
El aprendizaje automático está cambiando cada vez más de modelos diseñados a mano a tuberías optimizadas automáticamente usando herramientas como H20 , TPOT y auto-sklearn . Estas bibliotecas, junto con técnicas como la búsqueda aleatoria , tienen como objetivo simplificar la selección de modelos y ajustar partes del aprendizaje automático al encontrar el mejor modelo para un conjunto de datos sin ninguna intervención manual. Sin embargo, el desarrollo de objetos, posiblemente el aspecto más valioso de las tuberías de aprendizaje automático, sigue siendo casi completamente humano.
Características de diseño ( ingeniería de características), también conocido como creación de características, es el proceso de creación de nuevas características a partir de datos existentes para entrenar un modelo de aprendizaje automático. Este paso puede ser más importante que el modelo real utilizado porque el algoritmo de aprendizaje automático solo aprende de los datos que le proporcionamos, y es absolutamente necesario crear características que sean relevantes para la tarea (consulte el excelente artículo "Algunas cosas útiles"). Cosas que debe saber sobre el aprendizaje automático " ).
Por lo general, el desarrollo de características es un largo proceso manual basado en el conocimiento del dominio, la intuición y la manipulación de datos. Este proceso puede ser extremadamente tedioso, y las características finales estarán limitadas tanto por la subjetividad humana como por el tiempo. El diseño automatizado de funciones tiene como objetivo ayudar al científico de datos a crear automáticamente muchos objetos candidatos a partir de un conjunto de datos del cual se puede seleccionar y usar lo mejor para la capacitación.
En este artículo, veremos un ejemplo del uso del desarrollo automático de funciones con la biblioteca de herramientas de Python.... Usaremos un conjunto de datos de muestra para mostrar los conceptos básicos (cuidado con futuras publicaciones utilizando datos reales). El código completo de este artículo está disponible en GitHub .
Funciones básicas de desarrollo
El desarrollo característico significa crear características adicionales a partir de datos existentes, que a menudo se distribuyen en varias tablas relacionadas. El desarrollo de características requiere extraer información relevante de los datos y ponerla en una sola tabla que luego pueda usarse para entrenar un modelo de aprendizaje automático.
El proceso de creación de características lleva mucho tiempo, ya que generalmente se requieren varios pasos para crear cada nueva característica, especialmente cuando se usa información de varias tablas. Podemos agrupar las operaciones de creación de características en dos categorías: transformaciones y agregaciones . Echemos un vistazo a algunos ejemplos para ver estos conceptos en acción.
Transformaciónactúa en una sola tabla (en términos de Python, una tabla es solo Pandas
DataFrame), creando nuevas características a partir de una o más columnas existentes. Por ejemplo, si tenemos la tabla de clientes a continuación,
podemos crear entidades encontrando el mes de una columna
joinedo tomando el logaritmo natural de una columna income. Ambas son transformaciones porque solo usan información de una tabla.
Por otro lado, las agregaciones se realizan en tablas y usan una relación de uno a muchos para agrupar casos y luego calcular estadísticas. Por ejemplo, si tenemos otra tabla con información sobre préstamos de clientes, donde cada cliente puede tener varios préstamos, podemos calcular estadísticas tales como valores de préstamo promedio, máximo y mínimo para cada cliente.
Este proceso incluye agrupar la tabla de préstamos por cliente, calcular la agregación y luego combinar los datos recibidos con los datos del cliente. Así es como podríamos hacerlo en Python usando el lenguaje Pandas .
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)
Estas operaciones en sí mismas no son difíciles, pero si tenemos cientos de variables dispersas en docenas de tablas, este proceso no puede hacerse manualmente. Idealmente, necesitamos una solución que pueda realizar automáticamente transformaciones y agregaciones en varias tablas y combinar los datos resultantes en una sola tabla. Si bien Pandas es un gran recurso, todavía hay muchas manipulaciones de datos que queremos hacer manualmente. (Para obtener más información sobre el diseño manual de características, consulte el excelente Manual de Python Data Science) .
Herramientas
Afortunadamente, featuretools es exactamente la solución que estamos buscando. Esta biblioteca de Python de código abierto genera automáticamente muchos rasgos a partir de un conjunto de tablas relacionadas. Featuretools se basa en una técnica conocida como " Síntesis de características profundas " que suena mucho más impresionante de lo que realmente es (el nombre proviene de combinar múltiples características, ¡no porque utiliza el aprendizaje profundo!).
