En este artículo, te contaré sobre las principales funciones de BigQuery y mostraré sus capacidades con ejemplos específicos. Puede escribir consultas básicas y probarlas con datos de demostración.
Que es SQL y que dialectos tiene
SQL (Structured Query Language) es un lenguaje de consulta estructurado para trabajar con bases de datos. Con su ayuda, puede recibir, agregar a la base de datos y modificar grandes cantidades de datos. Google BigQuery admite dos dialectos: SQL estándar y SQL heredado.
El dialecto a elegir depende de su preferencia, pero Google recomienda usar SQL estándar debido a una serie de ventajas:
- Flexibilidad y funcionalidad al trabajar con campos anidados y repetidos.
- Soporte para lenguajes DML y DDL , que le permiten cambiar datos en tablas, así como manipular tablas y vistas en GBQ.
- El procesamiento de grandes cantidades de datos es más rápido que Legasy SQL.
- Compatibilidad con todas las actualizaciones de BigQuery actuales y futuras.
Puede obtener más información sobre la diferencia entre dialectos en la ayuda .
De forma predeterminada, las consultas de Google BigQuery se ejecutan en SQL heredado.
Hay varias formas de cambiar a SQL estándar:
- En la interfaz de BigQuery, en la ventana de edición de consultas, seleccione "Mostrar opciones" y desmarque la casilla junto a la opción "Usar SQL heredado".

- Agregue la línea #standardSQL antes de la consulta e inicie la consulta en una nueva línea

Dónde empezar
Para que pueda practicar la ejecución de consultas en paralelo con la lectura del artículo, he preparado una tabla con datos de demostración para usted . Cargue los datos de la hoja de cálculo en su proyecto de Google BigQuery.
Si aún no tiene un proyecto de GBQ, cree uno. Para hacer esto, necesita una cuenta de facturación activa en Google Cloud Platform . Deberá vincular la tarjeta, pero sin su conocimiento no se le debitará dinero, además, al registrarse recibirá $ 300 por 12 meses , que puede gastar en el almacenamiento y procesamiento de datos.
Funciones de Google BigQuery
Los grupos de funciones más utilizados al crear consultas son la función de agregación, la función de fecha, la función de cadena y la función de ventana. Ahora más sobre cada uno de ellos.
Función agregada
Las funciones de agregación le permiten obtener valores de resumen en toda la tabla. Por ejemplo, calcule el cheque promedio, el ingreso mensual total o resalte el segmento de usuarios que realizó el número máximo de compras.
Estas son las funciones más populares de esta sección:
| SQL heredado | SQL estándar | Que hace la función |
|---|---|---|
| AVG (campo) | AVG ([DISTINCT] (campo)) | Devuelve el promedio de la columna del campo. En SQL estándar, cuando se agrega la cláusula DISTINCT, el promedio se calcula solo para las filas con valores únicos (no duplicados) de la columna del campo |
| MAX (campo) | MAX (campo) | Devuelve el valor máximo de la columna del campo. |
| MIN (campo) | MIN (campo) | Devuelve el valor mínimo de la columna del campo. |
| SUM (campo) | SUM (campo) | Devuelve la suma de valores de la columna del campo. |
| COUNT (campo) | COUNT (campo) | Devuelve el número de filas en el campo de la columna. |
| EXACT_COUNT_DISTINCT (campo) | COUNT ([DISTINCT] (campo)) | Devuelve el número de filas únicas en la columna del campo. |
Puede encontrar una lista de todas las funciones en la Ayuda: SQL heredado y SQL estándar .
Veamos cómo funcionan las funciones enumeradas con una demostración de datos de ejemplo. Calculemos el ingreso promedio de transacciones, compras con el monto más alto y más bajo, el ingreso total y el número de todas las transacciones. Para comprobar si las compras están duplicadas, también calcularemos el número de transacciones únicas. Para ello, escribimos una consulta en la que indicamos el nombre de nuestro proyecto, conjunto de datos y tabla de Google BigQuery.
