
Quién soy
Mi nombre es Dmitry Ivanov. Soy un estudiante de posgrado de segundo año en economía en St. Petersburg HSE. Trabajo en el grupo de investigación " Agent Systems and Reinforcement Learning " en JetBrains Research , así como en el laboratorio internacional de Teoría de Juegos y Toma de Decisiones de la Escuela Superior de Economía . Además del aprendizaje de PU, estoy interesado en el aprendizaje por refuerzo y la investigación en la intersección del aprendizaje automático y la economía.
Preámbulo
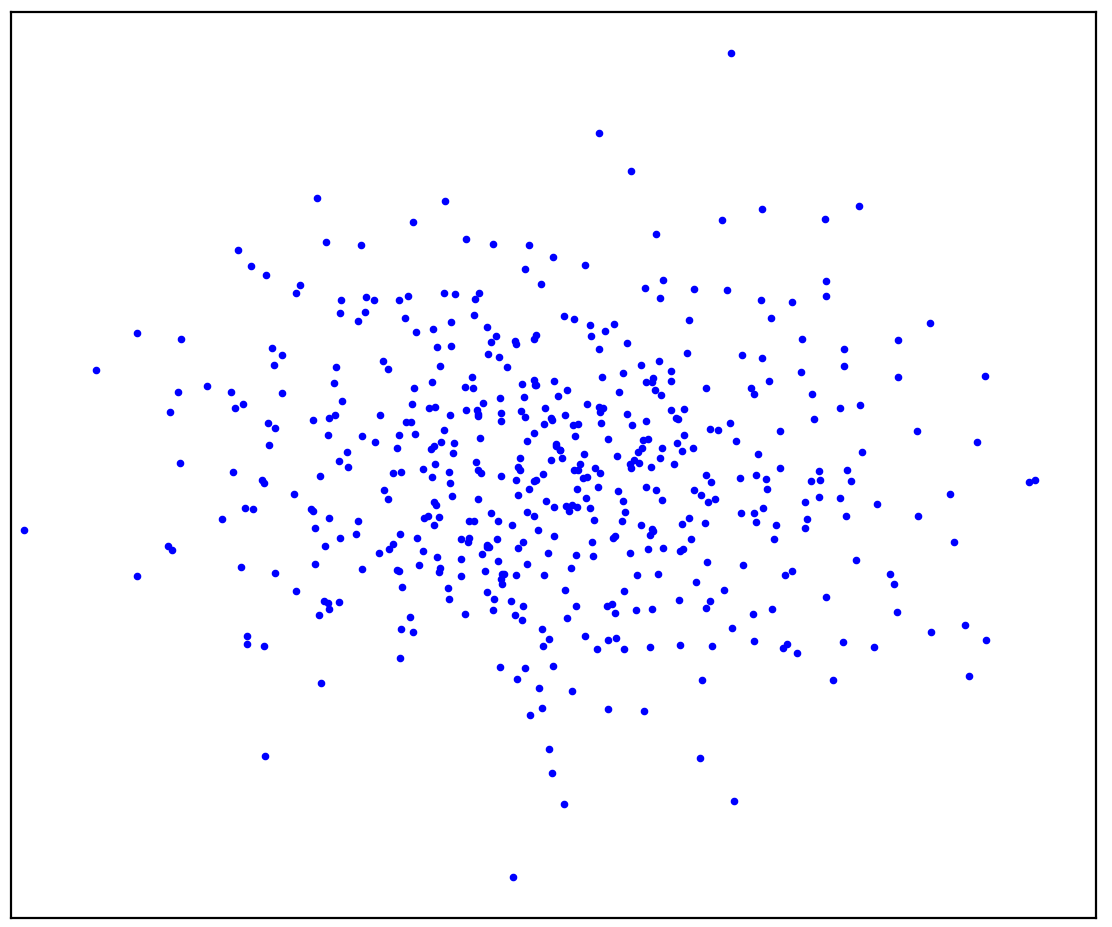
Figura: 1a. Datos positivos La
Figura 1a muestra un conjunto de puntos generados por alguna distribución, que llamaremos positivos. Todos los demás puntos posibles que no pertenecen a la distribución positiva se denominarán negativos. Trate de dibujar mentalmente una línea que separe los puntos positivos presentados de todos los posibles puntos negativos. Por cierto, esta tarea se llama "detección de anomalías".
La respuesta esta aqui

. 1.
. 1.
Es posible que haya imaginado algo como la Figura 1b: rodee los datos en una elipse. De hecho, así funcionan muchos métodos de detección de anomalías.
