
Buen día. Nuestros nombres son Tatiana Voronova y Elvira Dyaminova, nos dedicamos al análisis de datos en el Centro 2M. En particular, entrenamos modelos de redes neuronales para detectar objetos en imágenes: personas, equipos especiales, animales.
Al comienzo de cada proyecto, la empresa negocia con los clientes sobre la calidad de reconocimiento aceptable. Este nivel de calidad no solo debe garantizarse a la entrega del proyecto, sino que también debe mantenerse durante el funcionamiento posterior del sistema. Resulta que es necesario monitorear y entrenar constantemente el sistema. Me gustaría reducir los costos de este proceso y deshacerme del procedimiento de rutina, liberando tiempo para trabajar en nuevos proyectos.
El reentrenamiento automático no es una idea única, muchas empresas tienen herramientas de canalización internas similares. En este artículo, nos gustaría compartir nuestra experiencia y demostrar que no es necesario ser una gran corporación para implementar con éxito tales prácticas.
Uno de nuestros proyectos es contar personas en las colas . Debido al hecho de que el cliente es una gran empresa con una gran cantidad de sucursales, las personas a ciertas horas se acumulan según lo programado, es decir, se detecta regularmente una gran cantidad de objetos (cabezas de personas). Por lo tanto, decidimos comenzar la implementación del reentrenamiento automático precisamente para esta tarea.
Así es como se veía nuestro plan. Todos los artículos, excepto el trabajo del trazador, se llevan a cabo en modo automático:
- Una vez al mes, todas las imágenes de la cámara de la última semana se seleccionan automáticamente.
- xls- sharepoint, - : « ».
- ( ) – xml- ( ), – .
- « ». xls- ( – , – ). «». , , .
, : (, ) , , (, - ). -. - xls- «» > 0. , ( ). , . , , « ». , . , . , , .
- «» 0, – - .
- , , , , . , .
Al final, este proceso nos ayudó mucho. Seguimos el aumento de los errores del segundo tipo, cuando muchas cabezas se "enmascararon" repentinamente, enriquecieron el conjunto de datos de entrenamiento con un nuevo tipo de cabezas a tiempo y reentrenaron el modelo actual. Además, este viaje le permite tener en cuenta la estacionalidad. Estamos ajustando constantemente el conjunto de datos teniendo en cuenta la situación actual: las personas a menudo usan sombreros o, por el contrario, casi todos llegan a la institución sin ellos. En otoño, aumenta el número de personas que usan capuchas. El sistema se vuelve más flexible y reacciona a la situación.
Por ejemplo, en la imagen a continuación, una de las ramas (en un día de invierno), cuyos marcos no se presentaron en el conjunto de datos de entrenamiento:
Si calculamos las métricas para este marco (TP = 25, FN = 3, FP = 0), resulta que la recuperación es del 89%, la precisión es del 100% y el promedio armónico entre la precisión y la integridad es de aproximadamente 94. 2% (sobre las métricas justo debajo). Muy buen resultado para una nueva habitación.
Nuestro conjunto de datos de entrenamiento tenía tanto tapas como capuchas, por lo que el modelo no se confundió, pero con el inicio del modo de máscara comenzó a cometer errores. En la mayoría de los casos, cuando la cabeza es claramente visible, no surgen problemas. Pero si una persona está lejos de la cámara, entonces en cierto ángulo, el modelo deja de detectar la cabeza (la imagen izquierda es el resultado del trabajo del modelo anterior). Gracias a la marca semiautomática, pudimos arreglar estos casos y volver a entrenar el modelo a tiempo (la imagen correcta es el resultado del nuevo modelo).

Lady close:

Al probar el modelo, seleccionamos marcos que no estaban involucrados en el entrenamiento (un conjunto de datos con un número diferente de personas en el marco, desde diferentes ángulos y diferentes tamaños), para evaluar la calidad del modelo, utilizamos memoria y precisión.
Recordemos : la integridad muestra qué proporción de objetos que realmente pertenecen a una clase positiva, predijimos correctamente.
Precisión : la precisión muestra qué proporción de objetos reconocidos como objetos de una clase positiva, predijimos correctamente.
Cuando un cliente necesitaba un solo dígito, una combinación de precisión e integridad, proporcionamos la media armónica o medida F. Obtenga más información sobre las métricas.
Después de un ciclo, obtuvimos los siguientes resultados:
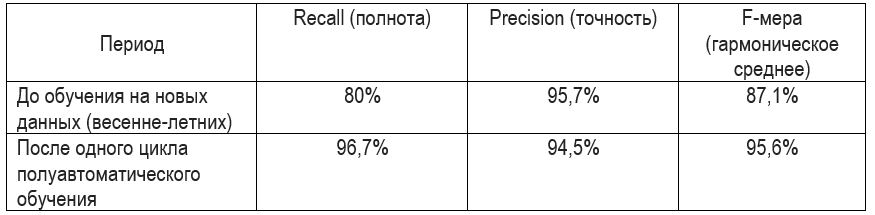
La integridad del 80% antes de cualquier cambio se debe al hecho de que se agregaron una gran cantidad de nuevos departamentos al sistema, aparecieron nuevas vistas. Además, la temporada ha cambiado, antes de eso, se presentaron "personas otoño-invierno" en el conjunto de datos de entrenamiento.
Después del primer ciclo, la integridad se convirtió en 96.7%. En comparación con el primer artículo, la integridad allí alcanzó el 90%. Tales cambios se deben al hecho de que ahora el número de personas en los departamentos ha disminuido, comenzaron a superponerse mucho menos (se han agotado las abultadas chaquetas) y la variedad de sombreros ha disminuido.
Por ejemplo, antes de que la norma fuera aproximadamente la misma cantidad de personas que en la imagen a continuación.

Así son las cosas ahora.

En resumen, mencionemos las ventajas de la automatización:
- Automatización parcial del proceso de marcado.
- ( ).
- ( ).
- . .
- . , .
La desventaja es el factor humano por parte del diseñador de marcado: puede que no sea lo suficientemente responsable del marcado, por lo tanto, el marcado con superposición o el uso de conjuntos dorados: las tareas con una respuesta predeterminada, que solo sirven para controlar la calidad del marcado, son necesarias. En muchas tareas más complejas, el analista debe verificar personalmente el marcado; en tales tareas, el modo automático no funcionará.
En general, la práctica del reciclaje automático ha demostrado ser viable. Dicha automatización puede considerarse como un mecanismo adicional que permite mantener la calidad de reconocimiento en un buen nivel durante el funcionamiento posterior del sistema.
Autores del artículo: Tatiana Voronova (tvoronova), Elvira Dyaminova (elviraa)