Pero el trabajo de Data Scientist está ligado a los datos, y uno de los momentos más importantes y que requieren más tiempo es procesar los datos antes de enviarlos a una red neuronal o analizarlos de cierta manera.
En este artículo, nuestro equipo describirá cómo puede procesar datos rápida y fácilmente con instrucciones y código paso a paso. Intentamos hacer que el código sea lo suficientemente flexible para que se pueda aplicar en diferentes conjuntos de datos.
Es posible que muchos profesionales no encuentren nada extraordinario en este artículo, pero los principiantes podrán aprender algo nuevo, y cualquiera que haya soñado durante mucho tiempo con hacer un cuaderno separado para un procesamiento de datos rápido y estructurado puede copiar el código y formatearlo por sí mismos, o descargar uno ya hecho. cuaderno de Github.
Tenemos un conjunto de datos. ¿Qué hacer a continuación?
Entonces, el estándar: debe comprender con qué estamos lidiando, el panorama general. Usaremos pandas para esto para simplemente definir diferentes tipos de datos.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 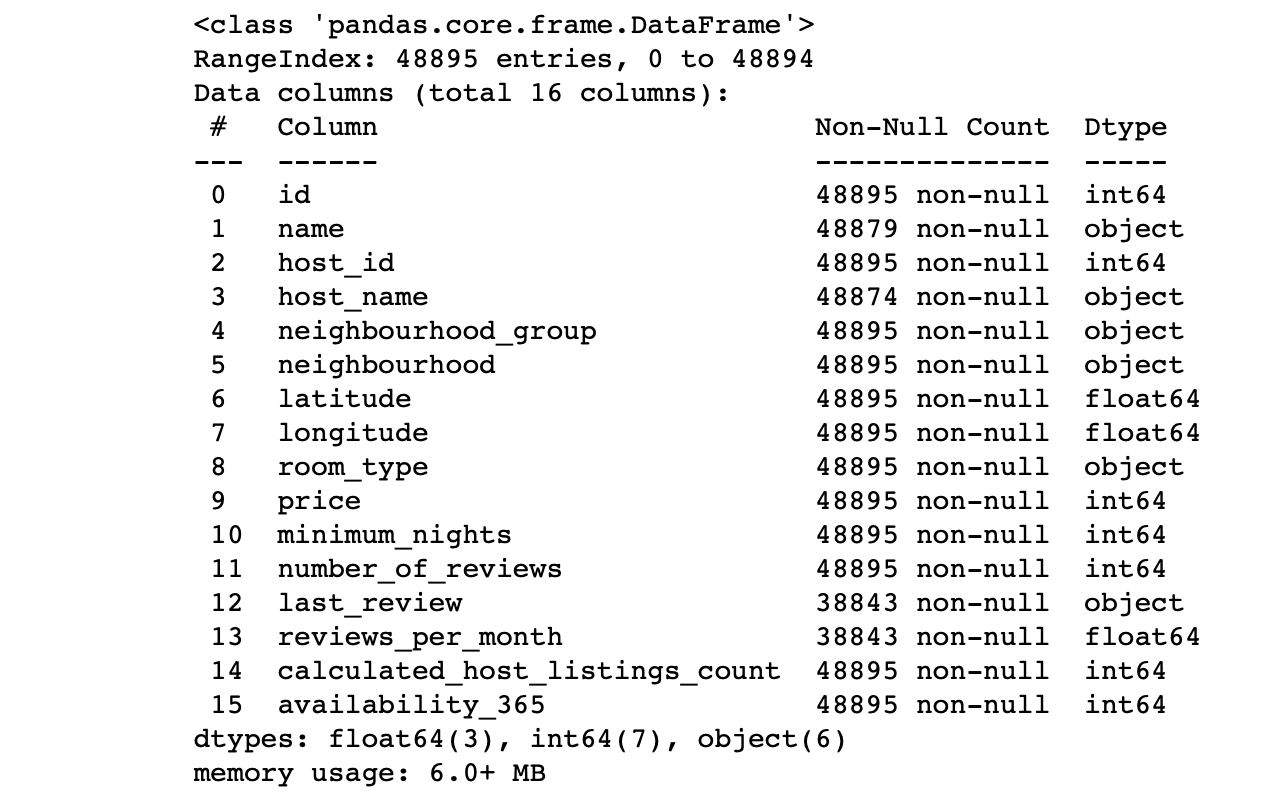
Observamos los valores de las columnas:
- ¿El número de líneas en cada columna corresponde al número total de líneas?
