
Introducción
Google Dorks o Google Hacking es una técnica utilizada por los medios, investigadores, ingenieros de seguridad y cualquier otra persona para consultar varios motores de búsqueda para descubrir información oculta y vulnerabilidades que se pueden encontrar en servidores públicos. Es una técnica en la que las consultas de búsqueda de sitios web convencionales se utilizan en su mayor medida para determinar la información oculta en la superficie.
¿Cómo funciona Google Dorking?
Este ejemplo de recopilación y análisis de información, que actúa como una herramienta OSINT, no es una vulnerabilidad de Google ni un dispositivo para piratear el alojamiento de sitios web. Por el contrario, actúa como un proceso de recuperación de datos convencional con capacidades avanzadas. Esto no es nuevo, ya que hay una gran cantidad de sitios web que tienen más de una década y sirven como repositorios para explorar y usar Google Hacking.
Mientras que los motores de búsqueda indexan, almacenan encabezados y contenido de la página, y los vinculan para obtener consultas de búsqueda óptimas. Pero desafortunadamente, las arañas web de cualquier motor de búsqueda están configuradas para indexar absolutamente toda la información encontrada. Aunque los administradores de los recursos web no tenían intención de publicar este material.
Sin embargo, lo más interesante de Google Dorking es la enorme cantidad de información que puede ayudar a todos en el proceso de aprendizaje del proceso de búsqueda de Google. Puede ayudar a los recién llegados a encontrar parientes desaparecidos o puede enseñarles cómo extraer información para su propio beneficio. En general, cada recurso es interesante y sorprendente a su manera y puede ayudar a todos en lo que buscan exactamente.
¿Qué información puedo encontrar a través de Dorks?
Desde controladores de acceso remoto de varias máquinas de fábrica hasta interfaces de configuración de sistemas críticos. Se supone que nadie encontrará nunca una gran cantidad de información publicada en la red.
Sin embargo, veámoslo en orden. Imagínese una nueva cámara de CCTV que le permite verla en vivo en su teléfono cuando lo desee. Lo configura y se conecta a través de Wi-Fi, y descarga la aplicación para autenticar el inicio de sesión de la cámara de seguridad. Después de eso, puede acceder a la misma cámara desde cualquier parte del mundo.
En el fondo, no todo parece tan simple. La cámara envía una solicitud al servidor chino y reproduce el video en tiempo real, lo que le permite iniciar sesión y abrir la transmisión de video alojada en el servidor en China desde su teléfono. Es posible que este servidor no requiera una contraseña para acceder a la transmisión desde su cámara web, por lo que está disponible públicamente para cualquiera que busque el texto contenido en la página de vista de la cámara.
Y, desafortunadamente, Google es despiadadamente eficiente para encontrar cualquier dispositivo en Internet que se ejecute en servidores HTTP y HTTPS. Y dado que la mayoría de estos dispositivos contienen algún tipo de plataforma web para personalizarlos, esto significa que muchas cosas que no estaban destinadas a estar en Google terminan ahí.
Con mucho, el tipo de archivo más serio es el que lleva las credenciales de los usuarios o de toda la empresa. Esto suele ocurrir de dos formas. En el primero, el servidor está configurado incorrectamente y expone sus registros administrativos o registros al público en Internet. Cuando se cambian las contraseñas o el usuario no puede iniciar sesión, estos archivos pueden filtrarse junto con las credenciales.
La segunda opción ocurre cuando los archivos de configuración que contienen la misma información (inicios de sesión, contraseñas, nombres de bases de datos, etc.) están disponibles públicamente. Estos archivos deben estar ocultos a cualquier acceso público, ya que a menudo dejan información importante. Cualquiera de estos errores puede llevar a un atacante a encontrar estas lagunas y obtener toda la información que necesita.
Este artículo ilustra el uso de Google Dorks para mostrar no solo cómo encontrar todos estos archivos, sino también cuán vulnerables pueden ser las plataformas que contienen información en forma de una lista de direcciones, correo electrónico, imágenes e incluso una lista de cámaras web disponibles públicamente.
Analizar operadores de búsqueda
Dorking se puede utilizar en varios motores de búsqueda, no solo en Google. En el uso diario, los motores de búsqueda como Google, Bing, Yahoo y DuckDuckGo toman una consulta de búsqueda o una cadena de búsqueda y devuelven resultados relevantes. Además, estos mismos sistemas están programados para aceptar operadores más avanzados y complejos que reducen en gran medida estos términos de búsqueda. Un operador es una palabra clave o frase que tiene un significado especial para un motor de búsqueda. Algunos ejemplos de operadores de uso común son: "inurl", "intext", "site", "feed", "language". Cada operador va seguido de dos puntos, seguidos de la frase o frases clave correspondientes.
Estos operadores le permiten buscar información más específica, como líneas específicas de texto dentro de las páginas de un sitio web o archivos alojados en una URL específica. Entre otras cosas, Google Dorking también puede encontrar páginas de inicio de sesión ocultas, mensajes de error que muestran información sobre vulnerabilidades disponibles y archivos compartidos. La razón principal es que el administrador del sitio web simplemente se olvidó de excluir del acceso público.
El servicio de Google más práctico y al mismo tiempo interesante es la capacidad de buscar páginas eliminadas o archivadas. Esto se puede hacer usando el operador "cache:". El operador trabaja de tal manera que muestra la versión guardada (eliminada) de la página web almacenada en la caché de Google. La sintaxis de este operador se muestra aquí:
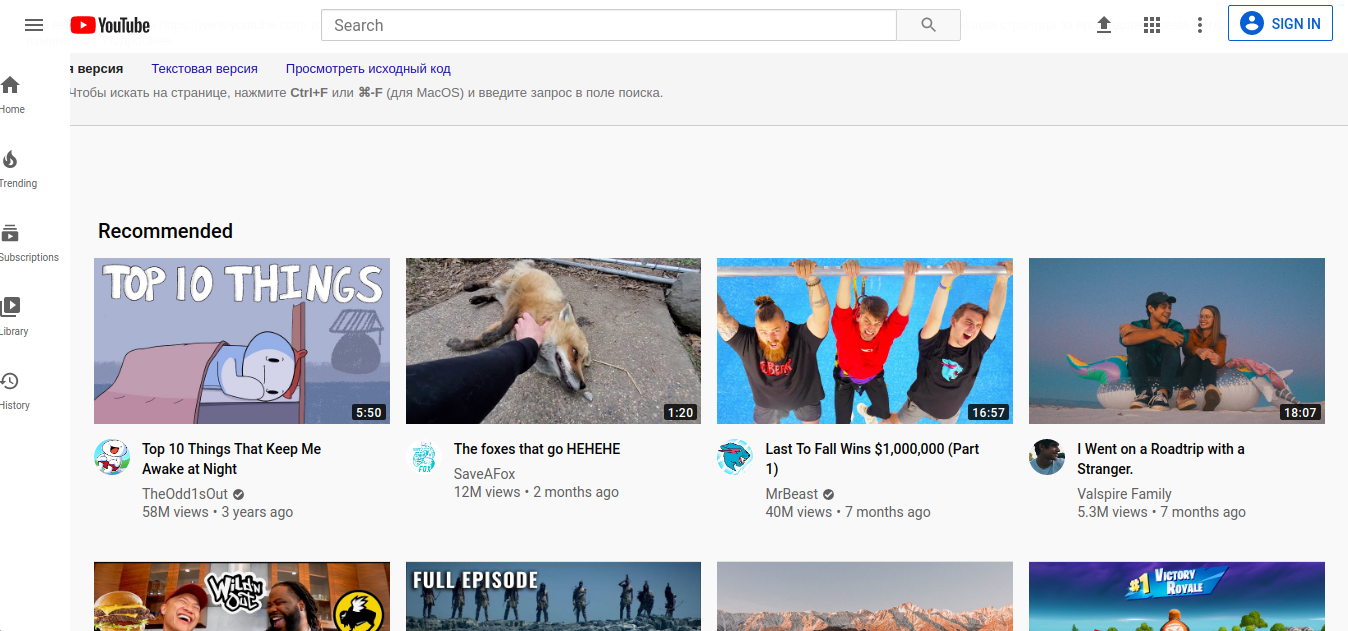
caché: www.youtube.com
Después de realizar la solicitud anterior a Google, se proporciona acceso a la versión anterior o desactualizada de la página web de Youtube. El comando le permite llamar a la versión completa de la página, la versión de texto o la fuente de la página en sí (código completo). También se indica la hora exacta (fecha, hora, minuto, segundo) de la indexación realizada por la araña de Google. La página se muestra en forma de archivo gráfico, aunque la búsqueda dentro de la propia página se realiza de la misma forma que en una página HTML normal (atajo de teclado CTRL + F). Los resultados del comando "cache:" dependen de la frecuencia con la que Google haya indexado la página web. Si el propio desarrollador establece el indicador con una cierta frecuencia de visitas en el encabezado del documento HTML, entonces Google reconoce la página como secundaria y generalmente la ignora a favor del ratio PageRank.que es el factor principal en la frecuencia de indexación de páginas. Por lo tanto, si el rastreador de Google ha modificado una página web en particular entre visitas, no se indexará ni se leerá mediante el comando "cache:". Algunos ejemplos que funcionan especialmente bien al probar esta función son blogs, cuentas de redes sociales y portales en línea que se actualizan con frecuencia.
La información eliminada o los datos que se colocaron por error o que deben eliminarse en algún momento se pueden recuperar muy fácilmente. La negligencia del administrador de la plataforma web puede ponerlo en riesgo de difundir información no deseada.
