distorsiones cognitivas sobre los costos hundidos (falacia de costos hundidos) es uno de los muchos sesgos cognitivos dañinos , de los cuales las personas se convierten en víctimas. Esto se refiere a nuestra tendencia a seguir dedicando tiempo.y recursos para una causa perdida, porque ya hemos pasado, ahogado, mucho tiempo en la búsqueda. La falacia de bajo costo se aplica a permanecer en un mal trabajo más de lo que deberíamos, trabajar servilmente en un proyecto incluso cuando está claro que no funcionará, y sí, continuar usando la biblioteca de trazado aburrida y obsoleta, matplotlib, cuando hay alternativas más eficientes, interactivas y más atractivas.
En los últimos meses, me di cuenta de que la única razón por la que estoy usando matplotlib es por las cientos de horas que he pasado aprendiendo la sintaxis compleja . Estas complejidades conducen a horas de frustración al descubrir en StackOverflow cómo formatear fechas o agregar un segundo eje Y... Afortunadamente, este es un buen momento para trazar gráficos en Python, y después de explorar las opciones , el claro ganador, en términos de facilidad de uso, documentación y funcionalidad, es trama . En este artículo, nos sumergiremos en la trama, aprendiendo cómo crear mejores gráficos en menos tiempo, a menudo con una sola línea de código.
Todo el código para este artículo está disponible en GitHub . Todos los gráficos son interactivos y se pueden ver en NBViewer .
Resumen de la trama
