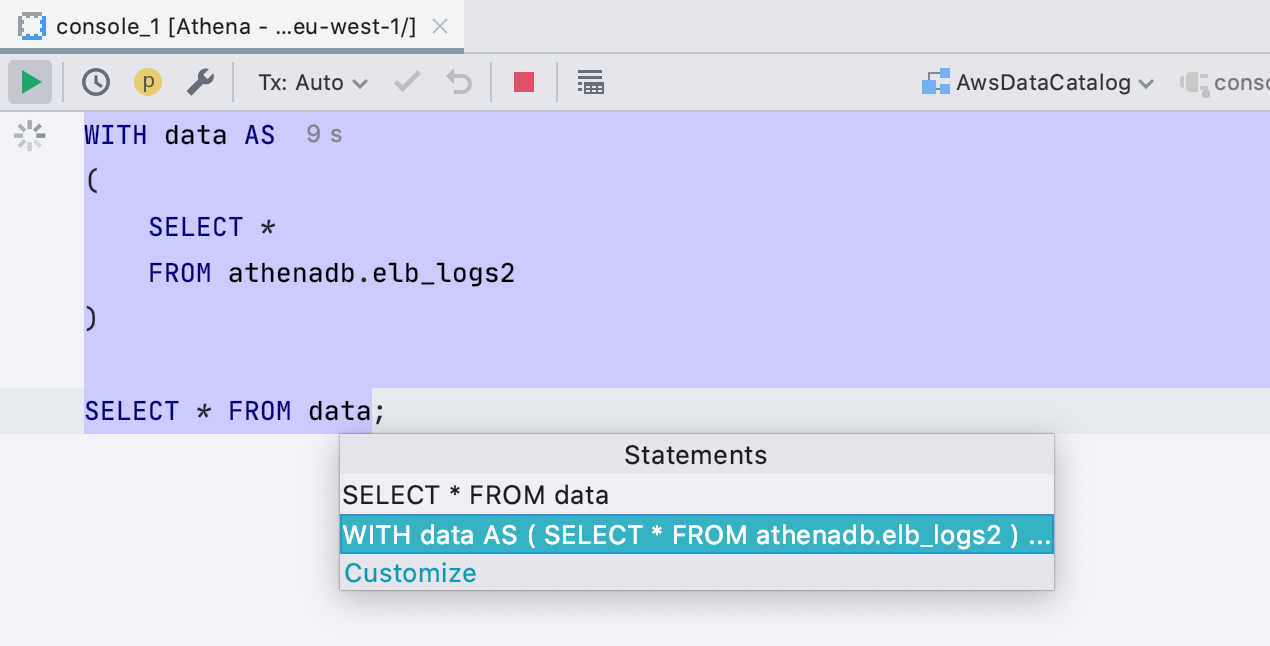
SQL 2016 como dialecto <Generic>
Si trabaja con una base de datos que no admitimos, las consultas se analizan y resaltan con el dialecto < Generic >. Antes era SQL 92, ahora SQL 2016. Lo más importante es que ahora procesamos correctamente las consultas con un bloque WITH, respectivamente, no solo están resaltados correctamente, sino que también puede ejecutarlos sin resaltar el código.
Caso de nombres de objetos en el formato
En la configuración de formato, había tres configuraciones para los nombres de los objetos de la base de datos: mayúsculas , minúsculas o no cambiar . Pero resultó que hay un cuarto caso: los usuarios quieren usar el caso que se utilizó al crear el objeto en el script. Apoyamos esto.

En el ejemplo, la tabla Actor se creó con la primera letra mayúscula y, en uso, convertimos el nombre de la tabla al mismo caso.