Informacion del usuario
La búsqueda de información del usuario se utiliza mediante operadores avanzados, que hacen que los resultados de la búsqueda sean precisos y detallados. El operador "@" se utiliza para buscar usuarios indexados en las redes sociales: Twitter, Facebook, Instagram. Usando el ejemplo de la misma universidad polaca, puede encontrar a su representante oficial, en una de las plataformas sociales, usando este operador de la siguiente manera:
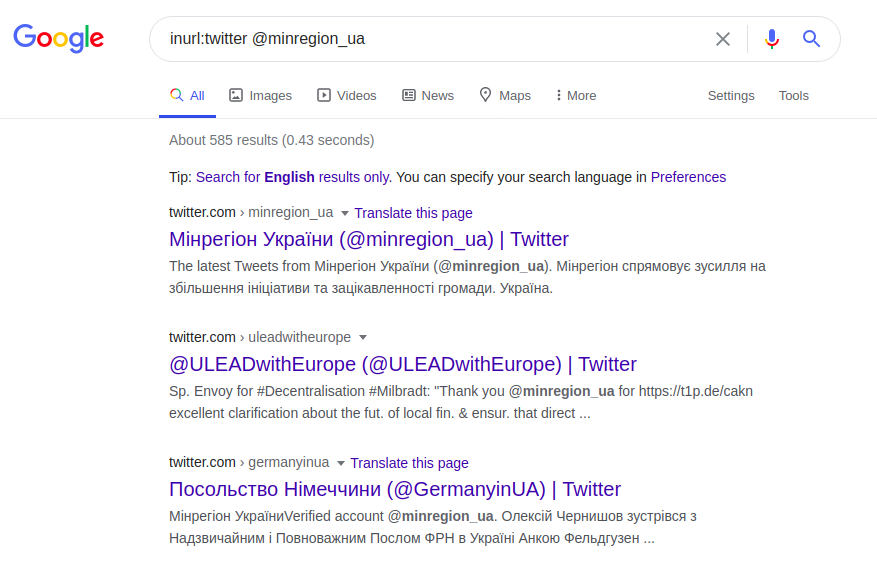
inurl: twitter @minregion_ua
Esta solicitud de Twitter encuentra al usuario "minregion_ua". Suponiendo que se conozca el lugar o nombre de la obra del usuario que estamos buscando (Ministerio de Desarrollo de Comunidades y Territorios de Ucrania) y su nombre, podemos realizar una solicitud más concreta. Y en lugar de tener que buscar tediosamente en toda la página web de la institución, puede realizar la consulta correcta en función de la dirección de correo electrónico y asumir que el nombre de la dirección debe incluir al menos el nombre del usuario o institución solicitada. Por ejemplo:
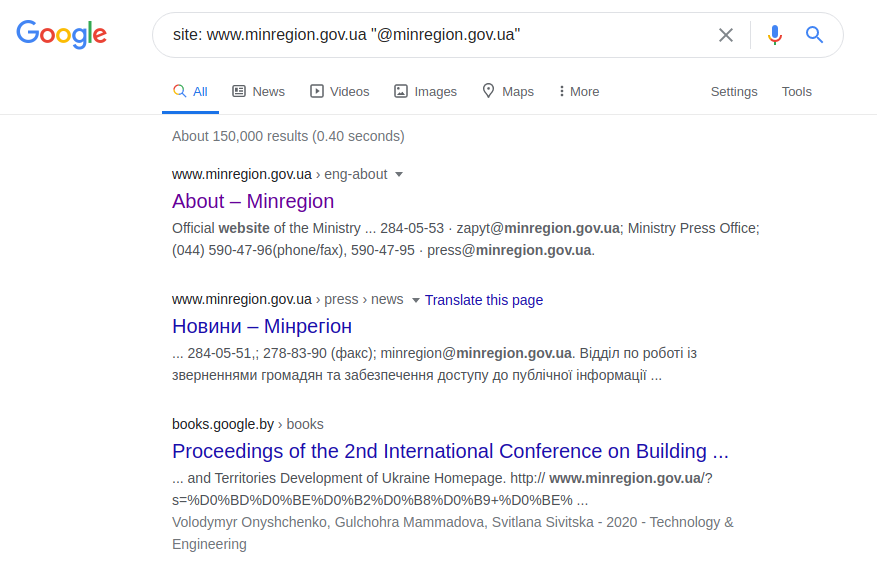
sitio: www.minregion.gov.ua "@ minregion.ua"
También puede utilizar un método menos complicado y enviar una solicitud solo a direcciones de correo electrónico, como se muestra a continuación, con la esperanza de suerte y falta de profesionalismo del administrador de recursos web.
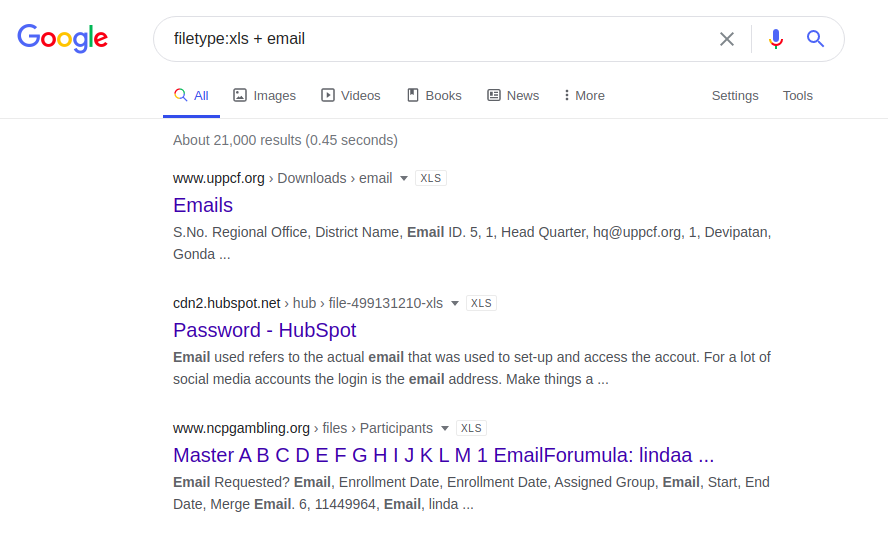
email.xlsx filetype
: xls + email
Además, puede intentar obtener direcciones de correo electrónico de una página web con la siguiente solicitud:

sitio: www.minregion.gov.ua intext: correo electrónico
La consulta anterior buscará la palabra clave "correo electrónico" en la página web del Ministerio para el Desarrollo de Comunidades y Territorios de Ucrania. Encontrar direcciones de correo electrónico tiene un uso limitado y generalmente requiere poca preparación y recopilación de información del usuario por adelantado.
Desafortunadamente, la búsqueda de números de teléfono indexados a través de la agenda de Google se limita a los Estados Unidos únicamente. Por ejemplo:
directorio telefónico: Arthur Mobile AL La
búsqueda de información del usuario también es posible a través de la "búsqueda de imágenes" de Google o la búsqueda inversa de imágenes. Esto le permite encontrar fotos idénticas o similares en sitios indexados por Google.
Información de recursos web
Google tiene varios operadores útiles, en particular "relacionados:", que muestra una lista de sitios web "similares" al deseado. La similitud se basa en vínculos funcionales, no vínculos lógicos o significativos.
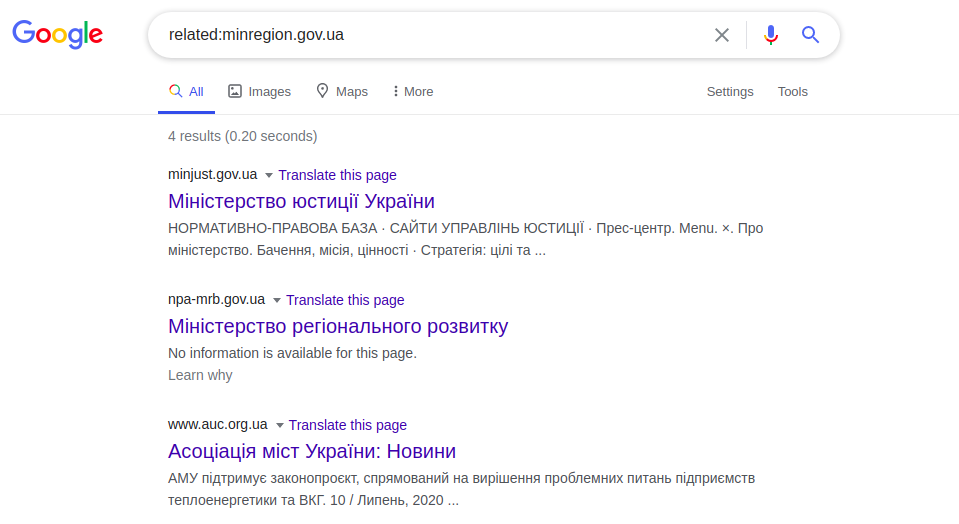
relacionado: minregion.gov.ua
Este ejemplo muestra páginas de otros Ministerios de Ucrania. Este operador funciona como el botón "Páginas relacionadas" en las búsquedas avanzadas de Google. De la misma forma funciona la solicitud “info:”, que muestra información en una página web específica. Esta es la información específica de la página web presentada en el título del sitio web (), es decir, en las etiquetas de meta descripción (<meta name = “Description”). Ejemplo:

info: minregion.gov.ua
Otra consulta, "define:", es bastante útil para encontrar trabajos científicos. Le permite obtener definiciones de palabras de fuentes como enciclopedias y diccionarios en línea. Un ejemplo de su aplicación:
definir: territorios de Ucrania El
operador universal - tilde ("~"), le permite buscar palabras o sinónimos similares:
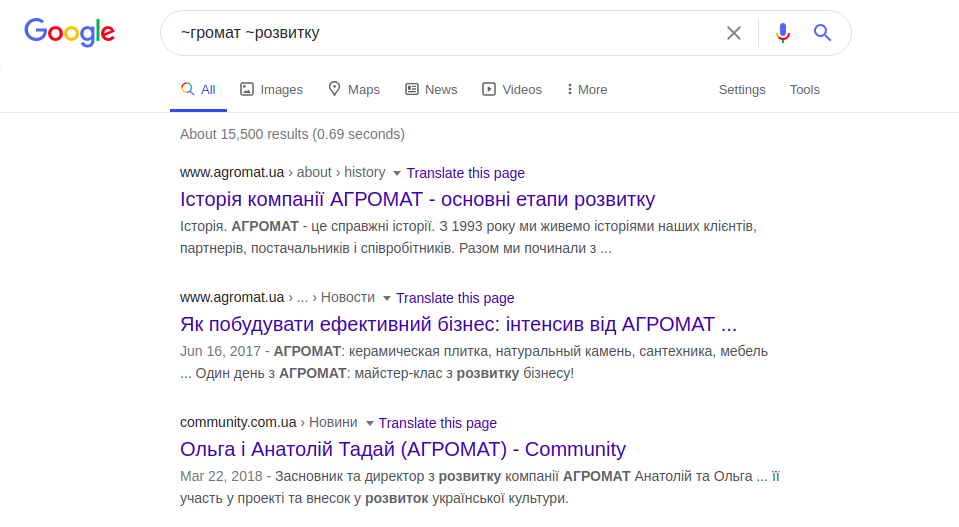
~ comunidades ~ desarrollo
La consulta anterior muestra sitios web con las palabras "comunidades" (territorios) y "desarrollo" (desarrollo), y sitios web con el sinónimo "comunidades". El operador "enlace:", que modifica la consulta, limita el rango de búsqueda a los enlaces especificados para una página específica.
enlace: www.minregion.gov.ua
Sin embargo, este operador no muestra todos los resultados y no expande los criterios de búsqueda.