Empaquetar argumentalmente para Python - una biblioteca de software de fuente abierta, construida sobre plotly.js , que, a su vez, se basa en d3.js . Vamos a utilizar un envoltorio sobre argumentalmente llamados gemelos diseñado para trabajar con los pandas DataFrame.So, nuestra pila gemelos> argumentalmente> plotly.js> d3.js - esto significa que obtenemos la eficiencia en la programación Python con increíbles capacidades gráficas d3 interactiva .
( Plotly es una compañía gráficacon varios productos y herramientas de código abierto. La biblioteca de Python es de uso gratuito y podemos crear gráficos ilimitados sin conexión, además de hasta 25 gráficos en línea para compartir con el mundo .)
Todo el trabajo en este artículo se realizó en Jupyter Notebook con plotly + gemelos funcionando desconectado. Después de instalar plotly y gemelos con,
pip install cufflinks plotly importe lo siguiente para ejecutarlo en Júpiter:
# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)Distribuciones de variables individuales: histogramas y diagramas de caja
Gráficos de una sola variable: unidimensional es la forma estándar de comenzar un análisis, mientras que un histograma es un gráfico de transición ( aunque con algunos problemas ) para trazar una distribución. Aquí, usando mis estadísticas promedio de artículos (puede ver cómo obtener sus propias estadísticas aquí, o usar las mías ), hagamos un histograma interactivo del número de aplausos en los artículos (
dfeste es el marco de datos estándar de Pandas):