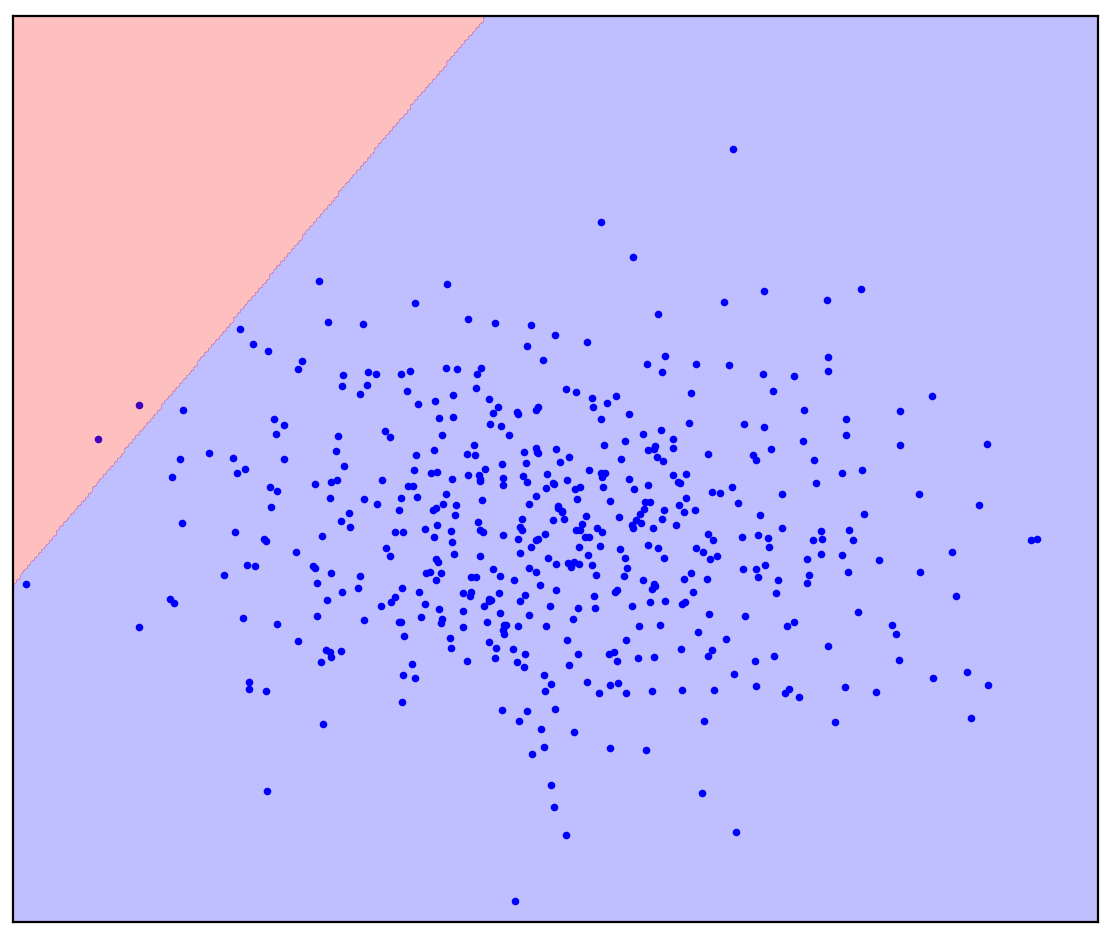
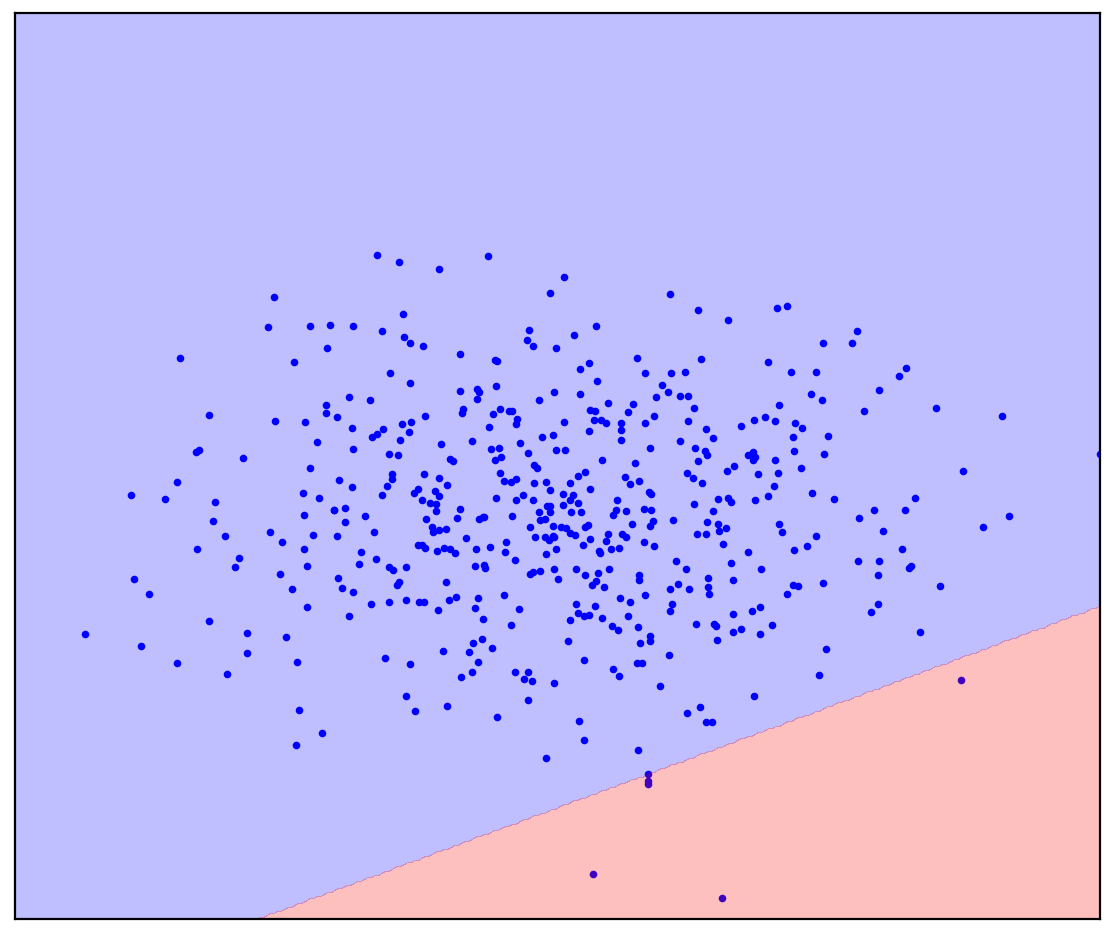
Ahora cambiemos un poco el problema: tengamos información adicional de que una línea recta debe separar los puntos positivos de los negativos. Intenta dibujarlo en tu mente.
La respuesta esta aqui
. 1. ( One-Class SVM)
. 1. ( One-Class SVM)
En el caso de una línea divisoria recta, no hay una respuesta única. No está claro en qué dirección trazar una línea recta.
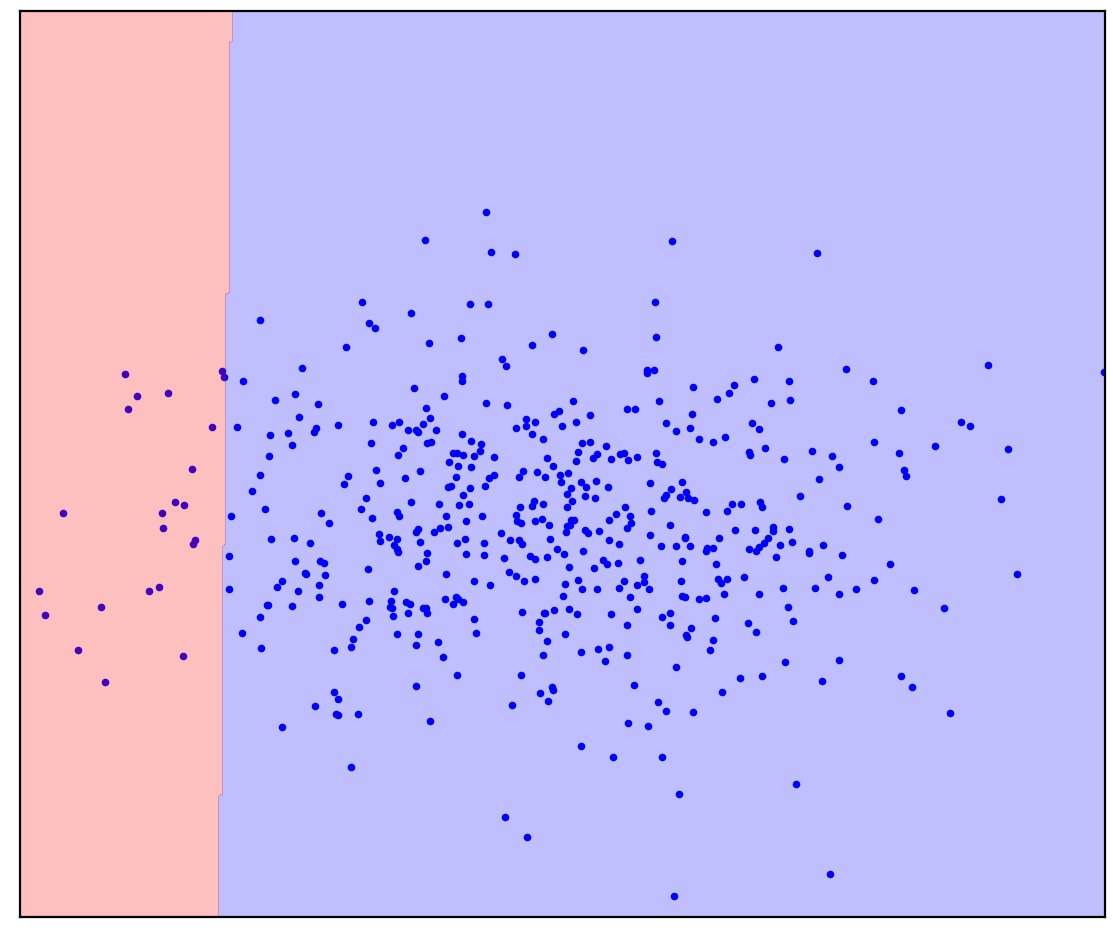
Ahora agregaré algunos puntos no asignados a la Figura 1d que contienen una mezcla de positivo y negativo. Por última vez, te pediré que hagas un esfuerzo mental e imagines una línea que separa los puntos positivos y negativos. ¡Pero esta vez puedes usar datos sin etiquetar!

Figura: 1d. Puntos positivos (azul) y sin etiquetar (rojo). Los puntos sin marcar se componen de positivos y negativos
La respuesta esta aqui

. 1.
. 1.