Solo buscamos scripts de creación dentro del mismo archivo donde se realiza el formateo. Si desea que el formateador encuentre la declaración de objeto en un archivo vecino, cree una fuente de datos basada en DDL a partir de sus archivos .
Varios carros en una selección
Ahora puede seleccionar un fragmento de código y poner un signo de intercalación en cada una de sus líneas. Para esto, use la acción Agregar signos de intercalación al final de las líneas seleccionadas o el atajo de teclado Shift + Alt + G

Explorador de bases de datos
Todas las bases y esquemas en el árbol
Por defecto, mostramos en el árbol solo aquellas bases y esquemas que usted mismo ha seleccionado. El árbol no es flojo y toda la metainformación sobre los objetos se utiliza para el trabajo posterior del IDE. Por lo tanto, descargamos solo lo necesario para no colgarnos accidentalmente de una base gigante.
Sin embargo, muchos están acostumbrados a herramientas que siempre muestran todos los objetos, y las personas que no están familiarizadas con nuestro concepto pueden perder de vista las bases y diagramas. Por lo tanto, hicimos la configuración Mostrar todos los espacios de nombres, y cuando está habilitada, todas las bases de datos y esquemas se mostrarán en el árbol, incluso si la información sobre sus objetos no está cargada. Tales esquemas y bases están marcados en gris.

Interfaz para crear vistas
Solemos decir que la función de generación de código en el editor (Alt + Ins o Cmd + N ) cubre muchas de las necesidades de creación de objetos del desarrollador, pero a veces es aún menos conveniente. Por lo tanto, comenzamos a agregar interfaces para crear objetos: en la nueva versión, puede crear vistas.

Archivos de secuencia de comandos en el panel Archivos
Si creó una fuente de datos basada en DDL, estos archivos irán automáticamente al panel
Archivos . Por lo que le resultará conveniente verlos y editarlos. Vinculación de base de datos de

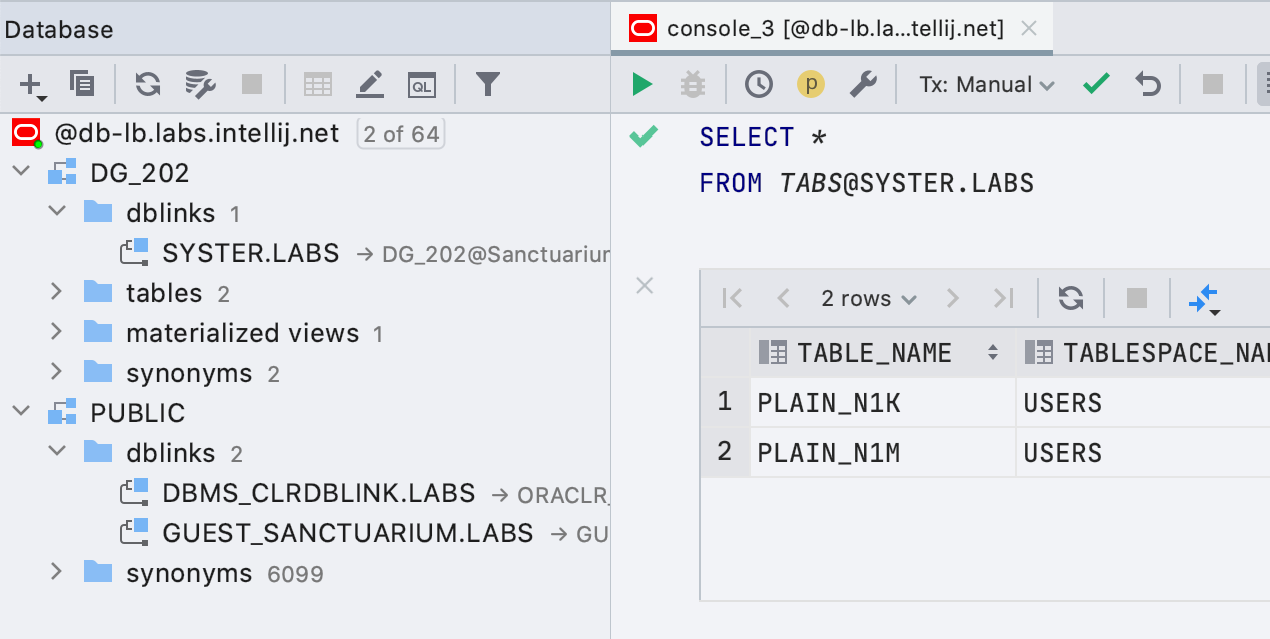
Oracle simple
Los vínculos de la base de datos ahora se muestran en el Explorador y las consultas que los utilizan se resaltan correctamente.
General
No más nombres de pestañas largas
A menudo se ha quejado de que las pestañas crecen sin control .