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]# SQL estándar
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`Como resultado, obtenemos los siguientes resultados:
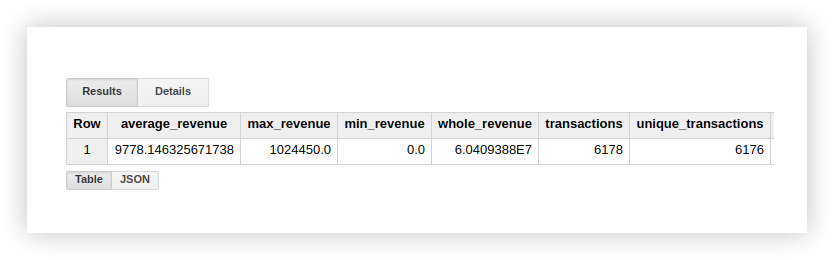
Puede verificar los resultados del cálculo en la tabla original con datos de demostración utilizando funciones estándar de Google Sheets (SUM, AVG y otras) o tablas dinámicas.
Como puede ver en la captura de pantalla anterior, la cantidad de transacciones y transacciones únicas es diferente.
Esto sugiere que hay 2 transacciones en nuestra tabla que tienen un transactionId duplicado:
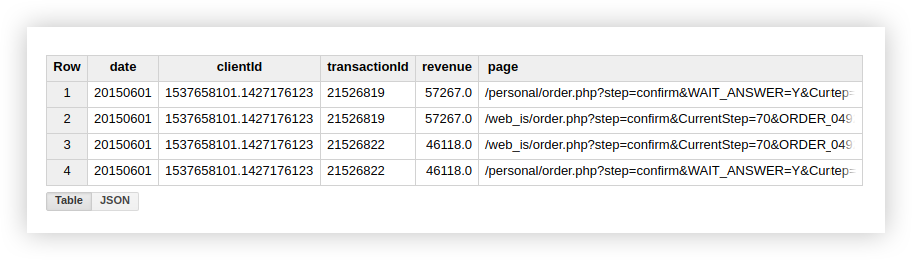
Por lo tanto, si está interesado en transacciones únicas, use la función que cuenta filas únicas. Alternativamente, puede agrupar los datos usando una cláusula GROUP BY para deshacerse de los duplicados antes de usar la función de agregación.
Funciones para trabajar con fechas (función de fecha)
Estas funciones le permiten procesar fechas: cambiar su formato, seleccionar la parte requerida (día, mes o año), cambiar la fecha en un cierto intervalo.
Pueden serle útiles en los siguientes casos:
- Al configurar análisis de extremo a extremo, para reunir fechas y horas de diferentes fuentes en un solo formato.
- Al crear informes actualizados automáticamente o correos activados. Por ejemplo, cuando necesite datos de las últimas 2 horas, una semana o un mes.
- Al crear informes de cohortes en los que es necesario obtener datos en el contexto de días, semanas, meses.
Funciones de fecha más utilizadas:
| SQL heredado | SQL estándar | Que hace la función |
|---|---|---|
| FECHA ACTUAL () | FECHA ACTUAL () | Devuelve la fecha actual en el formato% AAAA-% MM-% DD |
| FECHA (marca de tiempo) | FECHA (marca de tiempo) | Convierte una fecha del formato% AAAA-% MM-% DD% H:% M:% S. en el formato% AAAA-% MM-% DD |
| DATE_ADD (marca de tiempo, intervalo, unidades_intervalo) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
Para obtener una lista de todas las funciones, consulte la Ayuda de SQL heredado y SQL estándar .