¡Se volvió más fácil! Aunque no sabemos de antemano cómo se genera cada punto no marcado en particular, podemos marcarlos a grandes rasgos comparándolos con los positivos. Los puntos rojos que parecen azules probablemente sean positivos. Por el contrario, los distintos son probablemente negativos. Como resultado, a pesar de que no tenemos datos negativos "puros", la información sobre ellos se puede obtener de la mezcla sin etiquetar y utilizar para una clasificación más precisa. Esto es lo que hacen los algoritmos de aprendizaje Positive-Sin etiqueta, de los que quiero hablar.
Introducción
El aprendizaje positivo sin etiquetar (PU) se puede traducir como "aprender de datos positivos y sin etiquetar". De hecho, el aprendizaje de PU es un análogo de una clasificación binaria para los casos en los que hay datos etiquetados de solo una de las clases, pero se encuentra disponible una mezcla no etiquetada de datos de ambas clases. En el caso general, ni siquiera sabemos cuántos datos de la mezcla corresponden a una clase positiva y cuántos a una negativa. Basándonos en tales conjuntos de datos, queremos construir un clasificador binario: el mismo que en presencia de datos puros de ambas clases.
Como ejemplo de juguete, considere un clasificador para imágenes de perros y gatos. Tenemos algunas fotos de gatos y muchas más fotos de perros y gatos. En la salida, queremos obtener un clasificador: una función que predice para cada imagen la probabilidad de que se represente un gato. Al mismo tiempo, el clasificador puede marcar nuestra mezcla existente de imágenes para perros y gatos. Al mismo tiempo, puede ser difícil / costoso / lento / imposible marcar manualmente las imágenes para entrenar al clasificador, desea hacerlo sin él.
El aprendizaje de la PU es una tarea bastante natural. Los datos que se encuentran en el mundo real a menudo están sucios. La capacidad de aprender de datos sucios parece ser un truco de vida útil con una calidad relativamente alta. A pesar de esto, he conocido, paradójicamente, a pocas personas que hayan oído hablar del aprendizaje de la UP, y aún menos que conozcan algún método específico. Entonces decidí hablar sobre esta área.