Los hashtags son una especie de números de identificación que te permiten agrupar información. Actualmente se utilizan en Instagram, VK, Facebook, Tumblr y TikTok. Google te permite buscar en muchas redes sociales al mismo tiempo o solo en las recomendadas. Un ejemplo de una consulta típica para cualquier motor de búsqueda es:
# polyticavukrainі
El operador "AROUND (n)" le permite buscar dos palabras ubicadas a una distancia de un cierto número de palabras entre sí. Ejemplo:

Ministerio de AROUND (4) de Ucrania
El resultado de la consulta anterior es mostrar sitios web que contienen estas dos palabras ("ministerio" y "Ucrania"), pero están separados entre sí por otras cuatro palabras.
La búsqueda por tipo de archivo también es muy útil, ya que Google indexa el contenido según el formato en el que se grabó. Para hacer esto, use el operador "filetype:". Existe una amplia gama de búsquedas de archivos actualmente en uso. De todos los motores de búsqueda disponibles, Google proporciona el conjunto de operadores más sofisticado para buscar código abierto.
Como alternativa a los operadores antes mencionados, se recomiendan herramientas como Maltego y Oryon OSINT Browser. Proporcionan recuperación automática de datos y no requieren el conocimiento de operadores especiales. El mecanismo de los programas es muy sencillo: utilizando la consulta correcta enviada a Google o Bing, se encuentran los documentos publicados por la institución de su interés y se analizan los metadatos de estos documentos. Un recurso de información potencial para dichos programas es cada archivo con cualquier extensión, por ejemplo: ".doc", ".pdf", ".ppt", ".odt", ".xls" o ".jpg".
Además, hay que decir cómo cuidar adecuadamente de "limpiar sus metadatos" antes de hacer públicos los archivos. Algunas guías web ofrecen al menos varias formas de deshacerse de la metainformación. Sin embargo, es imposible deducir la mejor manera, porque todo depende de las preferencias individuales del propio administrador. Por lo general, se recomienda escribir los archivos en un formato que no almacene metadatos de forma nativa y luego hacer que los archivos estén disponibles. Existen numerosos programas gratuitos de limpieza de metadatos en Internet, principalmente para imágenes. ExifCleaner puede considerarse como uno de los más deseables. En el caso de los archivos de texto, se recomienda encarecidamente que los limpie manualmente.
Información dejada sin saberlo por los propietarios del sitio
Los recursos indexados por Google siguen siendo públicos (por ejemplo, documentos internos y materiales de la empresa que se dejan en el servidor), o los dejan las mismas personas para su conveniencia (por ejemplo, archivos de música o películas). La búsqueda de dicho contenido se puede realizar con Google de muchas formas diferentes, y la más fácil es adivinar. Si, por ejemplo, hay archivos 5.jpg, 8.jpg y 9.jpg en un directorio determinado, puede predecir que hay archivos del 1 al 4, del 6 al 7 e incluso más 9. Por lo tanto, puede acceder a materiales que no deberían iban a estar en público. Otra forma es buscar tipos específicos de contenido en sitios web. Puede buscar archivos de música, fotos, películas y libros (libros electrónicos, audiolibros).
En otro caso, pueden ser archivos que el usuario ha dejado sin saberlo en el dominio público (por ejemplo, música en un servidor FTP para su propio uso). Esta información se puede obtener de dos formas: utilizando el operador "filetype:" o el operador "inurl:". Por ejemplo:
tipo de archivo: doc sitio: gov.ua
sitio: www.minregion.gov.ua tipo de archivo: pdf
sitio: www.minregion.gov.ua inurl: doc
También puede buscar archivos de programa utilizando una consulta de búsqueda y filtrando el archivo deseado por su extensión:
tipo de archivo: iso
Información sobre la estructura de las páginas web
Para ver la estructura de una página web en particular y revelar su estructura completa, lo que ayudará al servidor y sus vulnerabilidades en el futuro, puede hacerlo utilizando solo el operador "site:". Analicemos la siguiente frase:
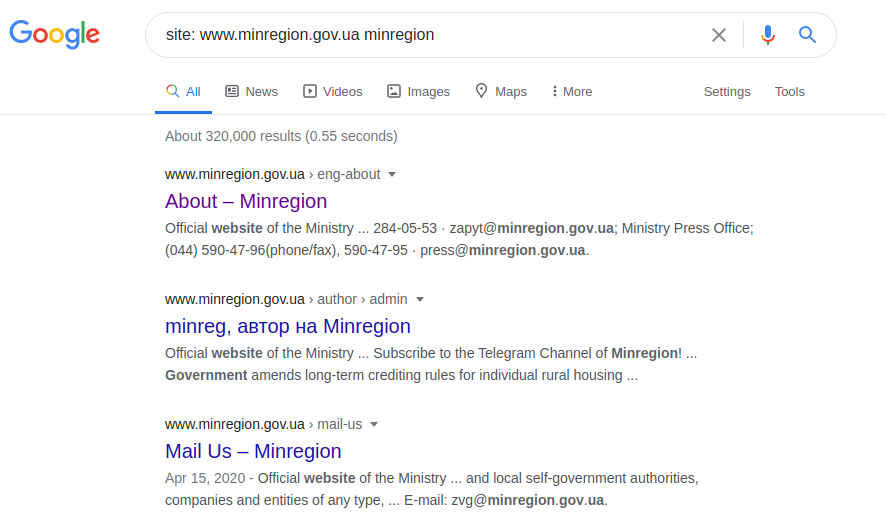
sitio: www.minregion.gov.ua minregion
Comenzamos a buscar la palabra “minregion” en el dominio “www.minregion.gov.ua”. Todos los sitios de este dominio (búsquedas de Google tanto en texto como en encabezados y en el título del sitio) contienen esta palabra. Por lo tanto, obtener la estructura completa de todos los sitios para ese dominio en particular. Una vez que la estructura del directorio está disponible, se puede obtener un resultado más preciso (aunque esto no siempre suceda) con la siguiente consulta:
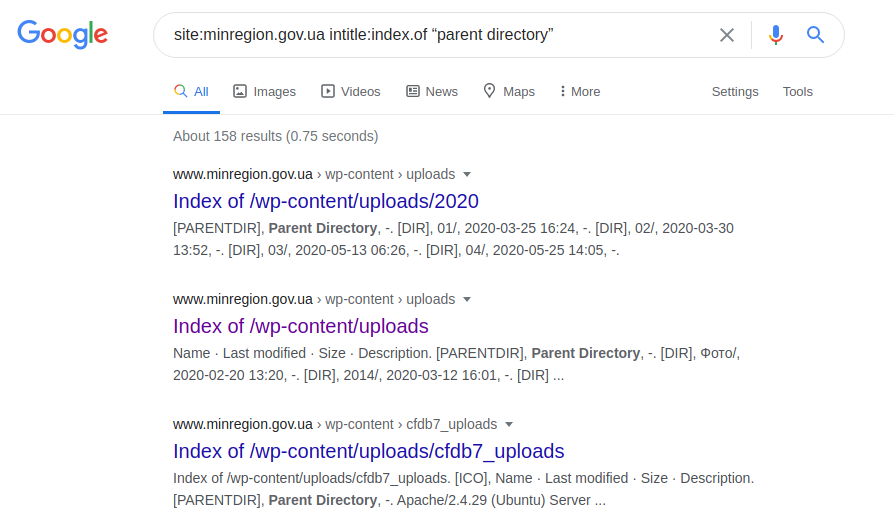
site: minregion.gov.ua intitle: index.of "directorio principal"
Muestra los subdominios menos protegidos de "minregion.gov.ua", a veces con la capacidad de buscar en todo el directorio, junto con posibles cargas de archivos. Por lo tanto, naturalmente, tal solicitud no es aplicable a todos los dominios, ya que pueden protegerse o ejecutarse bajo el control de algún otro servidor.