Echemos un vistazo a la demostración de datos sobre cómo funciona cada una de las funciones anteriores. Por ejemplo, obtenemos la fecha actual, traemos la fecha de la tabla original al formato% YYYY-% MM-% DD, restamos y agregamos un día. Luego calculamos la diferencia entre la fecha actual y la fecha de la tabla original y dividimos la fecha actual por separado en año, mes y día. Para hacer esto, puede copiar las consultas de ejemplo a continuación y reemplazar el nombre del proyecto, el conjunto de datos y la tabla de datos con el suyo.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
# SQL estándar
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
Después de aplicar la solicitud, recibirá el siguiente informe:
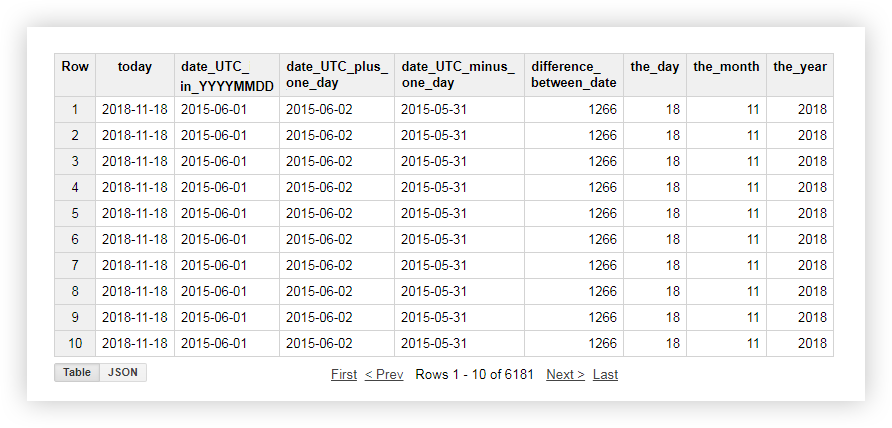
Funciones para trabajar con cadenas (función String)
Las funciones de cadena le permiten formar una cadena, resaltar y reemplazar subcadenas, calcular la longitud de la cadena y el índice ordinal de la subcadena en la cadena original.
Por ejemplo, con su ayuda puedes:
- Realice filtros en el informe mediante etiquetas UTM que se pasan a la URL de la página.
- Traiga los datos a un formato uniforme si los nombres de las fuentes y campañas están escritos en diferentes registros.
- Reemplace los datos incorrectos en el informe, por ejemplo, si el nombre de la campaña se envió con un error tipográfico.
Las funciones más populares para trabajar con cadenas:
| SQL heredado | SQL estándar | Que hace la función |
|---|---|---|
| CONCAT ('str1', 'str2') o 'str1' + 'str2' | CONCAT ('str1', 'str2') | Concatena varias cadenas 'str1' y 'str2' en una |
| 'str1' CONTIENE 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Devuelve el índice de la primera aparición de la cadena 'str2' en la cadena 'str1', de lo contrario - 0 |
| REEMPLAZAR ('str1', 'str2', 'str3') | REEMPLAZAR ('str1', 'str2', 'str3') | Reemplaza en la cadena 'str1' la subcadena 'str2' con la subcadena 'str3' |
Más detalles: en la ayuda: SQL heredado y SQL estándar .
Veamos el ejemplo de datos de demostración sobre cómo utilizar las funciones descritas. Supongamos que tenemos 3 columnas separadas que contienen los valores del día, mes y año:
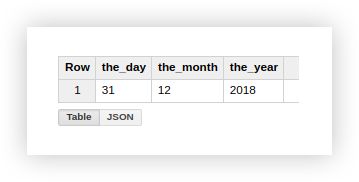
trabajar con una fecha en este formato no es muy conveniente, así que lo combinaremos en una sola columna. Para hacer esto, use las consultas SQL a continuación y no olvide incluir el nombre de su proyecto, conjunto de datos y tabla de Google BigQuery.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
# SQL estándar
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
Después de ejecutar la solicitud, recibiremos la fecha en una columna:

A menudo, al cargar una determinada página en el sitio, la URL contiene los valores de las variables que el usuario ha seleccionado. Este puede ser un método de pago o entrega, un número de transacción, un índice de una tienda física donde un cliente desea retirar un artículo, etc. Mediante una consulta SQL, puede extraer estos parámetros de la dirección de la página.
