Por lo tanto, cuando se produce un consumo anormal de recursos (CPU, memoria, disco, red, ...) en uno de los miles de servidores controlados , es necesario averiguar "quién tiene la culpa y qué hacer".
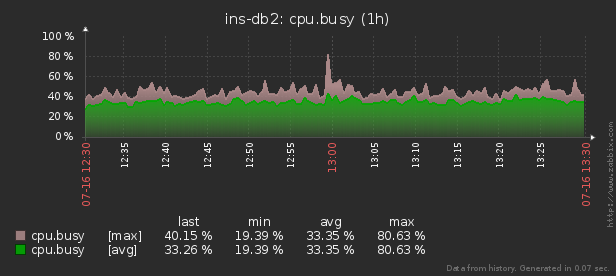
Existe una utilidad pidstat para el monitoreo en tiempo real del uso de recursos del servidor Linux "en este momento" . Es decir, si los picos de carga son periódicos, se pueden "sombrear" directamente en la consola. Pero queremos analizar estos datos después del hecho , tratando de encontrar el proceso que creó la carga máxima de recursos.
Es decir, me gustaría poder ver los datos recopilados anteriormente en varios informes hermosos con agrupaciones y detalles en un intervalo como estos:
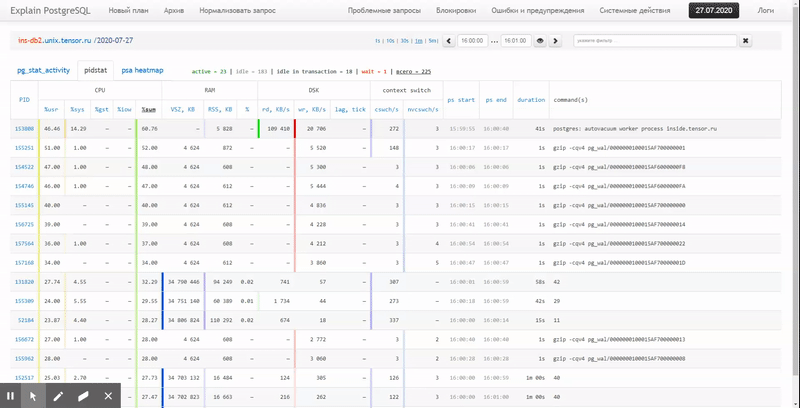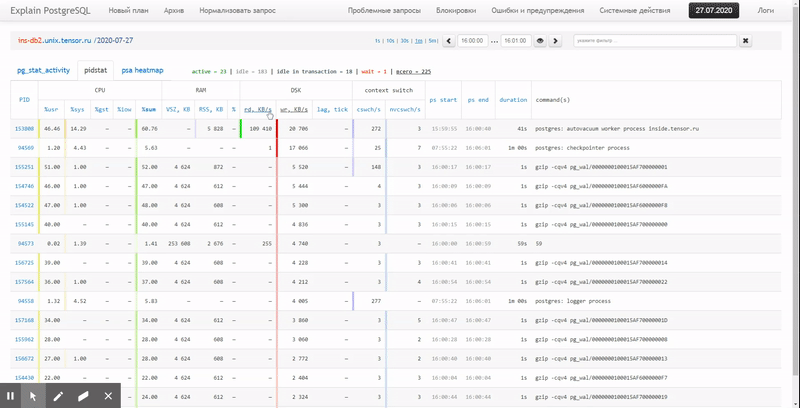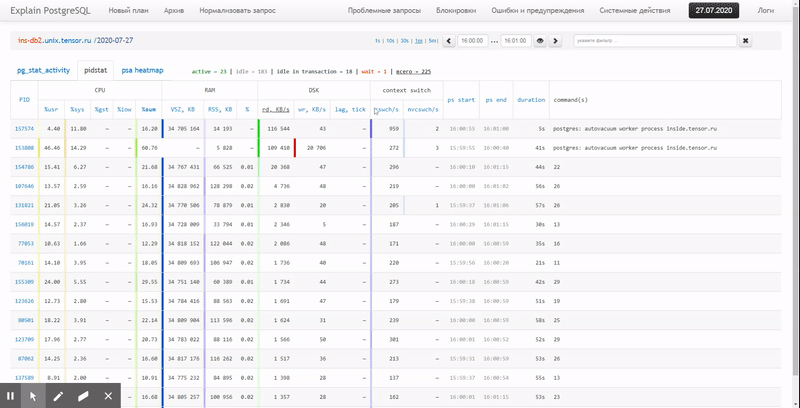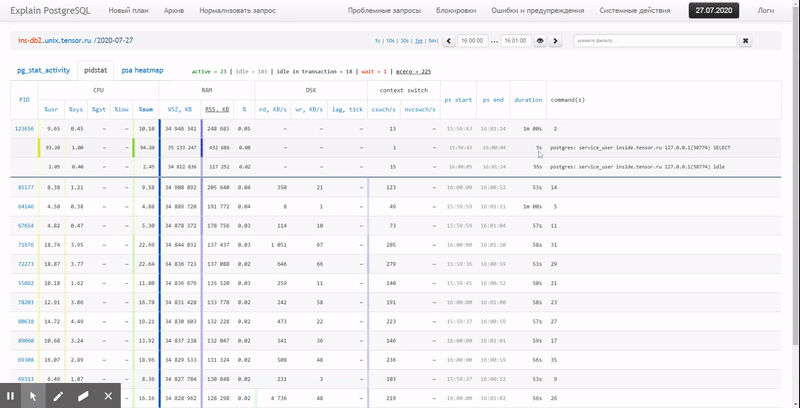
En este artículo, consideraremos cómo todo esto se puede ubicar económicamente en la base de datos y cómo recopilar de manera más efectiva un informe sobre estos datos utilizando funciones de ventana y GRUPO DE JUEGOS .
Primero, veamos qué tipo de datos podemos extraer si llevamos "todo al máximo":
pidstat -rudw -lh 1| Hora | UID | PID | % usr | % sistema | % invitado | % UPC | UPC | minflt / s | majflt / s | VSZ | Rss | % MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | Mando |
| 1594893415 | 0 | 1 | 0,00 | 13.08 | 0,00 | 13.08 | 52 | 0,00 | 0,00 | 197312 | 8512 | 0,00 | 0,00 | 0,00 | 0,00 | 0,00 | 7,48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | nueve | 0,00 | 0,93 | 0,00 | 0,93 | 40 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 350,47 | 0,00 | rcu_sched |