- ¿Cuál es la esencia de los datos de cada columna?
- ¿Para qué columna queremos que el objetivo haga predicciones?
Las respuestas a estas preguntas le permitirán analizar el conjunto de datos y trazar un plan para los próximos pasos.
Además, para una mirada más profunda a los valores en cada columna, podemos usar la función pandas describe (). Sin embargo, la desventaja de esta función es que no proporciona información sobre columnas con valores de cadena. Nos ocuparemos de ellos más tarde.
df.describe()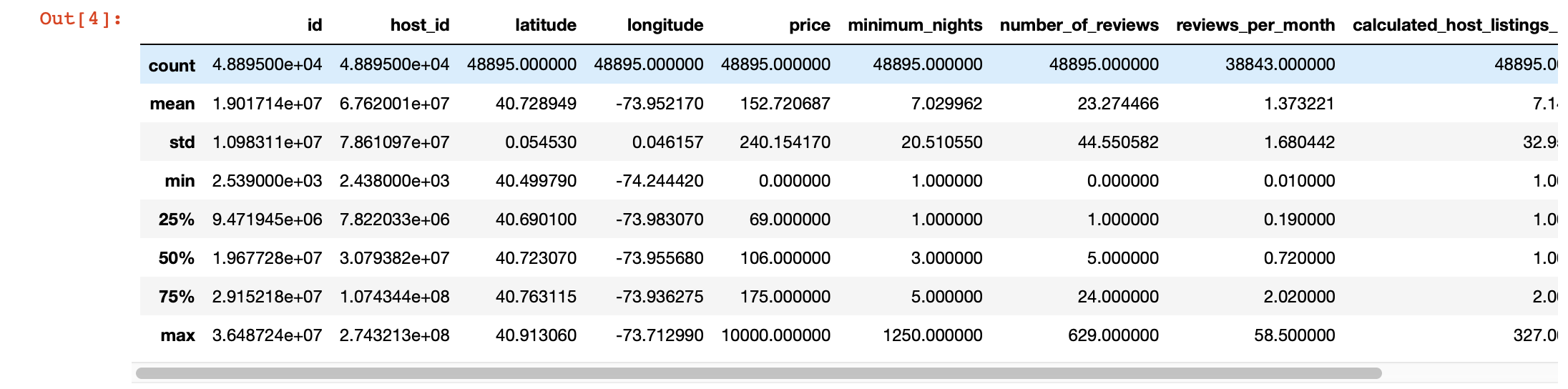
Visualización mágica
Veamos dónde no tenemos ningún valor:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')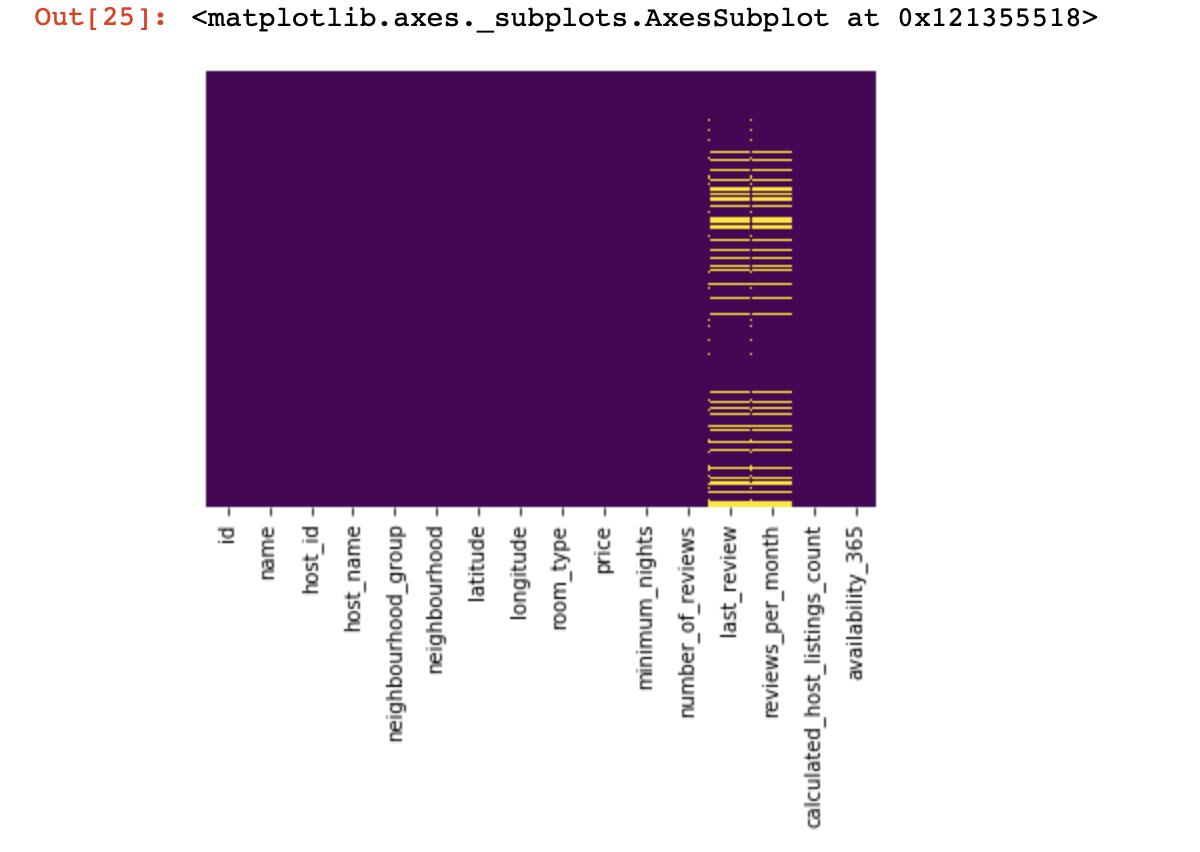
Fue una pequeña mirada desde arriba, ahora pasaremos a cosas más interesantes,
intentemos buscar y, si es posible, eliminar columnas que tengan un solo valor en todas las líneas (no afectarán el resultado de ninguna manera):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , Ahora nos protegemos a nosotros mismos y al éxito de nuestro proyecto de líneas duplicadas (líneas que contienen la misma información en el mismo orden que una de las líneas existentes):
df.drop_duplicates(inplace=True) # , .
# .Dividimos el conjunto de datos en dos: uno con valores cualitativos y el otro con valores cuantitativos
Aquí tenemos que hacer una pequeña aclaración: si las líneas con datos faltantes en datos cualitativos y cuantitativos no se correlacionan fuertemente entre sí, entonces será necesario decidir qué sacrificamos: todas las líneas con datos faltantes, solo una parte de ellas, o ciertas columnas. Si las líneas están relacionadas, entonces