Veamos dos ejemplos de cómo y por qué hacer esto.
Ejemplo 1 . Digamos que queremos saber la cantidad de compras en las que los usuarios recogen artículos de las tiendas físicas. Para hacer esto, necesita contar el número de transacciones enviadas desde páginas cuya URL contiene la subcadena shop_id (índice de la tienda física). Hacemos esto usando las siguientes consultas:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
# SQL estándar
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
En la tabla resultante, vemos que se enviaron 5502 transacciones desde las páginas que contienen shop_id (check = true):
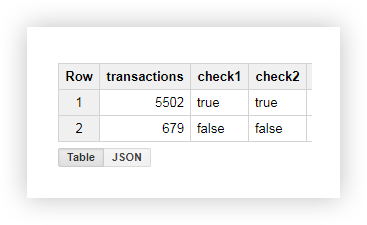
Ejemplo 2 . Supongamos que asignó su delivery_id a cada método de entrega y escribió el valor de este parámetro en la URL de la página. Para saber qué método de entrega ha elegido el usuario, seleccione delivery_id en una columna separada.
Usamos las siguientes consultas para esto:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
# SQL estándar
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
Como resultado, obtenemos la siguiente tabla en Google BigQuery:

Funciones para trabajar con subconjuntos de datos o funciones de ventana (función de ventana)
Estas funciones son similares a las funciones de agregación que discutimos anteriormente. Su principal diferencia es que los cálculos no se realizan en todo el conjunto de datos seleccionados mediante una consulta, sino en una parte de ella: un subconjunto o ventana.
Con las funciones de ventana, puede agregar datos por grupos sin usar el operador JOIN para combinar varias consultas. Por ejemplo, calcule el ingreso promedio por campañas publicitarias, el número de transacciones por dispositivo. Al agregar otro campo al informe, puede averiguar fácilmente, por ejemplo, la participación de los ingresos de una campaña publicitaria en el Black Friday o la participación de las transacciones realizadas desde una aplicación móvil.
Junto con cada función, se debe escribir una expresión OVER en la solicitud, que define los límites de la ventana. OVER contiene 3 componentes con los que puede trabajar:
- PARTICIÓN POR: define el atributo mediante el cual dividirá los datos de origen en subconjuntos, por ejemplo, PARTICIÓN POR clientId, DayTime.
- ORDER BY: define el orden de las filas en el subconjunto, por ejemplo, ORDER BY hora DESC.
- MARCO DE VENTANA: le permite procesar filas dentro de un subconjunto de acuerdo con una característica específica. Por ejemplo, puede calcular la suma de no todas las líneas de la ventana, sino solo las cinco primeras antes de la línea actual.
Esta tabla resume las funciones de ventana más utilizadas:
| SQL heredado | SQL estándar | Que hace la función |
|---|---|---|
| AVG (campo)
COUNT (campo) COUNT (campo DISTINCT) MAX () MIN () SUM () |
AVG ([DISTINCT] (campo))
COUNT (campo) COUNT ([DISTINCT] (campo)) MAX (campo) MIN (campo) SUM (campo) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
Puede ver una lista de todas las funciones en la ayuda de SQL heredado y SQL estándar: funciones analíticas agregadas , funciones de navegación .
Ejemplo 1. Supongamos que queremos analizar la actividad de los clientes en horario laboral y no laboral. Para ello es necesario dividir las transacciones en 2 grupos y calcular las métricas que nos interesan:
- Grupo 1: compras en horario comercial de 9:00 a 18:00 horas.
- Grupo 2 - compras fuera del horario laboral de 00:00 a 9:00 y de 18:00 a 00:00.