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')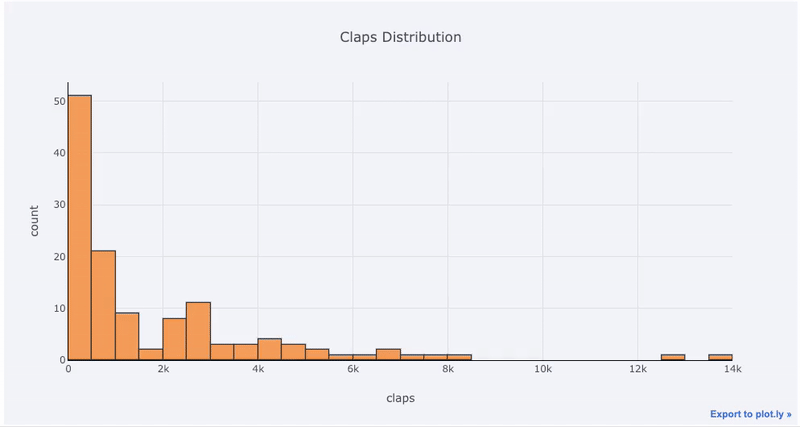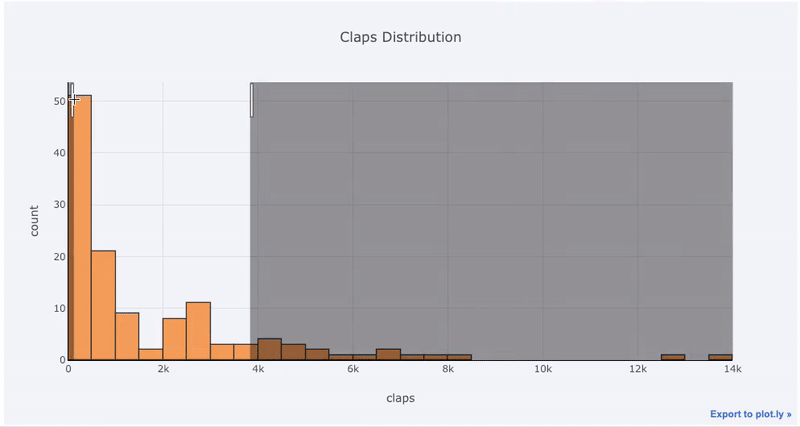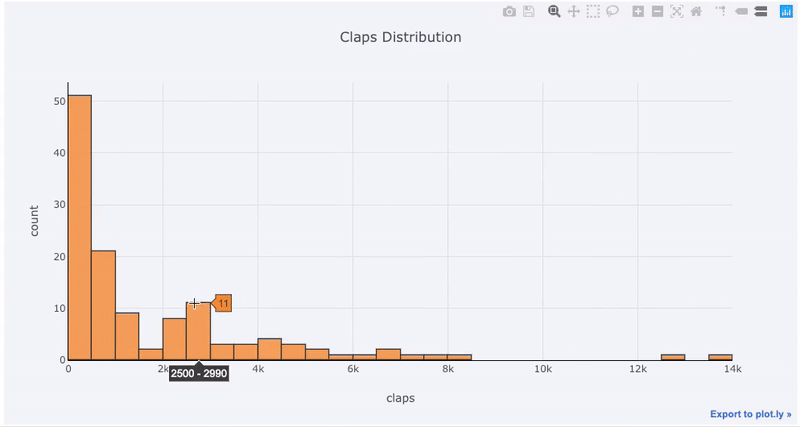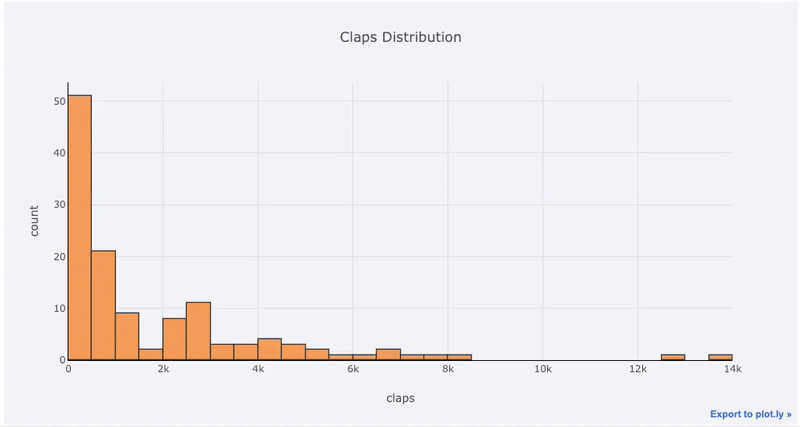
Para aquellos que están acostumbrados
matplotlib, ¡todo lo que tenemos que hacer es agregar una letra más (en iplotlugar de plot) y obtenemos un gráfico mucho más hermoso e interactivo! Podemos hacer clic en los datos para obtener más información, acercarnos a partes del gráfico y, como veremos más adelante, seleccionar diferentes categorías.
Si queremos trazar histogramas superpuestos, es igual de fácil:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')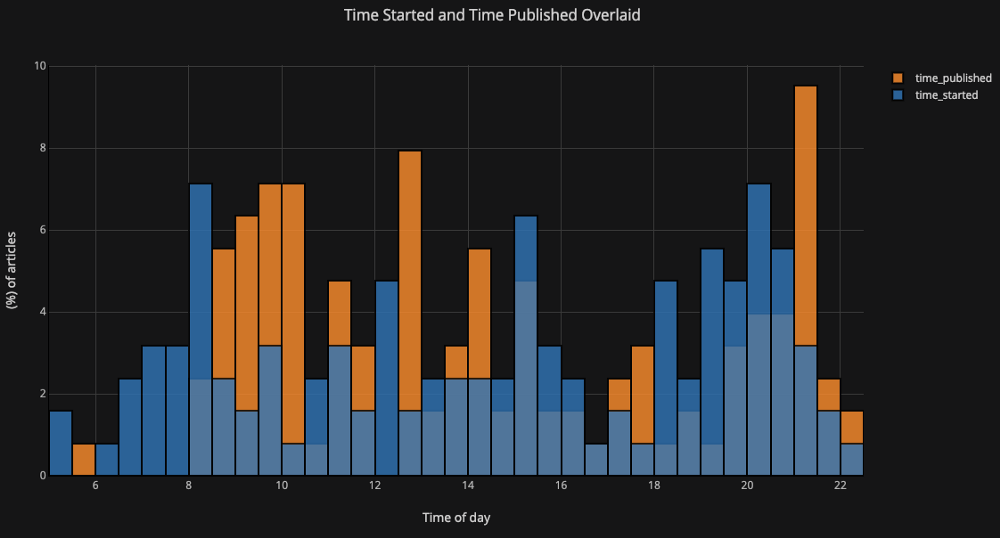
Con un poco de manipulación
Pandas, podemos hacer un diagrama de barras:
# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')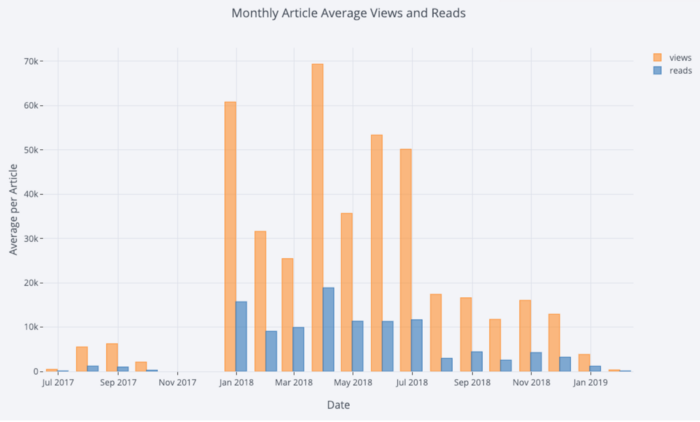
Como hemos visto, podemos combinar el poder de los pandas con plotly + gemelos. Para trazar la distribución de los ventiladores por publicación, usamos
pivoty luego trazamos:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')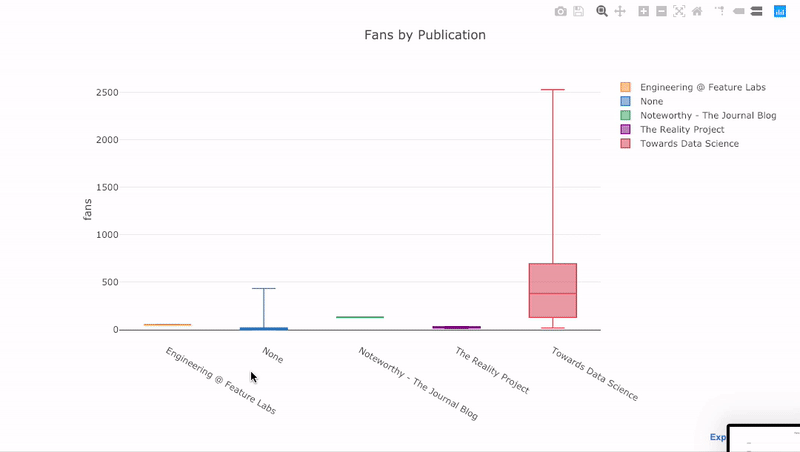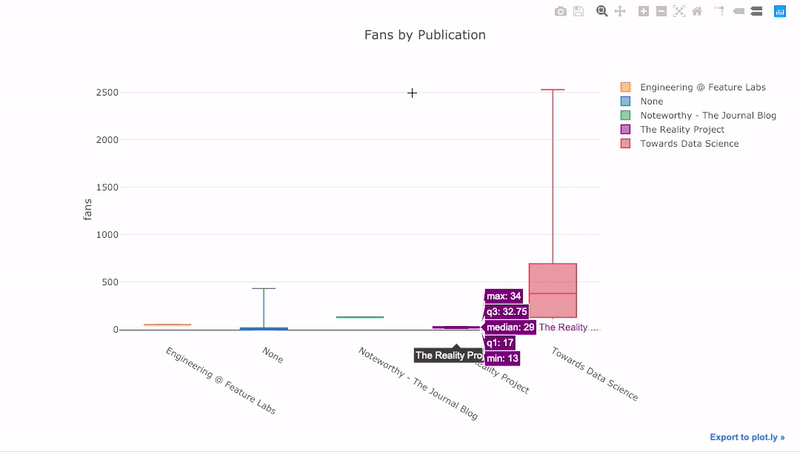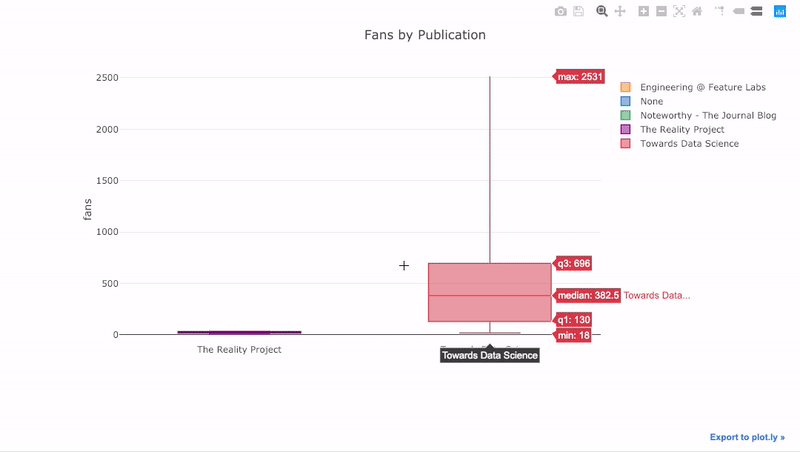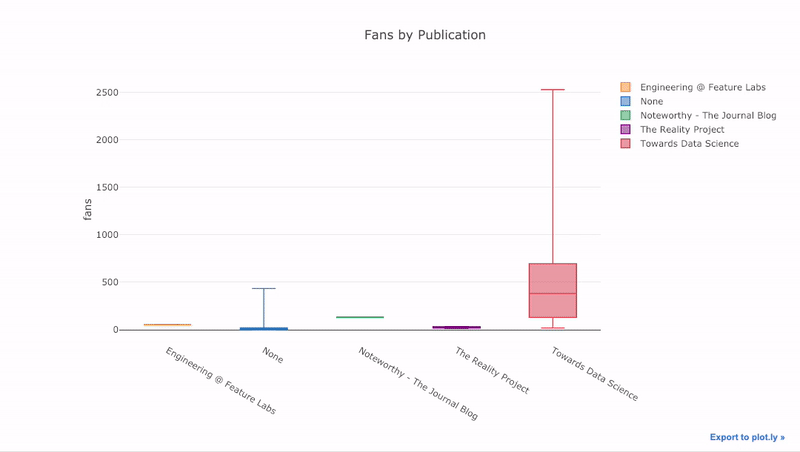
Los beneficios de la interactividad son que podemos explorar y alojar los datos como mejor nos parezca. Hay mucha información en la caja de balsa, y sin la capacidad de ver los números, ¡nos perderemos la mayor parte!