tenemos todo el derecho a dividir el conjunto de datos en dos. De lo contrario, primero deberá lidiar con las líneas que no correlacionan los datos faltantes en términos cualitativos y cuantitativos, y solo luego dividir el conjunto de datos en dos.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Hacemos esto para facilitarnos el procesamiento de estos dos tipos diferentes de datos; más adelante entenderemos cuánto más fácil nos hace la vida.
Trabajamos con datos cuantitativos
Lo primero que debemos hacer es determinar si hay "columnas espías" en los datos cuantitativos. Llamamos a estas columnas así porque pretenden ser datos cuantitativos y ellos mismos funcionan como datos cualitativos.
¿Cómo los definimos? Por supuesto, todo depende de la naturaleza de los datos que está analizando, pero en general, estas columnas pueden tener pocos datos únicos (en la región de 3-10 valores únicos).
print(df_numerical.nunique())Después de definir las columnas de espionaje, las pasaremos de datos cuantitativos a cualitativos:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - Finalmente, separamos completamente los datos cuantitativos de los datos cualitativos y ahora puede trabajar con ellos correctamente. La primera es entender dónde tenemos valores vacíos (NaN, y en algunos casos 0 se tomará como valores vacíos).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())En esta etapa, es importante comprender en qué columnas los ceros pueden significar valores perdidos: ¿está esto relacionado con cómo se recopilaron los datos? ¿O podría estar relacionado con los valores de los datos? Estas preguntas deben responderse caso por caso.