Además de las horas laborables y no laborables, otro signo para la formación de una ventana será clientId, es decir, para cada usuario tendremos dos ventanas:
| Subconjunto (ventana) | Identificación del cliente | Tiempo de día |
|---|---|---|
| 1 ventana | clientId 1 | Tiempo de trabajo |
| 2 ventana | clientId 2 | Horas no laborables |
| 3 ventana | clientId 3 | Tiempo de trabajo |
| 4 ventana | clientId 4 | Horas no laborables |
| N ventana | clientId N | Tiempo de trabajo |
| Ventana N + 1 | clientId N + 1 | Horas no laborables |
Calculemos el ingreso promedio, máximo, mínimo y total, el número de transacciones y el número de transacciones únicas para cada usuario durante el horario laboral y no laboral en los datos de demostración. Las consultas a continuación nos ayudarán a hacer esto.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
# SQL estándar
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
Veamos qué sucedió como resultado, usando el ejemplo de uno de los usuarios con clientId = '102041117.1428132012 ′. En la tabla original para este usuario, teníamos los siguientes datos:
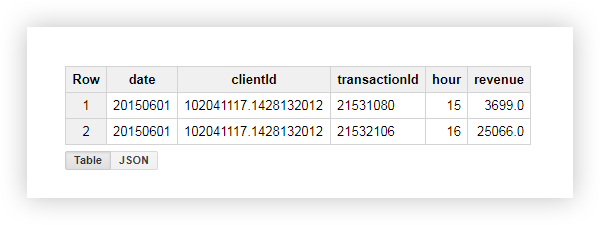
Al aplicar la consulta, recibimos un informe que contiene los ingresos promedio, mínimo, máximo y total de este usuario, así como el número de transacciones. Como puede ver en la captura de pantalla a continuación, el usuario realizó ambas transacciones durante el horario comercial:

Ejemplo 2 . Ahora compliquemos un poco la tarea:
- Pongamos los números de secuencia para todas las transacciones en la ventana, según el momento de su ejecución. Recuerde que definimos la ventana por usuario y tiempo laborable / no laborable.
- Visualicemos los ingresos de la transacción siguiente / anterior (en relación con la actual) dentro de la ventana.
- Visualicemos los ingresos de la primera y última transacción en la ventana.
Para ello utilizamos las siguientes consultas:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
# SQL estándar
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
Comprobemos los resultados del cálculo utilizando el ejemplo de un usuario que ya conocemos con clientId = '102041117.1428132012 ′:

De la captura de pantalla anterior, vemos que:
- La primera transacción fue a las 15:00 y la segunda a las 16:00.
- Después de la transacción actual a las 15:00, hubo una transacción a las 16:00, cuyo ingreso es 25066 (columna lead_revenue).
- Antes de la transacción actual a las 4:00 pm, hubo una transacción a las 3:00 pm con un ingreso de 3699 (columna lag_revenue).
- La primera transacción dentro de la ventana fue una transacción a las 15:00, cuyo ingreso es 3699 (columna first_revenue_by_hour).
- La solicitud procesa los datos línea por línea, por lo tanto, para la transacción en consideración, será la última en la ventana y los valores en las columnas last_revenue_by_hour e ingresos serán los mismos.
conclusiones
En este artículo, hemos cubierto las funciones más populares de las secciones Función agregada, Función de fecha, Función de cadena, Función de ventana. Sin embargo, Google BigQuery tiene muchas más funciones útiles, por ejemplo:
- Funciones de transmisión: le permiten transmitir datos a un formato específico.
- Funciones de comodín de tabla: le permiten acceder a varias tablas desde un conjunto de datos.
- Funciones de expresión regular: le permiten describir el modelo de una consulta de búsqueda y no su valor exacto.
Escriba en los comentarios si tiene sentido escribir con el mismo detalle sobre ellos.