
Este artículo describe los detalles técnicos de los problemas que causaron el bloqueo de Slack el 12 de mayo de 2020. Para más información sobre el proceso de respuesta a ese incidente, vea la cronología de Ryan Katkov, "Ambas manos en el control remoto" .
El 12 de mayo de 2020, Slack experimentó su primer accidente significativo en mucho tiempo. Pronto publicamos un resumen del incidente , pero es una historia bastante interesante, por lo que nos gustaría profundizar en los detalles técnicos con más detalle.
Los usuarios notaron el tiempo de inactividad a las 4:45 p.m. PT, pero la historia realmente comenzó alrededor de las 8:30 a.m. El equipo de ingeniería de confiabilidad de la base de datos recibió una advertencia sobre un aumento significativo en la carga de parte de la infraestructura. Al mismo tiempo, el Equipo de Tráfico recibió advertencias de que no estamos haciendo algunas solicitudes de API.
El aumento de la carga de la base de datos fue causado por el despliegue de una nueva configuración, lo que provocó un error de rendimiento de larga data. El cambio se detectó rápidamente y retrocedió: era una bandera para una función que realizaba un despliegue gradual, por lo que el problema se resolvió rápidamente. El incidente tuvo poco impacto en los clientes, pero solo duró tres minutos y la mayoría de los usuarios aún pudieron enviar mensajes con éxito durante esta breve falla de la mañana.
Una de las consecuencias del incidente fue una expansión significativa de nuestra capa principal de aplicaciones web. Nuestro CEO Stuart Butterfield escribió sobre algunos de los efectos de la cuarentena y el autoaislamiento en el uso de Slack. Como resultado de la pandemia, lanzamos significativamente más instancias a nivel de aplicación web que en febrero de este año. Escalamos rápidamente cuando se cargan los trabajadores, como sucedió aquí, pero los trabajadores esperaron mucho más tiempo para que se completaran algunas consultas de la base de datos, lo que provocó una carga mayor. Durante el incidente, aumentamos el número de instancias en un 75%, lo que resultó en el mayor número de hosts de aplicaciones web que hemos ejecutado hasta hoy.
Todo parecía estar funcionando bien durante las siguientes ocho horas, hasta que apareció un número inusualmente alto de errores HTTP 503 . Lanzamos un nuevo canal de respuesta a incidentes, y el ingeniero de aplicaciones web de servicio aumentó manualmente la flota de aplicaciones web como mitigación inicial. Por extraño que parezca, no ayudó en absoluto. Notamos muy rápidamente que algunas de las instancias de aplicaciones web estaban bajo una gran carga, mientras que el resto no. Numerosos estudios han comenzado a investigar tanto el rendimiento de la aplicación web como el equilibrio de carga. Después de unos minutos, identificamos el problema.
Detrás del equilibrador de carga de la capa 4 hay un conjunto de instancias HAProxy para distribuir solicitudes al nivel de aplicación web. Utilizamos Consul para el descubrimiento de servicios y una plantilla de cónsul para representar listas de backends de aplicaciones web saludables a las que HAProxy debe enrutar las solicitudes.
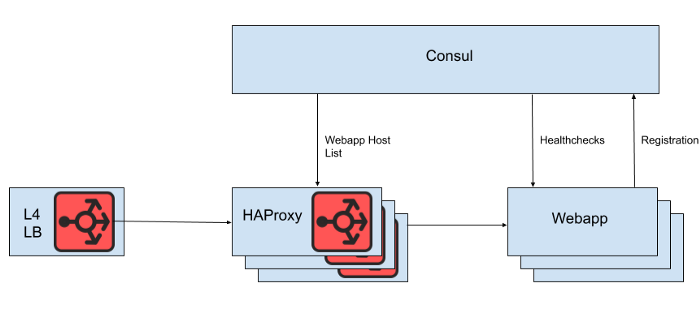
Higo. 1. Una vista de alto nivel de la arquitectura de equilibrio de carga de Slack
Sin embargo, no representamos la lista de hosts de aplicaciones web directamente desde el archivo de configuración de HAProxy, porque la actualización de la lista requeriría un reinicio de HAProxy. El proceso de reinicio de HAProxy implica crear un proceso completamente nuevo, mientras se mantiene el antiguo hasta que termine de procesar las solicitudes actuales. Los reinicios muy frecuentes pueden provocar la ejecución de demasiados procesos HAProxy y un bajo rendimiento. Esta limitación entra en conflicto con el objetivo de escalar automáticamente el nivel de aplicación web, que es traer nuevas instancias a producción lo más rápido posible. Por lo tanto, estamos utilizando la API HAProxy Runtimepara administrar el estado del servidor HAProxy sin reiniciar cada vez que el servidor de nivel web entra o sale. Vale la pena señalar que HAProxy puede integrarse con la interfaz DNS de Consul, pero esto agrega retraso debido al DNS TTL, limita la capacidad de usar etiquetas Consul, y administrar respuestas DNS muy grandes a menudo conduce a situaciones de borde dolorosas y errores.