Entonces, si a pesar de todo decidimos que es posible que no tengamos datos donde hay ceros, deberíamos reemplazar los ceros con NaN, para que sea más fácil trabajar con estos datos perdidos más adelante:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)Ahora veamos dónde tenemos datos faltantes:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()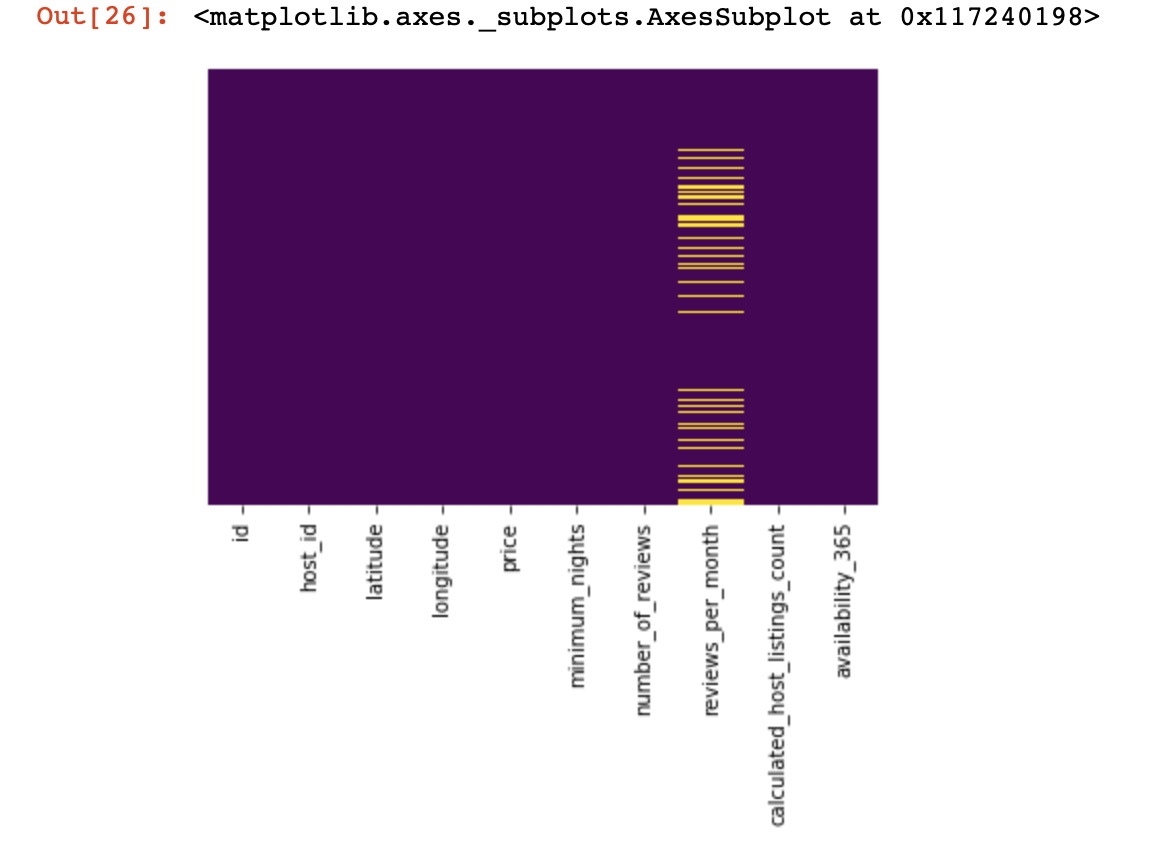
Aquí, los valores dentro de las columnas que faltan deben marcarse en amarillo. Y la diversión comienza ahora, ¿cómo comportarse con estos valores? ¿Eliminar líneas con estos valores o columnas? ¿O llenar estos valores vacíos con algún otro?