Gráfico de dispersión
El diagrama de dispersión es el corazón de la mayoría de los análisis. Esto nos permite ver la evolución de una variable a lo largo del tiempo, o la relación entre dos (o más) variables.
Series de tiempo
Gran parte de los datos reales tiene un elemento de tiempo. Por suerte, plotly + gemelos fue diseñado teniendo en cuenta la visualización de series de tiempo. Enmarquemos los datos de mis artículos de TDS y veamos cómo han cambiado las tendencias.
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')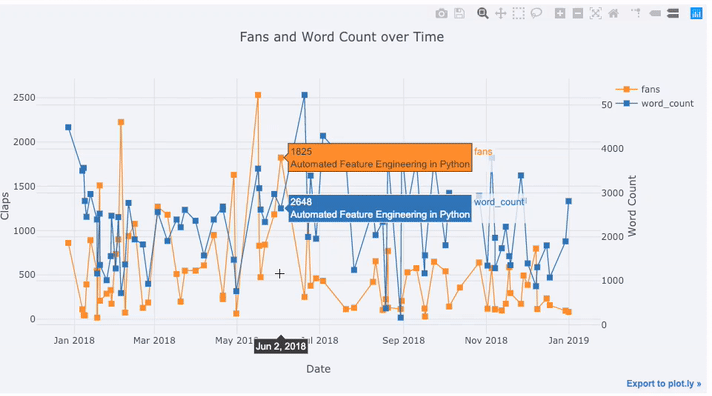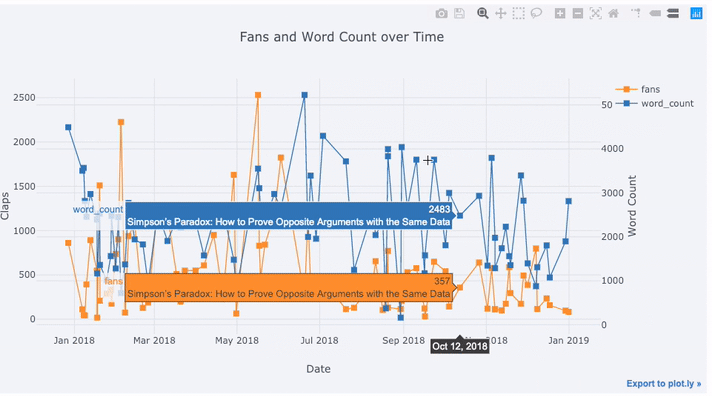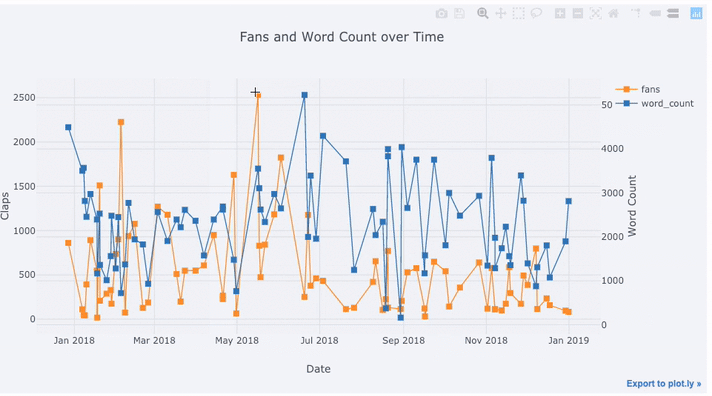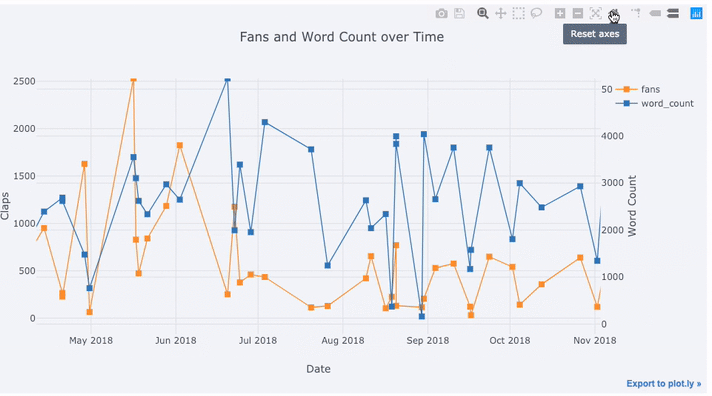
Vemos algunas cosas diferentes aquí:
- Obtenga automáticamente series de tiempo bien formateadas en el eje x
- Agregar un eje y secundario porque nuestras variables tienen diferentes rangos