| 1594893415 | 0 | trece | 0,00 | 0,00 | 0,00 | 0,00 | 1 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 1,87 | 0,00 | migración / 11,87 |
Todos estos valores se dividen en varias clases. Algunos de ellos cambian constantemente (CPU y actividad del disco), otros rara vez (asignación de memoria) y Command no solo cambia raramente dentro del mismo proceso, sino que también se repite regularmente en diferentes PID.
Estructura base
En aras de la simplicidad, limitémonos a una métrica para cada "clase" que guardaremos:% CPU, RSS y Command.
Como sabemos de antemano que Command se repite regularmente, simplemente lo trasladaremos a un diccionario de tabla separado, donde el hash MD5 actuará como clave UUID:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);Y para los datos en sí, una tabla de este tipo es adecuada para nosotros:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Me gustaría llamar su atención sobre el hecho de que, dado que el% de CPU siempre nos llega con una precisión de 2 lugares decimales y ciertamente no excede 100,00, entonces podemos multiplicarlo fácilmente por 100 y ponerlo
smallint. Por un lado, esto nos salvará de los problemas de precisión contable durante las operaciones, por otro lado, es mejor almacenar solo 2 bytes en comparación con 4 bytes realu 8 bytes double precision.
Puede leer más sobre formas de empaquetar registros de manera eficiente en el almacenamiento PostgreSQL en el artículo "Ahorre un centavo en grandes volúmenes" , y sobre cómo aumentar el rendimiento de la base de datos para escritura, en "Escritura en sublight: 1 host, 1 día, 1TB" .