Figura: 2. Jürgen Schmidhuber y Yann LeCun, NeurIPS 2020
Aplicación del aprendizaje de PU
Dividiré informalmente los casos en los que el aprendizaje de PU puede ser útil en tres categorías.
La primera categoría es probablemente la más obvia: el aprendizaje de PU puede usarse en lugar de la clasificación binaria habitual. En algunas tareas, los datos están inherentemente un poco sucios. En principio, esta contaminación se puede ignorar y se puede utilizar un clasificador convencional. Sin embargo, es posible cambiar muy poco la función de pérdida al entrenar al clasificador (Kiryo et al., 2017) o incluso las propias predicciones después del entrenamiento (Elkan & Noto, 2008) , y la clasificación se vuelve más precisa.
Como ejemplo, considere la identificación de nuevos genes responsables del desarrollo de genes de enfermedades. El enfoque estándar es tratar los genes de enfermedades que ya se encuentran como positivos y todos los demás genes como negativos. Obviamente, estos datos negativos pueden contener genes de enfermedades que aún no se han encontrado. Además, la tarea en sí es buscar genes de enfermedades entre los datos "negativos". Esta contradicción interna se nota aquí: (Yang et al., 2012) . Los investigadores se desviaron del enfoque convencional y consideraron los genes no relacionados con genes de enfermedades ya descubiertos como una mezcla no etiquetada, y luego aplicaron métodos de aprendizaje de PU.
Otro ejemplo es el aprendizaje por refuerzo basado en demostraciones de expertos. El desafío es capacitar al agente para que actúe de la misma manera que un experto. Esto se puede lograr utilizando el método de aprendizaje generativo por imitación adversarial (GAIL). GAIL utiliza una arquitectura similar a GAN (redes generativas adversarias): el agente genera trayectorias para que el discriminador (clasificador) no pueda distinguirlas de las demostraciones del experto. Investigadores de DeepMind notaron recientemente que en GAIL, el discriminador resuelve el problema de aprendizaje de PU (Xu & Denil, 2019)... Normalmente, el discriminador considera que los datos del experto son positivos y los datos generados, negativos. Esta aproximación es lo suficientemente precisa al comienzo del entrenamiento cuando el generador no puede producir datos que parezcan positivos. Sin embargo, a medida que avanza el entrenamiento, los datos generados se parecen más a datos de expertos hasta que se vuelven indistinguibles para el discriminador al final del entrenamiento. Por esta razón, los investigadores (Xu & Denil, 2019) consideran que los datos generados son datos sin etiquetar con una proporción de mezcla variable. Posteriormente, la GAN se modificó de manera similar a la hora de generar imágenes (Guo et al., 2020) .

Figura: 3. El aprendizaje de PU como análogo de la clasificación PN estándar
En la segunda categoría, el aprendizaje de PU puede utilizarse para la detección de anomalías como análogo de la clasificación de una clase (OCC). Ya hemos visto en el Preámbulo cómo pueden ayudar exactamente los datos sin etiquetar. Todos los métodos de OSS, sin excepción, están obligados a hacer una suposición sobre la distribución de datos negativos. Por ejemplo, es aconsejable encerrar en un círculo los datos positivos en una elipse (una hiperesfera en el caso multidimensional) fuera de la cual todos los puntos son negativos. En este caso, asumimos que los datos negativos se distribuyen uniformemente (Blanchard et al., 2010)... En lugar de hacer tales suposiciones, los métodos de aprendizaje de PU pueden estimar la distribución de datos negativos basados en datos sin etiquetar. Esto es especialmente importante si las distribuciones de las dos clases se superponen fuertemente (Scott y Blanchard, 2009) . Un ejemplo de detección de anomalías mediante el aprendizaje de PU es la detección de revisiones falsas (Ren et al., 2014) .

Figura: 4. Un ejemplo de reseña falsa
Detección de corrupción en subastas de contratación pública rusas
La tercera categoría de aprendizaje de PU se puede atribuir a problemas en los que no se puede utilizar ni la clasificación binaria ni la clasificación de una sola clase. A modo de ejemplo, les contaré sobre nuestro proyecto para detectar corrupción en subastas de contratación pública rusa (Ivanov & Nesterov, 2019) .