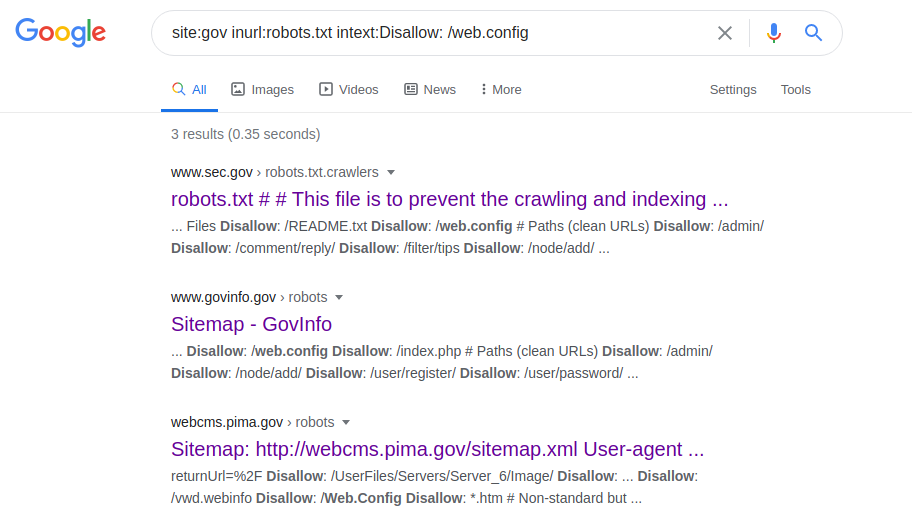
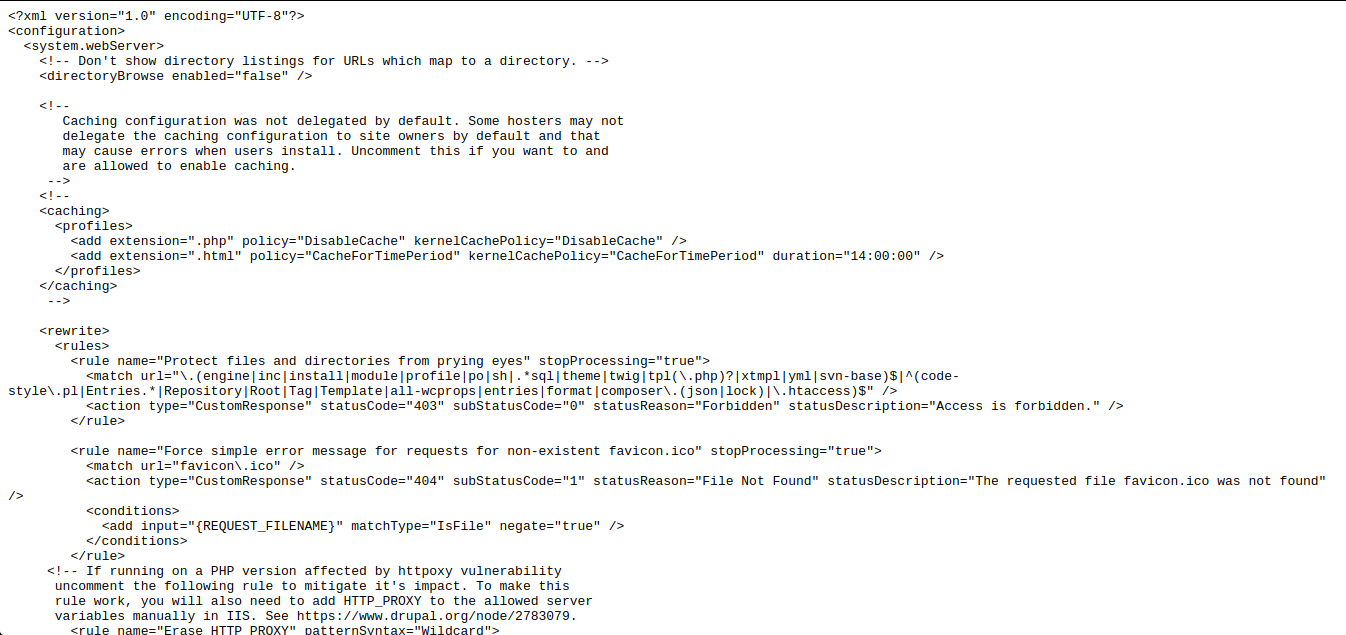
site: gov inurl: robots.txt intext: Disallow: /web.config
Este operador le permite acceder a los parámetros de configuración de varios servidores. Después de realizar la solicitud, vaya al archivo robots.txt, busque la ruta a "web.config" y vaya a la ruta del archivo especificado. Para obtener el nombre del servidor, su versión y otros parámetros (por ejemplo, puertos), se realiza la siguiente solicitud:
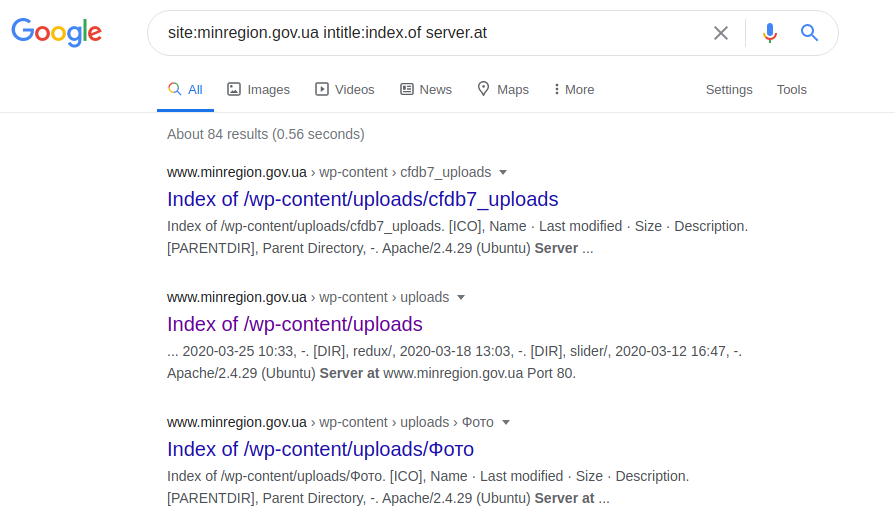
site: gosstandart.gov.by intitle: index.of server.at
Cada servidor tiene algunas frases únicas en sus páginas de inicio, por ejemplo, Internet Information Service (IIS):
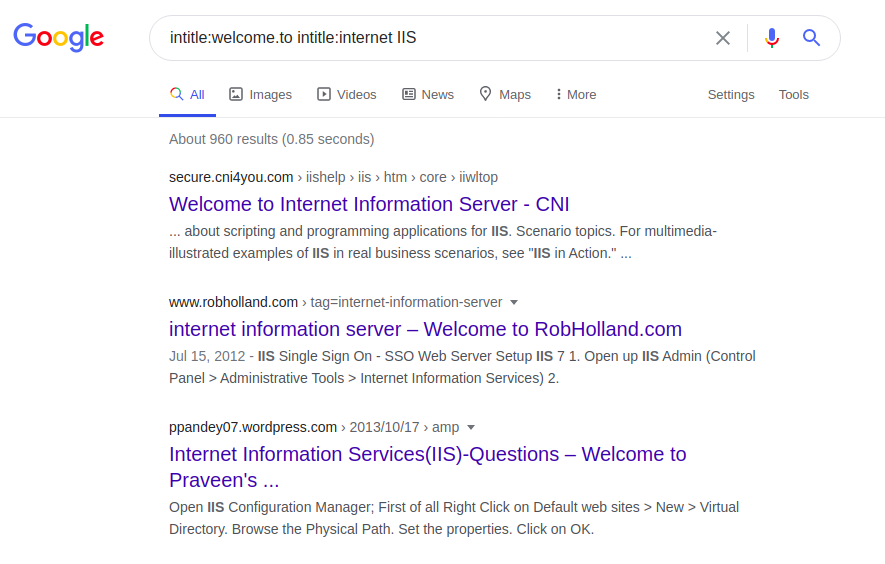
intitle: welcome.to intitle: internet IIS
La definición del servidor en sí y las tecnologías utilizadas en él dependen únicamente del ingenio de la consulta que se está realizando. Por ejemplo, puede intentar hacer esto aclarando una especificación técnica, un manual o las llamadas páginas de ayuda. Para demostrar esta capacidad, puede utilizar la siguiente consulta:
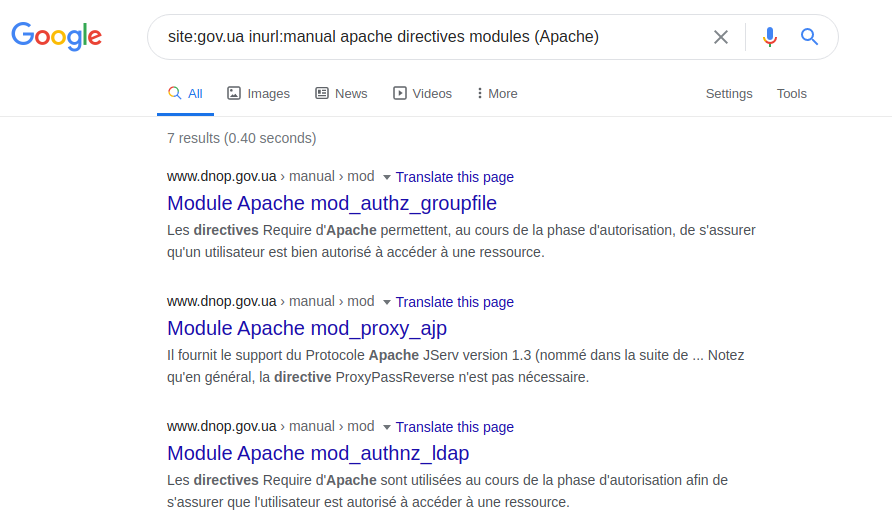
site: gov.ua inurl: módulos manuales de directivas apache (Apache) El
acceso se puede ampliar, por ejemplo, gracias al archivo con errores SQL:
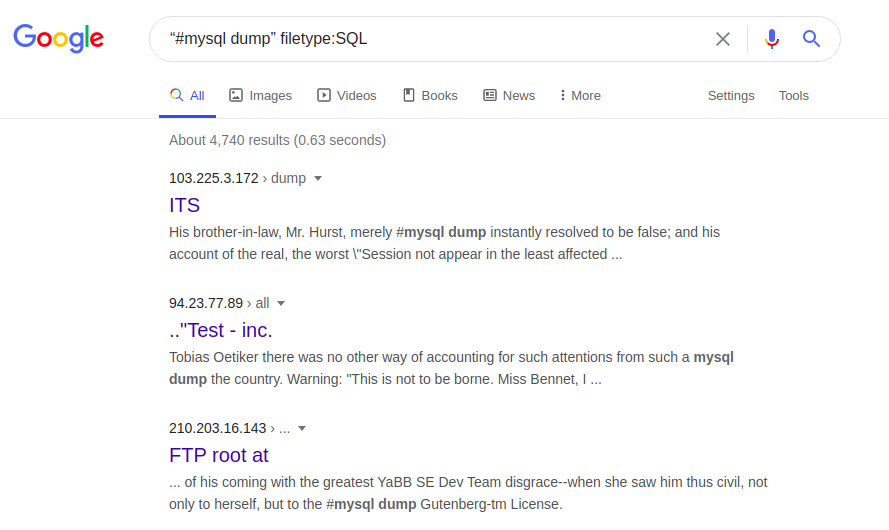
Tipo de archivo "#Mysql dump": Los
errores de SQL en una base de datos SQL pueden, en particular, proporcionar información sobre la estructura y el contenido de las bases de datos. A su vez, se puede acceder a toda la página web, su original y / o sus versiones actualizadas mediante la siguiente solicitud:
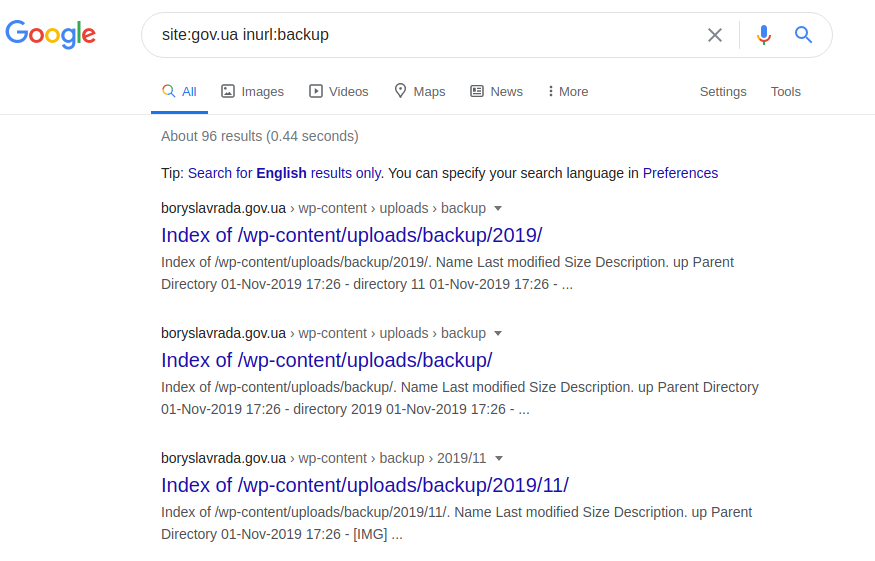
site: gov.ua inurl: backup
site: gov.ua inurl: backup intitle: index.of inurl: admin
Actualmente, el uso de los operadores anteriores rara vez da los resultados esperados, ya que pueden ser bloqueados con anticipación por usuarios expertos.