Deep Feature Synthesis combina varias operaciones de transformación y agregación (llamadas características primitivasen el diccionario FeatureTools) para crear características a partir de datos distribuidos en muchas tablas. Como la mayoría de las ideas en el aprendizaje automático, es un método complejo basado en conceptos simples. Al estudiar un bloque de construcción a la vez, podemos formar una buena comprensión de esta poderosa técnica.
Primero, echemos un vistazo a los datos de nuestro ejemplo. Ya hemos visto algo del conjunto de datos anterior, y el conjunto completo de tablas se ve así:
clients: información básica sobre clientes en la asociación de crédito. Cada cliente solo tiene una fila en este marco de datos
loans: préstamos a clientes. Cada crédito solo tiene su propia fila en este marco de datos, pero los clientes pueden tener múltiples créditos.
payments: pagos de préstamos. Cada pago tiene solo una línea, pero cada préstamo tendrá múltiples pagos.
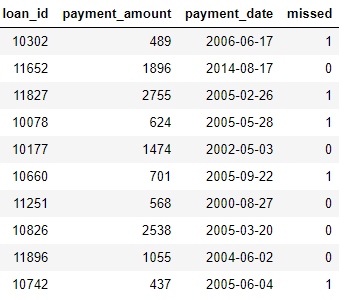
Si tenemos una tarea de aprendizaje automático, como predecir si un cliente pagará un préstamo futuro, queremos combinar toda la información del cliente en una tabla. Las tablas están vinculadas (a través de las variables
client_idy loan_id), y podríamos usar una serie de transformaciones y agregaciones para completar manualmente el proceso. Sin embargo, pronto veremos que en su lugar podemos usar featuretools para automatizar el proceso.
Entidades y EntitySets (entidades y conjuntos de entidades)
Los primeros dos conceptos de herramientas de características son entidades y conjuntos de entidades . La entidad es solo una mesa (o
DataFramesi piensas en Pandas). EntitySet es una colección de tablas y relaciones entre ellas. Imagine entityset es solo otra estructura de datos de Python con sus propios métodos y atributos.
Podemos crear un conjunto vacío de entidades en featuretools usando lo siguiente:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')Ahora necesitamos agregar entidades. Cada entidad debe tener un índice, que es una columna con todos los elementos únicos. Es decir, cada valor en el índice debe aparecer solo una vez en la tabla. El índice en el marco de datos
clientsse client_iddebe a que cada cliente solo tiene una fila en ese marco de datos. Agregamos una entidad con un índice existente al conjunto de entidades usando la siguiente sintaxis:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients,
index = 'client_id', time_index = 'joined')El marco de datos
loanstambién tiene un índice único loan_id, y la sintaxis para agregarlo a un conjunto de entidades es la misma que para clients. Sin embargo, no hay un índice único para el marco de datos de pago. Cuando agregamos esta entidad al conjunto de entidades, necesitamos pasar un parámetro make_index = Truey especificar el nombre del índice. Además, si bien featuretools deducirá automáticamente el tipo de datos de cada columna en una entidad, podemos anular esto pasando un diccionario de tipos de columna al parámetro variable_types.
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')Para este marco de datos, aunque
missedes un número entero, no es una variable numérica, ya que solo puede tomar 2 valores discretos, por lo que le decimos a featuretools que lo trate como una variable categórica. Después de agregar los marcos de datos al conjunto de entidades, examinamos cualquiera de ellos:
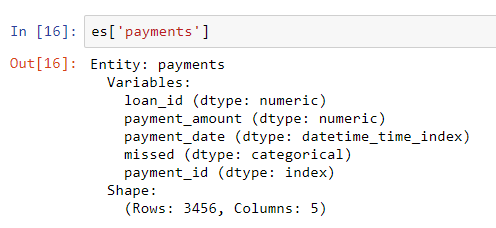
Los tipos de columna se dedujeron correctamente con la revisión especificada. A continuación, debemos indicar cómo se relacionan las tablas en el conjunto de entidades.
Relaciones entre mesas
La mejor manera de representar la relación entre dos tablas es con una analogía padre-hijo . Relación uno a muchos: cada padre puede tener varios hijos. En el área de la tabla, la tabla principal tiene una fila para cada elemento primario, pero la tabla secundaria puede tener varias filas correspondientes a varios elementos secundarios del mismo elemento primario.
Por ejemplo, en nuestro conjunto de datos, el
clientsmarco es el padre del loansmarco. Cada cliente tiene solo una línea clients, pero puede tener varias líneas loans. Asimismo, loansson padrespaymentsporque cada préstamo tendrá múltiples pagos. Los padres están vinculados a sus hijos por una variable común. Cuando hacemos la agregación, agrupamos la tabla secundaria por la variable principal y calculamos estadísticas sobre los elementos secundarios de cada elemento primario.