Higo. 2. Cómo se administra un conjunto de aplicaciones web en un solo servidor Slack HAProxy
En nuestro estado HAProxy, definimos plantillas para servidores HAProxy. De hecho, estos son "espacios" que pueden ocupar los servidores de aplicaciones web. Cuando se implementa una instancia de una nueva aplicación web o la anterior comienza a fallar, el catálogo de servicios de Consul se actualiza. Consul-template imprime una nueva versión de la lista de hosts, y un programa de administración de estado de servidor-servidor independiente desarrollado en Slack lee esta lista de hosts y utiliza la API HAProxy Runtime API para actualizar el estado de HAProxy.
Ejecutamos M grupos de instancias HAProxy concurrentes y grupos de aplicaciones web, cada uno en una zona de disponibilidad de AWS separada. HAProxy está configurado con N "ranuras" para backends de aplicaciones web en cada AZ, dando un total de N * M backends que pueden dirigirse a todas las AZ. Hace unos meses, ese número era más que suficiente: nunca hemos lanzado nada ni siquiera cerca de tantas instancias de nuestro nivel de aplicación web. Sin embargo, después del incidente de la base de datos de la mañana, lanzamos un poco más que las instancias de aplicaciones web N * M. Si piensa en las tragamonedas HAProxy como un juego gigante de sillas, algunas de estas instancias de aplicaciones web quedan sin espacio. Esto no fue un problema: tenemos una capacidad de servicio más que suficiente.
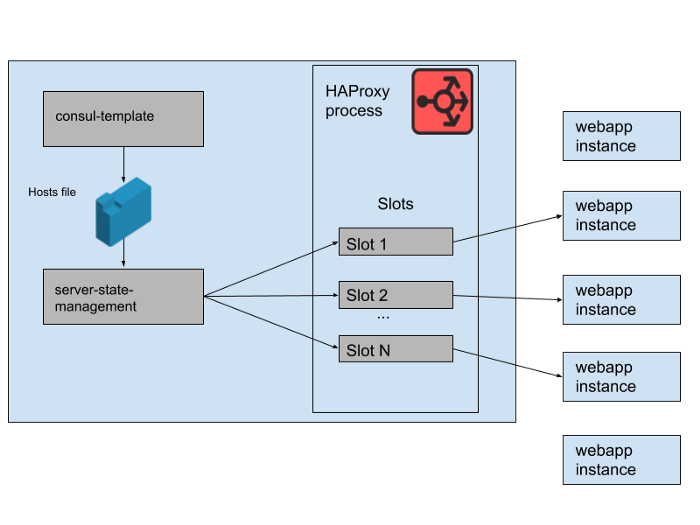
Higo. 3. "Ranuras" en el proceso HAProxy con algunas instancias de aplicaciones web redundantes que no reciben tráfico
Sin embargo, hubo un problema durante el día. Hubo un error en el programa que sincronizó la lista de hosts generada por la plantilla de cónsul con el estado del servidor HAProxy. El programa siempre trató de encontrar un espacio para nuevas instancias de aplicaciones web antes de liberar espacios ocupados por instancias antiguas de aplicaciones web que ya no funcionan. Este programa comenzó a arrojar errores y salir temprano porque no podía encontrar ningún espacio vacío, lo que significaba que las instancias de HAProxy en ejecución no estaban actualizando su estado. A medida que avanzaba el día, el grupo de escalado automático de aplicaciones web creció y se redujo, y la lista de backends en el estado HAProxy se volvió cada vez más obsoleta.