- Mostrar títulos de artículos al desplazar
Para obtener más información, podemos agregar anotaciones de texto con bastante facilidad:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')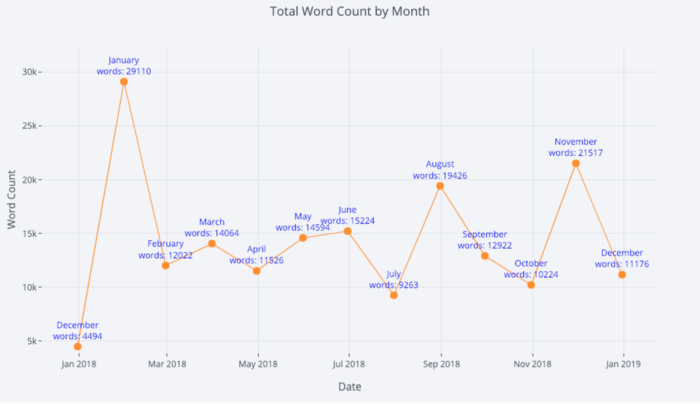
Para un diagrama de dispersión de dos variables coloreado con una tercera variable categórica, utilizamos:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')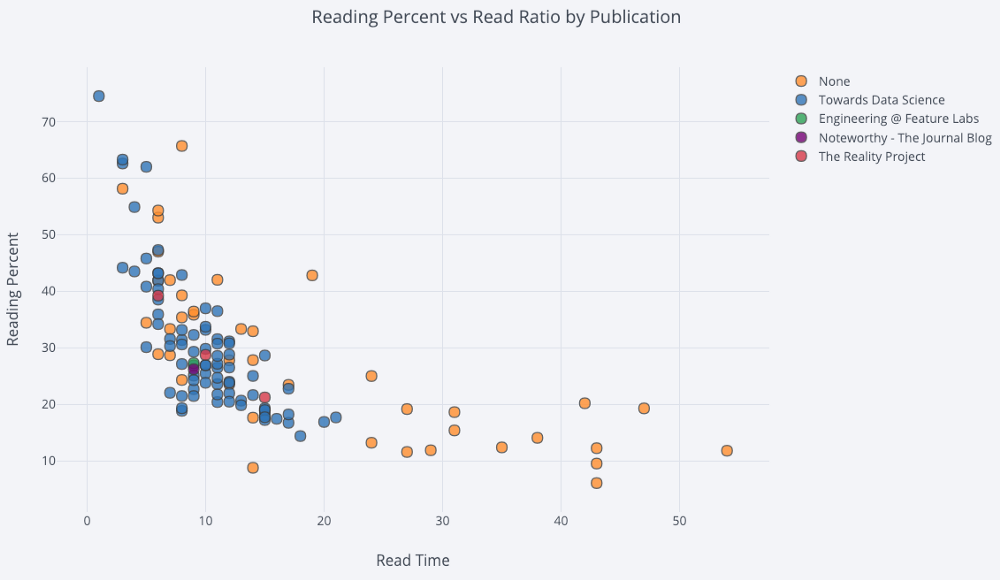
Vamos a complicar un poco las cosas usando un eje de registro, especificado como diseño de trazado (consulte la documentación de trazado para conocer las especificaciones de diseño) y especificando el tamaño de las burbujas de una variable numérica:
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
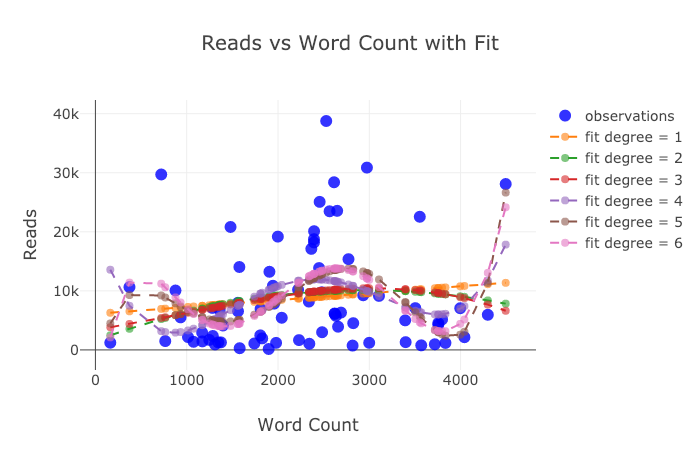
title='Reads vs Log Word Count Sized by Read Ratio'))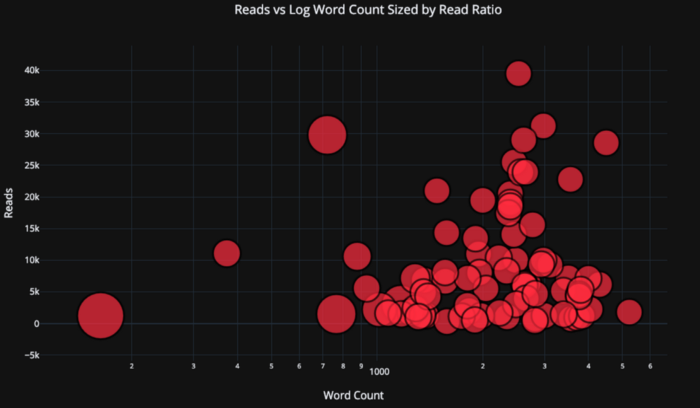