Además, al usar el programa FOCA, puede encontrar el mismo contenido que cuando busca los operadores anteriores. Para comenzar, el programa necesita el nombre del nombre de dominio, luego de lo cual analizará la estructura de todo el dominio y todos los demás subdominios conectados a los servidores de una institución en particular. Esta información se puede encontrar en el cuadro de diálogo en la pestaña Red:
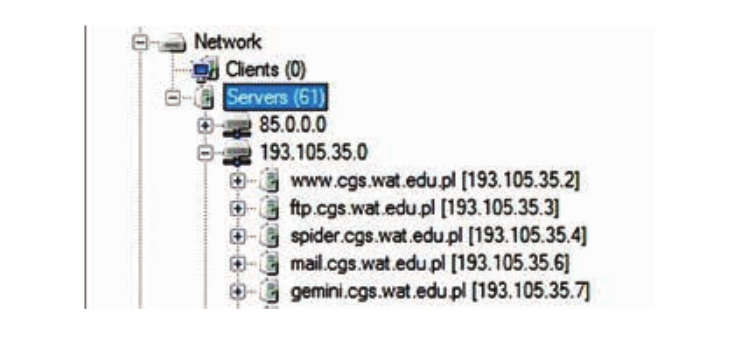
Por lo tanto, un atacante potencial puede interceptar los datos que dejan los administradores web, los documentos internos y los materiales de la empresa que se encuentran incluso en un servidor oculto.
Si desea conocer aún más información sobre todos los posibles operadores de indexación, puede consultar la base de datos de destino de todos los operadores de Google Dorking aquí . También puede familiarizarse con un proyecto interesante en GitHub, que ha recopilado todos los enlaces de URL más comunes y vulnerables e intentar buscar algo interesante para usted, puede verlo aquí en este enlace .
Combinar y obtener resultados
Para obtener ejemplos más específicos, a continuación se muestra una pequeña colección de operadores de Google de uso común. En una combinación de diversa información adicional y los mismos comandos, los resultados de la búsqueda muestran una visión más detallada del proceso de obtención de información confidencial. Después de todo, para un motor de búsqueda habitual de Google, este proceso de recopilación de información puede resultar bastante interesante.
Busque presupuestos en el sitio web del Departamento de Seguridad Nacional y Ciberseguridad de EE. UU.
La siguiente combinación proporciona todas las hojas de cálculo de Excel indexadas públicamente que contienen la palabra "presupuesto":
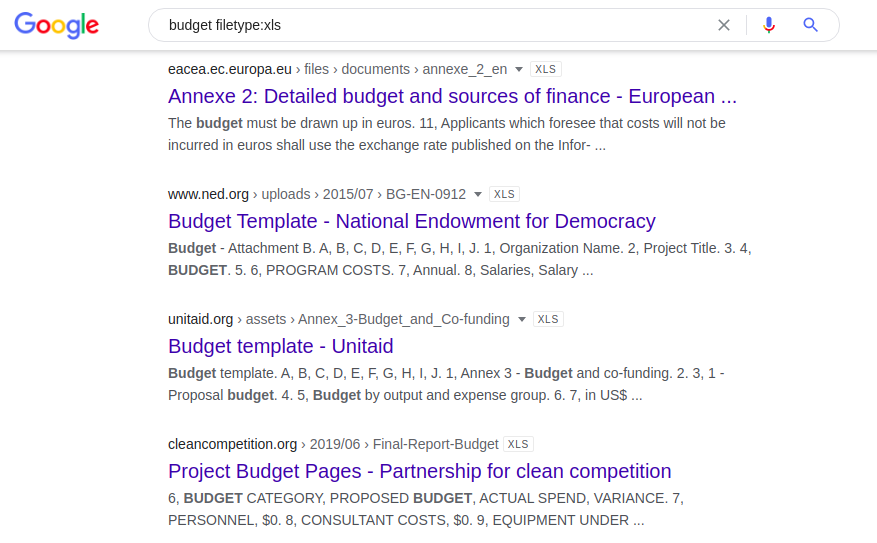
budget filetype: xls
Dado que el operador "filetype:" no reconoce automáticamente diferentes versiones del mismo formato de archivo (p. ej., doc frente a odt o xlsx frente a csv), cada uno de estos formatos debe dividirse por separado:
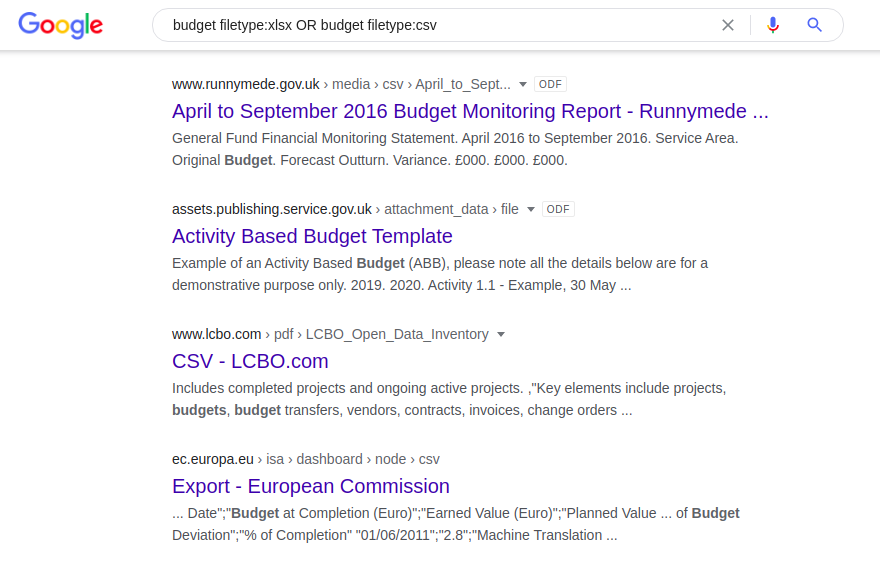
tipo de archivo de presupuesto: xlsx O tipo de archivo de presupuesto: csv El
siguiente dork devolverá archivos PDF en el sitio web de la NASA:
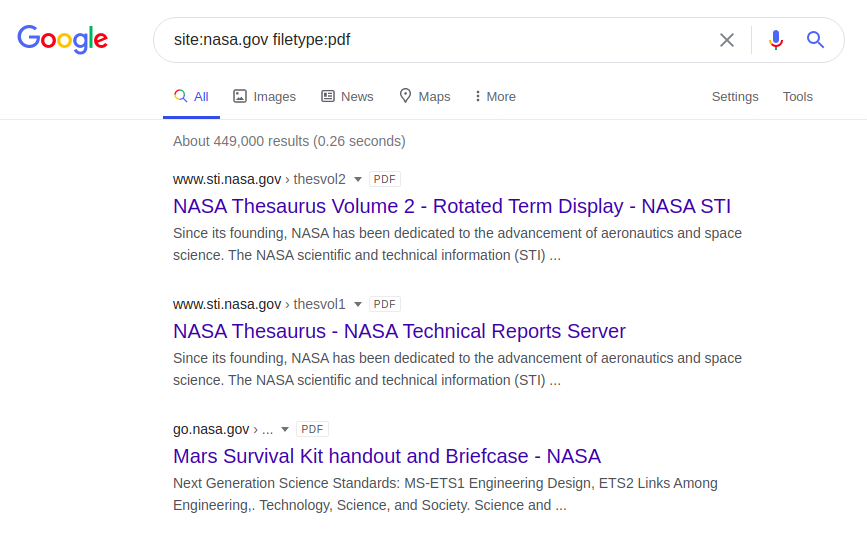
site: nasa.gov filetype: pdf
Otro ejemplo interesante del uso de un idiota con la palabra clave "presupuesto" es la búsqueda de documentos de ciberseguridad de EE. UU. en formato "pdf" en el sitio web oficial del Departamento de Defensa Nacional.