Almacenamiento "gratuito" de NULL
Para salvar el rendimiento del subsistema de disco de nuestra base de datos y el espacio que ocupa la base de datos, intentaremos representar la mayor cantidad de datos posible en forma de NULL - su almacenamiento es prácticamente "gratuito", ya que solo ocupa un poco en el encabezado del registro.
Se puede encontrar más información sobre la mecánica interna de representar registros en PostgreSQL en la charla de Nikolai Shaplov en PGConf.Russia 2016 "Qué hay dentro: almacenamiento de datos a bajo nivel" . La diapositiva n. ° 16 está dedicada al almacenamiento NULL .Echemos un vistazo más de cerca a los tipos de nuestros datos:
- CPU / DSK
Cambia constantemente, pero muy a menudo cambia a cero, por lo que es beneficioso escribir NULL en lugar de 0 en la base . - RSS / CMD
Cambia muy raramente, por lo que escribiremos NULL en lugar de repeticiones dentro del mismo PID.
Resulta una imagen como esta, si la miras en el contexto de un PID específico:

está claro que si nuestro proceso comenzaba a ejecutar otro comando, entonces el valor de la memoria utilizada probablemente también será diferente al anterior, por lo que estaremos de acuerdo en que al cambiar CMD, el valor de RSS también será arreglar independientemente del valor anterior.
Es decir , una entrada con un valor CMD completo también tiene un valor RSS . Recordemos este momento, todavía nos será útil.
Armado de un hermoso informe
Hagamos ahora una consulta que nos muestre los consumidores de recursos de un host específico en un intervalo de tiempo específico.
Pero hagámoslo de inmediato con un uso mínimo de recursos, similar al artículo sobre SELF JOIN y funciones de ventana .
Usando parámetros entrantes
Para no especificar los valores de los parámetros del informe (o $ 1 / $ 2) en varios lugares durante la consulta SQL, seleccionaremos el CTE del único campo json en el que estos parámetros están ubicados por claves:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
Recuperando datos brutos
Dado que no inventamos ningún agregado complejo, la única forma de analizar los datos es leerlos. Para esto necesitamos un índice obvio:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Agrupación de claves de análisis
Para cada PID encontrado, determine el intervalo de su actividad y tome el CMD del primer registro en este intervalo.
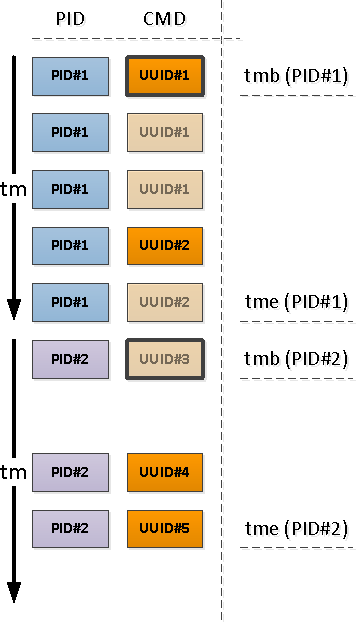
Para hacer esto, usaremos funciones de exclusividad a través
DISTINCT ONy de ventana:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Límites de actividad de proceso
Tenga en cuenta que en relación con el comienzo de nuestro intervalo, el primer registro que aparece puede ser uno que ya tiene un campo CMD lleno (PID # 1 en la imagen de arriba), o con NULL, lo que indica la continuación del valor completo "arriba" en cronología (PID # 2 ).
Aquellos de los PID que quedaron sin CMD como resultado de la operación anterior comenzaron antes del comienzo de nuestro intervalo, lo que significa que estos "comienzos" deben encontrarse:

ya que sabemos con certeza que el siguiente segmento de actividad comienza con un valor CMD completo (y hay un RSS completo, lo que significa ), el índice condicional nos ayudará aquí:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
Si queremos (y queremos) conocer la hora de finalización de la actividad del segmento, entonces para cada PID tendremos que utilizar un "bidireccional" para determinar el límite inferior.