Según la legislación, los datos completos sobre todas las subastas de contratación pública se colocan en el dominio público para todos los que quieran pasar un mes analizándolos. Hemos recopilado datos de más de un millón de subastas celebradas entre 2014 y 2018. Quién puso, cuándo y cuánto, quién ganó, en qué período se llevó a cabo la subasta, quién realizó, qué compró, todo esto está en los datos. Pero, por supuesto, no hay una etiqueta "la corrupción está aquí", por lo que no se puede construir un clasificador ordinario. En cambio, aplicamos el aprendizaje PU. Supuesto básico: los participantes con una ventaja injusta siempre ganarán. Usando esta suposición, los perdedores en las subastas pueden considerarse justos (positivos) y los ganadores como potencialmente deshonestos (sin marcar).Cuando se configura de esta manera, los métodos de aprendizaje de PU pueden encontrar patrones sospechosos en los datos basados en diferencias sutiles entre ganadores y perdedores. Por supuesto, en la práctica, surgen dificultades: se requiere un diseño preciso de características para el clasificador, un análisis de la interpretabilidad de sus predicciones y la verificación estadística de los supuestos sobre los datos.
Según nuestra estimación muy conservadora, alrededor del 9% de las subastas en los datos son corruptas, como resultado de lo cual el estado pierde alrededor de 120 millones de rublos al año. Las pérdidas pueden no parecer muy grandes, pero las subastas que estudiamos ocupan solo alrededor del 1% del mercado de contratación pública.


Figura: 5. La proporción de subastas de contratación pública corruptas en diferentes regiones de Rusia (Ivanov y Nesterov, 2019)
Observaciones finales
Para no dar la impresión de que la PU es la solución a todos los problemas de la humanidad, mencionaré las trampas. En una clasificación convencional, cuantos más datos tengamos, más preciso puede ser el clasificador. Además, al aumentar la cantidad de datos hasta el infinito, podemos acercarnos al clasificador ideal (según la fórmula bayesiana). Por lo tanto, el principal problema del aprendizaje de la PU es que es un problema mal planteado, es decir, un problema que no se puede resolver sin ambigüedades incluso con una cantidad infinita de datos. La situación mejora si se conoce la proporción de dos clases en los datos sin etiquetar, sin embargo, determinar esta proporción también es un problema mal planteado (Jain et al., 2016)... Lo mejor que podemos definir es el espaciado en el que se encuentra la proporción. Además, los métodos de aprendizaje de UP a menudo no ofrecen formas de estimar esta proporción y considerarla conocida. Hay métodos separados que lo estiman (la tarea se llama Estimación de la proporción de la mezcla), pero a menudo son lentos y / o inestables, especialmente cuando las dos clases están representadas de manera muy desigual en la mezcla.
En esta publicación, hablé sobre la definición intuitiva y la aplicación del aprendizaje PU. Además, puedo hablar sobre la definición formal del aprendizaje de la UP con fórmulas y sus explicaciones, así como sobre los métodos clásicos y modernos de aprendizaje de la UP. Si esta publicación despierta interés, escribiré una secuela.
Bibliografía
Blanchard, G., Lee, G., & Scott, C. (2010). Semi-supervised novelty detection. Journal of Machine Learning Research, 11(Nov), 2973–3009.
Elkan, C., & Noto, K. (2008). Learning classifiers from only positive and unlabeled data. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD 08, 213. https://doi.org/10.1145/1401890.1401920
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., & Tao, D. (2020). On Positive-Unlabeled Classification in GAN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8385–8393.
Ivanov, D. I., & Nesterov, A. S. (2019). Identifying Bid Leakage In Procurement Auctions: Machine Learning Approach. ArXiv Preprint ArXiv:1903.00261.
Jain, S., White, M., Trosset, M. W., & Radivojac, P. (2016). Nonparametric semi-supervised learning of class proportions. ArXiv Preprint ArXiv:1601.01944.
Kiryo, R., Niu, G., du Plessis, M. C., & Sugiyama, M. (2017). Positive-unlabeled learning with non-negative risk estimator. Advances in Neural Information Processing Systems, 1675–1685.
Ren, Y., Ji, D., & Zhang, H. (2014). Positive Unlabeled Learning for Deceptive Reviews Detection. EMNLP, 488–498.
Scott, C., & Blanchard, G. (2009). Novelty detection: Unlabeled data definitely help. Artificial Intelligence and Statistics, 464–471.
Xu, D., & Denil, M. (2019). Positive-Unlabeled Reward Learning. ArXiv:1911.00459 [Cs, Stat]. http://arxiv.org/abs/1911.00459
Yang, P., Li, X.-L., Mei, J.-P., Kwoh, C.-K., & Ng, S.-K. (2012). Positive-unlabeled learning for disease gene identification. Bioinformatics, 28(20), 2640–2647.