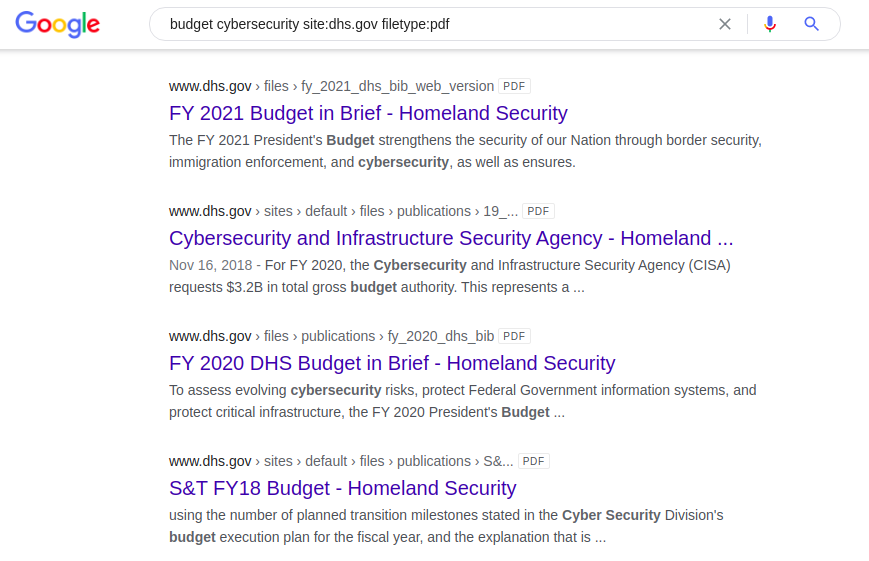
sitio de ciberseguridad de presupuesto: dhs.gov tipo de archivo: pdf La
misma aplicación tonta , pero esta vez el motor de búsqueda devolverá hojas de cálculo .xlsx que contienen la palabra "presupuesto" en el sitio web del Departamento de Seguridad Nacional de EE. UU.:
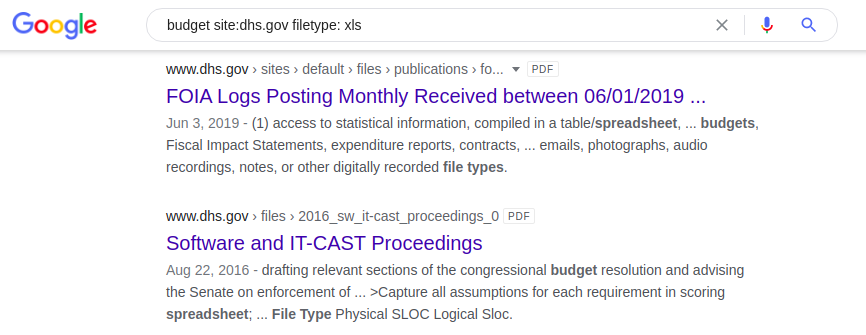
presupuesto sitio: dhs.gov tipo de archivo: xls
Buscar contraseñas
La búsqueda de información mediante el nombre de usuario y la contraseña puede resultar útil para buscar vulnerabilidades en su propio recurso. De lo contrario, las contraseñas se almacenan en documentos compartidos en servidores web. Puede probar las siguientes combinaciones en diferentes motores de búsqueda:
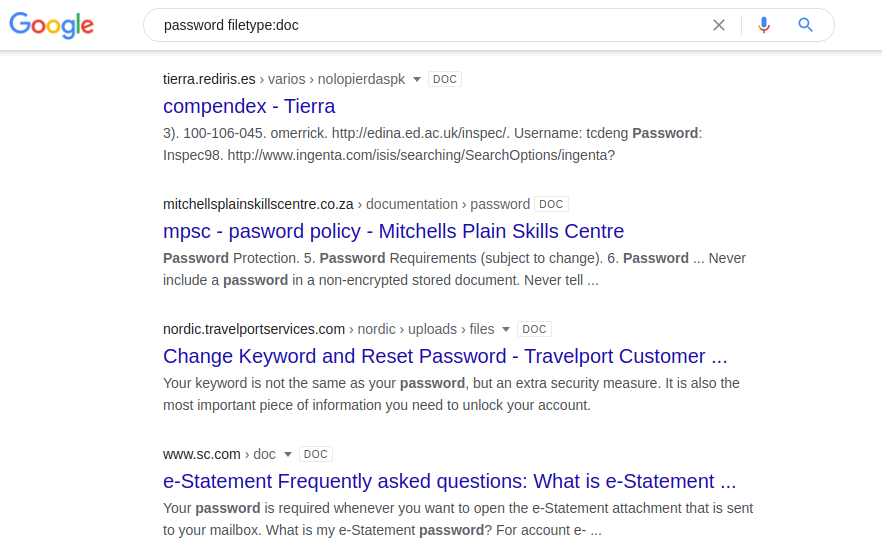
contraseña tipo de archivo: doc / docx / pdf / xls
contraseña tipo de archivo: doc / docx / pdf / xls sitio: [Nombre del sitio]
Si intenta ingresar una consulta de este tipo en otro motor de búsqueda, puede obtener resultados completamente diferentes. Por ejemplo, si ejecuta esta consulta sin el término "sitio: [Nombre del sitio] ", Google devolverá los resultados del documento que contienen los nombres de usuario y contraseñas reales de algunas escuelas secundarias estadounidenses. Otros motores de búsqueda no muestran esta información en las primeras páginas de resultados. Como puede ver a continuación, Yahoo y DuckDuckGo son ejemplos.
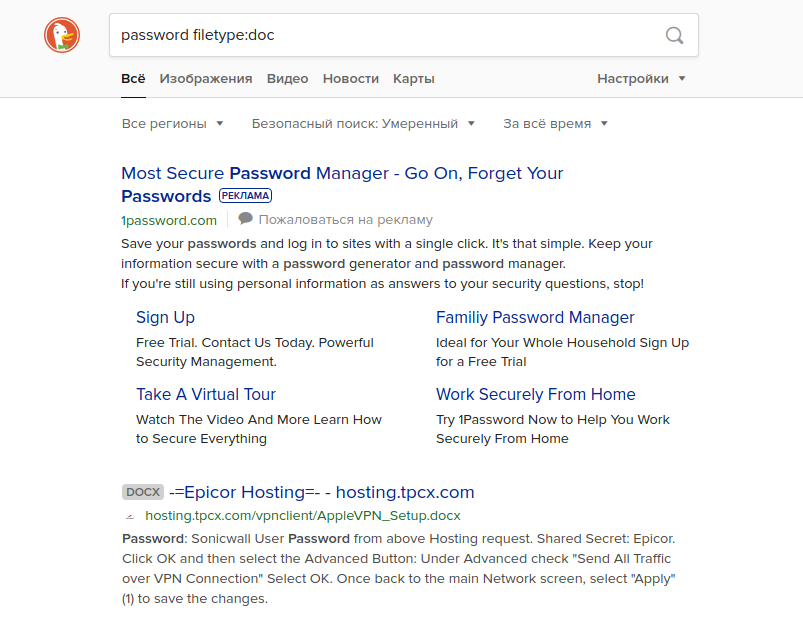
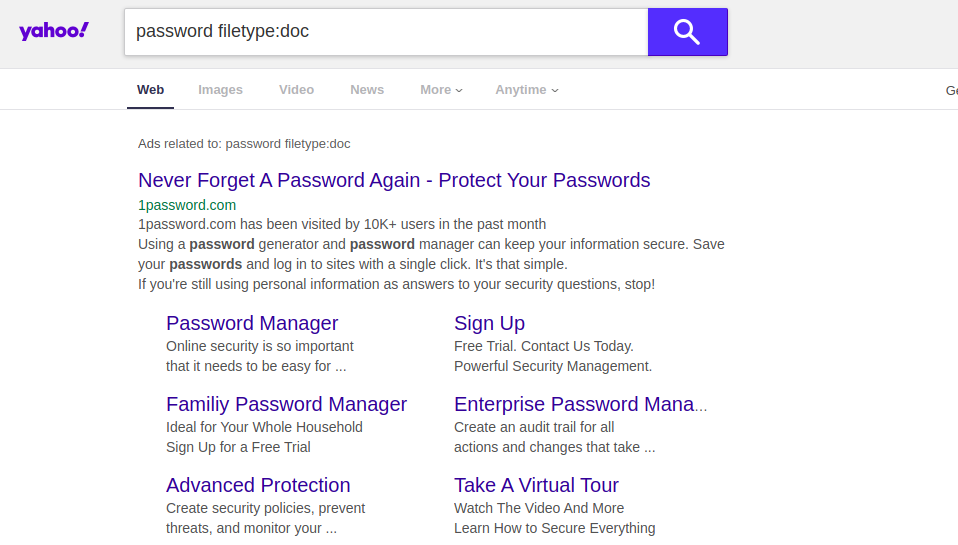
Precios de la vivienda en Londres
Otro ejemplo interesante se refiere a la información sobre el precio de la vivienda en Londres. A continuación se muestran los resultados de una consulta que se ingresó en cuatro motores de búsqueda diferentes:
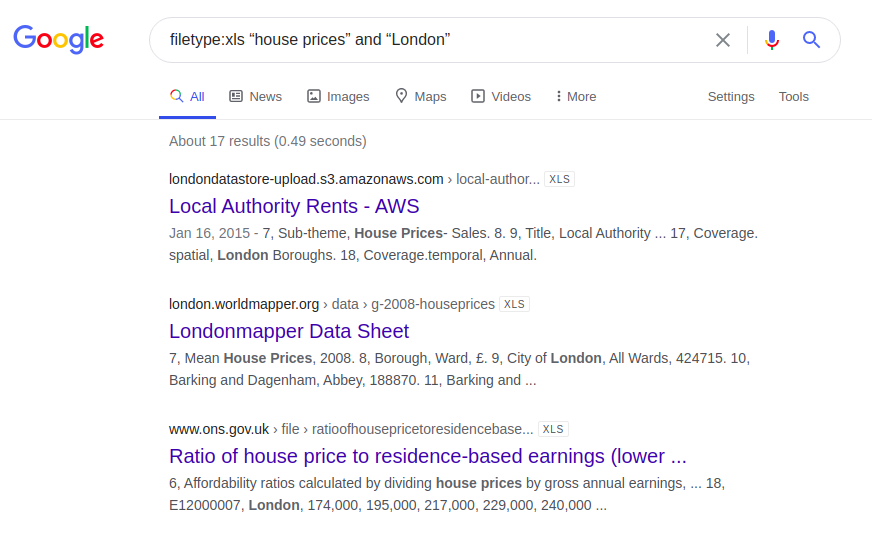
filetype: xls "precios de la vivienda" y "Londres"
Quizás ahora tenga sus propias ideas e ideas sobre los sitios web en los que le gustaría centrarse en su propia búsqueda de información, o cómo comprobar adecuadamente su propio recurso en busca de posibles vulnerabilidades ...