Con un poco de trabajo ( vea el Cuaderno de notas para más información ), ¡podemos incluso poner cuatro variables ( no recomendadas ) en un gráfico!
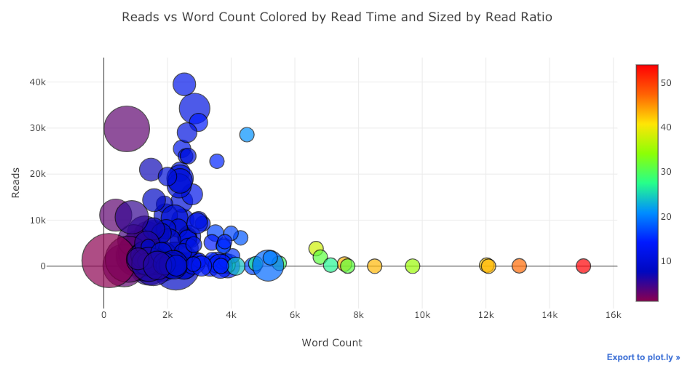
Como antes, podemos combinar Pandas con plotly + gemelos para obtener gráficos útiles
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))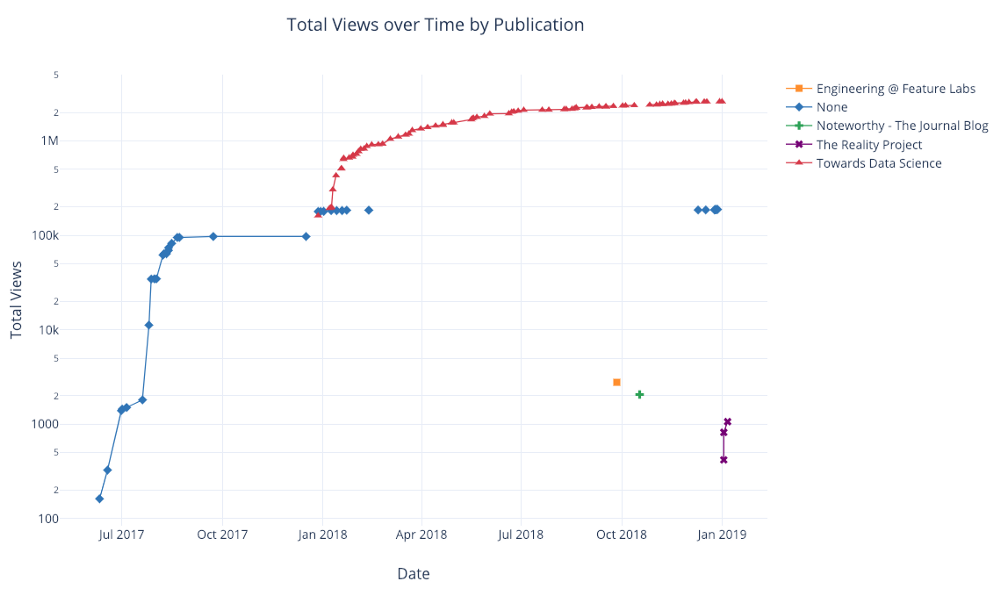
Para obtener más ejemplos de funcionalidad, consulte el cuaderno o la documentación . Podemos agregar anotaciones de texto, líneas de referencia y líneas de mejor ajuste a nuestros diagramas con una línea de código y aún con todas las interacciones.
Gráficos avanzados
Ahora pasamos a algunos gráficos que probablemente no usará con tanta frecuencia, pero que pueden ser bastante impresionantes. Usaremos plotly figure_factory para hacer incluso estas increíbles haffics en una línea.