A continuación, se muestra un diagrama aproximado que puede ayudarlo a decidir qué puede hacer básicamente con valores vacíos:
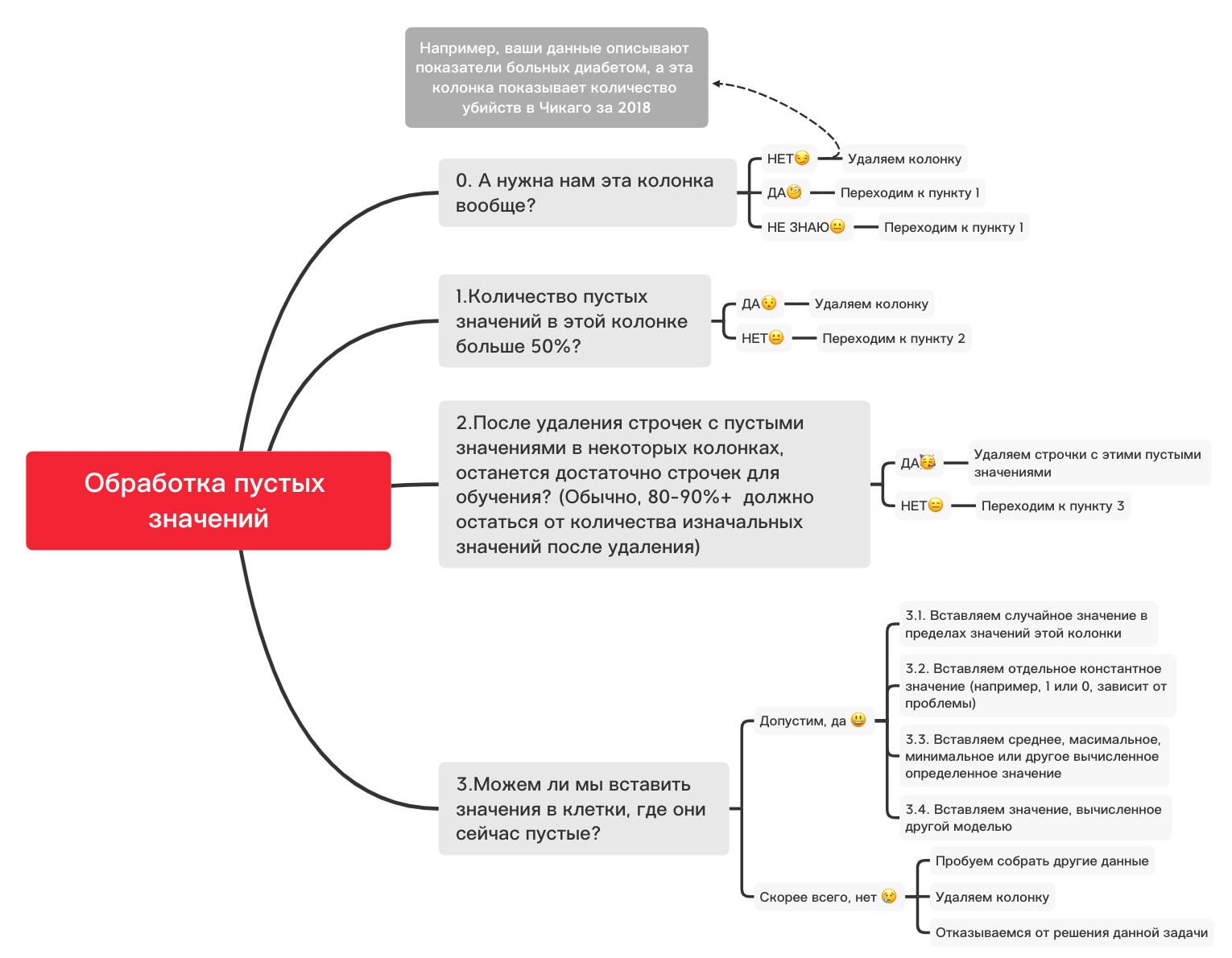
0. Eliminar columnas innecesarias
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. ¿Hay más del 50% de valores en blanco en esta columna?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. Eliminar líneas con valores vacíos
df_numerical.dropna(inplace=True)# , 3.1. Insertar un valor aleatorio
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2. Insertar valor constante
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3. Inserte el valor promedio o más frecuente
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. Insertar un valor calculado por otro modelo
A veces, los valores se pueden calcular usando modelos de regresión usando modelos de la biblioteca sklearn u otras bibliotecas similares. Nuestro equipo dedicará un artículo separado sobre cómo se puede hacer esto en un futuro próximo.
Entonces, si bien la narrativa sobre datos cuantitativos se interrumpirá, porque hay muchos otros matices sobre cómo hacer mejor la preparación y el preprocesamiento de datos para diferentes tareas, y en este artículo se han tenido en cuenta las cosas básicas para los datos cuantitativos, y ahora es el momento de volver a los datos cualitativos. que hemos separado unos pasos hacia atrás de lo cuantitativo. Puede cambiar este portátil como desee, ajustándolo para diferentes tareas, de modo que el preprocesamiento de datos sea muy rápido.