Herramientas de indexación de búsqueda alternativas
También existen otros métodos para recopilar información utilizando Google Dorking. Todas son alternativas y actúan como automatización de búsqueda. A continuación te proponemos echar un vistazo a algunos de los proyectos más populares que no es un pecado compartir.
Hacking de Google en línea
Google Hacking Online es una integración en línea de la búsqueda de Google Dorking de varios datos a través de una página web utilizando operadores establecidos, que puede encontrar aquí . La herramienta es un campo de entrada simple para encontrar la dirección IP o URL deseada de un enlace a un recurso de interés, junto con las opciones de búsqueda sugeridas.
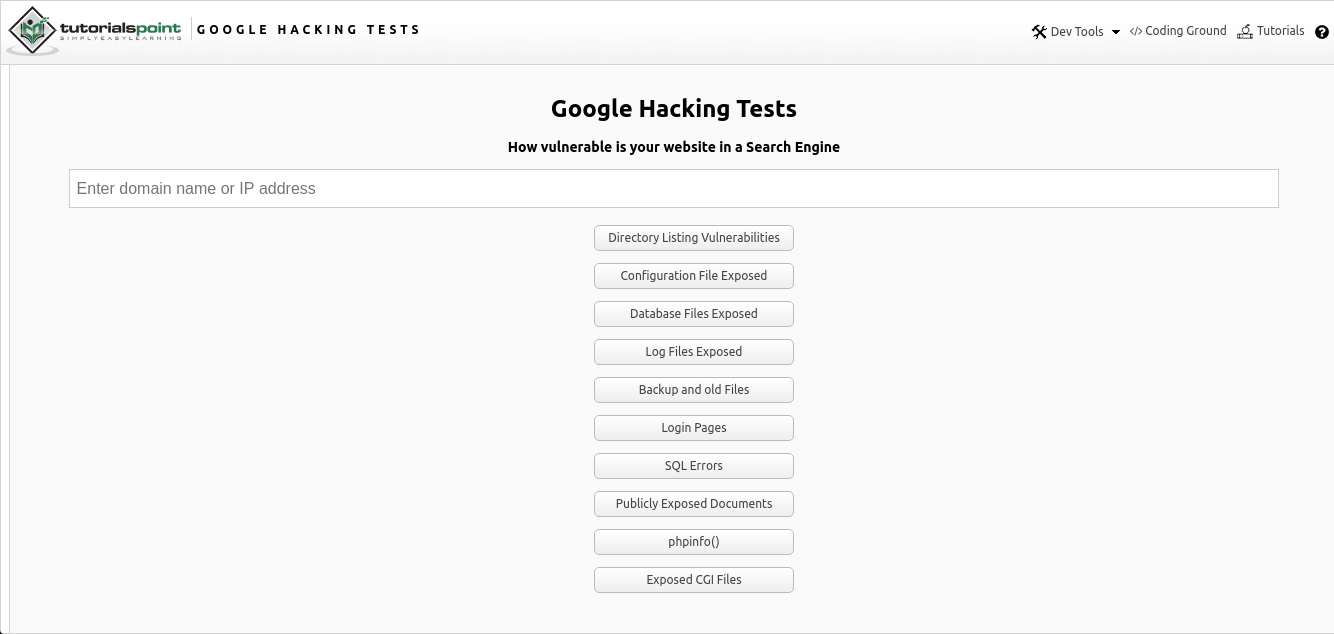
Como puede ver en la imagen de arriba, la búsqueda por varios parámetros se proporciona en forma de varias opciones:
- Búsqueda de directorios públicos y vulnerables
- Archivos de configuración
- Archivos de base de datos
- Registros
- Datos antiguos y datos de respaldo
- Páginas de autenticación
- Errores SQL
- Documentos disponibles al público
- Información de configuración del servidor php ("phpinfo")
- Archivos CGI (Common Gateway Interface)
Todo funciona en Vanilla JS, que está escrito en el archivo de la página web. Al principio, se toma la información del usuario ingresada, a saber, el nombre de host o la dirección IP de la página web. Y luego se solicita a los operadores la información ingresada. Se abre un enlace para buscar un recurso específico en una nueva ventana emergente con los resultados proporcionados.
BinGoo
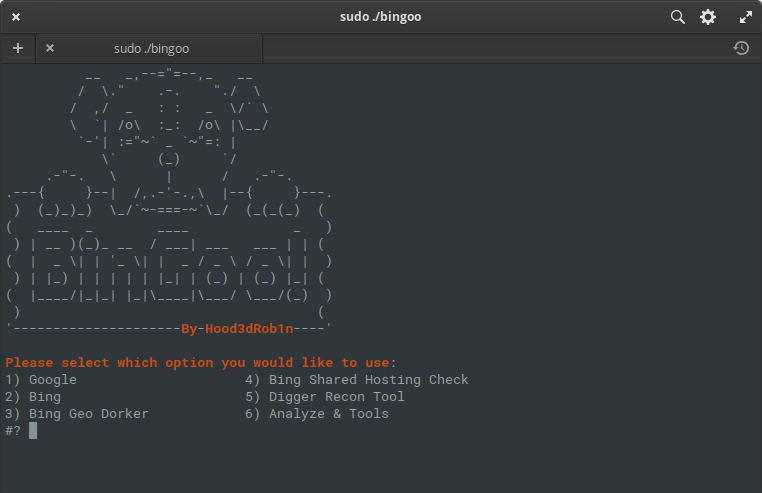
BinGoo es una herramienta versátil escrita en puro bash. Utiliza los operadores de búsqueda Google y Bing para filtrar una gran cantidad de enlaces en función de los términos de búsqueda proporcionados. Puede elegir buscar un operador a la vez, o enumerar un operador por línea y realizar un escaneo masivo. Una vez que se completa el proceso de recopilación inicial, o tiene enlaces recopilados de otras formas, puede pasar a las herramientas de análisis para buscar indicadores comunes de vulnerabilidades.
Los resultados se ordenan cuidadosamente en los archivos apropiados según los resultados obtenidos. Pero el análisis tampoco se detiene aquí, puede ir aún más lejos y ejecutarlos usando la funcionalidad adicional de SQL o LFI, o puede usar las herramientas de envoltura de SQLMAP y FIMAP, que funcionan mucho mejor, con resultados precisos.
También se incluyen varias funciones útiles para hacer la vida más fácil, como geodorking basado en el tipo de dominio, códigos de país en el dominio y verificador de alojamiento compartido que utiliza la búsqueda de Bing preconfigurada y la lista de dork para buscar posibles vulnerabilidades en otros sitios. También se incluye una búsqueda simple de páginas de administración basada en la lista proporcionada y los códigos de respuesta del servidor para confirmación. En general, este es un paquete de herramientas muy interesante y compacto que lleva a cabo la recopilación y análisis principal de la información dada. Puedes familiarizarte con él aquí .
Pagodo
El propósito de la herramienta Pagodo es la indexación pasiva por parte de los operadores de Google Dorking para recopilar páginas web y aplicaciones potencialmente vulnerables a través de Internet. El programa consta de dos partes. El primero es ghdb_scraper.py, que consulta y recopila los operadores de Google Dorks, y el segundo, pagodo.py, utiliza los operadores y la información recopilados a través de ghdb_scraper.py y los analiza mediante consultas de Google.
Para empezar, el archivo pagodo.py requiere una lista de operadores de Google Dorks. Se proporciona un archivo similar en el repositorio del proyecto en sí o simplemente puede consultar toda la base de datos a través de una sola solicitud GET usando ghdb_scraper.py. Y luego simplemente copie las declaraciones individuales de Dorks en un archivo de texto o colóquelas en json si se requieren datos de contexto adicionales.
Para realizar esta operación, debe ingresar el siguiente comando:
python3 ghdb_scraper.py -j -sAhora que hay un archivo con todos los operadores necesarios, se puede redirigir a pagodo.py usando la opción "-g" para comenzar a recopilar aplicaciones públicas y potencialmente vulnerables. El archivo pagodo.py usa la biblioteca "google" para encontrar estos sitios usando operadores como este:
intitle: "ListMail Login" admin -demo
site: example.com
Desafortunadamente, el proceso de tantas solicitudes (a saber, ~ 4600) a través de Google es simple no trabajará. Google lo identificará inmediatamente como un bot y bloqueará la dirección IP durante un período determinado. Se han agregado varias mejoras para que las consultas de búsqueda parezcan más orgánicas.