Ya hemos utilizado una técnica similar en el artículo PostgreSQL Antipatterns: Registry Navigation .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
Conversión JSON de formatos de publicación
Tenga en cuenta que seleccionamos
precmd/pstcmdsolo los campos que afectan a las líneas posteriores y cualquier CPU / DSK que cambie constantemente; no. Por lo tanto, el formato de los registros en la tabla original y estos CTEs diverge. ¡No hay problema!
- row_to_json : convierte cada registro con campos en un objeto json
- array_agg : recopila todas las entradas en '{...}' :: json []
- array_to_json - convierte array-from-JSON en JSON array '[...]' :: json
- json_populate_recordset : genera una selección de una estructura dada a partir de una matriz JSON
Aquí usamos una sola llamada enPegamos los "comienzos" y "finales" encontrados en un montón común y los agregamos al conjunto original de registros:json_populate_recordsetlugar de una múltiplejson_populate_record, porque es mucho más rápido.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Rellenar huecos nulos en repeticiones
Usemos el modelo discutido en el artículo "SQL HowTo: Construir cadenas con funciones de ventana" .Primero, seleccionemos los grupos de "repetición":
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
Además, según CMD y RSS, los grupos serán independientes entre sí, por lo que pueden verse así:
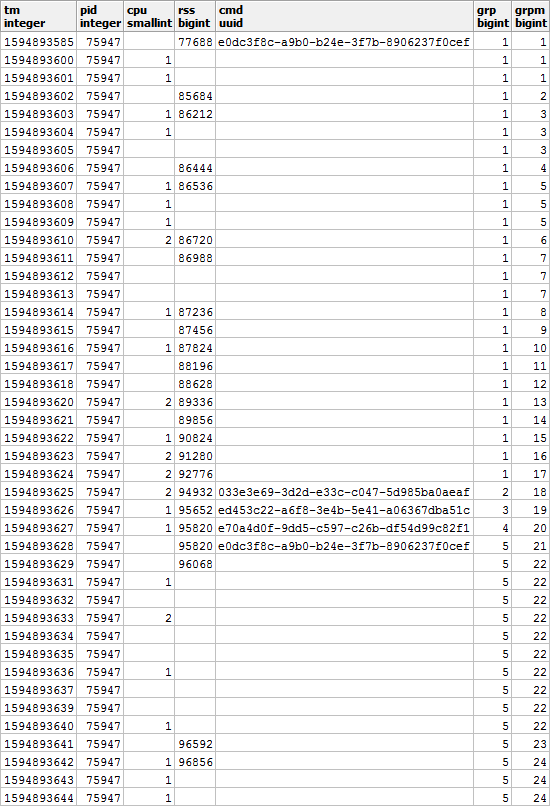
Rellene los huecos en RSS y calcule la duración de cada segmento para tener en cuenta correctamente la distribución de la carga en el tiempo:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Agrupación múltiple con JUEGOS DE AGRUPACIÓN
Como queremos ver como resultado tanto la información resumida de todo el proceso como su detalle por diferentes segmentos de actividad, usaremos la agrupación por varios conjuntos de claves a la vez usando GROUPING SETS :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
El caso de uso (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]nos permite obtener el primer valor no vacío (incluso si no es el primero) del conjunto completo justo al agrupar, sin movimientos corporales adicionales .La opción de obtener varias secciones de la muestra de destino a la vez es muy conveniente para generar varios informes con detalles, de modo que no es necesario reconstruir todos los datos detallados, sino que aparecen en la interfaz de usuario junto con la muestra principal.
Diccionario en lugar de JOIN
Cree un "diccionario" CMD para todos los segmentos encontrados:
Puede leer más sobre la técnica de "masterización" en el artículo "Antipatrones de PostgreSQL: vamos a hacer un JOIN pesado con un diccionario" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
Y ahora lo usamos en su lugar
JOIN, obteniendo los datos "hermosos" finales:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
Por último, asegurémonos de que toda nuestra consulta resultó ser bastante liviana cuando se ejecutó:

[mira explica.tensor.ru] ¡
Solo se leyeron 44 ms y 33 MB de datos!