Para formalizar la relación en featuretools , solo necesitamos especificar una variable que vincule las dos tablas.
clientsy la tabla está loansasociada con la variable client_id, y loans, y payments- con la ayuda de loan_id. La sintaxis para crear una relación y agregarla a un conjunto de entidades se muestra a continuación:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es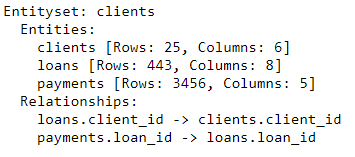
El conjunto de entidades ahora contiene tres entidades (tablas) y relaciones que unen estas entidades. Después de agregar entidades y formalizar relaciones, nuestro conjunto de entidades está completo y estamos listos para crear características.
Características primitivas
Antes de que podamos pasar completamente a la síntesis profunda de rasgos, necesitamos entender las primitivas de los rasgos . Ya sabemos lo que son, ¡pero los llamamos con diferentes nombres! Estas son solo las operaciones básicas que utilizamos para formar nuevas funciones:
- Agregaciones: operaciones realizadas en una relación padre-hijo (uno a muchos) que se agrupan por padre y calculan estadísticas para los hijos. Un ejemplo es el agrupamiento de una mesa
loansporclient_idy determinar la cantidad máxima del préstamo para cada cliente. - Conversiones: operaciones realizadas desde una tabla a una o más columnas. Los ejemplos incluyen la diferencia entre dos columnas en la misma tabla, o el valor absoluto de una columna.
Se crean nuevas características en herramientas de características que utilizan estas primitivas, ya sea por sí mismas o como primitivas múltiples. A continuación se muestra una lista de algunas de las primitivas en FeatureTools (también podemos definir primitivas personalizadas ):
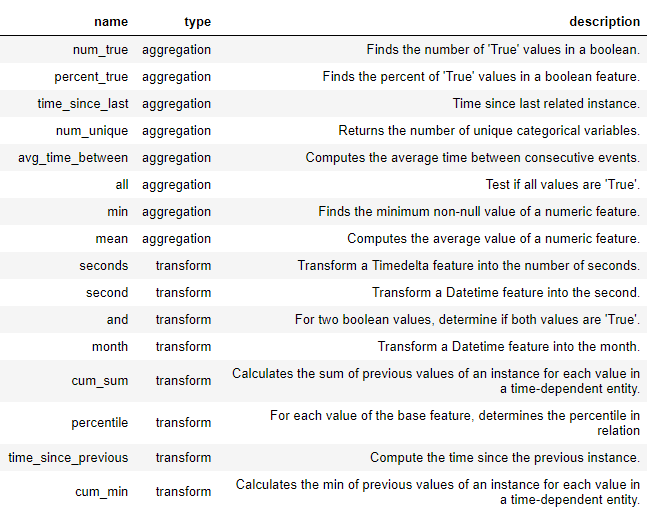
Estas primitivas se pueden usar solas o combinadas para crear características. Para crear entidades con las primitivas especificadas, utilizamos una función
ft.dfs(significa síntesis profunda de entidades). Pasamos un conjunto de entidades target_entity, que es una tabla a la que queremos agregar las características seleccionadas trans_primitives(transformaciones) y agg_primitives(agregados):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])El resultado es un marco de datos de nuevas características para cada cliente (porque creamos clientes
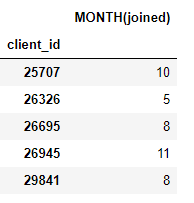
target_entity). Por ejemplo, tenemos un mes en el que se unió cada cliente, que es una primitiva de transformación:
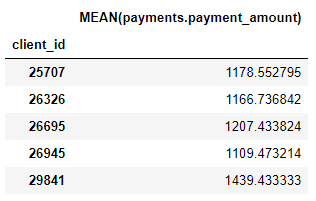
También tenemos una serie de primitivas de agregación, como los montos de pago promedio para cada cliente:
Aunque solo hemos especificado algunas primitivas, featuretools ha creado muchas características nuevas al combinar y apilar estas primitivas.
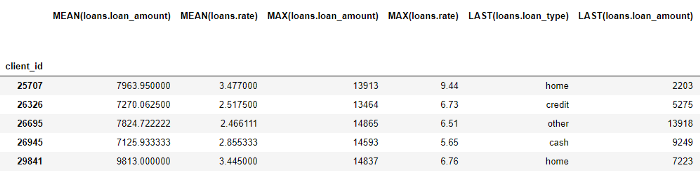
¡El marco de datos completo contiene 793 columnas de nuevas características!