El módulo de Google Python se ha ajustado especialmente para permitir la aleatorización del agente de usuario en las búsquedas de Google. Esta función está disponible en la versión 1.9.3 del módulo y le permite seleccionar aleatoriamente los diferentes agentes de usuario utilizados para cada consulta de búsqueda. Esta función le permite emular diferentes navegadores utilizados en un gran entorno corporativo.
La segunda mejora se centra en aleatorizar el tiempo entre búsquedas. El retardo mínimo se especifica mediante el parámetro -e, y el factor de fluctuación se utiliza para añadir tiempo al número mínimo de retardos. Se genera una lista de 50 jitters y uno de ellos se agrega aleatoriamente a la latencia mínima para cada búsqueda de Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Más adelante en el script, se selecciona un tiempo aleatorio de la matriz de jitter y se agrega al retraso en la creación de solicitudes:
pause_time = self.delay + random.choice (self.jitter)Puede experimentar con los valores usted mismo, pero la configuración predeterminada funciona bien. Tenga en cuenta que el proceso de la herramienta puede tardar varios días (en promedio 3; dependiendo de la cantidad de operadores especificados y el intervalo de solicitud), así que asegúrese de tener tiempo para esto.
Para ejecutar la herramienta en sí, es suficiente el siguiente comando, donde "example.com" es el enlace al sitio web de interés y "dorks.txt" es el archivo de texto que creó ghdb_scraper.py:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1Y puede tocar y familiarizarse con la herramienta haciendo clic en este enlace .
Métodos de protección de Google Dorking
Recomendaciones clave
Google Dorking, como cualquier otra herramienta de código abierto, tiene sus propias técnicas para proteger y evitar que los intrusos recopilen información confidencial. Los administradores de cualquier plataforma web y servidor deben seguir las siguientes recomendaciones de los cinco protocolos para evitar amenazas de "Google Dorking":
- Actualización sistemática de sistemas operativos, servicios y aplicaciones.
- Implementación y mantenimiento de sistemas anti-hacker.
- Conocimiento de los robots de Google y los diversos procedimientos de los motores de búsqueda, y cómo validar dichos procesos.
- Elimina el contenido sensible de las fuentes públicas.
- Separar contenido público, contenido privado y bloquear el acceso a contenido para usuarios públicos.
Configuración de archivos .Htaccess y robots.txt
Básicamente, todas las vulnerabilidades y amenazas asociadas con "Dorking" se generan debido al descuido o negligencia de los usuarios de diversos programas, servidores u otros dispositivos web. Por tanto, las normas de autoprotección y protección de datos no plantean dificultades ni complicaciones.
Para abordar con cuidado la prevención de la indexación desde cualquier motor de búsqueda, debe prestar atención a dos archivos de configuración principales de cualquier recurso de red: ".htaccess" y "robots.txt". El primero protege las rutas y directorios designados con contraseñas. El segundo excluye a los directorios de la indexación de los motores de búsqueda.
Si su propio recurso contiene ciertos tipos de datos o directorios que no deben indexarse en Google, primero debe configurar el acceso a las carpetas mediante contraseñas. En el siguiente ejemplo, puede ver claramente cómo y qué debe escribirse exactamente en el archivo ".htaccess" ubicado en el directorio raíz de cualquier sitio web.
En primer lugar, añadir unas pocas líneas como se muestra a continuación:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName "Documentos Seguros"
TipoAut básico
requiere nombredeusuario1 usuarios
requieren nombredeusuario2 usuarios
requieren USERNAME3 usuario
En la línea AuthUserFile, especifique la ruta a la ubicación del archivo .htaccess, que se encuentra en su directorio. Y en las últimas tres líneas, debe especificar el nombre de usuario correspondiente al que se proporcionará acceso. Luego debe crear ".htpasswd" en la misma carpeta que ".htaccess" y ejecutar el siguiente comando:
htpasswd -c .htpasswd username1
Ingrese la contraseña dos veces para username1 y después de eso, se creará un archivo completamente limpio ".htpasswd" en directorio actual y contendrá la versión encriptada de la contraseña.
Si hay varios usuarios, debe asignar una contraseña a cada uno de ellos. Para agregar usuarios adicionales, no necesita crear un nuevo archivo, simplemente puede agregarlos al archivo existente sin usar la opción -c usando este comando:
htpasswd .htpasswd username2
En otros casos, se recomienda configurar un archivo robots.txt, que es responsable de indexar las páginas de cualquier recurso web. Sirve como guía para cualquier motor de búsqueda que se vincule a direcciones de páginas específicas. Y antes de ir directamente a la fuente que está buscando, robots.txt bloqueará dichas solicitudes o las omitirá.
El archivo en sí se encuentra en el directorio raíz de cualquier plataforma web que se ejecute en Internet. La configuración se realiza simplemente cambiando dos parámetros principales: "User-agent" y "Disallow". El primero selecciona y marca todos o algunos motores de búsqueda específicos. Mientras que el segundo señala qué es exactamente lo que se debe bloquear (archivos, directorios, archivos con ciertas extensiones, etc.). A continuación se muestran algunos ejemplos: directorios, archivos y exclusiones de motores de búsqueda específicos excluidos del proceso de indexación.
User-agent: *
Disallow: / cgi-bin /
User-agent: *
Disallow: /~joe/junk.html
User-agent: Bing
Disallow: /
Usando metaetiquetas
Además, se pueden introducir restricciones para las arañas web en páginas web individuales. Se pueden ubicar en sitios web, blogs y páginas de configuración típicos. En el encabezado HTML, deben ir acompañadas de una de las siguientes frases:
<meta name = “Robots” content = “none” \>
<meta name = “Robots” content = “noindex, nofollow” \>
Cuando agrega una entrada de este tipo en el encabezado de la página, los robots de Google no indexarán ninguna página secundaria o principal. Esta cadena se puede ingresar en páginas que no deben indexarse. Sin embargo, esta decisión se basa en un acuerdo mutuo entre los motores de búsqueda y el propio usuario. Si bien Google y otras arañas web acatan las restricciones antes mencionadas, existen ciertos robots web que "buscan" tales frases para recuperar datos configurados inicialmente sin indexar.
De las opciones más avanzadas para indexar la seguridad, puede utilizar el sistema CAPTCHA. Esta es una prueba de computadora que permite que solo los humanos accedan al contenido de una página, no a los bots automatizados. Sin embargo, esta opción tiene un pequeño inconveniente. No es muy fácil de usar para los propios usuarios.
Otra técnica defensiva simple de Google Dorks podría ser, por ejemplo, codificar caracteres en archivos administrativos con ASCII, lo que dificulta el uso de Google Dorking.
Práctica de pentesting
Las prácticas de pentesting son pruebas para identificar vulnerabilidades en la red y en plataformas web. Son importantes a su manera, porque tales pruebas determinan de manera única el nivel de vulnerabilidad de las páginas web o servidores, incluido Google Dorking. Hay herramientas de pentesting dedicadas que se pueden encontrar en Internet. Uno de ellos es Site Digger, un sitio que le permite verificar automáticamente la base de datos de Google Hacking en cualquier página web seleccionada. Además, también hay herramientas como el escáner Wikto, SUCURI y varios otros escáneres en línea. Funcionan de manera similar.
Existen herramientas más avanzadas que imitan el entorno de la página web, junto con errores y vulnerabilidades, para atraer a un atacante y luego recuperar información confidencial sobre él, como Google Hack Honeypot. Un usuario estándar que tiene pocos conocimientos y experiencia insuficiente en la protección contra Google Dorking debe, en primer lugar, verificar su recurso de red para identificar las vulnerabilidades de Google Dorking y verificar qué datos confidenciales están disponibles públicamente. Vale la pena revisar estas bases de datos con regularidad, haveibeenpwned.com y dehashed.com , para ver si la seguridad de sus cuentas en línea se ha visto comprometida y publicada.
https://haveibeenpwned.com/ se refiere a páginas web poco seguras donde se recopilaron datos de la cuenta (direcciones de correo electrónico, inicios de sesión, contraseñas y otros datos). La base de datos contiene actualmente más de 5 mil millones de cuentas. Una herramienta más avanzada está disponible en https://dehashed.com , que le permite buscar información por nombres de usuario, direcciones de correo electrónico, contraseñas y sus hashes, direcciones IP, nombres y números de teléfono. Además, las cuentas filtradas se pueden comprar en línea. El acceso de un día cuesta solo $ 2.
Conclusión
Google Dorking es una parte integral de la recopilación de información confidencial y el proceso de su análisis. Se puede considerar legítimamente una de las herramientas principales y principales de OSINT. Los operadores de Google Dorking ayudan tanto a probar su propio servidor como a encontrar toda la información posible sobre una víctima potencial. De hecho, este es un ejemplo muy llamativo del uso correcto de los motores de búsqueda con el fin de explorar información específica. Sin embargo, si las intenciones de usar esta tecnología son buenas (verificando las vulnerabilidades de su propio recurso de Internet) o desagradables (buscar y recopilar información de varios recursos y usarla con fines ilegales), solo los usuarios deben decidir.
Los métodos alternativos y las herramientas de automatización brindan aún más oportunidades y conveniencia para analizar los recursos web. Algunos de ellos, como BinGoo, amplían la búsqueda indexada regular en Bing y analizan toda la información recibida a través de herramientas adicionales (SqlMap, Fimap). Ellos, a su vez, presentan información más precisa y específica sobre la seguridad del recurso web seleccionado.
Al mismo tiempo, es importante saber y recordar cómo proteger adecuadamente y evitar que sus plataformas en línea se indexen donde no deberían estar. Y también adhiérase a las disposiciones básicas proporcionadas para cada administrador web. Después de todo, el desconocimiento y el desconocimiento de que, por su propio error, otras personas obtuvieron tu información, no significa que todo pueda devolverse como estaba antes.