De ahora en adelante:
- Database | General | Always show qualified names for database objects , , .
- 20 , .
- , .
- — 36 , .
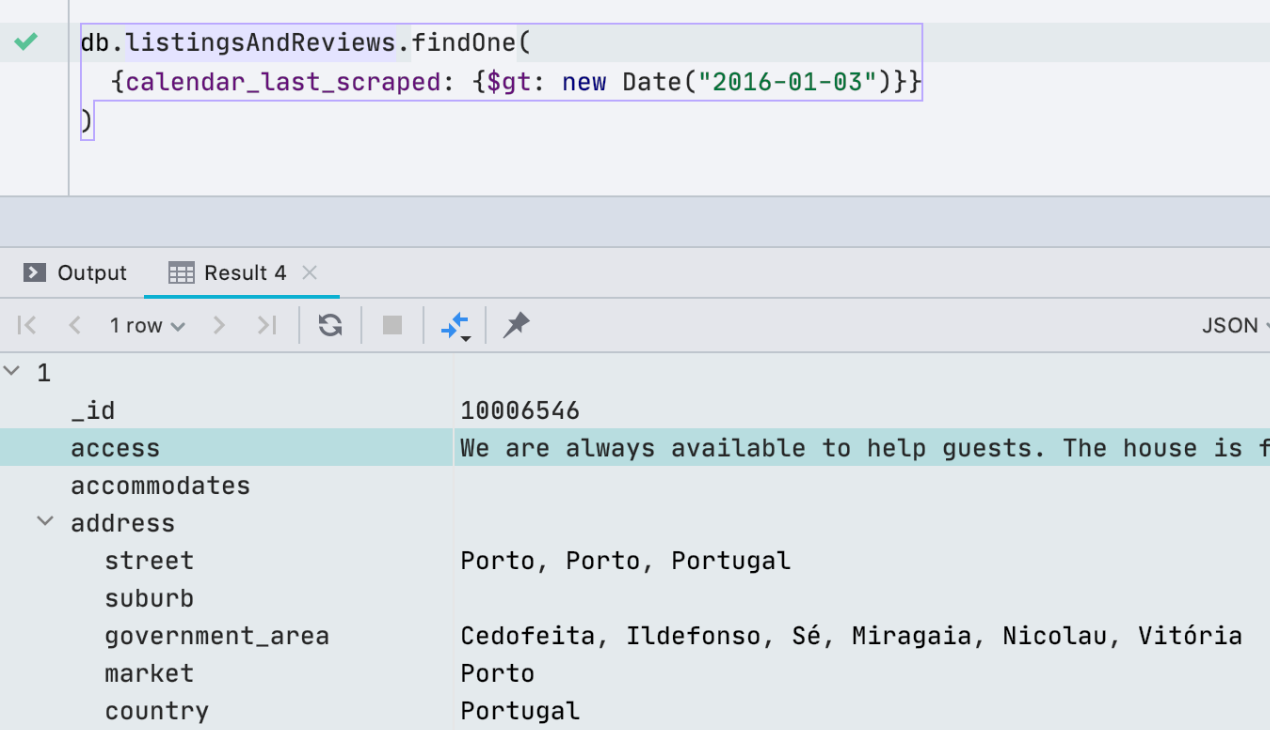
Compatibilidad con el shell de MongoDB
Hace un mes, actualizamos el controlador que usamos para conectarnos a MongoDB para admitir el shell de MongoDB. Esto significa que los nuevos comandos y métodos han funcionado, como help, db.getCollectionInfos (), db.getCollectionNames (), db.collection.remove () y otros. Aquí encontrará un artículo detallado en inglés sobre el soporte de shell de MongoDB .
Bibliotecas nativas en la configuración del controlador
Ahora puede especificar la ruta a la biblioteca nativa que necesita el controlador. Aquí hay algunas ocasiones en las que podría necesitarlo.