Datos cualitativos
Básicamente, para datos de calidad, se utiliza el método de codificación One-hot-encoding para formatearlos de una cadena (u objeto) a un número. Antes de pasar a este punto, usemos el diagrama y el código de arriba para tratar con valores vacíos.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')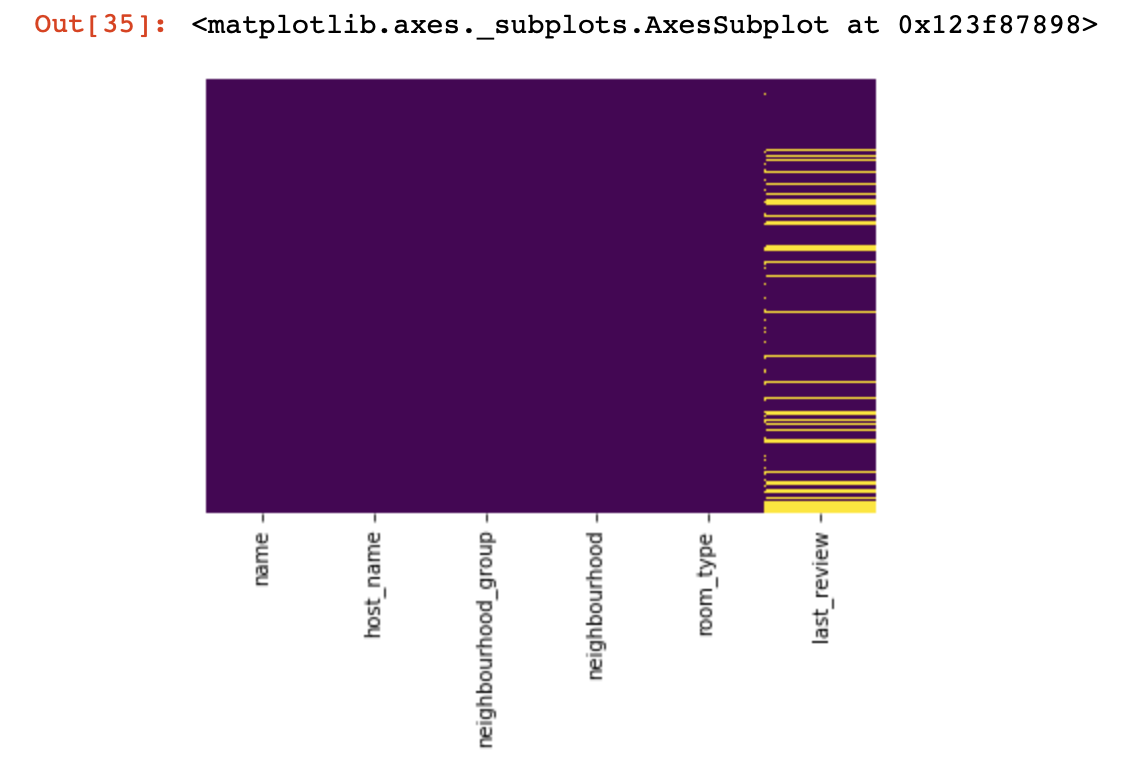
0. Eliminar columnas innecesarias
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. ¿Hay más del 50% de valores en blanco en esta columna?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. Eliminar líneas con valores vacíos
df_categorical.dropna(inplace=True)# ,
# 3.1. Insertar un valor aleatorio
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2. Insertar valor constante
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)Entonces, finalmente, nos hemos ocupado de los valores vacíos en los datos de calidad. Ahora es el momento de codificar en caliente los valores que están en su base de datos. Este método se usa con mucha frecuencia para que su algoritmo pueda entrenar con buenos datos.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Entonces, finalmente hemos terminado de procesar datos cualitativos y cuantitativos por separado; es hora de volver a combinarlos
new_df = pd.concat([df_numerical,df_categorical], axis=1)Después de haber fusionado los conjuntos de datos en uno, al final podemos usar la transformación de datos usando MinMaxScaler de la biblioteca sklearn. Esto hará que nuestros valores oscilen entre 0 y 1, lo que ayudará a la hora de entrenar el modelo en el futuro.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Estos datos ahora están listos para cualquier cosa: para redes neuronales, algoritmos ML estándar, etc.
En este artículo, no tomamos en cuenta el trabajo con datos relacionados con series de tiempo, ya que para tales datos se deben utilizar técnicas de procesamiento ligeramente diferentes, dependiendo de su tarea. En el futuro, nuestro equipo dedicará un artículo separado a este tema y esperamos que pueda traer algo interesante, nuevo y útil a su vida, como éste.