
Este artículo describirá la experiencia de crear una red neuronal para el reconocimiento facial, para ordenar todas las fotos de una conversación VK para encontrar una persona específica. Sin experiencia en redacción de redes neuronales y conocimientos mínimos de Python.
Introducción
Tenemos un amigo, que se llama Sergei, al que le encanta fotografiarse a sí mismo de una manera inusual y enviar una conversación, y también condimenta estas fotos con frases corporativas. Así que una de las noches en la discordia tuvimos una idea: crear un público en VK, donde pudiéramos publicar a Sergey con sus citas. Las primeras 10 publicaciones del aplazamiento fueron fáciles, pero luego quedó claro que no tenía sentido repasar todos los archivos adjuntos en una conversación con las manos. Entonces se decidió escribir una red neuronal para automatizar este proceso.
Plan
- Obtener enlaces a fotos de una conversación
- Descargar fotos
- Escribir una red neuronal
Antes de comenzar el desarrollo
, Python pip. , 0, ,
1. Obtener enlaces a fotos
Entonces queremos obtener todas las fotos de la conversación, el método messages.getHistoryAttachments es adecuado para nosotros , que devuelve los materiales del diálogo o conversación.
Desde el 15 de febrero de 2019, Vkontakte ha denegado el acceso a los mensajes de las aplicaciones que no han pasado la moderación. Como solución alternativa, puedo sugerir vkhost , que lo ayudará a obtener un token de mensajeros de terceros
Con el token recibido en vkhost, podemos recopilar la solicitud de API que necesitamos usando Postman . Puede, por supuesto, llenar todo con bolígrafos sin él, pero para mayor claridad lo usaremos.
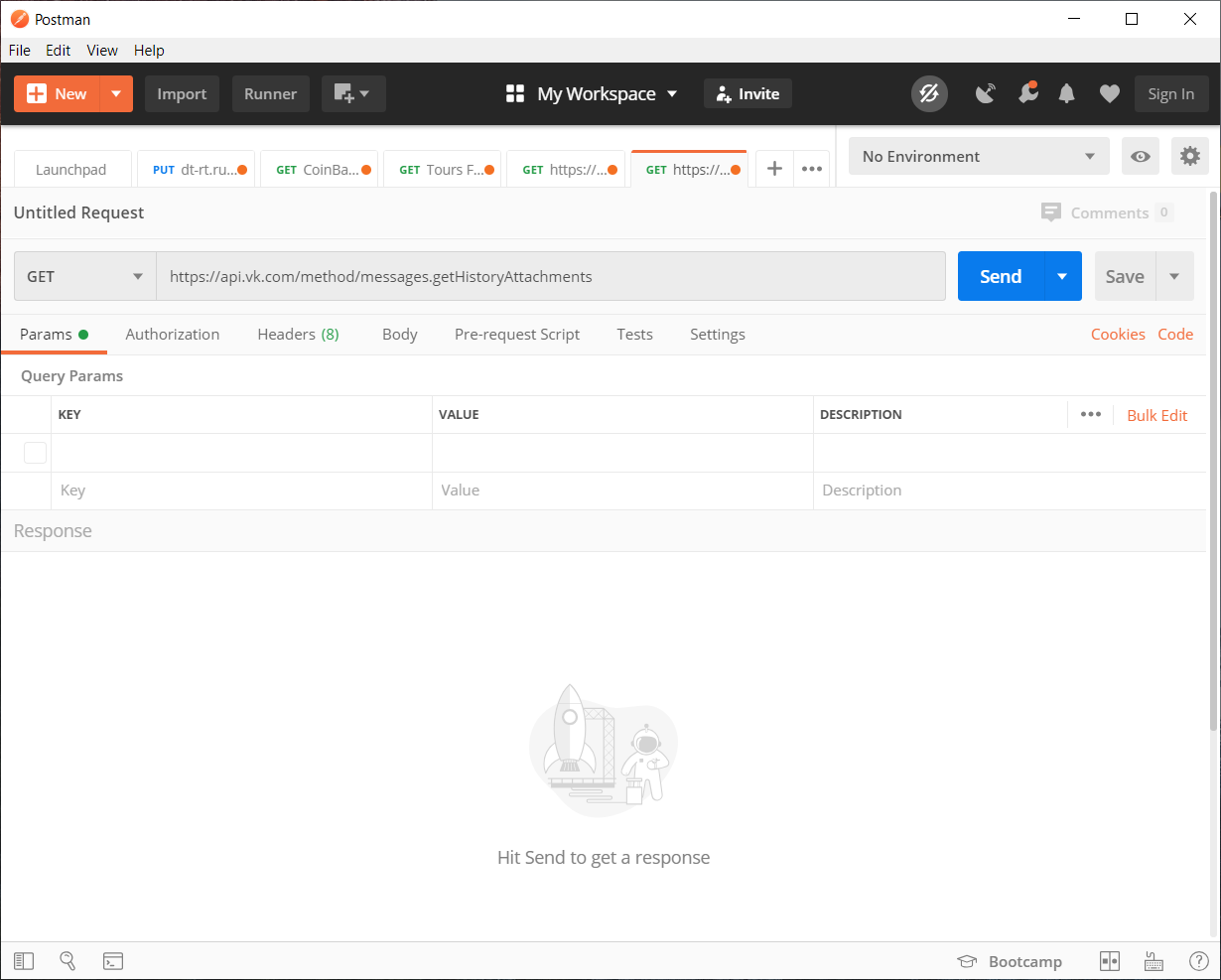
Complete los parámetros:
- peer_id - identificador de destino
Para una conversación: 2,000,000,000 + ID de conversación (se puede ver en la barra de direcciones).
Para usuario: ID de usuario. - media_type - tipo de medio
En nuestro caso, foto
- start_from - offset para seleccionar varios elementos.
Dejémoslo vacío por ahora.
- contar - el número de objetos recibidos
Máximo 200, eso es lo que usaremos
- photo_sizes - marca para devolver todos los tamaños en la matriz
1 o 0. Usamos 1
- preserve_order: marca que indica si los archivos adjuntos deben devolverse en su orden original
1 o 0. Usamos 1
- v - versión vk api
1 o 0. Usamos 1
Campos llenos en Postman
Ir a escribir código
Para mayor comodidad, todo el código se dividirá en varios scripts separados.
Utilizará el módulo json (para decodificar los datos) y la biblioteca de solicitudes (para realizar solicitudes http)
Listado de códigos si hay menos de 200 fotos en una conversación / diálogo
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
Si hay más de 200 fotos
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()Es hora de descargar enlaces
2. Descarga de imágenes
Para descargar fotos usamos la biblioteca urllib
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
El proceso de descarga de todas las imágenes no es el más rápido, especialmente si las fotos son 8330. También se requiere espacio para este caso, si la cantidad de fotos es igual a la mía o más, recomiendo liberar 1.5 - 2 GB para esto . El