- SQL Server mssql-jdbc_auth-<version>-<arch>.dll SSO, . , SSO .
- Oracle ocijdbc, OCI .
- SQLite, ,
, , .
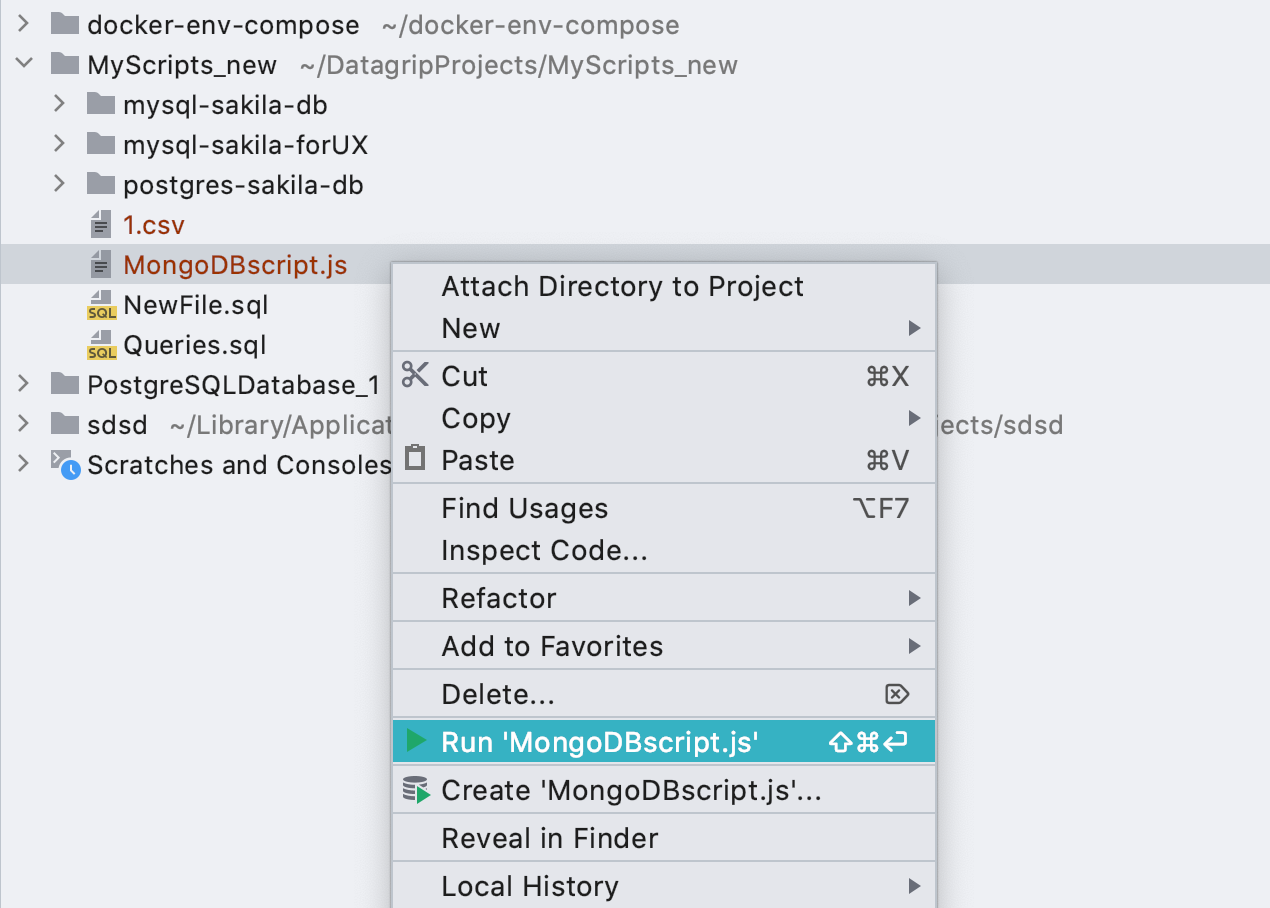
Configuraciones de lanzamiento para archivos * .js
Ahora las configuraciones de lanzamiento también funcionan para scripts de MongoDB .
La integración con Git y Github funciona desde el primer momento
Nuestra encuesta mostró que bastantes personas almacenan scripts en sistemas de control de versiones, por lo que decidimos empaquetar dos de los complementos más populares en esta área.

¡Gracias por su atención! Permítanos recordarle que tenemos nuestro propio canal en Telegram , donde puede hacer preguntas y compartir experiencias. Pero si encuentra un error, es mejor escribir inmediatamente en el rastreador para que no se pierda. Bueno, aquí, por supuesto, también escribir comentarios :) ¡
Eso es todo!
Equipo de DataGrip