
Autoidentificación
Mi nombre es Alexander, estoy desarrollando la dirección de análisis de datos y tecnología para fines de auditoría interna del grupo Rosbank. Mi equipo y yo usamos el aprendizaje automático y las redes neuronales para identificar riesgos como parte de las auditorías internas. Tenemos un servidor ~ 300 GB RAM y 4 procesadores con 10 núcleos en nuestro arsenal. Para la programación algorítmica o el modelado, utilizamos Python.
Introducción
Nos enfrentábamos a la tarea de analizar fotografías (retratos) de clientes realizadas por empleados bancarios durante el registro de un producto bancario. Nuestro objetivo es identificar los riesgos previamente descubiertos a partir de estas fotografías. Para identificar el riesgo, generamos y probamos un conjunto de hipótesis. En este artículo, describiré las hipótesis que se nos ocurrieron y cómo las probamos. Para simplificar la percepción del material, usaré la Mona Lisa, el estándar del género del retrato.

Comprobar suma
Al principio, adoptamos un enfoque sin aprendizaje automático y visión por computadora, simplemente comparando las sumas de verificación de los archivos. Para generarlos, tomamos el algoritmo md5 ampliamente utilizado de la biblioteca hashlib.
Implementación de Python *:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
Al formar la suma de comprobación, verificamos inmediatamente si hay duplicados utilizando un diccionario.
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
Este algoritmo es increíblemente simple en términos de carga computacional: en nuestro servidor se procesan 1000 imágenes en no más de 3 segundos.
Este algoritmo nos ayudó a identificar fotos duplicadas entre nuestros datos y, como resultado, a encontrar lugares para una posible mejora del proceso comercial del banco.
Puntos clave (visión por computadora)
A pesar del resultado positivo del método de suma de verificación, entendimos perfectamente que si se cambia al menos un píxel en la imagen, su suma de verificación será radicalmente diferente. Como desarrollo lógico de la primera hipótesis, asumimos que la imagen podría cambiarse en estructura de bits: volver a guardar (es decir, volver a comprimir jpg), redimensionar, recortar o rotar.
Para la demostración, recortemos los bordes a lo largo del contorno rojo y giremos la Mona Lisa 90 grados a la derecha.