trabajo duro está terminado, ahora puedes comenzar tú mismo interesante: escribir una red neuronal
3. Escribir una red neuronal
Después de revisar muchas bibliotecas y opciones diferentes, se decidió utilizar la biblioteca de
reconocimiento facial
¿Qué puede hacer?
A partir de la documentación, consideraremos las características más básicas
Buscar rostros en fotografías
Puede encontrar cualquier número de rostros en una foto, incluso hacer frente a imágenes borrosas.

Identificación de rostros en una fotografía.
Puede reconocer quién posee un rostro en una fotografía.

Para nosotros, la forma más adecuada es la identificación de rostros
Formación
De los requisitos para la biblioteca, se requiere Python 3.3+ o Python 2.7
En cuanto a las bibliotecas, se utilizará el reconocimiento facial y PIL antes mencionados para trabajar con imágenes.
La biblioteca de reconocimiento facial no es compatible oficialmente con Windows , pero me funcionó. Todo funciona de forma estable con macOS y Linux.
Explicación de lo que está pasando
Para empezar, necesitamos configurar un clasificador para buscar a una persona por la que ya se producirá una verificación adicional de las fotos.
Recomiendo elegir la foto más clara posible de una persona de rostro completoAl subir una foto, la biblioteca desglosa las imágenes en las coordenadas de los rasgos faciales de una persona (nariz, ojos, boca y barbilla)

Bueno, entonces el asunto es pequeño, solo queda aplicar un método similar a la foto para la que queremos comparar con nuestro clasificador. Luego dejamos que la red neuronal compare los rasgos faciales por coordenadas.
Bueno, el código real en sí:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
También es posible ejecutar todo un análisis en profundidad en una tarjeta de video, para esto es necesario agregar el parámetro model = "cnn" y cambiar el fragmento de código de la imagen con la que queremos buscar a la persona adecuada:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Resultado
Sin GPU. Por tiempo, la red neuronal pasó y ordenó 8330 fotos en 1 hora 40 minutos y al mismo tiempo encontró 142 fotos, 62 de ellas con la imagen de la persona deseada. Por supuesto, ha habido falsos positivos en memes y otras personas.
C GPU. El tiempo de procesamiento tomó mucho más, 17 horas y 22 minutos, y encontré 230 fotografías de las cuales 99 son la persona que necesitamos.
En conclusión, podemos decir que el trabajo no fue en vano. Hemos automatizado el proceso de clasificación de 8330 fotos, que es mucho mejor que ordenarlas usted mismo.
También puede descargar el código fuente completo de github