Matriz de dispersión
Cuando queremos explorar las relaciones entre muchas variables, la matriz de dispersión (también llamada splom) es una gran opción:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')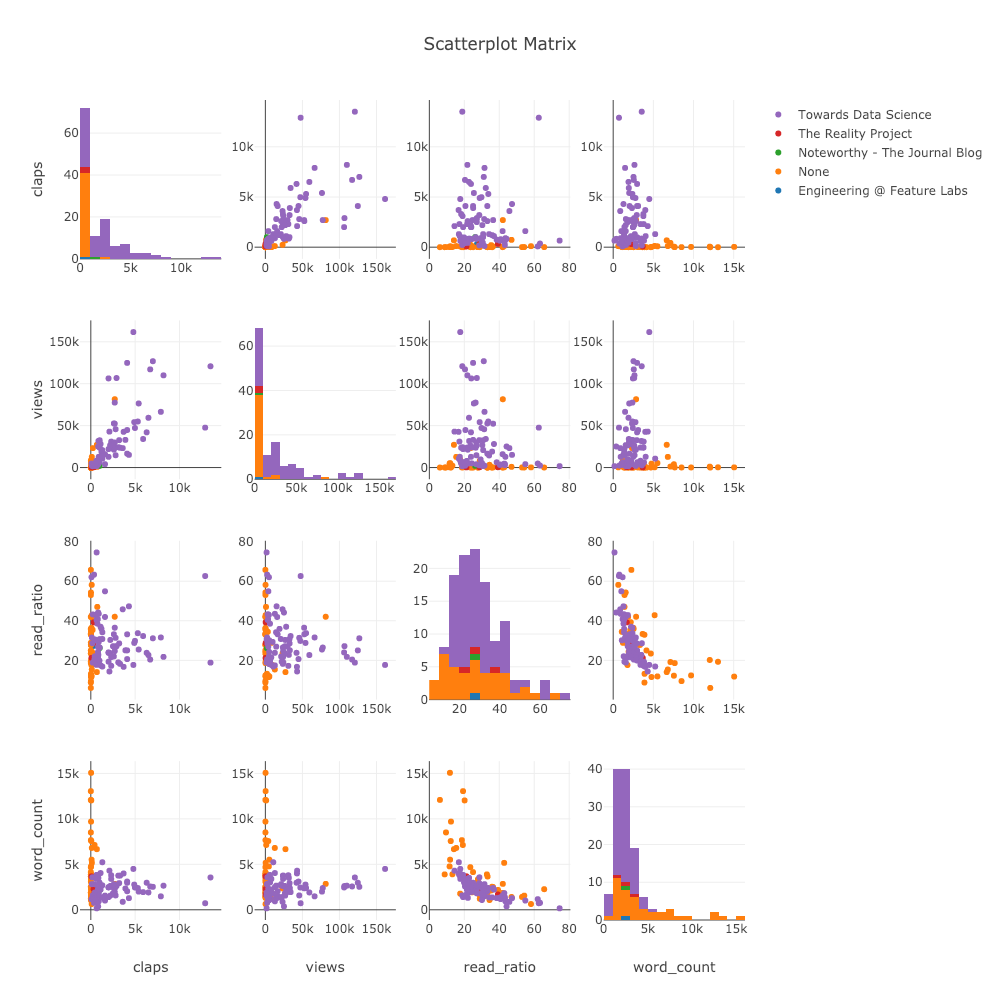
Incluso este gráfico es completamente interactivo, lo que nos permite explorar los datos.