A las 4:45 p.m., la mayoría de las instancias de HAProxy solo podían enviar solicitudes al conjunto de backends disponibles en la mañana, y este conjunto de backends de aplicaciones web ahora era una minoría. Regularmente proporcionamos nuevas instancias de HAProxy, por lo que hubo algunas nuevas con la configuración correcta, pero la mayoría de ellas tenían más de ocho horas y, por lo tanto, se quedaron con un estado de fondo completo y desactualizado. Finalmente, el servicio se bloqueó. Esto sucedió al final de un día hábil en los Estados Unidos, porque es cuando comenzamos a escalar el nivel de la aplicación web a medida que disminuye el tráfico. La escala automática cerraría las instancias antiguas de aplicaciones web en primer lugar, lo que significaba que no quedaban suficientes en el estado del servidor de HAProxy para satisfacer la demanda.
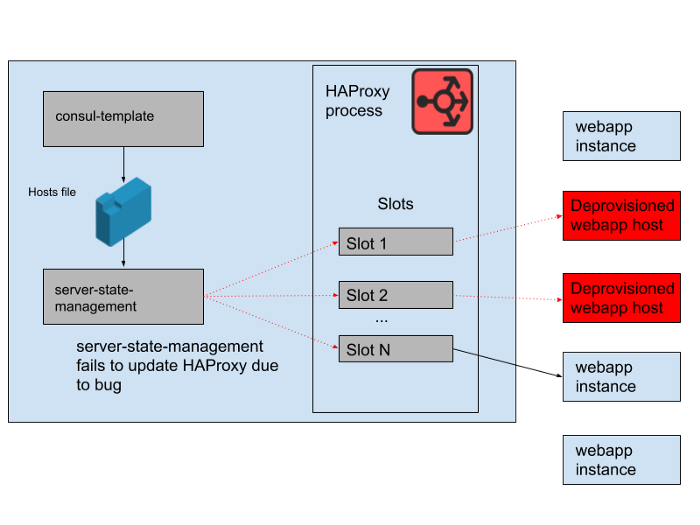
Higo. 4. El estado de HAProxy cambió con el tiempo y las ranuras comenzaron a referirse principalmente a hosts remotos.
Una vez que descubrimos la causa de la falla, se solucionó rápidamente mediante un reinicio sin problemas de la flota de HAProxy. Después de eso, inmediatamente hicimos una pregunta: por qué el monitoreo no detectó este problema. Tenemos un sistema de alerta para esta situación particular, pero desafortunadamente no funcionó según lo previsto. La falla de monitoreo no se notó, en parte porque el sistema "simplemente funcionó" durante mucho tiempo y no requirió ningún cambio. La implementación más amplia de HAProxy de la que forma parte esta aplicación también es relativamente estática. A un ritmo lento de cambio, menos ingenieros interactúan con la infraestructura de monitoreo y alerta.
No volvimos a trabajar mucho esta pila de HAProxy, porque estamos moviendo gradualmente todo el equilibrio de carga a Envoy (recientemente trasladamos el tráfico websocket). HAProxy ha servido bien y de manera confiable durante muchos años, pero tiene algunos problemas operativos como en este incidente. Reemplazaremos la compleja tubería para administrar el estado del servidor HAProxy con nuestra propia integración de Envoy con el plano de control xDS para el descubrimiento de punto final. Las versiones más recientes de HAProxy (desde la versión 2.0) también resuelven muchos de estos problemas operativos. Sin embargo, hemos estado confiando en Envoy con la malla de servicio interno durante algún tiempo, por lo que también nos esforzamos por transferirle el equilibrio de carga. Nuestras pruebas iniciales de Envoy + xDS a escala parecen prometedoras, y esta migración debería mejorar tanto el rendimiento como la disponibilidad en el futuro.La nueva arquitectura de equilibrio de carga y descubrimiento de servicios es inmune al problema que causó esta falla.
Nos esforzamos por mantener Slack accesible y confiable, pero en este caso hemos fallado. Slack es una herramienta esencial para nuestros usuarios, por eso nos esforzamos por aprender de cada incidente, ya sea que los clientes lo noten o no. Lamentamos los inconvenientes causados por esta falla. Prometemos utilizar este conocimiento para mejorar nuestros sistemas y procesos.