En este caso, los duplicados deben buscarse por el contenido visual de la imagen. Para ello, decidimos utilizar la biblioteca OpenCV, un método para construir puntos clave de una imagen y encontrar la distancia entre puntos clave. En la práctica, los puntos clave pueden ser esquinas, degradados de color o movimientos de superficie. Para nuestros propósitos, surgió uno de los métodos más simples: Combinación de fuerza bruta. Para medir la distancia entre los puntos clave de la imagen, usamos la distancia de Hamming. La siguiente imagen muestra el resultado de la búsqueda de puntos clave en las imágenes originales y modificadas (se dibujan los 20 puntos clave más cercanos de las imágenes).
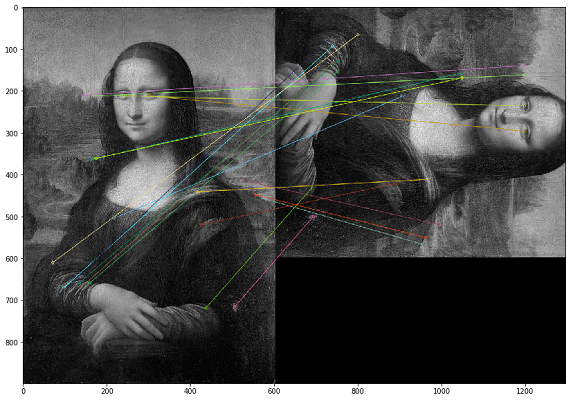
Es importante tener en cuenta que estamos analizando imágenes en un filtro en blanco y negro, ya que esto optimiza el tiempo de ejecución del script y da una interpretación más inequívoca de los puntos clave. Si una imagen tiene un filtro sepia y la otra tiene un color original, cuando las convertimos a un filtro en blanco y negro, los puntos clave se identificarán independientemente del procesamiento de color y los filtros.
Código de muestra para comparar dos imágenes *
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
Al probar los resultados, nos dimos cuenta de que en el caso de voltear una imagen (voltear), el orden de los píxeles dentro del punto clave cambia y tales imágenes no se identifican como iguales. Como medida compensatoria, puede reflejar cada imagen usted mismo y analizar el doble del volumen (o incluso el triple), que es mucho más caro en términos de potencia de cálculo.
Este algoritmo tiene una alta complejidad computacional y la mayor carga se crea mediante la operación de calcular la distancia entre puntos. Como tenemos que comparar cada imagen con cada una, entonces, como comprenderá, el cálculo de dicho conjunto cartesiano requiere una gran cantidad de ciclos computacionales. En una auditoría, un cálculo similar tomó más de un mes.
Otro problema con este enfoque fue la mala interpretación de los resultados de las pruebas. Obtenemos el coeficiente de las distancias entre los puntos clave de las imágenes, y surge la pregunta: "¿Qué umbral de este coeficiente debería elegirse suficiente para considerar las imágenes duplicadas?"
Utilizando la visión por computadora, pudimos encontrar casos que no estaban cubiertos por la primera prueba de suma de control. En la práctica, resultaron ser archivos jpg guardados en exceso. No identificamos casos más complejos de cambios de imagen en el conjunto de datos analizados.
Suma de comprobación VS puntos clave
Habiendo desarrollado dos enfoques radicalmente diferentes para encontrar duplicados y reutilizarlos en varias comprobaciones, llegamos a la conclusión de que para nuestros datos, la suma de comprobación da un resultado más tangible en menos tiempo. Por lo tanto, si tenemos tiempo suficiente para verificar, hacemos una comparación por puntos clave.
Buscar imágenes anormales
Después de analizar los resultados de la prueba en busca de puntos clave, notamos que las fotografías tomadas por un empleado tienen aproximadamente el mismo número de puntos clave cercanos. Y esto es lógico, porque si se comunica con los clientes en su lugar de trabajo y toma fotos en la misma habitación, entonces el fondo de todas sus fotos será el mismo. Esta observación nos llevó a creer que podríamos encontrar fotos excepcionales que no son como otras fotografías de este empleado, que pueden haber sido tomadas fuera de la oficina.
Volviendo al ejemplo de Mona Lisa, resulta que aparecerán otras personas en el mismo contexto. Pero, lamentablemente, no encontramos tales ejemplos, por lo que en esta sección mostraremos métricas de datos sin ejemplos. Para aumentar la velocidad de cálculo en el marco de la prueba de esta hipótesis, decidimos abandonar los puntos clave y utilizar histogramas.
El primer paso es traducir la imagen en un objeto (histograma) que podamos medir para poder comparar las imágenes por la distancia entre sus histogramas. Básicamente, un histograma es un gráfico que ofrece una descripción general de la imagen. Este es un gráfico con valores de píxeles en el eje de abscisas (eje X) y el número correspondiente de píxeles en la imagen a lo largo del eje de ordenadas (eje Y). Un histograma es una forma sencilla de interpretar y analizar una imagen. Con el histograma de una imagen, puede obtener una idea intuitiva del contraste, el brillo, la distribución de la intensidad, etc.
Para cada imagen, creamos un histograma usando la función calcHist de OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
En los ejemplos dados para tres imágenes, las describimos usando 256 factores a lo largo del eje horizontal (todos los tipos de píxeles). Pero también podemos reorganizar los píxeles. Nuestro equipo no hizo muchas pruebas en esta parte, ya que el resultado fue bastante bueno al usar 256 factores. Si es necesario, podemos cambiar este parámetro directamente en la función calcHist.
Una vez que hemos creado histogramas para cada imagen, simplemente podemos entrenar el modelo DBSCAN a partir de imágenes para cada empleado que fotografió al cliente. El punto técnico aquí es seleccionar los parámetros DBSCAN (epsilon y min_samples) para nuestra tarea.
Después de usar DBSCAN, podemos agrupar imágenes y luego aplicar el método PCA para visualizar los clústeres resultantes.

Como se puede ver en la distribución de las imágenes analizadas, tenemos dos grupos azules pronunciados. Al final resultó que, en diferentes días, un empleado puede trabajar en diferentes oficinas: las fotografías tomadas en una de las oficinas crean un grupo separado.
Mientras que los puntos verdes son fotos excepcionales, donde el fondo es diferente de estos grupos.
Tras un análisis detallado de las fotografías, encontramos muchas fotografías negativas falsas. Los casos más comunes son fotografías reventadas o fotografías en las que un gran porcentaje del área está ocupada por el rostro del cliente. Resulta que este método de análisis requiere la intervención humana obligatoria para validar los resultados.
Con este enfoque, puede encontrar anomalías interesantes en la foto, pero se necesitará una inversión de tiempo para analizar manualmente los resultados. Por estas razones, rara vez realizamos tales pruebas como parte de nuestras auditorías.
¿Hay una cara en la foto? (Detección de rostro)
Entonces, ya hemos probado nuestro conjunto de datos desde diferentes lados y, continuando desarrollando la complejidad de las pruebas, pasamos a la siguiente hipótesis: ¿hay una cara del cliente potencial en la foto? Nuestra tarea es aprender a identificar caras en imágenes, dar funciones a la entrada de una imagen y obtener el número de caras en la salida.
Este tipo de implementación ya existe, y decidimos elegir MTCNN (Multitasking Cascade Convolutional Neural Network) para nuestra tarea desde el módulo FaceNet de Google.
FaceNet es una arquitectura de aprendizaje automático profundo que consta de capas convolucionales. FaceNet devuelve un vector de 128 dimensiones para cada cara. De hecho, FaceNet son varias redes neuronales y un conjunto de algoritmos para preparar y procesar resultados intermedios de estas redes. Decidimos describir la mecánica de la búsqueda de rostros por esta red neuronal con más detalle, ya que no hay tantos materiales sobre esto.
Paso 1: preprocesamiento
Lo primero que hace MTCNN es crear varios tamaños de nuestra foto.
MTCNN intentará reconocer caras dentro de un cuadrado de tamaño fijo en cada fotografía. Usar este reconocimiento en la misma foto de diferentes tamaños aumentará nuestras posibilidades de reconocer correctamente todas las caras en la foto.