Mapa de calor de correlación
Para visualizar correlaciones entre variables numéricas, calculamos las correlaciones y luego hacemos un mapa de calor anotado:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
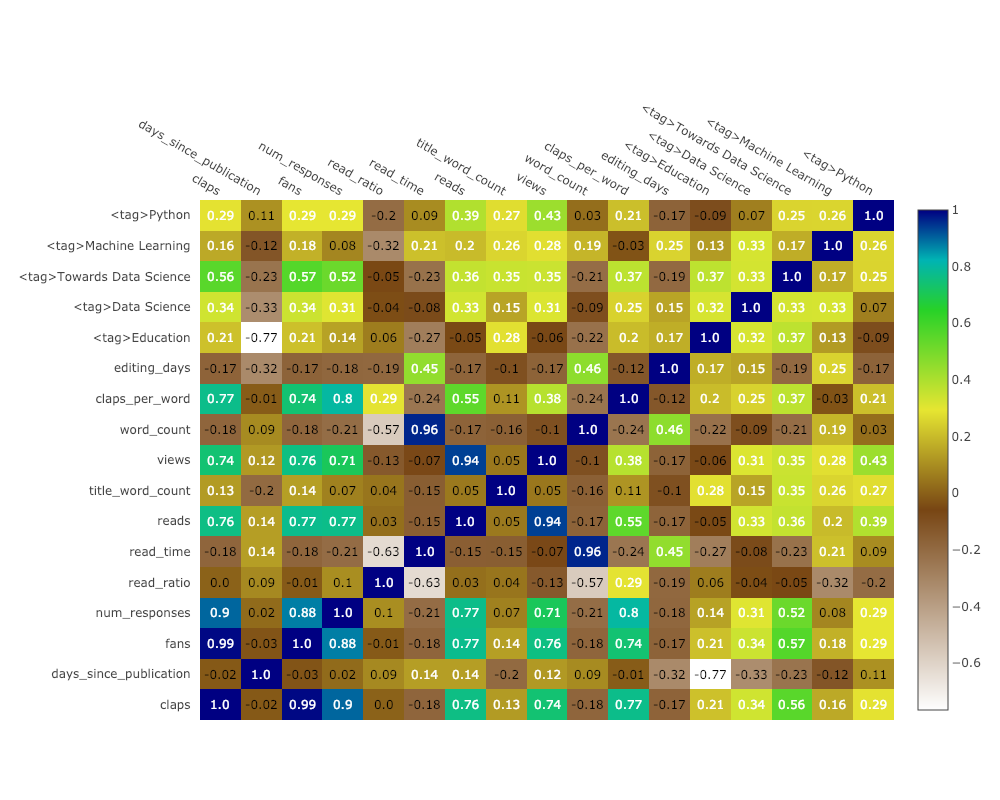
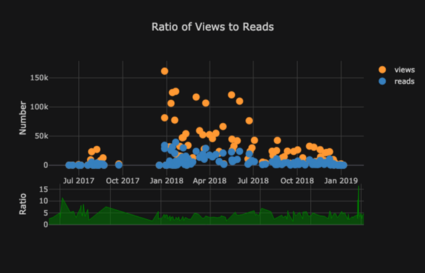
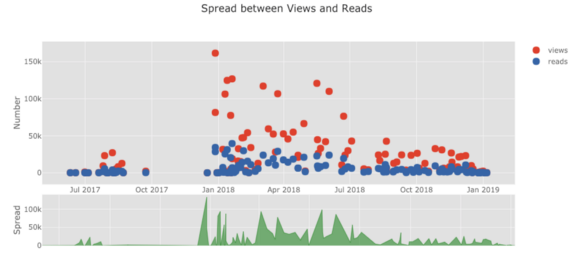
La lista de gráficos sigue y sigue. gemelos también tiene varios temas que podemos usar para obtener una apariencia completamente diferente sin ningún esfuerzo. Por ejemplo, a continuación tenemos un gráfico de proporción en el tema "espacio" y un diagrama de dispersión en "ggplot":
También obtenemos gráficos 3D (superficies y gráficos de burbujas):
para aquellos que quieran , incluso pueden hacer un gráfico circular:
Edición en Plotly Chart Studio
Cuando realice estos gráficos en NoteBook Jupiter, notará un pequeño enlace en la esquina inferior derecha del gráfico "Exportar a plot.ly", si hace clic en este enlace, será llevado a Chart Studio donde puede ajustar su gráfico para la presentación final. Puede agregar anotaciones, especificar colores y, en general, borrar todo para obtener un gráfico excelente. Luego, puede publicar su horario en Internet para que cualquiera pueda encontrarlo como referencia.
A continuación hay dos gráficos que modifiqué en Chart Studio: a
pesar de lo que se ha dicho aquí, ¡todavía no hemos explorado todas las características de la biblioteca! Le aconsejaría que mire tanto la documentación de la trama como la documentación de los gemelos para obtener parcelas más increíbles.
conclusiones
La peor parte del concepto erróneo infravalorado es que solo te das cuenta de cuánto tiempo has perdido después de dejar de fumar. Afortunadamente, ahora que he cometido el error de quedarme con matploblib durante demasiado tiempo, ¡no tienes que hacerlo!
Cuando pensamos en las bibliotecas de tramas, hay varias cosas que queremos:
- Gráficos de una línea para una exploración rápida.
- Sustitución / exploración interactiva de datos
- La capacidad de profundizar en los detalles según sea necesario
- Fácil configuración para la presentación final.
Por el momento, la mejor opción para hacer todo esto en Python es plotly. Plotly nos permite hacer visualizaciones rápidamente y nos ayuda a comprender mejor nuestros datos a través de la interactividad. Además, seamos sinceros, ¡los gráficos deben ser una de las mejores partes de la ciencia de datos! Con otras bibliotecas, trazar se ha convertido en una tarea tediosa, pero con plotly, ¡existe la alegría de volver a hacer una gran figura!

Descubra los detalles de cómo obtener una profesión de alto perfil desde cero o subir de nivel en habilidades y salario tomando los cursos en línea pagos de SkillFactory:
- Formación de la profesión de Data Science desde cero (12 meses)
- Profesión analítica con cualquier nivel inicial (9 meses)
- Curso de aprendizaje automático (12 semanas)
- «Python -» (9 )
- DevOps (12 )
- - (8 )