Síntesis profunda de signos
Ahora tenemos todo para comprender la síntesis profunda de características (dfs). De hecho, ¡ya hicimos dfs en la llamada a la función anterior! Un rasgo profundo es simplemente un rasgo que consiste en una combinación de múltiples primitivas, y dfs es el nombre del proceso que crea esos rasgos. La profundidad de una característica profunda es la cantidad de primitivas necesarias para crear una característica.
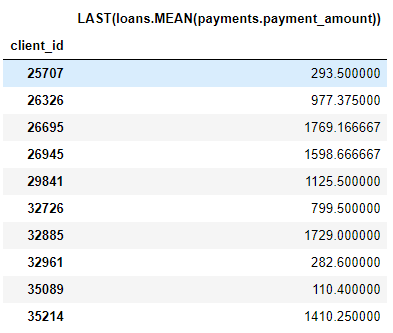
Por ejemplo, una columna
MEAN (payment.payment_amount)es una característica profunda con una profundidad de 1 porque se creó usando una única agregación. Un elemento con una profundidad de dos es este LAST(loans(MEAN(payment.payment_amount)). Esto se logra combinando dos agregaciones: LAST (más reciente) además de MEAN. Esto representa el pago promedio del préstamo más reciente para cada cliente.
Podemos componer características a cualquier profundidad que queramos, pero en la práctica nunca he ido más allá de la profundidad 2. Después de este punto, las características son difíciles de interpretar, pero insto a cualquier persona interesada a intentar "profundizar" .
No necesitamos especificar manualmente las primitivas, sino que podemos dejar que las herramientas de funciones seleccionen automáticamente las funciones para nosotros. Para esto usamos la misma llamada a la función
ft.dfs, pero no pasamos ninguna primitiva:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()
Featuretools ha creado muchas funciones nuevas para nosotros. Si bien este proceso crea automáticamente nuevos rasgos, no reemplazará a un Data Scientist porque todavía tenemos que averiguar qué hacer con todos esos rasgos. Por ejemplo, si nuestro objetivo es predecir si un cliente pagará un préstamo, podríamos buscar los signos más relevantes para un resultado en particular. Además, si tenemos conocimiento del área temática, podemos usarlo para seleccionar primitivas específicas de características o para una síntesis profunda de las características candidatas .
Próximos pasos
El diseño automatizado de funciones resolvió un problema pero creó otro: demasiadas funciones. Si bien es difícil decir cuáles de estas características serán importantes antes de ajustar un modelo, lo más probable es que no todas sean relevantes para la tarea en la que queremos capacitar a nuestro modelo. Además, demasiadas funciones pueden degradar el rendimiento del modelo porque las funciones menos útiles desplazan a las que son más importantes.
El problema de demasiados atributos se conoce como la maldición de la dimensión . A medida que aumenta el número de características (dimensión de datos) en el modelo, se hace más difícil estudiar la correspondencia entre características y objetivos. De hecho, la cantidad de datos necesarios para que el modelo funcione bien esescala exponencialmente con el número de características .
La maldición de la dimensionalidad se combina con la reducción de características (también conocida como selección de características) : el proceso de eliminar características innecesarias. Esto puede tomar muchas formas: Análisis de componentes principales (PCA), SelectKBest, usando valores de características de un modelo, o codificación automática usando redes neuronales profundas. Sin embargo, la reducción de características es un tema separado para otro artículo. En este punto, sabemos que podemos usar herramientas de funciones para crear muchas funciones de muchas tablas con un esfuerzo mínimo.
Salida
Al igual que muchos temas del aprendizaje automático, el diseño de funciones automatizadas con herramientas de funciones es un concepto complejo basado en ideas simples. Utilizando los conceptos de conjuntos de entidades, entidades y relaciones, las herramientas de características pueden realizar una síntesis profunda de características para crear nuevas características. La síntesis profunda de características, a su vez, combina primitivas ( agregados que operan a través de relaciones uno a muchos entre tablas y transformaciones , funciones aplicadas a una o más columnas en una tabla) para crear nuevas características a partir de múltiples tablas.

Descubra los detalles de cómo obtener una profesión de alto perfil desde cero o subir de nivel en habilidades y salario tomando los cursos en línea pagos de SkillFactory:
- Curso de aprendizaje automático (12 semanas)
- Data Science (12 )
- (9 )
- «Python -» (9 )
- DevOps (12 )
- - (8 )