Es posible que una cara no se reconozca en un tamaño de imagen normal, pero se puede reconocer en una imagen de tamaño diferente en un cuadrado de tamaño fijo. Este paso se realiza algorítmicamente sin una red neuronal.
Paso 2: P-Net
Tras crear distintas copias de nuestra foto, entra en juego la primera red neuronal, P-Net. Esta red utiliza un núcleo (bloque) de 12x12 que escaneará todas las fotos (copias de la misma foto, pero de diferentes tamaños), comenzando desde la esquina superior izquierda, y se moverá a lo largo de la imagen con un incremento de 2 píxeles.

Después de escanear todas las imágenes de diferentes tamaños, MTCNN nuevamente estandariza cada foto y recalcula las coordenadas del bloque.
El P-Net proporciona las coordenadas de los bloques y los niveles de confianza (qué tan precisa es esta cara) en relación con la cara que contiene para cada bloque. Puede dejar bloques con un cierto nivel de confianza utilizando el parámetro de umbral.
Al mismo tiempo, no podemos simplemente seleccionar los bloques con el máximo nivel de confianza, porque la imagen puede contener varias caras.
Si un bloque se superpone a otro y cubre casi la misma área, ese bloque se elimina. Este parámetro se puede controlar durante la inicialización de la red.

En este ejemplo, se eliminará el bloque amarillo. Básicamente, el resultado del P-Net son bloques de baja precisión. El siguiente ejemplo muestra los resultados reales de P-Net:

Paso 3: R-Net
R-Net realiza una selección de los bloques más adecuados formados como resultado del trabajo de P-Net, que en el grupo probablemente sea una persona. R-Net tiene una arquitectura similar a P-Net. En esta etapa, se forman capas completamente conectadas. La salida de R-Net también es similar a la salida de P-Net.

Paso 4: O-Net
La red O-Net es la última parte de la red MTCNN. Además de las dos últimas redes, forma cinco puntos para cada rostro (ojos, nariz, comisuras de labios). Si estos puntos caen completamente dentro del bloque, entonces se determina que es el más probable que contenga a la persona. Los puntos adicionales están marcados en azul:

Como resultado, obtenemos un bloque final que indica la precisión del hecho de que se trata de una cara. Si no se encuentra la cara, obtendremos un número cero de bloques de caras.
En promedio, el procesamiento de 1000 fotos por una red de este tipo lleva 6 minutos en nuestro servidor.
Hemos utilizado repetidamente esta red neuronal en las comprobaciones y nos ayudó a identificar automáticamente anomalías entre las fotografías de nuestros clientes.
Sobre el uso de FaceNet, me gustaría agregar que si en lugar de Mona Lisa comienza a analizar los lienzos de Rembrandt, los resultados serán algo como la imagen a continuación, y tendrá que analizar la lista completa de personas identificadas:

Conclusión
Estas hipótesis y enfoques de prueba demuestran que con absolutamente cualquier conjunto de datos puede realizar pruebas interesantes y buscar anomalías. Muchos auditores ahora están tratando de desarrollar prácticas similares, por lo que quería mostrar ejemplos prácticos del uso de la visión por computadora y el aprendizaje automático.
También me gustaría agregar que consideramos el reconocimiento facial como la próxima hipótesis para las pruebas, pero hasta ahora los datos y los detalles del proceso no proporcionan una base razonable para usar esta tecnología en nuestras pruebas.
En general, esto es todo lo que me gustaría contarles sobre nuestra forma de probar fotos.
¡Te deseo buenos análisis y datos etiquetados!
* El código de muestra se toma de fuentes abiertas.