Prerrequisitos
La tarea de buscar una frase en un texto paginado se reduce a calcular el coeficiente de relevancia para cada una de las páginas y luego ordenar la lista en orden descendente del coeficiente.
En el proceso de cálculo de acuerdo con el enfoque básico, cada página está sujeta a análisis símbolo por símbolo, y aquí radica la posibilidad de optimización.

Al calcular el coeficiente, se analizan grupos de caracteres coincidentes de cadenas de búsqueda y datos, mientras que los grupos se pueden formar solo dentro de las palabras. Por otro lado, considerando el problema de sobreestimar la importancia de las palabras "largas" (en la parte 2 ), como una posible solución, se propuso " calcular la relevancia de una frase de búsqueda como un promedio de las relevancias de las palabras incluidas en ella, calculadas independientemente ". El uso de un índice producirá un resultado equivalente a este enfoque particular.
Índice
La idea de indexación no es nueva y es la siguiente: debido a que las palabras en el texto se repiten, la cantidad de cálculos se puede reducir. Para hacer esto, el texto en el que se realizará la búsqueda debe generar primero un índice. En el caso más simple, el índice es una tabla de todas las palabras en el texto, que, además de las palabras, contiene datos sobre las páginas en las que aparecen. Fragmento de la tabla índice basada en el texto de la novela de L.N. La "Guerra y paz" de Tolstoi (en total contiene alrededor de 50 mil palabras), se muestra en la figura.

Directamente en el proceso de procesar una solicitud, la cadena de búsqueda se divide primero en palabras. Además, para cada una de las palabras de la cadena de búsqueda, la relevancia se calcula con cada una de las palabras en el índice . Los resultados del cálculo se acumulan entabla de resultados preliminares que contiene las columnas "Palabra de cadena de búsqueda", "Palabra de índice", "Factor de relevancia", "Número de página". La tabla contiene solo aquellas filas del índice, el coeficiente de relevancia para el cual las palabras han excedido el umbral especificado. Es decir, cada fila del índice con una palabra coincidente genera filas en la tabla de resultados preliminares iguales al número de páginas de texto en las que aparece esta palabra. A continuación se muestra un fragmento de la tabla de resultados preliminares para la búsqueda de la frase "Tarde en casa de Anna Pavlovna Sherer".

Luego, la tabla de resultados preliminares se ordena por columnas Número de página , Palabra de cadena de búsqueda , Factor(descendiendo)

Al recorrer las filas de la tabla ordenada, para cada una de las páginas y para cada palabra de la cadena de búsqueda, se identifica la palabra más relevante de esta página; gracias a la clasificación descrita anteriormente, esta es la primera palabra para cada número de página de combinación : palabra de cadena de búsqueda . El resto de las líneas se descartan por combinación.
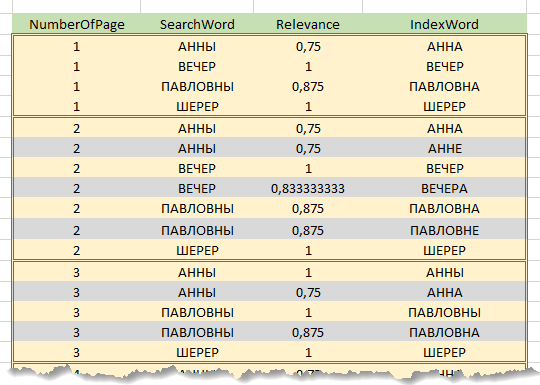
Por lo tanto, para cada página de texto incluida en la tabla de resultados preliminares , para cada palabra en la cadena de búsqueda, se encontrarán las palabras más relevantes de esta página con los coeficientes correspondientes. La suma de los coeficientes de las palabras encontradas en la página, referida al número de palabras en la barra de búsqueda, dará el coeficiente de relevancia para la página.

Por ejemplo, en la figura anterior, la búsqueda se realiza por la línea "Tarde en casa de Anna Pavlovna Sherer" (la preposición "y" no se tiene en cuenta), las líneas resaltadas en gris se descartan durante el recorrido. El coeficiente de relevancia para la página 1 será (0.75 + 1 + 0.875 + 1) / 4 = 0.906, para la página 2 - 0.906, para 3 - 0.75.
Beneficios
Si usted no toma en cuenta el tiempo transcurrido en la indexación, los resultados de los que se vuelven a utilizar y tener en cuenta que la cantidad total de la computación, la evaluación de los cuales se reproduce en la parte 1. , un múltiplo de la longitud de la cadena de datos:
 ;
;
podemos decir que la ganancia del uso del índice será un múltiplo de la relación:
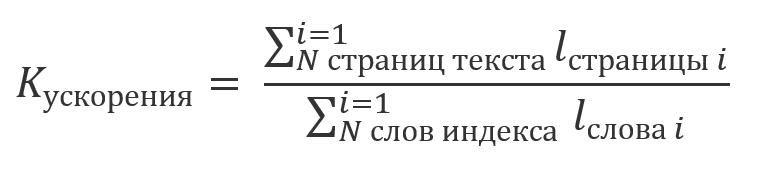
por ejemplo, en el stand de demostración textradar.ru , el texto de la novela "Guerra y paz" se divide en 1488 páginas de 2000 caracteres cada una. El número total de símbolos en las palabras del índice, que consta de 52156 elementos, es 434060. Es decir, la ganancia de la indexación será de aproximadamente 7:

Debido al hecho de que los resultados obtenidos usando la indexación son equivalentes a los resultados obtenidos usando uno de los enfoques descritos anteriormente sin él, es posible procesar conjuntamente los resultados de búsqueda para las partes indexadas y no indexadas del texto. Debido al hecho de que la indexación es una operación relativamente costosa y generalmente se realiza de manera programada, es posible que una parte del texto esté indexada, y parte todavía no. En este caso, el ahorro en la cantidad de cálculo será un múltiplo de la parte del texto indexado en su tamaño total:
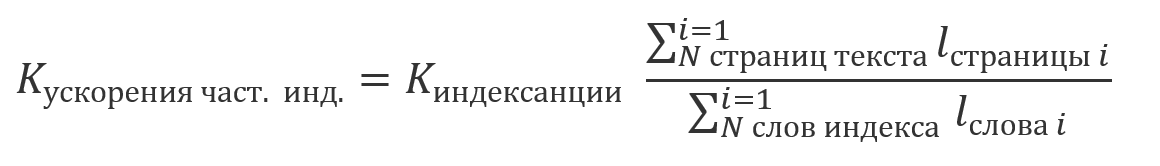
Además de mejorar la velocidad de búsqueda, el uso de un índice abre otras posibilidades. Por ejemplo, utilizando estadísticas obtenidas de la indexación, puede aumentar la importancia de las palabras raras, así como resaltar las páginas de texto en las que se encuentran con mayor frecuencia las palabras significativas de la frase de búsqueda. También puede ampliar la tabla de índice con sinónimos.
Esto concluye el ciclo de publicaciones dedicadas a la descripción de TextRadar. Gracias a todos por su interés y valiosos comentarios que nos permitieron avanzar más de lo planeado originalmente.
Los resultados de la aplicación de los enfoques descritos se pueden ver en el soporte de demostración implementado en el sitio web textradar.ru . La implementación (C # ASP.NET MVC) se puede encontrar aquí .